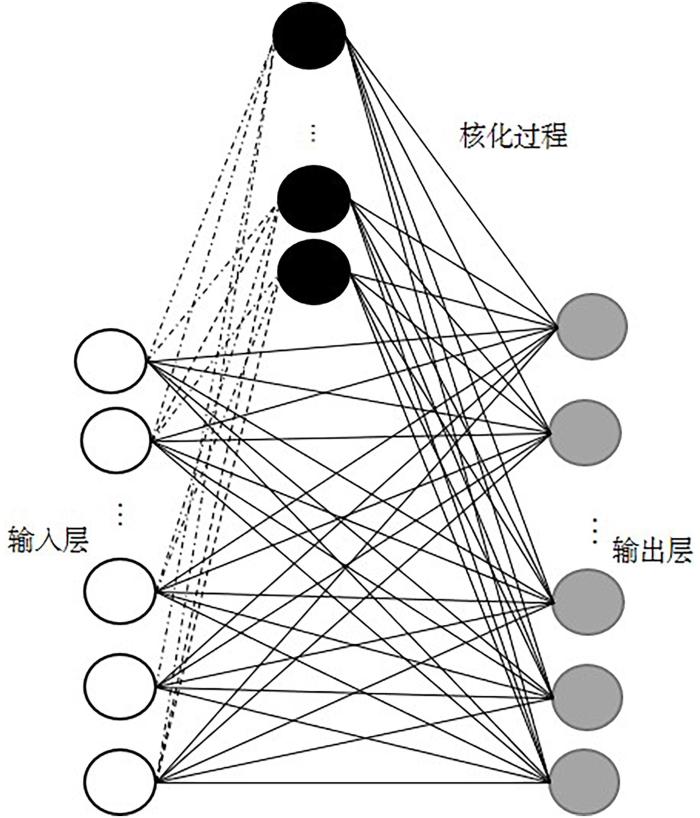
In many practical application scenarios,how to effectively use the multi perspective data obtained from different levels and different angles to obtain the feature data of the same object is a problem worthy of study. Compared with traditional single perspective learning,multi perspective learning shows certain advantages in the ap⁃plication of multi⁃source data. An important problem in multi⁃view learning (MVL) is how to keep the consistency of perspectives while satisfying the complementarity of different perspectives. To solve problems above,a new kernel multi⁃view privileged random vector functional link network (KMPRVFL) is proposed to effectively solve the multi view classification problem. The basic idea is to combine the extra information of redundant perspective with the privileged information of average perspective to supervise the classification task of the current perspective. The multi⁃view data is combined into a comprehensive second view by weighted linear combination after kernel. At the same time,an incremental learning method is designed to effectively reduce the amount of calculation. Experimental results on real datasets show that KMPRVFL is more powerful than traditional multi⁃view learning methods. The average test accuracy of KMPRVFL algorithm is better than that of comparison methods.
Wu Tianyu, Wang Shitong. Kernel Multi⁃view Privileged Random vector functional link net⁃work and its incremental learning method. Journal of nanjing University[J], 2022, 58(2): 275-285 doi:10.13232/j.cnki.jnju.2022.02.011
近年来提出了基于不同策略的多视角分类算法,旨在利用多视角之间的相关信息得到更精确、更高效的分类结果,常用的多视角算法有协同正则化算法和协同训练算法[3].实现协同训练型算法的重要前提是存在充分冗余的视角,协同训练类型算法的目标是最大化不同视角之间一致,代表算法有多训练支持向量机(Multi⁃Training Support Vector Machine,MTSVM)[4].而在协同正则化类算法中,目标函数需要将不同视角之间的分歧最小化,典型的方法有稀疏多视角支持向量机(Sparse Multi View SVMs)[5]、多视角拉普拉斯支持向量机(Multi View Laplacian SVMs)[6].这些基于SVM的方法可以有效地解决多视角的应用场景问题,但也具有一定的局限性,它们忽略了视角之间的互补信息.另一方面,支持向量机求解过程中的局限性,如二次规划求解,对计算机内存需求大,迭代速度慢.
现有的多视角学习算法主要体现了多视角学习的共识原理或互补性原理[1].在多视角学习中,共识和互补性原理在指导模型构建中起着重要作用.共识原理的目的是最大化多个不同视角的一致性,改善算法的泛化误差范围;相反,互补原理强调视角之间共享互补信息,目的是更全面地描述数据,提高算法的鲁棒性.Vapnik提出使用特权信息学习(Learning Using Privileged Information,LUPI)[7]来解决学习模型中的补充知识.LUPI将人类的教学理念融入机器学习的概念,对于一个特定的任务,比如分类,训练数据不仅是目标任务的监督信息,还有一些额外的特权信息(附加信息).从多视角学习的角度来看,不同的特征视角可以相互提供特权信息,实现互补[8].
多视角学习在一定程度上和特定的单视角学习相比具有一定的优势.多视角学习算法通常是在共识或互补原理的指导下建立的,现有的多视角算法可以分三类:协同训练类型算法、协同正则化类型算法和余量一致性类型算法[2].协同训练类型算法旨在最大化不同视角之间的一致性,如鲁棒协同训练支持向量机(Robust Co⁃Training SVM)[11].相比之下,协同正则化类型的算法可以最大程度地减少不同视角之间的分歧[11],例如多视角拉普拉斯支持向量机[6].余量一致性类型的算法利用多视角分类结果的潜在一致性[13],在最大熵判别(Maximue Entropy Dis⁃crimination,MED)[14]的基础上实现.余量一致性类型算法与协同正则化类型算法对多视角的判别或回归函数进行限制不同,它对多视角的余量变量进行建模,使其尽可能接近即每个输出变量和判别函数都大于每个余量变量,例如MVMED(Multi⁃View Maximum Entropy Discrimination),以最小化两个视角边距之间的相对熵实现了边距一致性[15].MED⁃2C (Consensus and Complementarity Based Maximun Entropy Discrimination)以互补子空间将共识和互补的两个原理整合到多视角MED,其泛化性比MVMED更好[16];Tang et al[17]的PSVM⁃2V (Privileged Svm⁃Based Two⁃View Classification Mode)是在SVM⁃2K的基础上结合特权信息并以QP问题迭代求解的算法.
LUPI使用仅在训练期间可用的数据帮助学习模型在测试阶段实现更好的预测结果.特权信息作为附加特征用来改进特定的分类器,Vipnik and Vashist提出了最早的LUPI算法支持向量机(Support Vector Machine+,SVM+)[7].Tang et al[18]将LUPI和多视角结合提出PSVM (Multiview Privileged Support Vector Machines),Li et al[19]提出基于LUPI双支持向量机(Robust Capped L1⁃norm Twin Support Vector Machine with Privileged Information,R⁃CTSVM+)来解决异常值和噪声问题.
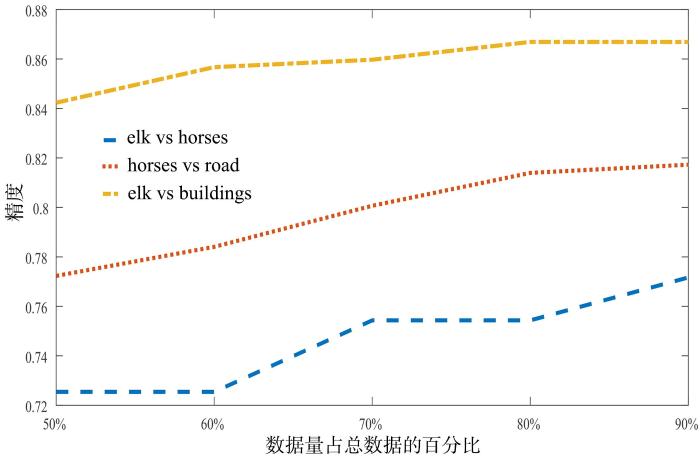
AwA2[24]:包含50种动物的30475张图像,图像数据是2016年从公共资源收集的.每张图像具有六个预先提取的特征表示.在二分类实验中使用(Speeded Up Robust Features,SURF)特征2000⁃D、(Histogram of Oriented Gradient,HOG)特征252⁃D、(Color Histogram features CHF)特征2600⁃D、(Local Self⁃Similarity features LSS)特征2000⁃D.
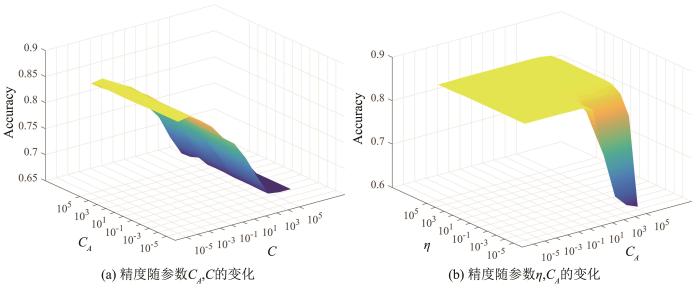
比较KMPRVFL和所有对比测试方法的性能.讨论KMPRVFL的参数敏感性,在隐节点参数固定后,精度随,,变化的选择参数的部分结果,如图3所示.由图可见,在buildings vs elk组实验中,=0.1时在处精度达到极大值,或都较小时模型的鲁棒性最佳.另外,在达到有效的后,的变化幅度不大,时达到极大值.
... 多视角学习在一定程度上和特定的单视角学习相比具有一定的优势.多视角学习算法通常是在共识或互补原理的指导下建立的,现有的多视角算法可以分三类:协同训练类型算法、协同正则化类型算法和余量一致性类型算法[2].协同训练类型算法旨在最大化不同视角之间的一致性,如鲁棒协同训练支持向量机(Robust Co⁃Training SVM)[11].相比之下,协同正则化类型的算法可以最大程度地减少不同视角之间的分歧[11],例如多视角拉普拉斯支持向量机[6].余量一致性类型的算法利用多视角分类结果的潜在一致性[13],在最大熵判别(Maximue Entropy Dis⁃crimination,MED)[14]的基础上实现.余量一致性类型算法与协同正则化类型算法对多视角的判别或回归函数进行限制不同,它对多视角的余量变量进行建模,使其尽可能接近即每个输出变量和判别函数都大于每个余量变量,例如MVMED(Multi⁃View Maximum Entropy Discrimination),以最小化两个视角边距之间的相对熵实现了边距一致性[15].MED⁃2C (Consensus and Complementarity Based Maximun Entropy Discrimination)以互补子空间将共识和互补的两个原理整合到多视角MED,其泛化性比MVMED更好[16];Tang et al[17]的PSVM⁃2V (Privileged Svm⁃Based Two⁃View Classification Mode)是在SVM⁃2K的基础上结合特权信息并以QP问题迭代求解的算法. ...
基于矩阵的AdaBoost多视角学习
1
2018
... 近年来提出了基于不同策略的多视角分类算法,旨在利用多视角之间的相关信息得到更精确、更高效的分类结果,常用的多视角算法有协同正则化算法和协同训练算法[3].实现协同训练型算法的重要前提是存在充分冗余的视角,协同训练类型算法的目标是最大化不同视角之间一致,代表算法有多训练支持向量机(Multi⁃Training Support Vector Machine,MTSVM)[4].而在协同正则化类算法中,目标函数需要将不同视角之间的分歧最小化,典型的方法有稀疏多视角支持向量机(Sparse Multi View SVMs)[5]、多视角拉普拉斯支持向量机(Multi View Laplacian SVMs)[6].这些基于SVM的方法可以有效地解决多视角的应用场景问题,但也具有一定的局限性,它们忽略了视角之间的互补信息.另一方面,支持向量机求解过程中的局限性,如二次规划求解,对计算机内存需求大,迭代速度慢. ...
基于矩阵的AdaBoost多视角学习
1
2018
... 近年来提出了基于不同策略的多视角分类算法,旨在利用多视角之间的相关信息得到更精确、更高效的分类结果,常用的多视角算法有协同正则化算法和协同训练算法[3].实现协同训练型算法的重要前提是存在充分冗余的视角,协同训练类型算法的目标是最大化不同视角之间一致,代表算法有多训练支持向量机(Multi⁃Training Support Vector Machine,MTSVM)[4].而在协同正则化类算法中,目标函数需要将不同视角之间的分歧最小化,典型的方法有稀疏多视角支持向量机(Sparse Multi View SVMs)[5]、多视角拉普拉斯支持向量机(Multi View Laplacian SVMs)[6].这些基于SVM的方法可以有效地解决多视角的应用场景问题,但也具有一定的局限性,它们忽略了视角之间的互补信息.另一方面,支持向量机求解过程中的局限性,如二次规划求解,对计算机内存需求大,迭代速度慢. ...
Multi?training support vector machine for image retrieval
1
2006
... 近年来提出了基于不同策略的多视角分类算法,旨在利用多视角之间的相关信息得到更精确、更高效的分类结果,常用的多视角算法有协同正则化算法和协同训练算法[3].实现协同训练型算法的重要前提是存在充分冗余的视角,协同训练类型算法的目标是最大化不同视角之间一致,代表算法有多训练支持向量机(Multi⁃Training Support Vector Machine,MTSVM)[4].而在协同正则化类算法中,目标函数需要将不同视角之间的分歧最小化,典型的方法有稀疏多视角支持向量机(Sparse Multi View SVMs)[5]、多视角拉普拉斯支持向量机(Multi View Laplacian SVMs)[6].这些基于SVM的方法可以有效地解决多视角的应用场景问题,但也具有一定的局限性,它们忽略了视角之间的互补信息.另一方面,支持向量机求解过程中的局限性,如二次规划求解,对计算机内存需求大,迭代速度慢. ...
Sparse semi?supervised learning using conjugate functions
1
2010
... 近年来提出了基于不同策略的多视角分类算法,旨在利用多视角之间的相关信息得到更精确、更高效的分类结果,常用的多视角算法有协同正则化算法和协同训练算法[3].实现协同训练型算法的重要前提是存在充分冗余的视角,协同训练类型算法的目标是最大化不同视角之间一致,代表算法有多训练支持向量机(Multi⁃Training Support Vector Machine,MTSVM)[4].而在协同正则化类算法中,目标函数需要将不同视角之间的分歧最小化,典型的方法有稀疏多视角支持向量机(Sparse Multi View SVMs)[5]、多视角拉普拉斯支持向量机(Multi View Laplacian SVMs)[6].这些基于SVM的方法可以有效地解决多视角的应用场景问题,但也具有一定的局限性,它们忽略了视角之间的互补信息.另一方面,支持向量机求解过程中的局限性,如二次规划求解,对计算机内存需求大,迭代速度慢. ...
Multi?view Laplacian support vector machines
2
2011
... 近年来提出了基于不同策略的多视角分类算法,旨在利用多视角之间的相关信息得到更精确、更高效的分类结果,常用的多视角算法有协同正则化算法和协同训练算法[3].实现协同训练型算法的重要前提是存在充分冗余的视角,协同训练类型算法的目标是最大化不同视角之间一致,代表算法有多训练支持向量机(Multi⁃Training Support Vector Machine,MTSVM)[4].而在协同正则化类算法中,目标函数需要将不同视角之间的分歧最小化,典型的方法有稀疏多视角支持向量机(Sparse Multi View SVMs)[5]、多视角拉普拉斯支持向量机(Multi View Laplacian SVMs)[6].这些基于SVM的方法可以有效地解决多视角的应用场景问题,但也具有一定的局限性,它们忽略了视角之间的互补信息.另一方面,支持向量机求解过程中的局限性,如二次规划求解,对计算机内存需求大,迭代速度慢. ...
... 多视角学习在一定程度上和特定的单视角学习相比具有一定的优势.多视角学习算法通常是在共识或互补原理的指导下建立的,现有的多视角算法可以分三类:协同训练类型算法、协同正则化类型算法和余量一致性类型算法[2].协同训练类型算法旨在最大化不同视角之间的一致性,如鲁棒协同训练支持向量机(Robust Co⁃Training SVM)[11].相比之下,协同正则化类型的算法可以最大程度地减少不同视角之间的分歧[11],例如多视角拉普拉斯支持向量机[6].余量一致性类型的算法利用多视角分类结果的潜在一致性[13],在最大熵判别(Maximue Entropy Dis⁃crimination,MED)[14]的基础上实现.余量一致性类型算法与协同正则化类型算法对多视角的判别或回归函数进行限制不同,它对多视角的余量变量进行建模,使其尽可能接近即每个输出变量和判别函数都大于每个余量变量,例如MVMED(Multi⁃View Maximum Entropy Discrimination),以最小化两个视角边距之间的相对熵实现了边距一致性[15].MED⁃2C (Consensus and Complementarity Based Maximun Entropy Discrimination)以互补子空间将共识和互补的两个原理整合到多视角MED,其泛化性比MVMED更好[16];Tang et al[17]的PSVM⁃2V (Privileged Svm⁃Based Two⁃View Classification Mode)是在SVM⁃2K的基础上结合特权信息并以QP问题迭代求解的算法. ...
A new learning paradigm:Learning using privileged information
2
2009
... 现有的多视角学习算法主要体现了多视角学习的共识原理或互补性原理[1].在多视角学习中,共识和互补性原理在指导模型构建中起着重要作用.共识原理的目的是最大化多个不同视角的一致性,改善算法的泛化误差范围;相反,互补原理强调视角之间共享互补信息,目的是更全面地描述数据,提高算法的鲁棒性.Vapnik提出使用特权信息学习(Learning Using Privileged Information,LUPI)[7]来解决学习模型中的补充知识.LUPI将人类的教学理念融入机器学习的概念,对于一个特定的任务,比如分类,训练数据不仅是目标任务的监督信息,还有一些额外的特权信息(附加信息).从多视角学习的角度来看,不同的特征视角可以相互提供特权信息,实现互补[8]. ...
... LUPI使用仅在训练期间可用的数据帮助学习模型在测试阶段实现更好的预测结果.特权信息作为附加特征用来改进特定的分类器,Vipnik and Vashist提出了最早的LUPI算法支持向量机(Support Vector Machine+,SVM+)[7].Tang et al[18]将LUPI和多视角结合提出PSVM (Multiview Privileged Support Vector Machines),Li et al[19]提出基于LUPI双支持向量机(Robust Capped L1⁃norm Twin Support Vector Machine with Privileged Information,R⁃CTSVM+)来解决异常值和噪声问题. ...
Learning using privileged information:Similarity control and knowledge transfer
1
2015
... 现有的多视角学习算法主要体现了多视角学习的共识原理或互补性原理[1].在多视角学习中,共识和互补性原理在指导模型构建中起着重要作用.共识原理的目的是最大化多个不同视角的一致性,改善算法的泛化误差范围;相反,互补原理强调视角之间共享互补信息,目的是更全面地描述数据,提高算法的鲁棒性.Vapnik提出使用特权信息学习(Learning Using Privileged Information,LUPI)[7]来解决学习模型中的补充知识.LUPI将人类的教学理念融入机器学习的概念,对于一个特定的任务,比如分类,训练数据不仅是目标任务的监督信息,还有一些额外的特权信息(附加信息).从多视角学习的角度来看,不同的特征视角可以相互提供特权信息,实现互补[8]. ...
Sparse kernel methods for high?dimensional survival data
... 多视角学习在一定程度上和特定的单视角学习相比具有一定的优势.多视角学习算法通常是在共识或互补原理的指导下建立的,现有的多视角算法可以分三类:协同训练类型算法、协同正则化类型算法和余量一致性类型算法[2].协同训练类型算法旨在最大化不同视角之间的一致性,如鲁棒协同训练支持向量机(Robust Co⁃Training SVM)[11].相比之下,协同正则化类型的算法可以最大程度地减少不同视角之间的分歧[11],例如多视角拉普拉斯支持向量机[6].余量一致性类型的算法利用多视角分类结果的潜在一致性[13],在最大熵判别(Maximue Entropy Dis⁃crimination,MED)[14]的基础上实现.余量一致性类型算法与协同正则化类型算法对多视角的判别或回归函数进行限制不同,它对多视角的余量变量进行建模,使其尽可能接近即每个输出变量和判别函数都大于每个余量变量,例如MVMED(Multi⁃View Maximum Entropy Discrimination),以最小化两个视角边距之间的相对熵实现了边距一致性[15].MED⁃2C (Consensus and Complementarity Based Maximun Entropy Discrimination)以互补子空间将共识和互补的两个原理整合到多视角MED,其泛化性比MVMED更好[16];Tang et al[17]的PSVM⁃2V (Privileged Svm⁃Based Two⁃View Classification Mode)是在SVM⁃2K的基础上结合特权信息并以QP问题迭代求解的算法. ...
... [11],例如多视角拉普拉斯支持向量机[6].余量一致性类型的算法利用多视角分类结果的潜在一致性[13],在最大熵判别(Maximue Entropy Dis⁃crimination,MED)[14]的基础上实现.余量一致性类型算法与协同正则化类型算法对多视角的判别或回归函数进行限制不同,它对多视角的余量变量进行建模,使其尽可能接近即每个输出变量和判别函数都大于每个余量变量,例如MVMED(Multi⁃View Maximum Entropy Discrimination),以最小化两个视角边距之间的相对熵实现了边距一致性[15].MED⁃2C (Consensus and Complementarity Based Maximun Entropy Discrimination)以互补子空间将共识和互补的两个原理整合到多视角MED,其泛化性比MVMED更好[16];Tang et al[17]的PSVM⁃2V (Privileged Svm⁃Based Two⁃View Classification Mode)是在SVM⁃2K的基础上结合特权信息并以QP问题迭代求解的算法. ...
Multi?view sampling for relevance feedback in image retrieval
0
2006
基于划分融合与视角加权的极大熵聚类算法
1
2016
... 多视角学习在一定程度上和特定的单视角学习相比具有一定的优势.多视角学习算法通常是在共识或互补原理的指导下建立的,现有的多视角算法可以分三类:协同训练类型算法、协同正则化类型算法和余量一致性类型算法[2].协同训练类型算法旨在最大化不同视角之间的一致性,如鲁棒协同训练支持向量机(Robust Co⁃Training SVM)[11].相比之下,协同正则化类型的算法可以最大程度地减少不同视角之间的分歧[11],例如多视角拉普拉斯支持向量机[6].余量一致性类型的算法利用多视角分类结果的潜在一致性[13],在最大熵判别(Maximue Entropy Dis⁃crimination,MED)[14]的基础上实现.余量一致性类型算法与协同正则化类型算法对多视角的判别或回归函数进行限制不同,它对多视角的余量变量进行建模,使其尽可能接近即每个输出变量和判别函数都大于每个余量变量,例如MVMED(Multi⁃View Maximum Entropy Discrimination),以最小化两个视角边距之间的相对熵实现了边距一致性[15].MED⁃2C (Consensus and Complementarity Based Maximun Entropy Discrimination)以互补子空间将共识和互补的两个原理整合到多视角MED,其泛化性比MVMED更好[16];Tang et al[17]的PSVM⁃2V (Privileged Svm⁃Based Two⁃View Classification Mode)是在SVM⁃2K的基础上结合特权信息并以QP问题迭代求解的算法. ...
基于划分融合与视角加权的极大熵聚类算法
1
2016
... 多视角学习在一定程度上和特定的单视角学习相比具有一定的优势.多视角学习算法通常是在共识或互补原理的指导下建立的,现有的多视角算法可以分三类:协同训练类型算法、协同正则化类型算法和余量一致性类型算法[2].协同训练类型算法旨在最大化不同视角之间的一致性,如鲁棒协同训练支持向量机(Robust Co⁃Training SVM)[11].相比之下,协同正则化类型的算法可以最大程度地减少不同视角之间的分歧[11],例如多视角拉普拉斯支持向量机[6].余量一致性类型的算法利用多视角分类结果的潜在一致性[13],在最大熵判别(Maximue Entropy Dis⁃crimination,MED)[14]的基础上实现.余量一致性类型算法与协同正则化类型算法对多视角的判别或回归函数进行限制不同,它对多视角的余量变量进行建模,使其尽可能接近即每个输出变量和判别函数都大于每个余量变量,例如MVMED(Multi⁃View Maximum Entropy Discrimination),以最小化两个视角边距之间的相对熵实现了边距一致性[15].MED⁃2C (Consensus and Complementarity Based Maximun Entropy Discrimination)以互补子空间将共识和互补的两个原理整合到多视角MED,其泛化性比MVMED更好[16];Tang et al[17]的PSVM⁃2V (Privileged Svm⁃Based Two⁃View Classification Mode)是在SVM⁃2K的基础上结合特权信息并以QP问题迭代求解的算法. ...
Maximum entropy discrimination (MED) feature subset selection for speech recognition
1
2003
... 多视角学习在一定程度上和特定的单视角学习相比具有一定的优势.多视角学习算法通常是在共识或互补原理的指导下建立的,现有的多视角算法可以分三类:协同训练类型算法、协同正则化类型算法和余量一致性类型算法[2].协同训练类型算法旨在最大化不同视角之间的一致性,如鲁棒协同训练支持向量机(Robust Co⁃Training SVM)[11].相比之下,协同正则化类型的算法可以最大程度地减少不同视角之间的分歧[11],例如多视角拉普拉斯支持向量机[6].余量一致性类型的算法利用多视角分类结果的潜在一致性[13],在最大熵判别(Maximue Entropy Dis⁃crimination,MED)[14]的基础上实现.余量一致性类型算法与协同正则化类型算法对多视角的判别或回归函数进行限制不同,它对多视角的余量变量进行建模,使其尽可能接近即每个输出变量和判别函数都大于每个余量变量,例如MVMED(Multi⁃View Maximum Entropy Discrimination),以最小化两个视角边距之间的相对熵实现了边距一致性[15].MED⁃2C (Consensus and Complementarity Based Maximun Entropy Discrimination)以互补子空间将共识和互补的两个原理整合到多视角MED,其泛化性比MVMED更好[16];Tang et al[17]的PSVM⁃2V (Privileged Svm⁃Based Two⁃View Classification Mode)是在SVM⁃2K的基础上结合特权信息并以QP问题迭代求解的算法. ...
Multi?view maximum entropy discrimination
1
2013
... 多视角学习在一定程度上和特定的单视角学习相比具有一定的优势.多视角学习算法通常是在共识或互补原理的指导下建立的,现有的多视角算法可以分三类:协同训练类型算法、协同正则化类型算法和余量一致性类型算法[2].协同训练类型算法旨在最大化不同视角之间的一致性,如鲁棒协同训练支持向量机(Robust Co⁃Training SVM)[11].相比之下,协同正则化类型的算法可以最大程度地减少不同视角之间的分歧[11],例如多视角拉普拉斯支持向量机[6].余量一致性类型的算法利用多视角分类结果的潜在一致性[13],在最大熵判别(Maximue Entropy Dis⁃crimination,MED)[14]的基础上实现.余量一致性类型算法与协同正则化类型算法对多视角的判别或回归函数进行限制不同,它对多视角的余量变量进行建模,使其尽可能接近即每个输出变量和判别函数都大于每个余量变量,例如MVMED(Multi⁃View Maximum Entropy Discrimination),以最小化两个视角边距之间的相对熵实现了边距一致性[15].MED⁃2C (Consensus and Complementarity Based Maximun Entropy Discrimination)以互补子空间将共识和互补的两个原理整合到多视角MED,其泛化性比MVMED更好[16];Tang et al[17]的PSVM⁃2V (Privileged Svm⁃Based Two⁃View Classification Mode)是在SVM⁃2K的基础上结合特权信息并以QP问题迭代求解的算法. ...
Consensus and complementarity based maximum entropy discrimination for multi?view classification
1
2016
... 多视角学习在一定程度上和特定的单视角学习相比具有一定的优势.多视角学习算法通常是在共识或互补原理的指导下建立的,现有的多视角算法可以分三类:协同训练类型算法、协同正则化类型算法和余量一致性类型算法[2].协同训练类型算法旨在最大化不同视角之间的一致性,如鲁棒协同训练支持向量机(Robust Co⁃Training SVM)[11].相比之下,协同正则化类型的算法可以最大程度地减少不同视角之间的分歧[11],例如多视角拉普拉斯支持向量机[6].余量一致性类型的算法利用多视角分类结果的潜在一致性[13],在最大熵判别(Maximue Entropy Dis⁃crimination,MED)[14]的基础上实现.余量一致性类型算法与协同正则化类型算法对多视角的判别或回归函数进行限制不同,它对多视角的余量变量进行建模,使其尽可能接近即每个输出变量和判别函数都大于每个余量变量,例如MVMED(Multi⁃View Maximum Entropy Discrimination),以最小化两个视角边距之间的相对熵实现了边距一致性[15].MED⁃2C (Consensus and Complementarity Based Maximun Entropy Discrimination)以互补子空间将共识和互补的两个原理整合到多视角MED,其泛化性比MVMED更好[16];Tang et al[17]的PSVM⁃2V (Privileged Svm⁃Based Two⁃View Classification Mode)是在SVM⁃2K的基础上结合特权信息并以QP问题迭代求解的算法. ...
Improved multi?view privileged support vector machine
1
2018
... 多视角学习在一定程度上和特定的单视角学习相比具有一定的优势.多视角学习算法通常是在共识或互补原理的指导下建立的,现有的多视角算法可以分三类:协同训练类型算法、协同正则化类型算法和余量一致性类型算法[2].协同训练类型算法旨在最大化不同视角之间的一致性,如鲁棒协同训练支持向量机(Robust Co⁃Training SVM)[11].相比之下,协同正则化类型的算法可以最大程度地减少不同视角之间的分歧[11],例如多视角拉普拉斯支持向量机[6].余量一致性类型的算法利用多视角分类结果的潜在一致性[13],在最大熵判别(Maximue Entropy Dis⁃crimination,MED)[14]的基础上实现.余量一致性类型算法与协同正则化类型算法对多视角的判别或回归函数进行限制不同,它对多视角的余量变量进行建模,使其尽可能接近即每个输出变量和判别函数都大于每个余量变量,例如MVMED(Multi⁃View Maximum Entropy Discrimination),以最小化两个视角边距之间的相对熵实现了边距一致性[15].MED⁃2C (Consensus and Complementarity Based Maximun Entropy Discrimination)以互补子空间将共识和互补的两个原理整合到多视角MED,其泛化性比MVMED更好[16];Tang et al[17]的PSVM⁃2V (Privileged Svm⁃Based Two⁃View Classification Mode)是在SVM⁃2K的基础上结合特权信息并以QP问题迭代求解的算法. ...
Multiview privileged support vector machines
1
2018
... LUPI使用仅在训练期间可用的数据帮助学习模型在测试阶段实现更好的预测结果.特权信息作为附加特征用来改进特定的分类器,Vipnik and Vashist提出了最早的LUPI算法支持向量机(Support Vector Machine+,SVM+)[7].Tang et al[18]将LUPI和多视角结合提出PSVM (Multiview Privileged Support Vector Machines),Li et al[19]提出基于LUPI双支持向量机(Robust Capped L1⁃norm Twin Support Vector Machine with Privileged Information,R⁃CTSVM+)来解决异常值和噪声问题. ...
R?CTSVM+:Robust capped L1?norm twin support vector machine with privileged information
1
2021
... LUPI使用仅在训练期间可用的数据帮助学习模型在测试阶段实现更好的预测结果.特权信息作为附加特征用来改进特定的分类器,Vipnik and Vashist提出了最早的LUPI算法支持向量机(Support Vector Machine+,SVM+)[7].Tang et al[18]将LUPI和多视角结合提出PSVM (Multiview Privileged Support Vector Machines),Li et al[19]提出基于LUPI双支持向量机(Robust Capped L1⁃norm Twin Support Vector Machine with Privileged Information,R⁃CTSVM+)来解决异常值和噪声问题. ...
Learning and generalization characteristics of the random vector Functional?link net
Zero?shot learning:A comprehensive evaluation of the good,the bad and the ugly
1
2019
... AwA2[24]:包含50种动物的30475张图像,图像数据是2016年从公共资源收集的.每张图像具有六个预先提取的特征表示.在二分类实验中使用(Speeded Up Robust Features,SURF)特征2000⁃D、(Histogram of Oriented Gradient,HOG)特征252⁃D、(Color Histogram features CHF)特征2600⁃D、(Local Self⁃Similarity features LSS)特征2000⁃D. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}