南京大学学报(自然科学版) ›› 2020, Vol. 56 ›› Issue (4): 581–590.doi: 10.13232/j.cnki.jnju.2020.04.016
基于FPGA的卷积神经网络加速模块设计
梅志伟1,2,王维东1,2( )
)
- 1.浙江大学信息与电子工程学院,杭州,310013
2.浙江大学?瑞芯微多媒体系统联合实验室,浙江大学信息与电子工程学院,杭州,310013
Design of Convolutional Neural Network acceleration module based on FPGA
Zhiwei Mei1,2,Weidong Wang1,2()
- 1.College of Information Science & Electronic Engineering,Zhejiang University,Hangzhou,310013,China
2.ZJU?Rock Chips Joint Laboratory of Multimedia System,College of Information Science & Electronic Engineering,Zhejiang University,Hangzhou,310013,China
摘要:
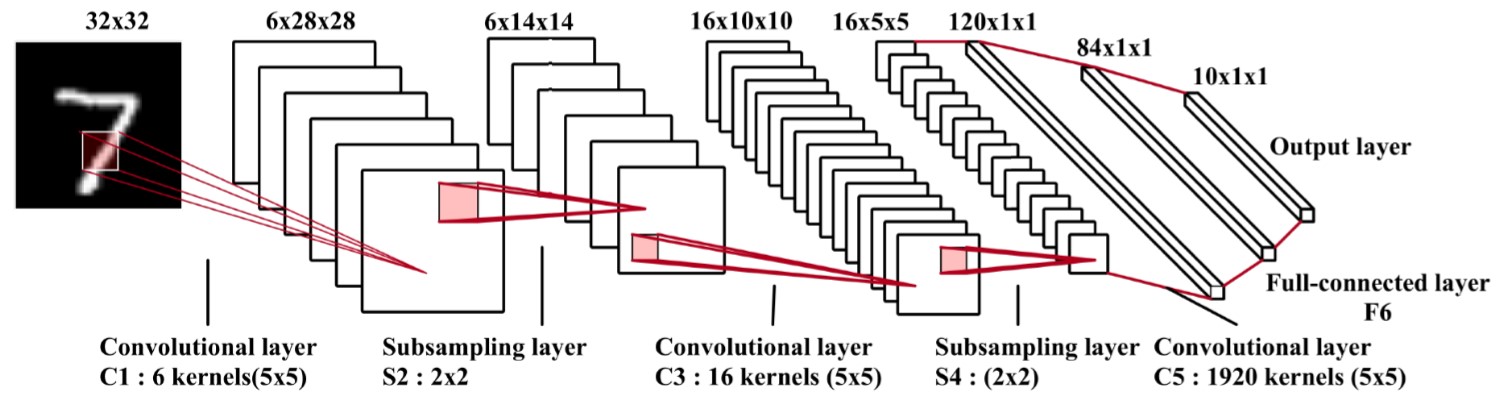
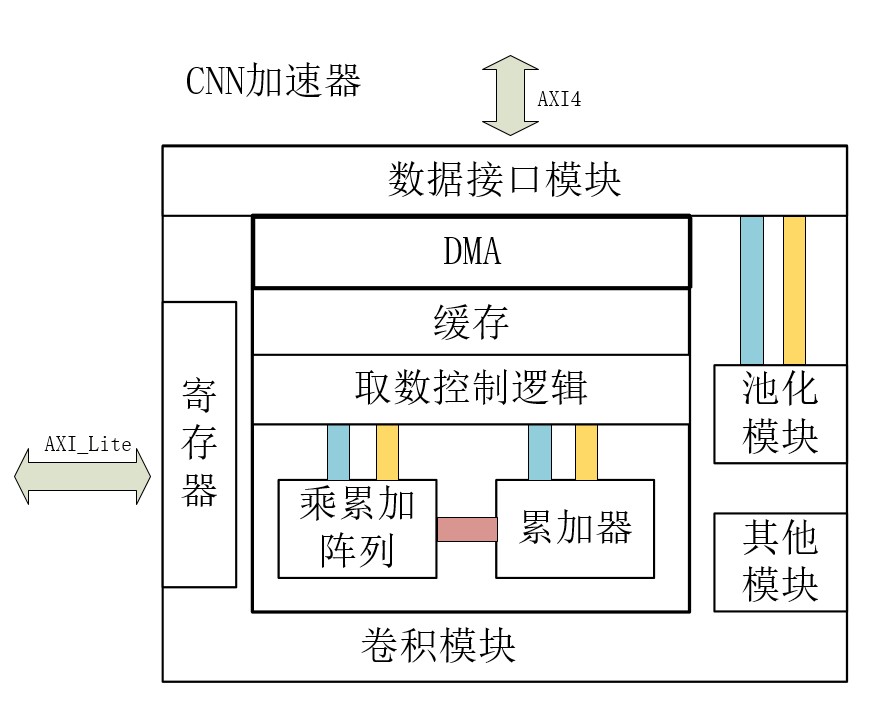
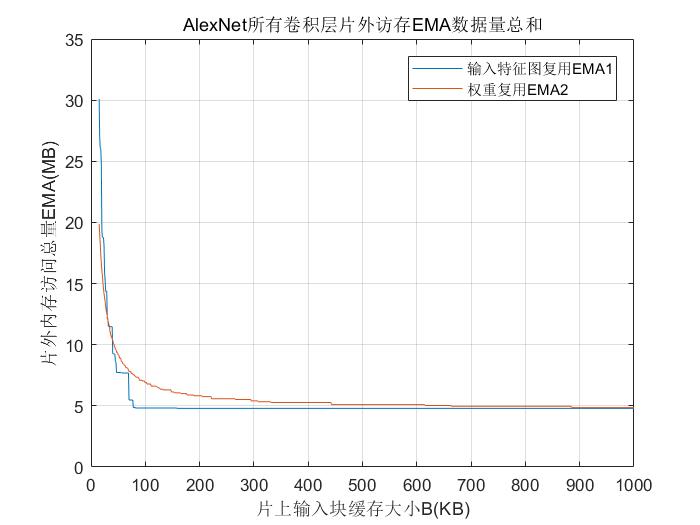
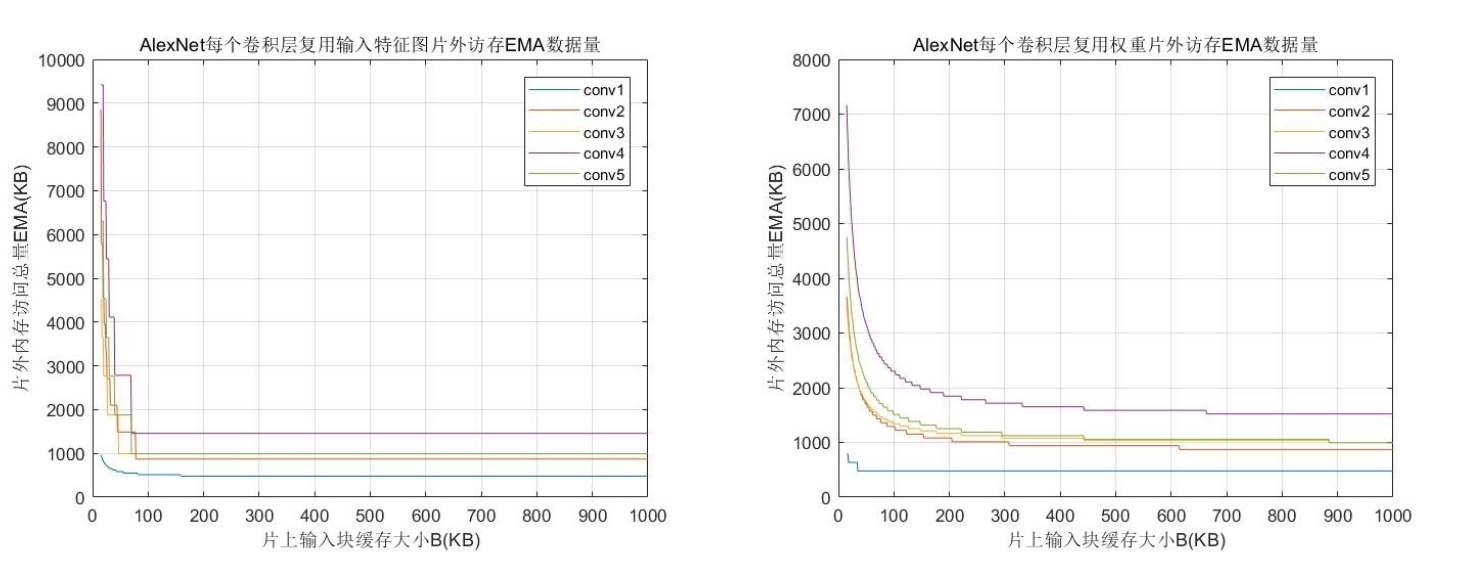
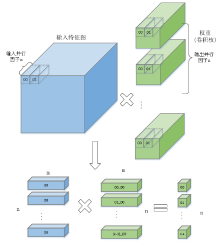
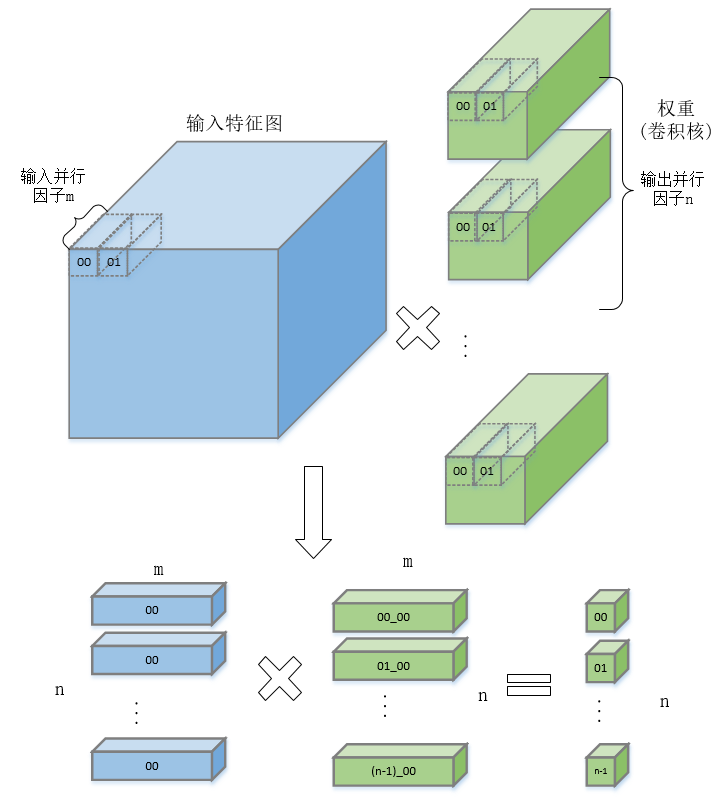
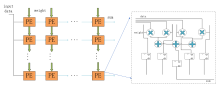
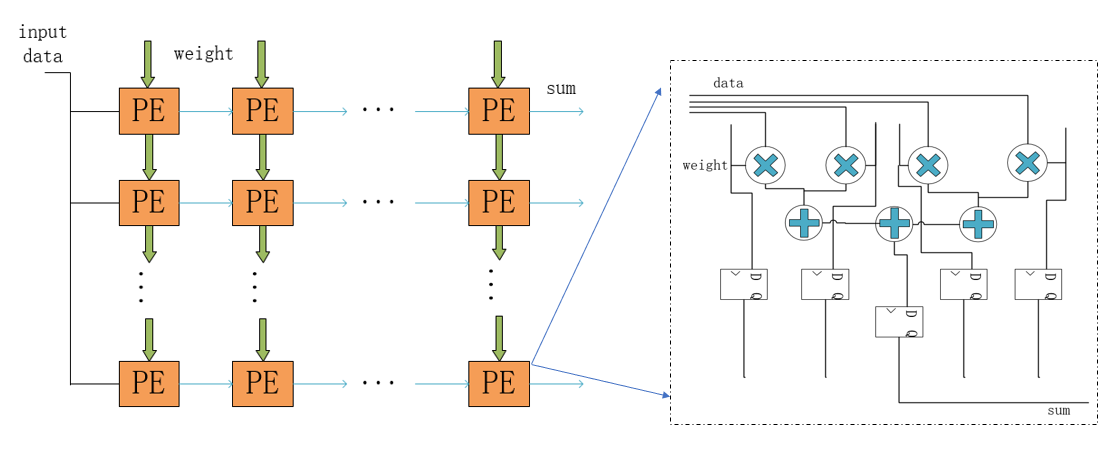
针对卷积神经网络前向推理硬件加速的研究,提出一种基于FPGA(Field Programmable Gate Array)的卷积神经网络加速模块,以期在资源受限的硬件平台中加速卷积运算.通过分析卷积神经网络基本结构与常见卷积神经网络的特性,设计了一种适用于常见卷积神经网络的硬件加速架构.在该架构中,采用分层次缓存数据与分类复用数据策略,优化卷积层片外访存总量,缓解带宽压力;在计算模块中,在输入输出通道上并行计算,设计了将乘加树与脉动阵列相结合的高效率计算阵列,兼顾了计算性能与资源消耗.实验结果表明,提出的加速模块运行VGG?16(Visual Geometry Group)卷积神经网络性能达到189.03 GOPS(Giga Operations per Second),在DSP(Digital Signal Processor)性能效率上优于大部分现有的解决方案,内存资源消耗比现有解决方案减少41%,适用于移动端卷积神经网络硬件加速.
中图分类号:
- TN4




| 1 | Girshick R,Donahue J,Darrell T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation∥2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus,OH,USA:IEEE,2014:580-587. |
| 2 | He K M,Zhang X Y,Ren S Q,et al. Delving deep into rectifiers:surpassing human?level performance on imagenet classification∥2015 IEEE International Conference on Computer Vision. Santiago,Chile:IEEE,2015:1026-1034. |
| 3 | Coates A,Huval B,Wang T,et al. Deep learning with COTS HPC systems∥International Conference on Machine Learning. Atlanta,USA:ACM,2013:1337-1345. |
| 4 | Navarro C A,Hitschfeld?Kahler N,Mateu L. A survey on parallel computing and its applications in data?parallel problems using GPU architectures. Communications in Computational Physics,2014,15(2):285-329. |
| 5 | Chen T S,Du Z D,Sun N H,et al. Diannao:a small?footprint high?throughput accelerator for ubiquitous machine?learning. ACM SIGARCH Computer Architecture News,2014,42(1):269-284. |
| 6 | Qiu J T,Wang J,Yao S,et al. Going deeper with embedded fpga platform for convolutional neural network∥The 2016 ACM/SIGDA International Symposium on Field?Programmable Gate Arrays. Monterey,CA,USA:ACM,2016:26-35. |
| 7 | Chen Y H,Krishna T,Emer J S,et al. Eyeriss:An energy?efficient reconfigurable accelerator for deep convolutional neural networks. IEEE Journal of Solid?State Circuits,2016,52(1):127-138. |
| 8 | Wei X C,Yu C H,Zhang P,et al. Automated systolic array architecture synthesis for high throughput CNN inference on FPGAs∥The 54th Annual Design Automation Conference 2017. Austin,TX,USA:ACM,2017:1-6. |
| 9 | Jouppi N P,Young C,Patil N,et al. In?datacenter performance analysis of a tensor processing unit∥2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture. Toronto,Canada:IEEE,2017:1-12. |
| 10 | Feng G,Hu Z Y,Chen S,et al. Energy?efficient and high?throughput FPGA?based accelerator for convolutional neural networks∥2016 13th IEEE International Conference on Solid?State and Integrated Circuit Technology (ICSICT). Hangzhou,China:IEEE,2016:624-626. |
| 11 | NVIDIA Corporation. Hardware Manual. http:∥nvdla.org/hw/contents.html,2018-05-12. |
| 12 | Zhang C,Li P,Sun G Y,et al. Optimizing fpga?based accelerator design for deep convolutional neural networks∥The 2015 ACM/SIGDA International Symposium on Field?Programmable Gate Arrays. Monterey,CA,USA:ACM,2015:161-170. |
| 13 | Suda N,Chandra V,Dasika G,et al. Throughput?optimized OpenCL?based FPGA accelerator for large?scale convolutional neural networks∥The 2016 ACM/SIGDA International Symposium on Field?Programmable Gate Arrays. Monterey,CA,USA:ACM,2016:16-25. |
| 14 | Guo K Y,Sui L Z,Qiu J T,et al. Angel?Eye:a complete design flow for mapping CNN onto embedded FPGA. IEEE Transactions on Computer:Aided Design of Integrated Circuits and Systems,2017,37(1):35-47. |
| 15 | Zhang C,Sun G Y,Fang Z M,et al. Caffeine:Toward uniformed representation and acceleration for deep convolutional neural networks. IEEE Transactions on Computer:Aided Design of Integrated Circuits and Systems,2018,38(11):2072-2085. |
| 16 | Shen J Z,Huang Y,Wang Z L,et al. Towards a uniform template?based architecture for accelerating 2D and 3D CNNS on FPGA∥The 2018 ACM/SIGDA International Symposium on Field?Programmable Gate Arrays. Monterey,CA,USA:ACM,2018:97-106. |
| [1] | 朱伟,张帅,辛晓燕,李文飞,王骏,张建,王炜. 结合区域检测和注意力机制的胸片自动定位与识别[J]. 南京大学学报(自然科学版), 2020, 56(4): 591-600. |
| [2] | 赵子龙,赵毅强,叶茂. 基于FPGA的多卷积神经网络任务实时切换方法[J]. 南京大学学报(自然科学版), 2020, 56(2): 167-174. |
| [3] | 王吉地,郭军军,黄于欣,高盛祥,余正涛,张亚飞. 融合依存信息和卷积神经网络的越南语新闻事件检测[J]. 南京大学学报(自然科学版), 2020, 56(1): 125-131. |
| [4] | 狄 岚, 何锐波, 梁久祯. 基于可能性聚类和卷积神经网络的道路交通标识识别算法[J]. 南京大学学报(自然科学版), 2019, 55(2): 238-250. |
| [5] | 安 晶, 艾 萍, 徐 森, 刘 聪, 夏建生, 刘大琨. 一种基于一维卷积神经网络的旋转机械智能故障诊断方法[J]. 南京大学学报(自然科学版), 2019, 55(1): 133-142. |
| [6] | 胡 太, 杨 明. 结合目标检测的小目标语义分割算法[J]. 南京大学学报(自然科学版), 2019, 55(1): 73-84. |
| [7] | 梁蒙蒙1,周 涛1,2*,夏 勇3,张飞飞1,杨 健1. 基于随机化融合和CNN的多模态肺部肿瘤图像识别[J]. 南京大学学报(自然科学版), 2018, 54(4): 775-. |
| [8] | 余双春,袁 杰,沈庆宏*. 实时视频去隔行的并行算法研究[J]. 南京大学学报(自然科学版), 2016, 52(5): 795-. |
| [9] | 沙 金*. LDPC码硬件仿真平台的FPGA实现[J]. 南京大学学报(自然科学版), 2014, 50(3): 325-. |
| [10] | 冯伟,袁杰**. 高清视频并行处理的研究*[J]. 南京大学学报(自然科学版), 2012, 48(1): 33-39. |
| [11] | 张 騄 1, 2 , 张兴敢 1,2** , 柏业超 1,2 , 张 尉 2, 3 . 便携式可在线编程雷达信号模拟器* [J]. 南京大学学报(自然科学版), 2010, 46(4): 359-365. |
|