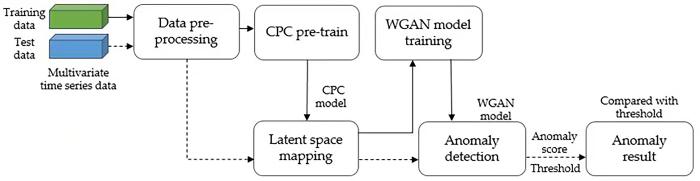
Anomaly detection is one of the important research directions of data mining. The indicators of industrial devices are monitored by sensors in the form of multivariate time series. Anomaly detection of multivariate time series is critical for security and improving service quality. However,the definition of anomalies is relatively vague and the data with anomalous labels is rare. Also,multivariate time series have complex time dependence and stochasticity which makes anomaly detection many issues to be settled. In this paper,we propose CPCGAN,a self⁃supervised learning method,to perform anomaly detection on multivariate time series data. Our main idea is to obtain the representation vector of multivariate time series data by using the contrastive learning method. We use the representation vector with prior information as input when training the generative adversarial network. The reconstruction error of the generative adversarial network is used to determine anomalies. We compare our method with five unsupervised anomaly detection methods on five datasets. Experimental results show that our method is effective at detecting both types of anomalies and performs better on most datasets compared with other methods.
Keywords:anomaly detection
;
multivariate time series
;
self⁃supervised learning
;
contrastive learning
;
Generative Adversarial Network
Zhou Yehan, Shen Ziyu, Zhou Qing, Li Yun. Self⁃supervised multivariate time series anomaly detection based on GAN. Journal of nanjing University[J], 2023, 59(2): 256-262 doi:10.13232/j.cnki.jnju.2023.02.008
传统的异常检测方法是基于统计过程控制(Statistical Process Control)的,如CUSUM,EWMA和萧华特管制图[3]等,然而,使用统计量来寻找异常点的做法难以处理多元时间序列这种复杂的数据.随着数据量的快速增加,许多基于机器学习的研究相继展开,由于带有异常值标签的时序数据很难得到,人工打标签成本高昂,因此无监督学习的异常检测方法吸引了很多学者.
当前,无监督机器学习异常检测主要分为基于预测的方法和基于重构的方法.Hundman et al[4]使用LSTM (Long Short⁃Term Memory)[5]对多元时序数据进行预测,针对预测误差进行异常检测.Li et al[6]使用原始GAN (Generative Adversarial Networks)模型拟合多元时序数据分布,通过重构时序数据误差和判别器来检测异常.Geiger et al[7]提出TadGAN模型,通过训练生成器来重构时序数据,并使用评价器来计算异常得分.Su et al[8]使用变分自动编码器和平面标准化流来学习多元时序数据的鲁棒性表征,并重构数据概率分布来进行异常检测.
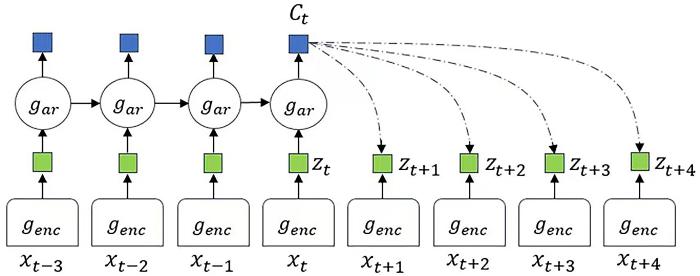
首先,一段多元时序数据通过非线性编码器被映射为潜在表示.考虑时序数据的时间依赖性,选定时间点t,将t时刻及之前的潜在向量作为输入,将其输入自回归模型,产生一个具有t时刻之前时间点信息的潜在表示.为了使得到的表示变量 Z 具有上下文信息,需要考虑未来第k个时间点的数据,使与之间的互信息最大化.此时令.由于难以直接对高维数据的概率分布建模,因此使用自动编码器和双线性模型来计算.其中,表示未来第k步时对的线性变换,将c变换成与z相同的维度.
On the properties of neural machine translation:Encoder⁃decoder approaches
∥Proceedings of the 8th Workshop on Syntax,Semantics and Structure in Statistical Translation. Doha,Qatar:Association for Computational Linguistics,2014:103-111.
Building energy doctors:An SPC and Kalman filter?based method for system?level fault detection in HVAC systems
1
2014
... 传统的异常检测方法是基于统计过程控制(Statistical Process Control)的,如CUSUM,EWMA和萧华特管制图[3]等,然而,使用统计量来寻找异常点的做法难以处理多元时间序列这种复杂的数据.随着数据量的快速增加,许多基于机器学习的研究相继展开,由于带有异常值标签的时序数据很难得到,人工打标签成本高昂,因此无监督学习的异常检测方法吸引了很多学者. ...
Detecting spacecraft anomalies using LSTMs and nonparametric dynamic thresholding
2
2018
... 当前,无监督机器学习异常检测主要分为基于预测的方法和基于重构的方法.Hundman et al[4]使用LSTM (Long Short⁃Term Memory)[5]对多元时序数据进行预测,针对预测误差进行异常检测.Li et al[6]使用原始GAN (Generative Adversarial Networks)模型拟合多元时序数据分布,通过重构时序数据误差和判别器来检测异常.Geiger et al[7]提出TadGAN模型,通过训练生成器来重构时序数据,并使用评价器来计算异常得分.Su et al[8]使用变分自动编码器和平面标准化流来学习多元时序数据的鲁棒性表征,并重构数据概率分布来进行异常检测. ...
... 当前,无监督机器学习异常检测主要分为基于预测的方法和基于重构的方法.Hundman et al[4]使用LSTM (Long Short⁃Term Memory)[5]对多元时序数据进行预测,针对预测误差进行异常检测.Li et al[6]使用原始GAN (Generative Adversarial Networks)模型拟合多元时序数据分布,通过重构时序数据误差和判别器来检测异常.Geiger et al[7]提出TadGAN模型,通过训练生成器来重构时序数据,并使用评价器来计算异常得分.Su et al[8]使用变分自动编码器和平面标准化流来学习多元时序数据的鲁棒性表征,并重构数据概率分布来进行异常检测. ...
Mad?GAN:Multivariate anomaly detection for time series data with generative adversarial networks
2
2019
... 当前,无监督机器学习异常检测主要分为基于预测的方法和基于重构的方法.Hundman et al[4]使用LSTM (Long Short⁃Term Memory)[5]对多元时序数据进行预测,针对预测误差进行异常检测.Li et al[6]使用原始GAN (Generative Adversarial Networks)模型拟合多元时序数据分布,通过重构时序数据误差和判别器来检测异常.Geiger et al[7]提出TadGAN模型,通过训练生成器来重构时序数据,并使用评价器来计算异常得分.Su et al[8]使用变分自动编码器和平面标准化流来学习多元时序数据的鲁棒性表征,并重构数据概率分布来进行异常检测. ...
TadGAN:Time series anomaly detection using generative adversarial networks
2
... 当前,无监督机器学习异常检测主要分为基于预测的方法和基于重构的方法.Hundman et al[4]使用LSTM (Long Short⁃Term Memory)[5]对多元时序数据进行预测,针对预测误差进行异常检测.Li et al[6]使用原始GAN (Generative Adversarial Networks)模型拟合多元时序数据分布,通过重构时序数据误差和判别器来检测异常.Geiger et al[7]提出TadGAN模型,通过训练生成器来重构时序数据,并使用评价器来计算异常得分.Su et al[8]使用变分自动编码器和平面标准化流来学习多元时序数据的鲁棒性表征,并重构数据概率分布来进行异常检测. ...
Robust anomaly detection for multivariate time series through stochastic recurrent neural network
2
2019
... 当前,无监督机器学习异常检测主要分为基于预测的方法和基于重构的方法.Hundman et al[4]使用LSTM (Long Short⁃Term Memory)[5]对多元时序数据进行预测,针对预测误差进行异常检测.Li et al[6]使用原始GAN (Generative Adversarial Networks)模型拟合多元时序数据分布,通过重构时序数据误差和判别器来检测异常.Geiger et al[7]提出TadGAN模型,通过训练生成器来重构时序数据,并使用评价器来计算异常得分.Su et al[8]使用变分自动编码器和平面标准化流来学习多元时序数据的鲁棒性表征,并重构数据概率分布来进行异常检测. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}