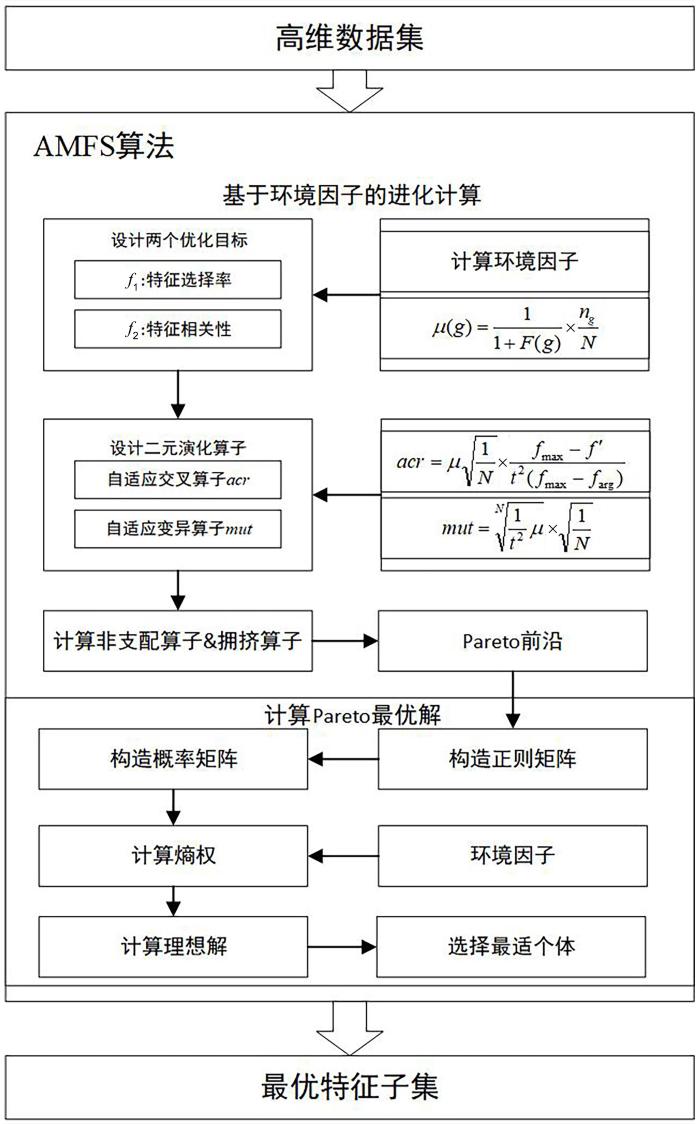
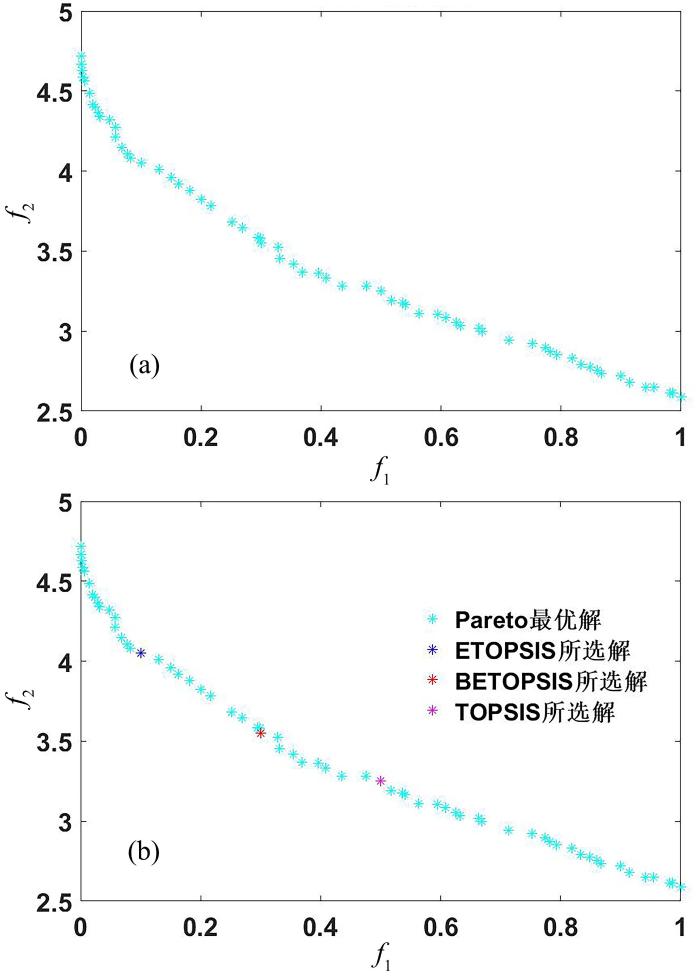
Multi⁃objective evolutionary algorithms have significant advantages in feature selection,but their performance in solving the optimal feature subset of high⁃dimensional data is still poor,and selecting a reasonable optimal solution from the obtained Pareto solution set remains a challenging issue. To solve this problem,this paper proposes a multi⁃objective feature selection algorithm based on adaptive environmental factor entropy weight decision⁃making. The advantages of the proposed algorithm are as follows. Firstly,key features are adaptively identified by designing environmental factors to optimize candidate feature subspaces. Secondly,environment factors are embedded into improved crossover and mutation operators to achieve adaptive search for the globally optimal feature subset. Finally,using an entropy weight decision⁃making strategy that correlates environmental factors,the optimal solution is selected from the obtained Pareto solution set. Experiments show that the proposed algorithm has higher classification accuracy and accurately obtains the global optimal solution compared to the existing five multi⁃objective feature selection algorithms,verifying the effectiveness of the proposed algorithm.
常见的特征选择方法可分为过滤式方法[7]、封装式方法[8-10]和嵌入式方法[11]三大类.过滤式方法在未训练学习器的情况下评估特征子集,虽然其扩展性强且计算成本低,但由于缺少学习器的训练学习导致分类性能较差.封装式方法结合具体学习器的误差来衡量候选特征子集,取得了较好的分类准确性,但其需要计算特征间的交互关系,计算开销较大.嵌入式的方法将特征选择与学习器训练相结合,在学习算法的执行过程中完成最优特征子集的选择.虽然上述三类特征选择方法已有大量探索,但仍存在特征子集陷入局部最优、关键特征选择不准确等问题.假设一个数据集的特征数为n,则存在2 n -1(除去空集)种候选特征子集,采用穷举搜索高维数据特征显然不可行.针对高维数据特征选择亟须解决的问题,一是由于维度高导致搜索空间巨大,需要减少评估候选特征子集的计算量;二是特征间存在复杂的互转化关系,需要准确识别与选择关键特征来构造全局最优特征子集.
近年来,进化计算方法(Evolutionary Computing Algorithms,EAs)因其强大的全局寻优能力引起了研究者的广泛关注,基于进化计算的特征选择方法可以提高全局最优解的搜索效率,根据优化目标的不同可以分为基于单目标的特征选择优化方法和基于多目标的特征选择优化方法.虽然基于多目标优化的特征选择方法一次运行就能获得多个解,但从获得的Pareto解集中正确选择合理的唯一特征子集仍是难点.比较经典的多目标优化算法是NSGA⁃II[12-14],主要采用非支配排序与拥挤距离的思想来评估两个优化目标上的个体,最后构成Pareto解集.近期,针对特征选择问题,学者们也提出众多有效的基于进化计算的多目标特征选择方法.Xu et al[15]提出NSGA⁃Ⅱ与MOPSO混合方法进行多目标特征选择,虽然探索性强,收敛性强,还能避免陷入局部最优的困境,但筛选的特征子集仍包含大量的冗余特征,且时间复杂度较高.Liu et al[16]提出基于高斯混合模型和改进NSGA⁃Ⅱ算法的多目标优化方法,利用平均距离将整个种群划分为若干子种群,再对各个子种群执行选择、交叉和变异操作.该方法能有效保持Pareto最优解集的多样性,进一步提高算法的收敛性,但忽略了特征之间的复杂相关性,增加了剔除关键特征的可能性,折中解较差.Zhang et al[17]提出一种改进的NSGA⁃Ⅱ算法,引入余弦相似性,使下一代的种群个体向偏好方向聚集,然后根据预期的特征首选项来调整解决方案的设置方向,以此评估优化算法的收敛性、解多样性和偏好一致性,但其没有针对获得的Pareto解集进行分析,无法获取最优个体.
Zhang et al[19]提出自学习二差分进化算法,用基于概率差的二元变异算子引导个体快速定位潜在的最优区域,还提出一种新型净化搜索算子来提高位于最优区域精英个体的自学习能力.具有拥挤距离的高效非支配排序算子可以降低差分进化中算子选择的计算复杂度,大幅度缩短搜索时间,提升分类表现,但在高维小样本数据集中的效果不理想,不具有普适性.Zhang et al[20]提出基于成本的特征选择多目标粒子群优化算法,采用概率的编码技术和有效的混合算子,将拥挤距离、外部档案和Pareto支配关系应用于粒子群算法,明显缩减了特征子集的搜索空间,有效解决了约简变量过多导致的局部最优问题,但没有考虑最优全局解集的情况.孙哲人等[21]提出一个基于多样性分类和距离回归的进化算法,把种群中的所有解作为训练样本,并根据是否为最小相关解,把训练样本分类为正负样本,使模型学习到训练样本中含有的分类信息.此外,它采用Kriging作为局部回归代理模型,其选择种群中距离当前候选解最近的解作为训练样本,拟合训练样本与理想点的距离,然后通过K⁃means方法把候选解划分为μ个簇,从每个簇中选择一个用于真实评估的候选解.该方法在低维度特征空间取得了不错的效果,但随着目标数量的增加,目标空间呈指数扩大,算法效果不理想.Zhou et al[22]提出一种基于两级粒子协作的多目标优化特征选择策略来进行高维数据的特征选择,考虑了特征数量、分类错误率和距离测量三个目标,将二进制粒子群优化与两级粒子协作策略相结合,有效地减少了特征数量,还组合了随机生成的普通粒子和ReliefF过滤粒子来实现快速收敛.然而,该方法的平均分类精度效果不佳.Rashno et al[23]提出一种新型的多目标粒子群优化特征选择方法,将特征向量解码为粒子并在二维优化空间中进行排名,对粒子进行排序,将优化空间分成主导粒子带与非主导粒子带,通过数学与实验详细解析了优化空间中均匀与非均匀分布对粒子模型的影响,将粒子秩与特征秩运用到迭代过程来更新粒子的速度与位置,找到多目标优化空间中最接近原点的最佳粒子.然而,该方法没有解决优势粒子与非优势粒子之间粒子距离的优化组合,所以得到的最佳粒子不一定是Pareto解集中的最适解.Wang et al[24]提出基于样本还原策略和进化算法的多目标特征选择框架,该框架主要包含K⁃means聚类的差分选择方法和样品利用策略,还在框架中嵌入了粒子更新模型的改进人工蜂群算法.该方法虽然降低了计算成本,减少了进化过程中使用的样本量,缩短了进化迭代的时间,但其在高维特征空间的应用效果不佳.
Multi⁃population coevolutionary dynamic multi⁃objective particle swarm optimization algorithm for power control based on improved crowding distance archive management in CRNs
BryanJ A, ZhangY L, WangH L,et al. Multi⁃objective design optimization of an integrated regenerative transcritical cycle considering sensitivity in Pareto⁃optimal solutions. Energy Conversion and Management:X,2023(18):100364.
PonsiF, BassoliE, VincenziL.
A multi⁃objective optimization approach for FE model updating based on a selection criterion of the preferred Pareto⁃optimal solution
... 常见的特征选择方法可分为过滤式方法[7]、封装式方法[8-10]和嵌入式方法[11]三大类.过滤式方法在未训练学习器的情况下评估特征子集,虽然其扩展性强且计算成本低,但由于缺少学习器的训练学习导致分类性能较差.封装式方法结合具体学习器的误差来衡量候选特征子集,取得了较好的分类准确性,但其需要计算特征间的交互关系,计算开销较大.嵌入式的方法将特征选择与学习器训练相结合,在学习算法的执行过程中完成最优特征子集的选择.虽然上述三类特征选择方法已有大量探索,但仍存在特征子集陷入局部最优、关键特征选择不准确等问题.假设一个数据集的特征数为n,则存在2 n -1(除去空集)种候选特征子集,采用穷举搜索高维数据特征显然不可行.针对高维数据特征选择亟须解决的问题,一是由于维度高导致搜索空间巨大,需要减少评估候选特征子集的计算量;二是特征间存在复杂的互转化关系,需要准确识别与选择关键特征来构造全局最优特征子集. ...
Wrapper feature selection method based differential evolution and extreme learning machine for intrusion detection system
1
2022
... 常见的特征选择方法可分为过滤式方法[7]、封装式方法[8-10]和嵌入式方法[11]三大类.过滤式方法在未训练学习器的情况下评估特征子集,虽然其扩展性强且计算成本低,但由于缺少学习器的训练学习导致分类性能较差.封装式方法结合具体学习器的误差来衡量候选特征子集,取得了较好的分类准确性,但其需要计算特征间的交互关系,计算开销较大.嵌入式的方法将特征选择与学习器训练相结合,在学习算法的执行过程中完成最优特征子集的选择.虽然上述三类特征选择方法已有大量探索,但仍存在特征子集陷入局部最优、关键特征选择不准确等问题.假设一个数据集的特征数为n,则存在2 n -1(除去空集)种候选特征子集,采用穷举搜索高维数据特征显然不可行.针对高维数据特征选择亟须解决的问题,一是由于维度高导致搜索空间巨大,需要减少评估候选特征子集的计算量;二是特征间存在复杂的互转化关系,需要准确识别与选择关键特征来构造全局最优特征子集. ...
Global Filter–Wrapper method based on class?dependent correlation for text classification
0
2019
A novel wrapper?based feature subset selection method using modified binary differential evolution algorithm
1
2021
... 常见的特征选择方法可分为过滤式方法[7]、封装式方法[8-10]和嵌入式方法[11]三大类.过滤式方法在未训练学习器的情况下评估特征子集,虽然其扩展性强且计算成本低,但由于缺少学习器的训练学习导致分类性能较差.封装式方法结合具体学习器的误差来衡量候选特征子集,取得了较好的分类准确性,但其需要计算特征间的交互关系,计算开销较大.嵌入式的方法将特征选择与学习器训练相结合,在学习算法的执行过程中完成最优特征子集的选择.虽然上述三类特征选择方法已有大量探索,但仍存在特征子集陷入局部最优、关键特征选择不准确等问题.假设一个数据集的特征数为n,则存在2 n -1(除去空集)种候选特征子集,采用穷举搜索高维数据特征显然不可行.针对高维数据特征选择亟须解决的问题,一是由于维度高导致搜索空间巨大,需要减少评估候选特征子集的计算量;二是特征间存在复杂的互转化关系,需要准确识别与选择关键特征来构造全局最优特征子集. ...
A fault detection method based on embedded feature extraction and SVM classification for UAV motors
1
2022
... 常见的特征选择方法可分为过滤式方法[7]、封装式方法[8-10]和嵌入式方法[11]三大类.过滤式方法在未训练学习器的情况下评估特征子集,虽然其扩展性强且计算成本低,但由于缺少学习器的训练学习导致分类性能较差.封装式方法结合具体学习器的误差来衡量候选特征子集,取得了较好的分类准确性,但其需要计算特征间的交互关系,计算开销较大.嵌入式的方法将特征选择与学习器训练相结合,在学习算法的执行过程中完成最优特征子集的选择.虽然上述三类特征选择方法已有大量探索,但仍存在特征子集陷入局部最优、关键特征选择不准确等问题.假设一个数据集的特征数为n,则存在2 n -1(除去空集)种候选特征子集,采用穷举搜索高维数据特征显然不可行.针对高维数据特征选择亟须解决的问题,一是由于维度高导致搜索空间巨大,需要减少评估候选特征子集的计算量;二是特征间存在复杂的互转化关系,需要准确识别与选择关键特征来构造全局最优特征子集. ...
基于多目标优化算法NSGA?Ⅱ推荐相似缺陷报告
2
2019
... 近年来,进化计算方法(Evolutionary Computing Algorithms,EAs)因其强大的全局寻优能力引起了研究者的广泛关注,基于进化计算的特征选择方法可以提高全局最优解的搜索效率,根据优化目标的不同可以分为基于单目标的特征选择优化方法和基于多目标的特征选择优化方法.虽然基于多目标优化的特征选择方法一次运行就能获得多个解,但从获得的Pareto解集中正确选择合理的唯一特征子集仍是难点.比较经典的多目标优化算法是NSGA⁃II[12-14],主要采用非支配排序与拥挤距离的思想来评估两个优化目标上的个体,最后构成Pareto解集.近期,针对特征选择问题,学者们也提出众多有效的基于进化计算的多目标特征选择方法.Xu et al[15]提出NSGA⁃Ⅱ与MOPSO混合方法进行多目标特征选择,虽然探索性强,收敛性强,还能避免陷入局部最优的困境,但筛选的特征子集仍包含大量的冗余特征,且时间复杂度较高.Liu et al[16]提出基于高斯混合模型和改进NSGA⁃Ⅱ算法的多目标优化方法,利用平均距离将整个种群划分为若干子种群,再对各个子种群执行选择、交叉和变异操作.该方法能有效保持Pareto最优解集的多样性,进一步提高算法的收敛性,但忽略了特征之间的复杂相关性,增加了剔除关键特征的可能性,折中解较差.Zhang et al[17]提出一种改进的NSGA⁃Ⅱ算法,引入余弦相似性,使下一代的种群个体向偏好方向聚集,然后根据预期的特征首选项来调整解决方案的设置方向,以此评估优化算法的收敛性、解多样性和偏好一致性,但其没有针对获得的Pareto解集进行分析,无法获取最优个体. ...
Recommending similar bug reports based on multi?targets optimization algorithm NSGA?Ⅱ
2
2019
... 近年来,进化计算方法(Evolutionary Computing Algorithms,EAs)因其强大的全局寻优能力引起了研究者的广泛关注,基于进化计算的特征选择方法可以提高全局最优解的搜索效率,根据优化目标的不同可以分为基于单目标的特征选择优化方法和基于多目标的特征选择优化方法.虽然基于多目标优化的特征选择方法一次运行就能获得多个解,但从获得的Pareto解集中正确选择合理的唯一特征子集仍是难点.比较经典的多目标优化算法是NSGA⁃II[12-14],主要采用非支配排序与拥挤距离的思想来评估两个优化目标上的个体,最后构成Pareto解集.近期,针对特征选择问题,学者们也提出众多有效的基于进化计算的多目标特征选择方法.Xu et al[15]提出NSGA⁃Ⅱ与MOPSO混合方法进行多目标特征选择,虽然探索性强,收敛性强,还能避免陷入局部最优的困境,但筛选的特征子集仍包含大量的冗余特征,且时间复杂度较高.Liu et al[16]提出基于高斯混合模型和改进NSGA⁃Ⅱ算法的多目标优化方法,利用平均距离将整个种群划分为若干子种群,再对各个子种群执行选择、交叉和变异操作.该方法能有效保持Pareto最优解集的多样性,进一步提高算法的收敛性,但忽略了特征之间的复杂相关性,增加了剔除关键特征的可能性,折中解较差.Zhang et al[17]提出一种改进的NSGA⁃Ⅱ算法,引入余弦相似性,使下一代的种群个体向偏好方向聚集,然后根据预期的特征首选项来调整解决方案的设置方向,以此评估优化算法的收敛性、解多样性和偏好一致性,但其没有针对获得的Pareto解集进行分析,无法获取最优个体. ...
Multi?objective intelligent production optimal scheduling based on improved NSGA?Ⅱ algorithm
0
2021
Structural,operational and economic optimization of cryogenic natural gas plant using NSGAII two?objective genetic algorithm
1
2018
... 近年来,进化计算方法(Evolutionary Computing Algorithms,EAs)因其强大的全局寻优能力引起了研究者的广泛关注,基于进化计算的特征选择方法可以提高全局最优解的搜索效率,根据优化目标的不同可以分为基于单目标的特征选择优化方法和基于多目标的特征选择优化方法.虽然基于多目标优化的特征选择方法一次运行就能获得多个解,但从获得的Pareto解集中正确选择合理的唯一特征子集仍是难点.比较经典的多目标优化算法是NSGA⁃II[12-14],主要采用非支配排序与拥挤距离的思想来评估两个优化目标上的个体,最后构成Pareto解集.近期,针对特征选择问题,学者们也提出众多有效的基于进化计算的多目标特征选择方法.Xu et al[15]提出NSGA⁃Ⅱ与MOPSO混合方法进行多目标特征选择,虽然探索性强,收敛性强,还能避免陷入局部最优的困境,但筛选的特征子集仍包含大量的冗余特征,且时间复杂度较高.Liu et al[16]提出基于高斯混合模型和改进NSGA⁃Ⅱ算法的多目标优化方法,利用平均距离将整个种群划分为若干子种群,再对各个子种群执行选择、交叉和变异操作.该方法能有效保持Pareto最优解集的多样性,进一步提高算法的收敛性,但忽略了特征之间的复杂相关性,增加了剔除关键特征的可能性,折中解较差.Zhang et al[17]提出一种改进的NSGA⁃Ⅱ算法,引入余弦相似性,使下一代的种群个体向偏好方向聚集,然后根据预期的特征首选项来调整解决方案的设置方向,以此评估优化算法的收敛性、解多样性和偏好一致性,但其没有针对获得的Pareto解集进行分析,无法获取最优个体. ...
Design optimization of a shell?and?tube heat exchanger with disc?and?doughnut baffles for aero?engine using one hybrid method of NSGA?Ⅱ and MOPSO
1
2023
... 近年来,进化计算方法(Evolutionary Computing Algorithms,EAs)因其强大的全局寻优能力引起了研究者的广泛关注,基于进化计算的特征选择方法可以提高全局最优解的搜索效率,根据优化目标的不同可以分为基于单目标的特征选择优化方法和基于多目标的特征选择优化方法.虽然基于多目标优化的特征选择方法一次运行就能获得多个解,但从获得的Pareto解集中正确选择合理的唯一特征子集仍是难点.比较经典的多目标优化算法是NSGA⁃II[12-14],主要采用非支配排序与拥挤距离的思想来评估两个优化目标上的个体,最后构成Pareto解集.近期,针对特征选择问题,学者们也提出众多有效的基于进化计算的多目标特征选择方法.Xu et al[15]提出NSGA⁃Ⅱ与MOPSO混合方法进行多目标特征选择,虽然探索性强,收敛性强,还能避免陷入局部最优的困境,但筛选的特征子集仍包含大量的冗余特征,且时间复杂度较高.Liu et al[16]提出基于高斯混合模型和改进NSGA⁃Ⅱ算法的多目标优化方法,利用平均距离将整个种群划分为若干子种群,再对各个子种群执行选择、交叉和变异操作.该方法能有效保持Pareto最优解集的多样性,进一步提高算法的收敛性,但忽略了特征之间的复杂相关性,增加了剔除关键特征的可能性,折中解较差.Zhang et al[17]提出一种改进的NSGA⁃Ⅱ算法,引入余弦相似性,使下一代的种群个体向偏好方向聚集,然后根据预期的特征首选项来调整解决方案的设置方向,以此评估优化算法的收敛性、解多样性和偏好一致性,但其没有针对获得的Pareto解集进行分析,无法获取最优个体. ...
Multi?objective optimization for greenhouse light environment using Gaussian mixture model and an improved NSGA?Ⅱ algorithm
1
2023
... 近年来,进化计算方法(Evolutionary Computing Algorithms,EAs)因其强大的全局寻优能力引起了研究者的广泛关注,基于进化计算的特征选择方法可以提高全局最优解的搜索效率,根据优化目标的不同可以分为基于单目标的特征选择优化方法和基于多目标的特征选择优化方法.虽然基于多目标优化的特征选择方法一次运行就能获得多个解,但从获得的Pareto解集中正确选择合理的唯一特征子集仍是难点.比较经典的多目标优化算法是NSGA⁃II[12-14],主要采用非支配排序与拥挤距离的思想来评估两个优化目标上的个体,最后构成Pareto解集.近期,针对特征选择问题,学者们也提出众多有效的基于进化计算的多目标特征选择方法.Xu et al[15]提出NSGA⁃Ⅱ与MOPSO混合方法进行多目标特征选择,虽然探索性强,收敛性强,还能避免陷入局部最优的困境,但筛选的特征子集仍包含大量的冗余特征,且时间复杂度较高.Liu et al[16]提出基于高斯混合模型和改进NSGA⁃Ⅱ算法的多目标优化方法,利用平均距离将整个种群划分为若干子种群,再对各个子种群执行选择、交叉和变异操作.该方法能有效保持Pareto最优解集的多样性,进一步提高算法的收敛性,但忽略了特征之间的复杂相关性,增加了剔除关键特征的可能性,折中解较差.Zhang et al[17]提出一种改进的NSGA⁃Ⅱ算法,引入余弦相似性,使下一代的种群个体向偏好方向聚集,然后根据预期的特征首选项来调整解决方案的设置方向,以此评估优化算法的收敛性、解多样性和偏好一致性,但其没有针对获得的Pareto解集进行分析,无法获取最优个体. ...
Multi?objective optimization for materials design with improved NSGA?Ⅱ
1
2021
... 近年来,进化计算方法(Evolutionary Computing Algorithms,EAs)因其强大的全局寻优能力引起了研究者的广泛关注,基于进化计算的特征选择方法可以提高全局最优解的搜索效率,根据优化目标的不同可以分为基于单目标的特征选择优化方法和基于多目标的特征选择优化方法.虽然基于多目标优化的特征选择方法一次运行就能获得多个解,但从获得的Pareto解集中正确选择合理的唯一特征子集仍是难点.比较经典的多目标优化算法是NSGA⁃II[12-14],主要采用非支配排序与拥挤距离的思想来评估两个优化目标上的个体,最后构成Pareto解集.近期,针对特征选择问题,学者们也提出众多有效的基于进化计算的多目标特征选择方法.Xu et al[15]提出NSGA⁃Ⅱ与MOPSO混合方法进行多目标特征选择,虽然探索性强,收敛性强,还能避免陷入局部最优的困境,但筛选的特征子集仍包含大量的冗余特征,且时间复杂度较高.Liu et al[16]提出基于高斯混合模型和改进NSGA⁃Ⅱ算法的多目标优化方法,利用平均距离将整个种群划分为若干子种群,再对各个子种群执行选择、交叉和变异操作.该方法能有效保持Pareto最优解集的多样性,进一步提高算法的收敛性,但忽略了特征之间的复杂相关性,增加了剔除关键特征的可能性,折中解较差.Zhang et al[17]提出一种改进的NSGA⁃Ⅱ算法,引入余弦相似性,使下一代的种群个体向偏好方向聚集,然后根据预期的特征首选项来调整解决方案的设置方向,以此评估优化算法的收敛性、解多样性和偏好一致性,但其没有针对获得的Pareto解集进行分析,无法获取最优个体. ...
A hybrid feature selection approach for Microarray datasets using graph theoretic?based method
Binary differential evolution with self?learning for multi?objective feature selection
2
2020
... Zhang et al[19]提出自学习二差分进化算法,用基于概率差的二元变异算子引导个体快速定位潜在的最优区域,还提出一种新型净化搜索算子来提高位于最优区域精英个体的自学习能力.具有拥挤距离的高效非支配排序算子可以降低差分进化中算子选择的计算复杂度,大幅度缩短搜索时间,提升分类表现,但在高维小样本数据集中的效果不理想,不具有普适性.Zhang et al[20]提出基于成本的特征选择多目标粒子群优化算法,采用概率的编码技术和有效的混合算子,将拥挤距离、外部档案和Pareto支配关系应用于粒子群算法,明显缩减了特征子集的搜索空间,有效解决了约简变量过多导致的局部最优问题,但没有考虑最优全局解集的情况.孙哲人等[21]提出一个基于多样性分类和距离回归的进化算法,把种群中的所有解作为训练样本,并根据是否为最小相关解,把训练样本分类为正负样本,使模型学习到训练样本中含有的分类信息.此外,它采用Kriging作为局部回归代理模型,其选择种群中距离当前候选解最近的解作为训练样本,拟合训练样本与理想点的距离,然后通过K⁃means方法把候选解划分为μ个簇,从每个簇中选择一个用于真实评估的候选解.该方法在低维度特征空间取得了不错的效果,但随着目标数量的增加,目标空间呈指数扩大,算法效果不理想.Zhou et al[22]提出一种基于两级粒子协作的多目标优化特征选择策略来进行高维数据的特征选择,考虑了特征数量、分类错误率和距离测量三个目标,将二进制粒子群优化与两级粒子协作策略相结合,有效地减少了特征数量,还组合了随机生成的普通粒子和ReliefF过滤粒子来实现快速收敛.然而,该方法的平均分类精度效果不佳.Rashno et al[23]提出一种新型的多目标粒子群优化特征选择方法,将特征向量解码为粒子并在二维优化空间中进行排名,对粒子进行排序,将优化空间分成主导粒子带与非主导粒子带,通过数学与实验详细解析了优化空间中均匀与非均匀分布对粒子模型的影响,将粒子秩与特征秩运用到迭代过程来更新粒子的速度与位置,找到多目标优化空间中最接近原点的最佳粒子.然而,该方法没有解决优势粒子与非优势粒子之间粒子距离的优化组合,所以得到的最佳粒子不一定是Pareto解集中的最适解.Wang et al[24]提出基于样本还原策略和进化算法的多目标特征选择框架,该框架主要包含K⁃means聚类的差分选择方法和样品利用策略,还在框架中嵌入了粒子更新模型的改进人工蜂群算法.该方法虽然降低了计算成本,减少了进化过程中使用的样本量,缩短了进化迭代的时间,但其在高维特征空间的应用效果不佳. ...
Multi?objective particle swarm optimization approach for cost?based feature selection in classification
2
2017
... Zhang et al[19]提出自学习二差分进化算法,用基于概率差的二元变异算子引导个体快速定位潜在的最优区域,还提出一种新型净化搜索算子来提高位于最优区域精英个体的自学习能力.具有拥挤距离的高效非支配排序算子可以降低差分进化中算子选择的计算复杂度,大幅度缩短搜索时间,提升分类表现,但在高维小样本数据集中的效果不理想,不具有普适性.Zhang et al[20]提出基于成本的特征选择多目标粒子群优化算法,采用概率的编码技术和有效的混合算子,将拥挤距离、外部档案和Pareto支配关系应用于粒子群算法,明显缩减了特征子集的搜索空间,有效解决了约简变量过多导致的局部最优问题,但没有考虑最优全局解集的情况.孙哲人等[21]提出一个基于多样性分类和距离回归的进化算法,把种群中的所有解作为训练样本,并根据是否为最小相关解,把训练样本分类为正负样本,使模型学习到训练样本中含有的分类信息.此外,它采用Kriging作为局部回归代理模型,其选择种群中距离当前候选解最近的解作为训练样本,拟合训练样本与理想点的距离,然后通过K⁃means方法把候选解划分为μ个簇,从每个簇中选择一个用于真实评估的候选解.该方法在低维度特征空间取得了不错的效果,但随着目标数量的增加,目标空间呈指数扩大,算法效果不理想.Zhou et al[22]提出一种基于两级粒子协作的多目标优化特征选择策略来进行高维数据的特征选择,考虑了特征数量、分类错误率和距离测量三个目标,将二进制粒子群优化与两级粒子协作策略相结合,有效地减少了特征数量,还组合了随机生成的普通粒子和ReliefF过滤粒子来实现快速收敛.然而,该方法的平均分类精度效果不佳.Rashno et al[23]提出一种新型的多目标粒子群优化特征选择方法,将特征向量解码为粒子并在二维优化空间中进行排名,对粒子进行排序,将优化空间分成主导粒子带与非主导粒子带,通过数学与实验详细解析了优化空间中均匀与非均匀分布对粒子模型的影响,将粒子秩与特征秩运用到迭代过程来更新粒子的速度与位置,找到多目标优化空间中最接近原点的最佳粒子.然而,该方法没有解决优势粒子与非优势粒子之间粒子距离的优化组合,所以得到的最佳粒子不一定是Pareto解集中的最适解.Wang et al[24]提出基于样本还原策略和进化算法的多目标特征选择框架,该框架主要包含K⁃means聚类的差分选择方法和样品利用策略,还在框架中嵌入了粒子更新模型的改进人工蜂群算法.该方法虽然降低了计算成本,减少了进化过程中使用的样本量,缩短了进化迭代的时间,但其在高维特征空间的应用效果不佳. ...
... Zhang et al[19]提出自学习二差分进化算法,用基于概率差的二元变异算子引导个体快速定位潜在的最优区域,还提出一种新型净化搜索算子来提高位于最优区域精英个体的自学习能力.具有拥挤距离的高效非支配排序算子可以降低差分进化中算子选择的计算复杂度,大幅度缩短搜索时间,提升分类表现,但在高维小样本数据集中的效果不理想,不具有普适性.Zhang et al[20]提出基于成本的特征选择多目标粒子群优化算法,采用概率的编码技术和有效的混合算子,将拥挤距离、外部档案和Pareto支配关系应用于粒子群算法,明显缩减了特征子集的搜索空间,有效解决了约简变量过多导致的局部最优问题,但没有考虑最优全局解集的情况.孙哲人等[21]提出一个基于多样性分类和距离回归的进化算法,把种群中的所有解作为训练样本,并根据是否为最小相关解,把训练样本分类为正负样本,使模型学习到训练样本中含有的分类信息.此外,它采用Kriging作为局部回归代理模型,其选择种群中距离当前候选解最近的解作为训练样本,拟合训练样本与理想点的距离,然后通过K⁃means方法把候选解划分为μ个簇,从每个簇中选择一个用于真实评估的候选解.该方法在低维度特征空间取得了不错的效果,但随着目标数量的增加,目标空间呈指数扩大,算法效果不理想.Zhou et al[22]提出一种基于两级粒子协作的多目标优化特征选择策略来进行高维数据的特征选择,考虑了特征数量、分类错误率和距离测量三个目标,将二进制粒子群优化与两级粒子协作策略相结合,有效地减少了特征数量,还组合了随机生成的普通粒子和ReliefF过滤粒子来实现快速收敛.然而,该方法的平均分类精度效果不佳.Rashno et al[23]提出一种新型的多目标粒子群优化特征选择方法,将特征向量解码为粒子并在二维优化空间中进行排名,对粒子进行排序,将优化空间分成主导粒子带与非主导粒子带,通过数学与实验详细解析了优化空间中均匀与非均匀分布对粒子模型的影响,将粒子秩与特征秩运用到迭代过程来更新粒子的速度与位置,找到多目标优化空间中最接近原点的最佳粒子.然而,该方法没有解决优势粒子与非优势粒子之间粒子距离的优化组合,所以得到的最佳粒子不一定是Pareto解集中的最适解.Wang et al[24]提出基于样本还原策略和进化算法的多目标特征选择框架,该框架主要包含K⁃means聚类的差分选择方法和样品利用策略,还在框架中嵌入了粒子更新模型的改进人工蜂群算法.该方法虽然降低了计算成本,减少了进化过程中使用的样本量,缩短了进化迭代的时间,但其在高维特征空间的应用效果不佳. ...
Diversity classification and distance regression assisted evolutionary algorithm
2
2022
... Zhang et al[19]提出自学习二差分进化算法,用基于概率差的二元变异算子引导个体快速定位潜在的最优区域,还提出一种新型净化搜索算子来提高位于最优区域精英个体的自学习能力.具有拥挤距离的高效非支配排序算子可以降低差分进化中算子选择的计算复杂度,大幅度缩短搜索时间,提升分类表现,但在高维小样本数据集中的效果不理想,不具有普适性.Zhang et al[20]提出基于成本的特征选择多目标粒子群优化算法,采用概率的编码技术和有效的混合算子,将拥挤距离、外部档案和Pareto支配关系应用于粒子群算法,明显缩减了特征子集的搜索空间,有效解决了约简变量过多导致的局部最优问题,但没有考虑最优全局解集的情况.孙哲人等[21]提出一个基于多样性分类和距离回归的进化算法,把种群中的所有解作为训练样本,并根据是否为最小相关解,把训练样本分类为正负样本,使模型学习到训练样本中含有的分类信息.此外,它采用Kriging作为局部回归代理模型,其选择种群中距离当前候选解最近的解作为训练样本,拟合训练样本与理想点的距离,然后通过K⁃means方法把候选解划分为μ个簇,从每个簇中选择一个用于真实评估的候选解.该方法在低维度特征空间取得了不错的效果,但随着目标数量的增加,目标空间呈指数扩大,算法效果不理想.Zhou et al[22]提出一种基于两级粒子协作的多目标优化特征选择策略来进行高维数据的特征选择,考虑了特征数量、分类错误率和距离测量三个目标,将二进制粒子群优化与两级粒子协作策略相结合,有效地减少了特征数量,还组合了随机生成的普通粒子和ReliefF过滤粒子来实现快速收敛.然而,该方法的平均分类精度效果不佳.Rashno et al[23]提出一种新型的多目标粒子群优化特征选择方法,将特征向量解码为粒子并在二维优化空间中进行排名,对粒子进行排序,将优化空间分成主导粒子带与非主导粒子带,通过数学与实验详细解析了优化空间中均匀与非均匀分布对粒子模型的影响,将粒子秩与特征秩运用到迭代过程来更新粒子的速度与位置,找到多目标优化空间中最接近原点的最佳粒子.然而,该方法没有解决优势粒子与非优势粒子之间粒子距离的优化组合,所以得到的最佳粒子不一定是Pareto解集中的最适解.Wang et al[24]提出基于样本还原策略和进化算法的多目标特征选择框架,该框架主要包含K⁃means聚类的差分选择方法和样品利用策略,还在框架中嵌入了粒子更新模型的改进人工蜂群算法.该方法虽然降低了计算成本,减少了进化过程中使用的样本量,缩短了进化迭代的时间,但其在高维特征空间的应用效果不佳. ...
Many?objective optimization of feature selection based on two?level particle cooperation
1
2020
... Zhang et al[19]提出自学习二差分进化算法,用基于概率差的二元变异算子引导个体快速定位潜在的最优区域,还提出一种新型净化搜索算子来提高位于最优区域精英个体的自学习能力.具有拥挤距离的高效非支配排序算子可以降低差分进化中算子选择的计算复杂度,大幅度缩短搜索时间,提升分类表现,但在高维小样本数据集中的效果不理想,不具有普适性.Zhang et al[20]提出基于成本的特征选择多目标粒子群优化算法,采用概率的编码技术和有效的混合算子,将拥挤距离、外部档案和Pareto支配关系应用于粒子群算法,明显缩减了特征子集的搜索空间,有效解决了约简变量过多导致的局部最优问题,但没有考虑最优全局解集的情况.孙哲人等[21]提出一个基于多样性分类和距离回归的进化算法,把种群中的所有解作为训练样本,并根据是否为最小相关解,把训练样本分类为正负样本,使模型学习到训练样本中含有的分类信息.此外,它采用Kriging作为局部回归代理模型,其选择种群中距离当前候选解最近的解作为训练样本,拟合训练样本与理想点的距离,然后通过K⁃means方法把候选解划分为μ个簇,从每个簇中选择一个用于真实评估的候选解.该方法在低维度特征空间取得了不错的效果,但随着目标数量的增加,目标空间呈指数扩大,算法效果不理想.Zhou et al[22]提出一种基于两级粒子协作的多目标优化特征选择策略来进行高维数据的特征选择,考虑了特征数量、分类错误率和距离测量三个目标,将二进制粒子群优化与两级粒子协作策略相结合,有效地减少了特征数量,还组合了随机生成的普通粒子和ReliefF过滤粒子来实现快速收敛.然而,该方法的平均分类精度效果不佳.Rashno et al[23]提出一种新型的多目标粒子群优化特征选择方法,将特征向量解码为粒子并在二维优化空间中进行排名,对粒子进行排序,将优化空间分成主导粒子带与非主导粒子带,通过数学与实验详细解析了优化空间中均匀与非均匀分布对粒子模型的影响,将粒子秩与特征秩运用到迭代过程来更新粒子的速度与位置,找到多目标优化空间中最接近原点的最佳粒子.然而,该方法没有解决优势粒子与非优势粒子之间粒子距离的优化组合,所以得到的最佳粒子不一定是Pareto解集中的最适解.Wang et al[24]提出基于样本还原策略和进化算法的多目标特征选择框架,该框架主要包含K⁃means聚类的差分选择方法和样品利用策略,还在框架中嵌入了粒子更新模型的改进人工蜂群算法.该方法虽然降低了计算成本,减少了进化过程中使用的样本量,缩短了进化迭代的时间,但其在高维特征空间的应用效果不佳. ...
... Zhang et al[19]提出自学习二差分进化算法,用基于概率差的二元变异算子引导个体快速定位潜在的最优区域,还提出一种新型净化搜索算子来提高位于最优区域精英个体的自学习能力.具有拥挤距离的高效非支配排序算子可以降低差分进化中算子选择的计算复杂度,大幅度缩短搜索时间,提升分类表现,但在高维小样本数据集中的效果不理想,不具有普适性.Zhang et al[20]提出基于成本的特征选择多目标粒子群优化算法,采用概率的编码技术和有效的混合算子,将拥挤距离、外部档案和Pareto支配关系应用于粒子群算法,明显缩减了特征子集的搜索空间,有效解决了约简变量过多导致的局部最优问题,但没有考虑最优全局解集的情况.孙哲人等[21]提出一个基于多样性分类和距离回归的进化算法,把种群中的所有解作为训练样本,并根据是否为最小相关解,把训练样本分类为正负样本,使模型学习到训练样本中含有的分类信息.此外,它采用Kriging作为局部回归代理模型,其选择种群中距离当前候选解最近的解作为训练样本,拟合训练样本与理想点的距离,然后通过K⁃means方法把候选解划分为μ个簇,从每个簇中选择一个用于真实评估的候选解.该方法在低维度特征空间取得了不错的效果,但随着目标数量的增加,目标空间呈指数扩大,算法效果不理想.Zhou et al[22]提出一种基于两级粒子协作的多目标优化特征选择策略来进行高维数据的特征选择,考虑了特征数量、分类错误率和距离测量三个目标,将二进制粒子群优化与两级粒子协作策略相结合,有效地减少了特征数量,还组合了随机生成的普通粒子和ReliefF过滤粒子来实现快速收敛.然而,该方法的平均分类精度效果不佳.Rashno et al[23]提出一种新型的多目标粒子群优化特征选择方法,将特征向量解码为粒子并在二维优化空间中进行排名,对粒子进行排序,将优化空间分成主导粒子带与非主导粒子带,通过数学与实验详细解析了优化空间中均匀与非均匀分布对粒子模型的影响,将粒子秩与特征秩运用到迭代过程来更新粒子的速度与位置,找到多目标优化空间中最接近原点的最佳粒子.然而,该方法没有解决优势粒子与非优势粒子之间粒子距离的优化组合,所以得到的最佳粒子不一定是Pareto解集中的最适解.Wang et al[24]提出基于样本还原策略和进化算法的多目标特征选择框架,该框架主要包含K⁃means聚类的差分选择方法和样品利用策略,还在框架中嵌入了粒子更新模型的改进人工蜂群算法.该方法虽然降低了计算成本,减少了进化过程中使用的样本量,缩短了进化迭代的时间,但其在高维特征空间的应用效果不佳. ...
Multi?objective feature selection based on artificial bee colony:An acceleration approach with variable sample size
1
... Zhang et al[19]提出自学习二差分进化算法,用基于概率差的二元变异算子引导个体快速定位潜在的最优区域,还提出一种新型净化搜索算子来提高位于最优区域精英个体的自学习能力.具有拥挤距离的高效非支配排序算子可以降低差分进化中算子选择的计算复杂度,大幅度缩短搜索时间,提升分类表现,但在高维小样本数据集中的效果不理想,不具有普适性.Zhang et al[20]提出基于成本的特征选择多目标粒子群优化算法,采用概率的编码技术和有效的混合算子,将拥挤距离、外部档案和Pareto支配关系应用于粒子群算法,明显缩减了特征子集的搜索空间,有效解决了约简变量过多导致的局部最优问题,但没有考虑最优全局解集的情况.孙哲人等[21]提出一个基于多样性分类和距离回归的进化算法,把种群中的所有解作为训练样本,并根据是否为最小相关解,把训练样本分类为正负样本,使模型学习到训练样本中含有的分类信息.此外,它采用Kriging作为局部回归代理模型,其选择种群中距离当前候选解最近的解作为训练样本,拟合训练样本与理想点的距离,然后通过K⁃means方法把候选解划分为μ个簇,从每个簇中选择一个用于真实评估的候选解.该方法在低维度特征空间取得了不错的效果,但随着目标数量的增加,目标空间呈指数扩大,算法效果不理想.Zhou et al[22]提出一种基于两级粒子协作的多目标优化特征选择策略来进行高维数据的特征选择,考虑了特征数量、分类错误率和距离测量三个目标,将二进制粒子群优化与两级粒子协作策略相结合,有效地减少了特征数量,还组合了随机生成的普通粒子和ReliefF过滤粒子来实现快速收敛.然而,该方法的平均分类精度效果不佳.Rashno et al[23]提出一种新型的多目标粒子群优化特征选择方法,将特征向量解码为粒子并在二维优化空间中进行排名,对粒子进行排序,将优化空间分成主导粒子带与非主导粒子带,通过数学与实验详细解析了优化空间中均匀与非均匀分布对粒子模型的影响,将粒子秩与特征秩运用到迭代过程来更新粒子的速度与位置,找到多目标优化空间中最接近原点的最佳粒子.然而,该方法没有解决优势粒子与非优势粒子之间粒子距离的优化组合,所以得到的最佳粒子不一定是Pareto解集中的最适解.Wang et al[24]提出基于样本还原策略和进化算法的多目标特征选择框架,该框架主要包含K⁃means聚类的差分选择方法和样品利用策略,还在框架中嵌入了粒子更新模型的改进人工蜂群算法.该方法虽然降低了计算成本,减少了进化过程中使用的样本量,缩短了进化迭代的时间,但其在高维特征空间的应用效果不佳. ...
An effective multi?objective artificial hummingbird algorithm with dynamic elimination?based crowding distance for solving engineering design problems
Multi?population coevolutionary dynamic multi?objective particle swarm optimization algorithm for power control based on improved crowding distance archive management in CRNs




{kind=link}
{kind=link}
{kind=link}
{kind=link}