A dynamic incremental attribute reduction method based on consisitent block partitioning
Xu Yang1, Wang Lei,1,2, Zhang Yizong1, Wang Chengbiao1
1.School of Information Engineering,Nanchang Institute of Engineering,Nanchang,330099,China
2.Jiangxi Province Key Laboratory of Water Information Cooperative Sensing and Intelligent Processing,School of Information Engineering,Nanchang Institute of Engineering,Nanchang,330099,China
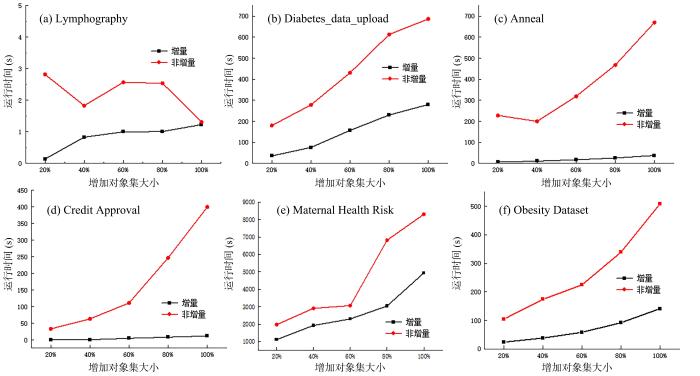
Attribute reduction is essential for preprocessing in research fields such as data mining and machine learning since its efficiency has an immediate impact on the performances of the above⁃mentioned fields. In this paper,an incremental attribute reduction approach with discrimination as heuristic information is proposed against the problem of the non⁃incremental attribute reduction method failing to efficiently update the attribute reduction when the object set is changed in the consistent block rough set model. To begin with,the concept of compatible block is introduced to divide the domain of discourse using compatible blocks. Then,the differentiation degree of incomplete information system is defined before the analysis on the update mechanism of discrimination when the object set is changed. Moreover,an incremental attribute reduction algorithm is built with the discrimination as heuristic information. At last,an incremental reduction updating experiment is conducted on six UCI data sets selected. The time consumed by the incremental method is 50 % shorter than that by the non⁃incremental updating method on the premise of not affecting the accuracy of attribute reduction,according to the experimental results. To sum up,the proposed incremental reduction algorithm is more feasible and efficient than the non⁃incremental reduction algorithm.
Xu Yang, Wang Lei, Zhang Yizong, Wang Chengbiao. A dynamic incremental attribute reduction method based on consisitent block partitioning. Journal of nanjing University[J], 2023, 59(4): 680-689 doi:10.13232/j.cnki.jnju.2023.04.014
经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度.
在实际应用中数据规模在不断变化,数据也会随着时间的变化而发生动态变化,因此属性约简的结果也会随之变化.非增量式方法在计算过程中需要从头开始计算,会消耗大量的时间.与非增量式方法相比,增量式方法被认为是处理动态数据的有效技术,因为它们可以在先前计算结果的基础上进行计算.鉴于不完备信息系统中数据的动态变化情况,许多学者也进行了系统深入的研究.如刘斌等[15]在对象集发生变化的条件下,设计了一种相容块模型划分条件下近似集增量更新的方法.Wang[16]在不完备信息表中针对属性集动态递增的情况提出基于条件熵的矩阵和非矩阵形式的两种增量机制,并由此给出属性集动态变化时的属性约简方法.Xie and Qin[17]分析不完备信息系统下容差类的更新机制并由此提出属性值变化条件下的增量式属性约简方法.上述研究推动了不完备决策信息系统领域的蓬勃发展,但在对象集发生变化时,相容块模型划分情况下的增量式属性约简方面的研究相对较少.
Application of the BORUTA algorithm to input data selection for a model based on rough set theory (RST) to prediction energy consumption for building heating
Application of the BORUTA algorithm to input data selection for a model based on rough set theory (RST) to prediction energy consumption for building heating
Rough set approach to incomplete information systems
2
1998
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
... 定义3[7] ...
Maximal consistent block technique for rule acquisition in incomplete information systems
1
2003
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
不完备系统中基于特征相容块的粗糙集
1
2012
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
Characteristic consistent blocks based rough set in incomplete system
1
2012
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
变精度极大相容块粗糙集模型及其属性约简
1
2020
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
Maximum consistent block based variable precision rough set model and attribute reduction
1
2020
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
基于数据相容填补的极大相容块构造算法
1
2012
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
Algorithm of constructing maximal consistent block based on consistent data reinforcement
1
2012
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
基于极大相容块的不完备信息处理新方法及其应用
1
2022
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
A new method of incomplete information processing based on maximal consistent block and its application
1
2022
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
基于极大相容块的不完备模糊目标信息系统的近似约简
1
2015
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
The approximate reduction in incomplete and fuzzy objective information systems based on maximal tolerance classes
1
2015
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
A tolerance classes partition?based re?definition of the rough approximations for incomplete information system
2
2022
... 经典粗糙集是在数据完整且没有缺失值的前提下,通过不可分辨关系对论域进行划分,对数据的要求严格.而在现实世界中,数据的收集、存储、传输等过程存在各种原因会导致数据的丢失,因此不完备信息系统中的粗糙集模型得到了广泛应用.各种基于不完备信息系统的研究任务也在持续开展.Kryszkiewicz[7]提出基于容差关系的粗糙集模型并将其运用于属性约简.Leung and Li[8]提出基于极大相容块的属性约简方法.杨习贝等[9]将极大相容块引入特征类,提出特征相容块的概念并且讨论了特征相容块的基本性质.孙妍等[10]将变精度粗糙集模型与极大相容块相结合,提出一种保持决策类上下近似不变的属性约简方法.周石泉和蒙祖强[11]分析极大相容块在不完备信息系统中的特点,提出一种通过数据填补的方法来获取极大相容块.王敬前和张小红[12]提出一种基于矩阵求取极大相容块与属性约简的方法.胡宝清和温彪[13]在不完备模糊目标信息系统中引入极大相容块的概念,定义上、下近似集并且提出近似一致集和近似约简的概念以及近似约简的方法.以上都是通过容差关系构成论域的覆盖范围形成极大相容块.2021年Wang et al[14]提出基于相容块的粗糙集模型,在不完备信息系统中运用对象的相容块构造论域的划分并由此给出概念上、下近似集的定义,该定义使上近似集中的元素个数减少,下近似集中的元素个数增加,与经典粗糙集模型相比,提高了其概念近似精度. ...
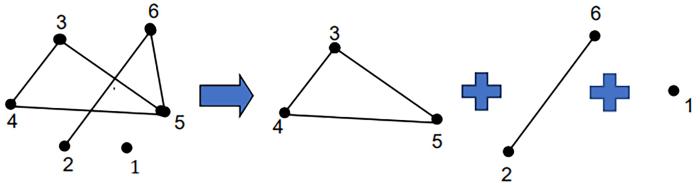
... 图1为极大相容块在论域上的覆盖.根据Wang et al[14]将其划分为 ...
对象集变化时相容块的近似集增量更新方法
1
2023
... 在实际应用中数据规模在不断变化,数据也会随着时间的变化而发生动态变化,因此属性约简的结果也会随之变化.非增量式方法在计算过程中需要从头开始计算,会消耗大量的时间.与非增量式方法相比,增量式方法被认为是处理动态数据的有效技术,因为它们可以在先前计算结果的基础上进行计算.鉴于不完备信息系统中数据的动态变化情况,许多学者也进行了系统深入的研究.如刘斌等[15]在对象集发生变化的条件下,设计了一种相容块模型划分条件下近似集增量更新的方法.Wang[16]在不完备信息表中针对属性集动态递增的情况提出基于条件熵的矩阵和非矩阵形式的两种增量机制,并由此给出属性集动态变化时的属性约简方法.Xie and Qin[17]分析不完备信息系统下容差类的更新机制并由此提出属性值变化条件下的增量式属性约简方法.上述研究推动了不完备决策信息系统领域的蓬勃发展,但在对象集发生变化时,相容块模型划分情况下的增量式属性约简方面的研究相对较少. ...
An incremental method for updating approximations of consistent blocks while the universe evolves over time
1
2023
... 在实际应用中数据规模在不断变化,数据也会随着时间的变化而发生动态变化,因此属性约简的结果也会随之变化.非增量式方法在计算过程中需要从头开始计算,会消耗大量的时间.与非增量式方法相比,增量式方法被认为是处理动态数据的有效技术,因为它们可以在先前计算结果的基础上进行计算.鉴于不完备信息系统中数据的动态变化情况,许多学者也进行了系统深入的研究.如刘斌等[15]在对象集发生变化的条件下,设计了一种相容块模型划分条件下近似集增量更新的方法.Wang[16]在不完备信息表中针对属性集动态递增的情况提出基于条件熵的矩阵和非矩阵形式的两种增量机制,并由此给出属性集动态变化时的属性约简方法.Xie and Qin[17]分析不完备信息系统下容差类的更新机制并由此提出属性值变化条件下的增量式属性约简方法.上述研究推动了不完备决策信息系统领域的蓬勃发展,但在对象集发生变化时,相容块模型划分情况下的增量式属性约简方面的研究相对较少. ...
Valid incremental attribute reduction algorithm based on attribute generalization for an incomplete information system
1
2019
... 在实际应用中数据规模在不断变化,数据也会随着时间的变化而发生动态变化,因此属性约简的结果也会随之变化.非增量式方法在计算过程中需要从头开始计算,会消耗大量的时间.与非增量式方法相比,增量式方法被认为是处理动态数据的有效技术,因为它们可以在先前计算结果的基础上进行计算.鉴于不完备信息系统中数据的动态变化情况,许多学者也进行了系统深入的研究.如刘斌等[15]在对象集发生变化的条件下,设计了一种相容块模型划分条件下近似集增量更新的方法.Wang[16]在不完备信息表中针对属性集动态递增的情况提出基于条件熵的矩阵和非矩阵形式的两种增量机制,并由此给出属性集动态变化时的属性约简方法.Xie and Qin[17]分析不完备信息系统下容差类的更新机制并由此提出属性值变化条件下的增量式属性约简方法.上述研究推动了不完备决策信息系统领域的蓬勃发展,但在对象集发生变化时,相容块模型划分情况下的增量式属性约简方面的研究相对较少. ...
A novel incremental attribute reduction approach for dynamic incomplete decision systems
1
2018
... 在实际应用中数据规模在不断变化,数据也会随着时间的变化而发生动态变化,因此属性约简的结果也会随之变化.非增量式方法在计算过程中需要从头开始计算,会消耗大量的时间.与非增量式方法相比,增量式方法被认为是处理动态数据的有效技术,因为它们可以在先前计算结果的基础上进行计算.鉴于不完备信息系统中数据的动态变化情况,许多学者也进行了系统深入的研究.如刘斌等[15]在对象集发生变化的条件下,设计了一种相容块模型划分条件下近似集增量更新的方法.Wang[16]在不完备信息表中针对属性集动态递增的情况提出基于条件熵的矩阵和非矩阵形式的两种增量机制,并由此给出属性集动态变化时的属性约简方法.Xie and Qin[17]分析不完备信息系统下容差类的更新机制并由此提出属性值变化条件下的增量式属性约简方法.上述研究推动了不完备决策信息系统领域的蓬勃发展,但在对象集发生变化时,相容块模型划分情况下的增量式属性约简方面的研究相对较少. ...
基于属性分辨度的最大相容块规则提取算法
0
2013
Algorithm for rules acquisition from maximal consistent blocks based on attribute discernibility






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}