南京大学学报(自然科学版) ›› 2020, Vol. 56 ›› Issue (2): 197–205.doi: 10.13232/j.cnki.jnju.2020.02.005
基于结构保持对抗网络的跨模态实体分辨
吕国俊1,曹建军2( ),郑奇斌1,常宸1,翁年凤2
),郑奇斌1,常宸1,翁年凤2
- 1.陆军工程大学指挥控制工程学院,南京,210007
2.国防科技大学第六十三研究所,南京,210007
Structure maintenance based adversarial network for cross⁃modal entity resolution
Lü Guojun1,Jianjun Cao2(),Qibin Zheng1,Chen Chang1,Nianfeng Weng2
- 1.Institute of Command and Control Engineering,Army Engineering University,Nanjing,210007,China
2.The Sixty?third Research Institute,National University of Defense Technology,Nanjing,210007,China
摘要:
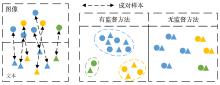
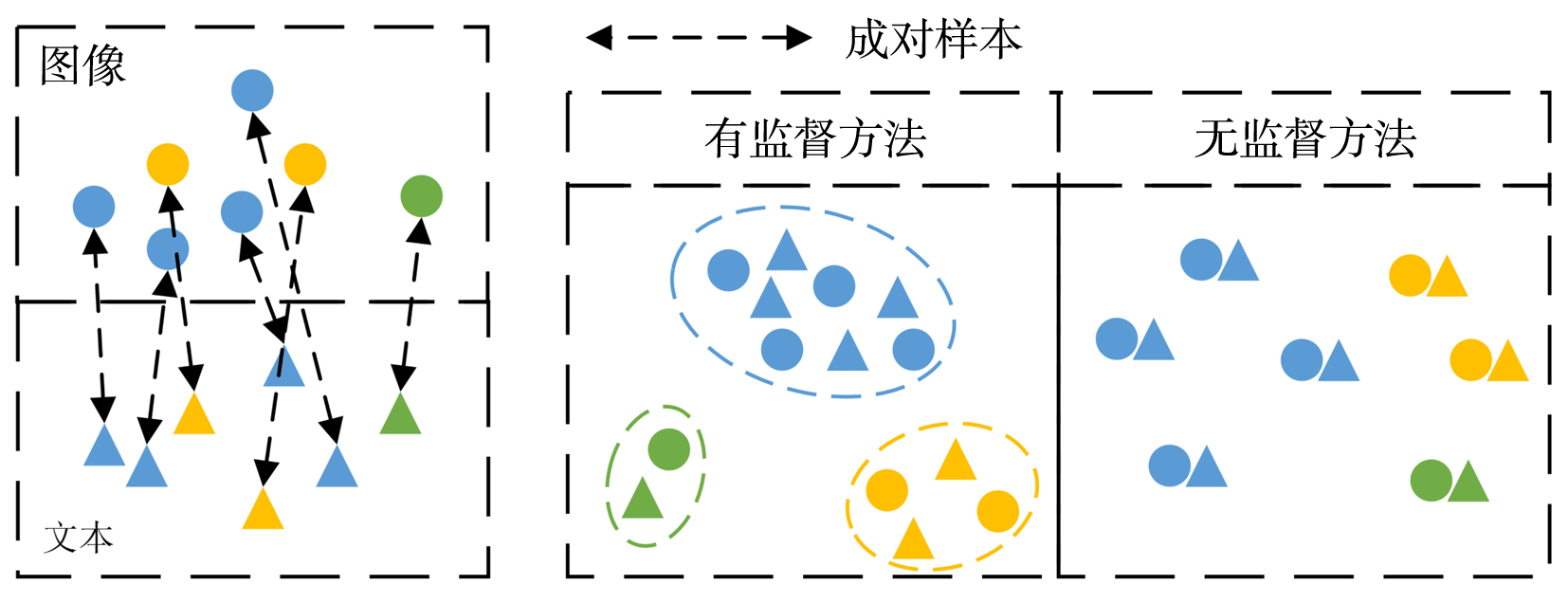
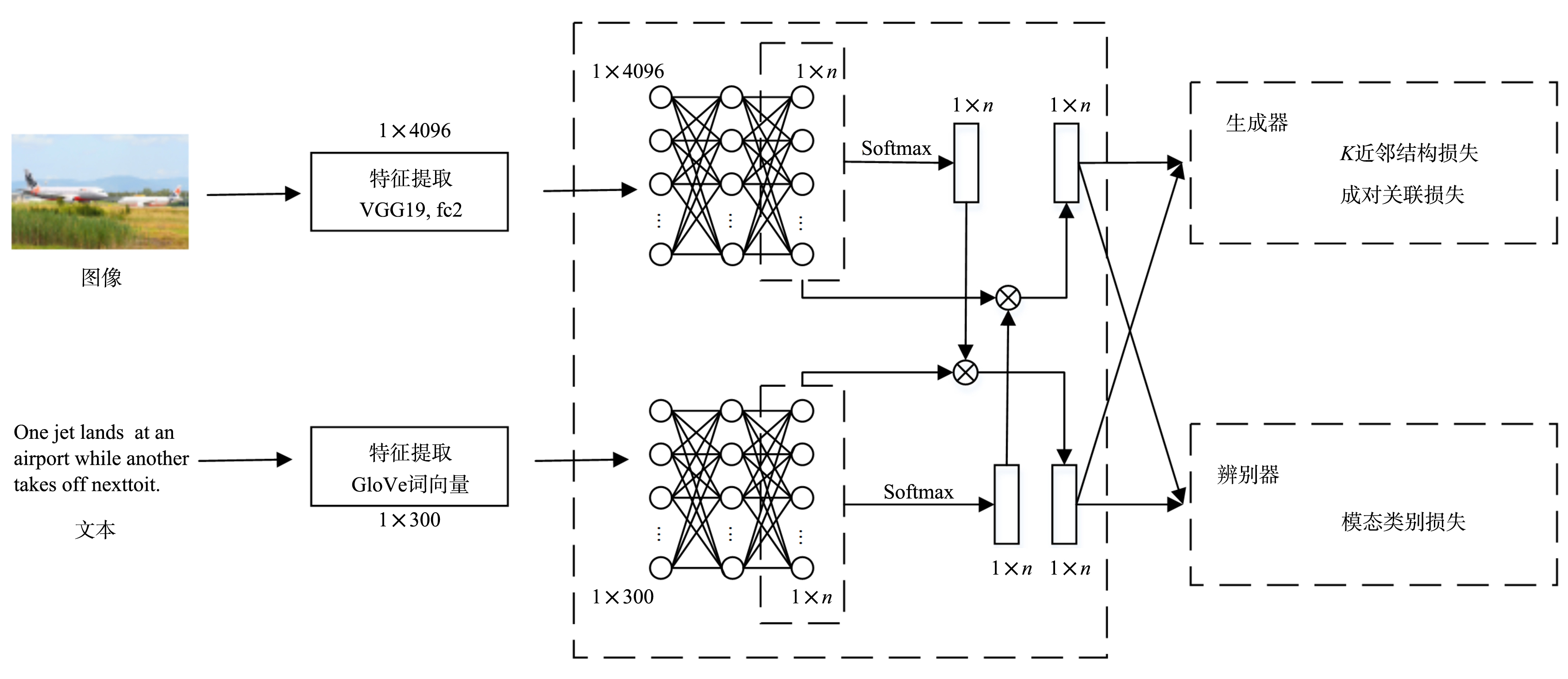
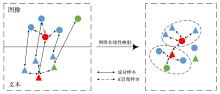
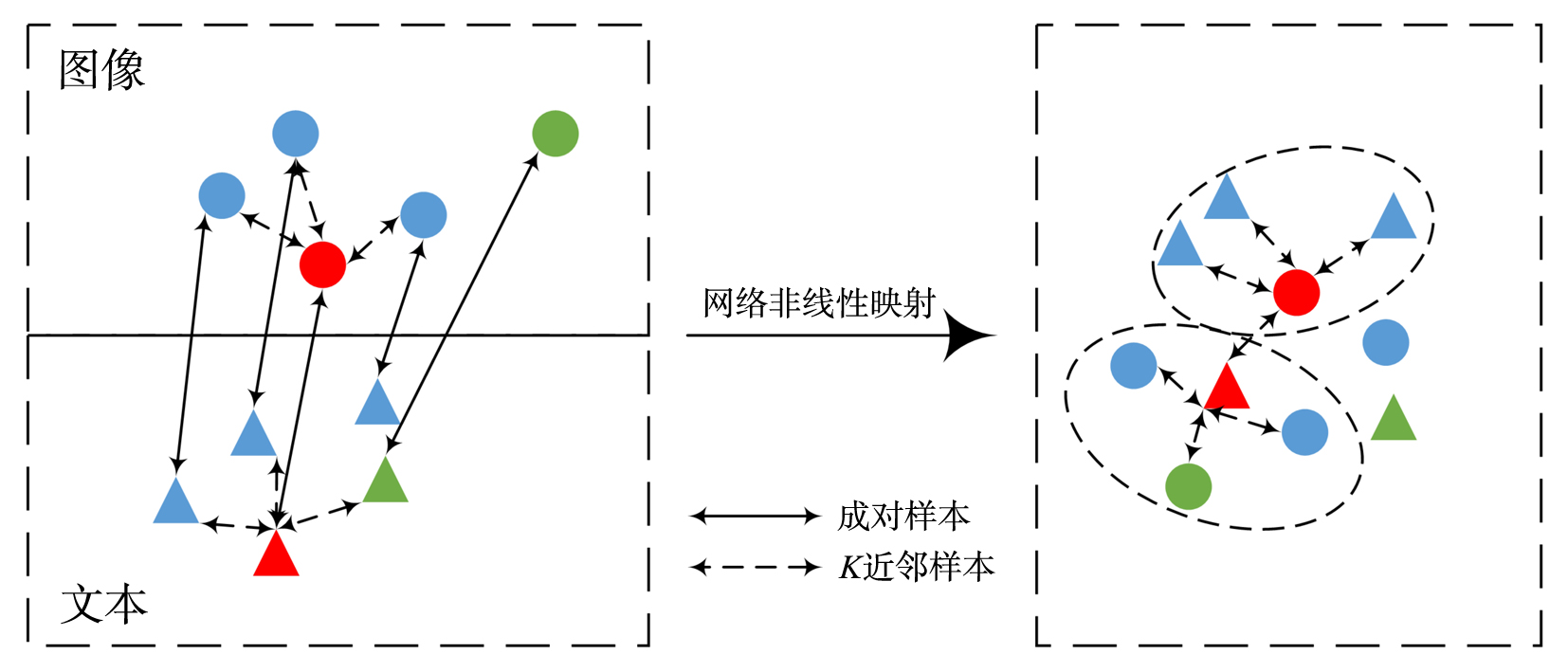
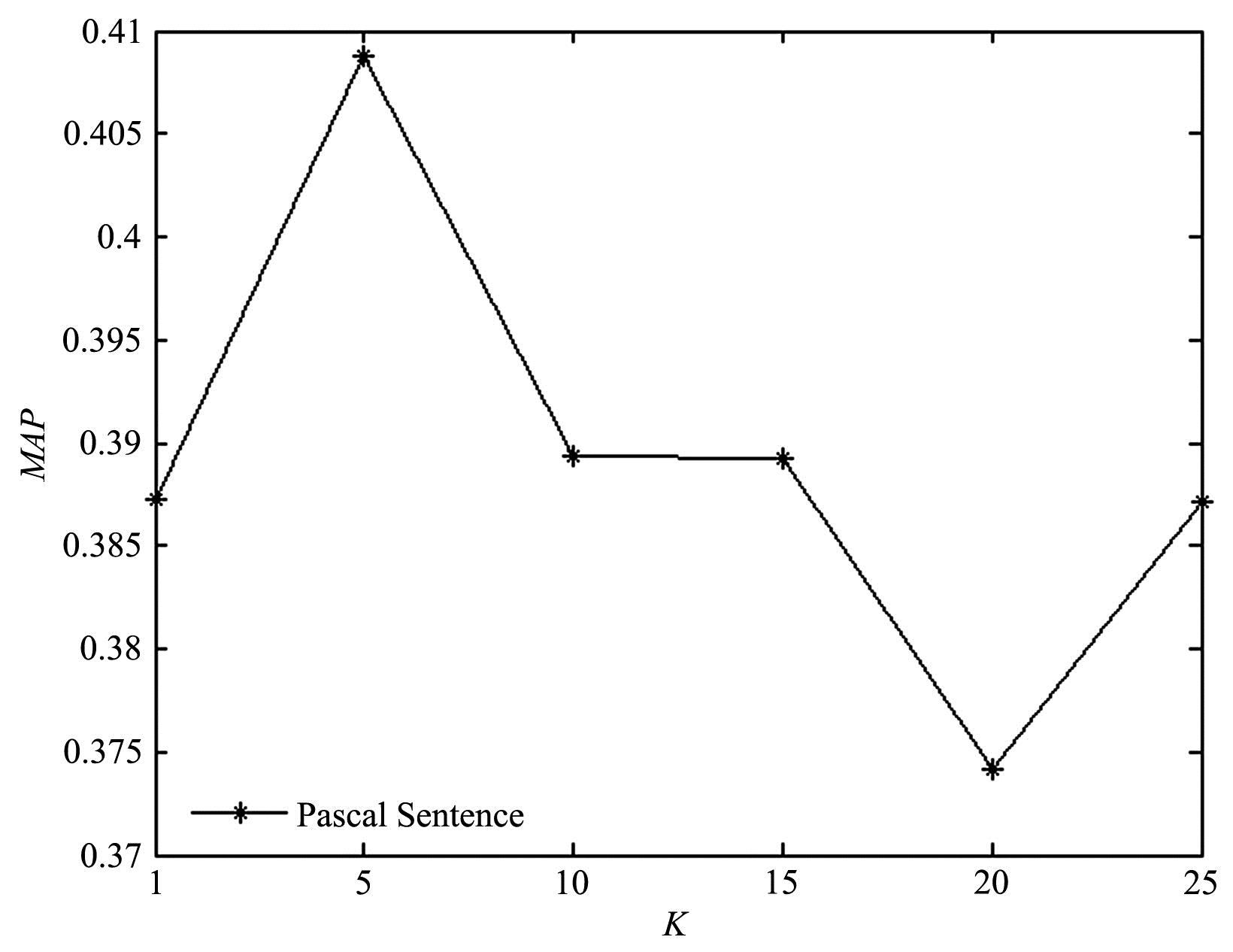
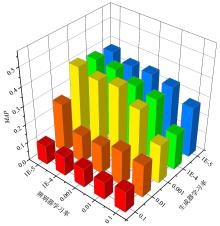
跨模态实体分辨旨在从不同模态的数据中找到对同一实体的不同客观描述.常用的跨模态实体分辨方法通过将不同模态数据映射到同一空间中进行相似性度量,大多通过使用类别信息建立映射前后的语义联系,却忽略了对跨模态成对样本信息的有效利用.在真实数据源中,给大量的数据进行标注耗时费力,难以获得足够的标签数据来完成监督学习.对此,提出一种基于结构保持的对抗网络跨模态实体分辨方法(Structure Maintenance based Adversarial Network,SMAN),在对抗网络模型下构建模态间的K近邻结构损失,利用模态间成对信息在映射前后的结构保持学习更一致的表示,引入联合注意力机制实现模态间成对样本信息的对齐.实验结果表明,在不同数据集上,SMAN和其他无监督方法和一些典型的有监督方法相比有更好的性能.
中图分类号:
- TP311


| 1 | 彭宇新,綦金玮,黄鑫.多媒体内容理解的研究现状与展望.计算机研究与发展,2019,56(1):183-208. |
| Peng Y X,Qi J W,Huang X.Current research status and prospects on multimedia content understanding. Journal of Computer Research and Development,2019,56(1):183-208.) | |
| 2 | Peng Y X,Huang X,Zhao Y Z.An overview of cross?media retrieval:concepts,methodologies,bench?marks,and challenges.IEEE Transactions on Circuits and Systems for Video Technology,2017,28(9):2372-2385. |
| 3 | Yu E,Sun J D,Li J,et al.Adaptive semi?supervised feature selection for cross?modal retrieval.IEEE Transactions on Multimedia,2019,21(5):1276-1288. |
| 4 | Rasiwasia N,Pereira J C,Coviello E,et al.A new approach to cross?modal multimedia retrieval∥Proceedings of the 18th ACM International Conference on Multimedia.Florence,Italy:ACM Press,2010:251-260. |
| 5 | Putthividhy D,Attias H T,Nagarajan S S.Topic regression multi?modal latent dirichlet allocation for image annotation∥2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.San Francisco,CA,USA:IEEE,2010:3408-3415. |
| 6 | Andrew G,Arora R,Bilmes JA,et al.Deep canonical correlation analysis∥Proceedings of the 30th International Conference on International Conference on Machine Learning.Atlanta,GA,USA:ICML Press,2013:1247-1255. |
| 7 | Srivastava N,Salakhutdinov R.Multimodal learning with deep Boltzmann machines.Journal of Machine Learning Research,2014(15):2949-2980. |
| 8 | Feng F X,Wang X J,Li R F.Cross?modal retrieval with correspondence autoencoder∥Proceedings of the 22nd ACM International Conference on Multimedia.Orlando,FL,USA:ACM Press,2014:7-16. |
| 9 | He L,Xu X,Lu H M,et al.Unsupervised cross-modal retrieval through adversarial learning∥2017 IEEE International Conference on Multimedia and Expo.Hong Kong,China:IEEE,2017:1153-1158. |
| 10 | Chung Y A,Weng W H,Tong S,et al.Unsupervised cross?modal alignment of speech and text embedding space∥Proceedings of Neural Information Processing Systems.Montreal,Canada:NIPS Press,2018:7354-7364. |
| 11 | Gong Y C,Ke Q F,Isard M,et al.A multi?view embedding space for modeling internet images,tags,and their semantics.International Journal of Computer Vision,2014,106(2):210-233. |
| 12 | Wang K Y,He R,Wang L,et al.Joint feature selection and subspace learning for cross?modal retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,38(10):2010-2023. |
| 13 | Peng Y X,Huang X,Qi J W.Cross?media shared representation by hierarchical learning with multiple deep networks∥Proceedings of the 25th International Joint Conference on Artificial Intelligence.New York,NY,USA:AAAI Press,2016:3846-3853. |
| 14 | Wang L W,Li Y,Lazebnik S.Learning deep structure?preserving image?text embeddings∥2016 IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas,NV,USA:IEEE,2016:5005-5013. |
| 15 | Yan F,Mikolajczyk K.Deep correlation for matching images and text∥2015 IEEE Conference on Computer Vision and Pattern Recognition.Boston,MA,USA:IEEE,2015:3441-3450. |
| 16 | Goodfellow I J,Pouget?Abadie J,Mirza M,et al.Generative adversarial nets∥Proceedings of the 27th International Conference on Neural Information Processing Systems.Cambridge,MA,USA:MIT Press,2014:2672-2680. |
| 17 | Wang B K,Yang Y,Xu X,et al.Adversarial cross?modal retrieval∥Proceedings of the 25th International Conference on Multimedia.New York,NY,USA:ACM Press,2017:154-162. |
| 18 | Hu L Q,Kan M N,Shan S G,et al.Duplex generative adversarial network for unsupervised domain adaptation∥2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA:IEEE,2018:1498-1507. |
| 19 | Wei Y C,Zhang Y,Lu C Y,et al.Cross?modal retrieval with CNN visual features:a new baseline.IEEE Transactions on Cybernetics,2017,47(2):449-460. |
| 20 | Kingma D P,Ba J.Adam:a method for stochastic optimization.2014,arXiv:1412.6980. |
| 21 | Wang K Y,He R,Wang W,et al.Learning coupled feature spaces for cross?modal matching∥2013 IEEE International Conference on Computer Vision.Sydney,Australia:IEEE,2013:2088-2095. |
| 22 | Xu X,Shimada A,Taniguchi R I,et al.Coupled dictionary learning and feature mapping for cross?modal retrieval∥2015 IEEE International Conference on Multimedia and Expo.Turin,Italy:IEEE,2015:1-6. |
| 23 | Blei D M,Jordan M I.Modeling annotated data∥Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval.New York,NY,USA:ACM Press,2003:127-134. |
| 24 | Van Der Maaten L,Hinton G.Visualizing data using t?SNE.Journal of Machine Learning,2008,9(11):2579-2605. |
| [1] | 陈俊芬,赵佳成,韩洁,翟俊海. 基于深度特征表示的Softmax聚类算法[J]. 南京大学学报(自然科学版), 2020, 56(4): 533-540. |
|