南京大学学报(自然科学版) ›› 2024, Vol. 60 ›› Issue (1): 38–52.doi: 10.13232/j.cnki.jnju.2024.01.005
面向大图的Top⁃Rank⁃K频繁模式挖掘算法
邹杰军, 王欣( ), 石俊豪, 兰卓, 方宇, 张翀, 谢文波, 沈玲珍
), 石俊豪, 兰卓, 方宇, 张翀, 谢文波, 沈玲珍
- 西南石油大学计算机科学学院,成都,610500
Top⁃Rank⁃K frequent pattern mining algorithm for large graphs
Jiejun Zou, Xin Wang(), Junhao Shi, Zhuo Lan, Yu Fang, Chong Zhang, Wenbo Xie, Lingzhen Shen
- School of Computer Science,Southwest Petroleum University,Chengdu,610500,China
摘要:
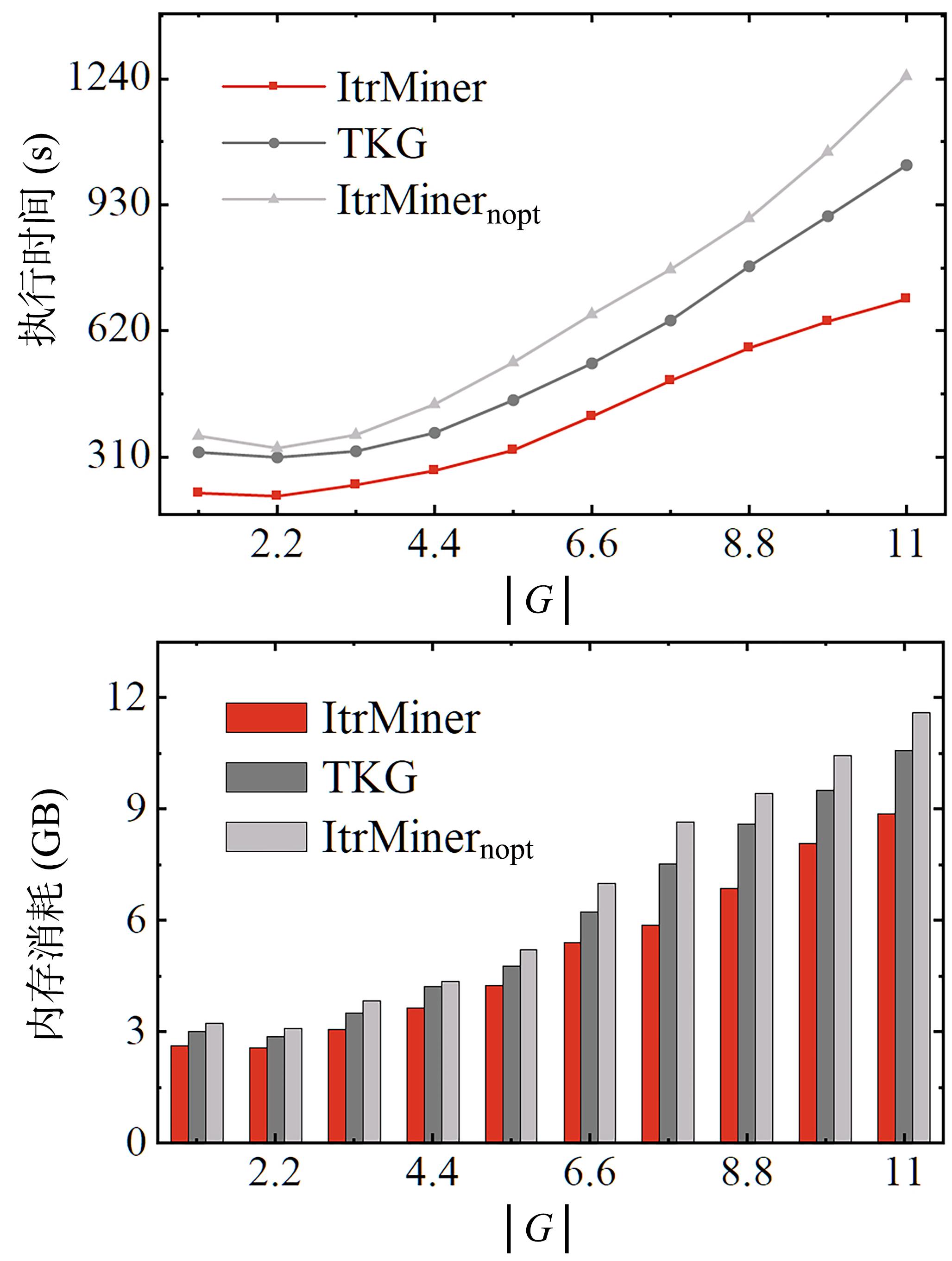
频繁模式挖掘(Frequent Pattern Mining,FPM)在社交分析中扮演重要角色,能从海量社交数据中挖掘用户行为的模式和规律,为社交网络的研究提供新的认识和决策支持.然而,对于一个FPM任务,设置一个合适的支持度阈值不容易;此外,FPM作为一个NP?hard问题,不存在多项式时间的算法.针对上述问题,提出一种无须用户设置初始支持度阈值的算法ItrMiner.该算法使用一种新的兴趣度指标对模式进行评估,综合考虑模式的大小和支持度,挖掘Top?Rank?K频繁模式.同时,为了解决去除初始支持度阈值后在算法剪枝阶段遇到的困难,提出基于树模式优先识别的策略和模式扩展约束策略,减少非必要候选模式的生成.在真实图和人工合成图数据集上进行了广泛的实验,证明ItrMiner在执行效率和可扩展性方面表现出色,尤其在稠密的数据集上,其时间开销仅为基线算法Top?K Graph Miner的13.2%.另外,提出的模式扩展约束策略的有效性较高,和无扩展约束优化的ItrMinernopt算法相比,效率提升最高可达9.5倍.
中图分类号:
- TP311















| 1 | Daud N N, Ab Hamid S H, Saadoon M,et al. Applications of link prediction in social networks:A review. Journal of Network and Computer Applications,2020,166:102716. |
| 2 | Sabe V T, Ntombela T, Jhamba L A,et al. Current trends in computer aided drug design and a highlight of drugs discovered via computational techniques:A review. European Journal of Medicinal Chemistry,2021,224:113705. |
| 3 | Xue Y, Klabjan D, Luo Y. Predicting ICU readmission using grouped physiological and medication trends. Artificial Intelligence in Medicine,2019,95:27-37. |
| 4 | Yang T, Hou B N, Cai Z P,et al. 6Graph:A graph?theoretic approach to address pattern mining for Internet?wide IPv6 scanning. Computer Networks,2022,203:108666. |
| 5 | Huan J, Wang W, Prins J,et al. SPIN:Mining maximal frequent subgraphs from graph databases∥Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Seattle,WA,USA:ACM,2004:581-586. |
| 6 | Deng Z H. Fast mining Top?Rank?K frequent patterns by using node?lists. Expert Systems with Applications,2014,41(4):1763-1768. |
| 7 | Huynh?Thi?Le Q, Le T, Vo B,et al. An efficient and effective algorithm for mining Top?Rank?K frequent patterns. Expert Systems with Applications,2015,42(1):156-164. |
| 8 | Chen W, Liu J, Chen Z Y,et al. PBSM:An efficient top?k subgraph matching algorithm. International Journal of Pattern Recognition and Artificial Intelligence,2018,32(6):1850020. |
| 9 | Natarajan D, Ranu S. A scalable and generic framework to mine top?k representative subgraph patterns∥2016 IEEE 16th International Conference on Data Mining. Barcelona,Spain:IEEE,2016:370-379. |
| 10 | Wang X, Tang L, Liu Y,et al. Diversified pattern mining on large graphs∥The 32nd International Conference on Database and Expert Systems Applications. Springer Berlin Heidelberg,2021:171-184. |
| 11 | Deng Z H, Fang G D. Mining Top?Rank?K frequent patterns∥2007 International Conference on Machine Learning and Cybernetics. Hong Kong,China:IEEE,2007:851-856. |
| 12 | Abdelaal A A, Abed S, Al?Shayeji M,et al. Customized frequent patterns mining algorithms for enhanced Top?Rank?K frequent pattern mining. Expert Systems with Applications,2021,169:114530. |
| 13 | Goyal N, Jain S K. An efficient algorithm for mining Top?Rank?K frequent patterns from uncertain databases∥2016 2nd International Conference on Applied and Theoretical Computing and Communication Technology. Bangalore,India:IEEE,2016:324-328. |
| 14 | Nguyen G, Le T, Vo B,et al. A new approach for mining Top?Rank?K erasable itemsets∥The 6th Asian Conference on Intelligent Information and Database Systems. Springer Berlin Heidelberg,2014:73-82. |
| 15 | Kuramochi M, Karypis G. Finding frequent patterns in a large sparse graph. Data Mining and Knowledge Discovery,2005,11(3):243-271. |
| 16 | Elseidy M, Abdelhamid E, Skiadopoulos S,et al. GraMi:Frequent subgraph and pattern mining in a single large graph. Proceedings of the VLDB Endowment,2014,7(7):517-528. |
| 17 | Teixeira C H C, Fonseca A J, Serafini M,et al. Arabesque:A system for distributed graph mining∥Proceedings of the 25th Symposium on Operating Systems Principles. Monterey,CA,USA:ACM,2015:425-440. |
| 18 | Dias V, Teixeira C H C, Guedes D,et al. Fractal:A general?purpose graph pattern mining system∥Proceedings of 2019 International Conference on Management of Data. Amsterdam,Netherlands:ACM,2019:1357-1374. |
| 19 | Abdelhamid E, Abdelaziz I, Kalnis P,et al. Scalemine:Scalable parallel frequent subgraph mining in a single large graph∥Proceedings of the International Conference for High Performance Computing,Networking,Storage and Analysis. Salt Lake City,UT,USA:IEEE,2016:716-727. |
| 20 | Chen H Z, Liu M, Zhao Y J,et al. G?miner:An efficient task?oriented graph mining system∥Proceedings of the 13th EuroSys Conference. Porto,Portugal:ACM,2018:32. |
| 21 | 李玲,印莹,赵宇海,等. 基于解耦概要图的大规模图数据高效分布式挖掘算法. 计算机学报,2020,43(7):1183-1198. |
| Li L, Yin Y, Zhao Y H,et al. An efficient distributed algorithm for large?scale graph data mining based on decoupled summary subgraph. Chinese Journal of Computers,2020,43(7):1183-1198. | |
| 22 | Wang X, Lan Z, He Y A,et al. A cost?effective approach for mining near?optimal top?k patterns. Expert Systems with Applications,2022,202:117262. |
| 23 | Li Y H, Lin Q, Li R X,et al. TGP:Mining top?k frequent closed graph pattern without minimum support∥The 6th International Conference on Advanced Data Mining and Applications. Springer Berlin Heidelberg,2010:537-548. |
| 24 | Saha T K, Al Hasan M. FS3:A sampling based method for top‐k frequent subgraph mining. Statistical Analysis and Data Mining:The ASA Data Science Journal,2015,8(4):245-261. |
| 25 | Fournier?Viger P, Cheng C, Lin J C W,et al. Tkg:Efficient mining of top?k frequent subgraphs∥The 7th International Conference on Big Data Analytics. Springer Berlin Heidelberg,2019:209-226. |
| 26 | Zeng J, Leong H U, Yan X,et al. Fast core?based top?k frequent pattern discovery in knowledge graphs∥2021 IEEE 37th International Conference on Data Engineering. Chania,Greece:IEEE,2021:936-947. |
| 27 | Bringmann B, Nijssen S. What is frequent in a single graph?∥The 12th Pacific?Asia Conference on Knowledge Discovery and Data Mining. Springer Berlin Heidelberg,2008:858-863. |
| 28 | Cordella L P, Foggia P, Sansone C,et al. A (sub) graph isomorphism algorithm for matching large graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(10):1367-1372. |
| 29 | Leskovec J, Adamic L A, Huberman B A. The dynamics of viral marketing. ACM Transactions on the Web,2007,1(1):5. |
| 30 | Cheng X, Dale C, Liu J C. Statistics and social network of YouTube videos∥2008 16th Interntional Workshop on Quality of Service. Enschede,Netherlands:IEEE,2008:229-238. |
| 31 | Mcauley J, Leskovec J. Learning to discover social circles in ego networks∥Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe,NV,USA:Curran Associates Inc.,2012:539-547. |
| 32 | Talukder N, Zaki M J. A distributed approach for graph mining in massive networks. Data Mining and Knowledge Discovery,2016,30(5):1024-1052. |
| [1] | 韦素云1**,业宁1,吉根林2,张丹丹1,殷晓飞1 . 基于项目类别和兴趣度的协同过滤推荐算法*[J]. 南京大学学报(自然科学版), 2013, 49(2): 142-149. |
|
||