Single⁃valued neutrosophic sets are effective tools to deal with uncertain and inconsistent information. Combined with single⁃valued neutrosophic rough set and multi⁃scale decision systems,this paper proposes the optimal scale selection and reduction algorithms based on multi⁃scale single⁃valued neutrosophic dominance rough set model. First,when constructing multi⁃scale dominant single⁃valued neutrosophic rough set model,we use the ideal positive point,ideal negative point and most uncertain point to describe the dominance relationship between neutrosophic numbers. Second,combining with the belief function and plausibility function in evidence theory,we examine the optimal scale selection algorithm and reduction algorithm of the presented model. Third,we utilize five groups of UCI datasets to verify the model and algorithm proposed in this paper,and analyze the effectiveness of the algorithm. The algorithm proposed in this paper improves the classification accuracy and algorithm efficiency,and furtherly expands the application of single⁃valued neutrosophic rough set in multi⁃scale decision⁃making system,which provides a reference for subsequent research in this field.
Wang Wenjue, Huang Bing. Optimal scale selection and reduction based on dominant rough set model in multi⁃scale single⁃valued neutrosophic systems. Journal of nanjing University[J], 2022, 58(3): 495-505 doi:10.13232/j.cnki.jnju.2022.03.013
针对经典粗糙集理论无法处理优势关系这一问题,1999年 et al[5]提出优势粗糙集理论(Dominance⁃based Rough Sets Approach,DRSA),DRSA弥补了经典粗糙集理论的不足并在之后的研究中得到了广泛应用.黄兵[7]及江效尧和黄兵[8]将优势关系与区间直觉模糊集结合,构建了优势区间直觉模糊粗糙集模型,并将其运用于信息系统设计风险判断.李佳等[9]利用属性重要度对优势度排序,解决并列的多属性决策排序问题.
由于一维隶属度表征的模糊信息无法解决大多数不确定性问题,因此学者们进一步提出直觉模糊集和中智集的概念.在Smarandache[10]首次提出中智集概念后,Dai et al[11]又进一步提出单值中智集的概念.此后,各国学者开始研究单值中智数的排序方法.Ye[12]对单值中智集的余弦相似度的公式进行了优化,进而比较单值中智数的大小.Huang et al[13]则结合现有的排序方法,利用相对距离有利度和相对相似度对单值中智集排序.
针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度.
尽管多尺度系统和单值中智集的研究和应用能更好地处理复杂的信息问题以及更全面地描述系统信息,但目前针对多尺度决策系统环境下的单值中智粗糙集研究并不常见.因此,本文基于Huang et al[13]的相对距离有利度构建基于优势关系的多尺度单值中智粗糙集模型,并根据模型给出最优尺度选择和最优尺度约简算法.本文提出的算法以多尺度单值中智数据为研究对象,在分类精度和时间效率上都有所提高,且进一步扩展了单值中智粗糙集在多尺度决策系统下的应用,为后续该领域的研究提供参考.
Zhang et al[27]将属性约简看成特殊的尺度选择,当时表示属性约简和最优尺度选择是同时进行的,则表示只进行最优尺度选择,并通过哈斯图计算边界域的极大元来优化算法.其算法的主要思想是令某属性的粒度为0,固定其他属性不变,逐渐增加属性粒度直至系统协调,最后重复操作得到最优尺度约简.该算法本质上通过减少检查系统协调性次数来提高算法效率,本节将讨论多尺度优势单值中智粗糙集模型尺度约简算法.
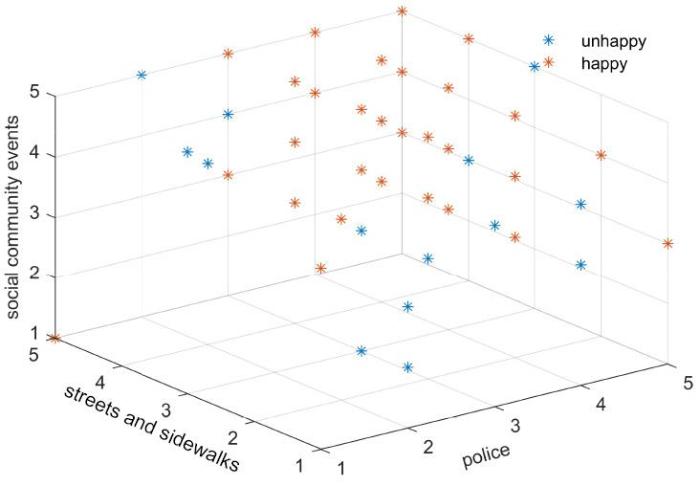
首先需对Somerville Happiness Survey数据集完成多尺度决策系统与单值中智粗糙集的构建,在构建多尺度决策系统时依据Hao et al[28]提出的方法,即利用属性值所属不同的区间值划分尺度较粗的评价标准,并利用区间的合并再一步划分尺度更粗的评价标准.本节实验划分区间值时将作为4值区间,为属性值的最大值减去最小值之后的属性值跨度,并通过将4值区间进一步合并为2值区间构建下一个层级的尺度系统,最后得到多尺度系统.本实验中将条件属性的尺度设定为,如表3所示.在构建单值中智粗糙集时将各属性值与该属性列的最大值、平均值、最小值之间的欧式距离作为标准来确定肯定度、犹豫度和否定度,然后将归一化处理后的距离与1相减得到的绝对值作为数据集中该属性的肯定度、犹豫度和否定度,并以定义2中的相对距离有利度作为评价单值中智数优劣关系的标准,得到各样本的优势类.
... 针对经典粗糙集理论无法处理优势关系这一问题,1999年 et al[5]提出优势粗糙集理论(Dominance⁃based Rough Sets Approach,DRSA),DRSA弥补了经典粗糙集理论的不足并在之后的研究中得到了广泛应用.黄兵[7]及江效尧和黄兵[8]将优势关系与区间直觉模糊集结合,构建了优势区间直觉模糊粗糙集模型,并将其运用于信息系统设计风险判断.李佳等[9]利用属性重要度对优势度排序,解决并列的多属性决策排序问题. ...
Dominance interval?valued intuitionistic fuzzy?rough set model and its application
1
2012
... 针对经典粗糙集理论无法处理优势关系这一问题,1999年 et al[5]提出优势粗糙集理论(Dominance⁃based Rough Sets Approach,DRSA),DRSA弥补了经典粗糙集理论的不足并在之后的研究中得到了广泛应用.黄兵[7]及江效尧和黄兵[8]将优势关系与区间直觉模糊集结合,构建了优势区间直觉模糊粗糙集模型,并将其运用于信息系统设计风险判断.李佳等[9]利用属性重要度对优势度排序,解决并列的多属性决策排序问题. ...
优势模糊区间目标粗糙集模型的群决策规则获取及应用
1
2012
... 针对经典粗糙集理论无法处理优势关系这一问题,1999年 et al[5]提出优势粗糙集理论(Dominance⁃based Rough Sets Approach,DRSA),DRSA弥补了经典粗糙集理论的不足并在之后的研究中得到了广泛应用.黄兵[7]及江效尧和黄兵[8]将优势关系与区间直觉模糊集结合,构建了优势区间直觉模糊粗糙集模型,并将其运用于信息系统设计风险判断.李佳等[9]利用属性重要度对优势度排序,解决并列的多属性决策排序问题. ...
Rules acquisition of group decision?making based on dominance and fuzzy interval objective rough set model and its application
1
2012
... 针对经典粗糙集理论无法处理优势关系这一问题,1999年 et al[5]提出优势粗糙集理论(Dominance⁃based Rough Sets Approach,DRSA),DRSA弥补了经典粗糙集理论的不足并在之后的研究中得到了广泛应用.黄兵[7]及江效尧和黄兵[8]将优势关系与区间直觉模糊集结合,构建了优势区间直觉模糊粗糙集模型,并将其运用于信息系统设计风险判断.李佳等[9]利用属性重要度对优势度排序,解决并列的多属性决策排序问题. ...
一种基于优势粗糙集的多属性决策排序方法
1
2016
... 针对经典粗糙集理论无法处理优势关系这一问题,1999年 et al[5]提出优势粗糙集理论(Dominance⁃based Rough Sets Approach,DRSA),DRSA弥补了经典粗糙集理论的不足并在之后的研究中得到了广泛应用.黄兵[7]及江效尧和黄兵[8]将优势关系与区间直觉模糊集结合,构建了优势区间直觉模糊粗糙集模型,并将其运用于信息系统设计风险判断.李佳等[9]利用属性重要度对优势度排序,解决并列的多属性决策排序问题. ...
A sorting method of multi?attribute decision making based on dominance rough set theory
1
2016
... 针对经典粗糙集理论无法处理优势关系这一问题,1999年 et al[5]提出优势粗糙集理论(Dominance⁃based Rough Sets Approach,DRSA),DRSA弥补了经典粗糙集理论的不足并在之后的研究中得到了广泛应用.黄兵[7]及江效尧和黄兵[8]将优势关系与区间直觉模糊集结合,构建了优势区间直觉模糊粗糙集模型,并将其运用于信息系统设计风险判断.李佳等[9]利用属性重要度对优势度排序,解决并列的多属性决策排序问题. ...
A unifying field in logics:Neutrosophic logic
1
1999
... 由于一维隶属度表征的模糊信息无法解决大多数不确定性问题,因此学者们进一步提出直觉模糊集和中智集的概念.在Smarandache[10]首次提出中智集概念后,Dai et al[11]又进一步提出单值中智集的概念.此后,各国学者开始研究单值中智数的排序方法.Ye[12]对单值中智集的余弦相似度的公式进行了优化,进而比较单值中智数的大小.Huang et al[13]则结合现有的排序方法,利用相对距离有利度和相对相似度对单值中智集排序. ...
Perturbation of fuzzy sets and fuzzy reasoning based on normalized Minkowski distances
1
2011
... 由于一维隶属度表征的模糊信息无法解决大多数不确定性问题,因此学者们进一步提出直觉模糊集和中智集的概念.在Smarandache[10]首次提出中智集概念后,Dai et al[11]又进一步提出单值中智集的概念.此后,各国学者开始研究单值中智数的排序方法.Ye[12]对单值中智集的余弦相似度的公式进行了优化,进而比较单值中智数的大小.Huang et al[13]则结合现有的排序方法,利用相对距离有利度和相对相似度对单值中智集排序. ...
Improved cosine similarity measures of simplified neutrosophic sets for medical diagnoses
1
2015
... 由于一维隶属度表征的模糊信息无法解决大多数不确定性问题,因此学者们进一步提出直觉模糊集和中智集的概念.在Smarandache[10]首次提出中智集概念后,Dai et al[11]又进一步提出单值中智集的概念.此后,各国学者开始研究单值中智数的排序方法.Ye[12]对单值中智集的余弦相似度的公式进行了优化,进而比较单值中智数的大小.Huang et al[13]则结合现有的排序方法,利用相对距离有利度和相对相似度对单值中智集排序. ...
Relative measure?based approaches for ranking single?valued neutrosophic values and their applications
4
2021
... 由于一维隶属度表征的模糊信息无法解决大多数不确定性问题,因此学者们进一步提出直觉模糊集和中智集的概念.在Smarandache[10]首次提出中智集概念后,Dai et al[11]又进一步提出单值中智集的概念.此后,各国学者开始研究单值中智数的排序方法.Ye[12]对单值中智集的余弦相似度的公式进行了优化,进而比较单值中智数的大小.Huang et al[13]则结合现有的排序方法,利用相对距离有利度和相对相似度对单值中智集排序. ...
... 尽管多尺度系统和单值中智集的研究和应用能更好地处理复杂的信息问题以及更全面地描述系统信息,但目前针对多尺度决策系统环境下的单值中智粗糙集研究并不常见.因此,本文基于Huang et al[13]的相对距离有利度构建基于优势关系的多尺度单值中智粗糙集模型,并根据模型给出最优尺度选择和最优尺度约简算法.本文提出的算法以多尺度单值中智数据为研究对象,在分类精度和时间效率上都有所提高,且进一步扩展了单值中智粗糙集在多尺度决策系统下的应用,为后续该领域的研究提供参考. ...
... 在对给定的两个单值中智数比较大小时,Huang et al[13]提出将单值中智数与理想正点、理想负点、最不确定点之间的欧式距离作为单值中智数大小关系判定的依据. ...
... 定义2[13] ...
Theory and applications of granular labelled partitions in multi?scale decision tables
2
2011
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
... 定义3[14] ...
A new approach of optimal scale selection to multi?scale decision tables
2
2017
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
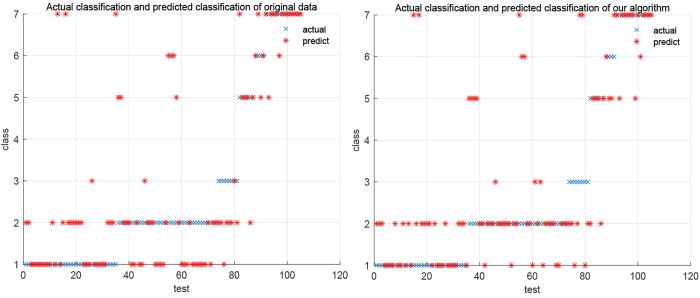
... 最后,将本文算法与Li and Hu[15]的算法进行对比,其结果如表4所示.显然,本文的算法在运行时间上有很大的优势,在处理条件属性较多的数据集时优势更明显. ...
广义不完备多粒度标记决策系统的粒度选择
1
2018
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
Granularity selections in generalized incomplete multi?granular labeled decision systems
1
2018
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
不协调广义多尺度决策系统的尺度组合
0
2018
Scale combinations in inconsistent generalized multi?scale decision systems
0
2018
不协调广义多尺度决策系统的局部最优尺度组合选择
1
2021
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
Local optimal scale combination selections in inconsistent generalized multi?scale decision systems
1
2021
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
多尺度集值决策信息系统
1
2021
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
Multi?scale set valued decision information system
1
2021
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
多尺度覆盖决策信息系统的布尔矩阵方法
1
2020
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
Boolean matrix approach for multi?scale covering decision information system
1
2020
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
基于熵的多尺度决策系统的最优尺度选择
1
2021
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
Entropy based optimal scale selection for multi?scale decision systems
1
2021
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
多尺度决策系统中代价敏感的最优尺度组合
1
2021
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
Cost?sensitive optimal scale combination in multi?scale decision systems
1
2021
... 针对单一尺度分析的信息系统不能解决复杂的信息处理问题,Wu and Leung[14]提出多尺度信息系统概念,并由Li and Hu[15]进一步改进.在多尺度信息系统中,最优尺度选择一直都是研究的核心问题.例如,吴伟志等[16-18]利用证据理论中的似然函数和信任函数对最优尺度组合进行刻画;陈应生等[19-20]利用矩阵对尺度组合进行刻画;郑嘉文等[21]利用熵定义最优尺度,最后提出了基于熵的最优尺度选择;张清华等[22]从尺度代价和属性代价这两个不同的角度来刻画,并将尺度与属性代价结合,从而建立基于代价敏感的多尺度决策系统来选择最优尺度. ...
基于包含度的单值中智决策信息系统属性约简
1
2020
... 定义1[23] ...
Attributes reduction of single valued neutrosophic decision information system based on inclusion degree
1
2020
... 定义1[23] ...
Inclusion measure?based multi?granulation decision?theoretic rough sets in multi?scale intuitionistic fuzzy information tables
2
2020
... 定义4[24-25] ...
... 定义5[24-25] ...
Double?quantitative rough sets,optimal scale selection and reduction in multi?scale dominance IF decision tables
Optimal scale combination selection integrating three?way decision with Hasse diagram
1
... Zhang et al[27]将属性约简看成特殊的尺度选择,当时表示属性约简和最优尺度选择是同时进行的,则表示只进行最优尺度选择,并通过哈斯图计算边界域的极大元来优化算法.其算法的主要思想是令某属性的粒度为0,固定其他属性不变,逐渐增加属性粒度直至系统协调,最后重复操作得到最优尺度约简.该算法本质上通过减少检查系统协调性次数来提高算法效率,本节将讨论多尺度优势单值中智粗糙集模型尺度约简算法. ...
Optimal scale selection in dynamic multi?scale decision tables based on sequential three?way decisions
1
2017
... 首先需对Somerville Happiness Survey数据集完成多尺度决策系统与单值中智粗糙集的构建,在构建多尺度决策系统时依据Hao et al[28]提出的方法,即利用属性值所属不同的区间值划分尺度较粗的评价标准,并利用区间的合并再一步划分尺度更粗的评价标准.本节实验划分区间值时将作为4值区间,为属性值的最大值减去最小值之后的属性值跨度,并通过将4值区间进一步合并为2值区间构建下一个层级的尺度系统,最后得到多尺度系统.本实验中将条件属性的尺度设定为,如表3所示.在构建单值中智粗糙集时将各属性值与该属性列的最大值、平均值、最小值之间的欧式距离作为标准来确定肯定度、犹豫度和否定度,然后将归一化处理后的距离与1相减得到的绝对值作为数据集中该属性的肯定度、犹豫度和否定度,并以定义2中的相对距离有利度作为评价单值中智数优劣关系的标准,得到各样本的优势类. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}