南京大学学报(自然科学版) ›› 2020, Vol. 56 ›› Issue (4): 524–532.doi: 10.13232/j.cnki.jnju.2020.04.010
融合标签结构依赖性的标签分布学习
黄雨婷1,徐媛媛1,张恒汝1( ),闵帆1,2
),闵帆1,2
- 1.西南石油大学计算机科学学院,成都,610500
2.西南石油大学人工智能研究院,成都,610500
Label distribution learning by exploiting structural label dependency
Yuting Huang1,Yuanyuan Xu1,Hengru Zhang1(),Fan Min1,2
- 1.School of Computer Science,Southwest Petroleum University,Chengdu,610500,China
2.Institute for Artificial Intelligence,Southwest Petroleum University,Chengdu,610500,China
摘要:
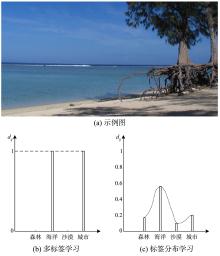
针对现有标签分布学习(Label Distribution Learning,LDL)算法较少考虑标签间关联性的问题,提出一种融合结构化标签依赖性的LDL算法.算法分为扩展、学习和恢复三个阶段:在扩展阶段,结合成对标签之间的关联性,构建结构化标签依赖性;在学习阶段,结合该依赖性,构建学习框架;在恢复阶段,利用最小二乘法求解超定方程组以预测标签分布.与七种常用的标签分布学习算法相比,在八个开放数据集上进行实验,提出的算法在Euclidean距离、S?rensen距离、Squard χ2距离、Kullback?Leibler散度、Intersection相似度和Fidelity相似度六个主流评估指标上明显占优.
中图分类号:
- TP391

| 1 | Geng X,Smith?Miles K,Zhou Z H. Facial age estimation by learning from label distributions∥Proceedings of the 24th AAAI Conference on Artificial Intelligence. Atlanta,GA,USA:AAAI,2010:451-456. |
| 2 | Geng X. Label distribution learning. IEEE Transactions on Knowledge and Data Engineering,2016,28(7):1734-1748. |
| 3 | Yang X,Gao B B,Xing C,et al. Deep label distribution learning for apparent age estimation∥Proceedings of the 2015 IEEE International Conference on Computer Vision Workshops. Santiago,Chile:IEEE,2015:102-108. |
| 4 | Geng X,Ling M G. Soft video parsing by label distribution learning∥Proceedings of the 31th AAAI Conference on Artificial Intelligence. San Francisco,CA,USA:AAAI Press,2017:1331-1337. |
| 5 | Geng X,Wang Q,Xia Y. Facial age estimation by adaptive label distribution learning∥Proceedings of the 22nd International Conference on Pattern Recognition. Stockholm,Sweden:IEEE,2014:4465-4470. |
| 6 | Geng X,Yin C,Zhou Z H. Facial age estimation by learning from label distributions. IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(10):2401-2412. |
| 7 | Zhang M L,Zhang K. Multi?label learning by exploiting label dependency∥Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Washington DC,USA:ACM,2010:999-1008. |
| 8 | Wei B,Kwok J T Y. Multilabel classification with label correlations and missing labels∥Proceedings of the 28th AAAI Conference on Artificial Intelligence. Québec City,Canada,2014:1680-1686. |
| 9 | Huang S J,Zhou Z H. Multi∥label learning by exploiting label correlations locally∥Proceedings of the 26th AAAI Conference on Artificial Intelligence. Toronto,Canada:AAAI,2012:949-955. |
| 10 | Zhou D Y,Zhang X,Zhou Y,et al. Emotion distribution learning from texts∥Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin,TX,USA:Associa?tion for Computational Linguistics,2016:638-647. |
| 11 | Zhang Z X,Wang M,Geng X. Crowd counting in public video surveillance by label distribution learning. Neurocomputing,2015,166:151-163. |
| 12 | Jégou H,Douze M,Schmid C. Hamming embedding and weak geometric consistency for large scale image search∥Proceedings of the 10th European Conference on Computer Vision. Springer Berlin Heidelberg,2008:304-317. |
| 13 | Kullback S,Leibler R A. On information and sufficiency. Annals of Mathematical Statistics,1951,22(1):79-86. |
| 14 | Zheng X,Jia X Y,Li W W. Label distribution learning by exploiting sample correlations locally∥Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans,LA,USA:AAAI,2018:4556-4563. |
| 15 | Berger A L,Pietra V J D,Pietra S A D. A maximum entropy approach to natural language processing. Computational Linguistics,1996,22(1):39-71. |
| 16 | Wang J,Geng X. Classification with label distribution learning∥Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macao,China:International Joint Conferences on Artificial Intelligence Organization,2019:3712-3718. |
| 17 | Jia X Y,Li W W,Liu J Y,et al. Label distribution learning by exploiting label correlations∥Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans,LA,USA:AAAI,2018:3310-3317. |
| 18 | Xu C D,Geng X. Hierarchical classification based on label distribution learning∥Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu,HI,USA:AAAI,2019:5533-5540. |
| 19 | Ren T T,Jia X Y,Li W W,et al. Label distribution learning with label correlations via low?rank approximation∥Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macao,China:International Joint Conferences on Artificial Intelligence Organization,2019:3325-3331. |
| 20 | Ren T T,Jia X Y,Li W W,et al. Label distribution learning with label?specific features∥Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macao,China:International Joint Conferences on Artificial Intelligence Organization,2019:3318-3324. |
| 21 | Mencía E L,Park S H,Fürnkranz J. Efficient voting prediction for pairwise multilabel classification. Neurocomputing,2010,73(7-9):1164-1176. |
| 22 | Yuan Y X. A modified BFGS algorithm for unconstrained optimization. IMA Journal of Numerical Analysis,1991,11(3):325-332. |
| 23 | Eisen M B,Spellman P T,Brown P O,et al. Cluster analysis and display of genome?wide expression patterns. The National Academy of Sciences of the United States of America,1998,95(25):14863-14868. |
| 24 | Danielsson P E. Euclidean distance mapping. Computer Graphics and Image Processing,1980,14(3):227-248. |
| 25 | S?renson T. A method of establishing groups of equal amplitudes in plant sociology based on similarity of species content and its application to analyses of the vegetation on Danish commons. Kongelige Danske Videnskabernes Selskab,Biologiske Skrifter,1948,5(4):1-34. |
| 26 | Gavin D G,Oswald W W,Wahl E R,et al. A statistical approach to evaluating distance metrics and analog assignments for pollen records. Quaternary Research,2003,60(3):356-367. |
| 27 | Duda R O,Hart P E,Stork D G. Pattern classification. The 2nd Edition. New York:Wiley?Interscience,2000,654. |
| 28 | Cha S H. Comprehensive survey on distance/similarity measures between probability density functions. International Journal of Mathematical Models and Methods in Applied Sciences,2007,1(4):300-307. |
| 附 录 | |
| 本文使用L?BFGS方法对目标函数T(θ)进行求解,对应当前迭代次的特征-标签矩阵的二阶泰勒展开为: |
| [1] | 朱伟,张帅,辛晓燕,李文飞,王骏,张建,王炜. 结合区域检测和注意力机制的胸片自动定位与识别[J]. 南京大学学报(自然科学版), 2020, 56(4): 591-600. |
| [2] | 李昭阳,龚安民,伏云发. 基于EEG脑网络下肢动作视觉想象识别研究[J]. 南京大学学报(自然科学版), 2020, 56(4): 570-580. |
| [3] | 郑建兴,李沁文,王素格,李德玉. 基于翻译模型的异质重边信息网络链路预测研究[J]. 南京大学学报(自然科学版), 2020, 56(4): 541-548. |
| [4] | 任睿,张超,庞继芳. 有限理性下多粒度q⁃RO模糊粗糙集的最优粒度选择及其在并购对象选择中的应用[J]. 南京大学学报(自然科学版), 2020, 56(4): 452-460. |
| [5] | 陈俊芬,赵佳成,韩洁,翟俊海. 基于深度特征表示的Softmax聚类算法[J]. 南京大学学报(自然科学版), 2020, 56(4): 533-540. |
| [6] | 王宝丽,姚一豫. 信息表中约简补集对及其一般定义[J]. 南京大学学报(自然科学版), 2020, 56(4): 461-468. |
| [7] | 陈石,张兴敢. 基于小波包能量熵和随机森林的级联H桥多电平逆变器故障诊断[J]. 南京大学学报(自然科学版), 2020, 56(2): 284-289. |
| [8] | 周昊,沈庆宏. 基于改进音形码的中文敏感词检测算法[J]. 南京大学学报(自然科学版), 2020, 56(2): 270-277. |
| [9] | 罗春春,郝晓燕. 基于双重注意力模型的微博情感倾向性分析[J]. 南京大学学报(自然科学版), 2020, 56(2): 236-243. |
| [10] | 王露,王士同. 改进模糊聚类在医疗卫生数据的Takagi⁃Sugeno模糊模型[J]. 南京大学学报(自然科学版), 2020, 56(2): 186-196. |
| [11] | 陈睿, 伏云发. 基于EEG握力变化及想象单次识别研究[J]. 南京大学学报(自然科学版), 2020, 56(2): 159-166. |
| [12] | 杨红鑫,杨绪兵,张福全,业巧林. 半监督平面聚类算法设计[J]. 南京大学学报(自然科学版), 2020, 56(1): 9-18. |
| [13] | 刘胜久,李天瑞,珠杰,刘佳. 带权图的多重分形研究[J]. 南京大学学报(自然科学版), 2020, 56(1): 85-97. |
| [14] | 张银芳,于洪,王国胤,谢永芳. 一种用于数据流自适应分类的主动学习方法[J]. 南京大学学报(自然科学版), 2020, 56(1): 67-73. |
| [15] | 陈超逸,林耀进,唐莉,王晨曦. 基于邻域交互增益信息的多标记流特征选择算法[J]. 南京大学学报(自然科学版), 2020, 56(1): 30-40. |
|