

图1a为需要标记的一个示例图片[12],其完整标签集为
图1
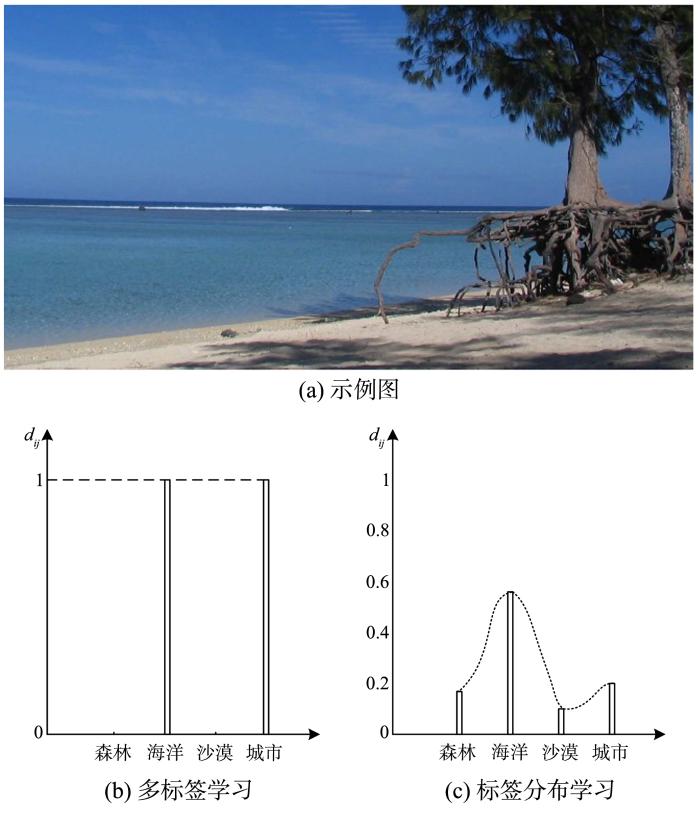
本文利用结构化标签依赖性来进行稳定准确的预测,其中依赖性通过标签表征度之间的差异来衡量.本文的工作分为扩展、学习和恢复三个阶段.在扩展阶段,将c个标签扩展为c(c-1)/2个,任意两个标签之差构成了新的标签,结合成对标签之间的关联性,构建结构化标签依赖性.在学习阶段,通过使用有限存储拟牛顿法求解最优模型,并预测新标签对应的分布.在恢复阶段,求解超定方程组以预测原始标签对应的标签分布.
在八个来自芽殖酿酒酵母的生物学实验的数据集上,将本文提出的算法与七种主流算法进行对比实验.结果表明,在多数的评价指标中,本文的算法比七种已有的LDL算法表现更好.
1 相关工作
首先提出问题描述,再回顾已有的LDL算法.表1列出本文中使用的符号.
表1 符号系统
Table 1
| Notations | Meaning |
|---|---|
| ℝq | q⁃dimensional input space |
| Y | The complete set of labels |
| S | The training set |
| xi | The i⁃th instance |
| di | The label distribution associated with xi |
| pi | The predicted label distribution associated with xi |
| xir | The r⁃th feature of xi |
| dij | The description degree of the j⁃th label to xi |
| θ | The distance⁃mapping model |
| X | The instance matrix |
| D | The label distribution matrix |
1.1 问题描述
与单标签和多标签学习相比,标签分布学习以一种更自然的方式去标记实例,并且为它的每个可能的标签分配一个数值.
下面给出它的形式化定义[2].令
当前,LDL的目标是学习到一个可以描述X和D之间关系的模型.预测的分布矩阵
1.2 已有的LDL算法
在已有的LDL算法中,有三种算法构造策略[14].
(1)问题转换策略:将LDL问题转换为单标签问题或多标签问题再处理.例如PT⁃SVM(Problem Transformation Support Vector Machine)算法[2]将标签分布数据转换为加权的单标签数据后,再使用支持向量机的方法处理数据.
(2)算法适应策略:扩展现有的学习算法以处理标签分布.例如AA⁃BP(Algorithm Adaptation Backpropagation)算法[2]构建了一个三层反向传播神经网络处理标签分布,为保证输出数据满足分布特征,使用Softmax函数作为激活函数.
(3)特殊算法策略:根据LDL的特征,设计特殊的专用算法直接匹配LDL问题.例如BFGS⁃LLD(Effective Quasi⁃Newton Label Distribution Learning)算法[2]根据分布数据的特征,学习到一个模型来直接预测标签分布.
通常,特殊算法由三部分组成:输出模型、目标函数和优化方法.
2 本文的SD⁃LDL算法
本文的SD⁃LDL算法分为三个阶段:标签扩展、标签学习和标签恢复.
2.1 标签扩展
现有的LDL算法通常都独立地考虑每个标签,未考虑标签之间的关系.受MLL中考虑标签的成对相关性[21]的启发,本文提出以下算法来获取标签之间的结构依赖性.对于实例xi,标签yj与标签yk对它的表征度的差异为:
其中,
是原始标签对(j,k)对应的新标签索引.
通过上述方式,获得与实例xi相关联的新标签分布
c(c-1)/2.
2.2 标签学习
遵循特殊算法策略的构建结构,本文的学习算法同样由三部分构成:输出模型、目标函数和优化方法.
(1)输出模型.经2.1标签扩展后,特征矩阵X仍然为q维,标签分布矩阵D扩展为c′维.构建一个q×c′的模型θ表示X与D的映射关系,通过该模型和X可计算得到与实例xi相关联的新标签的预测分布
其中
pij和pik分别是第j个原始标签和第k个原始标签对实例xi的预测表征度.
(2)目标函数.采用KL散度[13]设计目标函数:
其中,
(3)优化方法.本文采用L⁃BFGS方法[22]作为优化方法以获取最优模型θ.L⁃BFGS方法是在BFGS方法的基础上,对拟牛顿法的进一步精简.在拟牛顿法中,需要存储每一轮迭代产生的Hessian矩阵,这对机器的存储能力以及算法的时间复杂度都是很大的挑战.BFGS方法的基本思想是使用一个近似矩阵去拟合Hessian矩阵,以避免完整Hessian矩阵的计算及存储.L⁃BFGS方法仅存储部分用于拟合Hessian矩阵的向量,在保证拟合效果的前提下,达到进一步的存储空间的节约.有关L⁃BFGS方法的更多信息,请参阅附录.
2.3 标签恢复
在标签恢复阶段,通过标签学习获得的新标签对应的预测分布恢复为原始标签对应的预测分布.
根据
该方程组由c个变量和
3 实 验
3.1 数据集
表2 本文采用的数据集
Table 2
| Dataset | Instance | Feature | Label |
|---|---|---|---|
| Alpha | 2465 | 24 | 18 |
| Cdc | 2465 | 24 | 15 |
| Elu | 2465 | 24 | 14 |
| Diau | 2465 | 24 | 7 |
| Heat | 2465 | 24 | 6 |
| Spo | 2465 | 24 | 6 |
| Cold | 2465 | 24 | 4 |
| Dtt | 2465 | 24 | 4 |
3.2 评价指标
表3列出了评估LDL算法的六个评价指标.“↓”表示“越小越好”,“↑”表示“越大越好”.
表3 LDL算法的评价指标
Table 3
3.3 参数设置
表4列出SD⁃LDL算法与七种主流LDL算法相应的参数设置.
表4 参数设置
Table 4
| Algorithm | Settings |
|---|---|
| SD⁃LDL | λ=0.1 |
| PT⁃Bayes | 极大似然估计 |
| PT⁃SVM | C=1.0,Γ=0.01 |
| AA⁃kNN | k=5 |
| AA⁃BP | n=60 |
| IIS⁃LLD | - |
| BFGS⁃LLD | c1=10-4,c2=0.9 |
| EDL | - |
对于SD⁃LDL,式(8)中的参数设置为λ=0.1.对于PT⁃Bayes,使用极大似然估计作为估计高斯类条件概率密度函数.对于PT⁃SVM,参数设置为C=1.0,Γ=0.01.对于AA⁃kNN,参数k是邻居的数量,设置为5.对于AA⁃BP,参数n是隐藏层神经元的数量,设置为60.对于BFGS⁃LLD,参数设置为c1=10-4,c2=0.9.
3.4 实验结果
表5 Alpha数据集上的实验结果
Table 5
| Euclidean↓ | Sørensen↓ | Squard χ2↓ | KL↓ | Intersection↑ | Fidelity↑ | |
|---|---|---|---|---|---|---|
| SD⁃LDL | 0.0236±0.0003(1) | 0.0386±0.0003(1) | 0.0057±0.0003(1) | 0.0056±0.0002(1) | 0.9614±0.0005(1) | 0.9986±0.0003(1) |
| PT⁃Bayes | 0.2298±0.0124(8) | 0.3485±0.0154(8) | 0.3879±0.0277(8) | 0.5607±0.0710(8) | 0.6515±0.0154(8) | 0.8777±0.0100(8) |
| PT⁃SVM | 0.0276±0.0006(5) | 0.0445±0.0009(5) | 0.0071±0.0003(5) | 0.0071±0.0003(5) | 0.9565±0.0009(5) | 0.9981±0.0001(5) |
| AA⁃kNN | 0.0279±0.0006(6) | 0.0449±0.0012(6) | 0.0073±0.0003(6) | 0.0074±0.0004(7) | 0.9561±0.0012(6) | 0.9980±0.0001(6) |
| AA⁃BP | 0.0871±0.0070(7) | 0.1475±0.0131(7) | 0.1399±0.0501(7) | 0.0073±0.0058(6) | 0.8538±0.0117(7) | 0.9839±0.0017(7) |
| IIS⁃LLD | 0.269±0.0004(4) | 0.0429±0.0012(3) | 0.0069±0.0004(4) | 0.0069±0.0004(4) | 0.9571±0.0012(3) | 0.9983±0.0011(4) |
| BFGS⁃LLD | 0.0251±0.0004(2) | 0.0408±0.0011(2) | 0.0063±0.0008(2) | 0.0063±0.0004(2) | 0.9574±0.0009(2) | 0.9985±0.0011(2) |
| EDL | 0.0260±0.0011(3) | 0.0429±0.0022(4) | 0.0067±0.0006(3) | 0.0068±0.0006(3) | 0.9570±0.0022(4) | 0.9983±0.0002(3) |
表6 Cdc数据集上的实验结果
Table 6
| Euclidean↓ | Sørensen↓ | Squard χ2↓ | KL↓ | Intersection↑ | Fidelity↑ | |
|---|---|---|---|---|---|---|
| SD⁃LDL | 0.0282±0.0004(1) | 0.0428±0.0008(1) | 0.0073±0.0005(3) | 0.0071±0.0001(2) | 0.9572±0.0004(1) | 0.9983±0.0003(1) |
| PT⁃Bayes | 0.2399±0.0103(8) | 0.3455±0.0111(8) | 3853±0.0210(8) | 0.5374±0.0503(8) | 0.6545±0.0111(8) | 0.8778±0.0075(8) |
| PT⁃SVM | 0.0298±0.0007(4) | 0.0458±0.0012(5) | 0.0077±0.0004(5) | 0.0076±0.0004(5) | 0.9554±0.0012(5) | 0.9980±0.0001(5) |
| AA⁃kNN | 0.0301±0.0009(6) | 0.0462±0.0013(6) | 0.0080±0.0004(6) | 0.0079±0.0004(6) | 0.9538±0.0013(6) | 0.9980±0.0001(5) |
| AA⁃BP | 0.0769±0.0081(7) | 0.1192±0.0109(7) | 0.0842±0.0281(7) | 0.0511±0.0121(7) | 0.8829±0.0134(7) | 0.9879±0.0051(7) |
| IIS⁃LLD | 0.0290±0.0010(5) | 0.0445±0.0015(3) | 0.0073±0.0005(4) | 0.0072±0.0005(4) | 0.9556±0.0015(4) | 0.9982±0.0012(4) |
| BFGS⁃LLD | 0.0284±0.0011(3) | 0.0449±0.0016(4) | 0.0070±0.0004(1) | 0.0070±0.0005(1) | 0.9558±0.0016(3) | 0.9983±0.0011(2) |
| EDL | 0.0283±0.0006(2) | 0.0429±0.0008(2) | 0.0072±0.0004(2) | 0.0072±0.0004(3) | 0.9571±0.0008(2) | 0.9982±0.0001(3) |
表7 Elu数据集上的实验结果
Table 7
| Euclidean↓ | Sørensen↓ | Squard χ2↓ | KL↓ | Intersection↑ | Fidelity↑ | |
|---|---|---|---|---|---|---|
| SD⁃LDL | 0.0282±0.0004(1) | 0.0423±0.0006(1) | 0.0064±0.0005(1) | 0.0063±0.0003(1) | 0.9577±0.0006(1) | 0.9984±0.0003(1) |
| PT⁃Bayes | 0.2588±0.0203(8) | 0.3558±0.0198(8) | 0.4081±0.0408(8) | 0.6062±0.1030(8) | 0.6442±0.0198(8) | 0.8689±0.0156(8) |
| PT⁃SVM | 0.0293±0.0008(3) | 0.0438±0.0012(3) | 0.0068±0.0005(3) | 0.0068±0.0005(3) | 0.9562±0.0012(3) | 0.9983±0.0002(3) |
| AA⁃kNN | 0.0297±0.0010(4) | 0.0443±0.0014(4) | 0.0071±0.0006(5) | 0.0071±0.0006(5) | 0.9557±0.0014(4) | 0.9982±0.0002(4) |
| AA⁃BP | 0.0733±0.0037(7) | 0.1100±0.0048(7) | 0.0731±0.0026(7) | 0.0481±0.0061(7) | 0.8891±0.0064(7) | 0.9890±0.0025(7) |
| IIS⁃LLD | 0.0307±0.0009(5) | 0.0472±0.0014(5) | 0.0071±0.0004(4) | 0.0071±0.0004(4) | 0.9528±0.0015(6) | 0.9982±0.0035(5) |
| BFGS⁃LLD | 0.0308±0.0009(6) | 0.0475±0.0012(6) | 0.0075±0.0004(6) | 0.0073±0.0003(6) | 0.9552±0.0017(5) | 0.9979±0.0009(6) |
| EDL | 0.0289±0.0005(2) | 0.0431±0.0008(2) | 0.0067±0.0003(2) | 0.0067±0.0003(2) | 0.9569±0.0007(2) | 0.9983±0.0001(2) |
表8 Diau数据集上的实验结果
Table 8
| Euclidean↓ | Sørensen↓ | Squard χ2↓ | KL↓ | Intersection↑ | Fidelity↑ | |
|---|---|---|---|---|---|---|
| SD⁃LDL | 0.0602±0.0009(5) | 0.0660±0.0009(5) | 0.0160±0.0015(5) | 0.0155±0.0011(5) | 0.9340±0.0009(5) | 0.9959±0.0008(5) |
| PT⁃Bayes | 0.4027±0.0183(8) | 0.4177±0.0170(8) | 0.5280±0.0281(8) | 0.8512±0.0772(8) | 0.5823±0.0170(8) | 0.8230±0.0107(8) |
| PT⁃SVM | 0.0628±0.0037(6) | 0.0686±0.0041(6) | 0.0169±0.0018(6) | 0.0167±0.0017(6) | 0.9314±0.0041(6) | 0.9957±0.0004(6) |
| AA⁃kNN | 0.0567±0.0019(3) | 0.0622±0.0022(3) | 0.0145±0.0011(3) | 0.0145±0.0010(3) | 0.9378±0.0022(3) | 0.9963±0.0003(3) |
| AA⁃BP | 0.0802±0.0051(7) | 0.0863±0.0059(7) | 0.0276±0.0013(7) | 0.0291±0.0069(7) | 0.9142±0.0067(7) | 0.9929±0.0031(7) |
| IIS⁃LLD | 0.0539±0.0031(2) | 0.0593±0.0032(2) | 0.0144±0.0014(2) | 0.0141±0.0013(2) | 0.9407±0.0003(2) | 0.9964±0.0036(2) |
| BFGS⁃LLD | 0.0444±0.0022(1) | 0.0476±0.0023(1) | 0.0089±0.0008(1) | 0.0083±0.0009(1) | 0.9513±0.0027(1) | 0.9978±0.0031(1) |
| EDL | 0.0597±0.0010(4) | 0.0653±0.0010(4) | 0.0158±0.0005(4) | 0.0155±0.0005(4) | 0.9347±0.0010(4) | 0.9960±0.0002(4) |
表9 Heat数据集上的实验结果
Table 9
| Euclidean↓ | Sørensen↓ | Squard χ2↓ | KL↓ | Intersection↑ | Fidelity↑ | |
|---|---|---|---|---|---|---|
| SD⁃LDL | 0.0602±0.0009(1) | 0.0607±0.0008(1) | 0.0131±0.0012(1) | 0.0130±0.0008(1) | 0.9393±0.0008(1) | 0.9967±0.0008(1) |
| PT⁃Bayes | 0.4500±0.0231(8) | 0.4354±0.0193(8) | 0.5450±0.0361(8) | 0.8678±0.1198(8) | 0.5646±0.0193(8) | 0.8180±0.0131(8) |
| PT⁃SVM | 0.0625±0.0023(3) | 0.0627±0.0022(2) | 0.0141±0.0010(2) | 0.0141±0.0010(2) | 0.9373±0.0022(3) | 0.9964±0.0003(2) |
| AA⁃kNN | 0.0624±0.0020(2) | 0.0632±0.0018(3) | 0.0141±0.0010(2) | 0.0141±0.0010(2) | 0.9368±0.0018(2) | 0.9964±0.0003(2) |
| AA⁃BP | 0.0793±0.0068(7) | 0.0822±0.0071(7) | 0.0235±0.0047(7) | 0.0246±0.0053(7) | 0.9198±0.0061(7) | 0.9937±0.0028(7) |
| IIS⁃LLD | 0.0703±0.0036(5) | 0.0692±0.0033(5) | 0.0182±0.0016(5) | 0.0182±0.0016(5) | 0.9309±0.0033(5) | 0.9954±0.0042(6) |
| BFGS⁃LLD | 0.0728±0.0031(6) | 0.0791±0.0029(6) | 0.0188±0.0016(6) | 0.0186±0.0015(6) | 0.9304±0.0034(6) | 0.9961±0.0048(5) |
| EDL | 0.0629±0.0016(4) | 0.0633±0.0017(4) | 0.0143±0.0008(4) | 0.0143±0.0008(4) | 0.9366±0.0017(4) | 0.9963±0.0003(4) |
表10 Spo数据集上的实验结果
Table 10
| Euclidean↓ | Sørensen↓ | Squard χ2↓ | KL↓ | Intersection↑ | Fidelity↑ | |
|---|---|---|---|---|---|---|
| SD⁃LDL | 0.0835±0.0012(2) | 0.0860±0.0011(2) | 0.0265±0.0014(3) | 0.0266±0.0011(3) | 0.9140±0.0011(3) | 0.9932±0.0006(4) |
| PT⁃Bayes | 0.4038±0.0162(8) | 0.4030±0.0134(8) | 0.4972±0.0246(8) | 0.7172±0.0840(8) | 0.5971±0.0134(8) | 0.8342±0.0095(8) |
| PT⁃SVM | 0.0878±0.0019(5) | 0.0893±0.0022(5) | 0.0280±0.0015(5) | 0.0284±0.0015(5) | 0.9107±0.0022(5) | 0.9929±0.0004(5) |
| AA⁃kNN | 0.0879±0.0030(6) | 0.0899±0.0024(6) | 0.0286±0.0020(6) | 0.0286±0.0002(6) | 0.9096±0.0034(6) | 0.9927±0.0005(6) |
| AA⁃BP | 0.0979±0.0041(7) | 0.1012±0.0038(7) | 0.0344±0.0038(7) | 0.0359±0.0039(7) | 0.8982±0.0037(7) | 0.9906±0.0010(7) |
| IIS⁃LLD | 0.0863±0.0041(4) | 0.0861±0.0036(3) | 0.0251±0.0036(2) | 0.0252±0.0022(2) | 0.9139±0.0036(3) | 0.9937±0.0005(2) |
| BFGS⁃LLD | 0.0819±0.0045(1) | 0.0833±0.0038(1) | 0.0229±0.0019(1) | 0.0226±0.0021(1) | 0.9168±0.0039(1) | 0.9951±0.0007(1) |
| EDL | 0.0843±0.0029(3) | 0.0872±0.0029(4) | 0.0268±0.0015(4) | 0.0269±0.0016(4) | 0.9128±0.0028(4) | 0.9932±0.0004(3) |
表11 Cold数据集上的实验结果
Table 11
| Euclidean↓ | Sørensen↓ | Squard χ2↓ | KL↓ | Intersection↑ | Fidelity↑ | |
|---|---|---|---|---|---|---|
| SD⁃LDL | 0.0713±0.0009(1) | 0.0619±0.0009(1) | 0.0133±0.0019(1) | 0.0130±0.0014(1) | 0.9381±0.0009(1) | 0.9968±0.0014(1) |
| PT⁃Bayes | 0.5252±0.0224(8) | 0.4479±0.0189(8) | 0.5873±0.0352(8) | 0.9089±0.1042(8) | 0.5521±0.0189(8) | 0.7991±0.0134(8) |
| PT⁃SVM | 0.0753±0.0080(4) | 0.0654±0.0069(5) | 0.0147±0.0033(4) | 0.0146±0.0033(4) | 0.9346±0.0069(5) | 0.9963±0.0008(4) |
| AA⁃kNN | 0.0724±0.0027(2) | 0.0630±0.0024(2) | 0.0136±0.0011(2) | 0.0136±0.0011(2) | 0.9370±0.0024(2) | 0.9966±0.0003(3) |
| AA⁃BP | 0.0838±0.0045(7) | 0.0710±0.0027(7) | 0178±0.0011(7) | 0.0163±0.0030(7) | 0.9328±0.0029(7) | 0.9952±0.0017(7) |
| IIS⁃LLD | 0.0767±0.0004(5) | 0.0653±0.0034(4) | 0.0157±0.0015(6) | 0.0155±0.0015(6) | 0.9347±0.0034(4) | 0.9960±0.0039(6) |
| BFGS⁃LLD | 0.0745±0.0004(3) | 0.0641±0.0035(3) | 0.0139±0.0013(3) | 0.0143±0.0015(3) | 0.9348±0.0035(3) | 0.9968±0.0036(2) |
| EDL | 0.0771±0.0018(6) | 0.0668±0.0016(6) | 0.0154±0.0009(5) | 0.0153±0.0009(5) | 0.9332±0.0016(6) | 0.9961±0.0003(5) |
表12 Dtt数据集上的实验结果
Table 12
| Euclidean↓ | Sørensen↓ | Squard χ2↓ | KL↓ | Intersection↑ | Fidelity↑ | |
|---|---|---|---|---|---|---|
| SD⁃LDL | 0.0495±0.0015(1) | 0.0429±0.0013(2) | 0.0066±0.0038(2) | 0.0063±0.0029(2) | 0.9571±0.0013(2) | 0.9983±0.0021(3) |
| PT⁃Bayes | 0.4879±0.0242(8) | 0.4156±0.0192(8) | 0.5416±0.0438(8) | 0.9069±0.1580(8) | 0.5844±0.0192(8) | 0.8113±0.0186(8) |
| PT⁃SVM | 0.0516±0.0029(5) | 0.0447±0.0024(5) | 0.0071±0.0009(6) | 0.0071±0.0009(6) | 0.9553±0.0024(5) | 0.9982±0.0003(5) |
| AA⁃kNN | 0.0512±0.0019(4) | 0.0443±0.0017(4) | 0.0071±0.0007(5) | 0.0070±0.0007(5) | 0.9557±0.0017(4) | 0.9982±0.0002(4) |
| AA⁃BP | 0.0622±0.0032(7) | 0.0531±0.0029(7) | 0.0097±0.0012(7) | 0.0122±0.0037(7) | 0.9465±0.0024(7) | 0.9969±0.0011(7) |
| IIS⁃LLD | 0.0535±0.0023(6) | 0.0480±0.0023(6) | 0.0068±0.0005(3) | 0.0068±0.0005(3) | 0.9520±0.0023(6) | 0.9983±0.0013(2) |
| BFGS⁃LLD | 0.0495±0.0019(2) | 0.0409±0.0017(1) | 0.0058±0.0005(1) | 0.0054±0.0004(1) | 0.9584±0.0023(1) | 0.9989±0.0010(1) |
| EDL | 0.0508±0.0022(3) | 0.0440±0.0018(3) | 0.0069±0.0007(4) | 0.0068±0.0008(4) | 0.9560±0.0018(3) | 0.9982±0.0003(5) |
首先,对比SD⁃LDL算法与EDL算法,这两个算法均考虑了标签间的关系,但在所有数据集上的实验结果表明,本文提出的算法依然占优.
其次,对比PT⁃Bayes算法、PT⁃SVM算法、AA⁃kNN算法、AA⁃BP算法、IIS⁃LLD算法和BFGS⁃LLD算法,这六个算法均未考虑标签间的关系.BFGS⁃LLD算法在五个数据集上的表现占优,AA⁃kNN算法仅在两个数据集上的表现占优,IIS⁃LLD算法和PT⁃SVM算法仅在一个数据集上的表现较为占优.AA⁃BP算法和PT⁃Bayes算法在所有数据集上的表现均不佳.
最后,将本文提出的SD⁃LDL算法与七种主流的LDL算法作对比.本文提出的SD⁃LDL算法在七个数据集上的表现均占优.
3.5 讨 论
受MLL中考虑标签的成对相关性的启发,本文通过获取标签间的结构依赖性以提高模型的预测能力.通过标签扩展获得该依赖性,使得预测模型θ的维度增加,能够更细粒度地表征特征矩阵X和标签分布矩阵D之间的关系.实验结果证明在多数数据集上,本文提出的SD⁃LDL算法的表现比七种主流的LDL算法更好.
对于Alpha,Cold,Elu,Cdc和Heat数据集,本文提出的SD⁃LDL算法在绝大多数的评价指标上均为最佳.这些数据集拥有的标签数量较多,有更多可供利用的标签结构依赖性.
对于Spo和Diau数据集,SD⁃LDL算法和EDL算法的表现均略逊色于BFGS⁃LLD算法.前两种算法均考虑了标签间的关系,而BFGS⁃LLD算法并未考虑.可能是由于这两个数据集中标签间的关系不强,或者是由于现有算法中用于表征标签间关系的方式不适用于这两个数据集.
4 结 论
LDL是一个通用的学习框架,它可以有效地处理标签歧义问题.为了利用成对标签的结构依赖性,本文提出了SD⁃LDL算法.本文的方法包括标签扩展、标签学习和标签恢复三个阶段.实验结果表明,该算法适用于标签分布框架,并且比大多数现有的LDL算法表现更好.
在未来的工作中,将尝试从以下几个方面提高LDL算法的性能:
(1)在扩展阶段,利用新的差异函数来表示结构标签依赖性.
(2)在学习阶段,采用属性约简以减少时间复杂度,并且使用其他衡量相似度的函数.
(3)在恢复阶段,探索新的标签恢复方案.
(9)
其中,
上述二阶泰勒展开的最小化可得:
在L⁃BFGS方法中,
其中,
L⁃BFGS方法的核心思想是使用一个近似矩阵B用于拟合Hessian矩阵H,以避免复杂的计算,拟合矩阵B如
其中,I是单位矩阵,其余变量如下所示:
参考文献
Facial age estimation by learning from label distributions
∥
Label distribution learning
Deep label distribution learning for apparent age estimation
∥
Soft video parsing by label distribution learning
∥
Facial age estimation by adaptive label distribution learning
∥
Facial age estimation by learning from label distributions
Multi⁃label learning by exploiting label dependency
∥
Multilabel classification with label correlations and missing labels
∥
Multi
∥label learning by exploiting label correlations locally∥
Emotion distribution learning from texts
∥
Crowd counting in public video surveillance by label distribution learning
Hamming embedding and weak geometric consistency for large scale image search
∥
On information and sufficiency
Label distribution learning by exploiting sample correlations locally
∥
A maximum entropy approach to natural language processing
Classification with label distribution learning
∥
Label distribution learning by exploiting label correlations
∥
Hierarchical classification based on label distribution learning
∥
Label distribution learning with label correlations via low⁃rank approximation
∥
Label distribution learning with label⁃specific features
∥
Efficient voting prediction for pairwise multilabel classification
A modified BFGS algorithm for unconstrained optimization
Cluster analysis and display of genome⁃wide expression patterns
Euclidean distance mapping
A method of establishing groups of equal amplitudes in plant sociology based on similarity of species content and its application to analyses of the vegetation on Danish commons
A statistical approach to evaluating distance metrics and analog assignments for pollen records

{kind=link}
{kind=link}