随着互联网应用的蓬勃发展,一个人在不同的社交网络平台上都拥有账户是很常见的.如何在多个社交网络上找到同一个人的账户,对许多应用是很重要的问题,也被称为用户对齐问题.在用户对齐问题上,目前有两个主要的挑战:首先,收集手工对齐的用户对作为训练数据的代价非常大,但传统的有监督方法往往需要大量的标注数据才能获得较好的效果;其次,不同网络中的用户的结构和属性往往不太相同,进一步增加了用户对齐的难度.提出一种无监督用户对齐方法SPUAL(Soft Principle for User Alignment),设计了一种新颖的基于用户的属性与结构的软对齐一致性原则,通过无监督方法计算用户对是否服从此原则来推断用户对是否对齐.在几个公共数据集上的实验表明,该方法的性能比目前最先进的无监督方法都有明显提高.
关键词:用户对齐
;
社交网络
;
无监督
;
对齐原则
Abstract
With the fast development of Internet applications,it's common for someone to have accounts on different social network platforms. How to find out which account on multiple social networks are of the same person is an important issue for many applications today,which is also known as the user alignment problem. There are two major challenges when it comes to user alignment. First,it's extremely expensive to collect manually aligned user pairs as training data,but traditional supervised methods often need a large amount of labeled data to achieve better results. Second,users on different networks often have different structures and attributes,which further increase the difficulty of user alignment. We propose an unsupervised user alignment method SPUAL (Soft Principle for User Alignment),design a novel soft alignment principle based on user attributes and structure,and then infer whether the user alignment is correct or not by calculating whether the users meet to the principles by unsupervised method. Experiments on several common datasets show that the performance of our method is much better than the most advanced unsupervised methods.
Keywords:user alignment
;
social network
;
unsupervised
;
alignment principle
Yu Dongming, Li Yuan, Li Zhixing, Wang Guoyin. An unsupervised user alignment method based on user structure and attribute. Journal of nanjing University[J], 2020, 56(1): 1-8 doi:10.13232/j.cnki.jnju.2020.01.001
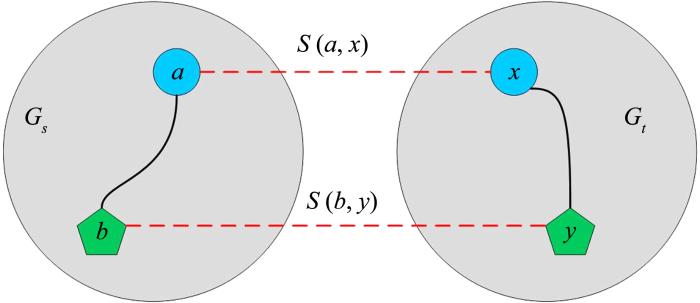
由于社交网络复杂度高、噪声大,在不同的社交网络中对齐的用户的属性和拓扑结构可能会不同,又因为不同的社交网络注重性不同,如果对用户进行严格的对齐反而会导致很多的错误对齐.针对这个问题,本文提出一种基于用户结构和属性的无监督用户对齐方法SPUAL(Soft Principle for User Alignment),主要贡献在于:
有监督方法通过从用户的属性中提取特征,并使用监督分类器模型来预测用户对是否对.Goga et al[9]基于属性的距离相似性特征训练逻辑斯蒂回归分类器,对候选对进行二分类.Liu et al[10]使用基于词袋和距离的特征,将用户对齐问题作为多目标优化问题进行求解.Zhang et al[1]采用基于词袋的特征和基本关系特征,并结合局部和全局一致性提出基于能量的模型.最近,许多基于嵌入的方法也被提出来[11,12,13].然而,监督的方法都需要昂贵的带标签的训练数据,应用场景因此受限.
IsoRank[4]是一种经典的无监督用户对齐方法,它是受到PageRank[14]的启发.IsoRankN[15]扩展了原有的IsoRank算法,并使用类似PageRank⁃Nibble[16]的方法对多个网络进行对齐.Bayati et al[17]提出一种利用最大乘积信念传播进行网络对齐的最大权值匹配算法.NetAlign[5]将用户对齐问题转化为一个整形二次规划问题,可以最大限度地增加网络的平方数.Zhang and Yu[18]分两步解决了多个匿名网络用户对齐问题,即无监督用户对齐推理和传递多网络匹配.这些方法都假设同一个用户在不同的社交网络的社交关系具有一致性,但这个假设在某些社交网络中并不适用,并且无法利用用户的属性信息.
... 有监督方法通过从用户的属性中提取特征,并使用监督分类器模型来预测用户对是否对.Goga et al[9]基于属性的距离相似性特征训练逻辑斯蒂回归分类器,对候选对进行二分类.Liu et al[10]使用基于词袋和距离的特征,将用户对齐问题作为多目标优化问题进行求解.Zhang et al[1]采用基于词袋的特征和基本关系特征,并结合局部和全局一致性提出基于能量的模型.最近,许多基于嵌入的方法也被提出来[11,12,13].然而,监督的方法都需要昂贵的带标签的训练数据,应用场景因此受限. ...
... IsoRank[4]是一种经典的无监督用户对齐方法,它是受到PageRank[14]的启发.IsoRankN[15]扩展了原有的IsoRank算法,并使用类似PageRank⁃Nibble[16]的方法对多个网络进行对齐.Bayati et al[17]提出一种利用最大乘积信念传播进行网络对齐的最大权值匹配算法.NetAlign[5]将用户对齐问题转化为一个整形二次规划问题,可以最大限度地增加网络的平方数.Zhang and Yu[18]分两步解决了多个匿名网络用户对齐问题,即无监督用户对齐推理和传递多网络匹配.这些方法都假设同一个用户在不同的社交网络的社交关系具有一致性,但这个假设在某些社交网络中并不适用,并且无法利用用户的属性信息. ...
... IsoRank[4]是一种经典的无监督用户对齐方法,它是受到PageRank[14]的启发.IsoRankN[15]扩展了原有的IsoRank算法,并使用类似PageRank⁃Nibble[16]的方法对多个网络进行对齐.Bayati et al[17]提出一种利用最大乘积信念传播进行网络对齐的最大权值匹配算法.NetAlign[5]将用户对齐问题转化为一个整形二次规划问题,可以最大限度地增加网络的平方数.Zhang and Yu[18]分两步解决了多个匿名网络用户对齐问题,即无监督用户对齐推理和传递多网络匹配.这些方法都假设同一个用户在不同的社交网络的社交关系具有一致性,但这个假设在某些社交网络中并不适用,并且无法利用用户的属性信息. ...
Large?scale correlation of accounts across social networks
1
2013
... 有监督方法通过从用户的属性中提取特征,并使用监督分类器模型来预测用户对是否对.Goga et al[9]基于属性的距离相似性特征训练逻辑斯蒂回归分类器,对候选对进行二分类.Liu et al[10]使用基于词袋和距离的特征,将用户对齐问题作为多目标优化问题进行求解.Zhang et al[1]采用基于词袋的特征和基本关系特征,并结合局部和全局一致性提出基于能量的模型.最近,许多基于嵌入的方法也被提出来[11,12,13].然而,监督的方法都需要昂贵的带标签的训练数据,应用场景因此受限. ...
HYDRA:Large?scale social identity linkage via heterogeneous behavior modeling
1
2014
... 有监督方法通过从用户的属性中提取特征,并使用监督分类器模型来预测用户对是否对.Goga et al[9]基于属性的距离相似性特征训练逻辑斯蒂回归分类器,对候选对进行二分类.Liu et al[10]使用基于词袋和距离的特征,将用户对齐问题作为多目标优化问题进行求解.Zhang et al[1]采用基于词袋的特征和基本关系特征,并结合局部和全局一致性提出基于能量的模型.最近,许多基于嵌入的方法也被提出来[11,12,13].然而,监督的方法都需要昂贵的带标签的训练数据,应用场景因此受限. ...
Structure based user identification across social networks
1
2017
... 有监督方法通过从用户的属性中提取特征,并使用监督分类器模型来预测用户对是否对.Goga et al[9]基于属性的距离相似性特征训练逻辑斯蒂回归分类器,对候选对进行二分类.Liu et al[10]使用基于词袋和距离的特征,将用户对齐问题作为多目标优化问题进行求解.Zhang et al[1]采用基于词袋的特征和基本关系特征,并结合局部和全局一致性提出基于能量的模型.最近,许多基于嵌入的方法也被提出来[11,12,13].然而,监督的方法都需要昂贵的带标签的训练数据,应用场景因此受限. ...
Aligning users across social networks using network embedding
1
2016
... 有监督方法通过从用户的属性中提取特征,并使用监督分类器模型来预测用户对是否对.Goga et al[9]基于属性的距离相似性特征训练逻辑斯蒂回归分类器,对候选对进行二分类.Liu et al[10]使用基于词袋和距离的特征,将用户对齐问题作为多目标优化问题进行求解.Zhang et al[1]采用基于词袋的特征和基本关系特征,并结合局部和全局一致性提出基于能量的模型.最近,许多基于嵌入的方法也被提出来[11,12,13].然而,监督的方法都需要昂贵的带标签的训练数据,应用场景因此受限. ...
Mego2vec:embedding matched ego networks for user alignment across social networks
1
2018
... 有监督方法通过从用户的属性中提取特征,并使用监督分类器模型来预测用户对是否对.Goga et al[9]基于属性的距离相似性特征训练逻辑斯蒂回归分类器,对候选对进行二分类.Liu et al[10]使用基于词袋和距离的特征,将用户对齐问题作为多目标优化问题进行求解.Zhang et al[1]采用基于词袋的特征和基本关系特征,并结合局部和全局一致性提出基于能量的模型.最近,许多基于嵌入的方法也被提出来[11,12,13].然而,监督的方法都需要昂贵的带标签的训练数据,应用场景因此受限. ...
The PageRank citation ranking:bringing order to the web
1
1999
... IsoRank[4]是一种经典的无监督用户对齐方法,它是受到PageRank[14]的启发.IsoRankN[15]扩展了原有的IsoRank算法,并使用类似PageRank⁃Nibble[16]的方法对多个网络进行对齐.Bayati et al[17]提出一种利用最大乘积信念传播进行网络对齐的最大权值匹配算法.NetAlign[5]将用户对齐问题转化为一个整形二次规划问题,可以最大限度地增加网络的平方数.Zhang and Yu[18]分两步解决了多个匿名网络用户对齐问题,即无监督用户对齐推理和传递多网络匹配.这些方法都假设同一个用户在不同的社交网络的社交关系具有一致性,但这个假设在某些社交网络中并不适用,并且无法利用用户的属性信息. ...
IsoRankN:Spectral methods for global alignment of multiple protein networks
1
2009
... IsoRank[4]是一种经典的无监督用户对齐方法,它是受到PageRank[14]的启发.IsoRankN[15]扩展了原有的IsoRank算法,并使用类似PageRank⁃Nibble[16]的方法对多个网络进行对齐.Bayati et al[17]提出一种利用最大乘积信念传播进行网络对齐的最大权值匹配算法.NetAlign[5]将用户对齐问题转化为一个整形二次规划问题,可以最大限度地增加网络的平方数.Zhang and Yu[18]分两步解决了多个匿名网络用户对齐问题,即无监督用户对齐推理和传递多网络匹配.这些方法都假设同一个用户在不同的社交网络的社交关系具有一致性,但这个假设在某些社交网络中并不适用,并且无法利用用户的属性信息. ...
Local graph partitioning using pageRank vectors
1
2006
... IsoRank[4]是一种经典的无监督用户对齐方法,它是受到PageRank[14]的启发.IsoRankN[15]扩展了原有的IsoRank算法,并使用类似PageRank⁃Nibble[16]的方法对多个网络进行对齐.Bayati et al[17]提出一种利用最大乘积信念传播进行网络对齐的最大权值匹配算法.NetAlign[5]将用户对齐问题转化为一个整形二次规划问题,可以最大限度地增加网络的平方数.Zhang and Yu[18]分两步解决了多个匿名网络用户对齐问题,即无监督用户对齐推理和传递多网络匹配.这些方法都假设同一个用户在不同的社交网络的社交关系具有一致性,但这个假设在某些社交网络中并不适用,并且无法利用用户的属性信息. ...
Maximum weight matching via max?product belief propagation
1
2005
... IsoRank[4]是一种经典的无监督用户对齐方法,它是受到PageRank[14]的启发.IsoRankN[15]扩展了原有的IsoRank算法,并使用类似PageRank⁃Nibble[16]的方法对多个网络进行对齐.Bayati et al[17]提出一种利用最大乘积信念传播进行网络对齐的最大权值匹配算法.NetAlign[5]将用户对齐问题转化为一个整形二次规划问题,可以最大限度地增加网络的平方数.Zhang and Yu[18]分两步解决了多个匿名网络用户对齐问题,即无监督用户对齐推理和传递多网络匹配.这些方法都假设同一个用户在不同的社交网络的社交关系具有一致性,但这个假设在某些社交网络中并不适用,并且无法利用用户的属性信息. ...
Multiple anonymized social networks alignment
1
2015
... IsoRank[4]是一种经典的无监督用户对齐方法,它是受到PageRank[14]的启发.IsoRankN[15]扩展了原有的IsoRank算法,并使用类似PageRank⁃Nibble[16]的方法对多个网络进行对齐.Bayati et al[17]提出一种利用最大乘积信念传播进行网络对齐的最大权值匹配算法.NetAlign[5]将用户对齐问题转化为一个整形二次规划问题,可以最大限度地增加网络的平方数.Zhang and Yu[18]分两步解决了多个匿名网络用户对齐问题,即无监督用户对齐推理和传递多网络匹配.这些方法都假设同一个用户在不同的社交网络的社交关系具有一致性,但这个假设在某些社交网络中并不适用,并且无法利用用户的属性信息. ...
ComSoc:adaptive transfer of user behaviors over composite social network



{kind=link}
{kind=link}