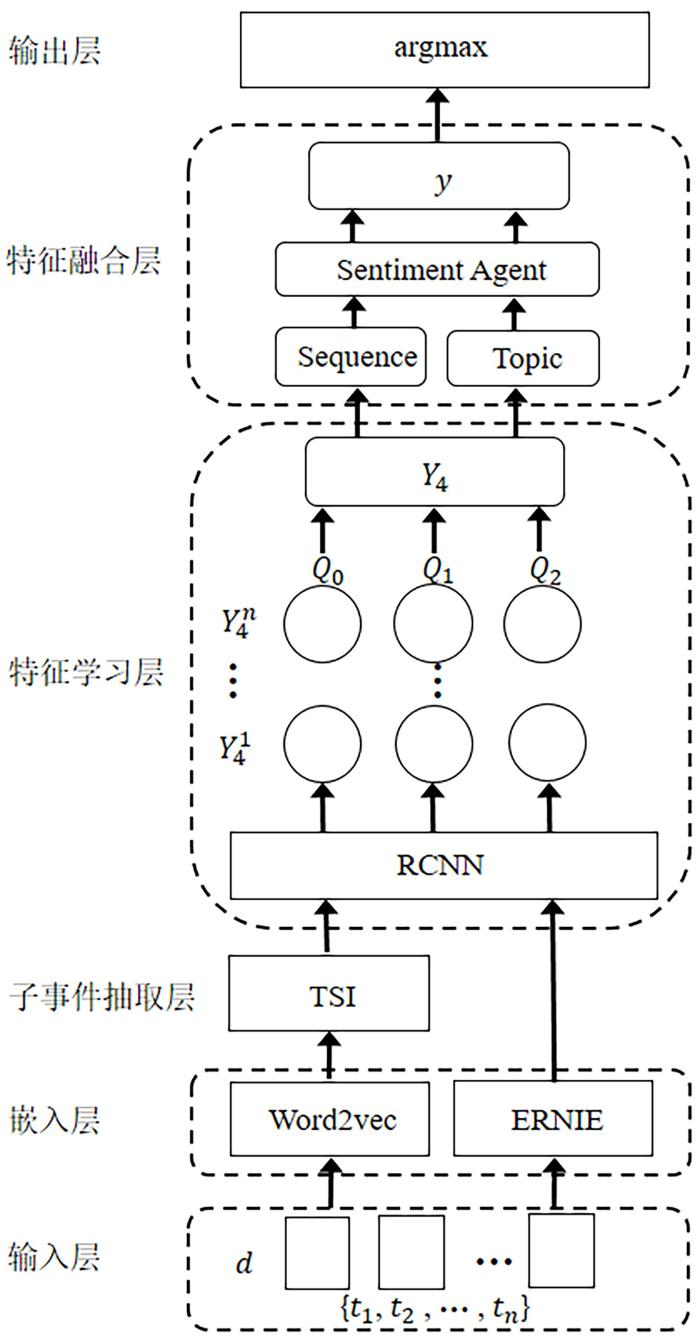
传统的情感分析方法主要针对句子、微博等形式的短文本,而对话长文本具有篇幅长、对话双方情感不同且情感易随对话发生变化等特点,使对话长文本中用户多重情感集成困难、情感分析任务精度低.为此,提出子事件交互模型TSI (Topic Subevents Interaction)、预训练模型ERNIE (Enhanced Language Representation with Informative Entities)和循环卷积神经网络(Recurrent Convolutional Neural Networks,RCNN)相结合的对话长文本情感分析模型(TSI with ERNIE⁃RCNN,TER).该模型通过动态滑动窗口抽取子事件,保留文本关键特征,降低文本冗余度,基于抽取的子事件分析对话双方的情感来识别情感主体,并集成各子事件的情感特征来解决对话双方情感不一致的问题.在真实数据上的实验结果表明,TER的精确率、召回率与F1均优于现有模型.
关键词:对话长文本
;
情感分析
;
子事件抽取
;
预训练模型
;
循环卷积神经网络
Abstract
Previous studies for sentiment analysis mainly focus on short texts such as sentences and microblogs text styles. Due to the long redundant text and the different and changeable sentiment of users,the integration of multiple sentiment of users is difficult and the precision of sentiment analysis task is low in the long dialogue text. For overcoming such problems,a long dialogue text sentiment analysis model TER (Topic Sub⁃Events Interaction with ERNIE⁃RCNN) is proposed. Firstly,TSI (Topic Subevents Interaction) is used to segment long dialogue text by the dynamic sliding window in order to retain the key features of the text and reduce the text redundancy. Secondly,ERNIE⁃RCNN is used to analyze the sentimental polarity of users in the subevents. Finally,our model identifies the sentiment agent to integrate the sentiment of each subevent and solve the problem of sentimental inconsistency. Experimental results show that TER outperforms baseline models in terms of precision,recall and F1⁃score.
Keywords:long dialogue text
;
sentiment analysis
;
subevent extraction
;
pre⁃trained model
;
recurrent convolutional neural network
Yang Jinghu, Duan Liang, Yue Kun, Li Zhongbin. Sentimenta analysis based on subevents for long dialogue texts. Journal of nanjing University[J], 2023, 59(3): 483-493 doi:10.13232/j.cnki.jnju.2023.03.011
预训练模型是在大规模无监督语料上训练的,具有强大的语义表示能力.百度提出ERNIE (Enhanced Language Representation with Informative Entities)[5],对BERT[6]进行改进,将句子中的短语、实体等语义单元掩码,重点学习对话类数据,将ERNIE作为嵌入模型能更好地对对话文本建模.循环卷积神经网络(Recurrent Convolutional Neural Networks,RCNN)[7]能更好地获取文本上下文特征,兼有CNN无偏模型的优点,因此,本文提出ERNIE⁃RCNN模型学习子事件的情感特征.针对对话双方具有的多重情感使子事件情感集成困难的问题,本文提出一种识别情感主体的方法来确定整个对话长文本的情感倾向.
在真实的移动运营商的通讯业务数据上的实验结果表明,本文提出的TER (Topic Sub⁃events Interaction with ERNIE⁃RCNN)的精确率、召回率与F1均优于现有模型.值得注意的是,虽然TER是基于移动通讯应用场景提出的,但微信、淘宝、论坛等媒体都有类似的对话长文本数据,因而有广阔的应用前景.
1 相关工作
1.1 长文本情感分析
Pappagari et al[8]将长文本分割后输入改进的BERT模型,获取文本特征进行分类.Xu et al[9]提出CLSTM模型来获取长文本的整体语义信息,通过一种缓存机制存储情感特征.上述方法在长文本情感分类任务上取得了较好的效果,但没有考虑实际场景下长文本的每部分内容在推断文本情感倾向上具有的不同价值,如何在不陷入某些局部无关的文本下获得有效的核心情感是值得注意的问题.Sheng and Yuan[10]设计新的截断方式,将文本标题、关键词等特征进行拼接,使用多个模型联合学习.Cheng et al[11]对每篇文章提取两个主题句,结合标题等文本特征进行加权计算,最后使用投票机制完成情感分类.这些研究虽然注意了长文本的冗余性,但在建模时损失了大量文本特征,依赖带标题的文本,不适合对话长文本的情感分析.
1.2 对话文本情感分析
Hazarika et al[12]考虑对话中用户情绪自我依赖关系及对话者之间的依赖关系,提出交互式对话神经网络模型,建模对话者的情感.Shen et al[13]提出分层匹配神经网络,设计双向注意力机制捕捉对话双方的情感信息并互相预测.Wang et al[14]研究通过增强的双向注意力网络,解决了通过单一问题或答案来推断情感会比较困难的问题.Hu et al[15]建模对话时人的认知与推理思维,提出语境推理网络,通过感知和认知两个阶段学习上下文信息,可以有效地获取文本情感特征.Zhu et al[16]提出以话题驱动且包含知识的Transformer模型,解决对话文本中不同主题下相同文本具有不同情感的问题.上述研究主要基于对话之间的上下文联系进行建模,但随着对话轮次的增加,文本中的噪声、对话中双方情感的不同及变化导致文本最终分类困难的问题未能解决.
1.3 子事件检测与抽取
相关研究主要分三类:命名实体识别结合特征工程、事件话题发现和文摘生成.命名实体识别结合特征工程通过对文本抽取关键词,并根据修辞状态、位置信息等来衡量句子重要性,但这类方法在建模时损失了大量情感特征,抽取的子事件缺少情感表达.周楠等[17]总结事件话题,发现基于文档和词两个角度,算法抽取的子事件存在理解性弱、不确定性高等问题.文摘生成分文本分割算法和文本摘要算法.Memon et al[18]采用文本分割实现文本不同主题的分割,但仍存在文本冗余的问题.采用文本摘要抽取子事件时,主要有生成式和抽取式两种方法,但生成式方法不适合长文本任务[19],抽取式方法无法保证子事件的连贯性与理解性.
BERT:Pre⁃training of deep bidirectional transformers for language understanding
∥Proceedings of 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies. Volume1. Long and Short Papers. Minneapolis,MN,USA:Association for Computational Linguistics,2019:4171-4186.
DialogueCRN:Contextual reasoning networks for emotion recognition in conversations
∥Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Bangkok,Thailand:ACL,2021:7042-7052.
Topic⁃driven and knowledge⁃aware transformer for dialogue emotion detection
∥Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1:Long Papers). Bangkok,Thailand:ACL,2021:1571-1582.
Hierarchical transformers for long document classification
1
2019
... Pappagari et al[8]将长文本分割后输入改进的BERT模型,获取文本特征进行分类.Xu et al[9]提出CLSTM模型来获取长文本的整体语义信息,通过一种缓存机制存储情感特征.上述方法在长文本情感分类任务上取得了较好的效果,但没有考虑实际场景下长文本的每部分内容在推断文本情感倾向上具有的不同价值,如何在不陷入某些局部无关的文本下获得有效的核心情感是值得注意的问题.Sheng and Yuan[10]设计新的截断方式,将文本标题、关键词等特征进行拼接,使用多个模型联合学习.Cheng et al[11]对每篇文章提取两个主题句,结合标题等文本特征进行加权计算,最后使用投票机制完成情感分类.这些研究虽然注意了长文本的冗余性,但在建模时损失了大量文本特征,依赖带标题的文本,不适合对话长文本的情感分析. ...
Cached long short?term memory neural networks for document?level sentiment classification
1
2016
... Pappagari et al[8]将长文本分割后输入改进的BERT模型,获取文本特征进行分类.Xu et al[9]提出CLSTM模型来获取长文本的整体语义信息,通过一种缓存机制存储情感特征.上述方法在长文本情感分类任务上取得了较好的效果,但没有考虑实际场景下长文本的每部分内容在推断文本情感倾向上具有的不同价值,如何在不陷入某些局部无关的文本下获得有效的核心情感是值得注意的问题.Sheng and Yuan[10]设计新的截断方式,将文本标题、关键词等特征进行拼接,使用多个模型联合学习.Cheng et al[11]对每篇文章提取两个主题句,结合标题等文本特征进行加权计算,最后使用投票机制完成情感分类.这些研究虽然注意了长文本的冗余性,但在建模时损失了大量文本特征,依赖带标题的文本,不适合对话长文本的情感分析. ...
An efficient long chinese text sentiment analysis method using BERT?based models with BiGRU
1
2021
... Pappagari et al[8]将长文本分割后输入改进的BERT模型,获取文本特征进行分类.Xu et al[9]提出CLSTM模型来获取长文本的整体语义信息,通过一种缓存机制存储情感特征.上述方法在长文本情感分类任务上取得了较好的效果,但没有考虑实际场景下长文本的每部分内容在推断文本情感倾向上具有的不同价值,如何在不陷入某些局部无关的文本下获得有效的核心情感是值得注意的问题.Sheng and Yuan[10]设计新的截断方式,将文本标题、关键词等特征进行拼接,使用多个模型联合学习.Cheng et al[11]对每篇文章提取两个主题句,结合标题等文本特征进行加权计算,最后使用投票机制完成情感分类.这些研究虽然注意了长文本的冗余性,但在建模时损失了大量文本特征,依赖带标题的文本,不适合对话长文本的情感分析. ...
Chinese long text sentiment analysis based on the combination of title and topic sentences
1
2020
... Pappagari et al[8]将长文本分割后输入改进的BERT模型,获取文本特征进行分类.Xu et al[9]提出CLSTM模型来获取长文本的整体语义信息,通过一种缓存机制存储情感特征.上述方法在长文本情感分类任务上取得了较好的效果,但没有考虑实际场景下长文本的每部分内容在推断文本情感倾向上具有的不同价值,如何在不陷入某些局部无关的文本下获得有效的核心情感是值得注意的问题.Sheng and Yuan[10]设计新的截断方式,将文本标题、关键词等特征进行拼接,使用多个模型联合学习.Cheng et al[11]对每篇文章提取两个主题句,结合标题等文本特征进行加权计算,最后使用投票机制完成情感分类.这些研究虽然注意了长文本的冗余性,但在建模时损失了大量文本特征,依赖带标题的文本,不适合对话长文本的情感分析. ...
ICON:Interactive conversational memory network for multimodal emotion detection
1
2018
... Hazarika et al[12]考虑对话中用户情绪自我依赖关系及对话者之间的依赖关系,提出交互式对话神经网络模型,建模对话者的情感.Shen et al[13]提出分层匹配神经网络,设计双向注意力机制捕捉对话双方的情感信息并互相预测.Wang et al[14]研究通过增强的双向注意力网络,解决了通过单一问题或答案来推断情感会比较困难的问题.Hu et al[15]建模对话时人的认知与推理思维,提出语境推理网络,通过感知和认知两个阶段学习上下文信息,可以有效地获取文本情感特征.Zhu et al[16]提出以话题驱动且包含知识的Transformer模型,解决对话文本中不同主题下相同文本具有不同情感的问题.上述研究主要基于对话之间的上下文联系进行建模,但随着对话轮次的增加,文本中的噪声、对话中双方情感的不同及变化导致文本最终分类困难的问题未能解决. ...
Sentiment classification towards question?answering with hierarchical matching network
1
2018
... Hazarika et al[12]考虑对话中用户情绪自我依赖关系及对话者之间的依赖关系,提出交互式对话神经网络模型,建模对话者的情感.Shen et al[13]提出分层匹配神经网络,设计双向注意力机制捕捉对话双方的情感信息并互相预测.Wang et al[14]研究通过增强的双向注意力网络,解决了通过单一问题或答案来推断情感会比较困难的问题.Hu et al[15]建模对话时人的认知与推理思维,提出语境推理网络,通过感知和认知两个阶段学习上下文信息,可以有效地获取文本情感特征.Zhu et al[16]提出以话题驱动且包含知识的Transformer模型,解决对话文本中不同主题下相同文本具有不同情感的问题.上述研究主要基于对话之间的上下文联系进行建模,但随着对话轮次的增加,文本中的噪声、对话中双方情感的不同及变化导致文本最终分类困难的问题未能解决. ...
Aspect sentiment classification towards question?answering with reinforced bidirectional attention network
1
2019
... Hazarika et al[12]考虑对话中用户情绪自我依赖关系及对话者之间的依赖关系,提出交互式对话神经网络模型,建模对话者的情感.Shen et al[13]提出分层匹配神经网络,设计双向注意力机制捕捉对话双方的情感信息并互相预测.Wang et al[14]研究通过增强的双向注意力网络,解决了通过单一问题或答案来推断情感会比较困难的问题.Hu et al[15]建模对话时人的认知与推理思维,提出语境推理网络,通过感知和认知两个阶段学习上下文信息,可以有效地获取文本情感特征.Zhu et al[16]提出以话题驱动且包含知识的Transformer模型,解决对话文本中不同主题下相同文本具有不同情感的问题.上述研究主要基于对话之间的上下文联系进行建模,但随着对话轮次的增加,文本中的噪声、对话中双方情感的不同及变化导致文本最终分类困难的问题未能解决. ...
DialogueCRN:Contextual reasoning networks for emotion recognition in conversations
1
2021
... Hazarika et al[12]考虑对话中用户情绪自我依赖关系及对话者之间的依赖关系,提出交互式对话神经网络模型,建模对话者的情感.Shen et al[13]提出分层匹配神经网络,设计双向注意力机制捕捉对话双方的情感信息并互相预测.Wang et al[14]研究通过增强的双向注意力网络,解决了通过单一问题或答案来推断情感会比较困难的问题.Hu et al[15]建模对话时人的认知与推理思维,提出语境推理网络,通过感知和认知两个阶段学习上下文信息,可以有效地获取文本情感特征.Zhu et al[16]提出以话题驱动且包含知识的Transformer模型,解决对话文本中不同主题下相同文本具有不同情感的问题.上述研究主要基于对话之间的上下文联系进行建模,但随着对话轮次的增加,文本中的噪声、对话中双方情感的不同及变化导致文本最终分类困难的问题未能解决. ...
Topic?driven and knowledge?aware transformer for dialogue emotion detection
2
2021
... Hazarika et al[12]考虑对话中用户情绪自我依赖关系及对话者之间的依赖关系,提出交互式对话神经网络模型,建模对话者的情感.Shen et al[13]提出分层匹配神经网络,设计双向注意力机制捕捉对话双方的情感信息并互相预测.Wang et al[14]研究通过增强的双向注意力网络,解决了通过单一问题或答案来推断情感会比较困难的问题.Hu et al[15]建模对话时人的认知与推理思维,提出语境推理网络,通过感知和认知两个阶段学习上下文信息,可以有效地获取文本情感特征.Zhu et al[16]提出以话题驱动且包含知识的Transformer模型,解决对话文本中不同主题下相同文本具有不同情感的问题.上述研究主要基于对话之间的上下文联系进行建模,但随着对话轮次的增加,文本中的噪声、对话中双方情感的不同及变化导致文本最终分类困难的问题未能解决. ...
... 相关研究主要分三类:命名实体识别结合特征工程、事件话题发现和文摘生成.命名实体识别结合特征工程通过对文本抽取关键词,并根据修辞状态、位置信息等来衡量句子重要性,但这类方法在建模时损失了大量情感特征,抽取的子事件缺少情感表达.周楠等[17]总结事件话题,发现基于文档和词两个角度,算法抽取的子事件存在理解性弱、不确定性高等问题.文摘生成分文本分割算法和文本摘要算法.Memon et al[18]采用文本分割实现文本不同主题的分割,但仍存在文本冗余的问题.采用文本摘要抽取子事件时,主要有生成式和抽取式两种方法,但生成式方法不适合长文本任务[19],抽取式方法无法保证子事件的连贯性与理解性. ...
ET?TAG:A tag generation model for the sub?topics of public opinion events
1
2018
... 相关研究主要分三类:命名实体识别结合特征工程、事件话题发现和文摘生成.命名实体识别结合特征工程通过对文本抽取关键词,并根据修辞状态、位置信息等来衡量句子重要性,但这类方法在建模时损失了大量情感特征,抽取的子事件缺少情感表达.周楠等[17]总结事件话题,发现基于文档和词两个角度,算法抽取的子事件存在理解性弱、不确定性高等问题.文摘生成分文本分割算法和文本摘要算法.Memon et al[18]采用文本分割实现文本不同主题的分割,但仍存在文本冗余的问题.采用文本摘要抽取子事件时,主要有生成式和抽取式两种方法,但生成式方法不适合长文本任务[19],抽取式方法无法保证子事件的连贯性与理解性. ...
An ensemble clustering approach for topic discovery using implicit text segmentation
1
2020
... 相关研究主要分三类:命名实体识别结合特征工程、事件话题发现和文摘生成.命名实体识别结合特征工程通过对文本抽取关键词,并根据修辞状态、位置信息等来衡量句子重要性,但这类方法在建模时损失了大量情感特征,抽取的子事件缺少情感表达.周楠等[17]总结事件话题,发现基于文档和词两个角度,算法抽取的子事件存在理解性弱、不确定性高等问题.文摘生成分文本分割算法和文本摘要算法.Memon et al[18]采用文本分割实现文本不同主题的分割,但仍存在文本冗余的问题.采用文本摘要抽取子事件时,主要有生成式和抽取式两种方法,但生成式方法不适合长文本任务[19],抽取式方法无法保证子事件的连贯性与理解性. ...
自动文本摘要研究综述
1
2021
... 相关研究主要分三类:命名实体识别结合特征工程、事件话题发现和文摘生成.命名实体识别结合特征工程通过对文本抽取关键词,并根据修辞状态、位置信息等来衡量句子重要性,但这类方法在建模时损失了大量情感特征,抽取的子事件缺少情感表达.周楠等[17]总结事件话题,发现基于文档和词两个角度,算法抽取的子事件存在理解性弱、不确定性高等问题.文摘生成分文本分割算法和文本摘要算法.Memon et al[18]采用文本分割实现文本不同主题的分割,但仍存在文本冗余的问题.采用文本摘要抽取子事件时,主要有生成式和抽取式两种方法,但生成式方法不适合长文本任务[19],抽取式方法无法保证子事件的连贯性与理解性. ...
Survey on automatic text summarization
1
2021
... 相关研究主要分三类:命名实体识别结合特征工程、事件话题发现和文摘生成.命名实体识别结合特征工程通过对文本抽取关键词,并根据修辞状态、位置信息等来衡量句子重要性,但这类方法在建模时损失了大量情感特征,抽取的子事件缺少情感表达.周楠等[17]总结事件话题,发现基于文档和词两个角度,算法抽取的子事件存在理解性弱、不确定性高等问题.文摘生成分文本分割算法和文本摘要算法.Memon et al[18]采用文本分割实现文本不同主题的分割,但仍存在文本冗余的问题.采用文本摘要抽取子事件时,主要有生成式和抽取式两种方法,但生成式方法不适合长文本任务[19],抽取式方法无法保证子事件的连贯性与理解性. ...
Convolutional neural networks for sentence classification




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}