粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释.
Pawlak粗糙集模型在容错能力上的缺陷[17 ] 逐渐引起了广大学者的注意.为了克服这一缺陷,加拿大学者Yao et al[18 ] 提出了基于贝叶斯风险分析的决策粗糙集模型.该模型主要有两大优势[19 ] :(1)决策粗糙集模型重新定义粗糙集的正域、边界域和负域,给予传统粗糙集模型全新的解释,丰富了传统决策方法;(2)决策粗糙集理论通过构建代价矩阵获取概率粗糙集所需要的一对阈值,引入损失函数,将粗糙集方法和代价敏感问题联系到一起.
近年来,以代价敏感[20 ] 为基础的属性约简问题越来越受到粗糙集学者的关注,他们将各式各样的策略运用到基于代价敏感的属性约简问题当中.相对于时间复杂度较高的穷举法[21 ,22 ] ,基于适应度函数的启发式搜索方法[23 ,24 ] 因具有较高的求解速度和普适性,被广泛地运用到面向代价敏感的属性约简问题中,但值得注意的是,根据启发式方法搜索出的属性子集往往仅能降低训练样本集上的决策代价,但却未必能够有效地保证测试样本集上的决策代价也能够被降低.鉴于此,本文试图将交叉验证[25 ,26 ] 的思想引入到属性约简当中,其目的是在训练样本集上的搜索进程中设置一个早停止策略,一旦决策代价不能够被降低了,则立即停止搜索.这一模式在训练样本集上模拟了测试样本的代价变化情况,证明它不仅进一步降低了训练集合的决策代价,而且能有效地测试集合的决策代价,从代价敏感的角度提高了属性子集的泛化能力.
1 决策粗糙集
经典的决策粗糙集理论是建立在两个状态与三个行动基础上[18 ] 的.一般的,定义状态集合Ω ={X ,~X }表示两种状态:对象x 属于集合X 和对象x 不属于集合X ;定义行动集A ={aP ,aB ,aN },aP ,aB ,aN 分别表示对象x 属于集合X 的正域、边界域、负域.此时,若考虑对象x 属于某个状态时,做出某个动作所需的代价函数值,则可以定义如下表1 所示的代价矩阵.
表1 中,λPP ,λBP 和λNP 分别表示当对象x 属于集合X 时,采取行动aP ,aB ,aN 付出的代价;λPN ,λBN 和λNN 分别表示当对象x 属于集合~X 时,采取行动aP ,aB ,aN 付出的代价.根据代价函数值的定义,显然有如下关系:0≤λPP ≤λBP ≤λNP ,0≤λNN ≤λBN ≤λPN .在决策粗糙集理论中,根据贝叶斯最小风险决策原则可以得到如下三种决策规则:
(1)若P r ( X | [ x ] A T ) ≥ α x ∈ P O S ( X )
(2)若β < P r ( X | [ x ] A T ) < α x ∈ B N D ( X )
(3)若P r ( X | [ x ] A T ) ≤ β x ∈ N E G ( X ) .
α = λ P N - λ B N ( λ P N - λ B N ) + ( λ B P - λ P P )
β = λ B N - λ N N ( λ B N - λ N N ) + ( λ N P - λ B P )
D S = U , A T ⋃ d
其中,U 是所有样本组成的非空集合,称为论域;AT 是所有条件属性组成的集合;{d }是决策属性组成的集合.根据如上所示三种决策规则,∀A ⊇AT ,则可以定义决策粗糙集的下近似集和上近似集分别为:
N A ̲ ( X ) = x i ∈ U : P r ( X | [ x i ] A ) ≥ α (1)
N A ¯ ( X ) = x i ∈ U : P r ( X | [ x i ] A ) > β (2)
x i A = y ∈ U : ( x i , y ) ∈ I N D ( A )
P O S A ( X ) = N A ̲ ( X )
B N D A ( X ) = N A ¯ ( X ) - N A ̲ ( X )
N E G A ( X ) = U - N A ¯ ( X )
至此,根据相应的决策规则,可以计算得该决策系统的总决策代价.∀ A ⊆ A T
C O S T A = C O S T A P O S + C O S T A B N D + C O S T A N E G = ∑ j = 1 t ∑ x i ∈ P O S A ( X ) P r ( X j | [ x i ] A ) ⋅ λ P P + ( 1 - P r ( X j | [ x i ] A ) ) ⋅ λ P N + ∑ j = 1 t ∑ x i ∈ B N D A ( X ) P r ( X j | [ x i ] A ) ⋅ λ B P + ( 1 - P r ( X j | [ x i ] A ) ) ⋅ λ B N + ∑ j = 1 t ∑ x i ∈ N E G A ( X ) P r ( X j | [ x i ] A ) ⋅ λ N P + ( 1 - P r ( X j | [ x i ] A ) ) ⋅ λ N N (3)
2 基于决策代价的启发式约简
属性约简是粗糙集理论中的一个核心问题,其本质是在受一定约束条件约束的前期下,删除条件属性中一定的冗余的属性,得到满足约束条件的最小条件属性子集.本文以决策代价为基础,对属性约简的方法进行讨论.
定义1 给定决策系统DS ,∀ A ⊆ A T A 被称为AT 的一个决策代价约简当且仅当:
1 C O S T A ≤ C O S T A T ; 2 ∀ B ⊂ A , C O S T B > C O S T A .
定义2 给定决策系统DS ,∀ A ⊆ A T , ∀ a ∈ A T - A , a 的重要度函数定义为:
S i g ( U , a , A ) = C O S T A ⋃ a - C O S T A (4)
定义1的约简保证总决策代价不会增加最小条件属性子集.定义2的重要度函数Sig (U ,a ,A )表示属性a 加入集合A 后该决策系统总决策代价的变化.加入属性a 后有C O S T A ⋃ a ≤
C O S T A a 对总决策代价的降低做出了贡献;否则属性a 为冗余属性.
当前,已有许多学者给出多种求解约简的算法.相对于基于穷举法的求解约简算法,启发式算法因具有较高的求解效率,所以广受青睐.根据定义2中重要度函数的定义,给出启发
S i g ( U , a , A ) = C O S T A ⋃ a - C O S T A
S i g ( U , b , A ) = m i n ∀ a i ∈ A T - A : S i g ( U , a i , A
步骤4 若S i g ( a k , A ) < 0 A = A ⋃ b
A = A - a
算法1的时间复杂度是O ( | U | 2 ⋅ | A T | 2 ) U |是样本的总个数,|AT |是条件属性的总个数.
3 基于交叉验证思想的决策代价约简
尽管基于决策代价的启发式约简方法具有较高的求解效率,但是这种算法求解出来的属性子集往往只能有效地降低训练集合的总决策代价,却经常不能有效地降低测试集合的总决策代价.为了解决上述算法不能有效地降低测试集合总决策代价的问题,本文将交叉验证的思想引入到属性约简当中,具体设计如算法2所示.
输入:决策系统D S = U , A T ⋃ d δ ,交叉折数k
步骤2 将样本集合分为k 个部分:T 1 ,T 2 ,… ,Tk ;
( 1 ) 令 U t r a i n j = U - T j
( 2 ) ∀ a i ∈ A T - A , 计 算 S i g ( U t r a i n j , a i , A )
m e a n ( a i ) = ∑ j = 1 k S i g ( U t r a i n j , a i , A ) k
S i g ( b , A ) = m i n ∀ a i ∈ A T - A : m e a n ( a i )
C O S T A ⋃ b t e s t = ∑ j = 1 k C O S T A ⋃ b ( T j ) k
C O S T A t e s t = ∑ j = 1 k C O S T A ( T j ) k
(2)若C O S T A ∪ { b } t e s t ≤ C O S T A t e s t A = A ⋃ b
算法2的时间复杂度是O ( k ⋅ | U | 2 ⋅ | A T | 2 ) k 是交叉验证的折数,|U |是样本的总个数,|AT |是条件属性的总个数.算法2在传统启发式决策代价约简的基础上引入了交叉验证的思想,其目的是期望约简集合可以有效地降低测试集合总决策代价.
4 实验分析
为了验证所提算法的有效性,选择UCI上的八组数据集合进行了实验验证.这八组数据的基本描述如表2 所示.实验的硬件配置为Windows 10操作系统,2.50 GHz CPU, 8 G内存的个人计算机,用Matlab 2017a实现算法.
在邻域粗糙集的框架下,选择10个不同的半径,半径的值分别是0.03,0.06,…,0.30.为了对比所提算法的有效性,采用五折交叉验证.该方法的具体操作流程是:用分层抽样的方法尽可能保证数据分布的一致性,将样本集合中的样本平均分为五份,即U 1 ,U 2 ,…,U 5 ;第一次将U 2 ∪U 3 ∪U 4 ∪U 5 作为训练集,U 1 作为测试集,分别求得两种算法在该半径下的约简集合;……;第五次将U 1 ∪U 2 ∪U 3 ∪U 4 作为训练集,U 5 作为测试集,分别求得两种算法在该半径下的约简集合.
4.1 分类精度和约简长度对比
实验使用KNN分类器(K 值取5)、SVM分类器、CART分类器分别求解两种算法在测试集合上的分类精度,同时用对分类精度和约简长度取算术平均值方法求得最终实验结果,实验结果如表3 所示,表中黑体字表示较高的分类精度或者较大的约简长度.
(1)相比于算法1,算法2求解出来的属性子集具有更好的分类性能.在KNN,SVM,CART三种分类器上的求解出的分类精度均普遍高于算法1.
(2)相对于算法1,算法2求解出来的属性子集具有较多的属性.
4.2 总决策代价对比
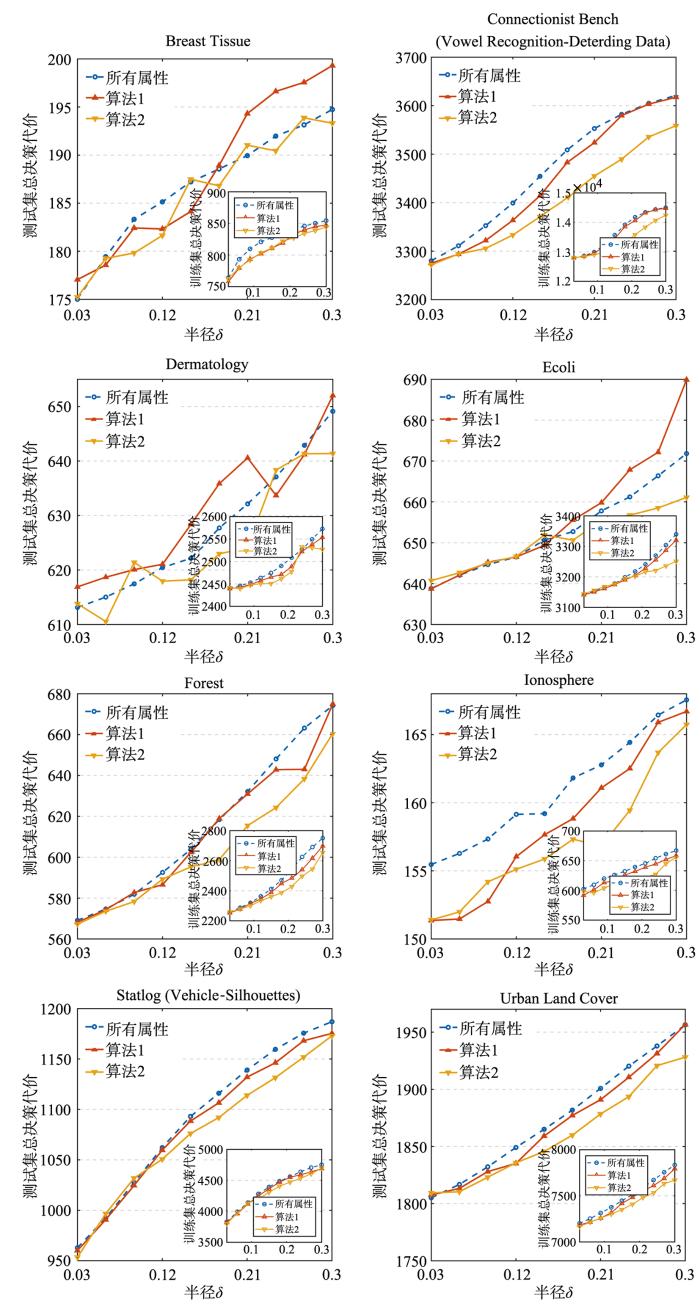
观察图1 ,不难发现,基于决策代价的启发式约简算法求解出的属性子集虽然在训练集合上可以有效地降低总决策代价,但当属性子集作用于测试集合时会出现不能有效降低总决策代价的情况.例如,数据集“Ecoli”在半径大于0.15时,基于决策代价的启发式约简算法求得的属性子集明显不能有效降低总决策代价.而相比于算法1,运用交叉验证思想的算法2求解出来的属性子集不仅进一步降低了训练集合的总决策代价,而且更加有效地降低了测试集合的决策总代价.
图1
图1
两种算法的总决策代价对比
Fig.1
Decision cost of two algorithms
此外,值得注意的是,根据图1 所示的结果,可以观察到:随着半径的增大,无论是利用所有属性,还是利用算法1或算法2所选择出来的属性子集,在训练样本以及测试样本上所求得的总决策代价都会相应地增加.这主要是因为随着半径的增大,决策粗糙集中的正域会进一步地缩减,而边界域和负域则会相应地扩张.又根据表1 ,边界域和负域中样本所对应的决策代价显然要大于正域样本所对应的决策代价,因此带来了总决策代价的增高.
4.3 时间消耗对比
从表4 和两种算法的时间复杂度可以看到,算法2求解约简的时间明显长于算法1,这主要是因为算法2在求解属性子集的时候将数据集分成k 部分,用交叉验证的方法会大幅度增加算法迭代次数,因此算法2具有较大的时间消耗.
5 结束语
决策粗糙集理论将粗糙集和代价敏感问题联系到一起,有效地丰富了粗糙集理论.基于决策代价的启发式约简算法,虽然具有较高的求解效率,但在测试集合上经常会出现不能有效地降低总决策代价的情况.鉴于此,结合交叉验证思想,本文基于决策代价设计了新的算法.通过实验对比分析可以看出,所提的新算法能够显著地降低测试集合的总决策代价,提高约简结果的分类精度.因而,基于交叉验证思想的决策代价约简算法是有效的.
在本文工作的基础上,笔者将就以下的问题进行进一步探讨:
(1)本文将交叉验证思想运用到基于决策代价的属性约简算法中,可以将该思想运用到其他约简算法当中,提高其他算法的有效性.
(2)虽然本文算法能有效降低测试集合的总决策代价,但是具有较大的时间消耗.笔者将进一步优化算法,减少算法的时间消耗.
参考文献
View Option
[1]
Pawlak Z Rough sets
International Journal of Computer & Information Sciences ,1982 ,11 (1 ):341 -356 .
[本文引用: 1]
[2]
Hu Q H Pan W W Zhang L et al Feature selection for monotonic classification
IEEE Transactions on Fuzzy Systems ,2012 ,20 (1 ):69 -81 .
[本文引用: 1]
[3]
Jia X Y Liao W H Tang Z M et al Minimum cost attribute reduction in decision⁃theoretic rough set models
Information Sciences ,2013 ,219 :151 -167 .
[本文引用: 1]
[4]
Min F Zhu W Attribute reduction of data with error ranges and test costs
Information Sciences ,2012 ,211 :48 -67 .
[本文引用: 1]
[5]
Qian Y H Cheng H H Wang J T et al Grouping granular structures in human granulation intelligence
Information Sciences ,2017 ,382-383 :150 -169 .
[本文引用: 1]
[6]
Hu Q H An S Yu D R Soft fuzzy rough sets for robust feature evaluation and selection
Informa⁃tion Sciences ,2010 ,180 (22 ):4384 -4400 .
[本文引用: 1]
[7]
Miao D Q Gao C Zhang N et al Diverse reduct subspaces based co⁃training for partially labeled data
International Journal of Approximate Reasoning ,2011 ,52 (8 ):1103 -1117 .
[本文引用: 1]
[8]
Chen Y F Yue X D Fujita H et al Three⁃way decision support for diagnosis on focal liver
[本文引用: 1]
lesions
Knowledge⁃Based Systems ,2017 ,127 :85 -99 .
[本文引用: 1]
[9]
Liu D Liang D C Wang C C A novel three⁃way decision model based on incomplete information system
Knowledge⁃Based Systems ,2016 ,91 :32 -45 .
[本文引用: 1]
[10]
Liu K Y Yang X B Yu H L et al Rough set based semi⁃supervised feature selection via ensemble selector
Knowledge⁃Based Systems ,2019 ,165 :282 -296 .
[本文引用: 1]
[11]
Song J J Tsang E C C Chen D G et al Minimal decision cost reduct in fuzzy decision⁃theoretic rough set model
Knowledge⁃Based Systems ,2017 ,126 :104 -112 .
[本文引用: 1]
[12]
Ju H R Li H X Yang X B et al Cost⁃sensitive rough set:a multi⁃granulation approach
Knowledge⁃Based Systems ,2017 ,123 :137 -153 .
[本文引用: 1]
[13]
Yao Y Y Zhang X Y Class⁃specific attribute reducts in rough set theory
Information Sciences ,2017 ,418-419 :601 -618 .
[本文引用: 1]
[14]
李智远 ,杨习贝 ,徐苏平 等 邻域决策一致性的属性约简方法研究
河南师范大学学报(自然科学版) ,2017 ,45 (5 ):68 -73 .
[本文引用: 1]
Li Z Y,Yang X B,Xu S P,et al .Attribute reduction approach to neighbor⁃hood decision agreement.
Journal of Henan Normal University (Natural Science Edition) ,2017 ,45 (5 ):68 -73 .
[本文引用: 1]
[15]
李智远 ,杨习贝 ,陈向坚 等 类别近似质量约束下的属性约简方法研究
河南师范大学学报(自然科学版) ,2018 ,46 (3 ):112 -118 .
[本文引用: 1]
Li Z Y,Yang X B,Chen X J,et al .Attribute reduction constrained by class⁃specific approximate quality.
Journal of Henan Normal University (Natural Science Edition) ,2018 ,46 (3 ):112 -118 .
[本文引用: 1]
[16]
杨习贝 ,徐苏平 ,戚湧 等 基于多特征空间的粗糙数据分析方法
江苏科技大学学报(自然科学版) ,2016 ,30 (4 ):370 -373 .
[本文引用: 1]
Yang X B,Xu S P,Qi Y,et al .Rough data analysis method based on multi⁃feature space.
Journal of Jiangsu University of Science and Technology ,2016 ,30 (4 ):370 -373 .
[本文引用: 1]
[17]
李华雄 ,刘盾 ,周献中 决策粗糙集模型研究综述
重庆邮电大学学报(自然科学版) ,2010 ,22 (5 ):624 -630 .
[本文引用: 1]
Li H X,Liu D,Zhou X Z .Review on decision⁃theoretic rough set model.
Pattern Recognition &Artificial IntelligenceJournal of Chongqing University of Posts and Telecommuni⁃cations (Natural Science Edition) ,2010 ,22 (5 ):624 -630 .
[本文引用: 1]
[18]
Yao Y Y Wong S K M Lingras P A decision⁃theoretic rough set model∥Ras Z W,Zemankova M,Emrich M L
Methodologies for Intelligent Systems. New York :North⁃Holland ,1990 :17 -25 .
[本文引用: 2]
[19]
杨习贝 ,戚湧 ,宋晓宁 等 决策单调约简的启示
琼州学院学报 ,2014 ,21 (5 ):17 -25 .
[本文引用: 1]
Yang X B,Qi Y,Song X N,et al .Inspiration of decision⁃monotonicity reduct.
Journal of Qiongzhou University ,2014 ,21 (5 ):17 -25 .
[本文引用: 1]
[20]
Li J Z Chen X J Wang P X et al Local view based cost⁃sensitive attribute reduction
Filomat ,2018 ,32 (5 ):1817 -1822 .
[本文引用: 1]
[21]
Min F He H P Qian Y H et al Test⁃cost⁃sensitive attribute reduction
Information Sciences ,2011 ,181 (22 ):4928 -4942 .
[本文引用: 1]
[22]
Yang X B Qi Y S Song X N et al Test cost sensitive multigranulation rough set:model and minimal cost selection
Information Sciences ,2013 ,250 :184 -199 .
[本文引用: 1]
[23]
杨习贝 ,颜旭 ,徐苏平 等 基于样本选择的启发式属性约简方法研究
计算机科学 ,2016 ,43 (1 ):40 -43 .
[本文引用: 1]
Yang X B,Yan X,Xu S P,et al .New heuristic attribute reduction algorithm based on sample selection.
Computer Science ,2016 ,43 (1 ):40 -43 .
[本文引用: 1]
[24]
Xu S P Yang X B Yu H L et al Multi⁃label learning with label⁃specific feature reduction
Knowledge Based Systems ,2016 ,104 :52 -61 .
[本文引用: 1]
[25]
Jiang G X Wang W J Markov cross⁃validation for time series model evaluations
Information Sciences ,2017 ,375 :219 -233 .
[本文引用: 1]
[26]
Hu Q H Yu D R Xie Z X Neighborhood classifiers
Expert Systems with Applications ,2008 ,34 (2 ):866 -876 .
[本文引用: 1]
Rough sets
1
1982
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
Feature selection for monotonic classification
1
2012
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
Minimum cost attribute reduction in decision?theoretic rough set models
1
2013
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
Attribute reduction of data with error ranges and test costs
1
2012
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
Grouping granular structures in human granulation intelligence
1
2017
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
Soft fuzzy rough sets for robust feature evaluation and selection
1
2010
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
Diverse reduct subspaces based co?training for partially labeled data
1
2011
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
lesions
1
2017
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
lesions
1
2017
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
A novel three?way decision model based on incomplete information system
1
2016
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
Rough set based semi?supervised feature selection via ensemble selector
1
2019
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
Minimal decision cost reduct in fuzzy decision?theoretic rough set model
1
2017
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
Cost?sensitive rough set:a multi?granulation approach
1
2017
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
Class?specific attribute reducts in rough set theory
1
2017
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
邻域决策一致性的属性约简方法研究
1
2017
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
邻域决策一致性的属性约简方法研究
1
2017
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
类别近似质量约束下的属性约简方法研究
1
2018
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
类别近似质量约束下的属性约简方法研究
1
2018
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
基于多特征空间的粗糙数据分析方法
1
2016
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
基于多特征空间的粗糙数据分析方法
1
2016
... 粗糙集理论[1 ] 是波兰学者Pawlak提出的一种处理不确定、不精确信息系统的数学工具,被广泛地应用于机器学习[2 ,3 ,4 ] 、粒计算[5 ] 、模式识别[6 ,7 ] 和知识发现[8 ,9 ] 等领域.属性约简[10 ,11 ,12 ,13 ,14 ,15 ,16 ] 作为一种数据处理的方法,是粗糙集理论中的核心问题.通过属性约简,不仅可以从数据集中剔除冗余属性来获得更简洁的规则,而且相对于其他特征选择方法,所求得的特征子集往往具有明确的语义解释. ...
决策粗糙集模型研究综述
1
2010
... Pawlak粗糙集模型在容错能力上的缺陷[17 ] 逐渐引起了广大学者的注意.为了克服这一缺陷,加拿大学者Yao et al[18 ] 提出了基于贝叶斯风险分析的决策粗糙集模型.该模型主要有两大优势[19 ] :(1)决策粗糙集模型重新定义粗糙集的正域、边界域和负域,给予传统粗糙集模型全新的解释,丰富了传统决策方法;(2)决策粗糙集理论通过构建代价矩阵获取概率粗糙集所需要的一对阈值,引入损失函数,将粗糙集方法和代价敏感问题联系到一起. ...
决策粗糙集模型研究综述
1
2010
... Pawlak粗糙集模型在容错能力上的缺陷[17 ] 逐渐引起了广大学者的注意.为了克服这一缺陷,加拿大学者Yao et al[18 ] 提出了基于贝叶斯风险分析的决策粗糙集模型.该模型主要有两大优势[19 ] :(1)决策粗糙集模型重新定义粗糙集的正域、边界域和负域,给予传统粗糙集模型全新的解释,丰富了传统决策方法;(2)决策粗糙集理论通过构建代价矩阵获取概率粗糙集所需要的一对阈值,引入损失函数,将粗糙集方法和代价敏感问题联系到一起. ...
A decision?theoretic rough set model∥Ras Z W,Zemankova M,Emrich M L
2
1990
... Pawlak粗糙集模型在容错能力上的缺陷[17 ] 逐渐引起了广大学者的注意.为了克服这一缺陷,加拿大学者Yao et al[18 ] 提出了基于贝叶斯风险分析的决策粗糙集模型.该模型主要有两大优势[19 ] :(1)决策粗糙集模型重新定义粗糙集的正域、边界域和负域,给予传统粗糙集模型全新的解释,丰富了传统决策方法;(2)决策粗糙集理论通过构建代价矩阵获取概率粗糙集所需要的一对阈值,引入损失函数,将粗糙集方法和代价敏感问题联系到一起. ...
... 经典的决策粗糙集理论是建立在两个状态与三个行动基础上[18 ] 的.一般的,定义状态集合Ω ={X ,~X }表示两种状态:对象x 属于集合X 和对象x 不属于集合X ;定义行动集A ={aP ,aB ,aN },aP ,aB ,aN 分别表示对象x 属于集合X 的正域、边界域、负域.此时,若考虑对象x 属于某个状态时,做出某个动作所需的代价函数值,则可以定义如下表1 所示的代价矩阵. ...
决策单调约简的启示
1
2014
... Pawlak粗糙集模型在容错能力上的缺陷[17 ] 逐渐引起了广大学者的注意.为了克服这一缺陷,加拿大学者Yao et al[18 ] 提出了基于贝叶斯风险分析的决策粗糙集模型.该模型主要有两大优势[19 ] :(1)决策粗糙集模型重新定义粗糙集的正域、边界域和负域,给予传统粗糙集模型全新的解释,丰富了传统决策方法;(2)决策粗糙集理论通过构建代价矩阵获取概率粗糙集所需要的一对阈值,引入损失函数,将粗糙集方法和代价敏感问题联系到一起. ...
决策单调约简的启示
1
2014
... Pawlak粗糙集模型在容错能力上的缺陷[17 ] 逐渐引起了广大学者的注意.为了克服这一缺陷,加拿大学者Yao et al[18 ] 提出了基于贝叶斯风险分析的决策粗糙集模型.该模型主要有两大优势[19 ] :(1)决策粗糙集模型重新定义粗糙集的正域、边界域和负域,给予传统粗糙集模型全新的解释,丰富了传统决策方法;(2)决策粗糙集理论通过构建代价矩阵获取概率粗糙集所需要的一对阈值,引入损失函数,将粗糙集方法和代价敏感问题联系到一起. ...
Local view based cost?sensitive attribute reduction
1
2018
... 近年来,以代价敏感[20 ] 为基础的属性约简问题越来越受到粗糙集学者的关注,他们将各式各样的策略运用到基于代价敏感的属性约简问题当中.相对于时间复杂度较高的穷举法[21 ,22 ] ,基于适应度函数的启发式搜索方法[23 ,24 ] 因具有较高的求解速度和普适性,被广泛地运用到面向代价敏感的属性约简问题中,但值得注意的是,根据启发式方法搜索出的属性子集往往仅能降低训练样本集上的决策代价,但却未必能够有效地保证测试样本集上的决策代价也能够被降低.鉴于此,本文试图将交叉验证[25 ,26 ] 的思想引入到属性约简当中,其目的是在训练样本集上的搜索进程中设置一个早停止策略,一旦决策代价不能够被降低了,则立即停止搜索.这一模式在训练样本集上模拟了测试样本的代价变化情况,证明它不仅进一步降低了训练集合的决策代价,而且能有效地测试集合的决策代价,从代价敏感的角度提高了属性子集的泛化能力. ...
Test?cost?sensitive attribute reduction
1
2011
... 近年来,以代价敏感[20 ] 为基础的属性约简问题越来越受到粗糙集学者的关注,他们将各式各样的策略运用到基于代价敏感的属性约简问题当中.相对于时间复杂度较高的穷举法[21 ,22 ] ,基于适应度函数的启发式搜索方法[23 ,24 ] 因具有较高的求解速度和普适性,被广泛地运用到面向代价敏感的属性约简问题中,但值得注意的是,根据启发式方法搜索出的属性子集往往仅能降低训练样本集上的决策代价,但却未必能够有效地保证测试样本集上的决策代价也能够被降低.鉴于此,本文试图将交叉验证[25 ,26 ] 的思想引入到属性约简当中,其目的是在训练样本集上的搜索进程中设置一个早停止策略,一旦决策代价不能够被降低了,则立即停止搜索.这一模式在训练样本集上模拟了测试样本的代价变化情况,证明它不仅进一步降低了训练集合的决策代价,而且能有效地测试集合的决策代价,从代价敏感的角度提高了属性子集的泛化能力. ...
Test cost sensitive multigranulation rough set:model and minimal cost selection
1
2013
... 近年来,以代价敏感[20 ] 为基础的属性约简问题越来越受到粗糙集学者的关注,他们将各式各样的策略运用到基于代价敏感的属性约简问题当中.相对于时间复杂度较高的穷举法[21 ,22 ] ,基于适应度函数的启发式搜索方法[23 ,24 ] 因具有较高的求解速度和普适性,被广泛地运用到面向代价敏感的属性约简问题中,但值得注意的是,根据启发式方法搜索出的属性子集往往仅能降低训练样本集上的决策代价,但却未必能够有效地保证测试样本集上的决策代价也能够被降低.鉴于此,本文试图将交叉验证[25 ,26 ] 的思想引入到属性约简当中,其目的是在训练样本集上的搜索进程中设置一个早停止策略,一旦决策代价不能够被降低了,则立即停止搜索.这一模式在训练样本集上模拟了测试样本的代价变化情况,证明它不仅进一步降低了训练集合的决策代价,而且能有效地测试集合的决策代价,从代价敏感的角度提高了属性子集的泛化能力. ...
基于样本选择的启发式属性约简方法研究
1
2016
... 近年来,以代价敏感[20 ] 为基础的属性约简问题越来越受到粗糙集学者的关注,他们将各式各样的策略运用到基于代价敏感的属性约简问题当中.相对于时间复杂度较高的穷举法[21 ,22 ] ,基于适应度函数的启发式搜索方法[23 ,24 ] 因具有较高的求解速度和普适性,被广泛地运用到面向代价敏感的属性约简问题中,但值得注意的是,根据启发式方法搜索出的属性子集往往仅能降低训练样本集上的决策代价,但却未必能够有效地保证测试样本集上的决策代价也能够被降低.鉴于此,本文试图将交叉验证[25 ,26 ] 的思想引入到属性约简当中,其目的是在训练样本集上的搜索进程中设置一个早停止策略,一旦决策代价不能够被降低了,则立即停止搜索.这一模式在训练样本集上模拟了测试样本的代价变化情况,证明它不仅进一步降低了训练集合的决策代价,而且能有效地测试集合的决策代价,从代价敏感的角度提高了属性子集的泛化能力. ...
基于样本选择的启发式属性约简方法研究
1
2016
... 近年来,以代价敏感[20 ] 为基础的属性约简问题越来越受到粗糙集学者的关注,他们将各式各样的策略运用到基于代价敏感的属性约简问题当中.相对于时间复杂度较高的穷举法[21 ,22 ] ,基于适应度函数的启发式搜索方法[23 ,24 ] 因具有较高的求解速度和普适性,被广泛地运用到面向代价敏感的属性约简问题中,但值得注意的是,根据启发式方法搜索出的属性子集往往仅能降低训练样本集上的决策代价,但却未必能够有效地保证测试样本集上的决策代价也能够被降低.鉴于此,本文试图将交叉验证[25 ,26 ] 的思想引入到属性约简当中,其目的是在训练样本集上的搜索进程中设置一个早停止策略,一旦决策代价不能够被降低了,则立即停止搜索.这一模式在训练样本集上模拟了测试样本的代价变化情况,证明它不仅进一步降低了训练集合的决策代价,而且能有效地测试集合的决策代价,从代价敏感的角度提高了属性子集的泛化能力. ...
Multi?label learning with label?specific feature reduction
1
2016
... 近年来,以代价敏感[20 ] 为基础的属性约简问题越来越受到粗糙集学者的关注,他们将各式各样的策略运用到基于代价敏感的属性约简问题当中.相对于时间复杂度较高的穷举法[21 ,22 ] ,基于适应度函数的启发式搜索方法[23 ,24 ] 因具有较高的求解速度和普适性,被广泛地运用到面向代价敏感的属性约简问题中,但值得注意的是,根据启发式方法搜索出的属性子集往往仅能降低训练样本集上的决策代价,但却未必能够有效地保证测试样本集上的决策代价也能够被降低.鉴于此,本文试图将交叉验证[25 ,26 ] 的思想引入到属性约简当中,其目的是在训练样本集上的搜索进程中设置一个早停止策略,一旦决策代价不能够被降低了,则立即停止搜索.这一模式在训练样本集上模拟了测试样本的代价变化情况,证明它不仅进一步降低了训练集合的决策代价,而且能有效地测试集合的决策代价,从代价敏感的角度提高了属性子集的泛化能力. ...
Markov cross?validation for time series model evaluations
1
2017
... 近年来,以代价敏感[20 ] 为基础的属性约简问题越来越受到粗糙集学者的关注,他们将各式各样的策略运用到基于代价敏感的属性约简问题当中.相对于时间复杂度较高的穷举法[21 ,22 ] ,基于适应度函数的启发式搜索方法[23 ,24 ] 因具有较高的求解速度和普适性,被广泛地运用到面向代价敏感的属性约简问题中,但值得注意的是,根据启发式方法搜索出的属性子集往往仅能降低训练样本集上的决策代价,但却未必能够有效地保证测试样本集上的决策代价也能够被降低.鉴于此,本文试图将交叉验证[25 ,26 ] 的思想引入到属性约简当中,其目的是在训练样本集上的搜索进程中设置一个早停止策略,一旦决策代价不能够被降低了,则立即停止搜索.这一模式在训练样本集上模拟了测试样本的代价变化情况,证明它不仅进一步降低了训练集合的决策代价,而且能有效地测试集合的决策代价,从代价敏感的角度提高了属性子集的泛化能力. ...
Neighborhood classifiers
1
2008
... 近年来,以代价敏感[20 ] 为基础的属性约简问题越来越受到粗糙集学者的关注,他们将各式各样的策略运用到基于代价敏感的属性约简问题当中.相对于时间复杂度较高的穷举法[21 ,22 ] ,基于适应度函数的启发式搜索方法[23 ,24 ] 因具有较高的求解速度和普适性,被广泛地运用到面向代价敏感的属性约简问题中,但值得注意的是,根据启发式方法搜索出的属性子集往往仅能降低训练样本集上的决策代价,但却未必能够有效地保证测试样本集上的决策代价也能够被降低.鉴于此,本文试图将交叉验证[25 ,26 ] 的思想引入到属性约简当中,其目的是在训练样本集上的搜索进程中设置一个早停止策略,一旦决策代价不能够被降低了,则立即停止搜索.这一模式在训练样本集上模拟了测试样本的代价变化情况,证明它不仅进一步降低了训练集合的决策代价,而且能有效地测试集合的决策代价,从代价敏感的角度提高了属性子集的泛化能力. ...



{kind=link}
{kind=link}