东巴文是一种原始的图画象形文字,源于纳西族的宗教典籍《东巴经》.由于这种文字由东巴(智者)所掌握,故称东巴文.东巴文至今已有一千多年的历史,约有1500个单字,其文字形态比甲骨文还要原始.2003年,我国纳西族东巴经典古籍被联合国教科文组织列为“世界记忆遗产”,采用数字化技术对东巴文进行整理归纳,有利于其文化传承.作为人类早期的一种图画文字向象形文字过渡的文字形式,东巴文结构复杂,字符类型众多、字形变化多样,而东巴古籍由众多东巴书写而成,各人书写风格的不同,更增加了识别难度.
在过去的几十年里,诸多学者对纳西族的东巴象形文字进行了深入的研究[1 -6 ] ,尤其是字符识别[7 -10 ] 更引起了科研人员的广泛关注.徐小力等[11 ] 将拓扑特征与投影法相结合提取东巴文字特征,再用模板匹配法进行文字识别,识别率达84.4%.吴国新等[12 ] 用特征点法和投影法进行特征提取,用相似法和神经网络反馈法进行东巴经典古籍象形文字智能识别,也获得了较高的识别率.王海燕等[13 ] 将拓扑特征和粗网格特征组合成新的特征,再利用支持向量机对东巴文字进行分类识别,也取得了不错的识别效果.近几年,深度学习技术得到飞速发展,广泛应用于文本处理、图像识别、广告推荐等领域.但由于目前收集到的东巴文图片样本较少,无法满足神经网络训练的要求,而常用的卷积神经网络结构(如循环神经网络(Recurrent Neural Network,RNN),Visual Geometry Group(VGG)等)往往需要大量的数据来训练模型.为了充分利用东巴文字固有的笔画特征,进一步提高东巴文的识别率,本文尝试引入方向梯度直方图(Histogram of Oriented Gradient,HOG)特征提取算法,并与支持向量机(Support Vector Machine,SVM)结合,进行东巴文的自动识别.
1 识别方法和流程
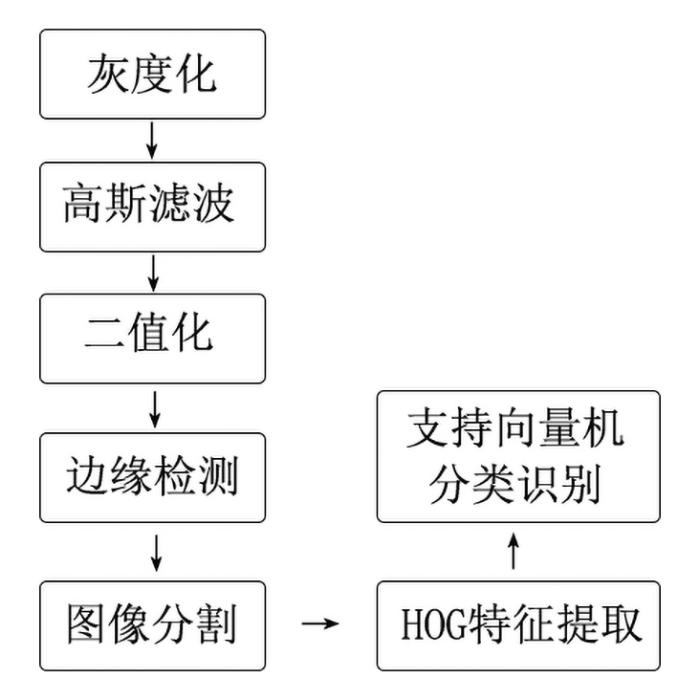
基于HOG特征提取和SVM分类相结合的东巴象形文字的识别包括图像采集、图像预处理、HOG特征提取和支持向量机分类识别四个步骤.识别流程如图1 所示.
图1
图1
本文对东巴文识别的流程图
Fig.1
The identification flowchart for the recognition of Dongba script
HOG特征提取算法[14 -15 ] 能提取图像X 和Y 方向的梯度信息,对图像中的边缘、拐点等梯度变化大的地方更敏感,因此能更好地捕捉文字的线条变化来提取该类文字特有的特征向量.SVM是在统计学基础上发展起来的一种模式识别方法[16 ] ,在人脸识别、手写字符识别、文本分类、生物信息学等领域得到广泛应用.本文将HOG与SVM相结合,不仅提高了识别率,而且识别过程简单快速.
2 图像预处理
用手机拍摄含有东巴文的图片,文字样本来源于《纳西象形文字谱》.选取200个常用的东巴象形文字符,每种文字采集10个样本.采集图像的过程中受光照、设备等影响,往往会产生极大的噪声,所以必须对图像进行预处理.步骤如下:
(1)灰度化.将彩色图像的三个分量RGB进行加权平均,去除图像的颜色信息,只含亮度信息,从而把三通道的彩色图像转化成一通道的灰度图像,在保留图像原始信息的同时还可以降低运算量.人眼对颜色的敏感度最高的是绿色,最低的是蓝色,因此按式(1)对输入的彩色图像进行灰度化处理:
G r a y i , j = 0.299 × R i , j + 0.578 × G i , j + 0.114 × B i , j (1)
(2)高斯模糊.高斯模糊也叫高斯平滑,将高斯分布应用于图像处理,可以起到模糊去噪、减少毛刺、增粗笔迹的作用.把中心像素点作为原点,即有最大的高斯分布值;其他点按照高斯分布曲线上的位置来分配权重,得到加权平均值代替中心值,这样可以更好地保留边缘效果.选用不同大小的高斯核进行图像预处理,结果表明,3×3高斯核更多地保留了文字的原始信息,而5×5和7×7高斯核在处理过程中容易丢失文字信息.故本文取3×3大小的高斯核,高斯分布标准差为10,进行高斯模糊.
(3)二值化.图像的二值化,就是将图像像素值设置为0或255,使整个图像呈现非黑即白的视觉效果.最大类间方差法(OTSU)能够很好地利用图像的灰度特性,将图像划分为前景和背景两类.其原理是通过遍历计算类间方差,类间方差最大时对应的阈值即为所求.将大于此阈值的像素值设为255(或0),将小于此阈值的像素值设为0(或255),从而实现图像的二值化.
(4)边缘检测.边缘检测可以捕捉图像中灰度值变化剧烈的像素点,边缘往往存在于背景和前景之间,对二值化后的图像进行边缘检测能够很好地提取文字轮廓,有利于后续高效高质量地提取文字的HOG特征,从而大幅减少计算量.本文分别用Roberts,Sobel,Prewitt,Canny,LOG算子进行边缘检测,并研究不同的边缘检测算子对东巴文识别效果的影响.
(5)图像分割.按照文字边缘进行裁切,分割出文字部分,减少无用信息.
手机拍摄的东巴文的原始图片如图2 所示,经过以上五个步骤处理后的图片如图3 所示.
图2
图2
预处理前的图片
Fig.2
An image before preprocessing
图3
图3
预处理后的图片
Fig.3
The image of Fig.2 after preprocessing
3 HOG特征提取
HOG特征提取的核心思想是所检测的局部物体外形能被光强梯度或边缘方向的分布描述.该算法提取图像X 和Y 方向的梯度信息,因此对于文字的线条变化(如边缘、拐角等)更敏感,能很好地描述文字特征.HOG特征提取的步骤如下:
(1)计算梯度.计算图像水平和竖直方向的梯度,首先用梯度算子- 1,0 , 1 - 1,0 , 1 T X ,Y 方向的梯度分量g x g y 式(2)和式(3)得到像素点(x ,y )处的梯度大小g 和方向角θ :
g = g x 2 + g y 2 (2)
θ = a r c t a n g y g x (3)
(2)构建每个细胞单元的梯度方向直方图.分别用4×4,8×8,16×16,32×32大小的细胞(cell)单元对预处理后的64×128东巴文图像进行分类识别,实验结果如表1 所示.
上述数据表明,4×4和8×8的cell单元识别率较高且相差不大,但是4×4 cell对应的特征向量维数显著高于8×8 cell,算法平均运行时间约为8×8 cell的五倍,所以本文选取8×8 cell进行HOG特征提取.构建8×8 cell的梯度方向直方图的步骤如下:将64×128大小的图像分割成若干个不重叠的8×8细胞单元(cell),用步骤(1)计算8×8 cell中的每个像素点的梯度大小和方向;将0~180°以20°为一个区间进行划分,九个bin分别对应0°,20°,…,180°;根据像素的梯度方向选择bin,幅值即bin的大小;线性插值把8×8 cell的所有像素点都投入九个bin中,就构建了一个cell的9 bin直方图,即每个cell对应一个九维向量.
(3)16×16 block归一化.由于一个cell的梯度对于整张图片的光线都很敏感且cell边缘的像素点会对其周围的cell产生影响,所以把局部直方图在更大的区域内(16×16 block)进行归一化,归一化后能对光线和阴影变化获得更好的效果.一个block由2×2个cell组成,因此,一个block包含四个9 bin直方图,归一化后形成一个36维向量.用16×16的窗口以8为步长遍历整张图像.
(4)生成HOG特征向量.计算图像所有block的HOG特征向量,合并成一个更大的向量.由于
64 8 - 1 × 128 8 - 1 × 4 × 9 = 3780
因此,一个64×128大小的图像可以生成一个3780维的HOG特征向量.
图4
图4
HOG特征提取后的图像
Fig.4
The image of Fig.2 after HOG feature extraction
4 SVM分类识别
SVM是机器学习领域的一个非常关键的方法.其核心思想是从输入空间向一个更高维度的特征空间(Feature Space)做映射,通常认为需要解决的问题在特征空间会被简化,变得线性可分.SVM本质是一个线性分类器,定义超平面公式为:
y = w T x + b (4)
y i w T x + b > 0 (5)
由点到平面的距离为w T x + b w x i y i w T x i + b w . 考虑y i x i γ i 式(6)所示:
γ i = y i w w • x i + b w (6)
几何间隔最大时的超平面即为所求,此时转化为一个凸二次规划问题,如式(7)所示:
m i n w , b 1 2 w 2 s . t . y i w i x + b - 1 ≥ 0 , i = 1,2 , ⋯ , N (7)
求出最优解w * , b * w * ⋅ x + b * = 0 . 首先添加拉格朗日乘子α i ≥ 0 式(8)所示:
L w , b , α = 1 2 w 2 + ∑ i = 1 m α i 1 - y i w T x i + b (8)
其次,根据强对偶关系和KKT条件可产生原问题的对偶问题,目标函数转化为m a x α i ≥ 0 m i n w , b L w , b , α L w , b , α w , b α w * , b * f x = s i g n w * ⋅ x + b * .
以上是用SVM对两类样本进行线性分类,通过引入核方法可将SVM用于非线性分类,即把输入空间向高维度的特征空间做映射时,使用非线性函数.要解决多分类问题,可以采取两种方法.假设有N 个类,第一种方法是在每两类之间构造一个二分类器,组成一个共N × N - 1 2 N 类的多分类器.本文采用后者,利用Matlab 2015 a自带的fitcecoc函数进行东巴文的分类识别.
5 实验过程及结果分析
实验电脑配置:Windows 10操作系统,8 GB内存,CPU 2.50 GHz,Matlab 2015 a.选取200个常用的东巴象形文字,每种文字采集10个样本,形成共2000个字的数据集,其中20%作为测试集,80%作为训练集.
实验具体步骤:(1)对数据集进行灰度化、高斯滤波、二值化、边缘检测,最后分割出文字部分,并resize图片大小为64×128.之后,给所有数据集打标签.(2)取8×8 cell,16×16 block,窗口移动步长为8,对数据集进行HOG特征提取,得到2000个3780维的特征向量.(3)打乱数据集,随机选取其中1600个作为训练集,400个作为测试集,生成X _train,Y _train,X _test,Y _test四个mat文件,其中X _train,Y _train是训练集及其标签,X _test,Y _test是测试集及其标签.利用Matlab自带的fitcecoc函数训练分类模型,分类方式选择onevsall,学习器设置为SVM.将测试集和训练好的模型作为参数,用predict函数得到测试集的预测值y _predict.识别率为正确识别个数和预测东巴字总个数的比值.
5.1 不同边缘检测算子识别性能分析
为了探究不同的边缘检测算子在东巴文识别中的效果,在实验过程中采用不同的边缘检测算子,每组测试10次,实验得到的结果如表2 所示.
从表2 可以看出,在本文的识别流程下,Roberts算子优于其他算子,识别率最高,达到97.60%.Sobel和Prewitt算子识别率相对较低,大约为96%.Roberts算子是2×2算子模板,利用图像的局部差分寻找边缘,将梯度幅值近似为对角线的两个相邻像素之差,显然,Roberts 算子更适合噪声较小且边缘明显的图像分割.Sobel算子和Prewitt算子都是3×3模板的一阶微分算子,在边缘检测之前,已经采用3×3的高斯核对图像进行滤波,所以再次用3×3的边缘算子对图像卷积,可能会丢失边缘的方向信息,造成边缘定位不准确,降低了识别率.
5.2 不同特征提取算法识别性能分析
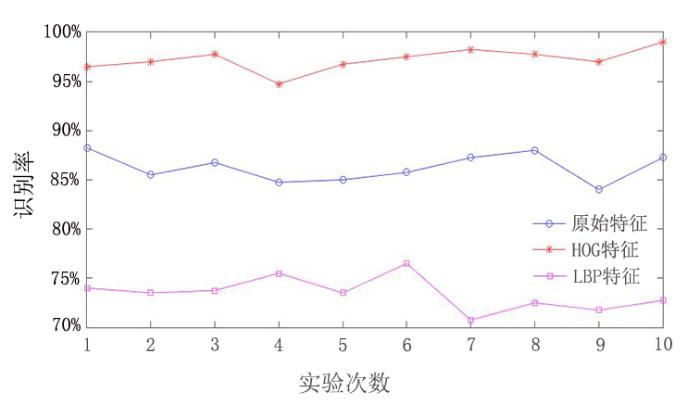
采用不同的特征提取算法提取东巴文特征向量,之后输入支持向量机进行分类识别.实验分别提取图像的原始特征(64×128维特征向量)、HOG特征、局部二值模式(Local Binary Patterns,LBP)特征,10次实验结果如图5 所示.
图5
图5
不同特征提取算法的识别率对比
Fig.5
Recognition rates of different feature extraction algorithms
由图5 可知,采用原始特征对东巴象形文字进行分类识别时,平均识别率为86.15%;LBP特征的识别率最低,为73.45%;HOG特征提取算法识别率显著高于原始特征及LBP特征,为97.23%.说明在本文识别流程及数据特点下,HOG+SVM更适合东巴象形文字的分类识别.
5.3 不同分类器识别性能分析
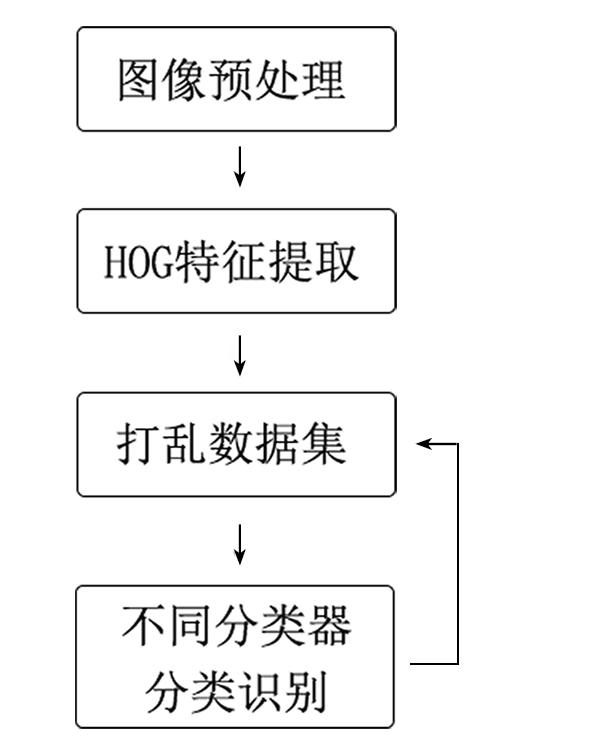
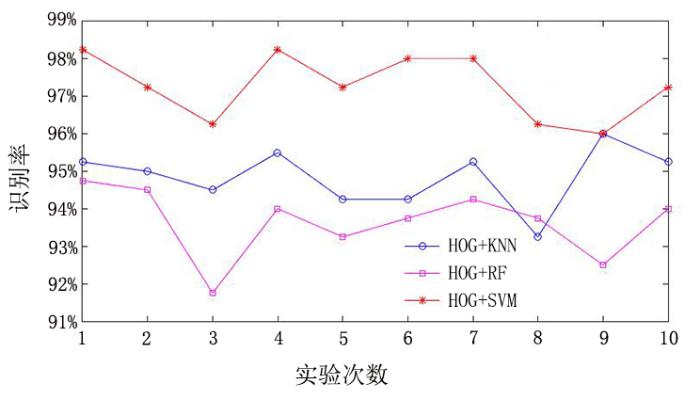
在图像预处理中采用Roberts算子进行边缘检测;打乱HOG特征提取后的数据集,并随机选取80%作为训练集,20%作为测试集;对每次随机生成的东巴文样本分别用SVM,K最近邻分类器(K⁃Nearest Neighbor,KNN)以及随机森林(Random Forests,RF)进行分类识别.完整的实验过程如图6 所示,图7 为不同分类器的10次实验结果对比图.
图6
图6
不同分类器识别实验的流程图
Fig.6
The flowchart of different classifier recognition experiments
图7
图7
不同分类器的识别率对比
Fig.7
Recognition rates of different classifiers
实验结果表明,HOG与KNN,RF和SVM分类器分别结合均能取得不错的识别效果.10次实验结果的平均识别率:HOG+KNN为94.85%,HOG+RF为93.65%,HOG+SVM识别率最高,达97.28%.为了进一步探究不同分类器在东巴文识别中的效果,使用十折交叉验证法,并计算10次十折交叉验证的识别准确率的均值和标准差,得到如表3 所示的实验结果.可以看出,与其他两种模型相比,HOG+SVM的准确性及稳定性更高,更适合东巴象形文字识别.
综合以上实验的的识别结果,HOG+SVM的识别率为97.42%.
6 结 论
本文提出一种基于HOG和SVM的东巴文识别方法,经实验测试表明,在文字识别之前进行充分的图像预处理,能够大幅提升东巴文的识别率.通过实验对比,发现Roberts算子比其他边缘检测算子更适合东巴文的识别,能够将识别率提高近1%.将HOG特征提取算法和支持向量机结合,比其他特征提取算法及分类器模型的识别精度更高、效果更好,准确率达97.42%,实现了对东巴文的高效准确识别.
但受条件所限,本文使用的数据集规模还比较小,后续将收集更多的古籍资料,进一步扩大样本数量,建立来源更为广泛的手写数据库,优化HOG特征提取及SVM模型参数,提高算法的泛化能力,最终实现对全部东巴文字手写数据的高效准确识别.
参考文献
View Option
[1]
郑丽萍 活着的象形文字——纳西东巴图画文字
艺术与设计(理论) ,2009 (12 ):311 -313 . (Zheng L P. The living hieroglyphs,the pictures and Characters of Naxi Dongba. Art and Design,2009(12):311-313.)
[本文引用: 1]
[2]
张志宏 国家非物质文化遗产保护与传承依托研究——以纳西东巴画为例
大众文艺 ,2013 (22 ):9 -10 .
[3]
胡莹 档案学视野下的东巴古籍文献遗产保护研究
档案学通讯 ,2015 (2 ):65 -67 .
[4]
和继全 东巴文百年研究与反思
.思想战线 ,2011 ,37 (05 ):34 -41 .
[5]
白庚胜 纳西学丛书 (共30卷) . 北京 :民族出版社 ,2008 ,507 .
[6]
方国瑜 方国瑜纳西学论集 . 北京 :民族出版社 ,2008 ,236 .
[本文引用: 1]
[7]
Zhang Y Zhou M L Wang Q H Interactions of stimulus quality and frequency on N400 in Chinese character recognition:evidence for cascaded processing
Neuroscience Letters ,2020 ,715 :134614 .
[本文引用: 1]
[8]
Gan J Wang W Q Lu K Compressing the CNN architecture for in⁃air handwritten Chinese character recognition
Pattern Recognition Letters ,2020 ,129 :190 -197 .
[9]
Lee Y H Song H T Suh J S Quantitative computed tomography (QCT) as a radiology reporting tool by using optical character recognition (OCR) and macro program
Journal of Digital Imaging ,2012 ,25 (6 ):815 -818 .
[10]
Li L Zhang L L Su J F Handwritten character recognition via direction string and nearest neighbor matching
The Journal of China Universities of Posts and Telecommunications ,2012 ,19 (S2 ):160 -165 ,196 .
[本文引用: 1]
[11]
徐小力 ,蒋章雷 ,吴国新 等 基于拓扑特征和投影法的东巴象形文识别方法研究
电子测量与仪器学报 ,2017 ,31 (1 ):150 -154 .
[本文引用: 1]
Xu X L Jiang Z L Wu G X et al Identification method of Dongba pictograph based on topological characteristic and projection method
Journal of Electronic Measurement and Instrumentation ,2017 ,31 (1 ):150 -154 .
[本文引用: 1]
[12]
吴国新 ,丁春艳 ,徐小力 等 东巴经典古籍象形文字智能识别研究
电子测量与仪器学报 ,2016 ,30 (11 ):1774 -1779 .
[本文引用: 1]
Wu G X Ding C Y Xu X L et al Intelligent recognition on Dongba manuscripts hieroglyphs
Journal of Electronic Measurement and Instrumentation ,2016 ,30 (11 ):1774 -1779 .
[本文引用: 1]
[13]
王海燕 ,王红军 ,徐小力 基于支持向量机的纳西东巴象形文字符识别
云南大学学报(自然科学版) ,2016 ,38 (5 ):730 -736 .
[本文引用: 1]
Wang H Y Wang H J Xu X L Recognition of Naxi Dongba pictographs based on support vector machine
Journal of Yunnan University (Natural Sciences Edition) ,2016 ,38 (5 ):730 -736 .
[本文引用: 1]
[14]
Hosotani D Yoda I Sakaue K Wheelchair recognition by using stereo vision and histogram of oriented gradients (HOG) in real environments
∥2009 Workshop on Applications of Computer Vision (WACV) . Snowbird,UT,USA :IEEE ,2009 ,doi:10.1109/WACV.2009.5403043 .
[本文引用: 1]
[15]
Reichman D Collins L Malof J M Learning improved pooling regions for the Histogram of Oriented Gradient (HOG) feature for buried threat detection in ground penetrating radar
∥Proceedings of SPIE 10182 ,Detection and Sensing of Mines,Explosive Objects,and Obscured Targets XXII ,2017 ,doi:10.1117/12.2263108 .
[本文引用: 1]
[16]
Huang ,J ,Shao ,X ,Wechsler ,H Face pose discrimination using support vector machines (SVM)∥Proceedings of the 14th International Conference on Pattern Recognition . Brisbane,Australia :IEEE ,1998 ,doi:10.1109/ICPR.1998.711102 .
[本文引用: 1]
(Zheng L P. The living hieroglyphs,the pictures and Characters of Naxi Dongba. Art and Design,2009(12):311-313.)
1
... 在过去的几十年里,诸多学者对纳西族的东巴象形文字进行了深入的研究[1 -6 ] ,尤其是字符识别[7 -10 ] 更引起了科研人员的广泛关注.徐小力等[11 ] 将拓扑特征与投影法相结合提取东巴文字特征,再用模板匹配法进行文字识别,识别率达84.4%.吴国新等[12 ] 用特征点法和投影法进行特征提取,用相似法和神经网络反馈法进行东巴经典古籍象形文字智能识别,也获得了较高的识别率.王海燕等[13 ] 将拓扑特征和粗网格特征组合成新的特征,再利用支持向量机对东巴文字进行分类识别,也取得了不错的识别效果.近几年,深度学习技术得到飞速发展,广泛应用于文本处理、图像识别、广告推荐等领域.但由于目前收集到的东巴文图片样本较少,无法满足神经网络训练的要求,而常用的卷积神经网络结构(如循环神经网络(Recurrent Neural Network,RNN),Visual Geometry Group(VGG)等)往往需要大量的数据来训练模型.为了充分利用东巴文字固有的笔画特征,进一步提高东巴文的识别率,本文尝试引入方向梯度直方图(Histogram of Oriented Gradient,HOG)特征提取算法,并与支持向量机(Support Vector Machine,SVM)结合,进行东巴文的自动识别. ...
国家非物质文化遗产保护与传承依托研究——以纳西东巴画为例
0
2013
档案学视野下的东巴古籍文献遗产保护研究
0
2015
1
2008
... 在过去的几十年里,诸多学者对纳西族的东巴象形文字进行了深入的研究[1 -6 ] ,尤其是字符识别[7 -10 ] 更引起了科研人员的广泛关注.徐小力等[11 ] 将拓扑特征与投影法相结合提取东巴文字特征,再用模板匹配法进行文字识别,识别率达84.4%.吴国新等[12 ] 用特征点法和投影法进行特征提取,用相似法和神经网络反馈法进行东巴经典古籍象形文字智能识别,也获得了较高的识别率.王海燕等[13 ] 将拓扑特征和粗网格特征组合成新的特征,再利用支持向量机对东巴文字进行分类识别,也取得了不错的识别效果.近几年,深度学习技术得到飞速发展,广泛应用于文本处理、图像识别、广告推荐等领域.但由于目前收集到的东巴文图片样本较少,无法满足神经网络训练的要求,而常用的卷积神经网络结构(如循环神经网络(Recurrent Neural Network,RNN),Visual Geometry Group(VGG)等)往往需要大量的数据来训练模型.为了充分利用东巴文字固有的笔画特征,进一步提高东巴文的识别率,本文尝试引入方向梯度直方图(Histogram of Oriented Gradient,HOG)特征提取算法,并与支持向量机(Support Vector Machine,SVM)结合,进行东巴文的自动识别. ...
Interactions of stimulus quality and frequency on N400 in Chinese character recognition:evidence for cascaded processing
1
2020
... 在过去的几十年里,诸多学者对纳西族的东巴象形文字进行了深入的研究[1 -6 ] ,尤其是字符识别[7 -10 ] 更引起了科研人员的广泛关注.徐小力等[11 ] 将拓扑特征与投影法相结合提取东巴文字特征,再用模板匹配法进行文字识别,识别率达84.4%.吴国新等[12 ] 用特征点法和投影法进行特征提取,用相似法和神经网络反馈法进行东巴经典古籍象形文字智能识别,也获得了较高的识别率.王海燕等[13 ] 将拓扑特征和粗网格特征组合成新的特征,再利用支持向量机对东巴文字进行分类识别,也取得了不错的识别效果.近几年,深度学习技术得到飞速发展,广泛应用于文本处理、图像识别、广告推荐等领域.但由于目前收集到的东巴文图片样本较少,无法满足神经网络训练的要求,而常用的卷积神经网络结构(如循环神经网络(Recurrent Neural Network,RNN),Visual Geometry Group(VGG)等)往往需要大量的数据来训练模型.为了充分利用东巴文字固有的笔画特征,进一步提高东巴文的识别率,本文尝试引入方向梯度直方图(Histogram of Oriented Gradient,HOG)特征提取算法,并与支持向量机(Support Vector Machine,SVM)结合,进行东巴文的自动识别. ...
Compressing the CNN architecture for in?air handwritten Chinese character recognition
0
2020
Quantitative computed tomography (QCT) as a radiology reporting tool by using optical character recognition (OCR) and macro program
0
2012
Handwritten character recognition via direction string and nearest neighbor matching
1
2012
... 在过去的几十年里,诸多学者对纳西族的东巴象形文字进行了深入的研究[1 -6 ] ,尤其是字符识别[7 -10 ] 更引起了科研人员的广泛关注.徐小力等[11 ] 将拓扑特征与投影法相结合提取东巴文字特征,再用模板匹配法进行文字识别,识别率达84.4%.吴国新等[12 ] 用特征点法和投影法进行特征提取,用相似法和神经网络反馈法进行东巴经典古籍象形文字智能识别,也获得了较高的识别率.王海燕等[13 ] 将拓扑特征和粗网格特征组合成新的特征,再利用支持向量机对东巴文字进行分类识别,也取得了不错的识别效果.近几年,深度学习技术得到飞速发展,广泛应用于文本处理、图像识别、广告推荐等领域.但由于目前收集到的东巴文图片样本较少,无法满足神经网络训练的要求,而常用的卷积神经网络结构(如循环神经网络(Recurrent Neural Network,RNN),Visual Geometry Group(VGG)等)往往需要大量的数据来训练模型.为了充分利用东巴文字固有的笔画特征,进一步提高东巴文的识别率,本文尝试引入方向梯度直方图(Histogram of Oriented Gradient,HOG)特征提取算法,并与支持向量机(Support Vector Machine,SVM)结合,进行东巴文的自动识别. ...
基于拓扑特征和投影法的东巴象形文识别方法研究
1
2017
... 在过去的几十年里,诸多学者对纳西族的东巴象形文字进行了深入的研究[1 -6 ] ,尤其是字符识别[7 -10 ] 更引起了科研人员的广泛关注.徐小力等[11 ] 将拓扑特征与投影法相结合提取东巴文字特征,再用模板匹配法进行文字识别,识别率达84.4%.吴国新等[12 ] 用特征点法和投影法进行特征提取,用相似法和神经网络反馈法进行东巴经典古籍象形文字智能识别,也获得了较高的识别率.王海燕等[13 ] 将拓扑特征和粗网格特征组合成新的特征,再利用支持向量机对东巴文字进行分类识别,也取得了不错的识别效果.近几年,深度学习技术得到飞速发展,广泛应用于文本处理、图像识别、广告推荐等领域.但由于目前收集到的东巴文图片样本较少,无法满足神经网络训练的要求,而常用的卷积神经网络结构(如循环神经网络(Recurrent Neural Network,RNN),Visual Geometry Group(VGG)等)往往需要大量的数据来训练模型.为了充分利用东巴文字固有的笔画特征,进一步提高东巴文的识别率,本文尝试引入方向梯度直方图(Histogram of Oriented Gradient,HOG)特征提取算法,并与支持向量机(Support Vector Machine,SVM)结合,进行东巴文的自动识别. ...
基于拓扑特征和投影法的东巴象形文识别方法研究
1
2017
... 在过去的几十年里,诸多学者对纳西族的东巴象形文字进行了深入的研究[1 -6 ] ,尤其是字符识别[7 -10 ] 更引起了科研人员的广泛关注.徐小力等[11 ] 将拓扑特征与投影法相结合提取东巴文字特征,再用模板匹配法进行文字识别,识别率达84.4%.吴国新等[12 ] 用特征点法和投影法进行特征提取,用相似法和神经网络反馈法进行东巴经典古籍象形文字智能识别,也获得了较高的识别率.王海燕等[13 ] 将拓扑特征和粗网格特征组合成新的特征,再利用支持向量机对东巴文字进行分类识别,也取得了不错的识别效果.近几年,深度学习技术得到飞速发展,广泛应用于文本处理、图像识别、广告推荐等领域.但由于目前收集到的东巴文图片样本较少,无法满足神经网络训练的要求,而常用的卷积神经网络结构(如循环神经网络(Recurrent Neural Network,RNN),Visual Geometry Group(VGG)等)往往需要大量的数据来训练模型.为了充分利用东巴文字固有的笔画特征,进一步提高东巴文的识别率,本文尝试引入方向梯度直方图(Histogram of Oriented Gradient,HOG)特征提取算法,并与支持向量机(Support Vector Machine,SVM)结合,进行东巴文的自动识别. ...
东巴经典古籍象形文字智能识别研究
1
2016
... 在过去的几十年里,诸多学者对纳西族的东巴象形文字进行了深入的研究[1 -6 ] ,尤其是字符识别[7 -10 ] 更引起了科研人员的广泛关注.徐小力等[11 ] 将拓扑特征与投影法相结合提取东巴文字特征,再用模板匹配法进行文字识别,识别率达84.4%.吴国新等[12 ] 用特征点法和投影法进行特征提取,用相似法和神经网络反馈法进行东巴经典古籍象形文字智能识别,也获得了较高的识别率.王海燕等[13 ] 将拓扑特征和粗网格特征组合成新的特征,再利用支持向量机对东巴文字进行分类识别,也取得了不错的识别效果.近几年,深度学习技术得到飞速发展,广泛应用于文本处理、图像识别、广告推荐等领域.但由于目前收集到的东巴文图片样本较少,无法满足神经网络训练的要求,而常用的卷积神经网络结构(如循环神经网络(Recurrent Neural Network,RNN),Visual Geometry Group(VGG)等)往往需要大量的数据来训练模型.为了充分利用东巴文字固有的笔画特征,进一步提高东巴文的识别率,本文尝试引入方向梯度直方图(Histogram of Oriented Gradient,HOG)特征提取算法,并与支持向量机(Support Vector Machine,SVM)结合,进行东巴文的自动识别. ...
东巴经典古籍象形文字智能识别研究
1
2016
... 在过去的几十年里,诸多学者对纳西族的东巴象形文字进行了深入的研究[1 -6 ] ,尤其是字符识别[7 -10 ] 更引起了科研人员的广泛关注.徐小力等[11 ] 将拓扑特征与投影法相结合提取东巴文字特征,再用模板匹配法进行文字识别,识别率达84.4%.吴国新等[12 ] 用特征点法和投影法进行特征提取,用相似法和神经网络反馈法进行东巴经典古籍象形文字智能识别,也获得了较高的识别率.王海燕等[13 ] 将拓扑特征和粗网格特征组合成新的特征,再利用支持向量机对东巴文字进行分类识别,也取得了不错的识别效果.近几年,深度学习技术得到飞速发展,广泛应用于文本处理、图像识别、广告推荐等领域.但由于目前收集到的东巴文图片样本较少,无法满足神经网络训练的要求,而常用的卷积神经网络结构(如循环神经网络(Recurrent Neural Network,RNN),Visual Geometry Group(VGG)等)往往需要大量的数据来训练模型.为了充分利用东巴文字固有的笔画特征,进一步提高东巴文的识别率,本文尝试引入方向梯度直方图(Histogram of Oriented Gradient,HOG)特征提取算法,并与支持向量机(Support Vector Machine,SVM)结合,进行东巴文的自动识别. ...
基于支持向量机的纳西东巴象形文字符识别
1
2016
... 在过去的几十年里,诸多学者对纳西族的东巴象形文字进行了深入的研究[1 -6 ] ,尤其是字符识别[7 -10 ] 更引起了科研人员的广泛关注.徐小力等[11 ] 将拓扑特征与投影法相结合提取东巴文字特征,再用模板匹配法进行文字识别,识别率达84.4%.吴国新等[12 ] 用特征点法和投影法进行特征提取,用相似法和神经网络反馈法进行东巴经典古籍象形文字智能识别,也获得了较高的识别率.王海燕等[13 ] 将拓扑特征和粗网格特征组合成新的特征,再利用支持向量机对东巴文字进行分类识别,也取得了不错的识别效果.近几年,深度学习技术得到飞速发展,广泛应用于文本处理、图像识别、广告推荐等领域.但由于目前收集到的东巴文图片样本较少,无法满足神经网络训练的要求,而常用的卷积神经网络结构(如循环神经网络(Recurrent Neural Network,RNN),Visual Geometry Group(VGG)等)往往需要大量的数据来训练模型.为了充分利用东巴文字固有的笔画特征,进一步提高东巴文的识别率,本文尝试引入方向梯度直方图(Histogram of Oriented Gradient,HOG)特征提取算法,并与支持向量机(Support Vector Machine,SVM)结合,进行东巴文的自动识别. ...
基于支持向量机的纳西东巴象形文字符识别
1
2016
... 在过去的几十年里,诸多学者对纳西族的东巴象形文字进行了深入的研究[1 -6 ] ,尤其是字符识别[7 -10 ] 更引起了科研人员的广泛关注.徐小力等[11 ] 将拓扑特征与投影法相结合提取东巴文字特征,再用模板匹配法进行文字识别,识别率达84.4%.吴国新等[12 ] 用特征点法和投影法进行特征提取,用相似法和神经网络反馈法进行东巴经典古籍象形文字智能识别,也获得了较高的识别率.王海燕等[13 ] 将拓扑特征和粗网格特征组合成新的特征,再利用支持向量机对东巴文字进行分类识别,也取得了不错的识别效果.近几年,深度学习技术得到飞速发展,广泛应用于文本处理、图像识别、广告推荐等领域.但由于目前收集到的东巴文图片样本较少,无法满足神经网络训练的要求,而常用的卷积神经网络结构(如循环神经网络(Recurrent Neural Network,RNN),Visual Geometry Group(VGG)等)往往需要大量的数据来训练模型.为了充分利用东巴文字固有的笔画特征,进一步提高东巴文的识别率,本文尝试引入方向梯度直方图(Histogram of Oriented Gradient,HOG)特征提取算法,并与支持向量机(Support Vector Machine,SVM)结合,进行东巴文的自动识别. ...
Wheelchair recognition by using stereo vision and histogram of oriented gradients (HOG) in real environments
1
2009
... HOG特征提取算法[14 -15 ] 能提取图像X 和Y 方向的梯度信息,对图像中的边缘、拐点等梯度变化大的地方更敏感,因此能更好地捕捉文字的线条变化来提取该类文字特有的特征向量.SVM是在统计学基础上发展起来的一种模式识别方法[16 ] ,在人脸识别、手写字符识别、文本分类、生物信息学等领域得到广泛应用.本文将HOG与SVM相结合,不仅提高了识别率,而且识别过程简单快速. ...
Learning improved pooling regions for the Histogram of Oriented Gradient (HOG) feature for buried threat detection in ground penetrating radar
1
2017
... HOG特征提取算法[14 -15 ] 能提取图像X 和Y 方向的梯度信息,对图像中的边缘、拐点等梯度变化大的地方更敏感,因此能更好地捕捉文字的线条变化来提取该类文字特有的特征向量.SVM是在统计学基础上发展起来的一种模式识别方法[16 ] ,在人脸识别、手写字符识别、文本分类、生物信息学等领域得到广泛应用.本文将HOG与SVM相结合,不仅提高了识别率,而且识别过程简单快速. ...
1
1998
... HOG特征提取算法[14 -15 ] 能提取图像X 和Y 方向的梯度信息,对图像中的边缘、拐点等梯度变化大的地方更敏感,因此能更好地捕捉文字的线条变化来提取该类文字特有的特征向量.SVM是在统计学基础上发展起来的一种模式识别方法[16 ] ,在人脸识别、手写字符识别、文本分类、生物信息学等领域得到广泛应用.本文将HOG与SVM相结合,不仅提高了识别率,而且识别过程简单快速. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}