

将包从原始空间转换到新特征空间进行学习的分类算法是近年来MIL的研究热点之一.Constructive Clustering⁃Based Ensemble (CCE)[11]首先将所有包中的实例聚类为d簇;然后将包映射为d维单向量,如果包中实例属于第i个簇,则第i个特征值设置为1,否则设置为0.Multi⁃Instance Learning via Embedded Instance Selection (MILES)[12]首先构建包含所有训练实例的特征空间,然后通过特征空间中实例与包中实例的相似关系,将包转化为单向量.Image Annotation by Multi⁃Instance Learning with Discriminative Feature Mapping and Selection (MILFM)[13]首先从正负包中选择原型实例并从负包中选择聚类实例,再利用包与正负实例原型的相关性进行映射.然而,上述算法没有考虑包内部的结构特征,且只能利用固定的空间关系进行映射.
本文提出一种多示例学习的两阶段实例选择和自适应包映射算法(The Two⁃stage Instance
Selection and Adaptive Bag Mapping Algorithm for Multi⁃Instance Learning,TAMI).实例选择技术分两个阶段来选择数据空间的代表实例:第一阶段,利用包中实例的密度值和关联性,分析包内结构特征,选取实例原型;第二阶段,根据实例原型分布的紧密程度,从中选出具有峰值密度[14]的实例作为代表实例.自适应包映射技术基于包与代表实例的自适应距离关系,通过差值处理将其转化为单向量.实验结果表明,TAMI在图像检索和医学图像数据集上取得了比其他MIL算法更好的效果,并在文本分类数据集上表现良好.
针对MIL分类任务,本文的主要贡献如下:
(1)提出一种高效的两阶段实例选择技术:第一阶段,实例选择技术最大限度地保留了包的内部结构特征,同时大幅度地缩减了代表实例的求解范围;第二阶段,实例选择技术从实例原型中寻找更具有代表性的实例,使得包在新特征空间更具有可区分性.
(2)提出一种自适应的包映射函数.包中实例与代表实例间以最佳相似度进行映射,使新的特征空间能最大程度地保留原始空间的特征.
1 相关工作
根据不同的处理策略,MIL算法主要包括基于统计的算法、基于包的算法、基于核的算法和基于实例的算法.
1.1 基于统计的算法
基于统计的算法使用一个或多个统计变量来对包进行量化,试图捕获包中实例的特征分布.Simple⁃Multi Instance (Simple⁃MI)[15]统计包中所有实例属性的平均值,即用均值向量来代表该包,具有简单快速的特点.
1.2 基于包的算法
基于包的算法在包空间寻找最具信息量的包节点,然后利用包与包之间的距离关系进行映射.Bag Level Multi⁃Instance Clustering (Bamic)[16]在训练包上建立聚类模型,将训练包分成k簇;根据k个簇的中心,将每个包转换成单向量.向量的第j个属性值则是该包到第j个簇中心的距离.
1.3 基于核的算法
基于核的算法专注于设计或使用核来进行实例之间的相似性描述,例如高斯核、Fisher核或隔离核.Multi⁃Instance Graph (miGraph)[8]考虑包内实例的关联性,设计了一种直接计算包与包之间相似性的graph核.Multi⁃Instance Learning Based on the Fisher Vector Representation (miFV)[8]使用预训练的高斯混合模型获取不同分布的权重、均值和协方差,然后基于这些信息和Fisher核将每个包编码为高维单向量.Isolation Set⁃Kernel (ISK)[18]从训练实例空间随机取样并构建多个维诺图,使用隔离核为包中的实例分配权重,最终基于包中带权重的实例和维诺图进行映射.
1.4 基于实例的算法
基于实例的算法在实例级进行处理.首先,通过无监督学习、指标分析或其他方法在实例空间中找到关键实例;其次,通过包与关键实例之间的距离,将每个包映射为单个向量.Multi⁃Instance Learning Based on the Vector of Locally Aggregated Descriptors Representation (miVLAD)[19]算法在整个实例空间中,通过
k⁃Means获得聚类中心,然后使用映射函数将包转化为单向量.单向量的维度与k⁃Means聚类中心数量直接关联,即k值越大,映射向量的维度越高.Discriminative Mapping Approach for Multi⁃Instance Learning (MILDM)[20]在整个实例空间构建满足关键实例判别标准的映射函数,尽可能保留包在新特征空间中的可区分性,然而算法的时间开销与实例空间的大小呈平方关系.Multi⁃Instance with Key Instance shift (MIKI)[21]首先训练一个加权的多类模型以选择具有高正性的实例作为原型实例,然后将包转换为具有原型实例信息的向量,其次将原型实例的权重合并到转换后的包向量中,以缩小训练/测试分布之间的差距,最后使用新的包向量及其权重来学习.
基于实例的算法在很大程度上保留了实例的信息,因此在特定的数据集上有更好的效果.
2 两阶段实例选择和自适应包映射算法
本算法的主要思想:通过两阶段实例选择技术快速选取代表实例,再采用自适应的映射方法将包转换成单示例.以图像数据集的处理过程为例,如图1所示(图片来源为Corel数据集):第一阶段,计算原始数据包中实例的密度值和关联性,分析其内部结构特征,选出实例原型;第二阶段,从实例原型池中选取出具有峰值密度特点的代表实例;最后,根据包中实例与代表实例的相似性,通过自适应差值处理,实现包映射.
图 1

2.1 符号系统
令
2.2 两阶段实例选择技术
两阶段实例选择技术首先在包内选取实例原型,然后在实例原型池中选出代表实例.
2.2.1 实例原型选择
第一阶段实例选择技术基于包内实例的优先级,选出具有包内部结构特征的实例原型.令
其中,
(1)为了使实例
其中,
图 2
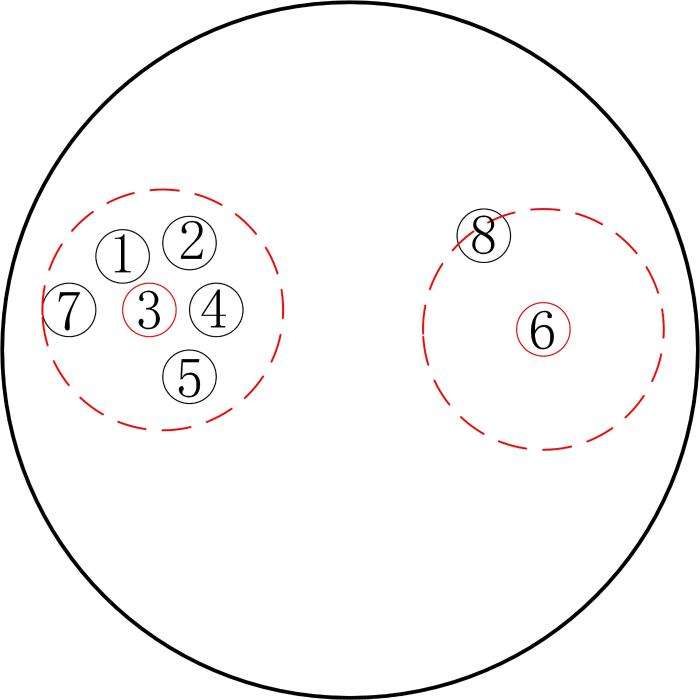
(2)MIL使用多个实例来表示对象,实例之间则存在一种特殊的内在结构.本文使用包中实例的关联性来分析包的内部结构特征.实例
其中,
图 3
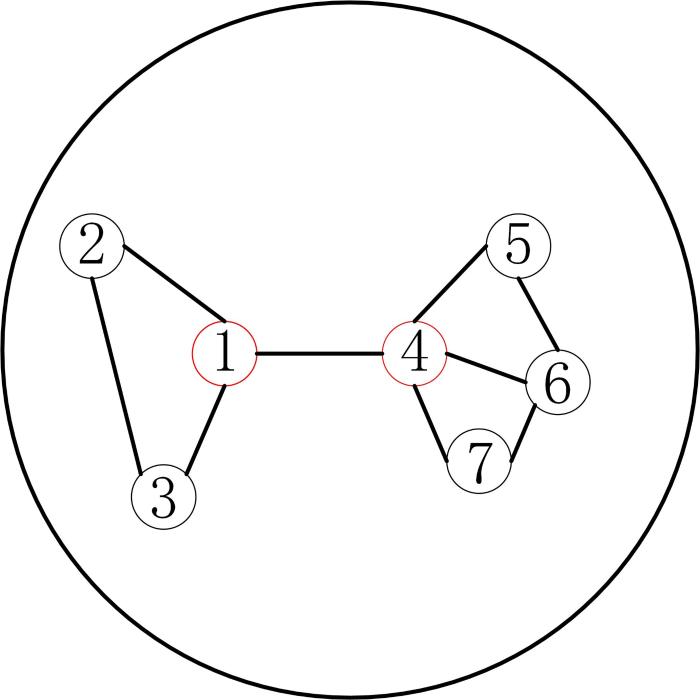
最后,利用
2.2.2 代表实例选择
第二阶段实例选择技术从
对于任意的
特别地,密度最大的实例原型的
基于实例原型的
图4

因此,本文从
2.3 自适应包映射技术
自适应包映射技术根据包中实例与代表实例间的最佳相似度进行映射,既突出了包的内部结构特征,也保证了包在新特征空间中的可区分性.
对于给定的包
图5

(4)将所有
进一步,对于
2.4 算法描述
TAMI算法分为两个阶段,如Algorithm 1所示:算法输入是训练集Btr(其中ntr表示Btr中包的个数)和代表实例的数量nr;输出是训练好的单示例分类器
Algorithm 1 The TAMI algorithm
Input:Training data
Output:The a single⁃instance classifier
representative instance pool
Train:
∥Step 1.Find instance prototypes
density and affinity of instances in the bag.
1.
2.for
3. Compute
4.
5.
6.end for
∥Step 2. Find representative instance pool
7.
8.
9.for
10.
11.
12.end for
∥Step 3. Map each bag into a single vector.
13.for
14. Compute
15.
16.
17.end for
18.Train a single⁃instance classifier
vector⁃label pairs
Test:
19.For each test bag
20.Output the prediction
3 实验与结果
为了验证TAMI算法的分类性能,选取三个领域的MIL数据集进行实验,包括图像检索、医学图像以及文本分类,并与Simple⁃MI,Bamic,miVLAD,miFV和MILDM四类MIL算法进行实验对比.表1给出了以上数据集的关键信息,采用支持向量机(Support Vector
表 1 实验使用的数据集信息
Table 1
| Name | Bag | Instance | Attribute | Class |
|---|---|---|---|---|
| Elephant | 200 | 1391 | 230 | 2 |
| Fox | 200 | 1320 | 230 | 2 |
| Tiger | 200 | 1220 | 230 | 2 |
| Messidor | 1200 | 12352 | 687 | 2 |
| Ucsb_breast | 58 | 2002 | 708 | 2 |
| Newsgroups | 2000 | 80137 | 200 | 20 |
Machine,SVM)作为单示例级别分类器.
实验的性能度量建立在混淆矩阵的基础上.对于二分类问题,可将样本分为真正例(TP)、假正例(FP)、真反例(TN)和假反例(FN)四种情形.最终选取Accuracy作为性能度量指标,如
3.1 数据集简介
Elephant,Fox和Tiger[7]是图像检索中常用的数据集,其任务是确定图像中是否包含感兴趣的对象.每类数据集包含200张图像,每个图像看作一个包,图像的不同区域则视为包中的实例.如果包中包含至少一个该类别的实例,则视为正包,反之为负包.
Newsgroups数据集属于文本分类问题[8],包含20个来自不同新闻帖子的子数据集,每个子数据集都包含50个正包和50个负包.每个正包中包含目标类别中3%的帖子以及从其他类别中随机抽取的97%的帖子.每个负包则只包含从其他类别中随机均匀抽取的帖子,不含目标类别的任何数据.
3.2 实验结果
表2 图像检索和医学图像数据集上不同算法的平均准确率
Table 2
| Datasets | Simple⁃MI | Bamic | miFV | miVLAD | MILDM | TAMI |
|---|---|---|---|---|---|---|
| Elephant | ||||||
| Fox | ||||||
| Tiger | ||||||
| Messidor | ||||||
| Ucsb_breast |
表3 文本分类数据集上不同算法的平均准确率
Table 3
| Datasets | Simple⁃MI | Bamic | miFV | miVLAD | MILDM | TAMI |
|---|---|---|---|---|---|---|
| alt.atheism | ||||||
| comp.graphics | ||||||
| comp.os.ms | ||||||
| comp.sys.ibm | ||||||
| comp.sys.mac | ||||||
| comp.window.x | ||||||
| misc.forsale | ||||||
| rec.autos | ||||||
| rec.motorcycles | ||||||
| rec.sport.baseball | ||||||
| rec.sport.hockey | ||||||
| sci.crypt | ||||||
| sci.electronics | ||||||
| sci.med | ||||||
| sci.religion | ||||||
| sci.space | ||||||
| talk.politics.guns | ||||||
| talk.politics.mideast | ||||||
| talk.politics.misc | ||||||
| talk.religion.misc |
用统计显著性检验[25]进一步分析TAMI算法的性能.采用Friedman检验比较各个算法准确率的平均排名.表4显示TAMI算法与其他五个算法的等级排名,等级越高取值越低.根据平均序值能够得到六个算法的分类性能排名,从高到低依次为TAMI,miVLAD,miFV,Bamic,Simple⁃MI,MILDM.图6直观地展现了各个算法之间的性能差异,实心点表示各算法的平均序值,以实心点为中心的水平线段表示临界值范围的大小.结果显示,TAMI算法与MILDM和Simple⁃MI的水平线段没有交叠区域,因此TAMI算法显著优于MILDM和Simple⁃MI;与Bamic有很少的交叠区域,因此TAMI优于算法Bamic;与miVLAD和miFV有部分交叠区域,因此它们存在一定差异.
表4 六种算法在三类数据集上的平均排名
Table 4
| Datasets | Simple⁃MI | Bamic | miFV | miVLAD | MILDM | TAMI |
|---|---|---|---|---|---|---|
| 平均等级 | 5.1 | 4.13 | 2.64 | 2.38 | 5.3 | 1.45 |
| 图像检索 | 5.3 | 4.3 | 4.3 | 2 | 4 | 1 |
| 医学图像 | 5 | 4 | 1.5 | 3 | 6 | 1.5 |
| 文本分类 | 4.95 | 4.05 | 2.1 | 2.15 | 5.9 | 1.85 |
图6

4 总结与展望
本文提出一种多示例学习的两阶段实例选择和自适应包映射(TAMI)算法.该算法首先计算包内实例的密度值和关联性,选出具有包内部结构信息的实例原型;然后基于实例原型的峰值密度特点,选择一定数目的代表实例;最后根据包与代表实例的相似关系来构建自适应背景,从而实现自适应包映射. 该算法的优势在于:(1)代表实例的选取无需迭代优化,计算速度快;(2)通过考虑包中实例的密度值和相关性,可以有效保留包的内部结构特征;(3)代表实例的数目可以自由选择,使用灵活.实验结果表明,TAMI在图像检索和医学图像数据集上取得了比其他MIL算法更好的效果,并在文本分类数据集上的表现良好.
通过实验也发现:(1)TAMI算法没有在所有数据集上都表现最优,例如在文本数据集上取得了和miFV相近的结果;(2)实例的关联性计算仅考虑了实例之间的距离关系.这些都是本文进一步研究的方向,将在未来的工作中尝试解决.
参考文献
Solving the multiple instance problem with axis⁃parallel rectangles
Multiple⁃instance learning for natural scene classification
∥
Sparse coding and classifier ensemble based multi⁃instance learning for image categorization
Multi⁃instance learning with emerging novel class
Multi⁃class multi⁃instance learning for lung cancer image classification based on bag feature selection
∥
Attention⁃based multi⁃instance neural network for medical diagnosis from incomplete and low quality data
∥
Support vector machines for multiple⁃instance learning
∥
Multi⁃instance learning by treating instances as non⁃I.I.D. samples
∥
Multiple instance learning networks for fine⁃grained sentiment analysis
MI2LS:Multi⁃instance learning from multiple informationsources
∥
Solving multi⁃instance problems with classifier ensemble based on constructive clustering
MILES:Multiple⁃instance learning via embedded instance selection
Image annotation by multiple⁃instance learning with discriminative feature mapping and selection
Clustering by fast search and find of density peaks
Multiple instance classification:Review,taxonomy and comparative study
Multi⁃instance clustering with applications to multi⁃instance prediction
Scalable multi⁃instance learning
∥
Isolation set⁃kernel and its application to multi⁃instance learning
∥
Scalable algorithms for multi⁃instance learning
Multi⁃instance learning with discriminative bag mapping
Multi⁃instance learning with key instance shift
∥
Image classification with the fisher vector:Theory and practice
Feedback on a publicly distributed image database:The messidor database
Computer⁃aided diagnosis from weak supervision:A benchmarking study
Statistical comparisons of classifiers over multiple data sets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}