Finding the causal relationship between variables from observed data is a key issue in many scientific research fields. Because the traditional Granger causality model is affected by the curse of dimension,it is difficult to accurately find causality in high⁃dimensional time series. In this paper,we propose a new Granger causality analysis method based on quantile factor model,QFM⁃CGC algorithm,which is used to find causality relationship in high⁃dimensional time series. Firstly,QFM⁃CGC uses Akaike information criterion to select models,which avoids setting the lag order by human intervention. Then,the quantile factor model is established to reduce the dimensionality of the conditional variables in a vector autoregressive (VAR) model,thus reducing the number of coefficients that need to be estimated. The reduced⁃dimensional VAR model is used for a conditional Granger causality analysis. Finally,Monte Carlo simulation is applied to evaluate the performance of different methods to identify the connectivity structure between the underlying system and the observation time series. Experiments compare the proposed method with benchmark and classical methods on a linear simulation system with variables in different dimensions and two sets of real data,confirming its effectiveness.
Keywords:high⁃dimensional time series
;
quantile factor model
;
conditional Granger causality analysis
;
data mining
Liang Huiling, Liu Hui, Liu Liwei, Zhao Jia, Ruan Huaijun. Causal relationship analysis of high⁃dimensional time series based on quantile factor model. Journal of nanjing University[J], 2023, 59(4): 550-560 doi:10.13232/j.cnki.jnju.2023.04.002
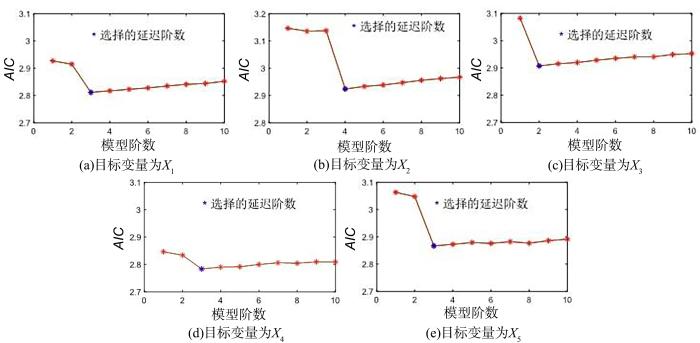
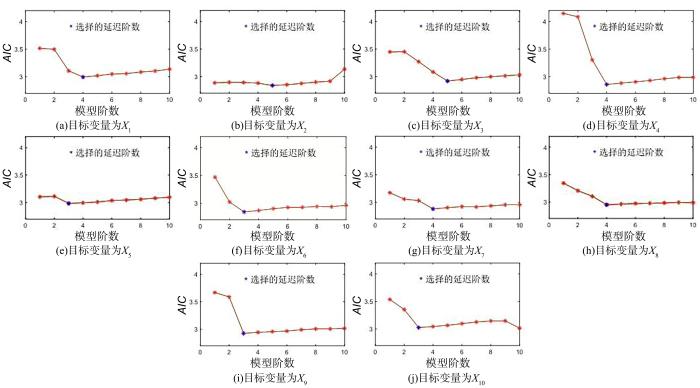
VAR模型中,如果解释变量的最大滞后阶数太小,残差可能存在自相关,导致参数估计不一致.虽然适当增加滞后阶数可以解决此问题,但过大会使待估计参数增多,严重降低自由度,最终影响模型参数估计的有效性[19],所以VAR模型中解释变量的最大滞后阶数的选择很重要.本文采用AIC (Akaike Information Criterion)[20]来自动选择合适的模型阶数,以消除人为选择的不确定性的干扰,如式(8)所示:
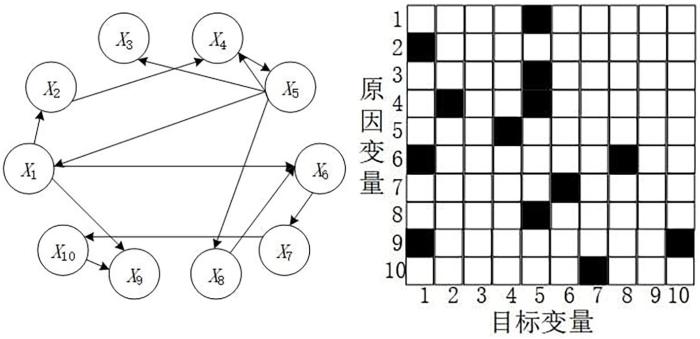
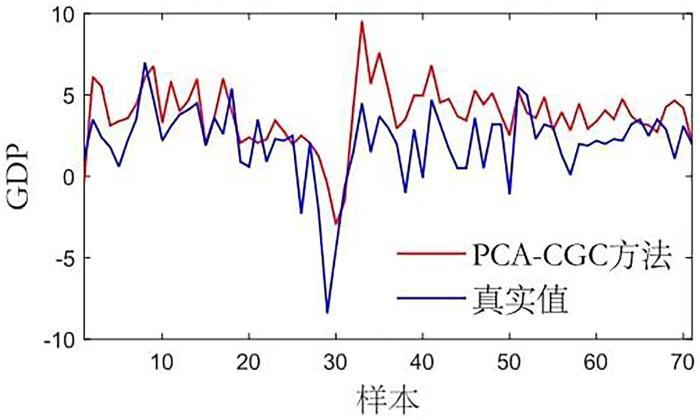
在仿真模拟研究中,比较QFM⁃CGC,经典方法CGC[8]和基准方法PCA⁃CGC[21],mBTS⁃CGC[22],PMIME[23]的性能.Geweke[8]向VAR模型中引入条件变量,提出条件Granger因果模型,改善了传统方法无法判断直接因果关系和间接因果关系的缺陷.Zhou et al[21]提出PCA⁃CGC方法,将PCA与条件Granger因果模型相结合来处理高维大脑神经网络的计算,与传统方法相比,降低了计算成本.Siggiridou and Kugiumtzis[22]采用backward⁃in⁃time方法对每个变量的滞后阶数使用有监督的逐步向前选择,有效减少VAR模型阶数,并与条件Granger因果模型结合,提出mBTS⁃CGC方法.Kugiumtzis[23]将度量混合嵌入的条件互信息(Conditional Mutual Information from Mixed Embedding,MIME)拓展到多变量时间序列,形成可以检测直接耦合的部分MIME (Partial MIME,PMIME).PMIME在由非均匀嵌入方案导出的滞后变量X,Y和Z的联合状态空间的子空间中重构一个点(向量),目的是最好地解释Y的演化,得到的混合嵌入向量只包含所有变量中最相关的成分,避免大维度会恶化估计的情况.
与Chen et al[13]相同,设置估计量的最大因子数.使用秩最小化估计器[13]估计分位数为时的因子估计数如表3所示.由表可见,QFA因子的数量在不同分位数之间存在显著差异,表明该数据集存在非标准因子结构.为了比较QFA因子和PCA因子,将QFA因子的每个元素与选择的八个PCA因子进行回归并计算这些回归中的R2,结果如表4[13]所示.很明显,当接近0.5时,QFA因子与PCA因子高相关,R2均在0.9以上.相比之下,时的第一个QFA因子(表示为)和,0.99时的第一个QFA因子(分别表示为和)与PCA因子的相关性较低,R2低于0.4.因此,,和包含可能有助于预测宏观经济变量的额外信息,在此应用程序中有使用QFA的空间.由表4可得,由于,和的R2分别为0.316,0.261和0.266,与其他QFA因子相比,与和有非常高的相关性,它们具有类似的捕获额外信息的能力,这些信息能够帮助预测宏观经济变量.因此,在后续分析中重点关注和的预测能力.
Table 3
表3
表3不同分位数下的因子估计数
Table 3 Estimation of factors at different quantiles
使用Chen et al[13]的秩最小化估计器在分位数为时进行因子估计,不同分位数条件下的因子估计数同为1.此外,将QFA因子的每个元素与选择的八个PCA因子进行回归并计算这些回归中的R2,分位数在时的R2分别为0.794,0.786,0.999,0.999,0.999,0.984,0.945,0.961.时的QFA因子(表示为)和时的QFA因子(表示为)与PCA因子的相关性较低,R2低于0.8.因此,和包含可能有助于预测宏观经济变量的额外信息,在此应用程序中有使用QFA的空间.
... 在仿真模拟研究中,比较QFM⁃CGC,经典方法CGC[8]和基准方法PCA⁃CGC[21],mBTS⁃CGC[22],PMIME[23]的性能.Geweke[8]向VAR模型中引入条件变量,提出条件Granger因果模型,改善了传统方法无法判断直接因果关系和间接因果关系的缺陷.Zhou et al[21]提出PCA⁃CGC方法,将PCA与条件Granger因果模型相结合来处理高维大脑神经网络的计算,与传统方法相比,降低了计算成本.Siggiridou and Kugiumtzis[22]采用backward⁃in⁃time方法对每个变量的滞后阶数使用有监督的逐步向前选择,有效减少VAR模型阶数,并与条件Granger因果模型结合,提出mBTS⁃CGC方法.Kugiumtzis[23]将度量混合嵌入的条件互信息(Conditional Mutual Information from Mixed Embedding,MIME)拓展到多变量时间序列,形成可以检测直接耦合的部分MIME (Partial MIME,PMIME).PMIME在由非均匀嵌入方案导出的滞后变量X,Y和Z的联合状态空间的子空间中重构一个点(向量),目的是最好地解释Y的演化,得到的混合嵌入向量只包含所有变量中最相关的成分,避免大维度会恶化估计的情况. ...
... [8]向VAR模型中引入条件变量,提出条件Granger因果模型,改善了传统方法无法判断直接因果关系和间接因果关系的缺陷.Zhou et al[21]提出PCA⁃CGC方法,将PCA与条件Granger因果模型相结合来处理高维大脑神经网络的计算,与传统方法相比,降低了计算成本.Siggiridou and Kugiumtzis[22]采用backward⁃in⁃time方法对每个变量的滞后阶数使用有监督的逐步向前选择,有效减少VAR模型阶数,并与条件Granger因果模型结合,提出mBTS⁃CGC方法.Kugiumtzis[23]将度量混合嵌入的条件互信息(Conditional Mutual Information from Mixed Embedding,MIME)拓展到多变量时间序列,形成可以检测直接耦合的部分MIME (Partial MIME,PMIME).PMIME在由非均匀嵌入方案导出的滞后变量X,Y和Z的联合状态空间的子空间中重构一个点(向量),目的是最好地解释Y的演化,得到的混合嵌入向量只包含所有变量中最相关的成分,避免大维度会恶化估计的情况. ...
... Chen et al[13]给出了当样本矩阵Y的维度趋于无穷时因子模型估计量的渐近性质,提出迭代分位数回归(Iterative Quantile Regression,IQR)算法,可以有效地找到目标函数的平稳点.令: ...
... 通过Chen et al[13]提出的基于秩最小化的方法来确定不可观测因子的数量. ...
... 与Chen et al[13]相同,设置估计量的最大因子数.使用秩最小化估计器[13]估计分位数为时的因子估计数如表3所示.由表可见,QFA因子的数量在不同分位数之间存在显著差异,表明该数据集存在非标准因子结构.为了比较QFA因子和PCA因子,将QFA因子的每个元素与选择的八个PCA因子进行回归并计算这些回归中的R2,结果如表4[13]所示.很明显,当接近0.5时,QFA因子与PCA因子高相关,R2均在0.9以上.相比之下,时的第一个QFA因子(表示为)和,0.99时的第一个QFA因子(分别表示为和)与PCA因子的相关性较低,R2低于0.4.因此,,和包含可能有助于预测宏观经济变量的额外信息,在此应用程序中有使用QFA的空间.由表4可得,由于,和的R2分别为0.316,0.261和0.266,与其他QFA因子相比,与和有非常高的相关性,它们具有类似的捕获额外信息的能力,这些信息能够帮助预测宏观经济变量.因此,在后续分析中重点关注和的预测能力. ...
... 使用Chen et al[13]的秩最小化估计器在分位数为时进行因子估计,不同分位数条件下的因子估计数同为1.此外,将QFA因子的每个元素与选择的八个PCA因子进行回归并计算这些回归中的R2,分位数在时的R2分别为0.794,0.786,0.999,0.999,0.999,0.984,0.945,0.961.时的QFA因子(表示为)和时的QFA因子(表示为)与PCA因子的相关性较低,R2低于0.8.因此,和包含可能有助于预测宏观经济变量的额外信息,在此应用程序中有使用QFA的空间. ...
1
1997
... 主成分分析(Principal Component Analysis,PCA)是目前最主要的降维方法之一[11],它将原始的高维数据投影到一个较低维的子空间上,使原始高维数据可以由一组低维变量表示[12].但是,PCA在降维时没有捕获隐藏的因子,值得注意的是相关因子可能会改变时间序列的分布特征(矩或分位数),而不是其均值.Chen et al[13]提出分位数因子模型(Quantile Factor Models,QFM)及其估计程序,简称分位数因子分析(Quantile Factor Analysis,QFA).与其他因子模型不同,QFM还捕获移动可观测分布的其他相关部分的未观测因子.QFM的一个重要优点是它能同时提取决定QFM因素结构的所有均值和额外(非均值)因子,而PCA只能提取平均因子,所以QFA克服了PCA没有捕捉隐藏因子的能力的问题.为此,Chen et al[13]通过蒙特卡洛模拟[14]说明存在异常值时,使用QFA有明显优势[13]. ...
High?dimensional Ising model selection with Bayesian information criteria
1
2015
... VAR模型中,如果解释变量的最大滞后阶数太小,残差可能存在自相关,导致参数估计不一致.虽然适当增加滞后阶数可以解决此问题,但过大会使待估计参数增多,严重降低自由度,最终影响模型参数估计的有效性[19],所以VAR模型中解释变量的最大滞后阶数的选择很重要.本文采用AIC (Akaike Information Criterion)[20]来自动选择合适的模型阶数,以消除人为选择的不确定性的干扰,如式(8)所示: ...
A new look at the statistical model identification
1
1974
... VAR模型中,如果解释变量的最大滞后阶数太小,残差可能存在自相关,导致参数估计不一致.虽然适当增加滞后阶数可以解决此问题,但过大会使待估计参数增多,严重降低自由度,最终影响模型参数估计的有效性[19],所以VAR模型中解释变量的最大滞后阶数的选择很重要.本文采用AIC (Akaike Information Criterion)[20]来自动选择合适的模型阶数,以消除人为选择的不确定性的干扰,如式(8)所示: ...
Analyzing brain networks with PCA and conditional Granger causality
2
2009
... 在仿真模拟研究中,比较QFM⁃CGC,经典方法CGC[8]和基准方法PCA⁃CGC[21],mBTS⁃CGC[22],PMIME[23]的性能.Geweke[8]向VAR模型中引入条件变量,提出条件Granger因果模型,改善了传统方法无法判断直接因果关系和间接因果关系的缺陷.Zhou et al[21]提出PCA⁃CGC方法,将PCA与条件Granger因果模型相结合来处理高维大脑神经网络的计算,与传统方法相比,降低了计算成本.Siggiridou and Kugiumtzis[22]采用backward⁃in⁃time方法对每个变量的滞后阶数使用有监督的逐步向前选择,有效减少VAR模型阶数,并与条件Granger因果模型结合,提出mBTS⁃CGC方法.Kugiumtzis[23]将度量混合嵌入的条件互信息(Conditional Mutual Information from Mixed Embedding,MIME)拓展到多变量时间序列,形成可以检测直接耦合的部分MIME (Partial MIME,PMIME).PMIME在由非均匀嵌入方案导出的滞后变量X,Y和Z的联合状态空间的子空间中重构一个点(向量),目的是最好地解释Y的演化,得到的混合嵌入向量只包含所有变量中最相关的成分,避免大维度会恶化估计的情况. ...
... [21]提出PCA⁃CGC方法,将PCA与条件Granger因果模型相结合来处理高维大脑神经网络的计算,与传统方法相比,降低了计算成本.Siggiridou and Kugiumtzis[22]采用backward⁃in⁃time方法对每个变量的滞后阶数使用有监督的逐步向前选择,有效减少VAR模型阶数,并与条件Granger因果模型结合,提出mBTS⁃CGC方法.Kugiumtzis[23]将度量混合嵌入的条件互信息(Conditional Mutual Information from Mixed Embedding,MIME)拓展到多变量时间序列,形成可以检测直接耦合的部分MIME (Partial MIME,PMIME).PMIME在由非均匀嵌入方案导出的滞后变量X,Y和Z的联合状态空间的子空间中重构一个点(向量),目的是最好地解释Y的演化,得到的混合嵌入向量只包含所有变量中最相关的成分,避免大维度会恶化估计的情况. ...
Granger causality in multivariate time series using a time?ordered restricted vector autoregressive model
2
2016
... 在仿真模拟研究中,比较QFM⁃CGC,经典方法CGC[8]和基准方法PCA⁃CGC[21],mBTS⁃CGC[22],PMIME[23]的性能.Geweke[8]向VAR模型中引入条件变量,提出条件Granger因果模型,改善了传统方法无法判断直接因果关系和间接因果关系的缺陷.Zhou et al[21]提出PCA⁃CGC方法,将PCA与条件Granger因果模型相结合来处理高维大脑神经网络的计算,与传统方法相比,降低了计算成本.Siggiridou and Kugiumtzis[22]采用backward⁃in⁃time方法对每个变量的滞后阶数使用有监督的逐步向前选择,有效减少VAR模型阶数,并与条件Granger因果模型结合,提出mBTS⁃CGC方法.Kugiumtzis[23]将度量混合嵌入的条件互信息(Conditional Mutual Information from Mixed Embedding,MIME)拓展到多变量时间序列,形成可以检测直接耦合的部分MIME (Partial MIME,PMIME).PMIME在由非均匀嵌入方案导出的滞后变量X,Y和Z的联合状态空间的子空间中重构一个点(向量),目的是最好地解释Y的演化,得到的混合嵌入向量只包含所有变量中最相关的成分,避免大维度会恶化估计的情况. ...
... [22]采用backward⁃in⁃time方法对每个变量的滞后阶数使用有监督的逐步向前选择,有效减少VAR模型阶数,并与条件Granger因果模型结合,提出mBTS⁃CGC方法.Kugiumtzis[23]将度量混合嵌入的条件互信息(Conditional Mutual Information from Mixed Embedding,MIME)拓展到多变量时间序列,形成可以检测直接耦合的部分MIME (Partial MIME,PMIME).PMIME在由非均匀嵌入方案导出的滞后变量X,Y和Z的联合状态空间的子空间中重构一个点(向量),目的是最好地解释Y的演化,得到的混合嵌入向量只包含所有变量中最相关的成分,避免大维度会恶化估计的情况. ...
Direct?coupling information measure from nonuniform embedding
2
2013
... 在仿真模拟研究中,比较QFM⁃CGC,经典方法CGC[8]和基准方法PCA⁃CGC[21],mBTS⁃CGC[22],PMIME[23]的性能.Geweke[8]向VAR模型中引入条件变量,提出条件Granger因果模型,改善了传统方法无法判断直接因果关系和间接因果关系的缺陷.Zhou et al[21]提出PCA⁃CGC方法,将PCA与条件Granger因果模型相结合来处理高维大脑神经网络的计算,与传统方法相比,降低了计算成本.Siggiridou and Kugiumtzis[22]采用backward⁃in⁃time方法对每个变量的滞后阶数使用有监督的逐步向前选择,有效减少VAR模型阶数,并与条件Granger因果模型结合,提出mBTS⁃CGC方法.Kugiumtzis[23]将度量混合嵌入的条件互信息(Conditional Mutual Information from Mixed Embedding,MIME)拓展到多变量时间序列,形成可以检测直接耦合的部分MIME (Partial MIME,PMIME).PMIME在由非均匀嵌入方案导出的滞后变量X,Y和Z的联合状态空间的子空间中重构一个点(向量),目的是最好地解释Y的演化,得到的混合嵌入向量只包含所有变量中最相关的成分,避免大维度会恶化估计的情况. ...
... [23]将度量混合嵌入的条件互信息(Conditional Mutual Information from Mixed Embedding,MIME)拓展到多变量时间序列,形成可以检测直接耦合的部分MIME (Partial MIME,PMIME).PMIME在由非均匀嵌入方案导出的滞后变量X,Y和Z的联合状态空间的子空间中重构一个点(向量),目的是最好地解释Y的演化,得到的混合嵌入向量只包含所有变量中最相关的成分,避免大维度会恶化估计的情况. ...
Performance of different synchronization measures in real data:A case study on electroencephalographic signals







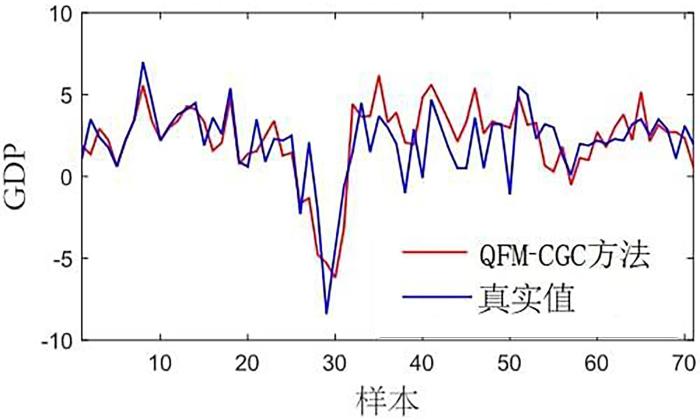
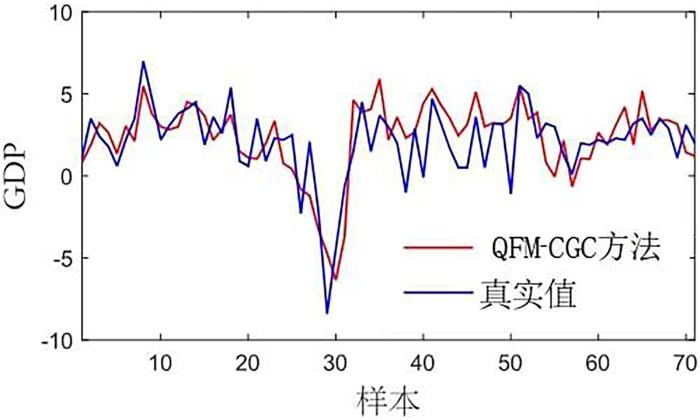

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}