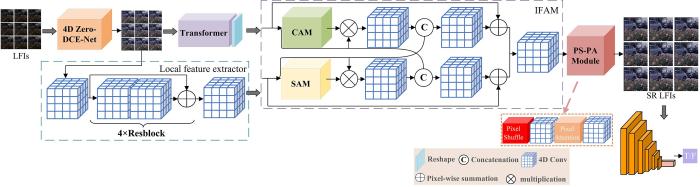
The limited spatial resolution of sensor of light field camera hinders the progress of light field image processing related research. This paper proposes a spatial super⁃resolution algorithm for light field images by integrating global and local features,which improves the ability of modeling the global relationship between light field sub⁃views. Since brightness of captured light field images is low and seriously affects the quality of the super⁃resolution image,this paper proposes an improved 4D Zero⁃DCE⁃Net to make full use of all sub⁃views of a light field to enlighten light field images. In order to solve the problem of low spatial resolution of light field images,we propose a spatial super⁃resolution network model of light field images based on generative adversarial network. The generator consists of three parts. The first part is a network structure that combines Transformer and 4D convolution in a parallel manner. It captures global and local details of the images with a shallower network layer. The second part proposes an interactive fusion attention module (IFAM) to effectively fuse the global self⁃attention and local detail information from the above two branches. The third part is a reconstruction module (PS⁃PA) to improve the spatial resolution of the entire light field. Finally,the relative discriminator is used to guide the training of the generator. Extensive experimental results show that our proposed method improves the PSNR (Peak Signal to Noise Ratio) performance index by at least 1 dB than other methods.
Keywords:light field image
;
super resolution
;
Transformer
;
4D convolution
Jing Huahua, Yan Tao, Liu Yuan. A spatial super⁃resolution method for light filed images by fusing global and local features. Journal of nanjing University[J], 2022, 58(2): 298-308 doi:10.13232/j.cnki.jnju.2022.02.013
通常使用两平面参数化来表示4D光场,即,表示空间平面,表示角度平面.近年来,研究者们已经提出多个传统的光场图像超分辨率算法,对视点之间的关系进行物理建模,将超分辨率视作优化问题.Wanner and Goldluecke[10-11]在EPI (Epipolar Plane Image)上使用结构张量来估计视差图,该视差图可用在变体框架中实现空间和角度超分辨率.Mitra and Veeraraghavan[12]提出一个通用框架,使用以视差值为条件的高斯混合模型对光场进行建模.Cho et al[13]提出一种基于稀疏编码的框架来训练低分辨率和高分辨率光场图像对的字典来提高算法的性能.
由于光场数据的高维特征,上述传统超分辨率算法的效果非常有限.随着深度神经网络研究的快速发展和成功,涌现了一些基于深度学习的算法来解决光场空间超分辨率的问题,它们主要利用多视点冗余性以及视点之间的补充信息来学习从低分辨率到高分辨率的映射关系.Rossi and Frossard[14]提出一个基于图的正则化器来增强光场的几何结构,从而提高光场全部视点的分辨率.Yoon et al[15-16]首次提出使用CNN(Convolutional Neural Networks)处理光场数据,同时实现角度和空间超分辨率.Wang et al[17]提出一个双向循环卷积神经网络,分别对水平和垂直两个方向上相邻子视点的空间相关性进行建模,然后利用堆栈泛化技术将两者集成起来获得高分辨率光场图像.Zhang et al[18]提出一个残差网络来实现光场图像的超分辨率,将四个不同方向的视点堆叠起来进入网络的四个分支提取特征,并将四个分支的残差信息融合在一起得到重建结果.Yeung et al[19]提出一种空间角度可分离的卷积模块,可以更高效地提取空间和角度的特征,进而更好地恢复光场图像的细节信息.Meng et al[20]提出一种高维密集残差卷积神经网络来重建光场,将光场的所有子视点作为输入,并使用4D卷积获取视点之间的关系.Wang et al[21]提出一个空间角度交互网络实现光场图像的超分辨率,首先从宏像素图像中提取角度和空间特征,然后通过交互模块实现空间⁃角度的信息交互,最后利用光场重塑得到高分辨率图像.Jin et al[22]提出一种All⁃to⁃One模块,通过当前视点与参考视点的组合相关性充分利用光场视点之间的补充信息,并使用结构一致性正则化模块来恢复光场的几何结构.
本文在光场超分辨率之前首先对图像进行亮度增强.由于光场相机捕捉的图像亮度较低,造成光场分解得到的子视点图像因存在较多噪声/坏点等导致图像失真的问题,影响了超分辨率图像的质量.真实场景的光场图像没有真值,无法用有监督的方法训练网络.Guo et al[23]提出零参考深度曲线估计网络(Zero⁃DCE⁃Net),增强了单张图像的亮度,效果比较好,但由于光场子视点从边缘到中心的亮度范围不同,边缘子视点会偏暗.因此,本文在Zero⁃DCE⁃Net的基础上将2D卷积改成4D卷积,提出改进的4D Zero⁃DCE⁃Net,利用各子视点之间亮度信息(光场的几何结构信息)来提高整个光场图像的亮度.
本文将光场的全部视点输入Transformer[25]中提取全局特征,这与传统的Transformer不同.传统的Transformer只对单张图像进行注意力操作,而Bertasius et al[25]的Transformer可以对多张图像进行注意力操作,它通过对不同视点相同位置的图像块进行注意力操作,再对同一视点不同位置的图像块进行空间注意力操作来提取光场全部子视点的信息.如图2所示,同时取多个视点同一位置的图像块(如图中左上角红色框位置)进行注意力操作,无红色框的图像块表示没有进行注意力操作.
使用PyTorch框架在Titan X GPU上进行网络训练,采用Adam优化器更新参数,学习率设置为2E-4,训练和测试的批量大小分别取2和1,训练次数epoch设为500,和分别设为0.04和0.01.不同和实验结果的峰值信号比(Peak Signal to Noise Ratio,PSNR)与结构相似性(Structural Similarity,SSIM)的平均值如表1所示,表中黑体字是最优结果.由表可见,本文拟定的深度神经网络参数可以使实验结果达到一个理想的指标.
Table 1
表1
表1不同超参数的PSNR与SSIM平均值
Table 1 Average value of PSNR and SSIM under different hyperparameters
Fig.3
Brightness enhancement results of light field images
2.4 图像超分辨率结果定量分析 将本文算法与基于优化的超分辨率算法[13]以及基于深度学习的算法[21-22,27-28]进行定量分析对比,其中Dai et al[27],Jo et al[28]分别是单张图像和视频图像的超分辨率算法.为了实验的公平性,所有算法都在我们的训练数据集上训练,在7×7光场的中心子视点上采用PSNR,SSIM,PI (Perceptual
Fig.9
Super⁃resolution results of light field images (Scene 6)
2.5 图像超分辨率结果定性分析
如图4、图5和图6所示,第一行从左到右依次是插值、Dai et al[27]、Jo et al[28]和Rossi and Frossard[14]的实验结果,第二行从左到右依次是Jin et al[22]、Wang et al[21]、本文算法的结果和真值(GT).由图可见,Wang et al[21]和Jin et al[22]的算法表现良好,Dai et al[27]和Jo et al[28]的算法在某些场景的结果也不错,但在纹理区域上还有一定程度的模糊,而本文算法的结果更加锐利,在一些复杂的场景的优势更明显.由图4可见,Wang et al[21]的算法表现优于前面几个算法,但也没本文算法的结果锐利.
本文还在自己采集的数据集上进行了定性分析,结果是本文算法的结果明显优于其他算法.如图7和图8所示,本文算法在文字的细节恢复方面明显好于其他算法.图9的结果也远胜其他算法.同时可以看出,Rossi and Frossard[14]和Wang et al[21]的算法在重建过程中损失了很多高频细节信息.更多的实验结果请参考https:∥github.com/jhh1996/LFSR/tree/main/experiment.
Spatial and angular variational super?resolution of 4D light fields
1
2012
... 通常使用两平面参数化来表示4D光场,即,表示空间平面,表示角度平面.近年来,研究者们已经提出多个传统的光场图像超分辨率算法,对视点之间的关系进行物理建模,将超分辨率视作优化问题.Wanner and Goldluecke[10-11]在EPI (Epipolar Plane Image)上使用结构张量来估计视差图,该视差图可用在变体框架中实现空间和角度超分辨率.Mitra and Veeraraghavan[12]提出一个通用框架,使用以视差值为条件的高斯混合模型对光场进行建模.Cho et al[13]提出一种基于稀疏编码的框架来训练低分辨率和高分辨率光场图像对的字典来提高算法的性能. ...
Variational light field analysis for disparity estimation and super?resolution
1
2014
... 通常使用两平面参数化来表示4D光场,即,表示空间平面,表示角度平面.近年来,研究者们已经提出多个传统的光场图像超分辨率算法,对视点之间的关系进行物理建模,将超分辨率视作优化问题.Wanner and Goldluecke[10-11]在EPI (Epipolar Plane Image)上使用结构张量来估计视差图,该视差图可用在变体框架中实现空间和角度超分辨率.Mitra and Veeraraghavan[12]提出一个通用框架,使用以视差值为条件的高斯混合模型对光场进行建模.Cho et al[13]提出一种基于稀疏编码的框架来训练低分辨率和高分辨率光场图像对的字典来提高算法的性能. ...
Light field denoising,light field superresolution and stereo camera based refocussing using a GMM light field patch prior
1
2012
... 通常使用两平面参数化来表示4D光场,即,表示空间平面,表示角度平面.近年来,研究者们已经提出多个传统的光场图像超分辨率算法,对视点之间的关系进行物理建模,将超分辨率视作优化问题.Wanner and Goldluecke[10-11]在EPI (Epipolar Plane Image)上使用结构张量来估计视差图,该视差图可用在变体框架中实现空间和角度超分辨率.Mitra and Veeraraghavan[12]提出一个通用框架,使用以视差值为条件的高斯混合模型对光场进行建模.Cho et al[13]提出一种基于稀疏编码的框架来训练低分辨率和高分辨率光场图像对的字典来提高算法的性能. ...
Modeling the calibration pipeline of the Lytro camera for high quality light?field image reconstruction
3
2013
... 通常使用两平面参数化来表示4D光场,即,表示空间平面,表示角度平面.近年来,研究者们已经提出多个传统的光场图像超分辨率算法,对视点之间的关系进行物理建模,将超分辨率视作优化问题.Wanner and Goldluecke[10-11]在EPI (Epipolar Plane Image)上使用结构张量来估计视差图,该视差图可用在变体框架中实现空间和角度超分辨率.Mitra and Veeraraghavan[12]提出一个通用框架,使用以视差值为条件的高斯混合模型对光场进行建模.Cho et al[13]提出一种基于稀疏编码的框架来训练低分辨率和高分辨率光场图像对的字典来提高算法的性能. ...
... 2.4 图像超分辨率结果定量分析 将本文算法与基于优化的超分辨率算法[13]以及基于深度学习的算法[21-22,27-28]进行定量分析对比,其中Dai et al[27],Jo et al[28]分别是单张图像和视频图像的超分辨率算法.为了实验的公平性,所有算法都在我们的训练数据集上训练,在7×7光场的中心子视点上采用PSNR,SSIM,PI (Perceptual ...
... Quantitative comparison results of light field super⁃resolution(40 arrays of test data)Table 3
Geometry?consistent light field super?resolution via graph?based regularization
3
2018
... 由于光场数据的高维特征,上述传统超分辨率算法的效果非常有限.随着深度神经网络研究的快速发展和成功,涌现了一些基于深度学习的算法来解决光场空间超分辨率的问题,它们主要利用多视点冗余性以及视点之间的补充信息来学习从低分辨率到高分辨率的映射关系.Rossi and Frossard[14]提出一个基于图的正则化器来增强光场的几何结构,从而提高光场全部视点的分辨率.Yoon et al[15-16]首次提出使用CNN(Convolutional Neural Networks)处理光场数据,同时实现角度和空间超分辨率.Wang et al[17]提出一个双向循环卷积神经网络,分别对水平和垂直两个方向上相邻子视点的空间相关性进行建模,然后利用堆栈泛化技术将两者集成起来获得高分辨率光场图像.Zhang et al[18]提出一个残差网络来实现光场图像的超分辨率,将四个不同方向的视点堆叠起来进入网络的四个分支提取特征,并将四个分支的残差信息融合在一起得到重建结果.Yeung et al[19]提出一种空间角度可分离的卷积模块,可以更高效地提取空间和角度的特征,进而更好地恢复光场图像的细节信息.Meng et al[20]提出一种高维密集残差卷积神经网络来重建光场,将光场的所有子视点作为输入,并使用4D卷积获取视点之间的关系.Wang et al[21]提出一个空间角度交互网络实现光场图像的超分辨率,首先从宏像素图像中提取角度和空间特征,然后通过交互模块实现空间⁃角度的信息交互,最后利用光场重塑得到高分辨率图像.Jin et al[22]提出一种All⁃to⁃One模块,通过当前视点与参考视点的组合相关性充分利用光场视点之间的补充信息,并使用结构一致性正则化模块来恢复光场的几何结构. ...
... 如图4、图5和图6所示,第一行从左到右依次是插值、Dai et al[27]、Jo et al[28]和Rossi and Frossard[14]的实验结果,第二行从左到右依次是Jin et al[22]、Wang et al[21]、本文算法的结果和真值(GT).由图可见,Wang et al[21]和Jin et al[22]的算法表现良好,Dai et al[27]和Jo et al[28]的算法在某些场景的结果也不错,但在纹理区域上还有一定程度的模糊,而本文算法的结果更加锐利,在一些复杂的场景的优势更明显.由图4可见,Wang et al[21]的算法表现优于前面几个算法,但也没本文算法的结果锐利. ...
... 本文还在自己采集的数据集上进行了定性分析,结果是本文算法的结果明显优于其他算法.如图7和图8所示,本文算法在文字的细节恢复方面明显好于其他算法.图9的结果也远胜其他算法.同时可以看出,Rossi and Frossard[14]和Wang et al[21]的算法在重建过程中损失了很多高频细节信息.更多的实验结果请参考https:∥github.com/jhh1996/LFSR/tree/main/experiment. ...
Learning a deep convolutional network for light?field image super?resolution
1
2015
... 由于光场数据的高维特征,上述传统超分辨率算法的效果非常有限.随着深度神经网络研究的快速发展和成功,涌现了一些基于深度学习的算法来解决光场空间超分辨率的问题,它们主要利用多视点冗余性以及视点之间的补充信息来学习从低分辨率到高分辨率的映射关系.Rossi and Frossard[14]提出一个基于图的正则化器来增强光场的几何结构,从而提高光场全部视点的分辨率.Yoon et al[15-16]首次提出使用CNN(Convolutional Neural Networks)处理光场数据,同时实现角度和空间超分辨率.Wang et al[17]提出一个双向循环卷积神经网络,分别对水平和垂直两个方向上相邻子视点的空间相关性进行建模,然后利用堆栈泛化技术将两者集成起来获得高分辨率光场图像.Zhang et al[18]提出一个残差网络来实现光场图像的超分辨率,将四个不同方向的视点堆叠起来进入网络的四个分支提取特征,并将四个分支的残差信息融合在一起得到重建结果.Yeung et al[19]提出一种空间角度可分离的卷积模块,可以更高效地提取空间和角度的特征,进而更好地恢复光场图像的细节信息.Meng et al[20]提出一种高维密集残差卷积神经网络来重建光场,将光场的所有子视点作为输入,并使用4D卷积获取视点之间的关系.Wang et al[21]提出一个空间角度交互网络实现光场图像的超分辨率,首先从宏像素图像中提取角度和空间特征,然后通过交互模块实现空间⁃角度的信息交互,最后利用光场重塑得到高分辨率图像.Jin et al[22]提出一种All⁃to⁃One模块,通过当前视点与参考视点的组合相关性充分利用光场视点之间的补充信息,并使用结构一致性正则化模块来恢复光场的几何结构. ...
Light?field image super?resolution using convolutional neural network
1
2017
... 由于光场数据的高维特征,上述传统超分辨率算法的效果非常有限.随着深度神经网络研究的快速发展和成功,涌现了一些基于深度学习的算法来解决光场空间超分辨率的问题,它们主要利用多视点冗余性以及视点之间的补充信息来学习从低分辨率到高分辨率的映射关系.Rossi and Frossard[14]提出一个基于图的正则化器来增强光场的几何结构,从而提高光场全部视点的分辨率.Yoon et al[15-16]首次提出使用CNN(Convolutional Neural Networks)处理光场数据,同时实现角度和空间超分辨率.Wang et al[17]提出一个双向循环卷积神经网络,分别对水平和垂直两个方向上相邻子视点的空间相关性进行建模,然后利用堆栈泛化技术将两者集成起来获得高分辨率光场图像.Zhang et al[18]提出一个残差网络来实现光场图像的超分辨率,将四个不同方向的视点堆叠起来进入网络的四个分支提取特征,并将四个分支的残差信息融合在一起得到重建结果.Yeung et al[19]提出一种空间角度可分离的卷积模块,可以更高效地提取空间和角度的特征,进而更好地恢复光场图像的细节信息.Meng et al[20]提出一种高维密集残差卷积神经网络来重建光场,将光场的所有子视点作为输入,并使用4D卷积获取视点之间的关系.Wang et al[21]提出一个空间角度交互网络实现光场图像的超分辨率,首先从宏像素图像中提取角度和空间特征,然后通过交互模块实现空间⁃角度的信息交互,最后利用光场重塑得到高分辨率图像.Jin et al[22]提出一种All⁃to⁃One模块,通过当前视点与参考视点的组合相关性充分利用光场视点之间的补充信息,并使用结构一致性正则化模块来恢复光场的几何结构. ...
... 由于光场数据的高维特征,上述传统超分辨率算法的效果非常有限.随着深度神经网络研究的快速发展和成功,涌现了一些基于深度学习的算法来解决光场空间超分辨率的问题,它们主要利用多视点冗余性以及视点之间的补充信息来学习从低分辨率到高分辨率的映射关系.Rossi and Frossard[14]提出一个基于图的正则化器来增强光场的几何结构,从而提高光场全部视点的分辨率.Yoon et al[15-16]首次提出使用CNN(Convolutional Neural Networks)处理光场数据,同时实现角度和空间超分辨率.Wang et al[17]提出一个双向循环卷积神经网络,分别对水平和垂直两个方向上相邻子视点的空间相关性进行建模,然后利用堆栈泛化技术将两者集成起来获得高分辨率光场图像.Zhang et al[18]提出一个残差网络来实现光场图像的超分辨率,将四个不同方向的视点堆叠起来进入网络的四个分支提取特征,并将四个分支的残差信息融合在一起得到重建结果.Yeung et al[19]提出一种空间角度可分离的卷积模块,可以更高效地提取空间和角度的特征,进而更好地恢复光场图像的细节信息.Meng et al[20]提出一种高维密集残差卷积神经网络来重建光场,将光场的所有子视点作为输入,并使用4D卷积获取视点之间的关系.Wang et al[21]提出一个空间角度交互网络实现光场图像的超分辨率,首先从宏像素图像中提取角度和空间特征,然后通过交互模块实现空间⁃角度的信息交互,最后利用光场重塑得到高分辨率图像.Jin et al[22]提出一种All⁃to⁃One模块,通过当前视点与参考视点的组合相关性充分利用光场视点之间的补充信息,并使用结构一致性正则化模块来恢复光场的几何结构. ...
Residual networks for light field image super?resolution
1
2019
... 由于光场数据的高维特征,上述传统超分辨率算法的效果非常有限.随着深度神经网络研究的快速发展和成功,涌现了一些基于深度学习的算法来解决光场空间超分辨率的问题,它们主要利用多视点冗余性以及视点之间的补充信息来学习从低分辨率到高分辨率的映射关系.Rossi and Frossard[14]提出一个基于图的正则化器来增强光场的几何结构,从而提高光场全部视点的分辨率.Yoon et al[15-16]首次提出使用CNN(Convolutional Neural Networks)处理光场数据,同时实现角度和空间超分辨率.Wang et al[17]提出一个双向循环卷积神经网络,分别对水平和垂直两个方向上相邻子视点的空间相关性进行建模,然后利用堆栈泛化技术将两者集成起来获得高分辨率光场图像.Zhang et al[18]提出一个残差网络来实现光场图像的超分辨率,将四个不同方向的视点堆叠起来进入网络的四个分支提取特征,并将四个分支的残差信息融合在一起得到重建结果.Yeung et al[19]提出一种空间角度可分离的卷积模块,可以更高效地提取空间和角度的特征,进而更好地恢复光场图像的细节信息.Meng et al[20]提出一种高维密集残差卷积神经网络来重建光场,将光场的所有子视点作为输入,并使用4D卷积获取视点之间的关系.Wang et al[21]提出一个空间角度交互网络实现光场图像的超分辨率,首先从宏像素图像中提取角度和空间特征,然后通过交互模块实现空间⁃角度的信息交互,最后利用光场重塑得到高分辨率图像.Jin et al[22]提出一种All⁃to⁃One模块,通过当前视点与参考视点的组合相关性充分利用光场视点之间的补充信息,并使用结构一致性正则化模块来恢复光场的几何结构. ...
Light field spatial super?resolution using deep efficient spatial?angular separable convolution
1
2019
... 由于光场数据的高维特征,上述传统超分辨率算法的效果非常有限.随着深度神经网络研究的快速发展和成功,涌现了一些基于深度学习的算法来解决光场空间超分辨率的问题,它们主要利用多视点冗余性以及视点之间的补充信息来学习从低分辨率到高分辨率的映射关系.Rossi and Frossard[14]提出一个基于图的正则化器来增强光场的几何结构,从而提高光场全部视点的分辨率.Yoon et al[15-16]首次提出使用CNN(Convolutional Neural Networks)处理光场数据,同时实现角度和空间超分辨率.Wang et al[17]提出一个双向循环卷积神经网络,分别对水平和垂直两个方向上相邻子视点的空间相关性进行建模,然后利用堆栈泛化技术将两者集成起来获得高分辨率光场图像.Zhang et al[18]提出一个残差网络来实现光场图像的超分辨率,将四个不同方向的视点堆叠起来进入网络的四个分支提取特征,并将四个分支的残差信息融合在一起得到重建结果.Yeung et al[19]提出一种空间角度可分离的卷积模块,可以更高效地提取空间和角度的特征,进而更好地恢复光场图像的细节信息.Meng et al[20]提出一种高维密集残差卷积神经网络来重建光场,将光场的所有子视点作为输入,并使用4D卷积获取视点之间的关系.Wang et al[21]提出一个空间角度交互网络实现光场图像的超分辨率,首先从宏像素图像中提取角度和空间特征,然后通过交互模块实现空间⁃角度的信息交互,最后利用光场重塑得到高分辨率图像.Jin et al[22]提出一种All⁃to⁃One模块,通过当前视点与参考视点的组合相关性充分利用光场视点之间的补充信息,并使用结构一致性正则化模块来恢复光场的几何结构. ...
High?dimensional dense residual convolutional neural network for light field reconstruction
1
2021
... 由于光场数据的高维特征,上述传统超分辨率算法的效果非常有限.随着深度神经网络研究的快速发展和成功,涌现了一些基于深度学习的算法来解决光场空间超分辨率的问题,它们主要利用多视点冗余性以及视点之间的补充信息来学习从低分辨率到高分辨率的映射关系.Rossi and Frossard[14]提出一个基于图的正则化器来增强光场的几何结构,从而提高光场全部视点的分辨率.Yoon et al[15-16]首次提出使用CNN(Convolutional Neural Networks)处理光场数据,同时实现角度和空间超分辨率.Wang et al[17]提出一个双向循环卷积神经网络,分别对水平和垂直两个方向上相邻子视点的空间相关性进行建模,然后利用堆栈泛化技术将两者集成起来获得高分辨率光场图像.Zhang et al[18]提出一个残差网络来实现光场图像的超分辨率,将四个不同方向的视点堆叠起来进入网络的四个分支提取特征,并将四个分支的残差信息融合在一起得到重建结果.Yeung et al[19]提出一种空间角度可分离的卷积模块,可以更高效地提取空间和角度的特征,进而更好地恢复光场图像的细节信息.Meng et al[20]提出一种高维密集残差卷积神经网络来重建光场,将光场的所有子视点作为输入,并使用4D卷积获取视点之间的关系.Wang et al[21]提出一个空间角度交互网络实现光场图像的超分辨率,首先从宏像素图像中提取角度和空间特征,然后通过交互模块实现空间⁃角度的信息交互,最后利用光场重塑得到高分辨率图像.Jin et al[22]提出一种All⁃to⁃One模块,通过当前视点与参考视点的组合相关性充分利用光场视点之间的补充信息,并使用结构一致性正则化模块来恢复光场的几何结构. ...
Spatial?angular interaction for light field image super?resolution
7
2020
... 由于光场数据的高维特征,上述传统超分辨率算法的效果非常有限.随着深度神经网络研究的快速发展和成功,涌现了一些基于深度学习的算法来解决光场空间超分辨率的问题,它们主要利用多视点冗余性以及视点之间的补充信息来学习从低分辨率到高分辨率的映射关系.Rossi and Frossard[14]提出一个基于图的正则化器来增强光场的几何结构,从而提高光场全部视点的分辨率.Yoon et al[15-16]首次提出使用CNN(Convolutional Neural Networks)处理光场数据,同时实现角度和空间超分辨率.Wang et al[17]提出一个双向循环卷积神经网络,分别对水平和垂直两个方向上相邻子视点的空间相关性进行建模,然后利用堆栈泛化技术将两者集成起来获得高分辨率光场图像.Zhang et al[18]提出一个残差网络来实现光场图像的超分辨率,将四个不同方向的视点堆叠起来进入网络的四个分支提取特征,并将四个分支的残差信息融合在一起得到重建结果.Yeung et al[19]提出一种空间角度可分离的卷积模块,可以更高效地提取空间和角度的特征,进而更好地恢复光场图像的细节信息.Meng et al[20]提出一种高维密集残差卷积神经网络来重建光场,将光场的所有子视点作为输入,并使用4D卷积获取视点之间的关系.Wang et al[21]提出一个空间角度交互网络实现光场图像的超分辨率,首先从宏像素图像中提取角度和空间特征,然后通过交互模块实现空间⁃角度的信息交互,最后利用光场重塑得到高分辨率图像.Jin et al[22]提出一种All⁃to⁃One模块,通过当前视点与参考视点的组合相关性充分利用光场视点之间的补充信息,并使用结构一致性正则化模块来恢复光场的几何结构. ...
... 2.4 图像超分辨率结果定量分析 将本文算法与基于优化的超分辨率算法[13]以及基于深度学习的算法[21-22,27-28]进行定量分析对比,其中Dai et al[27],Jo et al[28]分别是单张图像和视频图像的超分辨率算法.为了实验的公平性,所有算法都在我们的训练数据集上训练,在7×7光场的中心子视点上采用PSNR,SSIM,PI (Perceptual ...
... Quantitative comparison results of light field super⁃resolution(40 arrays of test data)Table 3
... 如图4、图5和图6所示,第一行从左到右依次是插值、Dai et al[27]、Jo et al[28]和Rossi and Frossard[14]的实验结果,第二行从左到右依次是Jin et al[22]、Wang et al[21]、本文算法的结果和真值(GT).由图可见,Wang et al[21]和Jin et al[22]的算法表现良好,Dai et al[27]和Jo et al[28]的算法在某些场景的结果也不错,但在纹理区域上还有一定程度的模糊,而本文算法的结果更加锐利,在一些复杂的场景的优势更明显.由图4可见,Wang et al[21]的算法表现优于前面几个算法,但也没本文算法的结果锐利. ...
... [21]和Jin et al[22]的算法表现良好,Dai et al[27]和Jo et al[28]的算法在某些场景的结果也不错,但在纹理区域上还有一定程度的模糊,而本文算法的结果更加锐利,在一些复杂的场景的优势更明显.由图4可见,Wang et al[21]的算法表现优于前面几个算法,但也没本文算法的结果锐利. ...
... [21]的算法表现优于前面几个算法,但也没本文算法的结果锐利. ...
... 本文还在自己采集的数据集上进行了定性分析,结果是本文算法的结果明显优于其他算法.如图7和图8所示,本文算法在文字的细节恢复方面明显好于其他算法.图9的结果也远胜其他算法.同时可以看出,Rossi and Frossard[14]和Wang et al[21]的算法在重建过程中损失了很多高频细节信息.更多的实验结果请参考https:∥github.com/jhh1996/LFSR/tree/main/experiment. ...
Light field spatial super?resolution via deep combinatorial geometry embedding and structural consistency regularization
5
2020
... 由于光场数据的高维特征,上述传统超分辨率算法的效果非常有限.随着深度神经网络研究的快速发展和成功,涌现了一些基于深度学习的算法来解决光场空间超分辨率的问题,它们主要利用多视点冗余性以及视点之间的补充信息来学习从低分辨率到高分辨率的映射关系.Rossi and Frossard[14]提出一个基于图的正则化器来增强光场的几何结构,从而提高光场全部视点的分辨率.Yoon et al[15-16]首次提出使用CNN(Convolutional Neural Networks)处理光场数据,同时实现角度和空间超分辨率.Wang et al[17]提出一个双向循环卷积神经网络,分别对水平和垂直两个方向上相邻子视点的空间相关性进行建模,然后利用堆栈泛化技术将两者集成起来获得高分辨率光场图像.Zhang et al[18]提出一个残差网络来实现光场图像的超分辨率,将四个不同方向的视点堆叠起来进入网络的四个分支提取特征,并将四个分支的残差信息融合在一起得到重建结果.Yeung et al[19]提出一种空间角度可分离的卷积模块,可以更高效地提取空间和角度的特征,进而更好地恢复光场图像的细节信息.Meng et al[20]提出一种高维密集残差卷积神经网络来重建光场,将光场的所有子视点作为输入,并使用4D卷积获取视点之间的关系.Wang et al[21]提出一个空间角度交互网络实现光场图像的超分辨率,首先从宏像素图像中提取角度和空间特征,然后通过交互模块实现空间⁃角度的信息交互,最后利用光场重塑得到高分辨率图像.Jin et al[22]提出一种All⁃to⁃One模块,通过当前视点与参考视点的组合相关性充分利用光场视点之间的补充信息,并使用结构一致性正则化模块来恢复光场的几何结构. ...
... 2.4 图像超分辨率结果定量分析 将本文算法与基于优化的超分辨率算法[13]以及基于深度学习的算法[21-22,27-28]进行定量分析对比,其中Dai et al[27],Jo et al[28]分别是单张图像和视频图像的超分辨率算法.为了实验的公平性,所有算法都在我们的训练数据集上训练,在7×7光场的中心子视点上采用PSNR,SSIM,PI (Perceptual ...
... Quantitative comparison results of light field super⁃resolution(40 arrays of test data)Table 3
... 如图4、图5和图6所示,第一行从左到右依次是插值、Dai et al[27]、Jo et al[28]和Rossi and Frossard[14]的实验结果,第二行从左到右依次是Jin et al[22]、Wang et al[21]、本文算法的结果和真值(GT).由图可见,Wang et al[21]和Jin et al[22]的算法表现良好,Dai et al[27]和Jo et al[28]的算法在某些场景的结果也不错,但在纹理区域上还有一定程度的模糊,而本文算法的结果更加锐利,在一些复杂的场景的优势更明显.由图4可见,Wang et al[21]的算法表现优于前面几个算法,但也没本文算法的结果锐利. ...
... [22]的算法表现良好,Dai et al[27]和Jo et al[28]的算法在某些场景的结果也不错,但在纹理区域上还有一定程度的模糊,而本文算法的结果更加锐利,在一些复杂的场景的优势更明显.由图4可见,Wang et al[21]的算法表现优于前面几个算法,但也没本文算法的结果锐利. ...
Zero?reference deep curve estimation for low?light image enhancement
3
2020
... 本文在光场超分辨率之前首先对图像进行亮度增强.由于光场相机捕捉的图像亮度较低,造成光场分解得到的子视点图像因存在较多噪声/坏点等导致图像失真的问题,影响了超分辨率图像的质量.真实场景的光场图像没有真值,无法用有监督的方法训练网络.Guo et al[23]提出零参考深度曲线估计网络(Zero⁃DCE⁃Net),增强了单张图像的亮度,效果比较好,但由于光场子视点从边缘到中心的亮度范围不同,边缘子视点会偏暗.因此,本文在Zero⁃DCE⁃Net的基础上将2D卷积改成4D卷积,提出改进的4D Zero⁃DCE⁃Net,利用各子视点之间亮度信息(光场的几何结构信息)来提高整个光场图像的亮度. ...
Is space?time attention all you need for video understanding?
2
2021
... 本文将光场的全部视点输入Transformer[25]中提取全局特征,这与传统的Transformer不同.传统的Transformer只对单张图像进行注意力操作,而Bertasius et al[25]的Transformer可以对多张图像进行注意力操作,它通过对不同视点相同位置的图像块进行注意力操作,再对同一视点不同位置的图像块进行空间注意力操作来提取光场全部子视点的信息.如图2所示,同时取多个视点同一位置的图像块(如图中左上角红色框位置)进行注意力操作,无红色框的图像块表示没有进行注意力操作. ...
Second?order attention network for single image super?resolution
5
2019
... 2.4 图像超分辨率结果定量分析 将本文算法与基于优化的超分辨率算法[13]以及基于深度学习的算法[21-22,27-28]进行定量分析对比,其中Dai et al[27],Jo et al[28]分别是单张图像和视频图像的超分辨率算法.为了实验的公平性,所有算法都在我们的训练数据集上训练,在7×7光场的中心子视点上采用PSNR,SSIM,PI (Perceptual ...
... [27],Jo et al[28]分别是单张图像和视频图像的超分辨率算法.为了实验的公平性,所有算法都在我们的训练数据集上训练,在7×7光场的中心子视点上采用PSNR,SSIM,PI (Perceptual ...
... Quantitative comparison results of light field super⁃resolution(40 arrays of test data)Table 3
... 如图4、图5和图6所示,第一行从左到右依次是插值、Dai et al[27]、Jo et al[28]和Rossi and Frossard[14]的实验结果,第二行从左到右依次是Jin et al[22]、Wang et al[21]、本文算法的结果和真值(GT).由图可见,Wang et al[21]和Jin et al[22]的算法表现良好,Dai et al[27]和Jo et al[28]的算法在某些场景的结果也不错,但在纹理区域上还有一定程度的模糊,而本文算法的结果更加锐利,在一些复杂的场景的优势更明显.由图4可见,Wang et al[21]的算法表现优于前面几个算法,但也没本文算法的结果锐利. ...
... [27]和Jo et al[28]的算法在某些场景的结果也不错,但在纹理区域上还有一定程度的模糊,而本文算法的结果更加锐利,在一些复杂的场景的优势更明显.由图4可见,Wang et al[21]的算法表现优于前面几个算法,但也没本文算法的结果锐利. ...
Deep video super?resolution network using dynamic upsampling filters without explicit motion compensation
5
2018
... 2.4 图像超分辨率结果定量分析 将本文算法与基于优化的超分辨率算法[13]以及基于深度学习的算法[21-22,27-28]进行定量分析对比,其中Dai et al[27],Jo et al[28]分别是单张图像和视频图像的超分辨率算法.为了实验的公平性,所有算法都在我们的训练数据集上训练,在7×7光场的中心子视点上采用PSNR,SSIM,PI (Perceptual ...
... 如图4、图5和图6所示,第一行从左到右依次是插值、Dai et al[27]、Jo et al[28]和Rossi and Frossard[14]的实验结果,第二行从左到右依次是Jin et al[22]、Wang et al[21]、本文算法的结果和真值(GT).由图可见,Wang et al[21]和Jin et al[22]的算法表现良好,Dai et al[27]和Jo et al[28]的算法在某些场景的结果也不错,但在纹理区域上还有一定程度的模糊,而本文算法的结果更加锐利,在一些复杂的场景的优势更明显.由图4可见,Wang et al[21]的算法表现优于前面几个算法,但也没本文算法的结果锐利. ...
... [28]的算法在某些场景的结果也不错,但在纹理区域上还有一定程度的模糊,而本文算法的结果更加锐利,在一些复杂的场景的优势更明显.由图4可见,Wang et al[21]的算法表现优于前面几个算法,但也没本文算法的结果锐利. ...
Analyzing perception?distortion tradeoff using enhanced perceptual super?resolution network












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}