南京大学学报(自然科学版) ›› 2021, Vol. 57 ›› Issue (6): 1075–1082.doi: 10.13232/j.cnki.jnju.2021.06.016
• • 上一篇
基于FPGA的卷积神经网络训练加速器设计
孟浩1,2, 刘强1,2( )
)
- 1.天津大学微电子学院,天津,300072
2.天津市成像与感知微电子技术重点实验室,天津,300072
A FPGA⁃based convolutional neural network training accelerator
Hao Meng1,2, Qiang Liu1,2()
- 1.School of Microelectronics,Tianjin University, Tianjin,300072,China
2.Tianjin Key Laboratory of Imaging and Sensing Microelectronics Technology,Tianjin,300072,China
摘要:
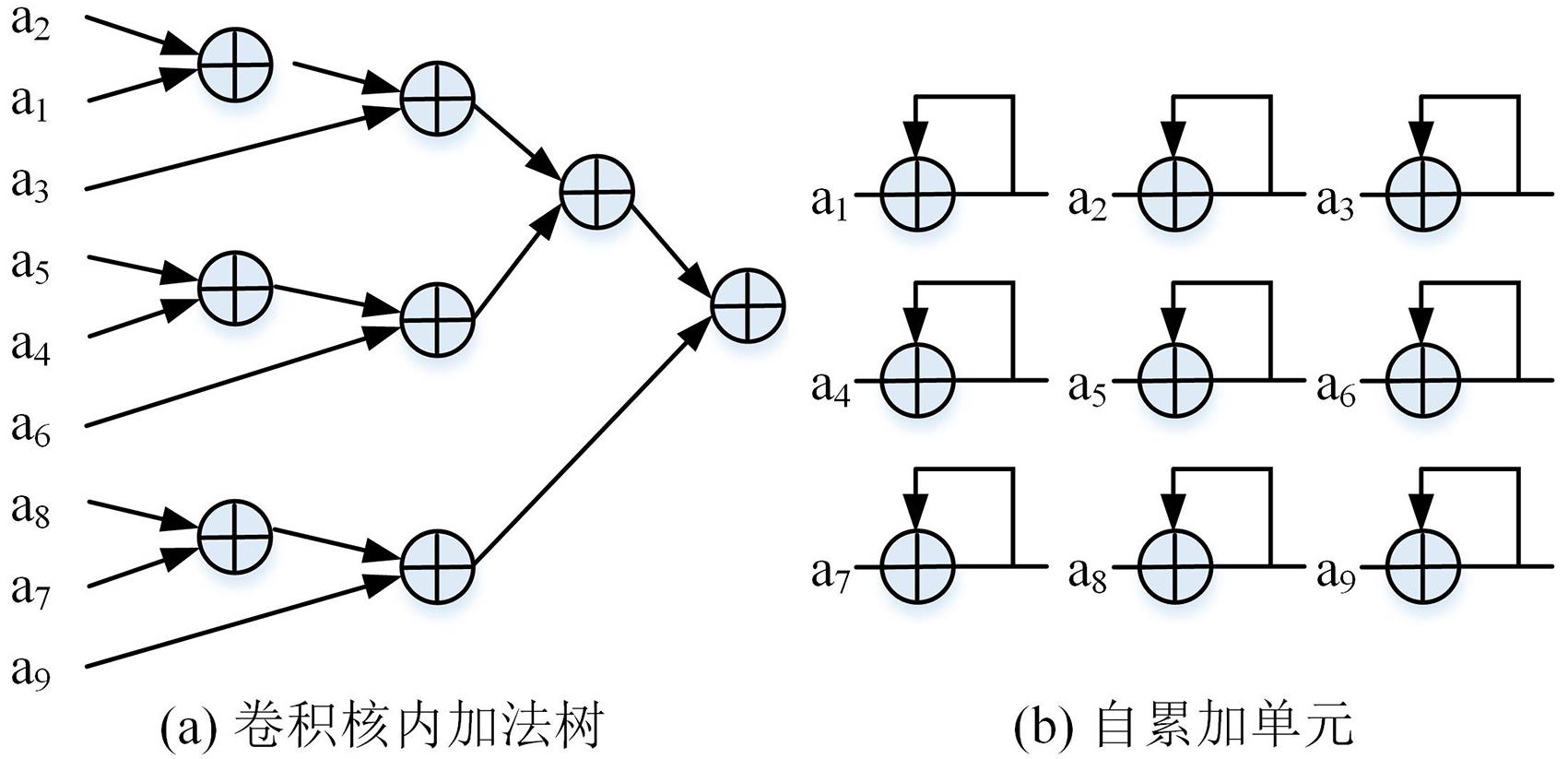
近年来卷积神经网络在图像分类、图像分割等任务中应用广泛.针对基于FPGA (Field Programmable Gate Array)的卷积神经网络训练加速器中存在的权重梯度计算效率低和加法器占用资源多的问题,设计一款高性能的卷积神经网络训练加速器.首先提出一种卷积单引擎架构,在推理卷积硬件架构的基础上增加额外的自累加单元,可兼容卷积层的正向传播与反向传播(误差反向传递和权重梯度计算),提高加速器的复用能力,同时提升权重梯度计算的效率;然后提出一种适配卷积核内加法树与自累加单元的新型加法树设计,进一步节约计算资源;最后在Xilinx Zynq xc7z045平台上实现了所提出的训练加速器,并基于CIFAR?10数据集训练VGG?like (Visual Geometry Group)网络模型.实验结果表明,在200 MHz的时钟频率下,支持8位定点的训练加速器可以达到64.6 GOPS (Giga Operations per Second)的平均性能,是Intel Xeon E5?2630 v4 CPU (Central Processing Unit)训练平台的9.36倍,能效是NVIDIA Tesla K40C GPU(Graphics Processing Unit)训练平台的17.96倍.与已有的FPGA加速器相比,提出的加速器在处理性能和存储资源使用效率上具有优势.
中图分类号:
- TP338.6









| 1 | Redmon J,Farhadi A. YOLO9000:Better,faster,stronger∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI,USA:IEEE,2017:6517-6525. |
| 2 | Russakovsk O,Deng J,Su H,et al. ImageNet large scale visual recognition challenge. International Journal of Computer Vision,2015,115(3):211-252. |
| 3 | Zhang Y,Chan W,Jaitly N. Very deep convolutional networks for end?to?end speech recognition∥Proceedings of the IEEE International Conference on Acoustics,Speech and Signal Processing. New Orleans,LA,USA:IEEE,2017:4845-4849. |
| 4 | Qiu J T,Wang J,Yao S,et al. Going deeper with embedded FPGA platform for convolutional neural network∥Proceedings of the 2016 ACM/SIGDA International Symposium on Field?Programmable Gate Arrays. New York:ACM Press,2016:26-35. |
| 5 | Zhao R Z,Niu X Y,Wu Y J,et al. Optimizing CNN?based object detection algorithms on embedded FPGA platforms∥13th International Symposium on Applied Reconfigurable Computing. Springer Berlin Heidelberg,2017:255-267. |
| 6 | 仇越,马文涛,柴志雷. 一种基于FPGA的卷积神经网络加速器设计与实现. 微电子学与计算机,2018,35(8):68-72,77. |
| Qiu Y,Ma W T,Chai Z L. Design and implementation of a convolutional neural network accelerator based on FPGA. Microelectronics & Computer,2018,35(8):68-72,77. | |
| 7 | 陈辰,柴志雷,夏珺. 基于Zynq7000 FPGA异构平台的YOLOv2加速器设计与实现. 计算机科学与探索,2019,13(10):1677-1693. |
| Chen C,Chai Z L,Xia J. Design and implementation of YOLOv2 acce?lerator based on Zynq7000 FPGA heterogeneous platform. Journal of Frontiers of Computer Science and Technology,2019,13(10):1677-1693. | |
| 8 | 曾成龙,刘强. 面向嵌入式FPGA的高性能卷积神经网络加速器设计. 计算机辅助设计与图形学学报,2019,31(9):1645-1652. |
| Zeng C L,Liu Q. Design of high performance convolutional neural network accelerator for embedded FPGA. Journal of Computer?Aided Design and Computer Graphics,2019,31(9):1645-1652. | |
| 9 | 徐欣,刘强,王少军. 一种高度并行的卷积神经网络加速器设计方法. 哈尔滨工业大学学报,2020,52(4):31-37. |
| Xu X,Liu Q,Wang S J. A highly parallel design method for convolutional neural networks accelerator. Journal of Harbin Institute of Technology,2020,52(4):31-37. | |
| 10 | Li F F,Zhang B,Liu B. Ternary weight networks. 2016,arXiv:. |
| 11 | Zhou S C,Wu Y X,Ni Z K,et al. Dorefa?net:Training low bitwidth convolutional neural networks with low bitwidth gradients. 2018,arXiv:. |
| 12 | Banner R,Hubara I,Hoffer E,et al. Scalable methods for 8?bit training of neural networks∥Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montreal,Canada:NIPS,2018:5145-5153. |
| 13 | Das D,Mellempudi N,Mudigere D,et al. Mixed precision training of convolutional neural networks using integer operation. 2018,arXiv:. |
| 14 | Deng L,Li G Q,Han S,et al. Model compression and hardware acceleration for neural networks:A comprehensive survey. Proceedings of the IEEE,2020,108(4):485-532. |
| 15 | Lin Y J,Han S,Mao H Z,et al. Deep gradient compression:Reducing the communication bandwidth for distributed training. 2020,arXiv:. |
| 16 | Han D,Lee J,Lee J,et al.A141.4 mW low?power online deep neural network training processor for real?time object tracking in mobile devices∥2018 IEEE International Symposium on Circuits and Systems. Florence,Italy:IEEE,2018:1-5. |
| 17 | Zhao W L,Fu H H,Luk W,et al. F?CNN:An FPGA?based framework for training convolutional neural networks∥IEEE 27th International Conference on Application?specific Systems,Architectures and Processors. London,UK:IEEE,2016:107-114. |
| 18 | Liu Z Q,Dou Y,Jiang J F,et al. An FPGA?based processor for training convolutional neural networks∥2017 International Conference on Field Programmable Technology. Melbourne,Australia:IEEE,2017:207-210. |
| 19 | Fox S,Faraon J,Boland D,et al. Training deep neural networks in low?precision with high accuracy using FPGAs∥2019 International Conference on Field?Programmable Technology. Tianjin,China:IEEE,2019:1-9. |
| 20 | Luo C,Sit M K,Fan H X,et al. Towards efficient deep neural network training by FPGA?based batch?level parallelism. Journal of Semiconductors,2020,41(2):022403. |
| [1] | 樊炎, 匡绍龙, 许重宝, 孙立宁, 张虹淼. 一种同步提取运动想象信号时⁃频⁃空特征的卷积神经网络算法[J]. 南京大学学报(自然科学版), 2021, 57(6): 1064-1074. |
| [2] | 陈磊, 孙权森, 王凡海. 基于深度对抗网络和局部模糊探测的目标运动去模糊[J]. 南京大学学报(自然科学版), 2021, 57(5): 735-749. |
| [3] | 倪斌, 陆晓蕾, 童逸琦, 马涛, 曾志贤. 胶囊神经网络在期刊文本分类中的应用[J]. 南京大学学报(自然科学版), 2021, 57(5): 750-756. |
| [4] | 杨静, 赵文仓, 徐越, 冯旸赫, 黄金才. 一种基于少样本数据的在线主动学习与分类方法[J]. 南京大学学报(自然科学版), 2021, 57(5): 757-766. |
| [5] | 贾霄, 郭顺心, 赵红. 基于图像属性的零样本分类方法综述[J]. 南京大学学报(自然科学版), 2021, 57(4): 531-543. |
| [6] | 普志方, 陈秀宏. 基于卷积神经网络的细胞核图像分割算法[J]. 南京大学学报(自然科学版), 2021, 57(4): 566-574. |
| [7] | 段建设, 崔超然, 宋广乐, 马乐乐, 马玉玲, 尹义龙. 基于多尺度注意力融合的知识追踪方法[J]. 南京大学学报(自然科学版), 2021, 57(4): 591-598. |
| [8] | 颜志良, 丰智鹏, 刘丹, 王会青. 一种混合深度神经网络的赖氨酸乙酰化位点预测方法[J]. 南京大学学报(自然科学版), 2021, 57(4): 627-640. |
| [9] | 方志文, 刘青山, 周峰. 基于像素⁃目标级共生关系学习的多标签航拍图像分类方法[J]. 南京大学学报(自然科学版), 2021, 57(2): 208-216. |
| [10] | 罗金屯, 滕飞, 周亚波, 池茂儒, 张海波. 数据驱动的高速铁路轮轨作用力反演模型[J]. 南京大学学报(自然科学版), 2021, 57(2): 299-308. |
| [11] | 范习健, 杨绪兵, 张礼, 业巧林, 业宁. 一种融合视觉和听觉信息的双模态情感识别算法[J]. 南京大学学报(自然科学版), 2021, 57(2): 309-317. |
| [12] | 曾宪华, 陆宇喆, 童世玥, 徐黎明. 结合马尔科夫场和格拉姆矩阵特征的写实类图像风格迁移[J]. 南京大学学报(自然科学版), 2021, 57(1): 1-9. |
| [13] | 余方超, 方贤进, 张又文, 杨高明, 王丽. 增强深度学习中的差分隐私防御机制[J]. 南京大学学报(自然科学版), 2021, 57(1): 10-20. |
| [14] | 高春永, 柏业超, 王琼. 基于改进的半监督阶梯网络SAR图像识别[J]. 南京大学学报(自然科学版), 2021, 57(1): 160-166. |
| [15] | 张萌, 韩冰, 王哲, 尤富生, 李浩然. 基于深度主动学习的甲状腺癌病理图像分类方法[J]. 南京大学学报(自然科学版), 2021, 57(1): 21-28. |
|
||