传统机器学习方法和深度神经网络在训练模型的过程中都需要大量标记样本作为支撑,然而标记大量样本是一个耗费巨大的过程,并且真实场景变化莫测,获得所有类别的标记样本是不现实的.因此,研究者开始突破标记样本的限制,提出一种更符合现实的场景——开放集识别(Open Set Recognition,OSR).OSR要求建立的模型不仅能分类训练过程中出现的类别,还可以有效地处理未见过的类别.近年来,OSR迅速发展成为热点领域,大量的工作围绕OSR展开.对现有的OSR工作进行总结:首先,从定义上将OSR与其他相关工作进行区分;其次,按照模型建立、度量选择、增量特点对OSR算法进行总结,并介绍了OSR的两种理论;最后展望了OSR未来的发展方向.
关键词:机器学习
;
深度神经网络
;
标记样本
;
开放集识别
;
度量选择
;
增量
Abstract
Traditional machine learning methods and deep neural networks need a large⁃scale of labeled samples as support in the process of training model. However,labeling a large⁃scale dataset is a time⁃consuming process,and it is not realistic to obtain all kinds of labeled samples due to the dynamic real world. Therefore,researchers broke through the limitation of labeled samples and proposed open set recognition which is more suitable to real scenes. Open set recognition models can not only classify the categories appearing in the training process,but also deal with the unseen categories effectively. In recent years,open set recognition has developed rapidly and attracted many researchers to focus on open set problems. This paper summarizes the existing open set recognition works. First,open set recognition is defined to distinguish from other related works. Second,the open set recognition algorithms are summarized according to the model building,metric selection and property of incremental. Furthermore,two theories used in open set recognition are introduced. Finally,this paper looks forward to the future development issues of open set recognition.
Keywords:machine learning
;
deep neural networks
;
labeled samples
;
open set recognition
;
metric selection
;
incremental
Gao Fei, Yang Liu, Li Hui. A survey on open set recognition. Journal of nanjing University[J], 2022, 58(1): 115-134 doi:10.13232/j.cnki.jnju.2022.01.012
开放集识别(Open Set Recognition,OSR)是依据真实场景提出的研究方向,要求模型在没有任何辅助信息时,不仅能分类见过的类别,还能准确识别新出现的类别.这一要求打破了传统封闭环境下识别的限制,建立模型的过程中人们不需要花费大量的时间和金钱收集标记样本甚至辅助信息.而且,OSR问题更贴近真实场景中新类不断出现的现实.
很多应用问题本身就具有开放集识别特性,例如在人脸识别[2-4]中,测试序列出现人脸库中没有的人脸图像是经常发生的.在开放集识别的定义正式提出之前,Phillips et al[8]已经通过设置阈值的评估方法解决了人脸识别中出现新类的情况,这是一个典型的开放集身份识别问题.同样地,Li and Wechsler[9]再次从评估的角度看待开放集人脸识别,将其当作早期人脸识别测试中观察列表公式的变体.2012年Scheirer et al[10]首次提出OSR的概念以及相关的定义,并从约束开放空间的角度建立了1⁃vs⁃set模型.
1.2 开放集识别的定义
1.2.1 样本集类别的定义
封闭环境下,训练集样本和测试集样本的类别相同,即测试集中不会出现训练集中没有的类别,样本类别比较简单.但是,当大量工作不满足于封闭环境下的研究时,样本类别变得相对复杂.因此,为更好地解决开放环境问题,需要重新定义样本的类别.Geng et al[11]在研究OSR问题时,对Scheirer et al[12]的基本识别类别的划分进行扩展,最终将OSR问题中的样本分为四类:
(1)已知辅助信息的已知类(Known Known Classes,KKCs):KKCs包含在训练过程中被标记的正样本(某一KKC中的正样本对其他KKCs是负样本),同时,这些样本的辅助信息(语义信息和属性信息等)可以获得.
Fig.1
Comparison of traditional classification and open set recognition:(a) the distribution of original dataset including KKCs and UUCs,(b) the decision boundary of each KKC obtained by traditional classification methods with UUCs included in KKCs' spaces,(c) open set recognition which can recognize UUCs as a class
其中,分别表示需要被识别的类别数(即该类样本经过分类器可以分到正确的类别中)、训练集中的类别数以及测试集中的类别数.式(1)中,O的值越大表示问题的开放程度越高,则是封闭环境下的问题.但是Scheirer et al[10]没有给出之间的关系,而文献[12,14-16]使用了一个假设.在进一步的研究中,Cardoso et al[17]给出了更加接近真实情况的假设,但这样的假设中很容易出现的情况,这显然是不合理的.为解决这个问题,Geng et al[11]重新给出开放性的定义:
2009年,Palatucci et al[7]正式提出零样本学习(ZSL)的概念,此后有大量的工作在语义空间[18-22]或嵌入空间[23-25]对零样本学习进行了研究.虽然零样本学习已经比以前的封闭环境下分类的设定更加现实,但是辅助信息的获取不是一个容易的过程,大量的属性都是通过人工标注的形式获取.并且零样本学习只考虑了测试集包含UKCs的状况,而在真实的情况下,无法提前知道测试样本是属于KKCs还是UKCs,这也进一步延伸出G⁃ZSL问题[26].
1.3.2 一类样本分类问题
一类样本分类问题[27-29]专门用来应对测试集中出现新类的情况.在测试过程中可以使用一类样本分类器识别样本是否属于KKCs,这也属于异常值检测问题,其最终的目的是拒绝不属于KKCs的类.但是,可以发现一类样本分类问题在分类的过程中将所有的KKCs都当成一类,也就是说,分类器虽然可以识别UUCs,但不能把KKCs中的类别分开(图1中的数字类“1”“2”“3”“4”“5”看作一类)[27-28].针对无法分类KKCs的情况,Tax and Duin[29]提出对每个KKC都建立一个一类分类器,但是最终效果并不理想.一类分类问题的出现,一定程度上为OSR问题的提出奠定了基础.
1.3.3 开放世界识别
开放世界识别是OSR的一个扩展.通常情况下,OSR是个静态的集合概念,但是,为了更加接近现实情况中环境的不断变化,数据集应该是动态的,系统必须不断检测并添加新的类别.因此,Bendale and Boult[30]提出开放世界识别的概念,希望解决开放世界识别的系统一共能完成三个过程:首先,该系统能够检测新类(UUCs),即OSR的问题;其次,对识别的新类(UUCs)进行标记并选择合适的新类(UUCs)将其加入到已知类(KKCs)中;最后是一个增量学习的阶段,根据更新的已知类(KKCs)数据集对之前的模型进行一个更新.当然,这些过程应该是自动完成的.虽然这里将开放世界识别问题当作一个单独的问题进行描述,但是因为它相当于给OSR问题提供了一个更好的研究方向,并且其本身解决了OSR的问题,因此,针对开放世界问题的算法也会总结到下一节OSR算法中.
2 开放集识别算法研究进展
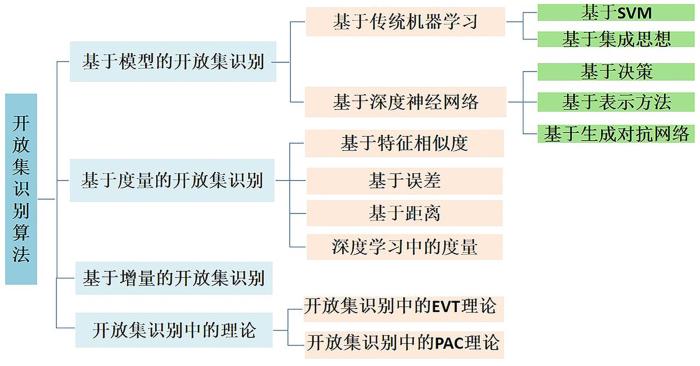
本节按照模型建立、度量选择、增量特点的角度对开放集识别算法进行总结,同时介绍开放集算法关于极值理论(Extreme Value Theory,EVT)和PAC(Probably Approximately Correct)的理论研究(如图2所示).
Scheirer et al[10]在定义开放集风险的基础上提出了一种新的机制“1⁃vs⁃set”.该算法基于带有线性核函数SVM算法,通过约束KKCs占据的空间减小开放空间风险.具体地,算法在核空间中构造另一个超平面,该超平面与SVM形成的超平面平行,两个超平面之间会形成一定距离的空间(如图3所示),此距离空间重新划定了KKCs的决策空间.具体的开放空间风险为:
式(6)包括了过度泛化风险以及过度专业化风险,这充分保障出现新类时模型会减小开放空间风险以及平衡经验风险.表示各自对应平面的边缘距离,表示两个超平面之间的距离(这个距离可以包含所有的正样本数据),对应两个边缘空间,是人为定义的两个权重参数.使用新加的超平面可以有效限制KKCs占有的空间,测试样本如果在两个超平面之间就可以被分到正确的类别中,否则将根据样本靠近的超平面界限去划分到其他KKCs或者UUCs中.该算法本质上是针对开放集特性利用超平面限制KKCs空间过度占用.与此想法相似,Cevikalp[32]提出使用最佳拟合平面算法来使每个超平面接近某一类样本,远离其他类样本.Cevikalp and Triggs[33]提出一组准线性多面体二次曲线判别算子,它的正样本区域是L1球型.这类线性算子可以通过非对称分类器为某类正样本生成更加紧凑、约束良好的决策边界.
Scheirer et al[10]的算法虽然能减小KKCs占据的空间,但这只是相对减小,每一类KKC占据的空间仍然是无界的.Scheirer et al[12]尝试将非线性核函数引入算法,通过用有限测度对样本进行标记来进一步限制开放空间风险.之前的算法适用于解决开放环境中的单类识别问题,因此进一步在1⁃vs⁃set的基础上提出针对开放环境中的多类识别问题[12].具体地,针对OSR问题提出紧凑衰减概率(Compact Abating Probability,CAP)模型[12],在该模型中,越靠近开放空间的样本属于此KKC的概率越低.同时,利用CAP模型和EVT理论[34]进行概率估计,提出韦伯校准SVM (Weibull⁃calibrated SVM,W⁃SVM)[12].该方法由一元SVM和二元SVM组成.样本首先经过第一个结合CAP的一元SVM模型产生一个后验概率,如果这个概率小于阈值,样本就会被拒绝.否则,样本会经过第二个结合CAP的二元SVM,产生一个对应KKC正样本的后验概率(基于韦伯分布)和一个KKC负样本的后验概率(基于逆韦伯分布).将问题进行形式定义一个指标变量:
对所有已知类别,多类W⁃SVM可以表示为:
其中,,是阈值,由具体问题的开放性定义为:
由于缺乏UUCs的先验知识,openness(开放性)在很多场景下无法确定.
如果算法可以准确地对任何KKCs的正样本建模而不出现过拟合的情况,那么即使存在UUCs,算法也可以有效拒绝UUCs.基于这一思想,Jain et al[27]提出PI⁃SVM算法.PI⁃SVM是以多分类SVM为基础,并用EVT对决策边界上的正训练样本进行建模.PI⁃SVM与W⁃SVM一样是基于阈值的方法,但是基于阈值的方法有几点限制:首先,这种基于阈值的方法通常假设对于所有KKCs阈值都是一样的,这显然不合理;其次,阈值的设定与开放性相关,但在开放环境中UUCs的先验知识很难获得;最后,有些阈值的设定是根据经验确定的,缺乏理论支持.因此,这种思想在开放集的效果上受到一定的局限.
为了突破现有的基于阈值方法的局限性,Scherreik and Rigling[35]引入POS⁃SVM分类器,该分类器根据定义2经验确定每个KKC的唯一拒绝阈值.Geng and Chen[16]提出基于HDP (Hierarchical Dirichlet Process)[36]的CD⁃OSR (Collective Decision⁃based OSR)模型,该算法不用设定分类KKCs和UUCs的阈值,而是引入了一些控制相应类中子类数量的阈值.
在某个特定任务中,KKCs和UUCs来自不同的数据分布,研究者采用集成思想针对KKCs和UUCs特征差异性做了大量研究.Vareto et al[37]在人脸识别任务上结合哈希函数和分类方法,并通过实验展示测试探测样本时响应值直方图对KKCs和UUCs的不同表现.Dong et al[38]提出一种将测试样本划分为已知、未知和不确定域的域划分算法,通过概率统计方法bootstrapping进行初始的域划分,然后引入Kolmogorov⁃Smirnov (K⁃S) Test进行微调得到最终的域划分.另外,bootstrapping和 K⁃S Test首次被引入挖掘和微调每个域的决策边界中.
同时,Neira et al[39]在考虑UUCs的前提下,将不同的分类器和特征结合起来.具体做法是将一个新提出的基于开放集图的最优路径树分类器(Open⁃Set Graph⁃Based Optimum⁃Path Forest,OSOPF)、遗传算法(GP)和多数投票融合技术结合在一起.OSOPF学到更加富有弹性的未知类和离群点边界;GP结合不同问题的特征设置合适的相似度函数并在早期融合阶段提供一个更加鲁棒的分类器;多数投票法通过晚期融合技术结合不同分类器和特征的结果.但该方法也存在不足:目前只致力于集成特定的类,而不致力于每个分类器的置信度,导致最终的分类效果不均衡.
Bendale and Boult[44]通过引入OpenMax层估计未知类的概率,提出一种适用于OSR的深度神经网络方法.具体地,首先,带有SoftMax层的深度神经网络通过最小化交叉熵损失函数进行训练,算法采用最近类平均的概念[45-46]将每个类表示为平均激活向量(MAV),激活向量的平均值(仅用正确分类的训练样本)位于该网络的倒数第二层.然后,计算所有正确分类正训练样本与相应类别MAV的距离,并将其用于拟合每个类别的单独韦伯分布.此外,根据韦伯分布拟合重新分配激活向量的值用于计算UUCs的伪激活,最后在这些新的重新分配的激活向量上再次使用SoftMax层计算KKCs和(伪)UUCs的类概率.
使用OpenMax可以自动拒绝许多开放环境下的UUCs样本及Fooling样本,但Rozsa et al[47]认为OpenMax与SoftMax一样容易受到比较复杂生成对抗技术的影响,因为这些技术直接作用于深层的表示.因此,深层表示的改进也能促进OSR的发展.基于深层表示的方法在下一小节进行详细的描述.
此外,Venkataram[48]将OpenMax引入文本分类的研究,解决了开放环境下的文本分类任务.同样用于文本分类,Shu et al[49]认为OpenMax是通过减少每个已知类的开放空间达到拒绝未知类的目的,这种拒绝方式很薄弱,因此提出一个深度开放分类器(DOC)模型.DOC模型用1⁃vs⁃rest层(包含对应可见类的所有sigmod函数)代替OpenMax层,这给所有其他类(其余可见类和未见类)提供了一个合理的表示,使每一类形成一个合理的边界.并且,算法用高斯拟合收紧决策边界,可以进一步降低被拒绝的开放空间风险.
Yang et al[50]提出卷积原型网络(Convolutional Prototype Network,CPN),其中,卷积神经网络继续用于表示学习,但在最终输出类别概率时,CPN用原型模型代替之前的SoftMax层,并设计了新的判别损失和生成损失,从而达到增大类间距离并减小类内距离.
OSR的方法大多是从KKCs的角度出发,在训练样本的嵌入空间上拟合一个概率分布,并根据这个概率分布检测异常值.这种方式对KKCs的分类比较有效,但对UUCs的识别效果一般.Zhang et al[51]引入一个基于流的密度估计器来进一步检测样本是否属于UUCs.
Cardoso et al[17]提出基于失重神经网络模型的精细距离计算的OSR方法,利用对未知数据和存储的知识之间的相似性进行分级的分类器,从训练样本中计算出对不属于任何KKCs的观测值的相似性的估计,此估计值用于定义属于KKCs的观测值和可能的异常值之间的边界.这种相似性等级类似于后验概率,但不依赖于关于类的先验概率分布的假设.Yoshihashi et al[52]将有监督的分类网络和无监督的重构网络联合起来提出CROSR (Classification⁃Reconstruction Learning for OSR)算法,利用重构过程中的潜在表示,补充在有监督分类过程中丢失的一些特征.这些特征可能对KKCs的分类不重要,但可能是区别KKCs与UUCs的关键,补充重构特征可以更好地区分KKCs和UUCs样本.Hassen and Chan[53]也提出一种表示,在这个表示中,来自同一类的样本彼此靠近,来自不同类的样本相对疏远.算法选择深度神经网络的最后一层线性层(将该层的输出作为SoftMax层的输入)的输出作为输入样本的投影表示,在此表示空间,利用基于距离的损失函数,增大不同类样本之间的距离,减小同一类样本之间的距离.虽然有大量的算法寻找一个合适的表示方法去区分KKCs和UUCs,但是由于每个任务中KKCs与UUCs判别信息差异比较大,这对研究者来说仍然是一项挑战.
变分自动编码器(Variational Auto⁃Encoder,AE)作为一种能够有效识别UUCs的手段被广泛应用,但它不能对KKCs提供有区别的表示.Sun et al[54]提出一种新方法:条件高斯分布学习(Conditional Gaussian Distribution Learning,CGDL),在VAE的基础上,除了有效检测UUCs,还通过强制不同的潜在特征来逼近不同的高斯模型,对已知样本进行分类.Perera et al[55]使用自监督方法捕获更高级的特征,如语义和结构属性,这给KKCs和UUCs的识别带来了更多的有用信息.
在以前的许多方法中,UUCs是根据特征或对KKCs的决策距离进行判断,没有对UUCs进行直接表示.并且,OpenMax方法虽然根据KKCs的激活分数估计了UUCs的伪概率,达到拒绝效果,但实质上没有考虑UUCs的先验知识.因此,为了能显式地对UUCs进行建模和决策得分,Ge et al[56]提出新的算法G⁃OpenMax,对OpenMax方法进行扩展,利用GANs合成新的类别图像直接估计UUCs概率,合成样本是由潜在空间中KKCs的混合分布生成.这种方法不仅克服了伪概率估计的不足,还能可视化KKCs样本和UUCs样本.但实验证明,G⁃OpenMax虽然可以在单色数据集上提高OSR的性能,却在自然图像上性能没有明显提升.
使用生成对抗思想可以很好地进行数据扩充,Neal et al[57]借助GANs对训练集样本进行扩充,提出了反事实图像生成(Open Set Learning with Counterfactual Images,OSRCI).OSRCI用一个编码⁃解码的生成对抗网络生成合成的开放集样本,这些样本很接近KKCs但不属于任何KKC.采用这种数据扩充的方式,还进一步把OSR问题定义为多加了UUCs一类的分类器问题.使用生成对抗网络不仅能生成负样本,还可以生成正样本进行数据扩充.Yu et al[58]提出对抗样本生成(Adversarial Sample Generation,ASG)框架,不仅可以生成KKCs的负样本作为UUCs样本,同时,如果KKCs样本比较少的话,也可以产生KKCs的正样本.从上述工作可以看出,研究者付出了很多努力来构建一个负样本集或为目标集设置一个最优阈值.在最近的工作中,Yang et al[15]基于GANs,用生成器生成与目标样本高度相似的样本并自动作为负的样本集,还重新设计了判别器以输出多个类别和一个UUCs.Ditria et al[59]提出一种开放集GAN体系结构(OpenGAN),为每个输入样本嵌入一个来自度量空间的特征.使用类别等级和细粒度语义信息的最先进的度量学习模型,能够生成在语义上与给定的源图像相似的样本.由度量学习模型提取的语义信息转移到分布之外的新类,允许生成模型生成不在训练分布之外的样本,通过这种方式,便可产生高质量的图像样本.
近年来,大量基于稀疏表示的分类与恢复算法[62-63]被提出.特别地,研究者对基于稀疏表示的分类算法(SRC)[64]进行了大量研究.为了适应OSR问题,Zhang and Patel[14]提出一种基于广义稀疏表示的分类算法SROSR (Sparse Representation⁃based Open Set Recognition),利用类重构误差进行分类.由于OSR的判别信息都隐藏在匹配重建误差分布和非匹配重建误差分布之和的尾部,作者引入统计极值理论对两种误差的分布的尾部进行建模.具体做法分为两步:第一步,用EVT对两个分布进行建模,将OSR问题化简为假设检验问题;第二步,计算测试样本的重建误差并融合基于两个尾部分布的置信度分数来确定测试样本的类别.实验证明,SROSR具有很强的解决OSR问题的能力.
2.2.3 基于距离
距离是衡量相似度的一个重要指标,但是传统的基于距离的分类器在开放环境下的分类效果并不理想.因此,Bendale and Boult[30]通过扩展NCM (Nearest Class Mean)分类器[45-46],提出最近非离群点算法(Nearest Non⁃Outlier,NNO).NNO根据测试样本与KKCs均值之间的距离进行分类,并且只有当所有分类器都拒绝测试样本时,该测试样本才会被拒绝.为优化距离的计算,研究者也做出了许多努力.在人脸识别任务中,对于未知样本会提供一个图像集合(Query Set)用来识别结果;同样,每个已知类样本也形成一个图像集(Gallery Images Set).Cevikalp and Yavuz[65]提出一个快速和准确地计算Query Set与Gallery Set之间距离的方法Polyhedral Conic Classifier,可以通过简单的点乘高效地计算距离.
基于最近邻(NN)算法,Júnior et al[66]提出开放集最近邻(OSNN)方法,具体介绍了两种适应开放环境的NN分类器的扩展.第一种是OSNN类验证(OSNN Class Verification,OSNNcv),该方法的思想是在预测阶段选出测试样本s的两个最近邻.如果两个具有相同的标签t,则把标签t分给测试样本s,否则测试样本会被分到UUCs当中.在这个算法中,如果测试样本离训练样本很远,则无法被分到UUCs当中,为了解决这个问题,使用最近邻距离比率算法(Nearest Neighbor Distance Ratio,NNDR).该方法的特点在于不是直接对某一最相似类的相似性得分设置阈值,而是对两个最相似类的相似性得分比率设置阈值.测试样本s两个不同的最近邻u和t,计算,如果R小于阈值τ,s被分为和t相同的标签,否则就会被分到UUCs.该方法也存在一个固有的缺点,因为只选择来自不同类的两个参考样本进行比较,所以当有异常值存在时,该方法的效果会受到很大的影响.
2.2.4 深度学习中的度量
上述方法都是基于传统机器学习的度量OSR方法,其实在深度学习方法中也有基于度量问题的OSR算法.在开放环境下,通常希望利用深度学习使样本的特征表示有两种特性:一是使来自同一类别的样本彼此靠近;二是使来自不同类别的样本相隔比较远.基于这个思想,Hassen and Chan[53]提出一种基于神经网络的表示方法和一种基于度量的损失函数解决OSR问题.该损失函数在训练过程中或者计算异常值得分时不用转换度量函数,都使用同一个距离函数进行度量.Mayer and Drummond[67]强调深度度量学习[68-74]在OSR的重要性.深度度量学习不同于传统的分类模型,利用带有SoftMax分类器的CNN,深度度量学习算法学习从图像空间到特征嵌入空间的转换,其中度量距离特指语义相似度.文献[68-74]的工作展示了深度度量学习强大的迁移能力并解释了样本特征是基于类的,即使这些类不在训练样本的分布中.此外,Shu et al[75]提出一种基于原型的开放式深度网络用于OSR任务,即通过使用原型模块和原型半径模块训练类别和原型半径的原型,将原型学习引入到OSR任务中,然后采用基于原型的距离度量方法检测未知类.基于样本与所有原型之间的统计信息,即样本与所有原型之间的距离,一定程度上打破了Júnior et al[66]的NNDR算法只选择不同两类的限制,不容易受到异常值的影响.基于原型的方法旨在寻找每个类的原型点,即所有属于这类的样本点与该原型点距离尽可能近.Chen et al[76]提出不同的想法,探索类以外的空间,并提出反向点(Reciprocal Points)的概念代表每个额外类空间,借助这些反向点,间接地将未知信息引入只有KKCs的学习,从而学习更紧凑、更具区别性的表征.Chen et al[77]还进一步对上述方法进行改进,并进行了丰富的实验验证.
2.3 基于增量的开放集识别
在开放世界识别框架[30]中,为了使研究环境发生动态变化而更加接近现实世界,研究者递增地向系统增加新类和检测来自UUCs的样本,同时不断地更新KKCs的模型.更新模型的过程中会出现一个非常现实的问题:每当有新的样本出现时模型就需要从头训练,这将是一个计算量巨大、消耗过度的过程,更严重的是,由于UUCs样本数量过少,重新训练的模型很大程度上会出现过拟合的现象.在此基础上,研究者希望系统具有增量学习的特性,即每当检测出新类样本时,更新模型不需要重新训练,只需在原来的基础上进行调整,这样能降低整个模型的训练成本.De Rosa et al[78]提出采用在线增量学习的方式对三种非参算法进行扩展,并且制定了在线的度量学习和阈值增量更新算法.其中,算法对NNO[30]进行扩展,进行置信度和阈值的更新:
基于增量的OSR思想也用于深度神经网络中,Venkataram[48]提出基于卷积神经网络的增量开放集算法,实验证明该算法能够处理UUCs的文本文档.Shu et al[75]设计了原型学习深度网络,该网络在检测到UUCs样本之后,手动地对样本进行标注,并利用这些标注好的UUCs样本对网络进行更新.网络的分类器会根据新样本和原型之间的距离分布进行初始化,具体的过程:首先,计算新样本和原型之间的距离分布,然后利用均值归一化得到一个权值分布,最后根据权值分布对新的预测器进行权重初始化.每一类在网络中新的权重更新为:
同时,EVT理论也用于其他算法中.由于OSR的判别信息都隐藏在匹配重建误差分布和非匹配重建误差分布之和的尾部,Zhang and Pater[14]的SROSR算法在基于广义稀疏表示上引入EVT理论对两种误差的分布的尾部进行建模.同样,Oza and Pater[82]提出一种新的基于深度卷积神经网络的OSR算法,该算法的解码器网络的重建误差被用于开放集的拒绝,为了提高整体性能也利用EVT对已知类的重建误差分布尾部进行建模.Mundt et al[83]还将EVT理论运用到分布外数据(OOD)检测,在能推出模型不确定性的深度神经网络的基础上,结合基于OSR的EVT算法,限制模型开放空间风险.
虽然EVT理论被许多研究者引入解决OSR问题,但是,如果KKCs和UUCs的几何结构不同,简单的识别任务也会失败.为了克服这一局限,Vignotto and Engelke[84]提出两种新的算法,这两种算法的思想是采用不基于已知类几何表示的EVT近似⁃GPD分类器和GEV分类器.
2.4.2 开放集识别中的PAC理论
在一般开放集问题的假设下,很少有算法能保证其检测UUCs的能力.因此,Liu et al[85]通过引入PAC理论,从概率的角度对模型从理论方面重新进行设计.该算法能实现具体的UUCs检测率,如能成功检测95%的UUCs.假设存在一个KKCs的分布D0,可以从D0中生成一个训练集S0,同时还存在一个混合分布Dm,Dm是KKCs分布D0和UUCs分布Da的混合,可以从Dm中生成混合数据集Sm.注意,在Dm中,假设可以以的概率从Da中生成一个UUCs数据,以1-α的概率从D0中生成一个KKCs数据.基于以上假设,设计使用异常检测器的阈值去判断UUCs,如果异常得分大于阈值则标记样本为UUCs,否则将样本标记为KKCs.因此,问题的关键在于阈值的选择.考虑固定异常检测器异常分数的累积分布函数(CDFs),混合分布Dm的异常值得分可以表示为:
由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs.
上面在计算OSR准确率时是根据样本数量进行判断的,这样的评价指标无法显示分类器对于KKCs和UUCs的分类效果.训练一个分类器时,分类器会倾向于样本数量最多的类.在OSR中,如果UUCs的数量比较多,则分类器对UUCs的拒绝能力比较强(这种情况是成立的,随着环境开放性增大UUCs是未知的),上述的准确率也较高.但这种情况下,分类器对KKCs的分类判断显然是不合理的,因为KKCs的准确率可能很低.因此,Júnior et al[66]同时考虑KKCs的准确率和UUCs的准确率,给对应权重提出了标准化的准确率:
F⁃measure对OSR的一个小扩展是将所有UUCs当作一个简单的类并以与封闭环境相同的方式获得其值,这种做法对于OSR测试的评价显然不正确.考虑下面的情况,所有UUCs的正确分类都被认为是正确的KKCs正样本分类,但这种分类结果没有任何意义,因为在训练过程中UUCs没有用于训练分类器.Júnior et al[66]在只考虑KKCs的基础上对精度和召回率的计算进行改进,从宏平均和微平均的角度进行计算:
此外,Sokolova and Lapalme[98]提出对于F⁃measure来说,无论TN怎么改变其值都不会变化,但在OSR下TN是一个非常重要的变量.因此,Scherreik and Rigling[35]引入约登指数J来表示一个算法避免失败的能力[99],J越高代表这个算法越能避免失败.
(3)AUROC (Area Under the ROC Curve):开放环境的开放性是不确定的,因此需要选择直接表示分类器性能好坏的指标AUROC[57],它提供检测算法性能的无校准测量,能表示从UUCs类别很少到UUCs类别占大多数的所有情况.目前,AUROC是OSR工作中最常用的评价指标.
3.3 模型以及实验结果分析
本节对OSR算法以及实验结果进行比较分析,分为基于非深度特征的OSR算法(如表2所示)和基于深度特征的OSR算法两部分(如表3所示).引用Geng et al[11]的实验结果,表2数据代表微平均F⁃measure(%),表3数据为AUROC.
Table 2
表2
表2基于非深度特征的开放集识别算法结果
Table 2 Results of OSR based the non⁃depth feature
领域自适应是迁移学习[105]的一个重要研究方向,传统领域自适应问题是训练集与测试集样本类别相同可是数据分布不同(如手写数字集与合成图像数字集),领域自适应能将在训练集中训练的模型应用于测试集中.Busto and Gall[106]通过在训练集中加入无关类,提出开放集领域自适应(OSDA)的概念.Saito et al[107]探讨了更具挑战的开放性场景,即在训练集没有无关类的情况下实现测试集中UUCs识别.算法具体采用了生成对抗网络,不仅使两个领域的KKCs差异缩小还有效识别了UUCs.刘晓龙和王士同[108]提出一种开放集模糊领域自适应算法,该方法通过计算目标域样本的模糊隶属度表示源域到目标域的映射,从而逐步在同一空间下实现对目标域的分类.为了进一步分离KKCs和UUCs,刘晓龙和王士同还在前文[107]的基础上,仅将从目标域分离出的KKCs与源域样本进行对齐[109].
开放世界识别就是将增量学习引入OSR中,开放世界识别模型不仅要求将UUCs识别出来,还要求根据人工标注等手段将UUCs加入KKCs中,将UUCs在下次模型的训练中当成KKCs进行模型的更新.强化学习[110]是在没有任何监督的标签的情况下,通过尝试性地做出一些行为得到反馈,不断地调整之前的行为,系统就可以知道什么样子的行为是最好的结果.在强化学习中,开放性是其特征,因此将强化学习与OSR结合起来具有很强的理论依据.对抗防御的目的是减少网络对图像的攻击,开放环境下这种攻击会变得更加复杂.Shao et al[111]考虑开放环境下的对抗防御问题,提出开放对抗防御机制(Open⁃Set Adversarial Defense,OSAD).本文已表明OSR系统容易受到对抗性攻击.联邦学习[112]是从用户隐私的角度出发形成的新的学习领域,传统学习中不管是KKCs还是UUCs,都假设模型可以直接获得这些数据进行处理,但在实际情况中,用户不希望模型能够获得自己的数据,因此将OSR与联邦学习结合起来是未来应用领域发展的潜在要求.
Breaking the closed world assumption in text classification
∥Proceedings of 2016 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. San Diego,CA,USA:ACL,2016:506-514.
SzepesváriC. Algorithms for reinforcement learning. Synthesis lectures on artificial intelligence and machine learning. San Franscisco,CA,USA:Morgan & Claypool,2010.
... 很多应用问题本身就具有开放集识别特性,例如在人脸识别[2-4]中,测试序列出现人脸库中没有的人脸图像是经常发生的.在开放集识别的定义正式提出之前,Phillips et al[8]已经通过设置阈值的评估方法解决了人脸识别中出现新类的情况,这是一个典型的开放集身份识别问题.同样地,Li and Wechsler[9]再次从评估的角度看待开放集人脸识别,将其当作早期人脸识别测试中观察列表公式的变体.2012年Scheirer et al[10]首次提出OSR的概念以及相关的定义,并从约束开放空间的角度建立了1⁃vs⁃set模型. ...
... 很多应用问题本身就具有开放集识别特性,例如在人脸识别[2-4]中,测试序列出现人脸库中没有的人脸图像是经常发生的.在开放集识别的定义正式提出之前,Phillips et al[8]已经通过设置阈值的评估方法解决了人脸识别中出现新类的情况,这是一个典型的开放集身份识别问题.同样地,Li and Wechsler[9]再次从评估的角度看待开放集人脸识别,将其当作早期人脸识别测试中观察列表公式的变体.2012年Scheirer et al[10]首次提出OSR的概念以及相关的定义,并从约束开放空间的角度建立了1⁃vs⁃set模型. ...
ImageNet classification with deep convolutional neural networks
... 2009年,Palatucci et al[7]正式提出零样本学习(ZSL)的概念,此后有大量的工作在语义空间[18-22]或嵌入空间[23-25]对零样本学习进行了研究.虽然零样本学习已经比以前的封闭环境下分类的设定更加现实,但是辅助信息的获取不是一个容易的过程,大量的属性都是通过人工标注的形式获取.并且零样本学习只考虑了测试集包含UKCs的状况,而在真实的情况下,无法提前知道测试样本是属于KKCs还是UKCs,这也进一步延伸出G⁃ZSL问题[26]. ...
Evaluation methods in face recognition
1
2011
... 很多应用问题本身就具有开放集识别特性,例如在人脸识别[2-4]中,测试序列出现人脸库中没有的人脸图像是经常发生的.在开放集识别的定义正式提出之前,Phillips et al[8]已经通过设置阈值的评估方法解决了人脸识别中出现新类的情况,这是一个典型的开放集身份识别问题.同样地,Li and Wechsler[9]再次从评估的角度看待开放集人脸识别,将其当作早期人脸识别测试中观察列表公式的变体.2012年Scheirer et al[10]首次提出OSR的概念以及相关的定义,并从约束开放空间的角度建立了1⁃vs⁃set模型. ...
Open set face recognition using transduction
1
2005
... 很多应用问题本身就具有开放集识别特性,例如在人脸识别[2-4]中,测试序列出现人脸库中没有的人脸图像是经常发生的.在开放集识别的定义正式提出之前,Phillips et al[8]已经通过设置阈值的评估方法解决了人脸识别中出现新类的情况,这是一个典型的开放集身份识别问题.同样地,Li and Wechsler[9]再次从评估的角度看待开放集人脸识别,将其当作早期人脸识别测试中观察列表公式的变体.2012年Scheirer et al[10]首次提出OSR的概念以及相关的定义,并从约束开放空间的角度建立了1⁃vs⁃set模型. ...
Toward open set recognition
9
2013
... 很多应用问题本身就具有开放集识别特性,例如在人脸识别[2-4]中,测试序列出现人脸库中没有的人脸图像是经常发生的.在开放集识别的定义正式提出之前,Phillips et al[8]已经通过设置阈值的评估方法解决了人脸识别中出现新类的情况,这是一个典型的开放集身份识别问题.同样地,Li and Wechsler[9]再次从评估的角度看待开放集人脸识别,将其当作早期人脸识别测试中观察列表公式的变体.2012年Scheirer et al[10]首次提出OSR的概念以及相关的定义,并从约束开放空间的角度建立了1⁃vs⁃set模型. ...
... 其中,分别表示需要被识别的类别数(即该类样本经过分类器可以分到正确的类别中)、训练集中的类别数以及测试集中的类别数.式(1)中,O的值越大表示问题的开放程度越高,则是封闭环境下的问题.但是Scheirer et al[10]没有给出之间的关系,而文献[12,14-16]使用了一个假设.在进一步的研究中,Cardoso et al[17]给出了更加接近真实情况的假设,但这样的假设中很容易出现的情况,这显然是不合理的.为解决这个问题,Geng et al[11]重新给出开放性的定义: ...
... Scheirer et al[10]在定义开放集风险的基础上提出了一种新的机制“1⁃vs⁃set”.该算法基于带有线性核函数SVM算法,通过约束KKCs占据的空间减小开放空间风险.具体地,算法在核空间中构造另一个超平面,该超平面与SVM形成的超平面平行,两个超平面之间会形成一定距离的空间(如图3所示),此距离空间重新划定了KKCs的决策空间.具体的开放空间风险为: ...
... Scheirer et al[10]的算法虽然能减小KKCs占据的空间,但这只是相对减小,每一类KKC占据的空间仍然是无界的.Scheirer et al[12]尝试将非线性核函数引入算法,通过用有限测度对样本进行标记来进一步限制开放空间风险.之前的算法适用于解决开放环境中的单类识别问题,因此进一步在1⁃vs⁃set的基础上提出针对开放环境中的多类识别问题[12].具体地,针对OSR问题提出紧凑衰减概率(Compact Abating Probability,CAP)模型[12],在该模型中,越靠近开放空间的样本属于此KKC的概率越低.同时,利用CAP模型和EVT理论[34]进行概率估计,提出韦伯校准SVM (Weibull⁃calibrated SVM,W⁃SVM)[12].该方法由一元SVM和二元SVM组成.样本首先经过第一个结合CAP的一元SVM模型产生一个后验概率,如果这个概率小于阈值,样本就会被拒绝.否则,样本会经过第二个结合CAP的二元SVM,产生一个对应KKC正样本的后验概率(基于韦伯分布)和一个KKC负样本的后验概率(基于逆韦伯分布).将问题进行形式定义一个指标变量: ...
... Results of OSR based the non⁃depth featureTable 2
... 封闭环境下,训练集样本和测试集样本的类别相同,即测试集中不会出现训练集中没有的类别,样本类别比较简单.但是,当大量工作不满足于封闭环境下的研究时,样本类别变得相对复杂.因此,为更好地解决开放环境问题,需要重新定义样本的类别.Geng et al[11]在研究OSR问题时,对Scheirer et al[12]的基本识别类别的划分进行扩展,最终将OSR问题中的样本分为四类: ...
... 其中,分别表示需要被识别的类别数(即该类样本经过分类器可以分到正确的类别中)、训练集中的类别数以及测试集中的类别数.式(1)中,O的值越大表示问题的开放程度越高,则是封闭环境下的问题.但是Scheirer et al[10]没有给出之间的关系,而文献[12,14-16]使用了一个假设.在进一步的研究中,Cardoso et al[17]给出了更加接近真实情况的假设,但这样的假设中很容易出现的情况,这显然是不合理的.为解决这个问题,Geng et al[11]重新给出开放性的定义: ...
... 本节对OSR算法以及实验结果进行比较分析,分为基于非深度特征的OSR算法(如表2所示)和基于深度特征的OSR算法两部分(如表3所示).引用Geng et al[11]的实验结果,表2数据代表微平均F⁃measure(%),表3数据为AUROC. ...
Probability models for open set recognition
6
2014
... 封闭环境下,训练集样本和测试集样本的类别相同,即测试集中不会出现训练集中没有的类别,样本类别比较简单.但是,当大量工作不满足于封闭环境下的研究时,样本类别变得相对复杂.因此,为更好地解决开放环境问题,需要重新定义样本的类别.Geng et al[11]在研究OSR问题时,对Scheirer et al[12]的基本识别类别的划分进行扩展,最终将OSR问题中的样本分为四类: ...
... 其中,分别表示需要被识别的类别数(即该类样本经过分类器可以分到正确的类别中)、训练集中的类别数以及测试集中的类别数.式(1)中,O的值越大表示问题的开放程度越高,则是封闭环境下的问题.但是Scheirer et al[10]没有给出之间的关系,而文献[12,14-16]使用了一个假设.在进一步的研究中,Cardoso et al[17]给出了更加接近真实情况的假设,但这样的假设中很容易出现的情况,这显然是不合理的.为解决这个问题,Geng et al[11]重新给出开放性的定义: ...
... Scheirer et al[10]的算法虽然能减小KKCs占据的空间,但这只是相对减小,每一类KKC占据的空间仍然是无界的.Scheirer et al[12]尝试将非线性核函数引入算法,通过用有限测度对样本进行标记来进一步限制开放空间风险.之前的算法适用于解决开放环境中的单类识别问题,因此进一步在1⁃vs⁃set的基础上提出针对开放环境中的多类识别问题[12].具体地,针对OSR问题提出紧凑衰减概率(Compact Abating Probability,CAP)模型[12],在该模型中,越靠近开放空间的样本属于此KKC的概率越低.同时,利用CAP模型和EVT理论[34]进行概率估计,提出韦伯校准SVM (Weibull⁃calibrated SVM,W⁃SVM)[12].该方法由一元SVM和二元SVM组成.样本首先经过第一个结合CAP的一元SVM模型产生一个后验概率,如果这个概率小于阈值,样本就会被拒绝.否则,样本会经过第二个结合CAP的二元SVM,产生一个对应KKC正样本的后验概率(基于韦伯分布)和一个KKC负样本的后验概率(基于逆韦伯分布).将问题进行形式定义一个指标变量: ...
... 其中,分别表示需要被识别的类别数(即该类样本经过分类器可以分到正确的类别中)、训练集中的类别数以及测试集中的类别数.式(1)中,O的值越大表示问题的开放程度越高,则是封闭环境下的问题.但是Scheirer et al[10]没有给出之间的关系,而文献[12,14-16]使用了一个假设.在进一步的研究中,Cardoso et al[17]给出了更加接近真实情况的假设,但这样的假设中很容易出现的情况,这显然是不合理的.为解决这个问题,Geng et al[11]重新给出开放性的定义: ...
... 近年来,大量基于稀疏表示的分类与恢复算法[62-63]被提出.特别地,研究者对基于稀疏表示的分类算法(SRC)[64]进行了大量研究.为了适应OSR问题,Zhang and Patel[14]提出一种基于广义稀疏表示的分类算法SROSR (Sparse Representation⁃based Open Set Recognition),利用类重构误差进行分类.由于OSR的判别信息都隐藏在匹配重建误差分布和非匹配重建误差分布之和的尾部,作者引入统计极值理论对两种误差的分布的尾部进行建模.具体做法分为两步:第一步,用EVT对两个分布进行建模,将OSR问题化简为假设检验问题;第二步,计算测试样本的重建误差并融合基于两个尾部分布的置信度分数来确定测试样本的类别.实验证明,SROSR具有很强的解决OSR问题的能力. ...
... 同时,EVT理论也用于其他算法中.由于OSR的判别信息都隐藏在匹配重建误差分布和非匹配重建误差分布之和的尾部,Zhang and Pater[14]的SROSR算法在基于广义稀疏表示上引入EVT理论对两种误差的分布的尾部进行建模.同样,Oza and Pater[82]提出一种新的基于深度卷积神经网络的OSR算法,该算法的解码器网络的重建误差被用于开放集的拒绝,为了提高整体性能也利用EVT对已知类的重建误差分布尾部进行建模.Mundt et al[83]还将EVT理论运用到分布外数据(OOD)检测,在能推出模型不确定性的深度神经网络的基础上,结合基于OSR的EVT算法,限制模型开放空间风险. ...
... Results of OSR based the non⁃depth featureTable 2
Method
LETTER(O*=0%)
LETTER (O*=25.46%)
YALEB (O*=0%)
YALEB (O*=23.30%)
EVT (y/n)
1⁃vs⁃set[10]
81.51±3.94
42.08±2.63
87.99±2.42
49.36±1.96
n
W⁃SVM[34]
95.64±0.25
85.72±0.85
86.01±2.42
84.56±2.19
y
PI⁃SVM[27]
96.92±0.36
84.16±1.01
93.47±2.74
88.96±1.16
y
SROSR[14]
84.21±2.49
66.50±8.22
88.09±3.41
83.99±4.19
y
OSNN[66]
83.12±17.41
64.97±13.75
81.81±8.40
72.90±9.41
y
EVM[79]
96.59±0.50
82.81±2.42
68.94±6.47
54.40±5.77
y
CD⁃OSR[36]
96.94±1.36
86.21±1.46
89.75±1.15
88.00±2.19
n
基于深度特征的开放集识别算法结果 ...
Open?set human activity recognition based on micro?Doppler signatures
1
2019
... 使用生成对抗思想可以很好地进行数据扩充,Neal et al[57]借助GANs对训练集样本进行扩充,提出了反事实图像生成(Open Set Learning with Counterfactual Images,OSRCI).OSRCI用一个编码⁃解码的生成对抗网络生成合成的开放集样本,这些样本很接近KKCs但不属于任何KKC.采用这种数据扩充的方式,还进一步把OSR问题定义为多加了UUCs一类的分类器问题.使用生成对抗网络不仅能生成负样本,还可以生成正样本进行数据扩充.Yu et al[58]提出对抗样本生成(Adversarial Sample Generation,ASG)框架,不仅可以生成KKCs的负样本作为UUCs样本,同时,如果KKCs样本比较少的话,也可以产生KKCs的正样本.从上述工作可以看出,研究者付出了很多努力来构建一个负样本集或为目标集设置一个最优阈值.在最近的工作中,Yang et al[15]基于GANs,用生成器生成与目标样本高度相似的样本并自动作为负的样本集,还重新设计了判别器以输出多个类别和一个UUCs.Ditria et al[59]提出一种开放集GAN体系结构(OpenGAN),为每个输入样本嵌入一个来自度量空间的特征.使用类别等级和细粒度语义信息的最先进的度量学习模型,能够生成在语义上与给定的源图像相似的样本.由度量学习模型提取的语义信息转移到分布之外的新类,允许生成模型生成不在训练分布之外的样本,通过这种方式,便可产生高质量的图像样本. ...
Collective decision for open set recognition
2
2020
... 其中,分别表示需要被识别的类别数(即该类样本经过分类器可以分到正确的类别中)、训练集中的类别数以及测试集中的类别数.式(1)中,O的值越大表示问题的开放程度越高,则是封闭环境下的问题.但是Scheirer et al[10]没有给出之间的关系,而文献[12,14-16]使用了一个假设.在进一步的研究中,Cardoso et al[17]给出了更加接近真实情况的假设,但这样的假设中很容易出现的情况,这显然是不合理的.为解决这个问题,Geng et al[11]重新给出开放性的定义: ...
... 为了突破现有的基于阈值方法的局限性,Scherreik and Rigling[35]引入POS⁃SVM分类器,该分类器根据定义2经验确定每个KKC的唯一拒绝阈值.Geng and Chen[16]提出基于HDP (Hierarchical Dirichlet Process)[36]的CD⁃OSR (Collective Decision⁃based OSR)模型,该算法不用设定分类KKCs和UUCs的阈值,而是引入了一些控制相应类中子类数量的阈值. ...
Weightless neural networks for open set recognition
3
2017
... 其中,分别表示需要被识别的类别数(即该类样本经过分类器可以分到正确的类别中)、训练集中的类别数以及测试集中的类别数.式(1)中,O的值越大表示问题的开放程度越高,则是封闭环境下的问题.但是Scheirer et al[10]没有给出之间的关系,而文献[12,14-16]使用了一个假设.在进一步的研究中,Cardoso et al[17]给出了更加接近真实情况的假设,但这样的假设中很容易出现的情况,这显然是不合理的.为解决这个问题,Geng et al[11]重新给出开放性的定义: ...
... Cardoso et al[17]提出基于失重神经网络模型的精细距离计算的OSR方法,利用对未知数据和存储的知识之间的相似性进行分级的分类器,从训练样本中计算出对不属于任何KKCs的观测值的相似性的估计,此估计值用于定义属于KKCs的观测值和可能的异常值之间的边界.这种相似性等级类似于后验概率,但不依赖于关于类的先验概率分布的假设.Yoshihashi et al[52]将有监督的分类网络和无监督的重构网络联合起来提出CROSR (Classification⁃Reconstruction Learning for OSR)算法,利用重构过程中的潜在表示,补充在有监督分类过程中丢失的一些特征.这些特征可能对KKCs的分类不重要,但可能是区别KKCs与UUCs的关键,补充重构特征可以更好地区分KKCs和UUCs样本.Hassen and Chan[53]也提出一种表示,在这个表示中,来自同一类的样本彼此靠近,来自不同类的样本相对疏远.算法选择深度神经网络的最后一层线性层(将该层的输出作为SoftMax层的输入)的输出作为输入样本的投影表示,在此表示空间,利用基于距离的损失函数,增大不同类样本之间的距离,减小同一类样本之间的距离.虽然有大量的算法寻找一个合适的表示方法去区分KKCs和UUCs,但是由于每个任务中KKCs与UUCs判别信息差异比较大,这对研究者来说仍然是一项挑战. ...
An embarrassingly simple approach to zero?shot learning
1
2015
... 2009年,Palatucci et al[7]正式提出零样本学习(ZSL)的概念,此后有大量的工作在语义空间[18-22]或嵌入空间[23-25]对零样本学习进行了研究.虽然零样本学习已经比以前的封闭环境下分类的设定更加现实,但是辅助信息的获取不是一个容易的过程,大量的属性都是通过人工标注的形式获取.并且零样本学习只考虑了测试集包含UKCs的状况,而在真实的情况下,无法提前知道测试样本是属于KKCs还是UKCs,这也进一步延伸出G⁃ZSL问题[26]. ...
Semantic autoencoder for zero?shot learning
0
2017
Improving semantic embedding consistency by metric learning for zero?shot classiffication
0
2016
Zero?shot learning by convex combination of semantic embeddings
0
2014
Zero?shot learning via semantic similarity embedding
1
2015
... 2009年,Palatucci et al[7]正式提出零样本学习(ZSL)的概念,此后有大量的工作在语义空间[18-22]或嵌入空间[23-25]对零样本学习进行了研究.虽然零样本学习已经比以前的封闭环境下分类的设定更加现实,但是辅助信息的获取不是一个容易的过程,大量的属性都是通过人工标注的形式获取.并且零样本学习只考虑了测试集包含UKCs的状况,而在真实的情况下,无法提前知道测试样本是属于KKCs还是UKCs,这也进一步延伸出G⁃ZSL问题[26]. ...
Learning a deep embedding model for zero?shot learning
1
2017
... 2009年,Palatucci et al[7]正式提出零样本学习(ZSL)的概念,此后有大量的工作在语义空间[18-22]或嵌入空间[23-25]对零样本学习进行了研究.虽然零样本学习已经比以前的封闭环境下分类的设定更加现实,但是辅助信息的获取不是一个容易的过程,大量的属性都是通过人工标注的形式获取.并且零样本学习只考虑了测试集包含UKCs的状况,而在真实的情况下,无法提前知道测试样本是属于KKCs还是UKCs,这也进一步延伸出G⁃ZSL问题[26]. ...
DeViSE:A deep visual?semantic embedding model
0
2013
Label?embedding for attribute?based classification
1
2013
... 2009年,Palatucci et al[7]正式提出零样本学习(ZSL)的概念,此后有大量的工作在语义空间[18-22]或嵌入空间[23-25]对零样本学习进行了研究.虽然零样本学习已经比以前的封闭环境下分类的设定更加现实,但是辅助信息的获取不是一个容易的过程,大量的属性都是通过人工标注的形式获取.并且零样本学习只考虑了测试集包含UKCs的状况,而在真实的情况下,无法提前知道测试样本是属于KKCs还是UKCs,这也进一步延伸出G⁃ZSL问题[26]. ...
An empirical study and analysis of generalized zero?shot learning for object recognition in the wild
1
2016
... 2009年,Palatucci et al[7]正式提出零样本学习(ZSL)的概念,此后有大量的工作在语义空间[18-22]或嵌入空间[23-25]对零样本学习进行了研究.虽然零样本学习已经比以前的封闭环境下分类的设定更加现实,但是辅助信息的获取不是一个容易的过程,大量的属性都是通过人工标注的形式获取.并且零样本学习只考虑了测试集包含UKCs的状况,而在真实的情况下,无法提前知道测试样本是属于KKCs还是UKCs,这也进一步延伸出G⁃ZSL问题[26]. ...
Multi?class open set recognition using probability of inclusion
4
2014
... 一类样本分类问题[27-29]专门用来应对测试集中出现新类的情况.在测试过程中可以使用一类样本分类器识别样本是否属于KKCs,这也属于异常值检测问题,其最终的目的是拒绝不属于KKCs的类.但是,可以发现一类样本分类问题在分类的过程中将所有的KKCs都当成一类,也就是说,分类器虽然可以识别UUCs,但不能把KKCs中的类别分开(图1中的数字类“1”“2”“3”“4”“5”看作一类)[27-28].针对无法分类KKCs的情况,Tax and Duin[29]提出对每个KKC都建立一个一类分类器,但是最终效果并不理想.一类分类问题的出现,一定程度上为OSR问题的提出奠定了基础. ...
... [27-28].针对无法分类KKCs的情况,Tax and Duin[29]提出对每个KKC都建立一个一类分类器,但是最终效果并不理想.一类分类问题的出现,一定程度上为OSR问题的提出奠定了基础. ...
... 如果算法可以准确地对任何KKCs的正样本建模而不出现过拟合的情况,那么即使存在UUCs,算法也可以有效拒绝UUCs.基于这一思想,Jain et al[27]提出PI⁃SVM算法.PI⁃SVM是以多分类SVM为基础,并用EVT对决策边界上的正训练样本进行建模.PI⁃SVM与W⁃SVM一样是基于阈值的方法,但是基于阈值的方法有几点限制:首先,这种基于阈值的方法通常假设对于所有KKCs阈值都是一样的,这显然不合理;其次,阈值的设定与开放性相关,但在开放环境中UUCs的先验知识很难获得;最后,有些阈值的设定是根据经验确定的,缺乏理论支持.因此,这种思想在开放集的效果上受到一定的局限. ...
... Results of OSR based the non⁃depth featureTable 2
Method
LETTER(O*=0%)
LETTER (O*=25.46%)
YALEB (O*=0%)
YALEB (O*=23.30%)
EVT (y/n)
1⁃vs⁃set[10]
81.51±3.94
42.08±2.63
87.99±2.42
49.36±1.96
n
W⁃SVM[34]
95.64±0.25
85.72±0.85
86.01±2.42
84.56±2.19
y
PI⁃SVM[27]
96.92±0.36
84.16±1.01
93.47±2.74
88.96±1.16
y
SROSR[14]
84.21±2.49
66.50±8.22
88.09±3.41
83.99±4.19
y
OSNN[66]
83.12±17.41
64.97±13.75
81.81±8.40
72.90±9.41
y
EVM[79]
96.59±0.50
82.81±2.42
68.94±6.47
54.40±5.77
y
CD⁃OSR[36]
96.94±1.36
86.21±1.46
89.75±1.15
88.00±2.19
n
基于深度特征的开放集识别算法结果 ...
Kernel null space methods for novelty detection
1
2013
... 一类样本分类问题[27-29]专门用来应对测试集中出现新类的情况.在测试过程中可以使用一类样本分类器识别样本是否属于KKCs,这也属于异常值检测问题,其最终的目的是拒绝不属于KKCs的类.但是,可以发现一类样本分类问题在分类的过程中将所有的KKCs都当成一类,也就是说,分类器虽然可以识别UUCs,但不能把KKCs中的类别分开(图1中的数字类“1”“2”“3”“4”“5”看作一类)[27-28].针对无法分类KKCs的情况,Tax and Duin[29]提出对每个KKC都建立一个一类分类器,但是最终效果并不理想.一类分类问题的出现,一定程度上为OSR问题的提出奠定了基础. ...
Growing a multi?class classifier with a reject option
2
2008
... 一类样本分类问题[27-29]专门用来应对测试集中出现新类的情况.在测试过程中可以使用一类样本分类器识别样本是否属于KKCs,这也属于异常值检测问题,其最终的目的是拒绝不属于KKCs的类.但是,可以发现一类样本分类问题在分类的过程中将所有的KKCs都当成一类,也就是说,分类器虽然可以识别UUCs,但不能把KKCs中的类别分开(图1中的数字类“1”“2”“3”“4”“5”看作一类)[27-28].针对无法分类KKCs的情况,Tax and Duin[29]提出对每个KKC都建立一个一类分类器,但是最终效果并不理想.一类分类问题的出现,一定程度上为OSR问题的提出奠定了基础. ...
... 开放世界识别是OSR的一个扩展.通常情况下,OSR是个静态的集合概念,但是,为了更加接近现实情况中环境的不断变化,数据集应该是动态的,系统必须不断检测并添加新的类别.因此,Bendale and Boult[30]提出开放世界识别的概念,希望解决开放世界识别的系统一共能完成三个过程:首先,该系统能够检测新类(UUCs),即OSR的问题;其次,对识别的新类(UUCs)进行标记并选择合适的新类(UUCs)将其加入到已知类(KKCs)中;最后是一个增量学习的阶段,根据更新的已知类(KKCs)数据集对之前的模型进行一个更新.当然,这些过程应该是自动完成的.虽然这里将开放世界识别问题当作一个单独的问题进行描述,但是因为它相当于给OSR问题提供了一个更好的研究方向,并且其本身解决了OSR的问题,因此,针对开放世界问题的算法也会总结到下一节OSR算法中. ...
... 距离是衡量相似度的一个重要指标,但是传统的基于距离的分类器在开放环境下的分类效果并不理想.因此,Bendale and Boult[30]通过扩展NCM (Nearest Class Mean)分类器[45-46],提出最近非离群点算法(Nearest Non⁃Outlier,NNO).NNO根据测试样本与KKCs均值之间的距离进行分类,并且只有当所有分类器都拒绝测试样本时,该测试样本才会被拒绝.为优化距离的计算,研究者也做出了许多努力.在人脸识别任务中,对于未知样本会提供一个图像集合(Query Set)用来识别结果;同样,每个已知类样本也形成一个图像集(Gallery Images Set).Cevikalp and Yavuz[65]提出一个快速和准确地计算Query Set与Gallery Set之间距离的方法Polyhedral Conic Classifier,可以通过简单的点乘高效地计算距离. ...
... 在开放世界识别框架[30]中,为了使研究环境发生动态变化而更加接近现实世界,研究者递增地向系统增加新类和检测来自UUCs的样本,同时不断地更新KKCs的模型.更新模型的过程中会出现一个非常现实的问题:每当有新的样本出现时模型就需要从头训练,这将是一个计算量巨大、消耗过度的过程,更严重的是,由于UUCs样本数量过少,重新训练的模型很大程度上会出现过拟合的现象.在此基础上,研究者希望系统具有增量学习的特性,即每当检测出新类样本时,更新模型不需要重新训练,只需在原来的基础上进行调整,这样能降低整个模型的训练成本.De Rosa et al[78]提出采用在线增量学习的方式对三种非参算法进行扩展,并且制定了在线的度量学习和阈值增量更新算法.其中,算法对NNO[30]进行扩展,进行置信度和阈值的更新: ...
... 式(6)包括了过度泛化风险以及过度专业化风险,这充分保障出现新类时模型会减小开放空间风险以及平衡经验风险.表示各自对应平面的边缘距离,表示两个超平面之间的距离(这个距离可以包含所有的正样本数据),对应两个边缘空间,是人为定义的两个权重参数.使用新加的超平面可以有效限制KKCs占有的空间,测试样本如果在两个超平面之间就可以被分到正确的类别中,否则将根据样本靠近的超平面界限去划分到其他KKCs或者UUCs中.该算法本质上是针对开放集特性利用超平面限制KKCs空间过度占用.与此想法相似,Cevikalp[32]提出使用最佳拟合平面算法来使每个超平面接近某一类样本,远离其他类样本.Cevikalp and Triggs[33]提出一组准线性多面体二次曲线判别算子,它的正样本区域是L1球型.这类线性算子可以通过非对称分类器为某类正样本生成更加紧凑、约束良好的决策边界. ...
Polyhedral conic classifiers for visual object detection and classification
1
2017
... 式(6)包括了过度泛化风险以及过度专业化风险,这充分保障出现新类时模型会减小开放空间风险以及平衡经验风险.表示各自对应平面的边缘距离,表示两个超平面之间的距离(这个距离可以包含所有的正样本数据),对应两个边缘空间,是人为定义的两个权重参数.使用新加的超平面可以有效限制KKCs占有的空间,测试样本如果在两个超平面之间就可以被分到正确的类别中,否则将根据样本靠近的超平面界限去划分到其他KKCs或者UUCs中.该算法本质上是针对开放集特性利用超平面限制KKCs空间过度占用.与此想法相似,Cevikalp[32]提出使用最佳拟合平面算法来使每个超平面接近某一类样本,远离其他类样本.Cevikalp and Triggs[33]提出一组准线性多面体二次曲线判别算子,它的正样本区域是L1球型.这类线性算子可以通过非对称分类器为某类正样本生成更加紧凑、约束良好的决策边界. ...
3
2000
... Scheirer et al[10]的算法虽然能减小KKCs占据的空间,但这只是相对减小,每一类KKC占据的空间仍然是无界的.Scheirer et al[12]尝试将非线性核函数引入算法,通过用有限测度对样本进行标记来进一步限制开放空间风险.之前的算法适用于解决开放环境中的单类识别问题,因此进一步在1⁃vs⁃set的基础上提出针对开放环境中的多类识别问题[12].具体地,针对OSR问题提出紧凑衰减概率(Compact Abating Probability,CAP)模型[12],在该模型中,越靠近开放空间的样本属于此KKC的概率越低.同时,利用CAP模型和EVT理论[34]进行概率估计,提出韦伯校准SVM (Weibull⁃calibrated SVM,W⁃SVM)[12].该方法由一元SVM和二元SVM组成.样本首先经过第一个结合CAP的一元SVM模型产生一个后验概率,如果这个概率小于阈值,样本就会被拒绝.否则,样本会经过第二个结合CAP的二元SVM,产生一个对应KKC正样本的后验概率(基于韦伯分布)和一个KKC负样本的后验概率(基于逆韦伯分布).将问题进行形式定义一个指标变量: ...
... Results of OSR based the non⁃depth featureTable 2
Method
LETTER(O*=0%)
LETTER (O*=25.46%)
YALEB (O*=0%)
YALEB (O*=23.30%)
EVT (y/n)
1⁃vs⁃set[10]
81.51±3.94
42.08±2.63
87.99±2.42
49.36±1.96
n
W⁃SVM[34]
95.64±0.25
85.72±0.85
86.01±2.42
84.56±2.19
y
PI⁃SVM[27]
96.92±0.36
84.16±1.01
93.47±2.74
88.96±1.16
y
SROSR[14]
84.21±2.49
66.50±8.22
88.09±3.41
83.99±4.19
y
OSNN[66]
83.12±17.41
64.97±13.75
81.81±8.40
72.90±9.41
y
EVM[79]
96.59±0.50
82.81±2.42
68.94±6.47
54.40±5.77
y
CD⁃OSR[36]
96.94±1.36
86.21±1.46
89.75±1.15
88.00±2.19
n
基于深度特征的开放集识别算法结果 ...
Open set recognition for automatic target classification with rejection
2
2016
... 为了突破现有的基于阈值方法的局限性,Scherreik and Rigling[35]引入POS⁃SVM分类器,该分类器根据定义2经验确定每个KKC的唯一拒绝阈值.Geng and Chen[16]提出基于HDP (Hierarchical Dirichlet Process)[36]的CD⁃OSR (Collective Decision⁃based OSR)模型,该算法不用设定分类KKCs和UUCs的阈值,而是引入了一些控制相应类中子类数量的阈值. ...
... 此外,Sokolova and Lapalme[98]提出对于F⁃measure来说,无论TN怎么改变其值都不会变化,但在OSR下TN是一个非常重要的变量.因此,Scherreik and Rigling[35]引入约登指数J来表示一个算法避免失败的能力[99],J越高代表这个算法越能避免失败. ...
A tutorial on Bayesian nonparametric models
2
2012
... 为了突破现有的基于阈值方法的局限性,Scherreik and Rigling[35]引入POS⁃SVM分类器,该分类器根据定义2经验确定每个KKC的唯一拒绝阈值.Geng and Chen[16]提出基于HDP (Hierarchical Dirichlet Process)[36]的CD⁃OSR (Collective Decision⁃based OSR)模型,该算法不用设定分类KKCs和UUCs的阈值,而是引入了一些控制相应类中子类数量的阈值. ...
... Results of OSR based the non⁃depth featureTable 2
Method
LETTER(O*=0%)
LETTER (O*=25.46%)
YALEB (O*=0%)
YALEB (O*=23.30%)
EVT (y/n)
1⁃vs⁃set[10]
81.51±3.94
42.08±2.63
87.99±2.42
49.36±1.96
n
W⁃SVM[34]
95.64±0.25
85.72±0.85
86.01±2.42
84.56±2.19
y
PI⁃SVM[27]
96.92±0.36
84.16±1.01
93.47±2.74
88.96±1.16
y
SROSR[14]
84.21±2.49
66.50±8.22
88.09±3.41
83.99±4.19
y
OSNN[66]
83.12±17.41
64.97±13.75
81.81±8.40
72.90±9.41
y
EVM[79]
96.59±0.50
82.81±2.42
68.94±6.47
54.40±5.77
y
CD⁃OSR[36]
96.94±1.36
86.21±1.46
89.75±1.15
88.00±2.19
n
基于深度特征的开放集识别算法结果 ...
Towa rds open?set face recognition using hashing functions
... Bendale and Boult[44]通过引入OpenMax层估计未知类的概率,提出一种适用于OSR的深度神经网络方法.具体地,首先,带有SoftMax层的深度神经网络通过最小化交叉熵损失函数进行训练,算法采用最近类平均的概念[45-46]将每个类表示为平均激活向量(MAV),激活向量的平均值(仅用正确分类的训练样本)位于该网络的倒数第二层.然后,计算所有正确分类正训练样本与相应类别MAV的距离,并将其用于拟合每个类别的单独韦伯分布.此外,根据韦伯分布拟合重新分配激活向量的值用于计算UUCs的伪激活,最后在这些新的重新分配的激活向量上再次使用SoftMax层计算KKCs和(伪)UUCs的类概率. ...
Distance?based image classification:Generalizing to new classes at near?zero cost
2
2013
... Bendale and Boult[44]通过引入OpenMax层估计未知类的概率,提出一种适用于OSR的深度神经网络方法.具体地,首先,带有SoftMax层的深度神经网络通过最小化交叉熵损失函数进行训练,算法采用最近类平均的概念[45-46]将每个类表示为平均激活向量(MAV),激活向量的平均值(仅用正确分类的训练样本)位于该网络的倒数第二层.然后,计算所有正确分类正训练样本与相应类别MAV的距离,并将其用于拟合每个类别的单独韦伯分布.此外,根据韦伯分布拟合重新分配激活向量的值用于计算UUCs的伪激活,最后在这些新的重新分配的激活向量上再次使用SoftMax层计算KKCs和(伪)UUCs的类概率. ...
... 距离是衡量相似度的一个重要指标,但是传统的基于距离的分类器在开放环境下的分类效果并不理想.因此,Bendale and Boult[30]通过扩展NCM (Nearest Class Mean)分类器[45-46],提出最近非离群点算法(Nearest Non⁃Outlier,NNO).NNO根据测试样本与KKCs均值之间的距离进行分类,并且只有当所有分类器都拒绝测试样本时,该测试样本才会被拒绝.为优化距离的计算,研究者也做出了许多努力.在人脸识别任务中,对于未知样本会提供一个图像集合(Query Set)用来识别结果;同样,每个已知类样本也形成一个图像集(Gallery Images Set).Cevikalp and Yavuz[65]提出一个快速和准确地计算Query Set与Gallery Set之间距离的方法Polyhedral Conic Classifier,可以通过简单的点乘高效地计算距离. ...
Incremental learning of NCM forests for large?scale image classification
2
2014
... Bendale and Boult[44]通过引入OpenMax层估计未知类的概率,提出一种适用于OSR的深度神经网络方法.具体地,首先,带有SoftMax层的深度神经网络通过最小化交叉熵损失函数进行训练,算法采用最近类平均的概念[45-46]将每个类表示为平均激活向量(MAV),激活向量的平均值(仅用正确分类的训练样本)位于该网络的倒数第二层.然后,计算所有正确分类正训练样本与相应类别MAV的距离,并将其用于拟合每个类别的单独韦伯分布.此外,根据韦伯分布拟合重新分配激活向量的值用于计算UUCs的伪激活,最后在这些新的重新分配的激活向量上再次使用SoftMax层计算KKCs和(伪)UUCs的类概率. ...
... 距离是衡量相似度的一个重要指标,但是传统的基于距离的分类器在开放环境下的分类效果并不理想.因此,Bendale and Boult[30]通过扩展NCM (Nearest Class Mean)分类器[45-46],提出最近非离群点算法(Nearest Non⁃Outlier,NNO).NNO根据测试样本与KKCs均值之间的距离进行分类,并且只有当所有分类器都拒绝测试样本时,该测试样本才会被拒绝.为优化距离的计算,研究者也做出了许多努力.在人脸识别任务中,对于未知样本会提供一个图像集合(Query Set)用来识别结果;同样,每个已知类样本也形成一个图像集(Gallery Images Set).Cevikalp and Yavuz[65]提出一个快速和准确地计算Query Set与Gallery Set之间距离的方法Polyhedral Conic Classifier,可以通过简单的点乘高效地计算距离. ...
Adversarial robustness:Softmax versus openmax
1
2017
... 使用OpenMax可以自动拒绝许多开放环境下的UUCs样本及Fooling样本,但Rozsa et al[47]认为OpenMax与SoftMax一样容易受到比较复杂生成对抗技术的影响,因为这些技术直接作用于深层的表示.因此,深层表示的改进也能促进OSR的发展.基于深层表示的方法在下一小节进行详细的描述. ...
2
2018
... 此外,Venkataram[48]将OpenMax引入文本分类的研究,解决了开放环境下的文本分类任务.同样用于文本分类,Shu et al[49]认为OpenMax是通过减少每个已知类的开放空间达到拒绝未知类的目的,这种拒绝方式很薄弱,因此提出一个深度开放分类器(DOC)模型.DOC模型用1⁃vs⁃rest层(包含对应可见类的所有sigmod函数)代替OpenMax层,这给所有其他类(其余可见类和未见类)提供了一个合理的表示,使每一类形成一个合理的边界.并且,算法用高斯拟合收紧决策边界,可以进一步降低被拒绝的开放空间风险. ...
... 基于增量的OSR思想也用于深度神经网络中,Venkataram[48]提出基于卷积神经网络的增量开放集算法,实验证明该算法能够处理UUCs的文本文档.Shu et al[75]设计了原型学习深度网络,该网络在检测到UUCs样本之后,手动地对样本进行标注,并利用这些标注好的UUCs样本对网络进行更新.网络的分类器会根据新样本和原型之间的距离分布进行初始化,具体的过程:首先,计算新样本和原型之间的距离分布,然后利用均值归一化得到一个权值分布,最后根据权值分布对新的预测器进行权重初始化.每一类在网络中新的权重更新为: ...
DOC:Deep open classification of text documents
1
2017
... 此外,Venkataram[48]将OpenMax引入文本分类的研究,解决了开放环境下的文本分类任务.同样用于文本分类,Shu et al[49]认为OpenMax是通过减少每个已知类的开放空间达到拒绝未知类的目的,这种拒绝方式很薄弱,因此提出一个深度开放分类器(DOC)模型.DOC模型用1⁃vs⁃rest层(包含对应可见类的所有sigmod函数)代替OpenMax层,这给所有其他类(其余可见类和未见类)提供了一个合理的表示,使每一类形成一个合理的边界.并且,算法用高斯拟合收紧决策边界,可以进一步降低被拒绝的开放空间风险. ...
Convolutional prototype network for open set recognition
1
2020
... Yang et al[50]提出卷积原型网络(Convolutional Prototype Network,CPN),其中,卷积神经网络继续用于表示学习,但在最终输出类别概率时,CPN用原型模型代替之前的SoftMax层,并设计了新的判别损失和生成损失,从而达到增大类间距离并减小类内距离. ...
Hybrid models for open set recognition
1
2020
... OSR的方法大多是从KKCs的角度出发,在训练样本的嵌入空间上拟合一个概率分布,并根据这个概率分布检测异常值.这种方式对KKCs的分类比较有效,但对UUCs的识别效果一般.Zhang et al[51]引入一个基于流的密度估计器来进一步检测样本是否属于UUCs. ...
Classification?reconstruction learning for open?set recognition
... Cardoso et al[17]提出基于失重神经网络模型的精细距离计算的OSR方法,利用对未知数据和存储的知识之间的相似性进行分级的分类器,从训练样本中计算出对不属于任何KKCs的观测值的相似性的估计,此估计值用于定义属于KKCs的观测值和可能的异常值之间的边界.这种相似性等级类似于后验概率,但不依赖于关于类的先验概率分布的假设.Yoshihashi et al[52]将有监督的分类网络和无监督的重构网络联合起来提出CROSR (Classification⁃Reconstruction Learning for OSR)算法,利用重构过程中的潜在表示,补充在有监督分类过程中丢失的一些特征.这些特征可能对KKCs的分类不重要,但可能是区别KKCs与UUCs的关键,补充重构特征可以更好地区分KKCs和UUCs样本.Hassen and Chan[53]也提出一种表示,在这个表示中,来自同一类的样本彼此靠近,来自不同类的样本相对疏远.算法选择深度神经网络的最后一层线性层(将该层的输出作为SoftMax层的输入)的输出作为输入样本的投影表示,在此表示空间,利用基于距离的损失函数,增大不同类样本之间的距离,减小同一类样本之间的距离.虽然有大量的算法寻找一个合适的表示方法去区分KKCs和UUCs,但是由于每个任务中KKCs与UUCs判别信息差异比较大,这对研究者来说仍然是一项挑战. ...
... Cardoso et al[17]提出基于失重神经网络模型的精细距离计算的OSR方法,利用对未知数据和存储的知识之间的相似性进行分级的分类器,从训练样本中计算出对不属于任何KKCs的观测值的相似性的估计,此估计值用于定义属于KKCs的观测值和可能的异常值之间的边界.这种相似性等级类似于后验概率,但不依赖于关于类的先验概率分布的假设.Yoshihashi et al[52]将有监督的分类网络和无监督的重构网络联合起来提出CROSR (Classification⁃Reconstruction Learning for OSR)算法,利用重构过程中的潜在表示,补充在有监督分类过程中丢失的一些特征.这些特征可能对KKCs的分类不重要,但可能是区别KKCs与UUCs的关键,补充重构特征可以更好地区分KKCs和UUCs样本.Hassen and Chan[53]也提出一种表示,在这个表示中,来自同一类的样本彼此靠近,来自不同类的样本相对疏远.算法选择深度神经网络的最后一层线性层(将该层的输出作为SoftMax层的输入)的输出作为输入样本的投影表示,在此表示空间,利用基于距离的损失函数,增大不同类样本之间的距离,减小同一类样本之间的距离.虽然有大量的算法寻找一个合适的表示方法去区分KKCs和UUCs,但是由于每个任务中KKCs与UUCs判别信息差异比较大,这对研究者来说仍然是一项挑战. ...
... 上述方法都是基于传统机器学习的度量OSR方法,其实在深度学习方法中也有基于度量问题的OSR算法.在开放环境下,通常希望利用深度学习使样本的特征表示有两种特性:一是使来自同一类别的样本彼此靠近;二是使来自不同类别的样本相隔比较远.基于这个思想,Hassen and Chan[53]提出一种基于神经网络的表示方法和一种基于度量的损失函数解决OSR问题.该损失函数在训练过程中或者计算异常值得分时不用转换度量函数,都使用同一个距离函数进行度量.Mayer and Drummond[67]强调深度度量学习[68-74]在OSR的重要性.深度度量学习不同于传统的分类模型,利用带有SoftMax分类器的CNN,深度度量学习算法学习从图像空间到特征嵌入空间的转换,其中度量距离特指语义相似度.文献[68-74]的工作展示了深度度量学习强大的迁移能力并解释了样本特征是基于类的,即使这些类不在训练样本的分布中.此外,Shu et al[75]提出一种基于原型的开放式深度网络用于OSR任务,即通过使用原型模块和原型半径模块训练类别和原型半径的原型,将原型学习引入到OSR任务中,然后采用基于原型的距离度量方法检测未知类.基于样本与所有原型之间的统计信息,即样本与所有原型之间的距离,一定程度上打破了Júnior et al[66]的NNDR算法只选择不同两类的限制,不容易受到异常值的影响.基于原型的方法旨在寻找每个类的原型点,即所有属于这类的样本点与该原型点距离尽可能近.Chen et al[76]提出不同的想法,探索类以外的空间,并提出反向点(Reciprocal Points)的概念代表每个额外类空间,借助这些反向点,间接地将未知信息引入只有KKCs的学习,从而学习更紧凑、更具区别性的表征.Chen et al[77]还进一步对上述方法进行改进,并进行了丰富的实验验证. ...
Conditional gaussian distribution learning for open set recognition
1
2020
... 变分自动编码器(Variational Auto⁃Encoder,AE)作为一种能够有效识别UUCs的手段被广泛应用,但它不能对KKCs提供有区别的表示.Sun et al[54]提出一种新方法:条件高斯分布学习(Conditional Gaussian Distribution Learning,CGDL),在VAE的基础上,除了有效检测UUCs,还通过强制不同的潜在特征来逼近不同的高斯模型,对已知样本进行分类.Perera et al[55]使用自监督方法捕获更高级的特征,如语义和结构属性,这给KKCs和UUCs的识别带来了更多的有用信息. ...
Generative?discriminative feature representations for openset recognition
1
2020
... 变分自动编码器(Variational Auto⁃Encoder,AE)作为一种能够有效识别UUCs的手段被广泛应用,但它不能对KKCs提供有区别的表示.Sun et al[54]提出一种新方法:条件高斯分布学习(Conditional Gaussian Distribution Learning,CGDL),在VAE的基础上,除了有效检测UUCs,还通过强制不同的潜在特征来逼近不同的高斯模型,对已知样本进行分类.Perera et al[55]使用自监督方法捕获更高级的特征,如语义和结构属性,这给KKCs和UUCs的识别带来了更多的有用信息. ...
Generative OpenMax for multi?class open set classification
3
2017
... 在以前的许多方法中,UUCs是根据特征或对KKCs的决策距离进行判断,没有对UUCs进行直接表示.并且,OpenMax方法虽然根据KKCs的激活分数估计了UUCs的伪概率,达到拒绝效果,但实质上没有考虑UUCs的先验知识.因此,为了能显式地对UUCs进行建模和决策得分,Ge et al[56]提出新的算法G⁃OpenMax,对OpenMax方法进行扩展,利用GANs合成新的类别图像直接估计UUCs概率,合成样本是由潜在空间中KKCs的混合分布生成.这种方法不仅克服了伪概率估计的不足,还能可视化KKCs样本和UUCs样本.但实验证明,G⁃OpenMax虽然可以在单色数据集上提高OSR的性能,却在自然图像上性能没有明显提升. ...
... 使用生成对抗思想可以很好地进行数据扩充,Neal et al[57]借助GANs对训练集样本进行扩充,提出了反事实图像生成(Open Set Learning with Counterfactual Images,OSRCI).OSRCI用一个编码⁃解码的生成对抗网络生成合成的开放集样本,这些样本很接近KKCs但不属于任何KKC.采用这种数据扩充的方式,还进一步把OSR问题定义为多加了UUCs一类的分类器问题.使用生成对抗网络不仅能生成负样本,还可以生成正样本进行数据扩充.Yu et al[58]提出对抗样本生成(Adversarial Sample Generation,ASG)框架,不仅可以生成KKCs的负样本作为UUCs样本,同时,如果KKCs样本比较少的话,也可以产生KKCs的正样本.从上述工作可以看出,研究者付出了很多努力来构建一个负样本集或为目标集设置一个最优阈值.在最近的工作中,Yang et al[15]基于GANs,用生成器生成与目标样本高度相似的样本并自动作为负的样本集,还重新设计了判别器以输出多个类别和一个UUCs.Ditria et al[59]提出一种开放集GAN体系结构(OpenGAN),为每个输入样本嵌入一个来自度量空间的特征.使用类别等级和细粒度语义信息的最先进的度量学习模型,能够生成在语义上与给定的源图像相似的样本.由度量学习模型提取的语义信息转移到分布之外的新类,允许生成模型生成不在训练分布之外的样本,通过这种方式,便可产生高质量的图像样本. ...
... 由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
... (3)AUROC (Area Under the ROC Curve):开放环境的开放性是不确定的,因此需要选择直接表示分类器性能好坏的指标AUROC[57],它提供检测算法性能的无校准测量,能表示从UUCs类别很少到UUCs类别占大多数的所有情况.目前,AUROC是OSR工作中最常用的评价指标. ...
Open?category classification by adversarial sample generation
2
2017
... 使用生成对抗思想可以很好地进行数据扩充,Neal et al[57]借助GANs对训练集样本进行扩充,提出了反事实图像生成(Open Set Learning with Counterfactual Images,OSRCI).OSRCI用一个编码⁃解码的生成对抗网络生成合成的开放集样本,这些样本很接近KKCs但不属于任何KKC.采用这种数据扩充的方式,还进一步把OSR问题定义为多加了UUCs一类的分类器问题.使用生成对抗网络不仅能生成负样本,还可以生成正样本进行数据扩充.Yu et al[58]提出对抗样本生成(Adversarial Sample Generation,ASG)框架,不仅可以生成KKCs的负样本作为UUCs样本,同时,如果KKCs样本比较少的话,也可以产生KKCs的正样本.从上述工作可以看出,研究者付出了很多努力来构建一个负样本集或为目标集设置一个最优阈值.在最近的工作中,Yang et al[15]基于GANs,用生成器生成与目标样本高度相似的样本并自动作为负的样本集,还重新设计了判别器以输出多个类别和一个UUCs.Ditria et al[59]提出一种开放集GAN体系结构(OpenGAN),为每个输入样本嵌入一个来自度量空间的特征.使用类别等级和细粒度语义信息的最先进的度量学习模型,能够生成在语义上与给定的源图像相似的样本.由度量学习模型提取的语义信息转移到分布之外的新类,允许生成模型生成不在训练分布之外的样本,通过这种方式,便可产生高质量的图像样本. ...
... 使用生成对抗思想可以很好地进行数据扩充,Neal et al[57]借助GANs对训练集样本进行扩充,提出了反事实图像生成(Open Set Learning with Counterfactual Images,OSRCI).OSRCI用一个编码⁃解码的生成对抗网络生成合成的开放集样本,这些样本很接近KKCs但不属于任何KKC.采用这种数据扩充的方式,还进一步把OSR问题定义为多加了UUCs一类的分类器问题.使用生成对抗网络不仅能生成负样本,还可以生成正样本进行数据扩充.Yu et al[58]提出对抗样本生成(Adversarial Sample Generation,ASG)框架,不仅可以生成KKCs的负样本作为UUCs样本,同时,如果KKCs样本比较少的话,也可以产生KKCs的正样本.从上述工作可以看出,研究者付出了很多努力来构建一个负样本集或为目标集设置一个最优阈值.在最近的工作中,Yang et al[15]基于GANs,用生成器生成与目标样本高度相似的样本并自动作为负的样本集,还重新设计了判别器以输出多个类别和一个UUCs.Ditria et al[59]提出一种开放集GAN体系结构(OpenGAN),为每个输入样本嵌入一个来自度量空间的特征.使用类别等级和细粒度语义信息的最先进的度量学习模型,能够生成在语义上与给定的源图像相似的样本.由度量学习模型提取的语义信息转移到分布之外的新类,允许生成模型生成不在训练分布之外的样本,通过这种方式,便可产生高质量的图像样本. ...
Breaking the closed world assumption in text classification
1
2016
... Fei and Liu[60]将基于中心的相似度学习(Center⁃Based Similarity,CBS)[61]引入OSR模型,成功降低了模型的开放空间风险.具体地,在CBS算法中,对一个二分类的文本分类问题,将文本的特征向量 ...
Social media text classification under negative covariate shift
1
2015
... Fei and Liu[60]将基于中心的相似度学习(Center⁃Based Similarity,CBS)[61]引入OSR模型,成功降低了模型的开放空间风险.具体地,在CBS算法中,对一个二分类的文本分类问题,将文本的特征向量 ...
Sparse representation for computer vision and pattern recognition
1
2010
... 近年来,大量基于稀疏表示的分类与恢复算法[62-63]被提出.特别地,研究者对基于稀疏表示的分类算法(SRC)[64]进行了大量研究.为了适应OSR问题,Zhang and Patel[14]提出一种基于广义稀疏表示的分类算法SROSR (Sparse Representation⁃based Open Set Recognition),利用类重构误差进行分类.由于OSR的判别信息都隐藏在匹配重建误差分布和非匹配重建误差分布之和的尾部,作者引入统计极值理论对两种误差的分布的尾部进行建模.具体做法分为两步:第一步,用EVT对两个分布进行建模,将OSR问题化简为假设检验问题;第二步,计算测试样本的重建误差并融合基于两个尾部分布的置信度分数来确定测试样本的类别.实验证明,SROSR具有很强的解决OSR问题的能力. ...
Maximum likelihood estimation?based joint sparse representation for the classification of hyperspectral remote sensing images
1
2019
... 近年来,大量基于稀疏表示的分类与恢复算法[62-63]被提出.特别地,研究者对基于稀疏表示的分类算法(SRC)[64]进行了大量研究.为了适应OSR问题,Zhang and Patel[14]提出一种基于广义稀疏表示的分类算法SROSR (Sparse Representation⁃based Open Set Recognition),利用类重构误差进行分类.由于OSR的判别信息都隐藏在匹配重建误差分布和非匹配重建误差分布之和的尾部,作者引入统计极值理论对两种误差的分布的尾部进行建模.具体做法分为两步:第一步,用EVT对两个分布进行建模,将OSR问题化简为假设检验问题;第二步,计算测试样本的重建误差并融合基于两个尾部分布的置信度分数来确定测试样本的类别.实验证明,SROSR具有很强的解决OSR问题的能力. ...
Robust face recognition via sparse representation
1
2009
... 近年来,大量基于稀疏表示的分类与恢复算法[62-63]被提出.特别地,研究者对基于稀疏表示的分类算法(SRC)[64]进行了大量研究.为了适应OSR问题,Zhang and Patel[14]提出一种基于广义稀疏表示的分类算法SROSR (Sparse Representation⁃based Open Set Recognition),利用类重构误差进行分类.由于OSR的判别信息都隐藏在匹配重建误差分布和非匹配重建误差分布之和的尾部,作者引入统计极值理论对两种误差的分布的尾部进行建模.具体做法分为两步:第一步,用EVT对两个分布进行建模,将OSR问题化简为假设检验问题;第二步,计算测试样本的重建误差并融合基于两个尾部分布的置信度分数来确定测试样本的类别.实验证明,SROSR具有很强的解决OSR问题的能力. ...
Fast and accurate face recognition with image sets
1
2017
... 距离是衡量相似度的一个重要指标,但是传统的基于距离的分类器在开放环境下的分类效果并不理想.因此,Bendale and Boult[30]通过扩展NCM (Nearest Class Mean)分类器[45-46],提出最近非离群点算法(Nearest Non⁃Outlier,NNO).NNO根据测试样本与KKCs均值之间的距离进行分类,并且只有当所有分类器都拒绝测试样本时,该测试样本才会被拒绝.为优化距离的计算,研究者也做出了许多努力.在人脸识别任务中,对于未知样本会提供一个图像集合(Query Set)用来识别结果;同样,每个已知类样本也形成一个图像集(Gallery Images Set).Cevikalp and Yavuz[65]提出一个快速和准确地计算Query Set与Gallery Set之间距离的方法Polyhedral Conic Classifier,可以通过简单的点乘高效地计算距离. ...
Nearest neighbors distance ratio open?set classifier
5
2017
... 基于最近邻(NN)算法,Júnior et al[66]提出开放集最近邻(OSNN)方法,具体介绍了两种适应开放环境的NN分类器的扩展.第一种是OSNN类验证(OSNN Class Verification,OSNNcv),该方法的思想是在预测阶段选出测试样本s的两个最近邻.如果两个具有相同的标签t,则把标签t分给测试样本s,否则测试样本会被分到UUCs当中.在这个算法中,如果测试样本离训练样本很远,则无法被分到UUCs当中,为了解决这个问题,使用最近邻距离比率算法(Nearest Neighbor Distance Ratio,NNDR).该方法的特点在于不是直接对某一最相似类的相似性得分设置阈值,而是对两个最相似类的相似性得分比率设置阈值.测试样本s两个不同的最近邻u和t,计算,如果R小于阈值τ,s被分为和t相同的标签,否则就会被分到UUCs.该方法也存在一个固有的缺点,因为只选择来自不同类的两个参考样本进行比较,所以当有异常值存在时,该方法的效果会受到很大的影响. ...
... 上述方法都是基于传统机器学习的度量OSR方法,其实在深度学习方法中也有基于度量问题的OSR算法.在开放环境下,通常希望利用深度学习使样本的特征表示有两种特性:一是使来自同一类别的样本彼此靠近;二是使来自不同类别的样本相隔比较远.基于这个思想,Hassen and Chan[53]提出一种基于神经网络的表示方法和一种基于度量的损失函数解决OSR问题.该损失函数在训练过程中或者计算异常值得分时不用转换度量函数,都使用同一个距离函数进行度量.Mayer and Drummond[67]强调深度度量学习[68-74]在OSR的重要性.深度度量学习不同于传统的分类模型,利用带有SoftMax分类器的CNN,深度度量学习算法学习从图像空间到特征嵌入空间的转换,其中度量距离特指语义相似度.文献[68-74]的工作展示了深度度量学习强大的迁移能力并解释了样本特征是基于类的,即使这些类不在训练样本的分布中.此外,Shu et al[75]提出一种基于原型的开放式深度网络用于OSR任务,即通过使用原型模块和原型半径模块训练类别和原型半径的原型,将原型学习引入到OSR任务中,然后采用基于原型的距离度量方法检测未知类.基于样本与所有原型之间的统计信息,即样本与所有原型之间的距离,一定程度上打破了Júnior et al[66]的NNDR算法只选择不同两类的限制,不容易受到异常值的影响.基于原型的方法旨在寻找每个类的原型点,即所有属于这类的样本点与该原型点距离尽可能近.Chen et al[76]提出不同的想法,探索类以外的空间,并提出反向点(Reciprocal Points)的概念代表每个额外类空间,借助这些反向点,间接地将未知信息引入只有KKCs的学习,从而学习更紧凑、更具区别性的表征.Chen et al[77]还进一步对上述方法进行改进,并进行了丰富的实验验证. ...
... 上面在计算OSR准确率时是根据样本数量进行判断的,这样的评价指标无法显示分类器对于KKCs和UUCs的分类效果.训练一个分类器时,分类器会倾向于样本数量最多的类.在OSR中,如果UUCs的数量比较多,则分类器对UUCs的拒绝能力比较强(这种情况是成立的,随着环境开放性增大UUCs是未知的),上述的准确率也较高.但这种情况下,分类器对KKCs的分类判断显然是不合理的,因为KKCs的准确率可能很低.因此,Júnior et al[66]同时考虑KKCs的准确率和UUCs的准确率,给对应权重提出了标准化的准确率: ...
... F⁃measure对OSR的一个小扩展是将所有UUCs当作一个简单的类并以与封闭环境相同的方式获得其值,这种做法对于OSR测试的评价显然不正确.考虑下面的情况,所有UUCs的正确分类都被认为是正确的KKCs正样本分类,但这种分类结果没有任何意义,因为在训练过程中UUCs没有用于训练分类器.Júnior et al[66]在只考虑KKCs的基础上对精度和召回率的计算进行改进,从宏平均和微平均的角度进行计算: ...
... Results of OSR based the non⁃depth featureTable 2
Method
LETTER(O*=0%)
LETTER (O*=25.46%)
YALEB (O*=0%)
YALEB (O*=23.30%)
EVT (y/n)
1⁃vs⁃set[10]
81.51±3.94
42.08±2.63
87.99±2.42
49.36±1.96
n
W⁃SVM[34]
95.64±0.25
85.72±0.85
86.01±2.42
84.56±2.19
y
PI⁃SVM[27]
96.92±0.36
84.16±1.01
93.47±2.74
88.96±1.16
y
SROSR[14]
84.21±2.49
66.50±8.22
88.09±3.41
83.99±4.19
y
OSNN[66]
83.12±17.41
64.97±13.75
81.81±8.40
72.90±9.41
y
EVM[79]
96.59±0.50
82.81±2.42
68.94±6.47
54.40±5.77
y
CD⁃OSR[36]
96.94±1.36
86.21±1.46
89.75±1.15
88.00±2.19
n
基于深度特征的开放集识别算法结果 ...
The importance of metric learning for robotic vision:Open set recognition and active learning
1
2019
... 上述方法都是基于传统机器学习的度量OSR方法,其实在深度学习方法中也有基于度量问题的OSR算法.在开放环境下,通常希望利用深度学习使样本的特征表示有两种特性:一是使来自同一类别的样本彼此靠近;二是使来自不同类别的样本相隔比较远.基于这个思想,Hassen and Chan[53]提出一种基于神经网络的表示方法和一种基于度量的损失函数解决OSR问题.该损失函数在训练过程中或者计算异常值得分时不用转换度量函数,都使用同一个距离函数进行度量.Mayer and Drummond[67]强调深度度量学习[68-74]在OSR的重要性.深度度量学习不同于传统的分类模型,利用带有SoftMax分类器的CNN,深度度量学习算法学习从图像空间到特征嵌入空间的转换,其中度量距离特指语义相似度.文献[68-74]的工作展示了深度度量学习强大的迁移能力并解释了样本特征是基于类的,即使这些类不在训练样本的分布中.此外,Shu et al[75]提出一种基于原型的开放式深度网络用于OSR任务,即通过使用原型模块和原型半径模块训练类别和原型半径的原型,将原型学习引入到OSR任务中,然后采用基于原型的距离度量方法检测未知类.基于样本与所有原型之间的统计信息,即样本与所有原型之间的距离,一定程度上打破了Júnior et al[66]的NNDR算法只选择不同两类的限制,不容易受到异常值的影响.基于原型的方法旨在寻找每个类的原型点,即所有属于这类的样本点与该原型点距离尽可能近.Chen et al[76]提出不同的想法,探索类以外的空间,并提出反向点(Reciprocal Points)的概念代表每个额外类空间,借助这些反向点,间接地将未知信息引入只有KKCs的学习,从而学习更紧凑、更具区别性的表征.Chen et al[77]还进一步对上述方法进行改进,并进行了丰富的实验验证. ...
FaceNet:A unified embedding for face recognition and clustering
2
2015
... 上述方法都是基于传统机器学习的度量OSR方法,其实在深度学习方法中也有基于度量问题的OSR算法.在开放环境下,通常希望利用深度学习使样本的特征表示有两种特性:一是使来自同一类别的样本彼此靠近;二是使来自不同类别的样本相隔比较远.基于这个思想,Hassen and Chan[53]提出一种基于神经网络的表示方法和一种基于度量的损失函数解决OSR问题.该损失函数在训练过程中或者计算异常值得分时不用转换度量函数,都使用同一个距离函数进行度量.Mayer and Drummond[67]强调深度度量学习[68-74]在OSR的重要性.深度度量学习不同于传统的分类模型,利用带有SoftMax分类器的CNN,深度度量学习算法学习从图像空间到特征嵌入空间的转换,其中度量距离特指语义相似度.文献[68-74]的工作展示了深度度量学习强大的迁移能力并解释了样本特征是基于类的,即使这些类不在训练样本的分布中.此外,Shu et al[75]提出一种基于原型的开放式深度网络用于OSR任务,即通过使用原型模块和原型半径模块训练类别和原型半径的原型,将原型学习引入到OSR任务中,然后采用基于原型的距离度量方法检测未知类.基于样本与所有原型之间的统计信息,即样本与所有原型之间的距离,一定程度上打破了Júnior et al[66]的NNDR算法只选择不同两类的限制,不容易受到异常值的影响.基于原型的方法旨在寻找每个类的原型点,即所有属于这类的样本点与该原型点距离尽可能近.Chen et al[76]提出不同的想法,探索类以外的空间,并提出反向点(Reciprocal Points)的概念代表每个额外类空间,借助这些反向点,间接地将未知信息引入只有KKCs的学习,从而学习更紧凑、更具区别性的表征.Chen et al[77]还进一步对上述方法进行改进,并进行了丰富的实验验证. ...
... 在OSR的重要性.深度度量学习不同于传统的分类模型,利用带有SoftMax分类器的CNN,深度度量学习算法学习从图像空间到特征嵌入空间的转换,其中度量距离特指语义相似度.文献[68-74]的工作展示了深度度量学习强大的迁移能力并解释了样本特征是基于类的,即使这些类不在训练样本的分布中.此外,Shu et al[75]提出一种基于原型的开放式深度网络用于OSR任务,即通过使用原型模块和原型半径模块训练类别和原型半径的原型,将原型学习引入到OSR任务中,然后采用基于原型的距离度量方法检测未知类.基于样本与所有原型之间的统计信息,即样本与所有原型之间的距离,一定程度上打破了Júnior et al[66]的NNDR算法只选择不同两类的限制,不容易受到异常值的影响.基于原型的方法旨在寻找每个类的原型点,即所有属于这类的样本点与该原型点距离尽可能近.Chen et al[76]提出不同的想法,探索类以外的空间,并提出反向点(Reciprocal Points)的概念代表每个额外类空间,借助这些反向点,间接地将未知信息引入只有KKCs的学习,从而学习更紧凑、更具区别性的表征.Chen et al[77]还进一步对上述方法进行改进,并进行了丰富的实验验证. ...
Deep metric learning via lifted structured feature embedding
0
2016
Improved deep metric learning with multi?class N?pair loss objective
0
2016
Learning local image descriptors with deep siamese and triplet convolutional networks by minimizing global loss functions
0
2016
Learnable structured clustering framework for deep metric learning
0
2017
Smart mining for deep metric learning
0
2017
Deep metric learning and image classification with nearest neighbour gaussian kernels
2
2018
... 上述方法都是基于传统机器学习的度量OSR方法,其实在深度学习方法中也有基于度量问题的OSR算法.在开放环境下,通常希望利用深度学习使样本的特征表示有两种特性:一是使来自同一类别的样本彼此靠近;二是使来自不同类别的样本相隔比较远.基于这个思想,Hassen and Chan[53]提出一种基于神经网络的表示方法和一种基于度量的损失函数解决OSR问题.该损失函数在训练过程中或者计算异常值得分时不用转换度量函数,都使用同一个距离函数进行度量.Mayer and Drummond[67]强调深度度量学习[68-74]在OSR的重要性.深度度量学习不同于传统的分类模型,利用带有SoftMax分类器的CNN,深度度量学习算法学习从图像空间到特征嵌入空间的转换,其中度量距离特指语义相似度.文献[68-74]的工作展示了深度度量学习强大的迁移能力并解释了样本特征是基于类的,即使这些类不在训练样本的分布中.此外,Shu et al[75]提出一种基于原型的开放式深度网络用于OSR任务,即通过使用原型模块和原型半径模块训练类别和原型半径的原型,将原型学习引入到OSR任务中,然后采用基于原型的距离度量方法检测未知类.基于样本与所有原型之间的统计信息,即样本与所有原型之间的距离,一定程度上打破了Júnior et al[66]的NNDR算法只选择不同两类的限制,不容易受到异常值的影响.基于原型的方法旨在寻找每个类的原型点,即所有属于这类的样本点与该原型点距离尽可能近.Chen et al[76]提出不同的想法,探索类以外的空间,并提出反向点(Reciprocal Points)的概念代表每个额外类空间,借助这些反向点,间接地将未知信息引入只有KKCs的学习,从而学习更紧凑、更具区别性的表征.Chen et al[77]还进一步对上述方法进行改进,并进行了丰富的实验验证. ...
... -74]的工作展示了深度度量学习强大的迁移能力并解释了样本特征是基于类的,即使这些类不在训练样本的分布中.此外,Shu et al[75]提出一种基于原型的开放式深度网络用于OSR任务,即通过使用原型模块和原型半径模块训练类别和原型半径的原型,将原型学习引入到OSR任务中,然后采用基于原型的距离度量方法检测未知类.基于样本与所有原型之间的统计信息,即样本与所有原型之间的距离,一定程度上打破了Júnior et al[66]的NNDR算法只选择不同两类的限制,不容易受到异常值的影响.基于原型的方法旨在寻找每个类的原型点,即所有属于这类的样本点与该原型点距离尽可能近.Chen et al[76]提出不同的想法,探索类以外的空间,并提出反向点(Reciprocal Points)的概念代表每个额外类空间,借助这些反向点,间接地将未知信息引入只有KKCs的学习,从而学习更紧凑、更具区别性的表征.Chen et al[77]还进一步对上述方法进行改进,并进行了丰富的实验验证. ...
P?ODN:Prototype based open deep network for open set recognition
2
2020
... 上述方法都是基于传统机器学习的度量OSR方法,其实在深度学习方法中也有基于度量问题的OSR算法.在开放环境下,通常希望利用深度学习使样本的特征表示有两种特性:一是使来自同一类别的样本彼此靠近;二是使来自不同类别的样本相隔比较远.基于这个思想,Hassen and Chan[53]提出一种基于神经网络的表示方法和一种基于度量的损失函数解决OSR问题.该损失函数在训练过程中或者计算异常值得分时不用转换度量函数,都使用同一个距离函数进行度量.Mayer and Drummond[67]强调深度度量学习[68-74]在OSR的重要性.深度度量学习不同于传统的分类模型,利用带有SoftMax分类器的CNN,深度度量学习算法学习从图像空间到特征嵌入空间的转换,其中度量距离特指语义相似度.文献[68-74]的工作展示了深度度量学习强大的迁移能力并解释了样本特征是基于类的,即使这些类不在训练样本的分布中.此外,Shu et al[75]提出一种基于原型的开放式深度网络用于OSR任务,即通过使用原型模块和原型半径模块训练类别和原型半径的原型,将原型学习引入到OSR任务中,然后采用基于原型的距离度量方法检测未知类.基于样本与所有原型之间的统计信息,即样本与所有原型之间的距离,一定程度上打破了Júnior et al[66]的NNDR算法只选择不同两类的限制,不容易受到异常值的影响.基于原型的方法旨在寻找每个类的原型点,即所有属于这类的样本点与该原型点距离尽可能近.Chen et al[76]提出不同的想法,探索类以外的空间,并提出反向点(Reciprocal Points)的概念代表每个额外类空间,借助这些反向点,间接地将未知信息引入只有KKCs的学习,从而学习更紧凑、更具区别性的表征.Chen et al[77]还进一步对上述方法进行改进,并进行了丰富的实验验证. ...
... 基于增量的OSR思想也用于深度神经网络中,Venkataram[48]提出基于卷积神经网络的增量开放集算法,实验证明该算法能够处理UUCs的文本文档.Shu et al[75]设计了原型学习深度网络,该网络在检测到UUCs样本之后,手动地对样本进行标注,并利用这些标注好的UUCs样本对网络进行更新.网络的分类器会根据新样本和原型之间的距离分布进行初始化,具体的过程:首先,计算新样本和原型之间的距离分布,然后利用均值归一化得到一个权值分布,最后根据权值分布对新的预测器进行权重初始化.每一类在网络中新的权重更新为: ...
Adversarial reciprocal points learning for open set recognition
1
2021
... 上述方法都是基于传统机器学习的度量OSR方法,其实在深度学习方法中也有基于度量问题的OSR算法.在开放环境下,通常希望利用深度学习使样本的特征表示有两种特性:一是使来自同一类别的样本彼此靠近;二是使来自不同类别的样本相隔比较远.基于这个思想,Hassen and Chan[53]提出一种基于神经网络的表示方法和一种基于度量的损失函数解决OSR问题.该损失函数在训练过程中或者计算异常值得分时不用转换度量函数,都使用同一个距离函数进行度量.Mayer and Drummond[67]强调深度度量学习[68-74]在OSR的重要性.深度度量学习不同于传统的分类模型,利用带有SoftMax分类器的CNN,深度度量学习算法学习从图像空间到特征嵌入空间的转换,其中度量距离特指语义相似度.文献[68-74]的工作展示了深度度量学习强大的迁移能力并解释了样本特征是基于类的,即使这些类不在训练样本的分布中.此外,Shu et al[75]提出一种基于原型的开放式深度网络用于OSR任务,即通过使用原型模块和原型半径模块训练类别和原型半径的原型,将原型学习引入到OSR任务中,然后采用基于原型的距离度量方法检测未知类.基于样本与所有原型之间的统计信息,即样本与所有原型之间的距离,一定程度上打破了Júnior et al[66]的NNDR算法只选择不同两类的限制,不容易受到异常值的影响.基于原型的方法旨在寻找每个类的原型点,即所有属于这类的样本点与该原型点距离尽可能近.Chen et al[76]提出不同的想法,探索类以外的空间,并提出反向点(Reciprocal Points)的概念代表每个额外类空间,借助这些反向点,间接地将未知信息引入只有KKCs的学习,从而学习更紧凑、更具区别性的表征.Chen et al[77]还进一步对上述方法进行改进,并进行了丰富的实验验证. ...
Learning open set network with discriminative reciprocal points
1
2020
... 上述方法都是基于传统机器学习的度量OSR方法,其实在深度学习方法中也有基于度量问题的OSR算法.在开放环境下,通常希望利用深度学习使样本的特征表示有两种特性:一是使来自同一类别的样本彼此靠近;二是使来自不同类别的样本相隔比较远.基于这个思想,Hassen and Chan[53]提出一种基于神经网络的表示方法和一种基于度量的损失函数解决OSR问题.该损失函数在训练过程中或者计算异常值得分时不用转换度量函数,都使用同一个距离函数进行度量.Mayer and Drummond[67]强调深度度量学习[68-74]在OSR的重要性.深度度量学习不同于传统的分类模型,利用带有SoftMax分类器的CNN,深度度量学习算法学习从图像空间到特征嵌入空间的转换,其中度量距离特指语义相似度.文献[68-74]的工作展示了深度度量学习强大的迁移能力并解释了样本特征是基于类的,即使这些类不在训练样本的分布中.此外,Shu et al[75]提出一种基于原型的开放式深度网络用于OSR任务,即通过使用原型模块和原型半径模块训练类别和原型半径的原型,将原型学习引入到OSR任务中,然后采用基于原型的距离度量方法检测未知类.基于样本与所有原型之间的统计信息,即样本与所有原型之间的距离,一定程度上打破了Júnior et al[66]的NNDR算法只选择不同两类的限制,不容易受到异常值的影响.基于原型的方法旨在寻找每个类的原型点,即所有属于这类的样本点与该原型点距离尽可能近.Chen et al[76]提出不同的想法,探索类以外的空间,并提出反向点(Reciprocal Points)的概念代表每个额外类空间,借助这些反向点,间接地将未知信息引入只有KKCs的学习,从而学习更紧凑、更具区别性的表征.Chen et al[77]还进一步对上述方法进行改进,并进行了丰富的实验验证. ...
Online open world recognition
1
2016
... 在开放世界识别框架[30]中,为了使研究环境发生动态变化而更加接近现实世界,研究者递增地向系统增加新类和检测来自UUCs的样本,同时不断地更新KKCs的模型.更新模型的过程中会出现一个非常现实的问题:每当有新的样本出现时模型就需要从头训练,这将是一个计算量巨大、消耗过度的过程,更严重的是,由于UUCs样本数量过少,重新训练的模型很大程度上会出现过拟合的现象.在此基础上,研究者希望系统具有增量学习的特性,即每当检测出新类样本时,更新模型不需要重新训练,只需在原来的基础上进行调整,这样能降低整个模型的训练成本.De Rosa et al[78]提出采用在线增量学习的方式对三种非参算法进行扩展,并且制定了在线的度量学习和阈值增量更新算法.其中,算法对NNO[30]进行扩展,进行置信度和阈值的更新: ...
The extreme value machine
2
2018
... 基于这个重点,Rudd et al[79]提出EVM模型,该模型考虑分布信息,将EVT理论引入分类器的构造中以获得更加紧凑的统计模型.作为间隔分布理论从每个类公式到逐样本公式的扩展,EVM是根据样本点相对于参考点的样本半距离分布来建模的,具体包含以下定理: ...
... Results of OSR based the non⁃depth featureTable 2
Deep cnn?based multi?task learning for open?set recognition
1
2019
... 同时,EVT理论也用于其他算法中.由于OSR的判别信息都隐藏在匹配重建误差分布和非匹配重建误差分布之和的尾部,Zhang and Pater[14]的SROSR算法在基于广义稀疏表示上引入EVT理论对两种误差的分布的尾部进行建模.同样,Oza and Pater[82]提出一种新的基于深度卷积神经网络的OSR算法,该算法的解码器网络的重建误差被用于开放集的拒绝,为了提高整体性能也利用EVT对已知类的重建误差分布尾部进行建模.Mundt et al[83]还将EVT理论运用到分布外数据(OOD)检测,在能推出模型不确定性的深度神经网络的基础上,结合基于OSR的EVT算法,限制模型开放空间风险. ...
Open set recognition through deep neural network uncertainty:Does out?of?distribution detection require generative classifiers?
1
2019
... 同时,EVT理论也用于其他算法中.由于OSR的判别信息都隐藏在匹配重建误差分布和非匹配重建误差分布之和的尾部,Zhang and Pater[14]的SROSR算法在基于广义稀疏表示上引入EVT理论对两种误差的分布的尾部进行建模.同样,Oza and Pater[82]提出一种新的基于深度卷积神经网络的OSR算法,该算法的解码器网络的重建误差被用于开放集的拒绝,为了提高整体性能也利用EVT对已知类的重建误差分布尾部进行建模.Mundt et al[83]还将EVT理论运用到分布外数据(OOD)检测,在能推出模型不确定性的深度神经网络的基础上,结合基于OSR的EVT算法,限制模型开放空间风险. ...
Extreme value theory for open set classification:GPD and GEV classifiers
1
2019
... 虽然EVT理论被许多研究者引入解决OSR问题,但是,如果KKCs和UUCs的几何结构不同,简单的识别任务也会失败.为了克服这一局限,Vignotto and Engelke[84]提出两种新的算法,这两种算法的思想是采用不基于已知类几何表示的EVT近似⁃GPD分类器和GEV分类器. ...
Open category detection with PAC guarantees
1
2018
... 在一般开放集问题的假设下,很少有算法能保证其检测UUCs的能力.因此,Liu et al[85]通过引入PAC理论,从概率的角度对模型从理论方面重新进行设计.该算法能实现具体的UUCs检测率,如能成功检测95%的UUCs.假设存在一个KKCs的分布D0,可以从D0中生成一个训练集S0,同时还存在一个混合分布Dm,Dm是KKCs分布D0和UUCs分布Da的混合,可以从Dm中生成混合数据集Sm.注意,在Dm中,假设可以以的概率从Da中生成一个UUCs数据,以1-α的概率从D0中生成一个KKCs数据.基于以上假设,设计使用异常检测器的阈值去判断UUCs,如果异常得分大于阈值则标记样本为UUCs,否则将样本标记为KKCs.因此,问题的关键在于阈值的选择.考虑固定异常检测器异常分数的累积分布函数(CDFs),混合分布Dm的异常值得分可以表示为: ...
Gradient?based learning applied to document recognition
1
1998
... Related datasets of OSRTable 1
Dataset
Abstract
Number of Instances
feature dimension
Number of classes
Number of KKCs
Number of UUCs
MNIST[86]
Handwritten Digits Images
60000
28×28
10
6
4
SVHN[87]
Color House⁃Number Images
630420
32×32
10
6
4
PENDIGITS[88]
Processed image features
10992
17
10
5
5
LETTER[89]
letters of an alphabet
20000
16
26
10
16
CIFAR10[90]
Color Images
60000
32×32
10
6
4
COIL20[91]
Grayscale Images
1440
16×16
20
10
10
YALEB[92]
Face Images
2414
32×32
38
10
28
Tiny⁃ImageNet[93]
Subset of Imagenet
100000
32×32
200
20
180
由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
Reading digits in natural images with unsupervised feature learning
1
... Related datasets of OSRTable 1
Dataset
Abstract
Number of Instances
feature dimension
Number of classes
Number of KKCs
Number of UUCs
MNIST[86]
Handwritten Digits Images
60000
28×28
10
6
4
SVHN[87]
Color House⁃Number Images
630420
32×32
10
6
4
PENDIGITS[88]
Processed image features
10992
17
10
5
5
LETTER[89]
letters of an alphabet
20000
16
26
10
16
CIFAR10[90]
Color Images
60000
32×32
10
6
4
COIL20[91]
Grayscale Images
1440
16×16
20
10
10
YALEB[92]
Face Images
2414
32×32
38
10
28
Tiny⁃ImageNet[93]
Subset of Imagenet
100000
32×32
200
20
180
由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
Integrating constraints and metric learning in semi?supervised clustering
1
2004
... Related datasets of OSRTable 1
Dataset
Abstract
Number of Instances
feature dimension
Number of classes
Number of KKCs
Number of UUCs
MNIST[86]
Handwritten Digits Images
60000
28×28
10
6
4
SVHN[87]
Color House⁃Number Images
630420
32×32
10
6
4
PENDIGITS[88]
Processed image features
10992
17
10
5
5
LETTER[89]
letters of an alphabet
20000
16
26
10
16
CIFAR10[90]
Color Images
60000
32×32
10
6
4
COIL20[91]
Grayscale Images
1440
16×16
20
10
10
YALEB[92]
Face Images
2414
32×32
38
10
28
Tiny⁃ImageNet[93]
Subset of Imagenet
100000
32×32
200
20
180
由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
Letter recognition using Holland?style adaptive classifiers
1
1991
... Related datasets of OSRTable 1
Dataset
Abstract
Number of Instances
feature dimension
Number of classes
Number of KKCs
Number of UUCs
MNIST[86]
Handwritten Digits Images
60000
28×28
10
6
4
SVHN[87]
Color House⁃Number Images
630420
32×32
10
6
4
PENDIGITS[88]
Processed image features
10992
17
10
5
5
LETTER[89]
letters of an alphabet
20000
16
26
10
16
CIFAR10[90]
Color Images
60000
32×32
10
6
4
COIL20[91]
Grayscale Images
1440
16×16
20
10
10
YALEB[92]
Face Images
2414
32×32
38
10
28
Tiny⁃ImageNet[93]
Subset of Imagenet
100000
32×32
200
20
180
由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
Learning multiple layers of features from tiny images
1
2009
... Related datasets of OSRTable 1
Dataset
Abstract
Number of Instances
feature dimension
Number of classes
Number of KKCs
Number of UUCs
MNIST[86]
Handwritten Digits Images
60000
28×28
10
6
4
SVHN[87]
Color House⁃Number Images
630420
32×32
10
6
4
PENDIGITS[88]
Processed image features
10992
17
10
5
5
LETTER[89]
letters of an alphabet
20000
16
26
10
16
CIFAR10[90]
Color Images
60000
32×32
10
6
4
COIL20[91]
Grayscale Images
1440
16×16
20
10
10
YALEB[92]
Face Images
2414
32×32
38
10
28
Tiny⁃ImageNet[93]
Subset of Imagenet
100000
32×32
200
20
180
由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
Columbia object image library (COIL?20)
1
96
... Related datasets of OSRTable 1
Dataset
Abstract
Number of Instances
feature dimension
Number of classes
Number of KKCs
Number of UUCs
MNIST[86]
Handwritten Digits Images
60000
28×28
10
6
4
SVHN[87]
Color House⁃Number Images
630420
32×32
10
6
4
PENDIGITS[88]
Processed image features
10992
17
10
5
5
LETTER[89]
letters of an alphabet
20000
16
26
10
16
CIFAR10[90]
Color Images
60000
32×32
10
6
4
COIL20[91]
Grayscale Images
1440
16×16
20
10
10
YALEB[92]
Face Images
2414
32×32
38
10
28
Tiny⁃ImageNet[93]
Subset of Imagenet
100000
32×32
200
20
180
由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
From few to many:Illumination cone models for face recognition under variable lighting and pose
1
2001
... Related datasets of OSRTable 1
Dataset
Abstract
Number of Instances
feature dimension
Number of classes
Number of KKCs
Number of UUCs
MNIST[86]
Handwritten Digits Images
60000
28×28
10
6
4
SVHN[87]
Color House⁃Number Images
630420
32×32
10
6
4
PENDIGITS[88]
Processed image features
10992
17
10
5
5
LETTER[89]
letters of an alphabet
20000
16
26
10
16
CIFAR10[90]
Color Images
60000
32×32
10
6
4
COIL20[91]
Grayscale Images
1440
16×16
20
10
10
YALEB[92]
Face Images
2414
32×32
38
10
28
Tiny⁃ImageNet[93]
Subset of Imagenet
100000
32×32
200
20
180
由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
Tiny ImageNet visual recognition challenge
1
2015
... Related datasets of OSRTable 1
Dataset
Abstract
Number of Instances
feature dimension
Number of classes
Number of KKCs
Number of UUCs
MNIST[86]
Handwritten Digits Images
60000
28×28
10
6
4
SVHN[87]
Color House⁃Number Images
630420
32×32
10
6
4
PENDIGITS[88]
Processed image features
10992
17
10
5
5
LETTER[89]
letters of an alphabet
20000
16
26
10
16
CIFAR10[90]
Color Images
60000
32×32
10
6
4
COIL20[91]
Grayscale Images
1440
16×16
20
10
10
YALEB[92]
Face Images
2414
32×32
38
10
28
Tiny⁃ImageNet[93]
Subset of Imagenet
100000
32×32
200
20
180
由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
Caltech?256 object category dataset
1
2007
... 由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
... 由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
Histograms of oriented gradients for human detection
1
2005
... 由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
FACE?GRAB:Face recognition with general region assigned to binary operator
1
2010
... 由表可见,大部分设置将同一个数据集的类别划分为KKCs和UUCs,但是也有一部分实验,为了丰富训练集和测试集,从不同的数据集进行KKCs和UUCs的划分.OSR早期算法1⁃vs⁃set和W⁃SVM联合Caltech 256[94]和Image⁃Net[95]设置实验并用方向梯度直方图(Histogram of Oriented Gradient,HOG)[96]以及LBP⁃Like[97]对图像特征进行描述.Neal et al[57]提出CIFAR+10和CIFAR+50,即从CIFAR10中选择四类作为KKCs,从CIFAR100中分别选择10类和50类作为UUCs. ...
A systematic analysis of performance measures for classification tasks
1
2009
... 此外,Sokolova and Lapalme[98]提出对于F⁃measure来说,无论TN怎么改变其值都不会变化,但在OSR下TN是一个非常重要的变量.因此,Scherreik and Rigling[35]引入约登指数J来表示一个算法避免失败的能力[99],J越高代表这个算法越能避免失败. ...
Beyond accuracy,F?score and ROC:A family of discriminant measures for performance evaluation
1
2006
... 此外,Sokolova and Lapalme[98]提出对于F⁃measure来说,无论TN怎么改变其值都不会变化,但在OSR下TN是一个非常重要的变量.因此,Scherreik and Rigling[35]引入约登指数J来表示一个算法避免失败的能力[99],J越高代表这个算法越能避免失败. ...
A multiobjective simultaneous learning framework for clustering and classification
... 领域自适应是迁移学习[105]的一个重要研究方向,传统领域自适应问题是训练集与测试集样本类别相同可是数据分布不同(如手写数字集与合成图像数字集),领域自适应能将在训练集中训练的模型应用于测试集中.Busto and Gall[106]通过在训练集中加入无关类,提出开放集领域自适应(OSDA)的概念.Saito et al[107]探讨了更具挑战的开放性场景,即在训练集没有无关类的情况下实现测试集中UUCs识别.算法具体采用了生成对抗网络,不仅使两个领域的KKCs差异缩小还有效识别了UUCs.刘晓龙和王士同[108]提出一种开放集模糊领域自适应算法,该方法通过计算目标域样本的模糊隶属度表示源域到目标域的映射,从而逐步在同一空间下实现对目标域的分类.为了进一步分离KKCs和UUCs,刘晓龙和王士同还在前文[107]的基础上,仅将从目标域分离出的KKCs与源域样本进行对齐[109]. ...
Open set domain adaptation
1
2017
... 领域自适应是迁移学习[105]的一个重要研究方向,传统领域自适应问题是训练集与测试集样本类别相同可是数据分布不同(如手写数字集与合成图像数字集),领域自适应能将在训练集中训练的模型应用于测试集中.Busto and Gall[106]通过在训练集中加入无关类,提出开放集领域自适应(OSDA)的概念.Saito et al[107]探讨了更具挑战的开放性场景,即在训练集没有无关类的情况下实现测试集中UUCs识别.算法具体采用了生成对抗网络,不仅使两个领域的KKCs差异缩小还有效识别了UUCs.刘晓龙和王士同[108]提出一种开放集模糊领域自适应算法,该方法通过计算目标域样本的模糊隶属度表示源域到目标域的映射,从而逐步在同一空间下实现对目标域的分类.为了进一步分离KKCs和UUCs,刘晓龙和王士同还在前文[107]的基础上,仅将从目标域分离出的KKCs与源域样本进行对齐[109]. ...
Open set domain adaptation by backpropagation
2
2018
... 领域自适应是迁移学习[105]的一个重要研究方向,传统领域自适应问题是训练集与测试集样本类别相同可是数据分布不同(如手写数字集与合成图像数字集),领域自适应能将在训练集中训练的模型应用于测试集中.Busto and Gall[106]通过在训练集中加入无关类,提出开放集领域自适应(OSDA)的概念.Saito et al[107]探讨了更具挑战的开放性场景,即在训练集没有无关类的情况下实现测试集中UUCs识别.算法具体采用了生成对抗网络,不仅使两个领域的KKCs差异缩小还有效识别了UUCs.刘晓龙和王士同[108]提出一种开放集模糊领域自适应算法,该方法通过计算目标域样本的模糊隶属度表示源域到目标域的映射,从而逐步在同一空间下实现对目标域的分类.为了进一步分离KKCs和UUCs,刘晓龙和王士同还在前文[107]的基础上,仅将从目标域分离出的KKCs与源域样本进行对齐[109]. ...
... [107]的基础上,仅将从目标域分离出的KKCs与源域样本进行对齐[109]. ...
面向开放集图像分类的模糊域自适应方法
1
2021
... 领域自适应是迁移学习[105]的一个重要研究方向,传统领域自适应问题是训练集与测试集样本类别相同可是数据分布不同(如手写数字集与合成图像数字集),领域自适应能将在训练集中训练的模型应用于测试集中.Busto and Gall[106]通过在训练集中加入无关类,提出开放集领域自适应(OSDA)的概念.Saito et al[107]探讨了更具挑战的开放性场景,即在训练集没有无关类的情况下实现测试集中UUCs识别.算法具体采用了生成对抗网络,不仅使两个领域的KKCs差异缩小还有效识别了UUCs.刘晓龙和王士同[108]提出一种开放集模糊领域自适应算法,该方法通过计算目标域样本的模糊隶属度表示源域到目标域的映射,从而逐步在同一空间下实现对目标域的分类.为了进一步分离KKCs和UUCs,刘晓龙和王士同还在前文[107]的基础上,仅将从目标域分离出的KKCs与源域样本进行对齐[109]. ...
面向开放集图像分类的模糊域自适应方法
1
2021
... 领域自适应是迁移学习[105]的一个重要研究方向,传统领域自适应问题是训练集与测试集样本类别相同可是数据分布不同(如手写数字集与合成图像数字集),领域自适应能将在训练集中训练的模型应用于测试集中.Busto and Gall[106]通过在训练集中加入无关类,提出开放集领域自适应(OSDA)的概念.Saito et al[107]探讨了更具挑战的开放性场景,即在训练集没有无关类的情况下实现测试集中UUCs识别.算法具体采用了生成对抗网络,不仅使两个领域的KKCs差异缩小还有效识别了UUCs.刘晓龙和王士同[108]提出一种开放集模糊领域自适应算法,该方法通过计算目标域样本的模糊隶属度表示源域到目标域的映射,从而逐步在同一空间下实现对目标域的分类.为了进一步分离KKCs和UUCs,刘晓龙和王士同还在前文[107]的基础上,仅将从目标域分离出的KKCs与源域样本进行对齐[109]. ...
渐进式分离的开放集模糊域自适应方法
1
2021
... 领域自适应是迁移学习[105]的一个重要研究方向,传统领域自适应问题是训练集与测试集样本类别相同可是数据分布不同(如手写数字集与合成图像数字集),领域自适应能将在训练集中训练的模型应用于测试集中.Busto and Gall[106]通过在训练集中加入无关类,提出开放集领域自适应(OSDA)的概念.Saito et al[107]探讨了更具挑战的开放性场景,即在训练集没有无关类的情况下实现测试集中UUCs识别.算法具体采用了生成对抗网络,不仅使两个领域的KKCs差异缩小还有效识别了UUCs.刘晓龙和王士同[108]提出一种开放集模糊领域自适应算法,该方法通过计算目标域样本的模糊隶属度表示源域到目标域的映射,从而逐步在同一空间下实现对目标域的分类.为了进一步分离KKCs和UUCs,刘晓龙和王士同还在前文[107]的基础上,仅将从目标域分离出的KKCs与源域样本进行对齐[109]. ...
渐进式分离的开放集模糊域自适应方法
1
2021
... 领域自适应是迁移学习[105]的一个重要研究方向,传统领域自适应问题是训练集与测试集样本类别相同可是数据分布不同(如手写数字集与合成图像数字集),领域自适应能将在训练集中训练的模型应用于测试集中.Busto and Gall[106]通过在训练集中加入无关类,提出开放集领域自适应(OSDA)的概念.Saito et al[107]探讨了更具挑战的开放性场景,即在训练集没有无关类的情况下实现测试集中UUCs识别.算法具体采用了生成对抗网络,不仅使两个领域的KKCs差异缩小还有效识别了UUCs.刘晓龙和王士同[108]提出一种开放集模糊领域自适应算法,该方法通过计算目标域样本的模糊隶属度表示源域到目标域的映射,从而逐步在同一空间下实现对目标域的分类.为了进一步分离KKCs和UUCs,刘晓龙和王士同还在前文[107]的基础上,仅将从目标域分离出的KKCs与源域样本进行对齐[109]. ...
1
2010
... 开放世界识别就是将增量学习引入OSR中,开放世界识别模型不仅要求将UUCs识别出来,还要求根据人工标注等手段将UUCs加入KKCs中,将UUCs在下次模型的训练中当成KKCs进行模型的更新.强化学习[110]是在没有任何监督的标签的情况下,通过尝试性地做出一些行为得到反馈,不断地调整之前的行为,系统就可以知道什么样子的行为是最好的结果.在强化学习中,开放性是其特征,因此将强化学习与OSR结合起来具有很强的理论依据.对抗防御的目的是减少网络对图像的攻击,开放环境下这种攻击会变得更加复杂.Shao et al[111]考虑开放环境下的对抗防御问题,提出开放对抗防御机制(Open⁃Set Adversarial Defense,OSAD).本文已表明OSR系统容易受到对抗性攻击.联邦学习[112]是从用户隐私的角度出发形成的新的学习领域,传统学习中不管是KKCs还是UUCs,都假设模型可以直接获得这些数据进行处理,但在实际情况中,用户不希望模型能够获得自己的数据,因此将OSR与联邦学习结合起来是未来应用领域发展的潜在要求. ...
Open?set adversarial defense
1
2020
... 开放世界识别就是将增量学习引入OSR中,开放世界识别模型不仅要求将UUCs识别出来,还要求根据人工标注等手段将UUCs加入KKCs中,将UUCs在下次模型的训练中当成KKCs进行模型的更新.强化学习[110]是在没有任何监督的标签的情况下,通过尝试性地做出一些行为得到反馈,不断地调整之前的行为,系统就可以知道什么样子的行为是最好的结果.在强化学习中,开放性是其特征,因此将强化学习与OSR结合起来具有很强的理论依据.对抗防御的目的是减少网络对图像的攻击,开放环境下这种攻击会变得更加复杂.Shao et al[111]考虑开放环境下的对抗防御问题,提出开放对抗防御机制(Open⁃Set Adversarial Defense,OSAD).本文已表明OSR系统容易受到对抗性攻击.联邦学习[112]是从用户隐私的角度出发形成的新的学习领域,传统学习中不管是KKCs还是UUCs,都假设模型可以直接获得这些数据进行处理,但在实际情况中,用户不希望模型能够获得自己的数据,因此将OSR与联邦学习结合起来是未来应用领域发展的潜在要求. ...
Federated machine learning:Concept and applications
1
2019
... 开放世界识别就是将增量学习引入OSR中,开放世界识别模型不仅要求将UUCs识别出来,还要求根据人工标注等手段将UUCs加入KKCs中,将UUCs在下次模型的训练中当成KKCs进行模型的更新.强化学习[110]是在没有任何监督的标签的情况下,通过尝试性地做出一些行为得到反馈,不断地调整之前的行为,系统就可以知道什么样子的行为是最好的结果.在强化学习中,开放性是其特征,因此将强化学习与OSR结合起来具有很强的理论依据.对抗防御的目的是减少网络对图像的攻击,开放环境下这种攻击会变得更加复杂.Shao et al[111]考虑开放环境下的对抗防御问题,提出开放对抗防御机制(Open⁃Set Adversarial Defense,OSAD).本文已表明OSR系统容易受到对抗性攻击.联邦学习[112]是从用户隐私的角度出发形成的新的学习领域,传统学习中不管是KKCs还是UUCs,都假设模型可以直接获得这些数据进行处理,但在实际情况中,用户不希望模型能够获得自己的数据,因此将OSR与联邦学习结合起来是未来应用领域发展的潜在要求. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}