Design of Convolutional Neural Network acceleration module based on FPGA
Mei Zhiwei1,2, Wang Weidong,1,2
1.College of Information Science & Electronic Engineering,Zhejiang University,Hangzhou,310013,China
2.ZJU⁃Rock Chips Joint Laboratory of Multimedia System,College of Information Science & Electronic Engineering,Zhejiang University,Hangzhou,310013,China
针对卷积神经网络前向推理硬件加速的研究,提出一种基于FPGA(Field Programmable Gate Array)的卷积神经网络加速模块,以期在资源受限的硬件平台中加速卷积运算.通过分析卷积神经网络基本结构与常见卷积神经网络的特性,设计了一种适用于常见卷积神经网络的硬件加速架构.在该架构中,采用分层次缓存数据与分类复用数据策略,优化卷积层片外访存总量,缓解带宽压力;在计算模块中,在输入输出通道上并行计算,设计了将乘加树与脉动阵列相结合的高效率计算阵列,兼顾了计算性能与资源消耗.实验结果表明,提出的加速模块运行VGG⁃16(Visual Geometry Group)卷积神经网络性能达到189.03 GOPS(Giga Operations per Second),在DSP(Digital Signal Processor)性能效率上优于大部分现有的解决方案,内存资源消耗比现有解决方案减少41%,适用于移动端卷积神经网络硬件加速.
关键词:卷积神经网络
;
硬件加速
;
FPGA
;
并行计算
;
高效率乘加阵列
Abstract
To accelerate the convolutional operation of Convolutional Neural Network in resource⁃constrained hardware platforms,a Convolutional Neural Network acceleration module based on FPGA (Field Programmable Gate Array) is proposed. By analyzing the basic structure of Convolutional Neural Network and the characteristics of common Convolutional Neural Networks,a hardware acceleration architecture for common Convolutional Neural Networks is designed. In the above architecture,the strategies of hierarchical caching data and classified reusing data are adopted to minimize the total amount of external memory access data and reduce the pressure of bandwidth. Considering the computing performance and resource consumption,a high efficiency computing array is designed which combines multiplicative and additive tree with systolic array for parallel computation on input and output channels in the computing module. The experimental results show that the performance of the proposed acceleration module reaches 189.03 GOPS (Giga Operations per Second) when running VGG⁃16(Visual Geometry Group) Convolutional Neural Network,which is better than most of the existing solutions in terms of DSP performance efficiency,and 41% lower than the existing solutions in terms of memory resource consumption. The proposed module is suitable for hardware acceleration of mobile terminal Convolutional Neural Network.
Mei Zhiwei, Wang Weidong. Design of Convolutional Neural Network acceleration module based on FPGA. Journal of nanjing University[J], 2020, 56(4): 581-590 doi:10.13232/j.cnki.jnju.2020.04.016
对卷积神经网络硬件加速的研究集中在优化加速运算与减少内存访问两个方面.Chen et al[5]设计的DianNao架构通过专用数据通路控制单元调配模块协作,计算单元采用乘加树结构,利用流水线实现卷积加速运算,但并行度低、数据重复利用率低.Qiu et al[6]采用图像处理中常用的滤波器结构缓存输入特征图行数据,数据复用程度高,计算单元结构易于实现乘累加,但在硬件电路中卷积窗口确定,难以适应不同尺寸卷积核的卷积神经网络.Chen et al[7]的Eyeriss为减小能耗提出Row Stationary数据流设计,通过配置计算阵列映射最大化局部数据复用来实线能效的优化,但乘加(Multiply and Accumulate,MAC)阵列映射策略复杂、阵列互连线太多,难以提高阵列规模.Wei et al[8]与Jouppi et al[9]采用脉动阵列进行乘加阵列设计,脉动阵列中的局部互连网络及相邻计算单元之间的数据传输,使得大规模脉动阵列综合后可以在高频率时钟下工作,加速性能优异,但数据预处理部分逻辑复杂、存储资源消耗偏大.
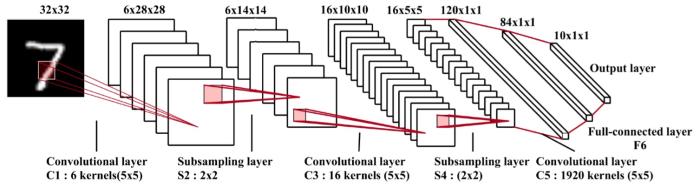
Feng et al[10]指出卷积层的计算量占整个卷积神经网络计算量的90%以上,卷积神经网络硬件加速的核心在于对卷积层计算的加速.卷积层的输入为三维(宽×高×通道)输入特征图和四维(宽×高×输入通道×输出通道)权重卷积核,输出为三维(宽×高×通道)输出特征图,中间运算为六重循环的乘加运算.卷积层运算的C语言代码见代码1,其中填充参数P根据是否需要补零的操作判断对输入特征图是否进行填充,S表示卷积运算窗口的滑动步长.卷积运算在填充后的输入特征图上依次截取大小的特征图与同等大小的三维卷积核进行乘累加,得到输出特征图的一个数据,根据滑动步长从左到右、从上到下遍历输入特征图,得到二维输出特征图.在卷积核的第四维通道N上,重复上述运算,得到三维输出特征图.在卷积运算六重循环中,三重循环为乘累加计算,三重循环为并行计算,同时在卷积窗口滑动中,部分数据存在重复使用的情况,卷积层的计算特性为并行计算与数据复用提供了较大的设计空间.
代码1 卷积层运算C语言代码
Code 1 The C code of convolutional layer operation
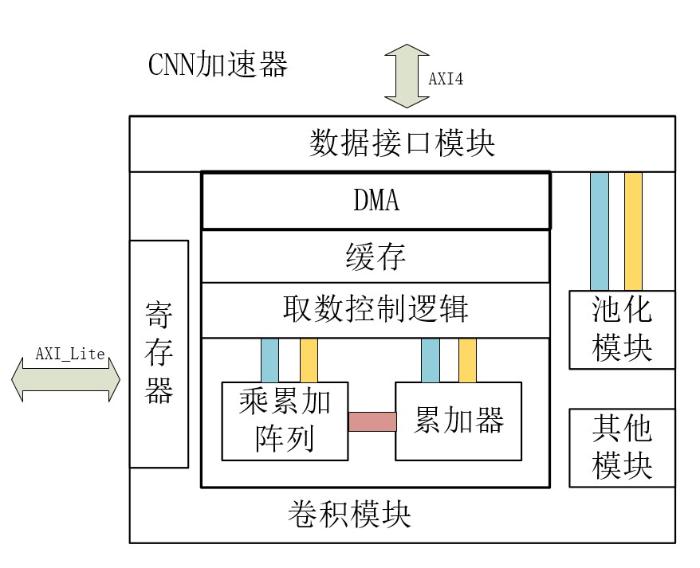
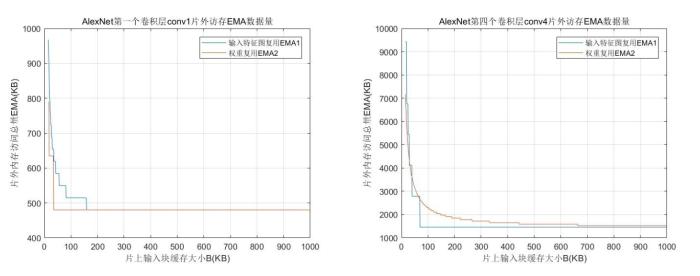
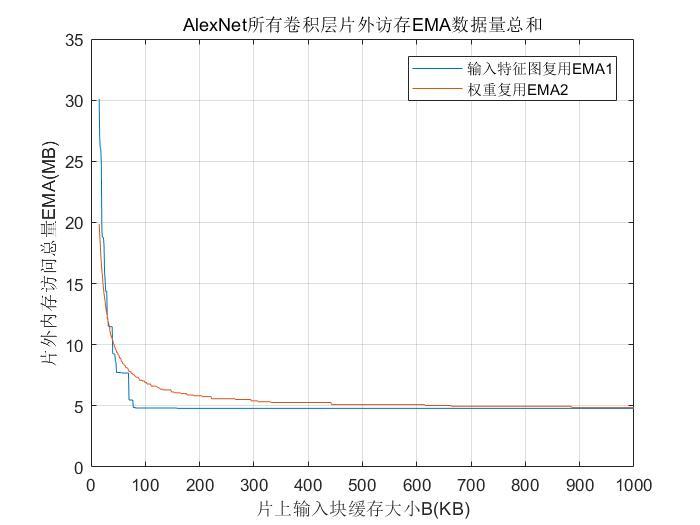
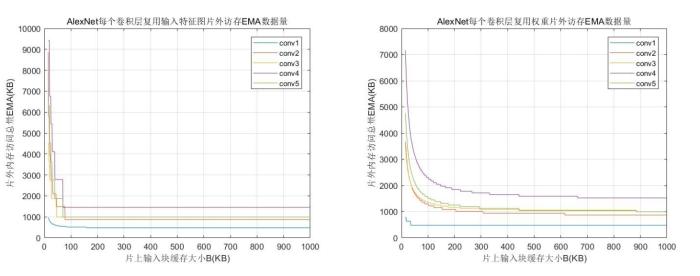
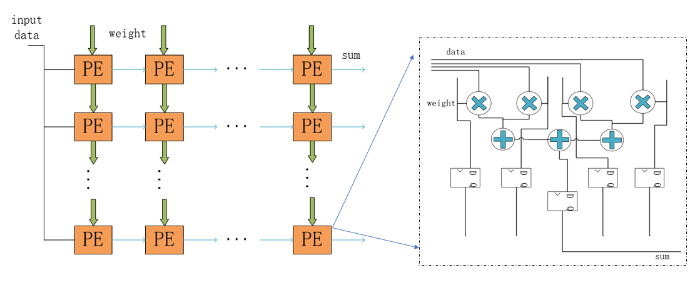
在卷积运算的六层循环中,三重计算可以直接映射到并行维度上,三重乘累加计算,先分块计算后在累加器中进行累加,并行计算设计依然成立.分析常见卷积神经网络中卷积层相关参数,卷积核大小变动较大,从1×1到11×11,映射到固定的乘加阵列中并行计算,在大小变化后乘加阵列资源利用率偏低;输出特征图平面维度随着网络层变深,整体呈递减趋势,且幅度较大,例如从227×227变为6×6.目前在这两个维度上并行计算,多采用分割和拼凑特征图的方法.输入输出通道两个维度,除首层与末层外,输入输出特征图通道数多为32的倍数,合理地利用该特性能够在并行计算上取得较好的效果.本文在并行计算设计上选择输入输出通道两个维度,将其映射到二维乘加阵列上.为了配合并行计算,在FPGA内部数据存储上,参考英伟达(NVIDIA)开源项目中加速器NVDLA(NVIDIA Deep Learning Accelerator)中数据存储格式[11],参与分块计算的输入输出特征图按照(输入通道块、输入宽、输入高)格式存储,权重按照(输入通道块、输出通道块、卷积核宽、卷积核高)格式存储.设定输入并行因子为m,输出并行因子为n,在一个时钟周期内,乘加阵列计算完成次乘加运算,其示意图见图6.
在矩形乘加阵列中有普通互连阵列与脉动阵列两种类型.普通阵列在各个计算单元之间互连线太多,单个数据要输出到所有单元,难以同时满足大规模阵列与高时钟的要求;脉动阵列各个计算单元只与周围连接,数据以脉动的形式从上到下、从左到右流动,计算单元时钟可以达到较高的频率.Wei et al[8]的脉动阵列在时序频率270.8 MHz时,加速性能为406.10 GOPS,但消耗BRAM资源多,还存在一定的计算空窗期.以32×32脉动阵列为例,数据读取与写入时需经63个周期所有计算资源才会同时开始计算.考虑到上述问题,本文提出32×32矩阵乘加阵列,在一个维度上采用互连的形式,一次性完成一个输入特征图数据与32个卷积核数据的并行计算,避免了重复读取数据;另一个维度同时完成输入特征图数据与卷积核数据在32个通道上的乘累加计算,在该维度上将采用脉动的形式传输计算数据,脉动规模为8,每个脉动单元内四个数据采用乘加树的结构进行计算,设计示意图见图7.该结构相对脉动阵列最高时序有所降低,但整体设计上考虑到了并行计算与数据复用,兼顾了性能与资源两个方面,利于在片上存储资源紧张的硬件上实现.
ZhangC,SunG Y,FangZ M,et al. Caffeine:Toward uniformed representation and acceleration for deep convolutional neural networks. IEEE Transactions on Computer:Aided Design of Integrated Circuits and Systems,2018,38(11):2072-2085.
Diannao:a small?footprint high?throughput accelerator for ubiquitous machine?learning
2
2014
... 对卷积神经网络硬件加速的研究集中在优化加速运算与减少内存访问两个方面.Chen et al[5]设计的DianNao架构通过专用数据通路控制单元调配模块协作,计算单元采用乘加树结构,利用流水线实现卷积加速运算,但并行度低、数据重复利用率低.Qiu et al[6]采用图像处理中常用的滤波器结构缓存输入特征图行数据,数据复用程度高,计算单元结构易于实现乘累加,但在硬件电路中卷积窗口确定,难以适应不同尺寸卷积核的卷积神经网络.Chen et al[7]的Eyeriss为减小能耗提出Row Stationary数据流设计,通过配置计算阵列映射最大化局部数据复用来实线能效的优化,但乘加(Multiply and Accumulate,MAC)阵列映射策略复杂、阵列互连线太多,难以提高阵列规模.Wei et al[8]与Jouppi et al[9]采用脉动阵列进行乘加阵列设计,脉动阵列中的局部互连网络及相邻计算单元之间的数据传输,使得大规模脉动阵列综合后可以在高频率时钟下工作,加速性能优异,但数据预处理部分逻辑复杂、存储资源消耗偏大. ...
Going deeper with embedded fpga platform for convolutional neural network
2
2016
... 对卷积神经网络硬件加速的研究集中在优化加速运算与减少内存访问两个方面.Chen et al[5]设计的DianNao架构通过专用数据通路控制单元调配模块协作,计算单元采用乘加树结构,利用流水线实现卷积加速运算,但并行度低、数据重复利用率低.Qiu et al[6]采用图像处理中常用的滤波器结构缓存输入特征图行数据,数据复用程度高,计算单元结构易于实现乘累加,但在硬件电路中卷积窗口确定,难以适应不同尺寸卷积核的卷积神经网络.Chen et al[7]的Eyeriss为减小能耗提出Row Stationary数据流设计,通过配置计算阵列映射最大化局部数据复用来实线能效的优化,但乘加(Multiply and Accumulate,MAC)阵列映射策略复杂、阵列互连线太多,难以提高阵列规模.Wei et al[8]与Jouppi et al[9]采用脉动阵列进行乘加阵列设计,脉动阵列中的局部互连网络及相邻计算单元之间的数据传输,使得大规模脉动阵列综合后可以在高频率时钟下工作,加速性能优异,但数据预处理部分逻辑复杂、存储资源消耗偏大. ...
Eyeriss:An energy?efficient reconfigurable accelerator for deep convolutional neural networks
2
2016
... 对卷积神经网络硬件加速的研究集中在优化加速运算与减少内存访问两个方面.Chen et al[5]设计的DianNao架构通过专用数据通路控制单元调配模块协作,计算单元采用乘加树结构,利用流水线实现卷积加速运算,但并行度低、数据重复利用率低.Qiu et al[6]采用图像处理中常用的滤波器结构缓存输入特征图行数据,数据复用程度高,计算单元结构易于实现乘累加,但在硬件电路中卷积窗口确定,难以适应不同尺寸卷积核的卷积神经网络.Chen et al[7]的Eyeriss为减小能耗提出Row Stationary数据流设计,通过配置计算阵列映射最大化局部数据复用来实线能效的优化,但乘加(Multiply and Accumulate,MAC)阵列映射策略复杂、阵列互连线太多,难以提高阵列规模.Wei et al[8]与Jouppi et al[9]采用脉动阵列进行乘加阵列设计,脉动阵列中的局部互连网络及相邻计算单元之间的数据传输,使得大规模脉动阵列综合后可以在高频率时钟下工作,加速性能优异,但数据预处理部分逻辑复杂、存储资源消耗偏大. ...
Automated systolic array architecture synthesis for high throughput CNN inference on FPGAs
5
2017
... 对卷积神经网络硬件加速的研究集中在优化加速运算与减少内存访问两个方面.Chen et al[5]设计的DianNao架构通过专用数据通路控制单元调配模块协作,计算单元采用乘加树结构,利用流水线实现卷积加速运算,但并行度低、数据重复利用率低.Qiu et al[6]采用图像处理中常用的滤波器结构缓存输入特征图行数据,数据复用程度高,计算单元结构易于实现乘累加,但在硬件电路中卷积窗口确定,难以适应不同尺寸卷积核的卷积神经网络.Chen et al[7]的Eyeriss为减小能耗提出Row Stationary数据流设计,通过配置计算阵列映射最大化局部数据复用来实线能效的优化,但乘加(Multiply and Accumulate,MAC)阵列映射策略复杂、阵列互连线太多,难以提高阵列规模.Wei et al[8]与Jouppi et al[9]采用脉动阵列进行乘加阵列设计,脉动阵列中的局部互连网络及相邻计算单元之间的数据传输,使得大规模脉动阵列综合后可以在高频率时钟下工作,加速性能优异,但数据预处理部分逻辑复杂、存储资源消耗偏大. ...
... 在矩形乘加阵列中有普通互连阵列与脉动阵列两种类型.普通阵列在各个计算单元之间互连线太多,单个数据要输出到所有单元,难以同时满足大规模阵列与高时钟的要求;脉动阵列各个计算单元只与周围连接,数据以脉动的形式从上到下、从左到右流动,计算单元时钟可以达到较高的频率.Wei et al[8]的脉动阵列在时序频率270.8 MHz时,加速性能为406.10 GOPS,但消耗BRAM资源多,还存在一定的计算空窗期.以32×32脉动阵列为例,数据读取与写入时需经63个周期所有计算资源才会同时开始计算.考虑到上述问题,本文提出32×32矩阵乘加阵列,在一个维度上采用互连的形式,一次性完成一个输入特征图数据与32个卷积核数据的并行计算,避免了重复读取数据;另一个维度同时完成输入特征图数据与卷积核数据在32个通道上的乘累加计算,在该维度上将采用脉动的形式传输计算数据,脉动规模为8,每个脉动单元内四个数据采用乘加树的结构进行计算,设计示意图见图7.该结构相对脉动阵列最高时序有所降低,但整体设计上考虑到了并行计算与数据复用,兼顾了性能与资源两个方面,利于在片上存储资源紧张的硬件上实现. ...
In?datacenter performance analysis of a tensor processing unit
2
2017
... 对卷积神经网络硬件加速的研究集中在优化加速运算与减少内存访问两个方面.Chen et al[5]设计的DianNao架构通过专用数据通路控制单元调配模块协作,计算单元采用乘加树结构,利用流水线实现卷积加速运算,但并行度低、数据重复利用率低.Qiu et al[6]采用图像处理中常用的滤波器结构缓存输入特征图行数据,数据复用程度高,计算单元结构易于实现乘累加,但在硬件电路中卷积窗口确定,难以适应不同尺寸卷积核的卷积神经网络.Chen et al[7]的Eyeriss为减小能耗提出Row Stationary数据流设计,通过配置计算阵列映射最大化局部数据复用来实线能效的优化,但乘加(Multiply and Accumulate,MAC)阵列映射策略复杂、阵列互连线太多,难以提高阵列规模.Wei et al[8]与Jouppi et al[9]采用脉动阵列进行乘加阵列设计,脉动阵列中的局部互连网络及相邻计算单元之间的数据传输,使得大规模脉动阵列综合后可以在高频率时钟下工作,加速性能优异,但数据预处理部分逻辑复杂、存储资源消耗偏大. ...
Energy?efficient and high?throughput FPGA?based accelerator for convolutional neural networks
1
2016
... Feng et al[10]指出卷积层的计算量占整个卷积神经网络计算量的90%以上,卷积神经网络硬件加速的核心在于对卷积层计算的加速.卷积层的输入为三维(宽×高×通道)输入特征图和四维(宽×高×输入通道×输出通道)权重卷积核,输出为三维(宽×高×通道)输出特征图,中间运算为六重循环的乘加运算.卷积层运算的C语言代码见代码1,其中填充参数P根据是否需要补零的操作判断对输入特征图是否进行填充,S表示卷积运算窗口的滑动步长.卷积运算在填充后的输入特征图上依次截取大小的特征图与同等大小的三维卷积核进行乘累加,得到输出特征图的一个数据,根据滑动步长从左到右、从上到下遍历输入特征图,得到二维输出特征图.在卷积核的第四维通道N上,重复上述运算,得到三维输出特征图.在卷积运算六重循环中,三重循环为乘累加计算,三重循环为并行计算,同时在卷积窗口滑动中,部分数据存在重复使用的情况,卷积层的计算特性为并行计算与数据复用提供了较大的设计空间. ...
Hardware Manual
1
... 在卷积运算的六层循环中,三重计算可以直接映射到并行维度上,三重乘累加计算,先分块计算后在累加器中进行累加,并行计算设计依然成立.分析常见卷积神经网络中卷积层相关参数,卷积核大小变动较大,从1×1到11×11,映射到固定的乘加阵列中并行计算,在大小变化后乘加阵列资源利用率偏低;输出特征图平面维度随着网络层变深,整体呈递减趋势,且幅度较大,例如从227×227变为6×6.目前在这两个维度上并行计算,多采用分割和拼凑特征图的方法.输入输出通道两个维度,除首层与末层外,输入输出特征图通道数多为32的倍数,合理地利用该特性能够在并行计算上取得较好的效果.本文在并行计算设计上选择输入输出通道两个维度,将其映射到二维乘加阵列上.为了配合并行计算,在FPGA内部数据存储上,参考英伟达(NVIDIA)开源项目中加速器NVDLA(NVIDIA Deep Learning Accelerator)中数据存储格式[11],参与分块计算的输入输出特征图按照(输入通道块、输入宽、输入高)格式存储,权重按照(输入通道块、输出通道块、卷积核宽、卷积核高)格式存储.设定输入并行因子为m,输出并行因子为n,在一个时钟周期内,乘加阵列计算完成次乘加运算,其示意图见图6. ...
Optimizing fpga?based accelerator design for deep convolutional neural networks





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}