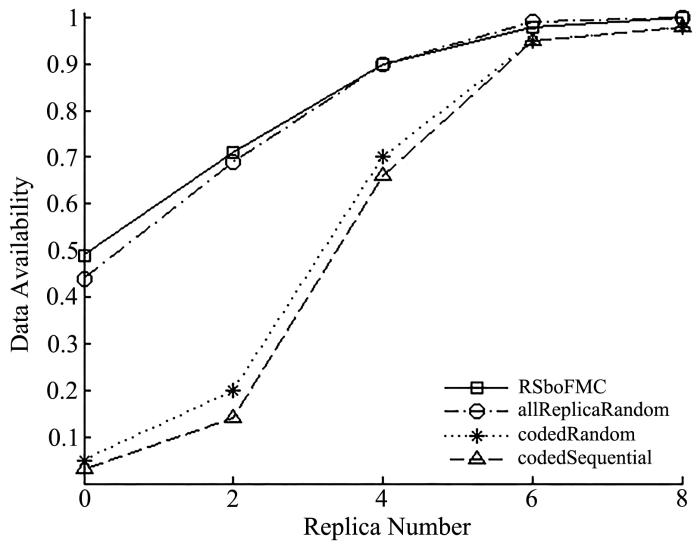
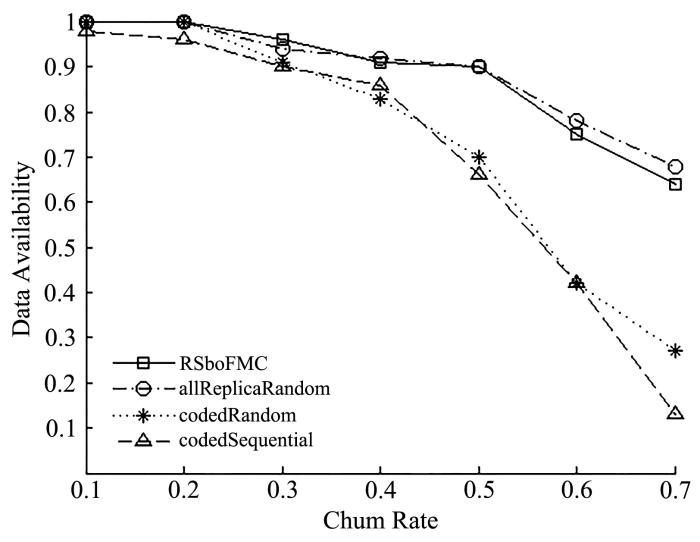
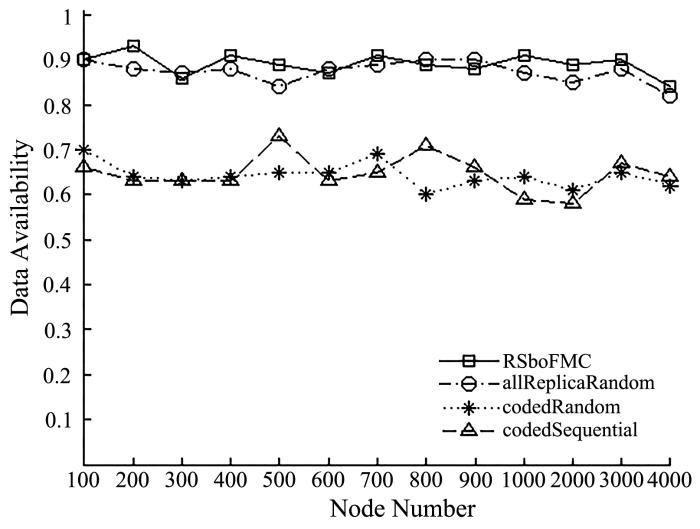
保证动荡环境下数据可被访问概率对数据存储网络十分重要,其可行方法之一是设计合理的存储策略,提高网络的数据可用性.将存储策略分为复制策略和放置策略进行设计,提出了基于碎片矩阵和缓存的存储策略RSboFMC(Replication Strategy based on Fragment Matrix and Cache),提高动荡环境下的数据可用性.其以重建效率和存储开销为目标,设计缓存机制和基于碎片矩阵的数据分块机制优化复制策略;以负载均衡为目标,设计基于分区和顺逆序的分发机制优化放置策略.仿真结果表明,RSboFMC在数据可用性和负载均衡性方面均优于其他策略,且具有良好的扩展性.
关键词:数据分块机制
;
数据可用性
;
缓存机制
;
数据分发机制
Abstract
It is critical for data storage network to provide expected possibility of data accessed under churn. One of possible method is to design proper storage strategy for increasing data availability of networks. RSboFMC(Replication Strategy based on Fragment Matrix and Cache) was proposed based on the fragment matrix and the cache to raise data availability under churn. It divided the storage strategy into replication and placement strategies,then the cache mechanism and the data partitioning mechanism which was based on fragment matrix were designed to optimize the replication strategy in consideration of reconstruct effectiveness and storage cost,as well as the distributing mechanism based on zone partition and opposite sequences was designed to optimize the placement strategy,considering the loadbalance. Simulation results show RSboFMC outperforms other strategies in terms of the data availability and the load balance. Besides,it has good scalability.
Keywords:data partitioning mechanism
;
data availability
;
cache mechanism
;
data distributing mechanism
Qi Xiaogang, Qiang Min, Liu Lifang. RSboFMC:Replication strategy based on fragment matrix and cachefor improving data availability and load balance. Journal of nanjing University(Natural Science)[J], 2019, 55(4): 667-677 doi:10.13232/j.cnki.jnju.2019.04.017
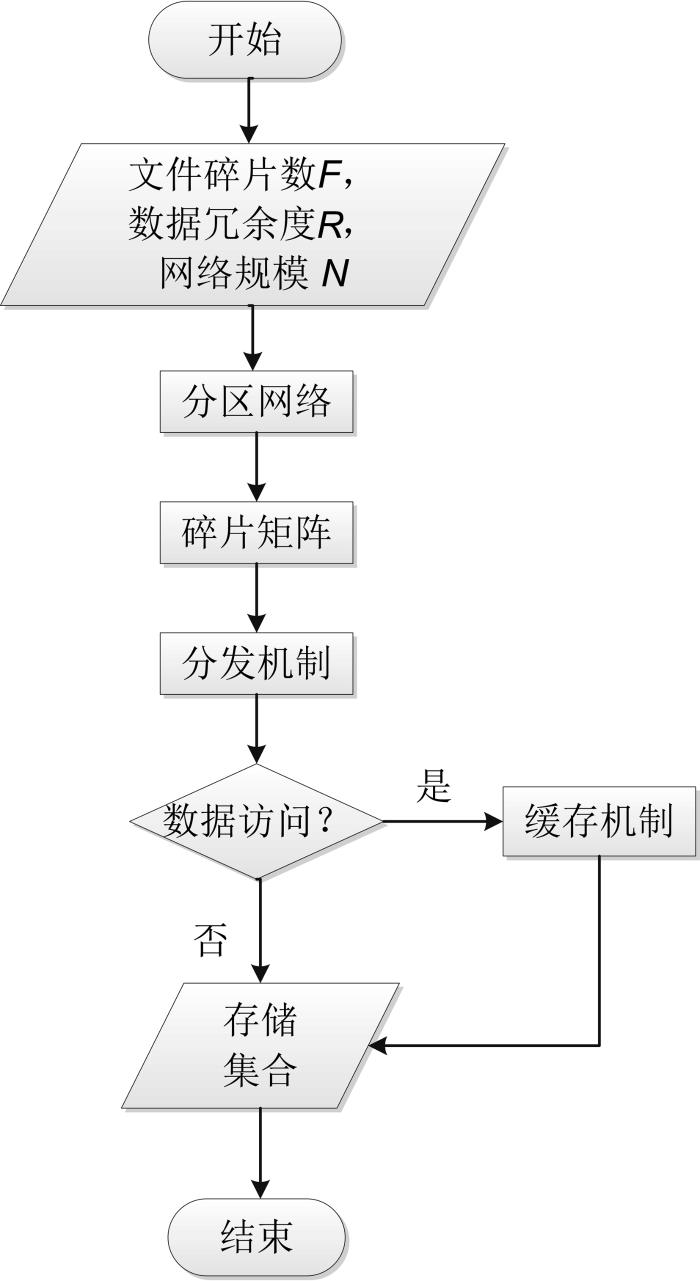
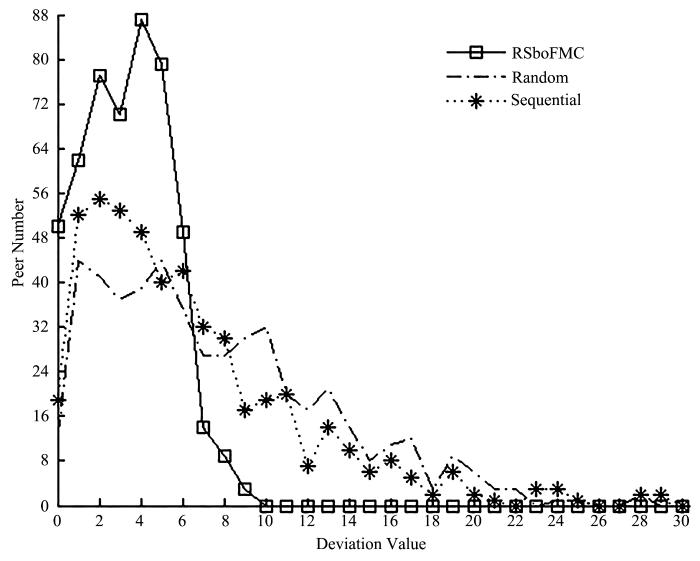
一般来说,存储策略主要由复制策略和放置策略组成,其中复制策略是生成文件备份并存储在不同服务器中,避免服务器崩溃造成的数据丢失[9],主要分为全复制或分块复制;放置策略是节点集选择问题,是提高系统容错性的方法之一[10].放置策略大致分为顺序放置和随机放置.顺序放置采用固定的映射方式将数据各个副本放置到相应节点上,简单、易于实施,但容易引发级联失效.而随机映射副本数据到相应节点上的方式,具有较高的容错性,但数据访问的本地性较弱,对系统的性能影响较大.本文提出一种基于碎片矩阵和缓存的全新存储策略RSboFMC(Replication Strategy based on Fragment Matrix and Cache),主要由数据分块机制、分发机制和缓存机制组成,在降低存储开销提高数据访问效率的同时,尽可能达到负载均衡.碎片矩阵主要是用于数据分块机制中,无需对复杂矩阵进行操作便可对文件进行类似编码的处理,有效地减少了存储开销.不可否认,全复制策略在高动荡情况下具有较好的数据可用性,所以提出存在数据访问时触发的缓存机制,在主节点上重建文件进行缓存,提高存储网络的动荡容忍性.基于分区且考虑了各区域最大副本节点数量的顺逆序分发机制具有良好的扩展性和负载均衡性,其可理解为一种特殊的随机放置策略.为验证RSboFMC的策略性能,不同于二项分布下定义的部分场景适应性数据可用性指标,本文基于超几何分布提出和网络规模、存储节点集等相关的数据可用性评价指标,分别以冗余因子、网络攻击强弱和网络规模为自变量,评价RSboFMC策略的数据可用性性能;再根据实际负载值和理想负载值之差设定负载波动公式,在此基础上得出偏差分布图,全面评价RSboFMC策略的负载均衡性性能.
由不可避免的原因造成的随机或蓄意攻击会引起数据损坏,但即使没有蓄意攻击,在一段时间之后,数据仍可能被损坏,因此对一个存储系统来说,提高网络相关性能的存储策略十分必要,其可从数据被存储形式、存储分发机制等方面进行优化策略设计以提高网络相关性能.数据被存储形式主要分为全复制和分块复制,Zhang et al[11]通过建立固定长度的list表识别流行文件和冷门文件,再将存储节点集分为冷热节点对数据进行存储,只需保证热节点处于活跃状态以确保系统性能,并以此应对全复制带来的高存储开销问题.Zhu et al[12]在FR编码的基础上提出基于分组设计的HFR数据分块机制,将文件分为正常块和奇偶校验块.在冗余因子R确定的情况下,每个正常块生成R份,校验块各生成R-1份.仿真结果表明,其在随机访问情况下可以优化存储空间并缩短数据重构时间,同时在节点失效情况下,具有多个修复组合方案.应用数据分块机制的存储优化策略,经常需要考虑改善数据块被重建效率,其有效方法之一是建立缓存.Inacio and Dantas[13]通过大量实验观察14个参数对Orange文件系统响应时间和吞吐量的影响,提出粗粒度页面缓存多元分析模型,提高并行文件系统的读写性能.存储分发机制与网络性能也有十分重要的关系,良好的分发机制可以提高数据可用性,增加系统动荡容错性.Lakshman and Malik[14]提出应用于Cassandra系统的随机分发机制,可以有效减小级联失效的概率,但可能造成节点负载不均衡.Silva et al[15]提出基于哈希表的全局目录式存储分发方法和基于希尔伯特空间填充曲线(Hilbert Space Filling Curves,HSFC)的查询机制,通过仿真结果证明可应用于网络规模、节点数量或存储信息量动态变化的环境中.
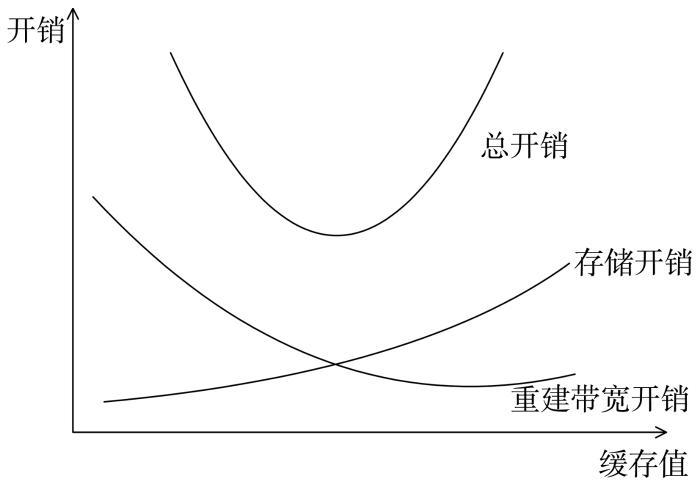
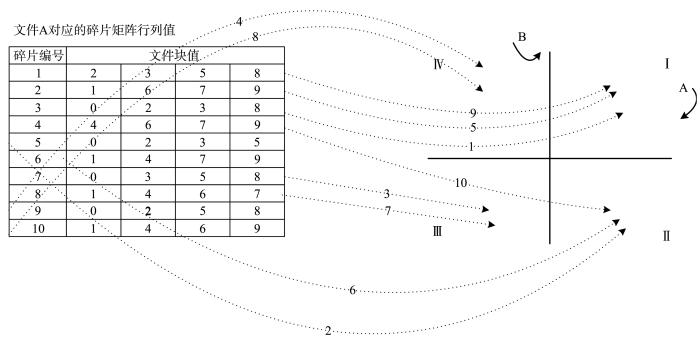
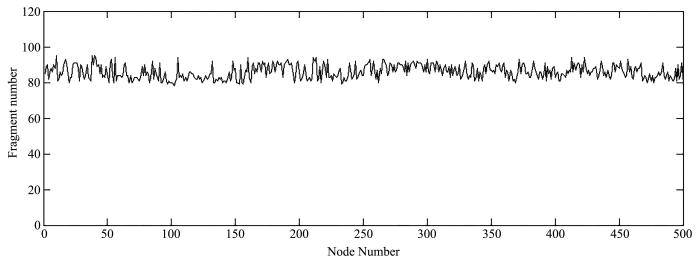
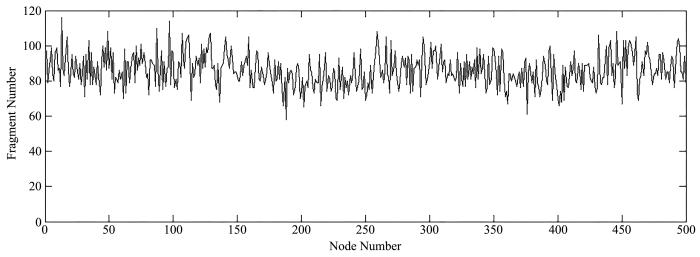
为节省存储空间降低存储开销,本文提出基于碎片矩阵的数据分块机制.同编码机制一样,数据请求时需要进行数据重构,影响用户服务质量,所以在分块的基础上提出了缓存机制,可有效针对流行文件的资源访问,缓解热点问题,降低重建开销改善用户服务质量.缓存机制有两种阈值标准:时间阈值TTL(Time to Live)和容量阈值CS(Cache Size).TTL标准使得存储忽略负载,本文以CS为阈值标准,基于当前最少使用原则LUC(Least Used Currently)删除溢出缓存.
Survey of research on big data storage∥Proceedings of the 2013 12th Interna⁃tional Symposium on Distributed Computing and Applications to Business,Engineering & Science
.. Kingston upon Thames,United Kingdom:IEEE,2013:76-80.
Rethinking erasure codes for cloud file systems:minimizing I/O for recovery and degraded reads∥Proceedings of the 10th USENIX Conference on File & Storage Technologies
Survey of research on big data storage∥Proceedings of the 2013 12th Interna?tional Symposium on Distributed Computing and Applications to Business,Engineering & Science
Rethinking erasure codes for cloud file systems:minimizing I/O for recovery and degraded reads∥Proceedings of the 10th USENIX Conference on File & Storage Technologies
1
2012
... 一般来说,存储策略主要由复制策略和放置策略组成,其中复制策略是生成文件备份并存储在不同服务器中,避免服务器崩溃造成的数据丢失[9],主要分为全复制或分块复制;放置策略是节点集选择问题,是提高系统容错性的方法之一[10].放置策略大致分为顺序放置和随机放置.顺序放置采用固定的映射方式将数据各个副本放置到相应节点上,简单、易于实施,但容易引发级联失效.而随机映射副本数据到相应节点上的方式,具有较高的容错性,但数据访问的本地性较弱,对系统的性能影响较大.本文提出一种基于碎片矩阵和缓存的全新存储策略RSboFMC(Replication Strategy based on Fragment Matrix and Cache),主要由数据分块机制、分发机制和缓存机制组成,在降低存储开销提高数据访问效率的同时,尽可能达到负载均衡.碎片矩阵主要是用于数据分块机制中,无需对复杂矩阵进行操作便可对文件进行类似编码的处理,有效地减少了存储开销.不可否认,全复制策略在高动荡情况下具有较好的数据可用性,所以提出存在数据访问时触发的缓存机制,在主节点上重建文件进行缓存,提高存储网络的动荡容忍性.基于分区且考虑了各区域最大副本节点数量的顺逆序分发机制具有良好的扩展性和负载均衡性,其可理解为一种特殊的随机放置策略.为验证RSboFMC的策略性能,不同于二项分布下定义的部分场景适应性数据可用性指标,本文基于超几何分布提出和网络规模、存储节点集等相关的数据可用性评价指标,分别以冗余因子、网络攻击强弱和网络规模为自变量,评价RSboFMC策略的数据可用性性能;再根据实际负载值和理想负载值之差设定负载波动公式,在此基础上得出偏差分布图,全面评价RSboFMC策略的负载均衡性性能. ...
Data placement strategy in data center distributed storage systems∥2016 IEEE International Conference on Communication Systems (ICCS)
1
2017
... 一般来说,存储策略主要由复制策略和放置策略组成,其中复制策略是生成文件备份并存储在不同服务器中,避免服务器崩溃造成的数据丢失[9],主要分为全复制或分块复制;放置策略是节点集选择问题,是提高系统容错性的方法之一[10].放置策略大致分为顺序放置和随机放置.顺序放置采用固定的映射方式将数据各个副本放置到相应节点上,简单、易于实施,但容易引发级联失效.而随机映射副本数据到相应节点上的方式,具有较高的容错性,但数据访问的本地性较弱,对系统的性能影响较大.本文提出一种基于碎片矩阵和缓存的全新存储策略RSboFMC(Replication Strategy based on Fragment Matrix and Cache),主要由数据分块机制、分发机制和缓存机制组成,在降低存储开销提高数据访问效率的同时,尽可能达到负载均衡.碎片矩阵主要是用于数据分块机制中,无需对复杂矩阵进行操作便可对文件进行类似编码的处理,有效地减少了存储开销.不可否认,全复制策略在高动荡情况下具有较好的数据可用性,所以提出存在数据访问时触发的缓存机制,在主节点上重建文件进行缓存,提高存储网络的动荡容忍性.基于分区且考虑了各区域最大副本节点数量的顺逆序分发机制具有良好的扩展性和负载均衡性,其可理解为一种特殊的随机放置策略.为验证RSboFMC的策略性能,不同于二项分布下定义的部分场景适应性数据可用性指标,本文基于超几何分布提出和网络规模、存储节点集等相关的数据可用性评价指标,分别以冗余因子、网络攻击强弱和网络规模为自变量,评价RSboFMC策略的数据可用性性能;再根据实际负载值和理想负载值之差设定负载波动公式,在此基础上得出偏差分布图,全面评价RSboFMC策略的负载均衡性性能. ...
Skewly replicating hot data to construct a powerefficient storage cluster
1
2015
... 由不可避免的原因造成的随机或蓄意攻击会引起数据损坏,但即使没有蓄意攻击,在一段时间之后,数据仍可能被损坏,因此对一个存储系统来说,提高网络相关性能的存储策略十分必要,其可从数据被存储形式、存储分发机制等方面进行优化策略设计以提高网络相关性能.数据被存储形式主要分为全复制和分块复制,Zhang et al[11]通过建立固定长度的list表识别流行文件和冷门文件,再将存储节点集分为冷热节点对数据进行存储,只需保证热节点处于活跃状态以确保系统性能,并以此应对全复制带来的高存储开销问题.Zhu et al[12]在FR编码的基础上提出基于分组设计的HFR数据分块机制,将文件分为正常块和奇偶校验块.在冗余因子R确定的情况下,每个正常块生成R份,校验块各生成R-1份.仿真结果表明,其在随机访问情况下可以优化存储空间并缩短数据重构时间,同时在节点失效情况下,具有多个修复组合方案.应用数据分块机制的存储优化策略,经常需要考虑改善数据块被重建效率,其有效方法之一是建立缓存.Inacio and Dantas[13]通过大量实验观察14个参数对Orange文件系统响应时间和吞吐量的影响,提出粗粒度页面缓存多元分析模型,提高并行文件系统的读写性能.存储分发机制与网络性能也有十分重要的关系,良好的分发机制可以提高数据可用性,增加系统动荡容错性.Lakshman and Malik[14]提出应用于Cassandra系统的随机分发机制,可以有效减小级联失效的概率,但可能造成节点负载不均衡.Silva et al[15]提出基于哈希表的全局目录式存储分发方法和基于希尔伯特空间填充曲线(Hilbert Space Filling Curves,HSFC)的查询机制,通过仿真结果证明可应用于网络规模、节点数量或存储信息量动态变化的环境中. ...
HFR code:a flexible replication scheme for cloud storage systems
1
2015
... 由不可避免的原因造成的随机或蓄意攻击会引起数据损坏,但即使没有蓄意攻击,在一段时间之后,数据仍可能被损坏,因此对一个存储系统来说,提高网络相关性能的存储策略十分必要,其可从数据被存储形式、存储分发机制等方面进行优化策略设计以提高网络相关性能.数据被存储形式主要分为全复制和分块复制,Zhang et al[11]通过建立固定长度的list表识别流行文件和冷门文件,再将存储节点集分为冷热节点对数据进行存储,只需保证热节点处于活跃状态以确保系统性能,并以此应对全复制带来的高存储开销问题.Zhu et al[12]在FR编码的基础上提出基于分组设计的HFR数据分块机制,将文件分为正常块和奇偶校验块.在冗余因子R确定的情况下,每个正常块生成R份,校验块各生成R-1份.仿真结果表明,其在随机访问情况下可以优化存储空间并缩短数据重构时间,同时在节点失效情况下,具有多个修复组合方案.应用数据分块机制的存储优化策略,经常需要考虑改善数据块被重建效率,其有效方法之一是建立缓存.Inacio and Dantas[13]通过大量实验观察14个参数对Orange文件系统响应时间和吞吐量的影响,提出粗粒度页面缓存多元分析模型,提高并行文件系统的读写性能.存储分发机制与网络性能也有十分重要的关系,良好的分发机制可以提高数据可用性,增加系统动荡容错性.Lakshman and Malik[14]提出应用于Cassandra系统的随机分发机制,可以有效减小级联失效的概率,但可能造成节点负载不均衡.Silva et al[15]提出基于哈希表的全局目录式存储分发方法和基于希尔伯特空间填充曲线(Hilbert Space Filling Curves,HSFC)的查询机制,通过仿真结果证明可应用于网络规模、节点数量或存储信息量动态变化的环境中. ...
A coarse?grained page cache aware multivariate analytical model for the storage performance of a parallel file system
1
2018
... 由不可避免的原因造成的随机或蓄意攻击会引起数据损坏,但即使没有蓄意攻击,在一段时间之后,数据仍可能被损坏,因此对一个存储系统来说,提高网络相关性能的存储策略十分必要,其可从数据被存储形式、存储分发机制等方面进行优化策略设计以提高网络相关性能.数据被存储形式主要分为全复制和分块复制,Zhang et al[11]通过建立固定长度的list表识别流行文件和冷门文件,再将存储节点集分为冷热节点对数据进行存储,只需保证热节点处于活跃状态以确保系统性能,并以此应对全复制带来的高存储开销问题.Zhu et al[12]在FR编码的基础上提出基于分组设计的HFR数据分块机制,将文件分为正常块和奇偶校验块.在冗余因子R确定的情况下,每个正常块生成R份,校验块各生成R-1份.仿真结果表明,其在随机访问情况下可以优化存储空间并缩短数据重构时间,同时在节点失效情况下,具有多个修复组合方案.应用数据分块机制的存储优化策略,经常需要考虑改善数据块被重建效率,其有效方法之一是建立缓存.Inacio and Dantas[13]通过大量实验观察14个参数对Orange文件系统响应时间和吞吐量的影响,提出粗粒度页面缓存多元分析模型,提高并行文件系统的读写性能.存储分发机制与网络性能也有十分重要的关系,良好的分发机制可以提高数据可用性,增加系统动荡容错性.Lakshman and Malik[14]提出应用于Cassandra系统的随机分发机制,可以有效减小级联失效的概率,但可能造成节点负载不均衡.Silva et al[15]提出基于哈希表的全局目录式存储分发方法和基于希尔伯特空间填充曲线(Hilbert Space Filling Curves,HSFC)的查询机制,通过仿真结果证明可应用于网络规模、节点数量或存储信息量动态变化的环境中. ...
Cassandra:a decen?tralized structured storage system
1
2010
... 由不可避免的原因造成的随机或蓄意攻击会引起数据损坏,但即使没有蓄意攻击,在一段时间之后,数据仍可能被损坏,因此对一个存储系统来说,提高网络相关性能的存储策略十分必要,其可从数据被存储形式、存储分发机制等方面进行优化策略设计以提高网络相关性能.数据被存储形式主要分为全复制和分块复制,Zhang et al[11]通过建立固定长度的list表识别流行文件和冷门文件,再将存储节点集分为冷热节点对数据进行存储,只需保证热节点处于活跃状态以确保系统性能,并以此应对全复制带来的高存储开销问题.Zhu et al[12]在FR编码的基础上提出基于分组设计的HFR数据分块机制,将文件分为正常块和奇偶校验块.在冗余因子R确定的情况下,每个正常块生成R份,校验块各生成R-1份.仿真结果表明,其在随机访问情况下可以优化存储空间并缩短数据重构时间,同时在节点失效情况下,具有多个修复组合方案.应用数据分块机制的存储优化策略,经常需要考虑改善数据块被重建效率,其有效方法之一是建立缓存.Inacio and Dantas[13]通过大量实验观察14个参数对Orange文件系统响应时间和吞吐量的影响,提出粗粒度页面缓存多元分析模型,提高并行文件系统的读写性能.存储分发机制与网络性能也有十分重要的关系,良好的分发机制可以提高数据可用性,增加系统动荡容错性.Lakshman and Malik[14]提出应用于Cassandra系统的随机分发机制,可以有效减小级联失效的概率,但可能造成节点负载不均衡.Silva et al[15]提出基于哈希表的全局目录式存储分发方法和基于希尔伯特空间填充曲线(Hilbert Space Filling Curves,HSFC)的查询机制,通过仿真结果证明可应用于网络规模、节点数量或存储信息量动态变化的环境中. ...
A flexible DHT?based directory service for informa?tion management
1
2015
... 由不可避免的原因造成的随机或蓄意攻击会引起数据损坏,但即使没有蓄意攻击,在一段时间之后,数据仍可能被损坏,因此对一个存储系统来说,提高网络相关性能的存储策略十分必要,其可从数据被存储形式、存储分发机制等方面进行优化策略设计以提高网络相关性能.数据被存储形式主要分为全复制和分块复制,Zhang et al[11]通过建立固定长度的list表识别流行文件和冷门文件,再将存储节点集分为冷热节点对数据进行存储,只需保证热节点处于活跃状态以确保系统性能,并以此应对全复制带来的高存储开销问题.Zhu et al[12]在FR编码的基础上提出基于分组设计的HFR数据分块机制,将文件分为正常块和奇偶校验块.在冗余因子R确定的情况下,每个正常块生成R份,校验块各生成R-1份.仿真结果表明,其在随机访问情况下可以优化存储空间并缩短数据重构时间,同时在节点失效情况下,具有多个修复组合方案.应用数据分块机制的存储优化策略,经常需要考虑改善数据块被重建效率,其有效方法之一是建立缓存.Inacio and Dantas[13]通过大量实验观察14个参数对Orange文件系统响应时间和吞吐量的影响,提出粗粒度页面缓存多元分析模型,提高并行文件系统的读写性能.存储分发机制与网络性能也有十分重要的关系,良好的分发机制可以提高数据可用性,增加系统动荡容错性.Lakshman and Malik[14]提出应用于Cassandra系统的随机分发机制,可以有效减小级联失效的概率,但可能造成节点负载不均衡.Silva et al[15]提出基于哈希表的全局目录式存储分发方法和基于希尔伯特空间填充曲线(Hilbert Space Filling Curves,HSFC)的查询机制,通过仿真结果证明可应用于网络规模、节点数量或存储信息量动态变化的环境中. ...
Proactive replication for data durability∥Proceedings of IPTPS




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}