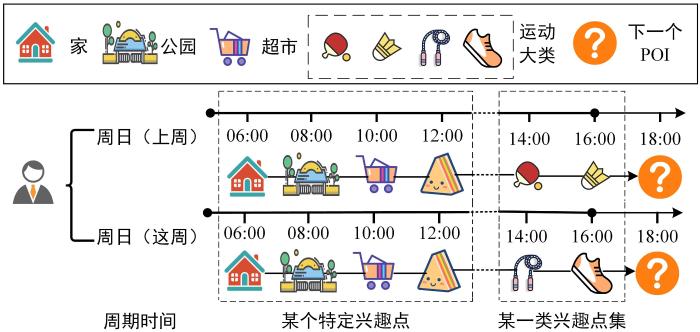
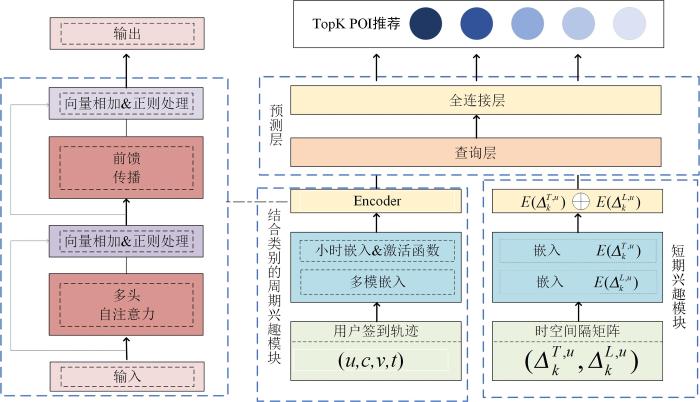
随着基于位置的社交网络在日常生活中的广泛应用,有效提取用户的隐藏兴趣和行为序列模式并向用户提供满足其个性化需求的下一个兴趣点推荐服务成为推荐领域的热点问题之一.针对下一个兴趣点推荐中的用户偏好挖掘问题,提出基于用户兴趣点类别周期性偏好和短期兴趣相结合的兴趣点推荐模型(Combining Periodic and Spatio⁃Temporal Intervals' Network,CPSTIN).该模型将用户的签到记录按小时时段模式嵌入时间窗口并使用多头自注意力机制提取用户结合用户兴趣点类别的周期性偏好;同时,将非连续时空间隔信息送入可学习矩阵,使用线性插值法提取用户基于高阶关联性的短期兴趣.最后,在两个真实数据集上验证了该模型的有效性,证明其能有效地利用用户高阶关联性短期兴趣和结合兴趣点类别的周期偏好,更准确地预测用户最有可能访问的下一个兴趣点.
关键词:兴趣点推荐
;
自注意力机制
;
线性插值嵌入
;
类别周期兴趣
Abstract
With the widespread application of location⁃based social networks in daily life,how to effectively extract users' hidden interests and behavior sequence patterns,and provide users with the next Point of Interest (POI) recommendation service to meet their personalized needs has become one of the hot issues in the recommendation field. Aiming at the problem of user preference mining in the next POI recommendation,this paper proposes a POI recommendation model CPSTIN (Combining Periodic and Spatio⁃Temporal Intervals' Network) based on the combination of periodic preference of user POI category and short⁃term interest. The model embeds the user record of signing in into the time window by hour period pattern,and uses the multi⁃head self⁃attention mechanism to extract the the user's periodic preference combined with the category of POI. At the same time,the model sends the discontinuous spatio⁃temporal interval information into the learnable matrix,and uses the linear interpolation method to extract the user's short⁃term interest based on high⁃order correlation. Finally,the validity of the model is verified on two real datasets. The model effectively uses the user's high⁃order relevance short⁃term interest and the periodic preference based on the POI category to more accurately predict the next POI that the user is most likely to visit.
Sang Chunyan, Yi Xingyu, Liao Shigen, Wen Junhao. A recommendation model combining point of interest category periodic attributes and user short⁃term preference features. Journal of nanjing University[J], 2024, 60(3): 429-441 doi:10.13232/j.cnki.jnju.2024.03.007
随着基于位置的社交网络(Location⁃Based Social Networking Service,LBSNs)在日常生活中的广泛应用,人们常在如Foursquare,Yelp,Facebook等LBSNs[1]上分享生活经历并发布签到记录,对海量的LBSN数据的分析挖掘可以帮助零售商向用户推荐精准的POI(Point of Interest)服务[2-3].下一个兴趣点推荐能预测用户在指定时间点最有可能访问的兴趣点,其应用场景时效强,使其成为推荐领域中的热点问题[4-5].
用户习惯与时空因素密切相关.针对时间效应在很大程度上影响用户偏好这一问题,Liu et al[6]和Kong and Wu[7]为了挖掘用户的长短期兴趣,提出基于时空间隔的兴趣点推荐.Kong and Wu[7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐.
为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法.
An effective and efficient self⁃attention based model for next POI recommendation
∥Proceedings of 2023 IEEE Inter⁃national Conference on Pervasive Computing and Communications Workshops and other Affiliated Events. Atlanta,GA,USA:IEEE,2023:478-483.
Point?of?interest recom?mender systems based on location?based social networks:A survey from an experimental perspective
1
2022
... 随着基于位置的社交网络(Location⁃Based Social Networking Service,LBSNs)在日常生活中的广泛应用,人们常在如Foursquare,Yelp,Facebook等LBSNs[1]上分享生活经历并发布签到记录,对海量的LBSN数据的分析挖掘可以帮助零售商向用户推荐精准的POI(Point of Interest)服务[2-3].下一个兴趣点推荐能预测用户在指定时间点最有可能访问的兴趣点,其应用场景时效强,使其成为推荐领域中的热点问题[4-5]. ...
GeoMF++:Scalable location recommendation via joint geographical modeling and matrix factorization
1
2018
... 随着基于位置的社交网络(Location⁃Based Social Networking Service,LBSNs)在日常生活中的广泛应用,人们常在如Foursquare,Yelp,Facebook等LBSNs[1]上分享生活经历并发布签到记录,对海量的LBSN数据的分析挖掘可以帮助零售商向用户推荐精准的POI(Point of Interest)服务[2-3].下一个兴趣点推荐能预测用户在指定时间点最有可能访问的兴趣点,其应用场景时效强,使其成为推荐领域中的热点问题[4-5]. ...
Attentive sequential model based on graph neural network for next poi recommendation
1
2021
... 随着基于位置的社交网络(Location⁃Based Social Networking Service,LBSNs)在日常生活中的广泛应用,人们常在如Foursquare,Yelp,Facebook等LBSNs[1]上分享生活经历并发布签到记录,对海量的LBSN数据的分析挖掘可以帮助零售商向用户推荐精准的POI(Point of Interest)服务[2-3].下一个兴趣点推荐能预测用户在指定时间点最有可能访问的兴趣点,其应用场景时效强,使其成为推荐领域中的热点问题[4-5]. ...
Next point?of?interest recommendation with temporal and multi?level context attention
1
2018
... 随着基于位置的社交网络(Location⁃Based Social Networking Service,LBSNs)在日常生活中的广泛应用,人们常在如Foursquare,Yelp,Facebook等LBSNs[1]上分享生活经历并发布签到记录,对海量的LBSN数据的分析挖掘可以帮助零售商向用户推荐精准的POI(Point of Interest)服务[2-3].下一个兴趣点推荐能预测用户在指定时间点最有可能访问的兴趣点,其应用场景时效强,使其成为推荐领域中的热点问题[4-5]. ...
A survey of point?of?interest recommendation in location?based social networks
1
2016
... 随着基于位置的社交网络(Location⁃Based Social Networking Service,LBSNs)在日常生活中的广泛应用,人们常在如Foursquare,Yelp,Facebook等LBSNs[1]上分享生活经历并发布签到记录,对海量的LBSN数据的分析挖掘可以帮助零售商向用户推荐精准的POI(Point of Interest)服务[2-3].下一个兴趣点推荐能预测用户在指定时间点最有可能访问的兴趣点,其应用场景时效强,使其成为推荐领域中的热点问题[4-5]. ...
Predicting the next location:A recurrent model with spatial and temporal contexts
4
2016
... 用户习惯与时空因素密切相关.针对时间效应在很大程度上影响用户偏好这一问题,Liu et al[6]和Kong and Wu[7]为了挖掘用户的长短期兴趣,提出基于时空间隔的兴趣点推荐.Kong and Wu[7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐. ...
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
HST?LSTM:A hierarchical spatial?temporal long?short term memory network for location prediction
5
2018
... 用户习惯与时空因素密切相关.针对时间效应在很大程度上影响用户偏好这一问题,Liu et al[6]和Kong and Wu[7]为了挖掘用户的长短期兴趣,提出基于时空间隔的兴趣点推荐.Kong and Wu[7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐. ...
... [7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐. ...
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
Where to go next:Modeling long?and short?term user preferences for point?of?interest recommendation
3
2020
... 用户习惯与时空因素密切相关.针对时间效应在很大程度上影响用户偏好这一问题,Liu et al[6]和Kong and Wu[7]为了挖掘用户的长短期兴趣,提出基于时空间隔的兴趣点推荐.Kong and Wu[7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐. ...
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
... LSTPM[8]:是考虑经纬度地理坐标以获得用户长短期兴趣的基于LSTM的模型. ...
Where to go next:A spatio?temporal gated network for next POI recommendation
2
2022
... 用户习惯与时空因素密切相关.针对时间效应在很大程度上影响用户偏好这一问题,Liu et al[6]和Kong and Wu[7]为了挖掘用户的长短期兴趣,提出基于时空间隔的兴趣点推荐.Kong and Wu[7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐. ...
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
基于GPS轨迹的用户兴趣点及频繁路径挖掘研究
1
2015
... 用户习惯与时空因素密切相关.针对时间效应在很大程度上影响用户偏好这一问题,Liu et al[6]和Kong and Wu[7]为了挖掘用户的长短期兴趣,提出基于时空间隔的兴趣点推荐.Kong and Wu[7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐. ...
Research on GPS?trajectory?based personalization POI and path mining
1
2015
... 用户习惯与时空因素密切相关.针对时间效应在很大程度上影响用户偏好这一问题,Liu et al[6]和Kong and Wu[7]为了挖掘用户的长短期兴趣,提出基于时空间隔的兴趣点推荐.Kong and Wu[7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐. ...
... 用户习惯与时空因素密切相关.针对时间效应在很大程度上影响用户偏好这一问题,Liu et al[6]和Kong and Wu[7]为了挖掘用户的长短期兴趣,提出基于时空间隔的兴趣点推荐.Kong and Wu[7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐. ...
Discovering subsequence patterns for next POI recommendation
1
2021
... 用户习惯与时空因素密切相关.针对时间效应在很大程度上影响用户偏好这一问题,Liu et al[6]和Kong and Wu[7]为了挖掘用户的长短期兴趣,提出基于时空间隔的兴趣点推荐.Kong and Wu[7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐. ...
ST?PIL:Spatial?temporal periodic interest learning for next point?of?interest recommendation
2
2021
... 用户习惯与时空因素密切相关.针对时间效应在很大程度上影响用户偏好这一问题,Liu et al[6]和Kong and Wu[7]为了挖掘用户的长短期兴趣,提出基于时空间隔的兴趣点推荐.Kong and Wu[7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐. ...
DeepMove:Predicting human mobility with attentional recurrent networks
2
2018
... 用户习惯与时空因素密切相关.针对时间效应在很大程度上影响用户偏好这一问题,Liu et al[6]和Kong and Wu[7]为了挖掘用户的长短期兴趣,提出基于时空间隔的兴趣点推荐.Kong and Wu[7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐. ...
... DeepMove[14]:是采用递归神经网络和注意力机制的先进的兴趣点预测模型. ...
STAN:Spatio?temporal attention network for next location recommen?dation
6
... 用户习惯与时空因素密切相关.针对时间效应在很大程度上影响用户偏好这一问题,Liu et al[6]和Kong and Wu[7]为了挖掘用户的长短期兴趣,提出基于时空间隔的兴趣点推荐.Kong and Wu[7]和Sun et al[8]提出了挖掘用户时间相关的长期和短期兴趣模型.Zhao et al[9]使用近期历史签到记录(最近时空间隔)有效地挖掘用户的短期兴趣.针对空间特性对用户行为的影响,研究人员假设用户的行动轨迹与区域相关[10],提出基于网格方法的下一个兴趣点推荐模型[11-12].为了挖掘用户在访问兴趣点时的周期特征,Cui et al[13]和Feng et al[14]将离散时间划分为小时、天等单位,纳入基于长短期兴趣的时间序列来挖掘用户的周期性偏好.为了挖掘非连续访问兴趣点之间的关联,Luo et al[15]使用时空间隔来对非连续访问兴趣点的签到建模来挖掘用户偏好.研究[6-7,15]认为,时空间隔既反映了兴趣点之间的空间信息,也反映了用户的运动规律,可以用来研究基于时空间隔的下一个兴趣点推荐. ...
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
Sequential recommendation model based on user's long and short term preference
1
2023
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
A semantic sequential correlation based LSTM model for next POI recommendation
1
2019
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
A contextual attention recurrent architecture for context?aware venue recommendation
1
2018
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
An attention?based spatiotemporal LSTM network for next POI recommendation
3
2021
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
... ,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
An effective and efficient self?attention based model for next POI recommendation
1
2023
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
Time?aware POI recommendation based on multi?grained location grouping
1
2023
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...
Attention is all you need
2
2017
... 为了挖掘用户的历史签到序列规则及其偏好[16],基于循环神经网络(Recurrent Neural Network,RNN)及其改进模型相继被提出[9,17-18].研究者[8,19-20]将基于注意力机制的技术应用于兴趣点推荐领域以挖掘历史签到的不同贡献权重,或基于深度学习和时空上下文来挖掘用户访问兴趣点的兴趣偏好[7,19,21].为了解决连续时空值的合理嵌入问题,Liu et al[6]提出一种线性插值方法,Luo et al[15]使用非连续时空间隔的线性插值嵌入法结合注意力机制来进行下一个兴趣点推荐.Vaswani et al[22]在挖掘具有时空效应的下一个兴趣点推荐时考虑了兴趣点类型的推荐方法. ...




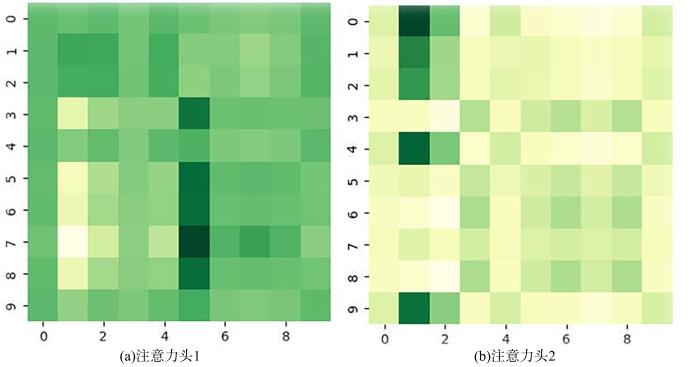

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}