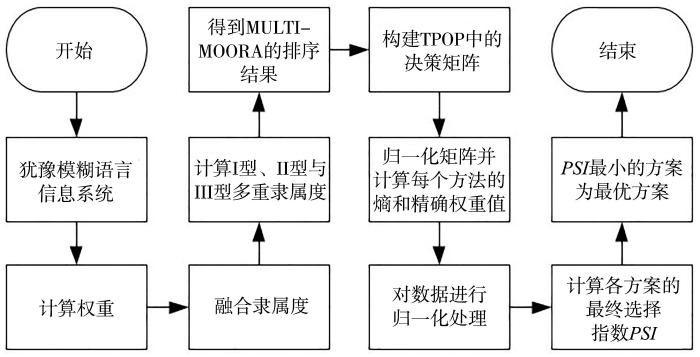
多粒度群决策是从决策信息中的多粒度特征出发,利用粒计算模型对群决策问题进行高效建模与分析的过程.现有多数多粒度群决策方法仅可提供单一的决策结果,然而不同方法带来的决策结果往往存在差异.为了深入探索犹豫模糊语言信息系统中的稳健型多粒度群决策方法,依据多粒度概率粗糙集、MULTIMOORA (Multi⁃Objective Optimization by Ratio Analysis Plus the Full Multi⁃plicative Form)和TPOP (Technique of Precise Order Preference)建立一种面向多粒度群决策的新型犹豫模糊语言多粒度计算方法.首先结合犹豫模糊语言术语集与多粒度概率粗糙集,提出犹豫模糊语言多粒度概率粗糙集模型,然后依据离差最大化法计算属性权重与决策者权重,并结合TPOP建立犹豫模糊语言稳健型多粒度群决策方法.最后,通过医学实例验证提出方法的可行性与有效性.
关键词:粒计算
;
多粒度
;
群决策
;
MULTIMOORA
;
TPOP
Abstract
From the aspect of multi⁃granularity features existed in decision⁃making information,multi⁃granularity group decision⁃making acts as a process of efficient modeling and analysis for group decision⁃making problems via granular computing models. Most of existing multi⁃granularity group decision⁃making methods only provide single decision results,however,diverse methods usually lead to diverse decision results. For the sake of deeply exploring robust multi⁃granularity group decision⁃making methods in hesitant fuzzy linguistic information systems,this paper investigates a brand⁃new hesitant fuzzy linguistic multi⁃granularity calculation method in light of multigranulation probabilistic rough sets,MULTIMOORA (Multi⁃Objective Optimization by Ratio Analysis Plus the Full Multi⁃plicative Form) and TPOP (Technique of Precise Order Preference) for multi⁃granularity group decision⁃making. First,by combining hesitant fuzzy linguistic term sets with multigranulation probabilistic rough sets,this paper puts forward hesitant fuzzy linguistic multigranulation probabilistic rough set models. Second,the weight of attributes and decision⁃makers are calculated based on the maximum deviation method,and a hesitant fuzzy linguistic robust multi⁃granularity group decision⁃making method is constructed in light of the TPOP method. Finally,the feasibility and effectiveness of the presented method are verified by a medical case analysis.
Li Xiaochuan, Zhang Chao, Li Deyu, Shangguan Xuekui, Ma Jinnan, Lu Wenrui. Hesitant fuzzy linguistic robust multi⁃granularity group decision⁃making based on the TPOP method. Journal of nanjing University[J], 2023, 59(1): 22-34 doi:10.13232/j.cnki.jnju.2023.01.003
在经典定性语言决策的信息描述中,决策者通常借助单一的语言术语来表达他们对定性信息的偏好.由于决策问题存在各类不确定性,决策者在进行决策评价时往往会在不同的语言术语间犹豫不决.鉴于此,Rodriguez et al[6]在语言术语集的基础上进一步发展了犹豫模糊语言术语集的概念,即通过纳入多个语言术语来刻画决策者犹豫不决的态度,以此来克服经典语言术语集在描述复杂决策问题时的局限.目前,学者们已发展了诸多犹豫模糊语言决策方法[6-7].
最优粒度选择是多粒度分析的热点话题,即在多粒度信息分析中,需选择一种有效的方法选出最优粒度,如集成算子、距离度量等.然而,不同方法带来的决策结果可能存在差异,因此,在做多粒度分析时需结合多种方法来提升决策结果的稳健性.Brauers and Zavadskas[14]在多类决策方法的基础上,将全乘模型引入比例分析多目标优化,提出MULTIMOORA (Multi⁃Objective Optimization by Ratio Analysis Plus the Full Multi⁃plicative Form).该方法包括比率系统、参考点理论方法和全乘比例形式,可从三类视角提供备选方案的排序结果,因而提升了排序结果的整体稳健性.然而,MULTIMOORA在排序机制上仍然存在不足.Bairagi et al[15]在MULTIMOORA的基础上建立了新型精确排序优先技术,即TPOP (Technique of Precise Order Preference),有望为应对MULTIMOORA的局限提供解决方案.鉴于此,本文在MULTIMOORA的基础上引入排序机制更全面的TPOP以获得更加精确且稳健的排序结果.近年来,已有一些学者利用TPOP对MULTIMOORA进行改进,通过获取各备选方案的精确选择指数来确定最优方案[16-17].
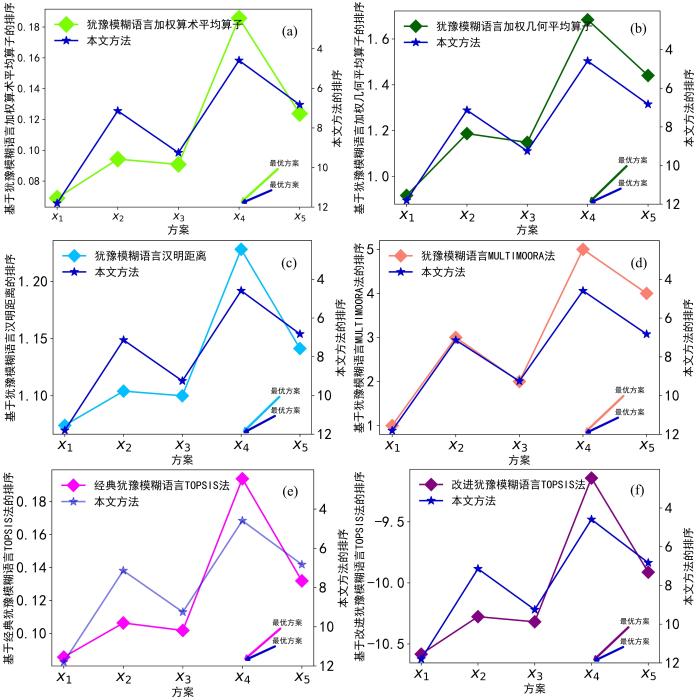
利用犹豫模糊语言加权算术平均算子、犹豫模糊语言汉明距离与犹豫模糊语言加权几何平均算子构建了三种多重隶属度来求解多粒度群决策问题,分别给出这三种决策方法的决策结果,并与本文方法的决策结果进行了对比.此外,为了进一步验证本文多粒度群决策方法的有效性,分别同经典犹豫模糊语言TOPSIS法与Hadi⁃Vencheh and Mirjaberi[29]提出的改进犹豫模糊语言TOPSIS法进行对比分析,对比结果如图2所示.
Fig.2
Comparative results of classic hesitant fuzzy linguistic group decision⁃making methods
经典犹豫模糊语言TOPSIS利用每个方案与犹豫模糊正理想解、犹豫模糊负理想解的距离构建相对贴近度,最后选择最大贴近度对应的方案为最优方案.而Hadi⁃Vencheh and Mirjaberi[29]认为TOPSIS在某些实际决策问题中,相对贴近度最大的方案并不一定能同时满足与犹豫模糊正理想解最近且离犹豫模糊负理想解最远.因此,犹豫模糊语言改进型贴进度被提出,用离正理想解最近且离负理想解最远的距离程度来进行排序,最后选择出最大犹豫模糊语言改进型贴进度对应的方案.
Multiple attribute group decision making based on multigranulation probabilistic models,MULTIMOORA and TPOP in incomplete q⁃rung orthopair fuzzy information systems
International Journal of Approximate Reasoning,2022(143):102-120.
Approaches to manage hesitant fuzzy linguistic information based on the cosine distance and similarity measures for HFLTSs and their application in qualitative decision making
Expert Systems with Applications,2015,42(12):5328-5336.
An extended fuzzy decision⁃making framework using hesitant fuzzy sets for the drug selection to treat the mild symptoms of Coronavirus Disease 2019 (COVID⁃19)
Hesitant fuzzy linguistic term sets for decision making
6
2012
... 在经典定性语言决策的信息描述中,决策者通常借助单一的语言术语来表达他们对定性信息的偏好.由于决策问题存在各类不确定性,决策者在进行决策评价时往往会在不同的语言术语间犹豫不决.鉴于此,Rodriguez et al[6]在语言术语集的基础上进一步发展了犹豫模糊语言术语集的概念,即通过纳入多个语言术语来刻画决策者犹豫不决的态度,以此来克服经典语言术语集在描述复杂决策问题时的局限.目前,学者们已发展了诸多犹豫模糊语言决策方法[6-7]. ...
... [6-7]. ...
... 定义1[6] ...
... 定义5[6] ...
... Rodriguez et al[6]在上界与下界的基础上,提出关于犹豫模糊语言元包络的概念,表示为.此后,Zhang et al[7]依据下标函数的概念构造了将犹豫模糊语言术语集转化为区间数的方法,即,并利用优势度的概念对区间数进行比较. ...
... 定义6[6] ...
Multi?granularity three?way decisions with adjustable hesitant fuzzy linguistic multigranulation decision?theoretic rough sets over two universes
4
2020
... 在经典定性语言决策的信息描述中,决策者通常借助单一的语言术语来表达他们对定性信息的偏好.由于决策问题存在各类不确定性,决策者在进行决策评价时往往会在不同的语言术语间犹豫不决.鉴于此,Rodriguez et al[6]在语言术语集的基础上进一步发展了犹豫模糊语言术语集的概念,即通过纳入多个语言术语来刻画决策者犹豫不决的态度,以此来克服经典语言术语集在描述复杂决策问题时的局限.目前,学者们已发展了诸多犹豫模糊语言决策方法[6-7]. ...
... 将上所有犹豫模糊语言关系记为.依据犹豫模糊语言关系,Zhang et al[7]提出了犹豫模糊语言背景下单一隶属度的概念. ...
... 定义4[7] ...
... Rodriguez et al[6]在上界与下界的基础上,提出关于犹豫模糊语言元包络的概念,表示为.此后,Zhang et al[7]依据下标函数的概念构造了将犹豫模糊语言术语集转化为区间数的方法,即,并利用优势度的概念对区间数进行比较. ...
The superiority of three?way decisions in probabilistic rough set models
Project management by MULTIMOORA as an instrument for transition economies
1
2010
... 最优粒度选择是多粒度分析的热点话题,即在多粒度信息分析中,需选择一种有效的方法选出最优粒度,如集成算子、距离度量等.然而,不同方法带来的决策结果可能存在差异,因此,在做多粒度分析时需结合多种方法来提升决策结果的稳健性.Brauers and Zavadskas[14]在多类决策方法的基础上,将全乘模型引入比例分析多目标优化,提出MULTIMOORA (Multi⁃Objective Optimization by Ratio Analysis Plus the Full Multi⁃plicative Form).该方法包括比率系统、参考点理论方法和全乘比例形式,可从三类视角提供备选方案的排序结果,因而提升了排序结果的整体稳健性.然而,MULTIMOORA在排序机制上仍然存在不足.Bairagi et al[15]在MULTIMOORA的基础上建立了新型精确排序优先技术,即TPOP (Technique of Precise Order Preference),有望为应对MULTIMOORA的局限提供解决方案.鉴于此,本文在MULTIMOORA的基础上引入排序机制更全面的TPOP以获得更加精确且稳健的排序结果.近年来,已有一些学者利用TPOP对MULTIMOORA进行改进,通过获取各备选方案的精确选择指数来确定最优方案[16-17]. ...
A DeNovo multi?approaches multi?criteria decision making technique with an application in performance evaluation of material handling device
2
2015
... 最优粒度选择是多粒度分析的热点话题,即在多粒度信息分析中,需选择一种有效的方法选出最优粒度,如集成算子、距离度量等.然而,不同方法带来的决策结果可能存在差异,因此,在做多粒度分析时需结合多种方法来提升决策结果的稳健性.Brauers and Zavadskas[14]在多类决策方法的基础上,将全乘模型引入比例分析多目标优化,提出MULTIMOORA (Multi⁃Objective Optimization by Ratio Analysis Plus the Full Multi⁃plicative Form).该方法包括比率系统、参考点理论方法和全乘比例形式,可从三类视角提供备选方案的排序结果,因而提升了排序结果的整体稳健性.然而,MULTIMOORA在排序机制上仍然存在不足.Bairagi et al[15]在MULTIMOORA的基础上建立了新型精确排序优先技术,即TPOP (Technique of Precise Order Preference),有望为应对MULTIMOORA的局限提供解决方案.鉴于此,本文在MULTIMOORA的基础上引入排序机制更全面的TPOP以获得更加精确且稳健的排序结果.近年来,已有一些学者利用TPOP对MULTIMOORA进行改进,通过获取各备选方案的精确选择指数来确定最优方案[16-17]. ...
Selecting project?critical path by a new interval type?2 fuzzy decision methodology based on MULTIMOORA,MOOSRA and TPOP methods
1
2018
... 最优粒度选择是多粒度分析的热点话题,即在多粒度信息分析中,需选择一种有效的方法选出最优粒度,如集成算子、距离度量等.然而,不同方法带来的决策结果可能存在差异,因此,在做多粒度分析时需结合多种方法来提升决策结果的稳健性.Brauers and Zavadskas[14]在多类决策方法的基础上,将全乘模型引入比例分析多目标优化,提出MULTIMOORA (Multi⁃Objective Optimization by Ratio Analysis Plus the Full Multi⁃plicative Form).该方法包括比率系统、参考点理论方法和全乘比例形式,可从三类视角提供备选方案的排序结果,因而提升了排序结果的整体稳健性.然而,MULTIMOORA在排序机制上仍然存在不足.Bairagi et al[15]在MULTIMOORA的基础上建立了新型精确排序优先技术,即TPOP (Technique of Precise Order Preference),有望为应对MULTIMOORA的局限提供解决方案.鉴于此,本文在MULTIMOORA的基础上引入排序机制更全面的TPOP以获得更加精确且稳健的排序结果.近年来,已有一些学者利用TPOP对MULTIMOORA进行改进,通过获取各备选方案的精确选择指数来确定最优方案[16-17]. ...
Multiple attribute group decision making based on multigranulation probabilistic models,MULTIMOORA and TPOP in incomplete q?rung orthopair fuzzy information systems
2
2022
... 最优粒度选择是多粒度分析的热点话题,即在多粒度信息分析中,需选择一种有效的方法选出最优粒度,如集成算子、距离度量等.然而,不同方法带来的决策结果可能存在差异,因此,在做多粒度分析时需结合多种方法来提升决策结果的稳健性.Brauers and Zavadskas[14]在多类决策方法的基础上,将全乘模型引入比例分析多目标优化,提出MULTIMOORA (Multi⁃Objective Optimization by Ratio Analysis Plus the Full Multi⁃plicative Form).该方法包括比率系统、参考点理论方法和全乘比例形式,可从三类视角提供备选方案的排序结果,因而提升了排序结果的整体稳健性.然而,MULTIMOORA在排序机制上仍然存在不足.Bairagi et al[15]在MULTIMOORA的基础上建立了新型精确排序优先技术,即TPOP (Technique of Precise Order Preference),有望为应对MULTIMOORA的局限提供解决方案.鉴于此,本文在MULTIMOORA的基础上引入排序机制更全面的TPOP以获得更加精确且稳健的排序结果.近年来,已有一些学者利用TPOP对MULTIMOORA进行改进,通过获取各备选方案的精确选择指数来确定最优方案[16-17]. ...
A novel risk decision making based on decision?theoretic rough sets under hesitant fuzzy information
1
2015
... 定义2[18] ...
Hesitant fuzzy linguistic rough set over two universes model and its applications
1
2018
... 定义3[19] ...
Approaches to manage hesitant fuzzy linguistic information based on the cosine distance and similarity measures for HFLTSs and their application in qualitative decision making
An extended fuzzy decision?making framework using hesitant fuzzy sets for the drug selection to treat the mild symptoms of Coronavirus Disease 2019 (COVID?19)
1
2021
... 以Mishra et al[27]的案例数据为背景进行实例分析,并给出基于TPOP的犹豫模糊语言稳健型多粒度群决策的具体步骤. ...
Ranking irregularities when evaluating alternatives by using some electre methods
1
2008
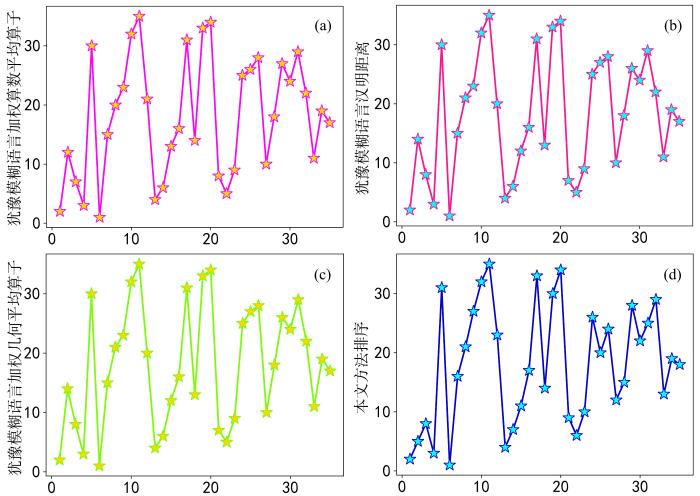
... Wang and Triantaphyllou[28]针对多粒度决策方法的正确性测试提出两类正确性测试标准,本文依据这两种测试标准来验证建立的犹豫模糊语言多粒度群决策方法的正确性. ...
Fuzzy inferior ratio method for multiple attribute decision making problems
2
2014
... 利用犹豫模糊语言加权算术平均算子、犹豫模糊语言汉明距离与犹豫模糊语言加权几何平均算子构建了三种多重隶属度来求解多粒度群决策问题,分别给出这三种决策方法的决策结果,并与本文方法的决策结果进行了对比.此外,为了进一步验证本文多粒度群决策方法的有效性,分别同经典犹豫模糊语言TOPSIS法与Hadi⁃Vencheh and Mirjaberi[29]提出的改进犹豫模糊语言TOPSIS法进行对比分析,对比结果如图2所示. ...
... 经典犹豫模糊语言TOPSIS利用每个方案与犹豫模糊正理想解、犹豫模糊负理想解的距离构建相对贴近度,最后选择最大贴近度对应的方案为最优方案.而Hadi⁃Vencheh and Mirjaberi[29]认为TOPSIS在某些实际决策问题中,相对贴近度最大的方案并不一定能同时满足与犹豫模糊正理想解最近且离犹豫模糊负理想解最远.因此,犹豫模糊语言改进型贴进度被提出,用离正理想解最近且离负理想解最远的距离程度来进行排序,最后选择出最大犹豫模糊语言改进型贴进度对应的方案. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}