


在频繁模式挖掘任务中,频繁模式被定义为支持度不小于给定阈值的模式,因此支持度阈值是频繁模式挖掘任务中的一个重要输入参数.通常模式的支持度度量应满足反单调性,即父模式的支持度不小于子模式的支持度.基于该特性,挖掘算法能有效地进行搜索空间的剪枝,然而,在算法运行之初,确定合适的支持度阈值难度较大.
图1a展示了一个社交网络图
图1
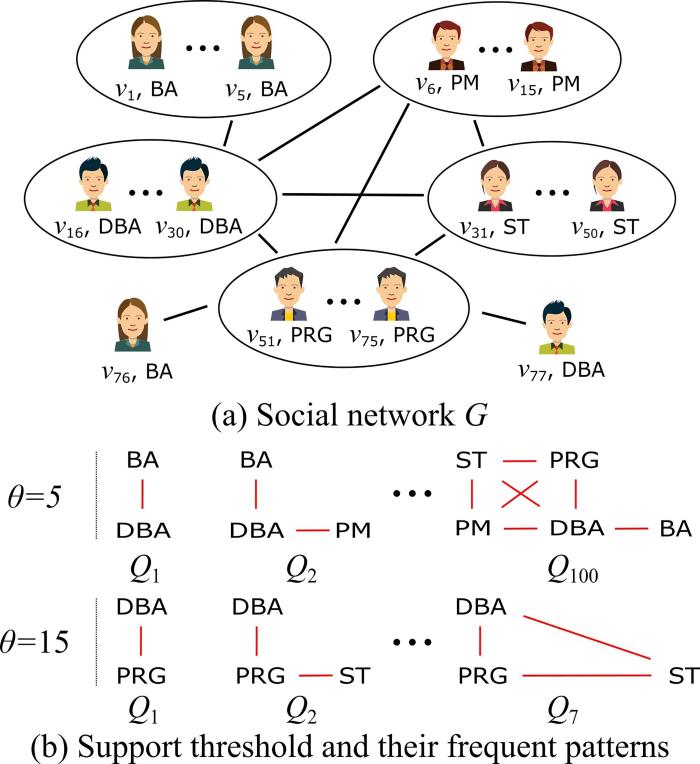
图1
社交网络示例图和在不同支持度阈值设定下的频繁模式
Fig.1
A social network graph and frequent patterns under different support threshold settings
上述例子表明:(1)支持度阈值设置过大会导致返回的模式数量过少,且模式中单边模式的占比过大,实际应用价值偏低;(2)一个过小的支持度阈值会返回过多的模式,使用户难以找到满意的模式,还会增加算法的搜索空间和计算开销,严重的甚至可能导致程序因内存溢出而崩溃.
以上观察激发了本文对单一大图上的Top⁃Rank⁃K频繁模式挖掘问题的探究,即在无初始支持度阈值的情况下高效地挖掘排名前
(1)设计一个兴趣度指标来对模式进行排名,该指标在理想状态下能同时考虑模式的支持度和模式的大小.
(2)设计一种有效的算法,在没有初始支持度阈值输入时也能高效地进行频繁模式挖掘.
本文的具体贡献如下.
(1)提出一种基于模式大小和模式支持度的模式兴趣度度量指标.
(2)提出一种无须设置初始支持度阈值的Top⁃Rank⁃K模式挖掘算法ItrMiner,只须输入图
(3)在真实图和人工合成图数据集上进行了广泛的实验研究,验证了ItrMiner的性能.首先,ItrMiner模式的扩展约束有效性较高,和无扩展约束优化的ItrMinernopt相比,效率提升最高可达9.5倍;其次,与Grami算法进行了对比,验证了ItrMiner的有效性和可行性,为传统频繁模式挖掘提供了一种有价值的替代方案;另外,ItrMiner的执行效率和可扩展性表现良好,尤其在稠密的数据集上,其时间开销仅为基线算法Top⁃K Graph Miner (TKG)的13.2%.
1 相关工作
图数据在描述数据关系方面的卓越表现日益凸显,频繁模式挖掘的研究方向逐渐从传统的事务型数据库扩展到包含图结构数据的领域,单一大图数据的频繁模式挖掘问题受到了众多学者的关注.其中,Sigram[15]和Grami[16]是两种代表性算法.Sigram采用支持度大于指定阈值的顶点来扩展模式并生成候选模式,通过搜索候选模式的匹配来计算其支持度,然而,采用存储模式匹配来计算支持度的方式会消耗大量内存.为了解决这一问题,Elseidy et al[16]提出Grami算法,将子图同构查找问题转换为约束满足问题CSP (Constraint Satisfaction Problem),通过MNI (Minimum Image)支持度规则,找到足够的证据来证明该模式是频繁的部分匹配.
随着图结构数据规模的增大,为了提高在单图上进行频繁模式挖掘的效率,Arabesque[17],Fractal[18]和ScaleMine[19]等分布式挖掘算法被提出.其中,Arabesque采用BFS (Breadth First Search)策略来识别频繁模式,导致每个工作站点需要生成并存储大量的中间状态,内存开销较大.为了解决该问题,Fractal采用DFS (Depth First Search)以及模式重复生成策略,有效降低了内存消耗,并且使用局部感知的任务窃取策略来实现动态负载均衡.另一个分布式系统ScaleMine将模式挖掘分成近似挖掘和精确挖掘两个阶段工作,通过近似挖掘的结果来指导精确挖掘阶段的负载分配,实现更好的负载平衡,提升了算法的执行效率.和上述分布式算法相比,G⁃Miner[20]采用一种细粒度的图划分方法来保证分割子图的局部性,并通过任务窃取策略来实现负载均衡.该方法不再需要每个工作站点都加载完整的输入图,可以有效地处理数据规模超过单机内存的超大单图.此外,与G⁃Miner采用的图划分方法不同,李玲等[21]提出一种基于垂直分解框架的分布式框架,并设计了Desu⁃FSM算法,旨在挖掘大规模图中的封闭子图.
实际应用中用户通常只关注最感兴趣的前
对于频繁模式挖掘,还有部分工作专注于避免支持度阈值设置的困扰,提出了无须设置初始支持度阈值的算法.其中,TGP[23]采用名为Lexicographical Pattern Net的结构来存储所有子图的DFS代码,并利用该结构来挖掘前
虽然现有方法可以识别满足支持度阈值的全部或前
2 基本概念
本文研究的数据集包含带标签的图,每个点都有一个标签来描述其属性.首先回顾图、模式和模式匹配的概念,再对频繁模式挖掘进行形式化描述.
2.1 图、模式与模式匹配
图和子图 给定三元组标签图
图
模式和子模式 给定一个模式
模式匹配 给定图
图
(1)对于每个节点
(2)对于每个模式边
这样,当模式
模式
图2a的图
图2
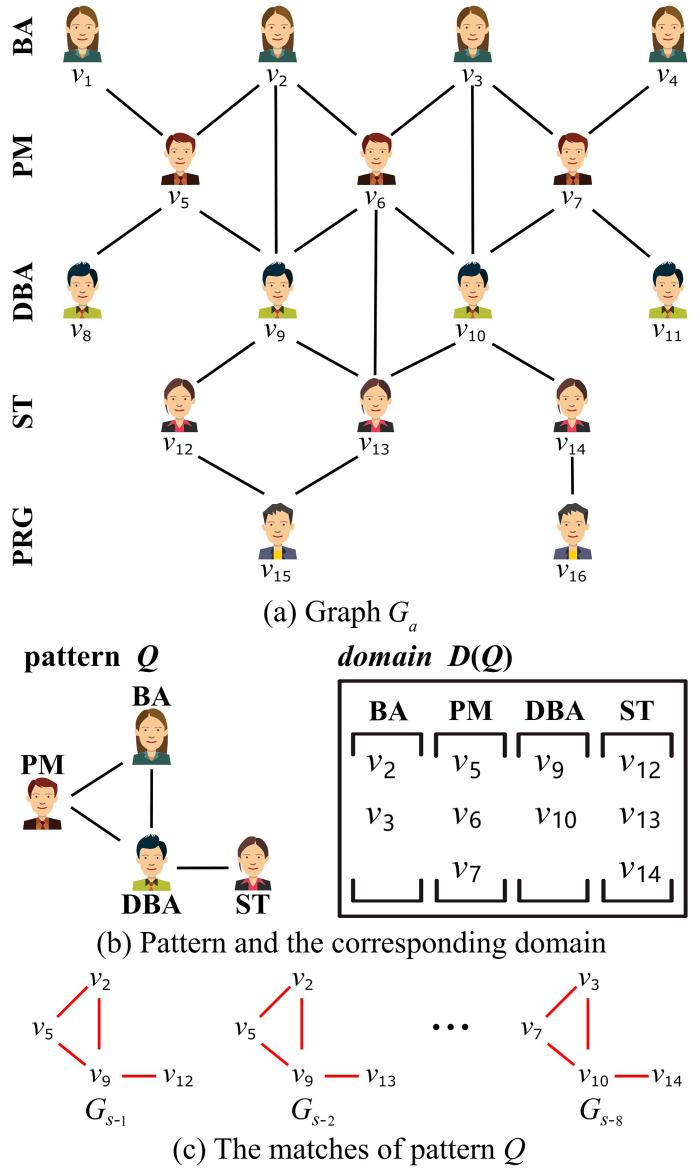
图2
样本图、模式、模式定义域及其模式匹配
Fig2
A sample of graph,patterns,domains and their matches
前向扩展和后向扩展 给定模式
如图2b所示,
模式大小 给定模式
不少工作中,模式的大小被定义为点集与边集大小的和,而本文对此进行调整,主要因为模式无论通过前向还是后向扩展,其边数都会增加1,而点数在后向扩展时保持不变,故采用边集的数量来描述模式大小的增长会更平滑.因此,本文将模式大小
2.2 频繁模式挖掘
支持度 给定模式
基于图像的最小支持度[27]是一个广泛使用的度量标准,它保证了模式扩展的反单调性.本文用其来计算模式的支持度,其定义如下所示:
其中,
如图2b所示,模式
所以,
反单调性 给定图
域 给定图
频繁模式挖掘 给定图
表1给出了本文中重要的符号及其含义.
表1 本文使用的符号
Table 1
| 符号 | 含义 |
|---|---|
| 一个原始数据图 | |
| 一个模式 | |
| 模式 | |
| 模式 |
3 Top⁃Rank⁃K模式挖掘算法
3.1 问题描述
下面给出Top⁃Rank⁃K模式挖掘问题的形式化描述.
输入:单个大图
输出:一个从
这里,
其中,
其中,
直观上,Top⁃Rank⁃K模式挖掘任务旨在从图
在设计模式兴趣度时,从应用出发,考虑两个因素:(1)模式的支持度越大,兴趣度越高;(2)模式的规模越大,兴趣度越高.然而,随着模式规模的增长,支持度必然会单调递减.对此,基于削减小模式支持度收益的思想,本文设计了如
本文中参数
Top⁃Rank⁃K模式挖掘是NP⁃hard问题.
子图同构(Subgraph Isomorphism,SISO)可以检测图
由于算法无须输入支持度阈值,故其无法直接用支持度阈值进行搜索空间的剪枝.另一方面,直接对整个搜索空间进行穷举显然不可取.为了纠正这一点,算法采用兴趣度优先的树模式识别方法并结合严格的模式扩展约束来降低不必要的搜索开销,具体将在下文中详细介绍.
3.2 整体框架
如算法1中的伪代码所示,ItrMiner以图
输入:图
输出:兴趣度排名在前
1.initialize
2.initialize
3.initialize
4.update T,
5.while
6.
7. if
8. break;
9.
10. for each pattern
11. if
12. insert
13. update
14. If
15. update
16.
17.Return
3.3 初始化
算法1一共初始化了
图3
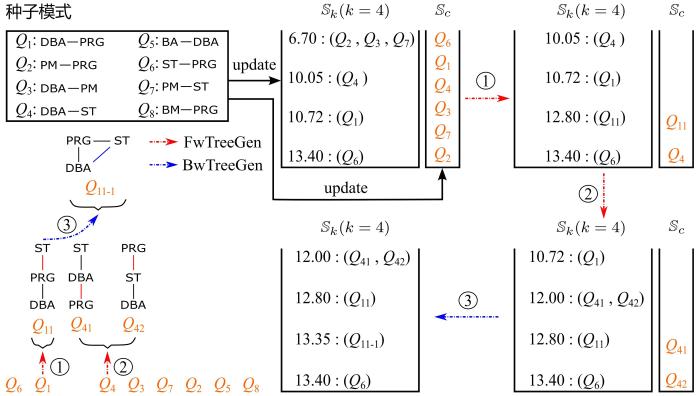
表2 种子模式的支持度,兴趣度和rank排名
Table 2
| 模式 | 支持度 | 兴趣度 | rank排名 |
|---|---|---|---|
| 20 | 13.40 | 1 | |
| 16 | 10.72 | 2 | |
| 15 | 10.05 | 3 | |
| 10 | 6.70 | 4 | |
| 10 | 6.70 | 4 | |
| 10 | 6.70 | 4 | |
| 5 | 3.35 | 5 | |
| 1 | 0.67 | 6 |
3.4 兴趣度优先的树模式识别
在这一阶段,ItrMiner以兴趣度为优先级,通过函数FwTreeGen扩展当前支持度最高的模式,以尽快提升最小兴趣度minItr并剪掉低兴趣度的模式.具体地,当
如图3所示,将八个种子模式
3.5 非树模式挖掘
非树模式挖掘,即后向扩展,是在当前模式的基础上继续增添新的边.算法2展示了后向扩展的具体细节.
输入:
输出:
1.initialize
2.initialize
3.while
4. for each pattern
5. if
6. break;
7.
8. for each pattern
9. if
10. insert
11. if
12. update minItr;
13. h++;
14.return
编码树
当树模式识别完成之后,BackSearch调用函数BwTreeGen后向扩展编码树
3.6 模式扩展约束规则
为了解决传统的使用频繁单边进行扩展的方法在Top⁃Rank⁃K模式挖掘中产生大量低兴趣度模式的问题,提出模式扩展约束规则,要求每个模式都有一个扩展约束支持度
有约束的模式扩展不会错过任何一个模式的生成.
给定图
图4

上述例子表明,在结果相同的情况下,采用带有约束的模式扩展策略,搜索空间会更小,算法的执行效率更高.下文将详细探讨这种优化对算法性能的影响.
4 实验
为了全面评估ItrMiner算法的性能进行了实验研究,并与基线算法进行比较.实验涵盖了真实图数据和合成图数据,考察算法的运行时间、内存消耗和可扩展性.每个实验重复五次,并对结果进行平均处理.
测试环境为一台配备2.5 GHz 48核CPU和192 GB RAM的服务器,操作系统为CentOS Linux release 7.8,实验代码均用java编写.
4.1 实验数据
使用如表3所示的六个真实数据集.
表 3 实验使用的数据集
Table 3
| 数据集 | 点集大小 | 边集大小 | 平均度数 |
|---|---|---|---|
| Amazon | 410236 | 3356824 | 16.36 |
| MiCo | 100000 | 1080298 | 21.61 |
| YouTube | 154817 | 1055572 | 13.63 |
| 81306 | 1768149 | 43.49 | |
| CiteSeer | 3312 | 4591 | 2.77 |
| PDB | 20226 | 83356 | 8.24 |
(1) Amazon[29]是产品联合采购网络,包含0.41×106个点和3.35×106条边.当两个商品a和b被客户同时购买的频次达到一定数量时,就会形成边
(2) MiCo[16]是由微软合作作者信息构建的网络,包含0.1×106个点和1.08×106条边.每个节点代表作者,每条边代表两位作者之间的合作关系.
(3) YouTube[30]是由来自YouTube平台的视频及其相关视频构建的网络,包含0.15×106个点和1.05×106条边.每个节点代表一个用户或频道,每条边代表两个节点之间的关系.
(4) Twitter[31]是来自Twitter平台的社交网络,包含八万多个点和1.76×106条边.每个节点代表一个Twitter用户,每条边代表两个用户的关注.由于原始图数据没有标签,因此随机地对节点添加标签,标签分布服从高斯分布.
(5) CiteSeer[16]是计算科学领域的引文网络,包含三千个点和四千条边.每个节点代表一篇学术论文,每条边代表两篇论文之间的引用关系.
(6) PDB[32]是来自PDB的一个蛋白质结构网络,包含两万多个点和八万多条边.每个节点代表一个原子,每条边表示分子之间的化学键.
4.2 实验设置
使用4.1的六种真实图数据集和通过图生成器生成的10种不同大小规模的人工合成图数据集.
使用Java实现ItrMiner和以下算法.
(1) TKG.通过实现TKG算法[25]并对其加入支持单个大图中的支持度和兴趣度的计算,使其能在单个大图中挖掘Top⁃Rank⁃K频繁模式.
(2) Grami.是一种改良版的Grami算法[16],在Grami的基础上引入本文提出的兴趣度计算来挖掘Top⁃Rank⁃K频繁模式.具体地,首先挖掘得到所有的频繁模式,随后计算其兴趣度,经排序后返回前
(3) ItrMinernopt.是ItrMiner无模式扩展约束的版本,与ItrMiner相比,ItrMinernopt除了在模式扩展中没有实现扩展约束以外,其余基本一致.
4.3 实验结果
4.3.1 实验一:
首先,固定系数
图5
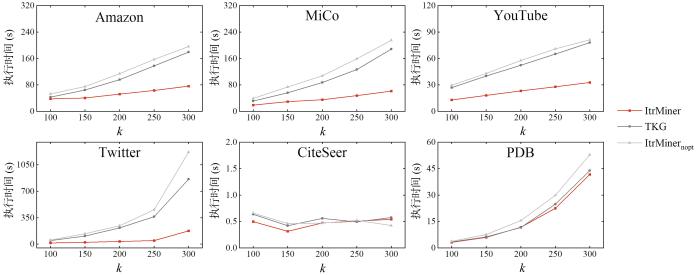
图5
在六个数据集上k对各算法执行时间的的影响
Fig.5
The execution time of each algorithm with different k on six datasets
(1)随着
(2)与TKG和ItrMinernopt相比,ItrMiner的效率更高,在六个真实数据集上,ItrMiner平均花费的时间分别为TKG的51.9%,39.2%,43.9%,18.7%,76.5%和94.4%.同时,ItrMiner的模式扩展约束对提升执行效率有显著作用,在六个真实数据集上,加入模式扩展约束后,ItrMiner平均花费的时间是ItrMinernopt的45.4%,32.3%,40.4%,14.1%,74.7%和78.0%.此外,ItrMiner在稠密的数据集上的表现尤为出色.以Twitter数据集为例,当
图6展示了各算法在六个真实数据集上的内存消耗.由图可见,随着
图6
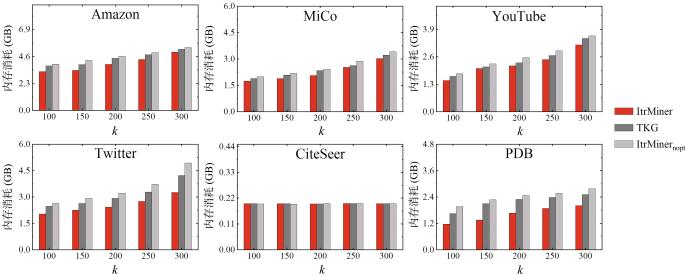
图6
在六个数据集上k对各算法内存消耗的的影响
Fig.5
The memory consumption of each algorithm with different k on six datasets
4.3.2 实验二:ItrMiner与Grami的比较
比较ItrMiner与Grami的性能,以评估使用ItrMiner进行前
需要注意,与ItrMiner在挖掘过程中动态维护兴趣度排名在前
表4 Grami和ItrMiner算法在六个数据集上的执行时间 (s)
Table 4
| 算法 | Amazon | MiCo | YouTube | CiteSeer | PDB | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Grami | 55.41 | 217.08 | 15.69 | 59.37 | 27.93 | 123.1 | 13.23 | 79.78 | 0.92 | 0.94 | 3.78 | 58.61 |
| ItrMiner | 36.02 | 74.19 | 17.38 | 59.95 | 12.67 | 32.12 | 15.64 | 173.4 | 0.47 | 0.42 | 3.28 | 41.79 |
表5 Grami和ItrMiner算法在六个数据集上的内存消耗 (GB)
Table 5
| 算法 | Amazon | MiCo | YouTube | CiteSeer | PDB | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Grami | 3.81 | 6.80 | 1.96 | 3.46 | 1.67 | 3.83 | 1.81 | 2.78 | 0.21 | 0.21 | 0.74 | 1.58 |
| ItrMiner | 3.30 | 4.97 | 1.73 | 3.02 | 1.48 | 3.16 | 2.03 | 3.26 | 0.18 | 0.18 | 1.13 | 1.98 |
由表4可知,在六个真实数据集上,ItrMiner的执行时间比Grami更短,尤其在YouTube数据集上,
由表5可知,除了PDB和Twitter数据集外,ItrMiner在其余数据集上的内存消耗比Grami更低.这是因为ItrMiner采用模式扩展约束策略,可以避免生成大量的冗余模式和实例检验,有效地减小了算法的搜索空间.但在PDB和Twitter数据集上,ItrMiner消耗的内存高于Grami,因为ItrMiner需要同时维护两个队列
实际应用中,用户通常难以确定适当的支持度阈值(参考例1).为此,本文在不同数据集上,对支持度阈值进行调整,并计算k不同时的挖掘任务耗时.表6展示了运行结果,表中黑体字表示性能最优.由表可见,ItrMiner在所有数据集上的执行时间均比Grami更短,并且,随着
表6 Grami和ItrMiner算法在六个数据集上的执行时间 (s)
Table 6
| 算法 | Amazon | MiCo | YouTube | CiteSeer | PDB | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 阈值降低50 | 阈值降低50 | 阈值降低50 | 阈值降低150 | 阈值不变 | 阈值降低20 | |||||||
| Grami | 61.90 | 244.8 | 23.72 | 101.1 | 31.93 | 160.6 | 20.23 | 266.7 | 0.92 | 0.94 | 5.78 | 110.6 |
| ItrMiner | 36.02 | 74.19 | 17.38 | 59.95 | 12.67 | 32.12 | 15.64 | 173.4 | 0.47 | 0.42 | 3.28 | 41.79 |
在不同数据集上比较这两种算法的性能表现,验证了ItrMiner的可行性和实用性,为实际应用中的用户提供更多选择和灵活性,更高效地进行模式挖掘分析.因此,可以将ItrMiner视为传统频繁模式挖掘的一种有价值的替代方案.
4.3.3 实验三:算法的可扩展性
首先,固定系数
图7
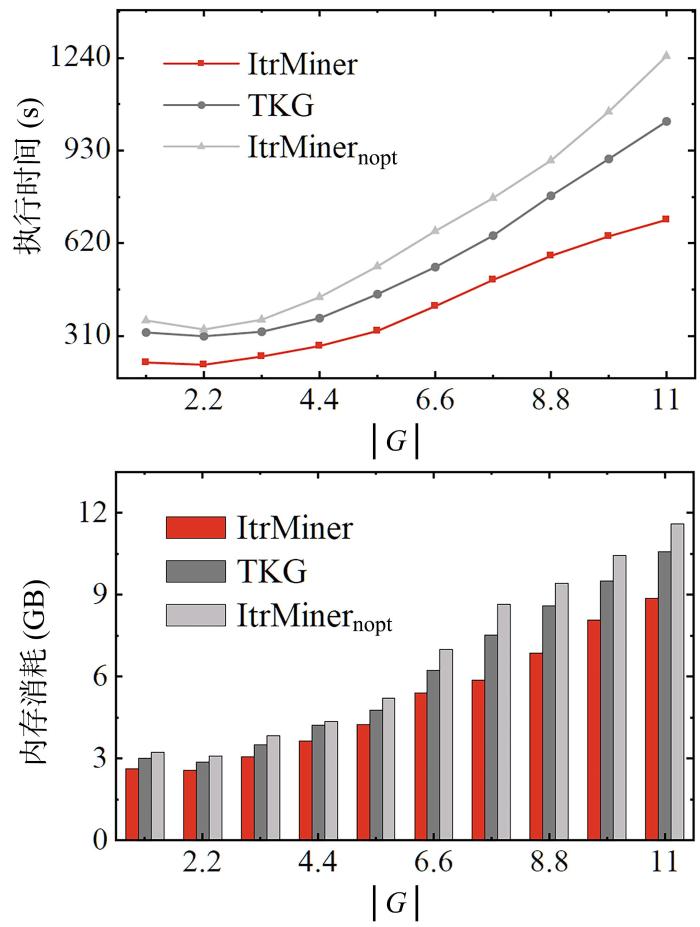
4.3.4 实验四:
首先,固定
图8
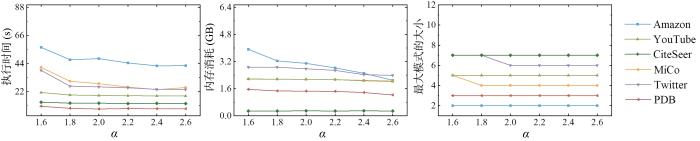
由图可见:(1)随着
5 结论
针对频繁模式挖掘支持度阈值难以设定的问题,本文研究了Top⁃Rank⁃K的频繁模式挖掘问题.首先设计了一项同时考虑模式大小和模式支持度的兴趣度指标,并基于该指标提出一种无须设置初始支持度阈值,直接挖掘排名前
未来将致力于解决更大规模图数据的频繁模式挖掘问题,并尝试通过并行计算的方法进一步提高ItrMiner算法的执行效率.
参考文献
Applications of link prediction in social networks:A review
Current trends in computer aided drug design and a highlight of drugs discovered via computational techniques:A review
Predicting ICU readmission using grouped physiological and medication trends
6Graph:A graph⁃theoretic approach to address pattern mining for Internet⁃wide IPv6 scanning
SPIN:Mining maximal frequent subgraphs from graph databases
∥
Fast mining Top⁃Rank⁃K frequent patterns by using node⁃lists
An efficient and effective algorithm for mining Top⁃Rank⁃K frequent patterns
PBSM:An efficient top⁃k subgraph matching algorithm
A scalable and generic framework to mine top⁃k representative subgraph patterns
∥
Diversified pattern mining on large graphs
∥
Mining Top⁃Rank⁃K frequent patterns
∥
Customized frequent patterns mining algorithms for enhanced Top⁃Rank⁃K frequent pattern mining
An efficient algorithm for mining Top⁃Rank⁃K frequent patterns from uncertain databases
∥
A new approach for mining Top⁃Rank⁃K erasable itemsets
∥
Finding frequent patterns in a large sparse graph
GraMi:Frequent subgraph and pattern mining in a single large graph
Arabesque:A system for distributed graph mining
∥
Fractal:A general⁃purpose graph pattern mining system
∥
Scalemine:Scalable parallel frequent subgraph mining in a single large graph
∥
G⁃miner:An efficient task⁃oriented graph mining system
∥
基于解耦概要图的大规模图数据高效分布式挖掘算法
An efficient distributed algorithm for large⁃scale graph data mining based on decoupled summary subgraph
A cost⁃effective approach for mining near⁃optimal top⁃k patterns
TGP:Mining top⁃k frequent closed graph pattern without minimum support
∥
FS3:A sampling based method for top‐k frequent subgraph mining
Tkg:Efficient mining of top⁃k frequent subgraphs
∥
Fast core⁃based top⁃k frequent pattern discovery in knowledge graphs
∥
What is frequent in a single graph?
∥
A (sub) graph isomorphism algorithm for matching large graphs
The dynamics of viral marketing
Statistics and social network of YouTube videos
∥
Learning to discover social circles in ego networks
∥
A distributed approach for graph mining in massive networks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}