Thyroid cancer is the most common form of endocrine malignancy and the informative pathological images are critical for thyroid cancer risk stratification,prognosis and treatment guidance. Recent advances in deep learning have achieved promising results on pathology image classification benchmarks. However,to achieve an acceptable classification performance,most of the existing methods require a large number of labeled images. The manual annotation for the medical image is known to be tedious,time⁃consuming,and requires guidance from domain knowledge. To reduce the labeling cost,this paper proposes a classification method which integrates the convolutional neural network (CNN) and active learning to actively select a few samples for annotation. Specifically,we utilize CNN to extract feature of the pathological image. And then the deep feature is employed to estimate the uncertainty and representativeness of pathological image for “valuable” sample selection. Finally,the selected samples are annotated by pathologists and continuously fine⁃tune CNN to enhance the classification performance. The experimental results on thyroid pathological images demonstrate that the proposed method can reduce the labeling cost without sacrificing the accuracy of the classification system.
Keywords:papillary thyroid carcinoma pathological image
;
deep learning
;
active learning
;
image classification
;
Hash code
Zhang Meng, Han Bing, Wang Zhe, You Fusheng, Li Haoran. Papillary thyroid carcinoma pathological image classification based on deep active learning. Journal of nanjing University[J], 2021, 57(1): 21-28 doi:10.13232/j.cnki.jnju.2021.01.003
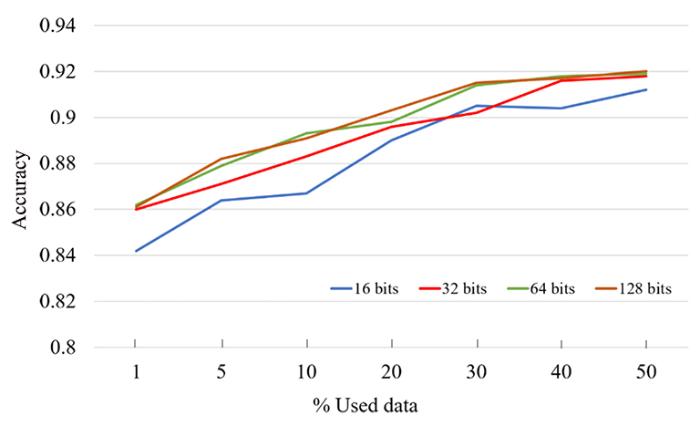
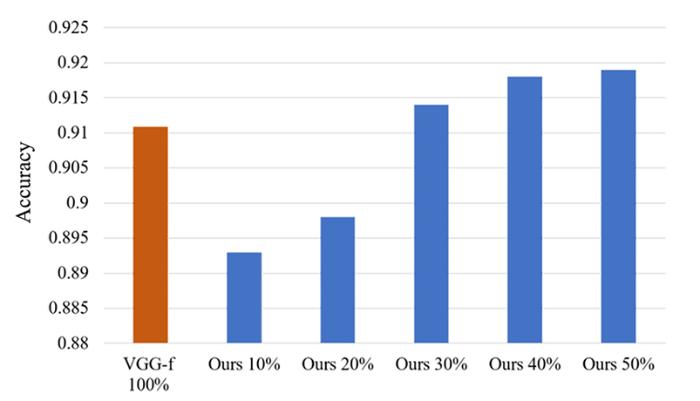
近年来,由于数字数据的爆炸性增长,存储和检索效率极高的哈希编码在各种计算机视觉任务中已被广泛应用.Venkateswara et al[5]使用深度神经网络学习样本的代表性哈希码来解决域适配问题,在无监督域自适应方面取得良好的效果.本文以该深度哈希网络为基础,结合主动学习算法,提出一种基于深度主动学习的甲状腺乳头状癌病理图像分类方法,将深度学习与主动学习集成到同一框架中.该方法通过CNN来提取图像特征,并利用不确定性信息与代表性信息对未标注数据集中“有价值的”样本进行注释.通过在每一轮迭代中加入新注释的样本对模型进行微调以增强模型的分类性能.在甲状腺癌病理图像数据集上的实验结果表明,和原始的CNN网络相比,本文提出的基于深度主动学习的甲状腺乳头状癌病理图像分类方法将标注样本数量降低了70%左右.
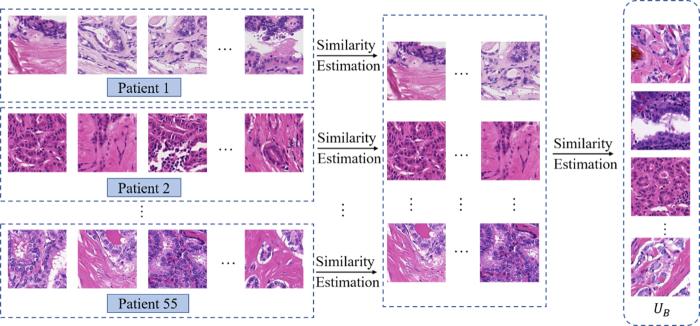
目前,解决标注问题的方法可以分为两大类:无监督方法和有监督方法.无监督学习能够根据未知类别的训练样本解决分类等问题,然而无监督学习的效果远远比不上监督学习,尤其对于医学图像,准确的分类是十分重要的,关乎后续治疗方案的制订.主动学习(Active Learining,AL)可以很好地平衡这两个问题,在减少标注代价的同时能保证分类准确率,因此众多研究者对主动学习进行了深入研究.在主动学习的早期研究中,主要依赖手工特征进行信息查询与样本选择.Abe and Mamitsuka[6]提出一种查询学习策略,结合委员会查询和装袋查询学习策略,在实际应用中获得了较好的效果.Ebert et al[7]分析不同的采样标准并提出一种基于强化学习的新型反馈驱动的主动学习框架,能够根据经验在学习过程中调整采样策略.Huang et al[8]提出一种基于主动学习的最小⁃最大观点,为结合样本的信息性和代表性提供了一种系统的方法.Tang and Huang[9]提出一种自定步长的主动学习方法:一方面考虑了信息量和代表性,选取的实例对模型的改进具有较高的潜在价值;另一方面,利用样本的易用性,使模型能够充分利用样本潜在价值.
近年来,由于深度学习的发展,主动学习与深度学习的研究[10-14]逐渐受到越来越多的重视.Wang and Shang[10]可能是第一次将主动学习与深度学习相结合,提出基于堆叠受限玻尔兹曼机和堆叠自动编码器的主动标记方法.Li[11]也将类似的方法应用于高光谱图像分类.Stark et al[12]利用主动学习提高基于CNNs的验证码识别性能,Al Rahhal et al[13]利用深度学习和主动学习进行心电图分类.Zhou et al[14]利用同一样本的不同裁剪图像块的类别及概率的选择样本进行标注,并在三个不同的生物医学图像数据集上获得了良好的效果,然而由于病理图像不同的裁剪的图像往往属于不同的类别,因此该方法不适用于甲状腺癌病理图像分类.Yang et al[15]将全卷积神经网络与主动学习进行结合,通过对最有效的注释区域进行注释来显著减少注释工作量,在2015年MICCAI腺体分割数据集上获得了较好的分割结果.
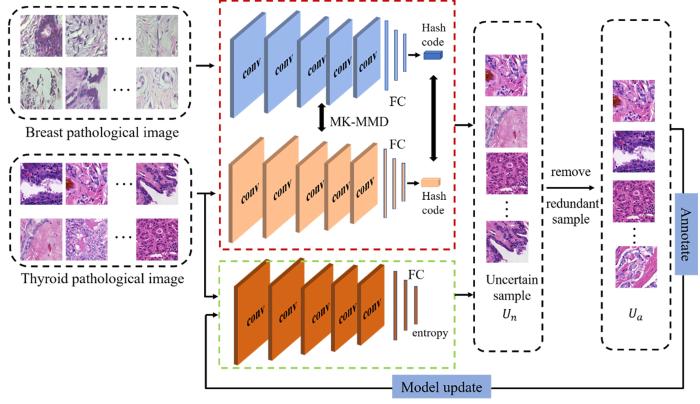
甲状腺癌病理图像与乳腺癌病理图像虽然都是病理数据,但这两种组织取自人体不同部位,切片制作过程不同,且扫描时使用的扫描仪不同,因此需要减小这两种数据的差异.对于病理图像,细胞核的特征是关键,底层感受野较小的神经元能够学到核的形状及分布等特征,网络的高层特征对分类十分重要,因此对网络的五个卷积层与全连接层进行特征对齐,以减少甲状腺癌病理图像特征与乳腺癌病理图像特征表示之间的域差异.多核最大均值差异(Multi⁃Kernel Maximum Mean Discrepancy,MK⁃MMD)在减少域差异方面表现优异.然而现有的减小域差异的模型大多针对自然图像数据,需要对MK⁃MMD进行改进.多层MK⁃MMD损失函数表示为:
,regional,and national cancer incidence,mortality,years of life lost,years lived with disability,and disability⁃adjusted life⁃years for 32 cancer groups,1990 to
2015:a systematic analysis for the global burden of disease study
WangW. Research progress in metastatic cervical lymph node dissection of thyroid papillary carcinoma. Ph.D. Dissertation. Bengbu:Bengbu Medical College,2015.
Deep hashing network for unsupervised domain adaptation
2
2017
... 近年来,由于数字数据的爆炸性增长,存储和检索效率极高的哈希编码在各种计算机视觉任务中已被广泛应用.Venkateswara et al[5]使用深度神经网络学习样本的代表性哈希码来解决域适配问题,在无监督域自适应方面取得良好的效果.本文以该深度哈希网络为基础,结合主动学习算法,提出一种基于深度主动学习的甲状腺乳头状癌病理图像分类方法,将深度学习与主动学习集成到同一框架中.该方法通过CNN来提取图像特征,并利用不确定性信息与代表性信息对未标注数据集中“有价值的”样本进行注释.通过在每一轮迭代中加入新注释的样本对模型进行微调以增强模型的分类性能.在甲状腺癌病理图像数据集上的实验结果表明,和原始的CNN网络相比,本文提出的基于深度主动学习的甲状腺乳头状癌病理图像分类方法将标注样本数量降低了70%左右. ...
Query learning strategies using boosting and bagging
2
1998
... 目前,解决标注问题的方法可以分为两大类:无监督方法和有监督方法.无监督学习能够根据未知类别的训练样本解决分类等问题,然而无监督学习的效果远远比不上监督学习,尤其对于医学图像,准确的分类是十分重要的,关乎后续治疗方案的制订.主动学习(Active Learining,AL)可以很好地平衡这两个问题,在减少标注代价的同时能保证分类准确率,因此众多研究者对主动学习进行了深入研究.在主动学习的早期研究中,主要依赖手工特征进行信息查询与样本选择.Abe and Mamitsuka[6]提出一种查询学习策略,结合委员会查询和装袋查询学习策略,在实际应用中获得了较好的效果.Ebert et al[7]分析不同的采样标准并提出一种基于强化学习的新型反馈驱动的主动学习框架,能够根据经验在学习过程中调整采样策略.Huang et al[8]提出一种基于主动学习的最小⁃最大观点,为结合样本的信息性和代表性提供了一种系统的方法.Tang and Huang[9]提出一种自定步长的主动学习方法:一方面考虑了信息量和代表性,选取的实例对模型的改进具有较高的潜在价值;另一方面,利用样本的易用性,使模型能够充分利用样本潜在价值. ...
RALF:a reinforced active learning formulation for object class recognition
2
2012
... 目前,解决标注问题的方法可以分为两大类:无监督方法和有监督方法.无监督学习能够根据未知类别的训练样本解决分类等问题,然而无监督学习的效果远远比不上监督学习,尤其对于医学图像,准确的分类是十分重要的,关乎后续治疗方案的制订.主动学习(Active Learining,AL)可以很好地平衡这两个问题,在减少标注代价的同时能保证分类准确率,因此众多研究者对主动学习进行了深入研究.在主动学习的早期研究中,主要依赖手工特征进行信息查询与样本选择.Abe and Mamitsuka[6]提出一种查询学习策略,结合委员会查询和装袋查询学习策略,在实际应用中获得了较好的效果.Ebert et al[7]分析不同的采样标准并提出一种基于强化学习的新型反馈驱动的主动学习框架,能够根据经验在学习过程中调整采样策略.Huang et al[8]提出一种基于主动学习的最小⁃最大观点,为结合样本的信息性和代表性提供了一种系统的方法.Tang and Huang[9]提出一种自定步长的主动学习方法:一方面考虑了信息量和代表性,选取的实例对模型的改进具有较高的潜在价值;另一方面,利用样本的易用性,使模型能够充分利用样本潜在价值. ...
Active learning by querying informative and representative examples
2
2010
... 目前,解决标注问题的方法可以分为两大类:无监督方法和有监督方法.无监督学习能够根据未知类别的训练样本解决分类等问题,然而无监督学习的效果远远比不上监督学习,尤其对于医学图像,准确的分类是十分重要的,关乎后续治疗方案的制订.主动学习(Active Learining,AL)可以很好地平衡这两个问题,在减少标注代价的同时能保证分类准确率,因此众多研究者对主动学习进行了深入研究.在主动学习的早期研究中,主要依赖手工特征进行信息查询与样本选择.Abe and Mamitsuka[6]提出一种查询学习策略,结合委员会查询和装袋查询学习策略,在实际应用中获得了较好的效果.Ebert et al[7]分析不同的采样标准并提出一种基于强化学习的新型反馈驱动的主动学习框架,能够根据经验在学习过程中调整采样策略.Huang et al[8]提出一种基于主动学习的最小⁃最大观点,为结合样本的信息性和代表性提供了一种系统的方法.Tang and Huang[9]提出一种自定步长的主动学习方法:一方面考虑了信息量和代表性,选取的实例对模型的改进具有较高的潜在价值;另一方面,利用样本的易用性,使模型能够充分利用样本潜在价值. ...
Self?paced active learning:Query the right thing at the right time
2
2019
... 目前,解决标注问题的方法可以分为两大类:无监督方法和有监督方法.无监督学习能够根据未知类别的训练样本解决分类等问题,然而无监督学习的效果远远比不上监督学习,尤其对于医学图像,准确的分类是十分重要的,关乎后续治疗方案的制订.主动学习(Active Learining,AL)可以很好地平衡这两个问题,在减少标注代价的同时能保证分类准确率,因此众多研究者对主动学习进行了深入研究.在主动学习的早期研究中,主要依赖手工特征进行信息查询与样本选择.Abe and Mamitsuka[6]提出一种查询学习策略,结合委员会查询和装袋查询学习策略,在实际应用中获得了较好的效果.Ebert et al[7]分析不同的采样标准并提出一种基于强化学习的新型反馈驱动的主动学习框架,能够根据经验在学习过程中调整采样策略.Huang et al[8]提出一种基于主动学习的最小⁃最大观点,为结合样本的信息性和代表性提供了一种系统的方法.Tang and Huang[9]提出一种自定步长的主动学习方法:一方面考虑了信息量和代表性,选取的实例对模型的改进具有较高的潜在价值;另一方面,利用样本的易用性,使模型能够充分利用样本潜在价值. ...
... 近年来,由于深度学习的发展,主动学习与深度学习的研究[10-14]逐渐受到越来越多的重视.Wang and Shang[10]可能是第一次将主动学习与深度学习相结合,提出基于堆叠受限玻尔兹曼机和堆叠自动编码器的主动标记方法.Li[11]也将类似的方法应用于高光谱图像分类.Stark et al[12]利用主动学习提高基于CNNs的验证码识别性能,Al Rahhal et al[13]利用深度学习和主动学习进行心电图分类.Zhou et al[14]利用同一样本的不同裁剪图像块的类别及概率的选择样本进行标注,并在三个不同的生物医学图像数据集上获得了良好的效果,然而由于病理图像不同的裁剪的图像往往属于不同的类别,因此该方法不适用于甲状腺癌病理图像分类.Yang et al[15]将全卷积神经网络与主动学习进行结合,通过对最有效的注释区域进行注释来显著减少注释工作量,在2015年MICCAI腺体分割数据集上获得了较好的分割结果. ...
... [10]可能是第一次将主动学习与深度学习相结合,提出基于堆叠受限玻尔兹曼机和堆叠自动编码器的主动标记方法.Li[11]也将类似的方法应用于高光谱图像分类.Stark et al[12]利用主动学习提高基于CNNs的验证码识别性能,Al Rahhal et al[13]利用深度学习和主动学习进行心电图分类.Zhou et al[14]利用同一样本的不同裁剪图像块的类别及概率的选择样本进行标注,并在三个不同的生物医学图像数据集上获得了良好的效果,然而由于病理图像不同的裁剪的图像往往属于不同的类别,因此该方法不适用于甲状腺癌病理图像分类.Yang et al[15]将全卷积神经网络与主动学习进行结合,通过对最有效的注释区域进行注释来显著减少注释工作量,在2015年MICCAI腺体分割数据集上获得了较好的分割结果. ...
Notice of removal:active learning for hyperspectral image classification with a stacked autoencoders based neural network
1
2016
... 近年来,由于深度学习的发展,主动学习与深度学习的研究[10-14]逐渐受到越来越多的重视.Wang and Shang[10]可能是第一次将主动学习与深度学习相结合,提出基于堆叠受限玻尔兹曼机和堆叠自动编码器的主动标记方法.Li[11]也将类似的方法应用于高光谱图像分类.Stark et al[12]利用主动学习提高基于CNNs的验证码识别性能,Al Rahhal et al[13]利用深度学习和主动学习进行心电图分类.Zhou et al[14]利用同一样本的不同裁剪图像块的类别及概率的选择样本进行标注,并在三个不同的生物医学图像数据集上获得了良好的效果,然而由于病理图像不同的裁剪的图像往往属于不同的类别,因此该方法不适用于甲状腺癌病理图像分类.Yang et al[15]将全卷积神经网络与主动学习进行结合,通过对最有效的注释区域进行注释来显著减少注释工作量,在2015年MICCAI腺体分割数据集上获得了较好的分割结果. ...
CAPTCHA recognition with active deep learning
1
2015
... 近年来,由于深度学习的发展,主动学习与深度学习的研究[10-14]逐渐受到越来越多的重视.Wang and Shang[10]可能是第一次将主动学习与深度学习相结合,提出基于堆叠受限玻尔兹曼机和堆叠自动编码器的主动标记方法.Li[11]也将类似的方法应用于高光谱图像分类.Stark et al[12]利用主动学习提高基于CNNs的验证码识别性能,Al Rahhal et al[13]利用深度学习和主动学习进行心电图分类.Zhou et al[14]利用同一样本的不同裁剪图像块的类别及概率的选择样本进行标注,并在三个不同的生物医学图像数据集上获得了良好的效果,然而由于病理图像不同的裁剪的图像往往属于不同的类别,因此该方法不适用于甲状腺癌病理图像分类.Yang et al[15]将全卷积神经网络与主动学习进行结合,通过对最有效的注释区域进行注释来显著减少注释工作量,在2015年MICCAI腺体分割数据集上获得了较好的分割结果. ...
Deep learning approach for active classification of electrocardiogram signals
1
2016
... 近年来,由于深度学习的发展,主动学习与深度学习的研究[10-14]逐渐受到越来越多的重视.Wang and Shang[10]可能是第一次将主动学习与深度学习相结合,提出基于堆叠受限玻尔兹曼机和堆叠自动编码器的主动标记方法.Li[11]也将类似的方法应用于高光谱图像分类.Stark et al[12]利用主动学习提高基于CNNs的验证码识别性能,Al Rahhal et al[13]利用深度学习和主动学习进行心电图分类.Zhou et al[14]利用同一样本的不同裁剪图像块的类别及概率的选择样本进行标注,并在三个不同的生物医学图像数据集上获得了良好的效果,然而由于病理图像不同的裁剪的图像往往属于不同的类别,因此该方法不适用于甲状腺癌病理图像分类.Yang et al[15]将全卷积神经网络与主动学习进行结合,通过对最有效的注释区域进行注释来显著减少注释工作量,在2015年MICCAI腺体分割数据集上获得了较好的分割结果. ...
Fine?tuning convolutional neural networks for biomedical image analysis:actively and incrementally
2
2017
... 近年来,由于深度学习的发展,主动学习与深度学习的研究[10-14]逐渐受到越来越多的重视.Wang and Shang[10]可能是第一次将主动学习与深度学习相结合,提出基于堆叠受限玻尔兹曼机和堆叠自动编码器的主动标记方法.Li[11]也将类似的方法应用于高光谱图像分类.Stark et al[12]利用主动学习提高基于CNNs的验证码识别性能,Al Rahhal et al[13]利用深度学习和主动学习进行心电图分类.Zhou et al[14]利用同一样本的不同裁剪图像块的类别及概率的选择样本进行标注,并在三个不同的生物医学图像数据集上获得了良好的效果,然而由于病理图像不同的裁剪的图像往往属于不同的类别,因此该方法不适用于甲状腺癌病理图像分类.Yang et al[15]将全卷积神经网络与主动学习进行结合,通过对最有效的注释区域进行注释来显著减少注释工作量,在2015年MICCAI腺体分割数据集上获得了较好的分割结果. ...
... [14]利用同一样本的不同裁剪图像块的类别及概率的选择样本进行标注,并在三个不同的生物医学图像数据集上获得了良好的效果,然而由于病理图像不同的裁剪的图像往往属于不同的类别,因此该方法不适用于甲状腺癌病理图像分类.Yang et al[15]将全卷积神经网络与主动学习进行结合,通过对最有效的注释区域进行注释来显著减少注释工作量,在2015年MICCAI腺体分割数据集上获得了较好的分割结果. ...
Suggestive annotation:a deep active learning framework for biomedical image segmentation
1
2017
... 近年来,由于深度学习的发展,主动学习与深度学习的研究[10-14]逐渐受到越来越多的重视.Wang and Shang[10]可能是第一次将主动学习与深度学习相结合,提出基于堆叠受限玻尔兹曼机和堆叠自动编码器的主动标记方法.Li[11]也将类似的方法应用于高光谱图像分类.Stark et al[12]利用主动学习提高基于CNNs的验证码识别性能,Al Rahhal et al[13]利用深度学习和主动学习进行心电图分类.Zhou et al[14]利用同一样本的不同裁剪图像块的类别及概率的选择样本进行标注,并在三个不同的生物医学图像数据集上获得了良好的效果,然而由于病理图像不同的裁剪的图像往往属于不同的类别,因此该方法不适用于甲状腺癌病理图像分类.Yang et al[15]将全卷积神经网络与主动学习进行结合,通过对最有效的注释区域进行注释来显著减少注释工作量,在2015年MICCAI腺体分割数据集上获得了较好的分割结果. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}