Abstact: Breast ultrasound is widely used in the diagnosis of breast tumors. Deep learning⁃based tumor benign⁃malignant classification models effectively assist doctors in diagnosis,improving efficiency and reducing misdiagnosis rates,among other benefits. However,the high cost of annotated data limits the development and application of such models. In this study,we construct an unlabeled pretraining dataset from breast ultrasound videos,which includes 11805 target samples and dynamically generated positive and negative sample datasets (with sample sizes of 188880 and 1310355,respectively). Based on this dataset,we build a triplet network and conduct self⁃supervised contrastive learning. Additionally,we develope Hard Negative Mining and Hard Positive Mining methods to select challenging positive and negative samples for constructing the contrastive loss function,accelerating model convergence. After parameter transfer,the triplet network is fine⁃tuned and tested on the SYU dataset. Experimental results demonstrate that the triplet network model developed in this study exhibits stronger generalization capability and better classification performance compared to several state⁃of⁃the⁃art models pretrained on ImageNet and previous multi⁃view contrastive models for breast ultrasound. Furthermore,we test the minimum requirement of annotated data for the model and find that using only 96 annotated data points achieves a performance with an A U C = 0.901
作为最常用的成像模态之一,超声(Ultrasound,US)是临床上不可或缺的扫查与诊断工具,具有无损伤、无放射性、低成本等优点.在当前的临床实践中,医学超声在各个专业科室得到了应用,如心电图、乳腺超声、腹部超声、经直肠超声、心血管超声以及产前诊断超声,尤其广泛应用于妇产科[1 ] .一次高质量的超声成像诊断,不仅要求超声图像包含的噪声和伪影少,还要求机器操作者和诊断医生具有丰富的临床经验.近年来,为了减轻医生负担,获得更客观、更准确和更高时效性的诊断,人们致力于开发先进的自动化超声图像识别方法作为医生的辅助工具.
深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战.
为了解决上述问题,本文采用自监督对比学习[14 -15 ] 和迁移学习[16 -17 ] 两种技术,将训练分为预训练和微调阶段.和监督学习相比,自监督学习具有无须标注训练样本的优势,能保证大量训练数据的低成本获取,结合大容量的深度学习模型可以发挥巨大的潜力.本文在预训练阶段利用自监督对比学习,从一个无标签的乳腺超声视频数据集中学习通用性知识,再将其迁移到下游的乳腺病变良恶性分类任务中.首先,构建一个无标签乳腺超声视频数据集,包含来自200位病人的1360个乳腺超声扫描视频,视频长度为8~10 s,从中选出11805例目标样本图片,并对每个目标样本动态生成相应的正样本和负样本.将上述样本用于对比学习训练一个三胞胎网络.在预训练阶段,提出多近邻采样及平均化方法来扩充正样本数量,并基于Hard Negative Mining和Hard Positive Mining构建对比损失函数Hard Triplet Loss以挑选困难正负样本,加快模型收敛.预训练完成后,把网络参数迁移到下游的乳腺肿瘤分类任务中,针对一个小的人工标注数据集进行微调.最后报告模型分类性能,并和基于ImageNet的迁移学习模型和其他SOTA (State⁃of⁃The⁃Art)模型进行了比较.
1 自监督对比学习网络模型
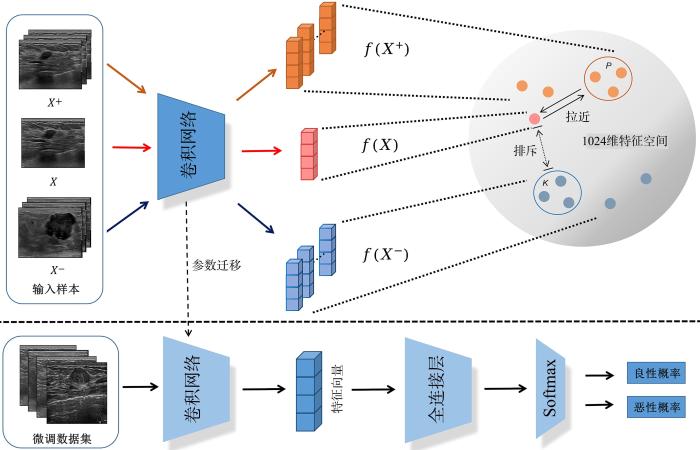
本文提出的模型包括两个部分,如图1 所示.虚线上部是一个三胞胎网络(Triplet Network),负责利用视频相邻帧进行预训练.预训练过程中,通过优化卷积网络,使相似样本对应的特征在特征空间具有较近的距离,不相似样本的距离较远.虚线下部是一分类网络,其卷积网络部分与三胞胎网络共享参数,负责对预训练后的模型进行微调.
图1
图1
三胞胎模型的预训练(上半部分)与微调(下半部分)
Fig.1
The pretraining (upper part) and finetuning (lower part) of Triplet Network
1.1 自监督对比学习模型及迁移学习
1.1.1 三胞胎网络Triplet Network
采用三胞胎网络(Triplet Network),其输入分别是目标样本X 、 正样 本 X + X - X 正样 本 X + X X - f X + , f X f X - . 如图1 所示,这些特征向量对应1024维特征空间中的特征点.
三胞胎网络本质上是三个共享参数的深度卷积网络.其中,深度卷积网络采用密集型网络DenseNet[18 ] ,包括一个7 × 7 3 × 3
1.1.2 损失函数
优化预训练的基本思想为在特征空间中减小目标样本点与正样本点的距离,加大目标样本点与负样本点的距离.基于此优化目标,本文采用两种损失函数并进行了比较.一种是目前常用的InfoNCE Loss,另一种是本文新发展的Hard Triplet Loss.
I n f o N C E L o s s [19 -20 ] ,由解决二分类问题NCE Loss(Noise Contrastive Estimation)损失函数演变而来[21 ] .I n f o N C E L o s s [19 ] :
I n f o N C E L o s s = - l g ∑ i = 1 P e x p C o s i n e f X ⋅ f X i + / τ ∑ j = 1 P + K e x p C o s i n e f X ⋅ f X j / τ (1)
其中,τ C o s i n e ∙ P ,K 分别是正、负样本的总数;分子表示目标样本和所有正样本特征向量相似度的总和,分母表示目标样本和所有正负样本相似度的总和.目标样本和正样本的相似度越大,和负样本的相似度越小,InfoNCE Loss就越小,表明预训练越好.
T r i p l e t L o s s = m a x 0 , D f X , f X + - D f X , f X - + M (2)
其中,M 是自定义优化阈值,M ≥ 0 ; D ∙ M 值与正负样本之间特征距离大小.当D f X , f X - - D f X , f X + ≥ M M ,T r i p l e t L o s s = 0 D f X , f X - - D f X , f X + < M M ,T r i p l e t L o s s > 0
D f X , f X + = 1 - f X , f X + ∥ f X ∥ ∥ f X + ∥ (3)
D f X , f X - = 1 - f X , f X - ∥ f X ∥ ∥ f X - ∥ (4)
对于对比学习,每次训练选取的正负样本越多,模型的泛化性就越强[19 ,22 ] ,但一次性把大量图像输入三胞胎网络,对所有图像计算对比损失,进行梯度下降、更新参数,对机器的存储和计算要求很高,模型的收敛速度会非常慢.因此,本文在式(2)的基础上发展了Hard Negative Mining和Hard Positive Mining.
如图1 所示,每个样本经过深度网络被映射到1024维特征空间上后,困难的正负样本被挑选出来参与训练.具体地,选择距离目标样本最远的P 个正样本以及距离最近的K 个负样本进行训练,构建新的对比损失函数Hard Triplet Loss:
H a r d T r i p l e t L o s s = ∑ i = 1 K m a x 0 , D f X , M e a n + - D f X , f X i - + M K + λ 2 ∥ W ∥ 2 2 (5)
其中,W 是预训练模型权重,λ L 2 正则化系数;M e a n + = ∑ j = 1 P f X j + P
计算每个困难负样本与M e a n + M = 0.5 , P = K = 3 , λ = 0.0005 e t a _ m i n
1.2 参数迁移后微调
将预训练得到的深度学习网络迁移到下游的乳腺超声肿瘤良恶性分类任务中.网络的微调过程具体为:固定前面网络层参数不变,优化后面部分层参数,并为模型添加一个新的全连接层和Softmax层,最后输出判断为良性、恶性的概率.
2 数据集及训练方法
2.1 预训练数据集与SYU数据集
进行微调和测试的数据集包括一个预训练数据集和一个来自中山大学附属第三医院(中大三院)的SYU数据集.其中,预训练数据集包含目标样本数据集、正样本数据集和负样本数据集.具体如表1 所示.
2.1.1 目标样本数据集
如表1 所示,目标样本数据集从200个病人的1360个乳腺超声视频中构建.目标样本数据集构建步骤如下.
( 1 ) [23 ] 来判断截取的图像有无肿瘤.
( 2 ) ( 2 )
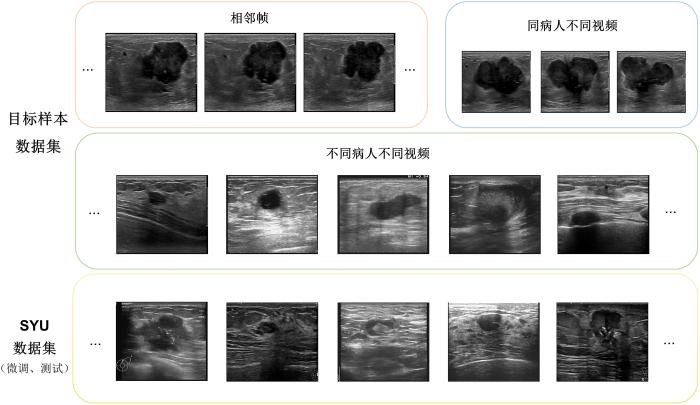
( 3 ) 224 像素 × 224 像素 . 图2 展示了目标样本数据集中同一视频相邻的三张图像、来自相同病人不同视频的三张图像以及来自不同病人不同视频的五张图像.
图2
图2
目标样本数据集和SYU数据集的部分乳腺超声图像
Fig.2
Examples of breast ultrasound images from target sample dataset and SYU dataset
2.1.2 正负样本数据集
如表1 所示,正负样本数据集根据目标样本数据集动态生成.具体步骤为:以目标样本为锚点,从相邻帧选取正样本,从不同病人不同视频随机选取负样本.不考虑从相同病人的其他视频选取负样本,原因是相同病人不同视频拍摄的肿瘤相同,拍摄角度和肿瘤呈现的形态虽然不同,但特征信息相似.
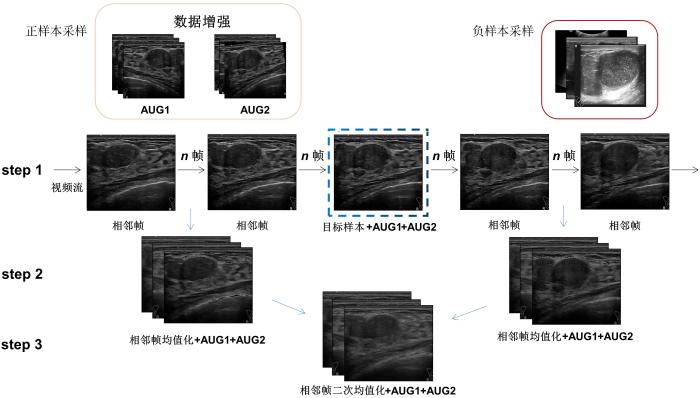
数据增强是一种常见的数据扩增技术,可以对现有数据应用一组变换来生成新样本,如平移、旋转、变形、缩放、颜色空间变换、裁剪等等,目标是生成更多样本以创建更大的数据集.一般地,在对比学习中,大量正样本可通过数据增强生成,但乳腺超声图像对数据增强操作十分敏感,除了小角度旋转和左右翻转操作,其他数据增强的手段均会破坏肿瘤关键的特征信息.为了提高正样本的数量,保证正样本的采样质量,本文提出多近邻采样及平均化方法,具体如图3 所示.
图3
图3
正负样本的采样过程
Fig.3
Positives and negatives sampling
(1)以目标样本为锚点,找到左右相邻n 帧、2n 帧等间隔的图像,对目标样本和相邻帧进行小角度旋转和左右翻转操作,即图3 中的AUG1和AUG2,相邻帧与AUG1,AUG2组成第一批次正样本.
(2)对第一批次中的相邻帧做均值化处理.均值化处理能进一步突出肿瘤的关键特征,也能去除残留的噪声.这些相邻帧均值化图像加上其数据扩增图像组成第二批次正样本,如图3 中相邻帧均值化+AUG1+AUG2所示.
(3)对第二批次均值化图像进行二次均值化,并进行数据扩增,得到第三批次正样本,如图3 中相邻帧二次均值化+AUG1+AUG2所示.
由此得到的正样本一共是16个,如表1 所示,1个目标样本、16个正样本和111个随机采样的负样本组成一个批次进行训练,规定一个批次的样本数是2的指数,如64,128等.预训练过程中正负样本采样总量分别是188880和1310355个.间隔单位n = 5
2.1.3 SYU数据集
如表1 所示,SYU数据集来自中大三院[23 -24 ] ,包括400张乳腺超声图像,其中175张良性,225张恶性,经预处理后统一尺寸为224 像素 × 224 像素 . 按照五折交叉验证方法把SYU数据集随机分成两个独立的微调数据集和测试数据集,微调数据集含乳腺超声图像320张,测试数据集含乳腺超声图像80张.图2 展示了SYU数据集的部分乳腺超声图像.
2.1.4 ImageNet数据集
ImageNet是一个用于计算机视觉识别研究的大型可视化数据集,由斯坦福大学李飞飞教授带领创建[25 ] ,包含14197122张图像和21841个Synset索引,常用作评估图像分类算法性能的基准.基于ImageNet数据集,目前已有一大批有监督的预训练模型,如ResNet,DenseNet,GoogleNet等,这些模型提高了图像分类[26 -27 ] 、目标检测[28 -29 ] 、图像分割[30 ] 、图像描述[31 -32 ] 等多种任务的性能.
2.2 数据预处理
采用模糊增强和双边滤波两种数据预处理方法来降低噪声,增强信噪比.其中,模糊增强利用大津法(OTSU)[33 ] 生成二值化图像,增强肿瘤边缘特征;双边滤波采用加权平均去掉原图尖锐噪声,保留肿瘤的边界.但这两种数据增强均会丢失或削弱肿瘤的有用信息,因此原始图像也予以保留.将原始图像和两种数据增强的图像在通道维度上堆叠在一起,组成三通道图片输入模型.
2.3 模型的训练及评估
训练了四个分别以DenseNet121,DenseNet161,DenseNet169和DenseNet201[18 ] 为骨架的三胞胎网络.在预训练阶段,输入图像的尺寸统一为224像素×224像素,数值归一化到0~1;网络采用带动量的随机梯度下降作为权值更新算法,初始学习率均为1 × 10 - 3 eta _min限制为0.0005.预训练一共包含200个epoch,每个epoch依次从11805张图像中选出目标样本,通过多近邻采样及平均化方法得到每个目标样本对应的正样本数据集,从不同病人视频中随机挑选负样本集,把目标样本、正负样本数据集组成一个训练批次,输入三胞胎网络中完成一次迭代训练.实验规定一个epoch对预训练数据集里所有图像完成一次迭代训练.预训练结束后,保留对比损失最小的模型参数,把最优参数迁移到下游乳腺肿瘤良恶性分类任务中,在三胞胎网络后面加入新的全连接层和Softmax输出分类结果.微调时冻结网络前面层的参数,解冻Dense Block3和Dense Block4的部分参数[18 ] ,在SYU数据集上进行五折交叉验证.
采用机器学习领域常用的评估指标:受试者操作特征曲线下面积(Area Under Curve,AUC )、灵敏度(Sensitivity)和特异度(Specificity).灵敏度和特异度的计算如下:
S e n s i t i v i t y = T P T P + F N (6)
S p e c i f i c i t y = T N T N + F P (7)
其中,TP 表示将阳性样本预测为阳性,TN 表示将阴性样本预测为阴性,FN 表示将阳性样本预测为阴性,FP 表示将阴性样本预测为阳性.
3 结果与讨论
3.1 两种损失函数结果对比
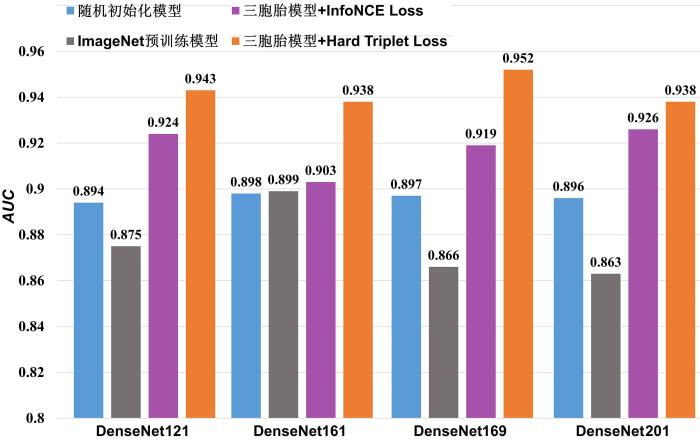
对比预训练损失函数分别为InfoNCE Loss和Hard Triplet Loss的三胞胎网络在下游分类任务的分类结果.使用AUC 作为模型分类结果的评估指标,在SYU测试集肿瘤良恶性分类任务上进行计算.AUC 越高,算法的分类性能越好.如图4 所示,无论以哪个卷积网络为框架,以Hard Triplet Loss作为预训练损失函数,其分类结果都比InfoNCE Loss更好.
图4
图4
四种预训练模型在四种DenseNet框架下的AUC 对比
Fig.4
AUC of four pre⁃trained models with four DenseNet as backbones
具体的评价结果如表2 所示,表中黑体字表示性能最优.由表可得,与损失函数为InfoNCE L o s s AUC 提升2 % ~ 4 % 2 % ~ 6 % . 可见本文构建的Hard Triplet Loss在视频相邻帧对比学习任务上的表现比InfoNCE Loss更出色.
3.2 三胞胎网络、ImageNet预训练模型和随机初始化模型的对比
为了评估三胞胎网络的预训练性能,对比了三种模型.模型1,基于三胞胎网络和视频流进行预训练,利用表1 所示的微调数据集进行微调,再用得到的结果在测试集进行测试,计算各种指标.模型2,基于四种DenseNet框架的ImageNet预训练模型,微调和测试同模型1.模型3,使用随机初始化模型,微调和测试同模型1.
使用AUC 作为模型分类性能的评估指标,在SYU测试集肿瘤良恶性分类任务上进行计算,AUC 越高,算法的分类性能越好.需要强调的是,实验挑选的是四种没有经过特殊方法训练的ImageNet预训练模型.对比结果亦如图4 所示.由图可见,和ImageNet预训练模型及随机初始化模型相比,三胞胎模型的分类性能更好,尤其是以Hard Triplet Loss为对比损失函数的三胞胎模型,分类性能大幅领先.ImageNet预训练模型分类的性能甚至比随机初始化模型还要差,在DenseNet161框架上,ImageNet预训练模型的AUC 仅比随机初始化模型高0.1 %
具体的评估结果亦如表2 所示,表中黑体字表示性能最优.
首先,损失函数为Hard Triplet Loss的三胞胎网络的AUC 比ImageNet预训练模型提高4 % ~ 9 % 9 % ~ 10 % AUC 平均下降2.1 % 4.1 % 表2 还可以看到,损失函数为Hard Triplet Loss的三胞胎网络在SYU数据集上有优异的分类性能.以Hard Triplet Loss为损失函数的四种卷积网络三胞胎模型,AUC 均大于0.93,灵敏度和特异度均超过0.87,尤其在DenseNet⁃169卷积网络上,AUC 达0.952,灵敏度和特异度均达0.89.需要强调的是,预训练数据集和SYU数据集是两个独立的数据集,在跨数据集迁移后,三胞胎网络分类的性能表现仍然很突出,证明本文模型的泛化性能强,分类性能优异.
3.3 与其他基于ImageNet的SOTA预训练模型的对比
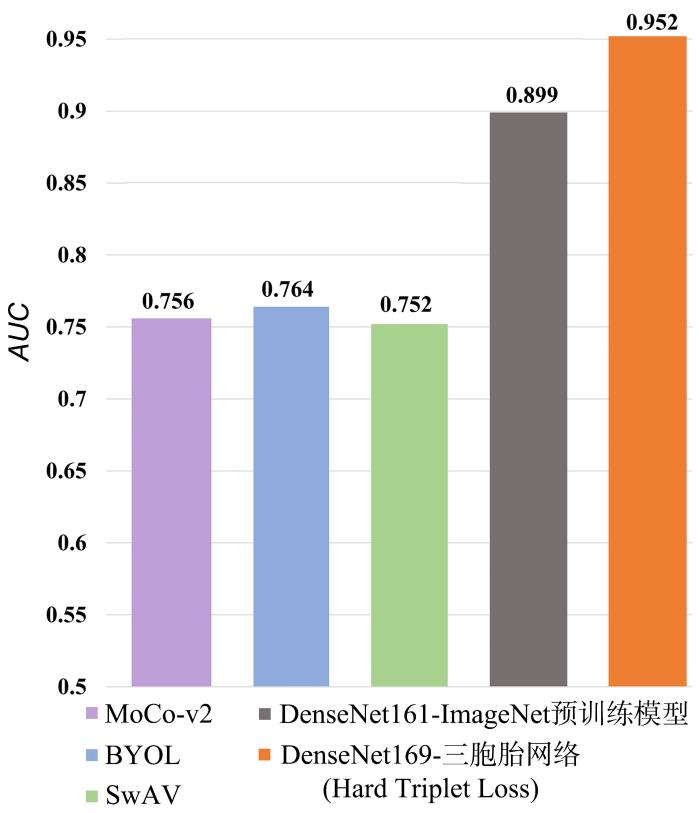
为了进一步证明三胞胎网络的分类性能,挑选最先进的三种ImageNet预训练模型[34 ] ,分别是MoCo⁃v2,BYOL和SwAV来进行对比实验,它们采用的是和本文不同的骨架网络.把这些预训练好的模型迁移到SYU数据集上进行微调和测试,并和前文DenseNet161⁃ImageNet预训练模型和DenseNet169⁃三胞胎网络(使用Hard Triplet Loss)进行对比.实验结果如图5 所示,余下两种指标详见表3 ,表中黑体字表示性能最优.可见DenseNet169⁃三胞胎网络(Hard Triplet Loss)的三种指标均领先于所有ImageNet预训练模型,DenseNet161⁃ImageNet预训练模型仅次于三胞胎网络.MoCo⁃v2,BYOL和SwAV的表现基本一致,AUC 在0.752~0.764,灵敏度和特异度均在0.665~0.676.原因可能是MoCo⁃v2,BYOL和SwAV三种模型虽然能较好地学习自然图像域的分布,但其自然图像与医学图像内秉的分布不同,所以模型不能很好地跨数据集泛化.
图5
图5
三胞胎网络和其他SOTA预训练模型的AUC 对比
Fig.5
AUC of our Triplet Network and other SOTA models
3.4 小数据集训练
本文的主要思想是使用视频流数据对模型进行预训练,从而降低对标注数据量的要求,以解决标注数据缺乏和模型过拟合等问题.为此,需测试模型对小样本需求的下限.
从SYU数据集中随机划分出四个独立小数据集,对每个小数据集进行五折交叉验证.四个小数据集的样本数分别是:80(64个样本用于训练,16个样本用于测试,简记为64/16),120(96/24),175(140/35)和190(152/38).
在基于对比学习方法对乳腺超声肿瘤的自动识别和分类任务上,之前的一个SOTA工作提出了一个多任务框架,利用单个病变的多个视图之间的关系开展对比学习[35 ] .我们重现了这一模型,本文命名为Multi⁃task LR(Lesion Recognition),并采用和我们的模型一样的预训练和微调数据集进行训练和测试.
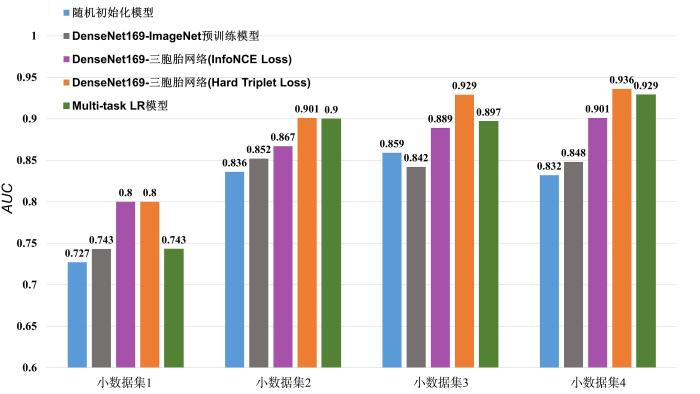
图6 给出了五种模型在四个小数据集上的分类性能,包括以DenseNet169为骨架的两种损失函数的三胞胎模型、基于DenseNet169的Image⁃Net预训练模型、随机初始化模型和Multi⁃task LR.由图可见,在最小的数据集1中,三胞胎网络的AUC 比DenseNet169⁃ImageNet预训练模型高6 % AUC 超过0.9,在小数据集3和4上,AUC 分别是0.929和0.936.DenseNet169⁃ImageNet预训练模型和随机初始化模型的AUC 均低于0.86.
图6
图6
两种损失函数的DenseNet169⁃三胞胎网络、Multi⁃task LR模型、DenseNet169⁃ImageNet预训练模型和随机初始化模型在四个小数据集上AUC 的对比
Fig.6
AUC of Triplet Network based on DenseNet169 with two loss functions,Multi-task LR model,DenseNet169⁃ImageNet pre⁃trained model and stochastic initialization model on four small datasets
临床上,灵敏度在辅助诊断系统中占有重要地位.如表4 所示,损失函数为Hard Triplet Loss的DenseNet169⁃三胞胎模型在小数据集2上的灵敏度是0.835,在小数据集3和4上均超过0.86,而DenseNet169⁃ImageNet预训练模型的灵敏度均低于0.77.
从图6 和表4 可见,本文提出的模型在所有数据集上的各个评价指标都高于Multi⁃task LR模型,说明本文提出的模型框架更优.
综上,对于损失函数为Hard Triplet Loss的DenseNet169⁃三胞胎模型,仅需96个标注数据进行微调,就能使模型的分类性能达到一个较好的结果(AUC 为0.901,敏感度为0.835),极大降低了基于监督学习的方法对标注数据的依赖,在医疗影像人工智能辅助诊断领域有重要的价值.
4 结论
基于深度学习的医学影像辅助诊断系统在相关领域发挥着越来越大的作用,降低其对标注数据的依赖有很大的学术价值和应用价值.本文从乳腺超声视频流出发,根据病人、视频相邻帧等信息,构建包含目标样本和正负样本的非标注数据集,并通过自监督对比学习对一个三胞胎网络进行预训练,然后把模型迁移到下游小样本乳腺肿瘤良恶性分类任务中,以解决医疗数据中标注数据缺乏的问题.本文还提出多近邻采样及平均化方法扩充正样本数量,并利用Hard Negative Mining和Hard Positive Mining方法挑选困难正负样本以构建损失函数,加快模型收敛、提高预测精度.
从实验结果可见,经过预训练的三胞胎网络在SYU数据集上的AUC 最高可达0.952,和基于DenseNet框架的ImageNet预训练模型相比,平均高6.7 % 19.47 %
本文模型还可在以下方面继续优化,包括优化网络架构以提高训练速度,进行多中心合作以扩充数据集,融合多个模态如X射线、磁共振等数据.另外,肿瘤分类任务可与其他如异常检测、分割和定位等相关任务联合进行多任务学习,通过共享特征表示来提高模型的性能和泛化能力.还可以和传统的基于影像组学的方法融合,输入不同类型和分级的肿瘤形状、纹理等特征来加快收敛和提高泛化能力.为了将研究成果转化为实际临床应用,还需对不同来源的数据集进行微调和测试,增强其泛化能力和鲁棒性,并最终在真实的医疗环境中进行验证.最后,增强模型的可解释性,也是临床应用上需要关注的方面.
综上,本文基于深度学习和自监督对比学习技术,从乳腺超声视频流出发,搭建数据集、预训练了一个三胞胎网络模型,并应用于下游肿瘤分类任务.测试结果优于同类SOTA模型,并在只有少量标签数据的情况下,可达到良好的分类性能,有较好的临床应用前景.
参考文献
View Option
[1]
Noble J A Boukerroui D Ultrasound image segmentation:A survey
IEEE Transactions on Medical Imaging ,2006 ,25 (8 ):987 -1010 .
[本文引用: 1]
[2]
Melendez J Sánchez C I Philipsen R H H M et al An automated tuberculosis screening strategy combining X⁃ray⁃based computer⁃aided detection and clinical information
Scientific Reports ,2016 ,6 :25265 .
[本文引用: 1]
[3]
Lakhani P Sundaram B Deep learning at chest radiography:Automated classification of pulmonary tuberculosis by using convolutional neural networks
Radiology ,2017 ,284 (2 ):574 -582 .
[本文引用: 1]
[4]
Setio A A A Ciompi F Litjens G et al Pulmonary nodule detection in CT images:False positive reduction using multi⁃view convolutional networks
IEEE Transactions on Medical Imaging ,2016 ,35 (5 ):1160 -1169 .
[本文引用: 1]
[5]
Pesce E Withey S J Ypsilantis P P et al Learning to detect chest radiographs containing pulmonary lesions using visual attention networks
Medical Image Analysis ,2019 ,53 :26 -38 .
[本文引用: 1]
[6]
Evain E Raynaud C Ciofolo⁃Veit C et al Breast nodule classification with two⁃dimensional ultrasound using Mask⁃RCNN ensemble aggregation
Diagnostic and Interventional Imaging ,2021 ,102 (11 ):653 -658 .
[本文引用: 1]
[7]
Gao Y H Liu B Zhu Y et al Detection and recognition of ultrasound breast nodules based on semi⁃supervised deep learning:A powerful alternative strategy
Quantitative Imaging in Medicine and Surgery ,2021 ,11 (6 ):2265 -2278 .
[本文引用: 1]
[8]
Lei Y He X X Yao J C et al Breast tumor segmentation in 3D automatic breast ultrasound using Mask scoring R⁃CNN
Medical Physics ,2021 ,48 (1 ):204 -214 .
[本文引用: 1]
[9]
Cui W J Peng Y S Yuan G et al FMRNet:A fused network of multiple tumoral regions for breast tumor classification with ultrasound images
Medical Physics ,2022 ,49 (1 ):144 -157 .
[本文引用: 1]
[10]
Dosovitskiy A Beyer L Kolesnikov A et al An image is worth 16×16 words:Transformers for image recognition at scale
∥The 9th International Conference on Learning Representations . Online,2021 .
[本文引用: 1]
[11]
Al-Dhabyani W Gomaa M Khaled H et al Dataset of breast ultrasound images
Data in Brief ,2020 ,28 :104863 .
[本文引用: 1]
[12]
Yap M H Pons G Martí J et al Automated breast ultrasound lesions detection using convolutional neural networks
IEEE Journal of Biomedical and Health Informatics ,2018 ,22 (4 ):1218 -1226 .
[本文引用: 1]
[13]
Zhang Y T Xian M Cheng H D et al BUSIS:A benchmark for breast ultrasound image segmentation
Healthcare ,2022 ,10 (4 ):729 .
[本文引用: 1]
[14]
Jaiswal A Babu A R Zadeh M Z et al A survey on contrastive self⁃supervised learning
Technologies ,2020 ,9 (1 ):2 .
[本文引用: 1]
[15]
Han X Zhang Z Y Ding N et al Pre⁃trained models:Past,present and future
AI Open ,2021 ,2 :225 -250 .
[本文引用: 1]
[16]
Thrun S Pratt L Learning to learn:Introduction and overview
∥Thrun S,Pratt L. Learning to learn . Springer Berlin Heidelberg,1998 :3 -17 .
[本文引用: 1]
[17]
Pan S J Yang Q A survey on transfer learning
IEEE Transactions on Knowledge and Data Engineering ,2010 ,22 (10 ):1345 -1359 .
[本文引用: 1]
[18]
Huang G Liu Z Van Der Maaten L et al Densely connected convolutional networks
∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu,HI,USA :IEEE ,2017 :2261 -2269 .
[本文引用: 3]
[19]
He K M Fan H Q Wu Y X et al Momentum contrast for unsupervised visual representation learning
∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle,WA,USA :IEEE ,2020 :9726 -9735 .
[本文引用: 3]
[20]
van den Oord A Li Y Z Vinyals O Representation learning with contrastive predictive coding
2018 ,arXiv:.
[本文引用: 1]
[21]
Dyer C Notes on noise contrastive estimation and negative sampling
2014 ,arXiv:.
[本文引用: 1]
[22]
Chen T Kornblith S Norouzi M et al A simple framework for contrastive learning of visual representations
∥The 37th International Conference on Machine Learning . Online :PMLR ,2020 :1597 -1607 .
[本文引用: 1]
[23]
Zhang S Liao M Wang J et al Fully automatic tumor segmentation of breast ultrasound images with deep learning
Journal of Applied Clinical Medical Physics ,2023 ,24 (1 ):E13863 .
[本文引用: 2]
[24]
Zhang S Tang T Y Peng X et al Automatic localization and identification of thoracic diseases from chest X⁃rays with deep learning
Current Medical Imaging ,2022 ,18 (13 ):1416 -1425 .
[本文引用: 1]
[25]
Fei-Fei L Deng J Li K ImageNet:Constructing a large⁃scale image database
Journal of Vision ,2009 ,9 (8 ):1037 .
[本文引用: 1]
[26]
He K M Zhang X Y Ren S Q et al Deep residual learning for image recognition
∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas,NV,USA :IEEE ,2016 :770 -778 .
[本文引用: 1]
[27]
Lee C Y Xie S N Gallagher P et al Deeply⁃supervised nets
∥Proceedings of the 8th International Conference on Artificial Intelligence and Statistics . San Diego,CA,USA :JMLR.org ,2015 :562 -570 .
[本文引用: 1]
[28]
Ren S Q He K M Girshick R et al Faster R⁃CNN:Towards real⁃time object detection with region proposal networks
IEEE Transactions on Pattern Analysis and Machine Intelligence ,2017 ,39 (6 ):1137 -1149 .
[本文引用: 1]
[29]
Gidaris S Komodakis N Object detection via a multi⁃region and semantic segmentation⁃aware CNN model
∥Proceedings of the IEEE International Conference on Computer Vision . Santiago,Chile :IEEE ,2015 :1134 -1142 .
[本文引用: 1]
[30]
Long J Shelhamer E Darrell T Fully convolutional networks for semantic segmentation
∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston,MA,USA :IEEE ,2015 :3431 -3440 .
[本文引用: 1]
[31]
Vinyals O Toshev A Bengio S et al Show and tell:A neural image caption generator
∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston,MA,USA :IEEE ,2015 :3156 -3164 .
[本文引用: 1]
[32]
Johnson J Karpathy A Fei⁃Fei L DenseCap:Fully convolutional localization networks for dense captioning
∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas,NV,USA :IEEE ,2016 :4565 -4574 .
[本文引用: 1]
[33]
Otsu N A threshold selection method from gray⁃level histograms
IEEE Transactions on Systems,Man,and Cybernetics ,1979 ,9 (1 ):62 -66 .
[本文引用: 1]
[34]
Anton J Castelli L Chan M F et al How well do self⁃supervised models transfer to medical imaging?
Journal of Imaging ,2022 ,8 (12 ):320 .
[本文引用: 1]
[35]
Guo Y F Yang C Q Lin T C et al Self supervised lesion recognition for breast ultrasound diagnosis
∥2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI) . Kolkata,India :IEEE ,2022 :1 -4 .
[本文引用: 1]
Ultrasound image segmentation:A survey
1
2006
... 作为最常用的成像模态之一,超声(Ultrasound,US)是临床上不可或缺的扫查与诊断工具,具有无损伤、无放射性、低成本等优点.在当前的临床实践中,医学超声在各个专业科室得到了应用,如心电图、乳腺超声、腹部超声、经直肠超声、心血管超声以及产前诊断超声,尤其广泛应用于妇产科[1 ] .一次高质量的超声成像诊断,不仅要求超声图像包含的噪声和伪影少,还要求机器操作者和诊断医生具有丰富的临床经验.近年来,为了减轻医生负担,获得更客观、更准确和更高时效性的诊断,人们致力于开发先进的自动化超声图像识别方法作为医生的辅助工具. ...
An automated tuberculosis screening strategy combining X?ray?based computer?aided detection and clinical information
1
2016
... 深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战. ...
Deep learning at chest radiography:Automated classification of pulmonary tuberculosis by using convolutional neural networks
1
2017
... 深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战. ...
Pulmonary nodule detection in CT images:False positive reduction using multi?view convolutional networks
1
2016
... 深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战. ...
Learning to detect chest radiographs containing pulmonary lesions using visual attention networks
1
2019
... 深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战. ...
Breast nodule classification with two?dimensional ultrasound using Mask?RCNN ensemble aggregation
1
2021
... 深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战. ...
Detection and recognition of ultrasound breast nodules based on semi?supervised deep learning:A powerful alternative strategy
1
2021
... 深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战. ...
Breast tumor segmentation in 3D automatic breast ultrasound using Mask scoring R?CNN
1
2021
... 深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战. ...
FMRNet:A fused network of multiple tumoral regions for breast tumor classification with ultrasound images
1
2022
... 深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战. ...
An image is worth 16×16 words:Transformers for image recognition at scale
1
2021
... 深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战. ...
Dataset of breast ultrasound images
1
2020
... 深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战. ...
Automated breast ultrasound lesions detection using convolutional neural networks
1
2018
... 深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战. ...
BUSIS:A benchmark for breast ultrasound image segmentation
1
2022
... 深度学习(Deep Learning,DL)是机器学习的一个分支,是一种表征学习方法,能直接从原始数据自动学习不同层次的抽象特征,被广泛应用于计算机自动图像识别领域,如分割、分类、目标检测等等,也包含医疗影像的自动化识别.医疗影像包括CT (Computed Tomography)影片、医学超声图像、核医学成像、核磁共振成像等,针对特定疾病的诊断算法层出不穷,常见的有肺结核[2 -3 ] 、肺结节[4 -5 ] 、乳腺结节[6 -7 ] 和乳腺癌[8 -9 ] 等.目前在图像自动识别领域中常用的深度学习网络有两种,一种是深度卷积神经网络(Convolutional Neural Networks,CNN),另一种是新兴代表ViT(Vision Transformer)[10 ] ,但这些深度网络的参数量都非常大,一般以百万(Mega,M)或十亿(Giga,G)为单位,这要求用于训练网络的数据量要足够大,否则深度学习网络会出现过拟合现象,影响模型性能.然而,目前在乳腺超声领域上,公开的有标签数据集只有BUSI,DatasetB和BUSIS.其中,BUSI数据集[11 ] 由Al⁃Dhabyani团队从600个病人中采集,包含133张无肿瘤图像、437张恶性肿瘤图像和210张良性肿瘤图像,图像平均像素为500× 500 ;DatasetB数据集[12 ] 来自西班牙萨巴德尔Parc Tauli公司的UDIAT诊断中心,一共有163张图像,其中良性110张,恶性53张;BUSIS数据集[13 ] 由哈尔滨医科大学附属第二医院、青岛大学附属医院和河北医科大学第二医院使用多种超声设备采集,从26~78岁女性中采集到562张乳腺超声图像.乳腺超声数据集的严重稀缺,给乳腺肿瘤自动识别任务带来巨大的挑战. ...
A survey on contrastive self?supervised learning
1
2020
... 为了解决上述问题,本文采用自监督对比学习[14 -15 ] 和迁移学习[16 -17 ] 两种技术,将训练分为预训练和微调阶段.和监督学习相比,自监督学习具有无须标注训练样本的优势,能保证大量训练数据的低成本获取,结合大容量的深度学习模型可以发挥巨大的潜力.本文在预训练阶段利用自监督对比学习,从一个无标签的乳腺超声视频数据集中学习通用性知识,再将其迁移到下游的乳腺病变良恶性分类任务中.首先,构建一个无标签乳腺超声视频数据集,包含来自200位病人的1360个乳腺超声扫描视频,视频长度为8~10 s,从中选出11805例目标样本图片,并对每个目标样本动态生成相应的正样本和负样本.将上述样本用于对比学习训练一个三胞胎网络.在预训练阶段,提出多近邻采样及平均化方法来扩充正样本数量,并基于Hard Negative Mining和Hard Positive Mining构建对比损失函数Hard Triplet Loss以挑选困难正负样本,加快模型收敛.预训练完成后,把网络参数迁移到下游的乳腺肿瘤分类任务中,针对一个小的人工标注数据集进行微调.最后报告模型分类性能,并和基于ImageNet的迁移学习模型和其他SOTA (State⁃of⁃The⁃Art)模型进行了比较. ...
Pre?trained models:Past,present and future
1
2021
... 为了解决上述问题,本文采用自监督对比学习[14 -15 ] 和迁移学习[16 -17 ] 两种技术,将训练分为预训练和微调阶段.和监督学习相比,自监督学习具有无须标注训练样本的优势,能保证大量训练数据的低成本获取,结合大容量的深度学习模型可以发挥巨大的潜力.本文在预训练阶段利用自监督对比学习,从一个无标签的乳腺超声视频数据集中学习通用性知识,再将其迁移到下游的乳腺病变良恶性分类任务中.首先,构建一个无标签乳腺超声视频数据集,包含来自200位病人的1360个乳腺超声扫描视频,视频长度为8~10 s,从中选出11805例目标样本图片,并对每个目标样本动态生成相应的正样本和负样本.将上述样本用于对比学习训练一个三胞胎网络.在预训练阶段,提出多近邻采样及平均化方法来扩充正样本数量,并基于Hard Negative Mining和Hard Positive Mining构建对比损失函数Hard Triplet Loss以挑选困难正负样本,加快模型收敛.预训练完成后,把网络参数迁移到下游的乳腺肿瘤分类任务中,针对一个小的人工标注数据集进行微调.最后报告模型分类性能,并和基于ImageNet的迁移学习模型和其他SOTA (State⁃of⁃The⁃Art)模型进行了比较. ...
Learning to learn:Introduction and overview
1
1998
... 为了解决上述问题,本文采用自监督对比学习[14 -15 ] 和迁移学习[16 -17 ] 两种技术,将训练分为预训练和微调阶段.和监督学习相比,自监督学习具有无须标注训练样本的优势,能保证大量训练数据的低成本获取,结合大容量的深度学习模型可以发挥巨大的潜力.本文在预训练阶段利用自监督对比学习,从一个无标签的乳腺超声视频数据集中学习通用性知识,再将其迁移到下游的乳腺病变良恶性分类任务中.首先,构建一个无标签乳腺超声视频数据集,包含来自200位病人的1360个乳腺超声扫描视频,视频长度为8~10 s,从中选出11805例目标样本图片,并对每个目标样本动态生成相应的正样本和负样本.将上述样本用于对比学习训练一个三胞胎网络.在预训练阶段,提出多近邻采样及平均化方法来扩充正样本数量,并基于Hard Negative Mining和Hard Positive Mining构建对比损失函数Hard Triplet Loss以挑选困难正负样本,加快模型收敛.预训练完成后,把网络参数迁移到下游的乳腺肿瘤分类任务中,针对一个小的人工标注数据集进行微调.最后报告模型分类性能,并和基于ImageNet的迁移学习模型和其他SOTA (State⁃of⁃The⁃Art)模型进行了比较. ...
A survey on transfer learning
1
2010
... 为了解决上述问题,本文采用自监督对比学习[14 -15 ] 和迁移学习[16 -17 ] 两种技术,将训练分为预训练和微调阶段.和监督学习相比,自监督学习具有无须标注训练样本的优势,能保证大量训练数据的低成本获取,结合大容量的深度学习模型可以发挥巨大的潜力.本文在预训练阶段利用自监督对比学习,从一个无标签的乳腺超声视频数据集中学习通用性知识,再将其迁移到下游的乳腺病变良恶性分类任务中.首先,构建一个无标签乳腺超声视频数据集,包含来自200位病人的1360个乳腺超声扫描视频,视频长度为8~10 s,从中选出11805例目标样本图片,并对每个目标样本动态生成相应的正样本和负样本.将上述样本用于对比学习训练一个三胞胎网络.在预训练阶段,提出多近邻采样及平均化方法来扩充正样本数量,并基于Hard Negative Mining和Hard Positive Mining构建对比损失函数Hard Triplet Loss以挑选困难正负样本,加快模型收敛.预训练完成后,把网络参数迁移到下游的乳腺肿瘤分类任务中,针对一个小的人工标注数据集进行微调.最后报告模型分类性能,并和基于ImageNet的迁移学习模型和其他SOTA (State⁃of⁃The⁃Art)模型进行了比较. ...
Densely connected convolutional networks
3
2017
... 三胞胎网络本质上是三个共享参数的深度卷积网络.其中,深度卷积网络采用密集型网络DenseNet[18 ] ,包括一个7 × 7 3 × 3
... 训练了四个分别以DenseNet121,DenseNet161,DenseNet169和DenseNet201[18 ] 为骨架的三胞胎网络.在预训练阶段,输入图像的尺寸统一为224像素×224像素,数值归一化到0~1;网络采用带动量的随机梯度下降作为权值更新算法,初始学习率均为1 × 10 - 3 eta _min限制为0.0005.预训练一共包含200个epoch,每个epoch依次从11805张图像中选出目标样本,通过多近邻采样及平均化方法得到每个目标样本对应的正样本数据集,从不同病人视频中随机挑选负样本集,把目标样本、正负样本数据集组成一个训练批次,输入三胞胎网络中完成一次迭代训练.实验规定一个epoch对预训练数据集里所有图像完成一次迭代训练.预训练结束后,保留对比损失最小的模型参数,把最优参数迁移到下游乳腺肿瘤良恶性分类任务中,在三胞胎网络后面加入新的全连接层和Softmax输出分类结果.微调时冻结网络前面层的参数,解冻Dense Block3和Dense Block4的部分参数[18 ] ,在SYU数据集上进行五折交叉验证. ...
... [18 ],在SYU数据集上进行五折交叉验证. ...
Momentum contrast for unsupervised visual representation learning
3
2020
... I n f o N C E L o s s [19 -20 ] ,由解决二分类问题NCE Loss(Noise Contrastive Estimation)损失函数演变而来[21 ] .I n f o N C E L o s s [19 ] : ...
... [19 ]: ...
... 对于对比学习,每次训练选取的正负样本越多,模型的泛化性就越强[19 ,22 ] ,但一次性把大量图像输入三胞胎网络,对所有图像计算对比损失,进行梯度下降、更新参数,对机器的存储和计算要求很高,模型的收敛速度会非常慢.因此,本文在式(2) 的基础上发展了Hard Negative Mining和Hard Positive Mining. ...
Representation learning with contrastive predictive coding
1
2018
... I n f o N C E L o s s [19 -20 ] ,由解决二分类问题NCE Loss(Noise Contrastive Estimation)损失函数演变而来[21 ] .I n f o N C E L o s s [19 ] : ...
Notes on noise contrastive estimation and negative sampling
1
2014
... I n f o N C E L o s s [19 -20 ] ,由解决二分类问题NCE Loss(Noise Contrastive Estimation)损失函数演变而来[21 ] .I n f o N C E L o s s [19 ] : ...
A simple framework for contrastive learning of visual representations
1
2020
... 对于对比学习,每次训练选取的正负样本越多,模型的泛化性就越强[19 ,22 ] ,但一次性把大量图像输入三胞胎网络,对所有图像计算对比损失,进行梯度下降、更新参数,对机器的存储和计算要求很高,模型的收敛速度会非常慢.因此,本文在式(2) 的基础上发展了Hard Negative Mining和Hard Positive Mining. ...
Fully automatic tumor segmentation of breast ultrasound images with deep learning
2
2023
... ( 1 ) [23 ] 来判断截取的图像有无肿瘤. ...
... 如表1 所示,SYU数据集来自中大三院[23 -24 ] ,包括400张乳腺超声图像,其中175张良性,225张恶性,经预处理后统一尺寸为224 像素 × 224 像素 . 按照五折交叉验证方法把SYU数据集随机分成两个独立的微调数据集和测试数据集,微调数据集含乳腺超声图像320张,测试数据集含乳腺超声图像80张.图2 展示了SYU数据集的部分乳腺超声图像. ...
Automatic localization and identification of thoracic diseases from chest X?rays with deep learning
1
2022
... 如表1 所示,SYU数据集来自中大三院[23 -24 ] ,包括400张乳腺超声图像,其中175张良性,225张恶性,经预处理后统一尺寸为224 像素 × 224 像素 . 按照五折交叉验证方法把SYU数据集随机分成两个独立的微调数据集和测试数据集,微调数据集含乳腺超声图像320张,测试数据集含乳腺超声图像80张.图2 展示了SYU数据集的部分乳腺超声图像. ...
ImageNet:Constructing a large?scale image database
1
2009
... ImageNet是一个用于计算机视觉识别研究的大型可视化数据集,由斯坦福大学李飞飞教授带领创建[25 ] ,包含14197122张图像和21841个Synset索引,常用作评估图像分类算法性能的基准.基于ImageNet数据集,目前已有一大批有监督的预训练模型,如ResNet,DenseNet,GoogleNet等,这些模型提高了图像分类[26 -27 ] 、目标检测[28 -29 ] 、图像分割[30 ] 、图像描述[31 -32 ] 等多种任务的性能. ...
Deep residual learning for image recognition
1
2016
... ImageNet是一个用于计算机视觉识别研究的大型可视化数据集,由斯坦福大学李飞飞教授带领创建[25 ] ,包含14197122张图像和21841个Synset索引,常用作评估图像分类算法性能的基准.基于ImageNet数据集,目前已有一大批有监督的预训练模型,如ResNet,DenseNet,GoogleNet等,这些模型提高了图像分类[26 -27 ] 、目标检测[28 -29 ] 、图像分割[30 ] 、图像描述[31 -32 ] 等多种任务的性能. ...
Deeply?supervised nets
1
2015
... ImageNet是一个用于计算机视觉识别研究的大型可视化数据集,由斯坦福大学李飞飞教授带领创建[25 ] ,包含14197122张图像和21841个Synset索引,常用作评估图像分类算法性能的基准.基于ImageNet数据集,目前已有一大批有监督的预训练模型,如ResNet,DenseNet,GoogleNet等,这些模型提高了图像分类[26 -27 ] 、目标检测[28 -29 ] 、图像分割[30 ] 、图像描述[31 -32 ] 等多种任务的性能. ...
Faster R?CNN:Towards real?time object detection with region proposal networks
1
2017
... ImageNet是一个用于计算机视觉识别研究的大型可视化数据集,由斯坦福大学李飞飞教授带领创建[25 ] ,包含14197122张图像和21841个Synset索引,常用作评估图像分类算法性能的基准.基于ImageNet数据集,目前已有一大批有监督的预训练模型,如ResNet,DenseNet,GoogleNet等,这些模型提高了图像分类[26 -27 ] 、目标检测[28 -29 ] 、图像分割[30 ] 、图像描述[31 -32 ] 等多种任务的性能. ...
Object detection via a multi?region and semantic segmentation?aware CNN model
1
2015
... ImageNet是一个用于计算机视觉识别研究的大型可视化数据集,由斯坦福大学李飞飞教授带领创建[25 ] ,包含14197122张图像和21841个Synset索引,常用作评估图像分类算法性能的基准.基于ImageNet数据集,目前已有一大批有监督的预训练模型,如ResNet,DenseNet,GoogleNet等,这些模型提高了图像分类[26 -27 ] 、目标检测[28 -29 ] 、图像分割[30 ] 、图像描述[31 -32 ] 等多种任务的性能. ...
Fully convolutional networks for semantic segmentation
1
2015
... ImageNet是一个用于计算机视觉识别研究的大型可视化数据集,由斯坦福大学李飞飞教授带领创建[25 ] ,包含14197122张图像和21841个Synset索引,常用作评估图像分类算法性能的基准.基于ImageNet数据集,目前已有一大批有监督的预训练模型,如ResNet,DenseNet,GoogleNet等,这些模型提高了图像分类[26 -27 ] 、目标检测[28 -29 ] 、图像分割[30 ] 、图像描述[31 -32 ] 等多种任务的性能. ...
Show and tell:A neural image caption generator
1
2015
... ImageNet是一个用于计算机视觉识别研究的大型可视化数据集,由斯坦福大学李飞飞教授带领创建[25 ] ,包含14197122张图像和21841个Synset索引,常用作评估图像分类算法性能的基准.基于ImageNet数据集,目前已有一大批有监督的预训练模型,如ResNet,DenseNet,GoogleNet等,这些模型提高了图像分类[26 -27 ] 、目标检测[28 -29 ] 、图像分割[30 ] 、图像描述[31 -32 ] 等多种任务的性能. ...
DenseCap:Fully convolutional localization networks for dense captioning
1
2016
... ImageNet是一个用于计算机视觉识别研究的大型可视化数据集,由斯坦福大学李飞飞教授带领创建[25 ] ,包含14197122张图像和21841个Synset索引,常用作评估图像分类算法性能的基准.基于ImageNet数据集,目前已有一大批有监督的预训练模型,如ResNet,DenseNet,GoogleNet等,这些模型提高了图像分类[26 -27 ] 、目标检测[28 -29 ] 、图像分割[30 ] 、图像描述[31 -32 ] 等多种任务的性能. ...
A threshold selection method from gray?level histograms
1
1979
... 采用模糊增强和双边滤波两种数据预处理方法来降低噪声,增强信噪比.其中,模糊增强利用大津法(OTSU)[33 ] 生成二值化图像,增强肿瘤边缘特征;双边滤波采用加权平均去掉原图尖锐噪声,保留肿瘤的边界.但这两种数据增强均会丢失或削弱肿瘤的有用信息,因此原始图像也予以保留.将原始图像和两种数据增强的图像在通道维度上堆叠在一起,组成三通道图片输入模型. ...
How well do self?supervised models transfer to medical imaging?
1
2022
... 为了进一步证明三胞胎网络的分类性能,挑选最先进的三种ImageNet预训练模型[34 ] ,分别是MoCo⁃v2,BYOL和SwAV来进行对比实验,它们采用的是和本文不同的骨架网络.把这些预训练好的模型迁移到SYU数据集上进行微调和测试,并和前文DenseNet161⁃ImageNet预训练模型和DenseNet169⁃三胞胎网络(使用Hard Triplet Loss)进行对比.实验结果如图5 所示,余下两种指标详见表3 ,表中黑体字表示性能最优.可见DenseNet169⁃三胞胎网络(Hard Triplet Loss)的三种指标均领先于所有ImageNet预训练模型,DenseNet161⁃ImageNet预训练模型仅次于三胞胎网络.MoCo⁃v2,BYOL和SwAV的表现基本一致,AUC 在0.752~0.764,灵敏度和特异度均在0.665~0.676.原因可能是MoCo⁃v2,BYOL和SwAV三种模型虽然能较好地学习自然图像域的分布,但其自然图像与医学图像内秉的分布不同,所以模型不能很好地跨数据集泛化. ...
Self supervised lesion recognition for breast ultrasound diagnosis
1
2022
... 在基于对比学习方法对乳腺超声肿瘤的自动识别和分类任务上,之前的一个SOTA工作提出了一个多任务框架,利用单个病变的多个视图之间的关系开展对比学习[35 ] .我们重现了这一模型,本文命名为Multi⁃task LR(Lesion Recognition),并采用和我们的模型一样的预训练和微调数据集进行训练和测试. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}