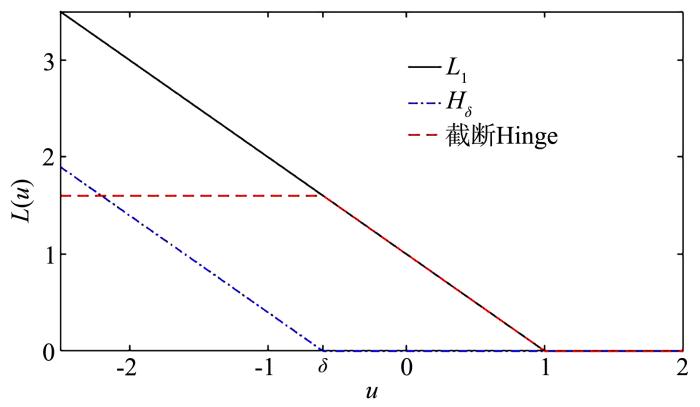
截断Hinge损失能够获得更为稀疏的支持向量,因此在鲁棒性上有显著的优点,但却由此导致了难以求解的非凸问题.MM(Majorization⁃Minimization)是一种求解非凸问题的一般框架,多阶段MM策略已经在稀疏性上取得了很好的效果,但是计算复杂度较高.另一方面,非精确线搜割平面方法可以高效求解线性支持向量机问题.针对截断L1⁃SVM(L1 Support Vector Machine)这一非凸非光滑问题,提出一种基于非精确线性搜索的多阶段割平面方法,避免每个阶段都进行批处理求解,克服了计算复杂度高的缺点,具有每个阶段求解速度快的优点.该算法适用于大规模问题的求解,也从理论上保证了其收敛性.最后,与其他多阶段算法进行了实验对比,验证了该方法的有效性.
关键词:截断Hinge损失
;
非凸优化
;
多阶段策略
;
非精确线性搜索
Abstract
The truncated Hinge loss can get more sparse support vectors,thus it has significant advantages in robustness. But it leads to a non⁃convex problem which is difficult to solve. MM (Majorization⁃Minimization) is a general framework and is suitable for solving non⁃convex problems. The specific multi⁃stage MM strategy has a good effect in sparsity for the non⁃convex problem considering the structure of the objective function,but higher computational complexity is caused. On the other hand,a cutting plane method with inexact line search can efficiently solve linear support vector machines,and the theoretical analysis shows that it has the same optimal convergence bound as the exact line search method with a higher speed and lower cost. In this paper,for the truncated L1⁃SVM (L1 Support Vector Machine) which is non⁃convex and non⁃smooth,we propose a multi⁃stage cutting plane method with inexact line search. It avoids solving the problem by a batch method at each stage,which overcomes the shortcoming of high computational complexity. Meanwhile,there is an advantage that a faster solution can be got at each stage. The algorithm is suitable for solving large⁃scale problems and it is convergent in theory. Finally,comparison experiments with other multi⁃stage algorithm demonstrate that our method is effective.
Keywords:truncated Hinge loss
;
non⁃convex optimization
;
multi⁃stage strategy
;
inexact line search
Yuan Youhong, Liu Xin, Bao Lei. A multi⁃stage cutting plane method with inexact line search forsolving non⁃convex truncated L1⁃SVMs. Journal of nanjing University[J], 2020, 56(1): 98-106 doi:10.13232/j.cnki.jnju.2020.01.011
SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想.
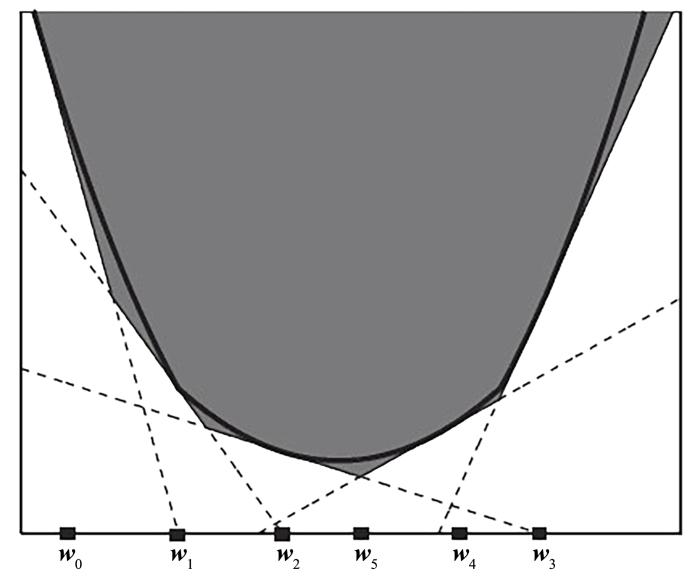
还有很多可以高效求解线性SVM的算法,如割平面算法、Pegasos算法[19].Joachims[20]在2006年引入割平面算法来解决线性SVM问题,并证明了算法的收敛性.后来Teo et al[21]将其推广为求解一般正则化损失函数的方法,但在处理实际问题时,割平面算法的性能未能得到充分发挥,并且不能保证主问题单调下降.2008年,Franc and Sonnenburg[22]在此基础上提出优化割平面算法(Optimized Cutting Plane Algorithm,OCAS),在每次迭代过程中,对优化变量w进行精确线性搜索,使目标函数单调下降且保证算法收敛.最近,Chu et al[23]提出一种加速精确线性搜索割平面算法,比Pegasos算法的求解速度更快.2014年储德军等[24]提出一种非精确线性搜索割平面算法,对非光滑目标函数进行了收敛性分析,能保证目标函数单调下降,并且每次迭代都采用非精确线性搜索,使时间消耗大大降低.本文分析表明,这种方法的计算复杂度低于加速精确线性搜索割平面算法.
Fig.2
Piecewise linear approximation for convex function
OCAS算法在每次求得后,关键是进行一次精确线性搜索,如式(9):
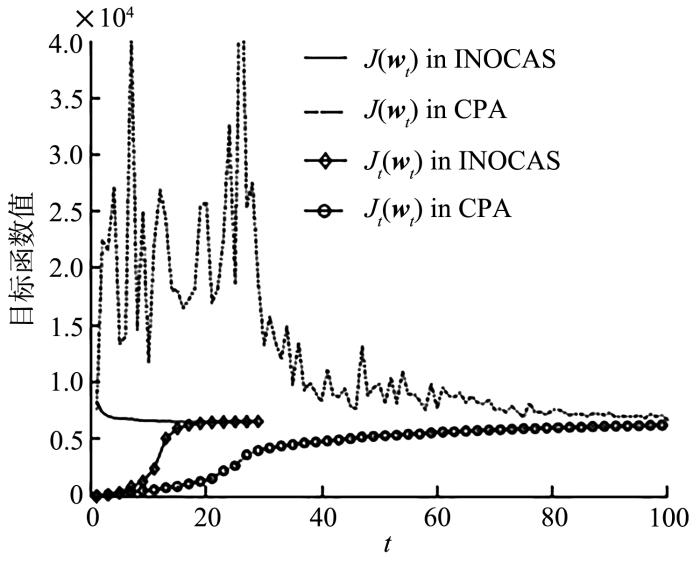
在精确线性搜索求解时需要通过排序所有的值来得到值.容易知道,排序算法的时间复杂度为.在处理大规模机器学习问题的时候,一方面,精确线性搜索式(9)不仅受到特征维数的影响,并且关键的排序算法会受到数据规模的限制;另一方面,优化算法只是一种手段,其目的是使机器学习有更好的泛化能力,有时为了使机器学习算法获得良好的鲁棒性,无需求得模型的最优精确解.储德军等[24]在Franc and Sonnenburg[22]工作的基础上(算法2),提出一种非精确线性搜索的优化割平面算法(INexact⁃Line⁃Search OCAS,INOCAS,算法3),克服了上述缺点,并且保持了OCAS算法的优点,能够保证目标函数值单调下降,并且比OCAS算法的效率更高.加速效果如图3所示.
Coordinate descent method for large?scale L2?loss linear support vector machines
1
2008
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Comment on "Support vector machines with applications"
1
2006
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Statistical behavior and consistency of classification methods based on convex risk minimization
2
2004
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
... [5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Efficient generalized conditional gradient with gradient sliding for composite optimization
1
2015
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Sparseness of support vector machines
1
2003
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Trading convexity for scalability
2
2006
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Robust truncated hinge loss support vector machines
2
2007
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Solving a class of linearly constrained indefinite quadratic problems by D
1
1997
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
The concave?convex procedure
1
2003
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Stochastic majorization?minimization algorithms for large?scale optimization
1
2013
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Incremental majorization?minimization optimization with application to large?scale machine learning
1
2015
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Spider:near?optimal non?convex optimization via stochastic path integrated differential estimator
1
2018
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Accelerated methods for nonconvex optimization
1
2018
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Accelerated stochastic algorithms for nonconvex finite?sum and multi?block optimi?zation
1
2018
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Improving sparsity and scalability in regularized nonconvex truncated?loss learning problems
1
2018
... SVM优化问题中,Hinge损失[3](又称L1⁃Loss)的引入是其取得成功的关键性因素[4,5,6].一方面,在无限样本的情况下,Hinge损失所具有的统计一致性保证SVM的解能收敛到贝叶斯最优分类器[5];另一方面,Hinge损失的特点使分类器只利用了非零向量,这些非零向量被称为支持向量.然而,支持向量的数量会随着样本数线性增加[7],导致在解决大规模问题的时候,时间消耗过大.针对这类问题,文献[8,9,10]通过截断损失函数把SVM的一些不必要的误差样本点剔除,这些误差样本点称为outlier点,但却由此导致了棘手的非凸问题.光滑条件下的非凸问题比较好解决,传统的解决方案是直接利用凹凸优化技巧,例如DCA(Difference Convex Algorithm)算法[11]和CCCP(Concave⁃Convex Procedure)算法[12],通过分解目标非凸函数为一系列凸的子问题来得到一个局部解.Mairal[13]将DCA和CCCP这类处理方法都归结为一个统一的MM(Majorization⁃Minimization)框架.MM框架特别适用于处理有限和形式的目标函数,在非凸领域中被广泛应用.Mairal[14]于2015年提出一种增量MM算法,增量计算比传统批处理方法的计算复杂度低.Fang et al[15]利用随机估计对非凸光滑问题进行最优化,也适用于有限和形式的目标函数.Carmon et al[16]利用梯度计算对非凸问题进行加速,非常适用于大规模问题的求解.此外,Lan and Yang[17]于2019年提出一种针对上述有限和目标函数的加速随机算法,在速度上取得了很好的效果.但这些方法前提是要满足一阶稳定点条件,即目标函数可以是非凸的但必须是光滑的,满足Lipschitz条件.而截断Hinge损失函数不满足这一条件.2018年Tao et al[18]为得到稀疏的支持向量并减少计算复杂度,提出多阶段支持向量机(Multistage Supporting Vector Machine,MS⁃SVM)算法,其原理是在每次迭代之前将满足outlier点的样本点删去,目标函数被截断,再用新的替代函数逼近原始目标函数,然后优化新的替代函数得到最优解.MS⁃SVM算法可以看作MM框架下的一种考虑损失函数结构的特殊方法,但因为在每个阶段都要批处理求解一个SVM问题的精确解,计算复杂度很高,在大规模数据上效果不理想. ...
Pegasos:primal estimated sub?gradient solver for SVM
1
2011
... 还有很多可以高效求解线性SVM的算法,如割平面算法、Pegasos算法[19].Joachims[20]在2006年引入割平面算法来解决线性SVM问题,并证明了算法的收敛性.后来Teo et al[21]将其推广为求解一般正则化损失函数的方法,但在处理实际问题时,割平面算法的性能未能得到充分发挥,并且不能保证主问题单调下降.2008年,Franc and Sonnenburg[22]在此基础上提出优化割平面算法(Optimized Cutting Plane Algorithm,OCAS),在每次迭代过程中,对优化变量w进行精确线性搜索,使目标函数单调下降且保证算法收敛.最近,Chu et al[23]提出一种加速精确线性搜索割平面算法,比Pegasos算法的求解速度更快.2014年储德军等[24]提出一种非精确线性搜索割平面算法,对非光滑目标函数进行了收敛性分析,能保证目标函数单调下降,并且每次迭代都采用非精确线性搜索,使时间消耗大大降低.本文分析表明,这种方法的计算复杂度低于加速精确线性搜索割平面算法. ...
Training linear SVMs in linear time
1
2006
... 还有很多可以高效求解线性SVM的算法,如割平面算法、Pegasos算法[19].Joachims[20]在2006年引入割平面算法来解决线性SVM问题,并证明了算法的收敛性.后来Teo et al[21]将其推广为求解一般正则化损失函数的方法,但在处理实际问题时,割平面算法的性能未能得到充分发挥,并且不能保证主问题单调下降.2008年,Franc and Sonnenburg[22]在此基础上提出优化割平面算法(Optimized Cutting Plane Algorithm,OCAS),在每次迭代过程中,对优化变量w进行精确线性搜索,使目标函数单调下降且保证算法收敛.最近,Chu et al[23]提出一种加速精确线性搜索割平面算法,比Pegasos算法的求解速度更快.2014年储德军等[24]提出一种非精确线性搜索割平面算法,对非光滑目标函数进行了收敛性分析,能保证目标函数单调下降,并且每次迭代都采用非精确线性搜索,使时间消耗大大降低.本文分析表明,这种方法的计算复杂度低于加速精确线性搜索割平面算法. ...
A scalable modular convex solver for regularized risk minimization
2
2007
... 还有很多可以高效求解线性SVM的算法,如割平面算法、Pegasos算法[19].Joachims[20]在2006年引入割平面算法来解决线性SVM问题,并证明了算法的收敛性.后来Teo et al[21]将其推广为求解一般正则化损失函数的方法,但在处理实际问题时,割平面算法的性能未能得到充分发挥,并且不能保证主问题单调下降.2008年,Franc and Sonnenburg[22]在此基础上提出优化割平面算法(Optimized Cutting Plane Algorithm,OCAS),在每次迭代过程中,对优化变量w进行精确线性搜索,使目标函数单调下降且保证算法收敛.最近,Chu et al[23]提出一种加速精确线性搜索割平面算法,比Pegasos算法的求解速度更快.2014年储德军等[24]提出一种非精确线性搜索割平面算法,对非光滑目标函数进行了收敛性分析,能保证目标函数单调下降,并且每次迭代都采用非精确线性搜索,使时间消耗大大降低.本文分析表明,这种方法的计算复杂度低于加速精确线性搜索割平面算法. ...
... 在CPA算法中原始问题式(6)被称为主问题,使用Teo et al[21]的方法可以定义一个子问题: ...
Optimized cutting plane algorithm for support vector machines
3
2008
... 还有很多可以高效求解线性SVM的算法,如割平面算法、Pegasos算法[19].Joachims[20]在2006年引入割平面算法来解决线性SVM问题,并证明了算法的收敛性.后来Teo et al[21]将其推广为求解一般正则化损失函数的方法,但在处理实际问题时,割平面算法的性能未能得到充分发挥,并且不能保证主问题单调下降.2008年,Franc and Sonnenburg[22]在此基础上提出优化割平面算法(Optimized Cutting Plane Algorithm,OCAS),在每次迭代过程中,对优化变量w进行精确线性搜索,使目标函数单调下降且保证算法收敛.最近,Chu et al[23]提出一种加速精确线性搜索割平面算法,比Pegasos算法的求解速度更快.2014年储德军等[24]提出一种非精确线性搜索割平面算法,对非光滑目标函数进行了收敛性分析,能保证目标函数单调下降,并且每次迭代都采用非精确线性搜索,使时间消耗大大降低.本文分析表明,这种方法的计算复杂度低于加速精确线性搜索割平面算法. ...
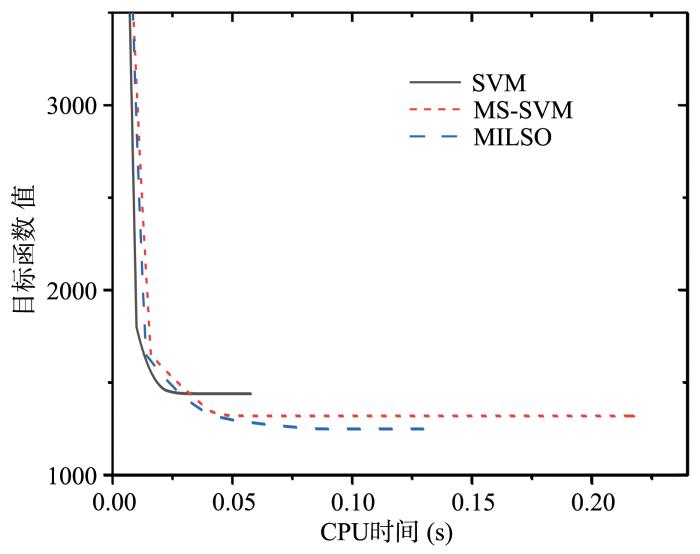
... 在精确线性搜索求解时需要通过排序所有的值来得到值.容易知道,排序算法的时间复杂度为.在处理大规模机器学习问题的时候,一方面,精确线性搜索式(9)不仅受到特征维数的影响,并且关键的排序算法会受到数据规模的限制;另一方面,优化算法只是一种手段,其目的是使机器学习有更好的泛化能力,有时为了使机器学习算法获得良好的鲁棒性,无需求得模型的最优精确解.储德军等[24]在Franc and Sonnenburg[22]工作的基础上(算法2),提出一种非精确线性搜索的优化割平面算法(INexact⁃Line⁃Search OCAS,INOCAS,算法3),克服了上述缺点,并且保持了OCAS算法的优点,能够保证目标函数值单调下降,并且比OCAS算法的效率更高.加速效果如图3所示. ...
A faster cutting plane algorithm with accelerated line search for linear SVM
1
2017
... 还有很多可以高效求解线性SVM的算法,如割平面算法、Pegasos算法[19].Joachims[20]在2006年引入割平面算法来解决线性SVM问题,并证明了算法的收敛性.后来Teo et al[21]将其推广为求解一般正则化损失函数的方法,但在处理实际问题时,割平面算法的性能未能得到充分发挥,并且不能保证主问题单调下降.2008年,Franc and Sonnenburg[22]在此基础上提出优化割平面算法(Optimized Cutting Plane Algorithm,OCAS),在每次迭代过程中,对优化变量w进行精确线性搜索,使目标函数单调下降且保证算法收敛.最近,Chu et al[23]提出一种加速精确线性搜索割平面算法,比Pegasos算法的求解速度更快.2014年储德军等[24]提出一种非精确线性搜索割平面算法,对非光滑目标函数进行了收敛性分析,能保证目标函数单调下降,并且每次迭代都采用非精确线性搜索,使时间消耗大大降低.本文分析表明,这种方法的计算复杂度低于加速精确线性搜索割平面算法. ...
求解线性SVM的非精确步长搜索割平面方法
4
2014
... 还有很多可以高效求解线性SVM的算法,如割平面算法、Pegasos算法[19].Joachims[20]在2006年引入割平面算法来解决线性SVM问题,并证明了算法的收敛性.后来Teo et al[21]将其推广为求解一般正则化损失函数的方法,但在处理实际问题时,割平面算法的性能未能得到充分发挥,并且不能保证主问题单调下降.2008年,Franc and Sonnenburg[22]在此基础上提出优化割平面算法(Optimized Cutting Plane Algorithm,OCAS),在每次迭代过程中,对优化变量w进行精确线性搜索,使目标函数单调下降且保证算法收敛.最近,Chu et al[23]提出一种加速精确线性搜索割平面算法,比Pegasos算法的求解速度更快.2014年储德军等[24]提出一种非精确线性搜索割平面算法,对非光滑目标函数进行了收敛性分析,能保证目标函数单调下降,并且每次迭代都采用非精确线性搜索,使时间消耗大大降低.本文分析表明,这种方法的计算复杂度低于加速精确线性搜索割平面算法. ...
... 在精确线性搜索求解时需要通过排序所有的值来得到值.容易知道,排序算法的时间复杂度为.在处理大规模机器学习问题的时候,一方面,精确线性搜索式(9)不仅受到特征维数的影响,并且关键的排序算法会受到数据规模的限制;另一方面,优化算法只是一种手段,其目的是使机器学习有更好的泛化能力,有时为了使机器学习算法获得良好的鲁棒性,无需求得模型的最优精确解.储德军等[24]在Franc and Sonnenburg[22]工作的基础上(算法2),提出一种非精确线性搜索的优化割平面算法(INexact⁃Line⁃Search OCAS,INOCAS,算法3),克服了上述缺点,并且保持了OCAS算法的优点,能够保证目标函数值单调下降,并且比OCAS算法的效率更高.加速效果如图3所示. ...
... [24]Speedup effect of INOCAS<sup>[<xref ref-type="bibr" rid="R24">24</xref>]</sup>Fig.3
算法2 非精确线性搜索算法 ...
... [24]Fig.3
算法2 非精确线性搜索算法 ...
求解线性SVM的非精确步长搜索割平面方法
4
2014
... 还有很多可以高效求解线性SVM的算法,如割平面算法、Pegasos算法[19].Joachims[20]在2006年引入割平面算法来解决线性SVM问题,并证明了算法的收敛性.后来Teo et al[21]将其推广为求解一般正则化损失函数的方法,但在处理实际问题时,割平面算法的性能未能得到充分发挥,并且不能保证主问题单调下降.2008年,Franc and Sonnenburg[22]在此基础上提出优化割平面算法(Optimized Cutting Plane Algorithm,OCAS),在每次迭代过程中,对优化变量w进行精确线性搜索,使目标函数单调下降且保证算法收敛.最近,Chu et al[23]提出一种加速精确线性搜索割平面算法,比Pegasos算法的求解速度更快.2014年储德军等[24]提出一种非精确线性搜索割平面算法,对非光滑目标函数进行了收敛性分析,能保证目标函数单调下降,并且每次迭代都采用非精确线性搜索,使时间消耗大大降低.本文分析表明,这种方法的计算复杂度低于加速精确线性搜索割平面算法. ...
... 在精确线性搜索求解时需要通过排序所有的值来得到值.容易知道,排序算法的时间复杂度为.在处理大规模机器学习问题的时候,一方面,精确线性搜索式(9)不仅受到特征维数的影响,并且关键的排序算法会受到数据规模的限制;另一方面,优化算法只是一种手段,其目的是使机器学习有更好的泛化能力,有时为了使机器学习算法获得良好的鲁棒性,无需求得模型的最优精确解.储德军等[24]在Franc and Sonnenburg[22]工作的基础上(算法2),提出一种非精确线性搜索的优化割平面算法(INexact⁃Line⁃Search OCAS,INOCAS,算法3),克服了上述缺点,并且保持了OCAS算法的优点,能够保证目标函数值单调下降,并且比OCAS算法的效率更高.加速效果如图3所示. ...
... [24]Speedup effect of INOCAS<sup>[<xref ref-type="bibr" rid="R24">24</xref>]</sup>Fig.3



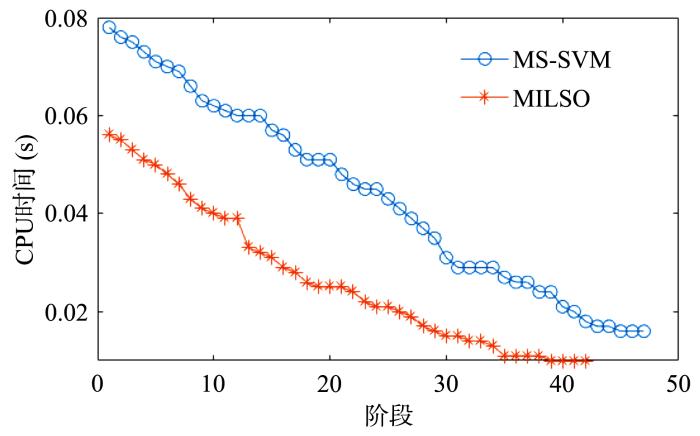

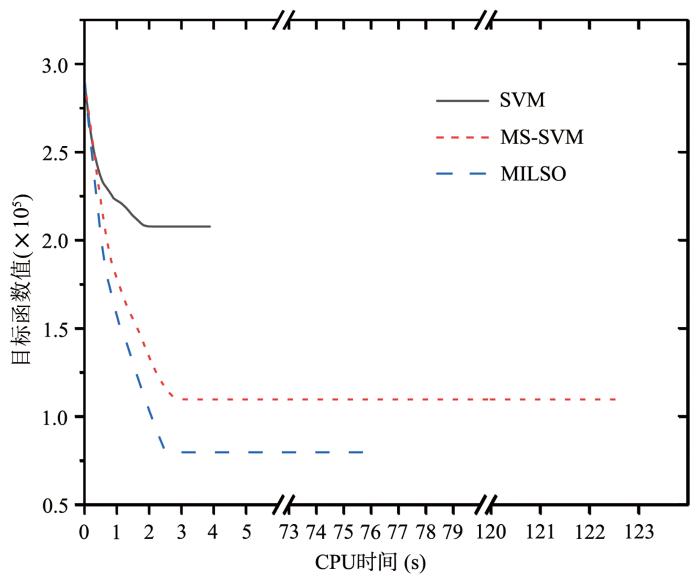
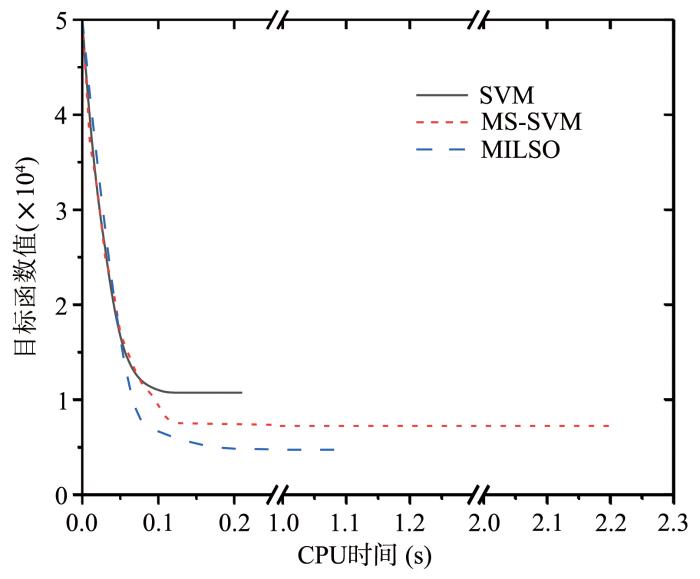
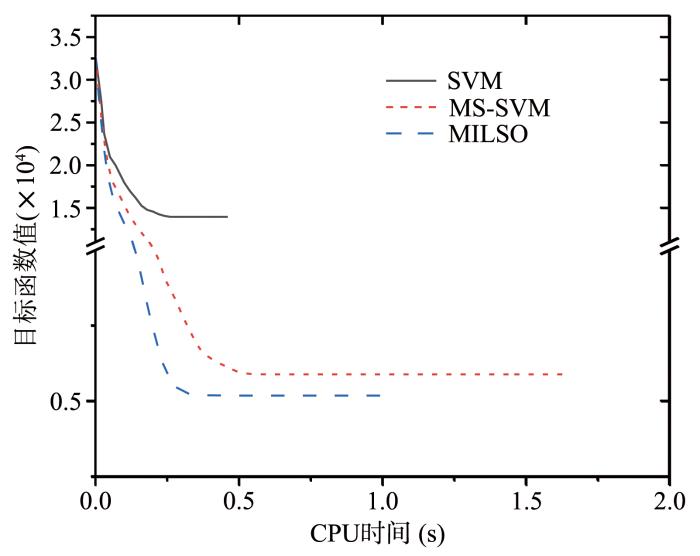

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}