In Chinese Spelling Correction (CSC) tasks,there are often problems such as insufficient semantic understanding of sentences and less use of phonetic and visual information of Chinese characters. Addressing these issues,we propose a novel error correction method based on context confidence and Chinese character similarity for Chinese spelling error correction (ECS). Based on deep learning principles,this approach integrates visual similarity of Chinese characters,and phonetic similarity of Chinese characters,and a fine⁃tuned pre⁃trained BERT model,which automatically extracts sentence semantics and exploits the similarity of Chinese characters. Specifically,we fine⁃tune the pre⁃trained Chinese BERT model to adapt to downstream Chinese spelling correction tasks. Then,we use the ideographic description sequence to capture the tree structure of Chinese characters as visual information and the phonetic sequence of Chinese characters as phonetic information. Finally,combining the visual and phonetic similarity (calculated by Levenshtein distance) of Chinese characters with the fine⁃tuned BERT model,we achieve the completion of the correction task. Experimental results on SIGHAN benchmark datasets show that the proposed ECS method has a huge improvement in F1⁃score compared with the baseline model,which is 2.1% higher on the error detection level and 2.8% higher on the error correction level,verifying the applicability of the fusion of context information,visual information and phonetic information for Chinese spelling correction tasks.
Keywords:Chinese spelling correction
;
BERT
;
phonological similarity of Chinese characters
;
visual similarity of Chinese characters
;
pretrained model
Liu Changchun, Zhang Kai, Bao Meikai, Liu Ye, Liu Qi. Research on Chinese spelling correction based on the integration of context and text structure. Journal of nanjing University[J], 2024, 60(3): 451-463 doi:10.13232/j.cnki.jnju.2024.03.009
随着计算机计算能力的不断提升和大数据时代下数据的不断丰富,以深度学习为代表的各种模型算法层出不穷,和传统机器学习相比,这些模型大大提升了对特定任务的效果,并逐渐成为主流的机器学习算法.例如,Li et al[7]利用Transformer设计了检错网络和纠错网络,仅纠正被检错网络遮盖的字.Hong et al[8]利用预训练的BERT,采用特殊的数据遮罩模式对数据进行遮罩,并对模型进行微调,将模型输出的置信度与汉字的视觉与语音相似度相结合,拟合二者曲线来寻找最优解.Wang et al[9]提出一种基于指针网络的复制机制来减少搜索空间并提高生成正确字的概率,同时,还利用混淆集来确保生成的字只能在混淆集中,而不是在整个词表中.Cheng et al[10]利用图卷积网络来提取汉字的语义,并将图卷积网络的输出作为预训练模型输出结果的分类器.
Li et al[11]提出一种基于字符替换的方法,鼓励模型探索看不见的拼写错误,创建大型伪数据来训练模型.Zhang et al[12]发现了预训练模型检错能力的不足,并提出检错网络与纠错网络架构,利用Bi⁃GRU (Gate Recurrent Unit)作为检错网络,将soft⁃mask的检错结果输入BERT组成的纠错网络.Liu et al[13]利用GRU获得汉字的语音与视觉编码,加入词嵌入并利用预训练中文模型RoBERTa来进行预测,最后通过预测拼音和汉字并进行联合优化来进行纠错.Wang et al[14]将语音加入词嵌入并利用动态规划算法和语音相似性来解决以往预测中预测词语不连贯的问题.Liu et al[15]为了解决错别字给句子带来的噪声,在预训练时给每个训练样本构造一个噪声上下文,然后修正模型被迫产生相似的基于噪声和原始上下文的输出.为了解决过度纠正问题还提出了复制机制,如Zhang et al[16]将语音相似性融入预训练过程,用语音相似的单词替换原单词,并利用嵌入的拼音和预训练模型一起改正错误.
Guo et al[17]针对以往方法没有考虑句子中的错误词对句子表征及纠错任务的影响,训练了一个针对纠错任务的预训练语言模型BERT_CRS,提出全局注意力解码器(Global Attention Decoder,GAD)方法来学习输入句子中正确字符和错误字符候选集之间的关联关系,减轻局部错误的上下文影响.Bao et al[18]提出基于组块解码的方法,以单字、多字词、短语、成语为组块,利用全局优化修改单字和多字词错误,结合发音、字形、语义混淆集来处理多种不同的错误.Xu et al[19]使用文本、声音、视觉三个编码器来学习信息表示,采用BERT作为语义编码器的主干来捕获文本信息,使用分层编码器处理字符级和句子拼音字母,使用ResNet对图像进行分块编码,构建了多通道字符图像作为图形特征,得到字符图形标识.Huang et al[20]分别利用VGG19,TTS和BERT模型来获取汉字的视觉、语音和语义信息,并联合三者信息进行纠错.Ji et al[21]同样利用视觉和语音信息,分别采用部首偏旁信息,将整个拼音视为整体而非序列,并利用图网络进行信息融合.
Wang and Shang[22]针对连续错误会改变语义导致无法有效提取语义的问题,提出基于混淆集生成多个候选句子来改正错误.Zhu et al[23]基于Transformer和BERT设计一个多任务的网络修正模型,保留错误字的信息,使预测更准确.Yang and Yu[24]通过复制机制来解决BERT过度纠正的问题,并将注意力机制用于提取汉字的语音与形状信息.Bao et al[25]利用Bi⁃GRU编码汉字语音信息,利用表意文字序列(Ideographic Description Characters,IDS)编码汉字结构信息,多通道融合进行纠错.Zhao et al[26]利用视觉转换器、GRU+CNN和BERT分别提取字形、拼音和语义特征,并对三种嵌入进行平均来生成最终的多模态表示,送入Transfomer进行纠正.Li et al[27]认为错误的拼写会导致错误的分词,提出在嵌入层加入分词信息并加以训练来提高分词正确率,提升模型效果.Li et al[28]引入汉语语音预测辅助任务来改进汉语语音识别,并首次系统讨论了该辅助任务的自适应性和粒度问题.Sun et al[29]提出一种错误检测方法,引导模型更多地关注编码过程中可能出现的错误标记,并引入一个新的损失函数来整合错误混淆集,使模型能区分容易被误用的词语.Li[30]提出一个名为uChecker的框架来进行无监督拼写错误检测和纠正,还提出一种混淆集引导掩蔽策略来精细训练掩蔽语言模型,以进一步提高无监督检测和校正的性能.Jiang et al[31]定义了医学领域中文拼写纠正(Medical CSC,MCSC)的任务,并提出MCSCSet,这是一个包含大约20万个样本的大规模专家注释数据集,还论证了开放领域和医学领域的拼写纠正之间存在的显著差距.Sun et al[32]提出一种新的基于知识图谱的纠错方法,从知识图谱中查询三元组,并将查询到的三元组作为领域知识注入句子,使模型具有推理能力和常识.
SIGHAN数据集是中国台湾学者公开的用于中文文本纠错任务的数据集,其测试集已成为中文拼写纠错领域中判断模型好坏的基准数据集.SIGHAN目前包含三个版本,分别是SIGHAN13,SIGHAN14,SIGHAN15,其数据量如表3所示.但其存在一些问题,首先,这个数据集中的句子都由繁体字组成,而目前主流的中文拼写纠错任务是基于简体字来完成的,所以本文利用Open Chinese Convert (OpenCC)工具包将其转换为简体字.此外,SIGHAN数据集还有很多不一致的地方,包括编码问题、句子编号对不上、标签问题等,但这些错误的量不大,较易修复.为了解决SIGHAN数据集中的不一致问题,可以根据其特点,使用基于规则的方法进行简单修复,方便后面的实验.
Confusionset⁃guided pointer networks for Chinese spelling check
∥Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence,Italy:Association for Computational Linguistics,2019:5780-5785.
SpellGCN:Incorporating phonological and visual similarities into language models for Chinese spelling check
∥Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Seattle,WA,USA:Association for Computational Linguistics,2020:871-881.
Exploration and exploitation:Two ways to improve Chinese spelling correction models
∥Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Confe⁃rence on Natural Language Processing. Online:Association for Computational Linguistics,2021:441-446.
∥Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online:Association for Compu⁃tational Linguistics,2020:882-890.
PLOME:Pre⁃training with misspelled knowledge for Chinese spelling correction
∥Proceedings of the 59th Annual Meeting of the Association for Computational Linguis⁃tics and the 11th International Joint Conference on Natural Language Processing. Online:Association for Computational Linguistics,2021:2991-3000.
PHMOSpell:Phonological and morphological knowledge guided Chinese spelling check
∥Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Online:Association for Computational Linguistics,2021:5958-5967.
WSpeller:Robust word segmentation for enhancing Chinese spelling check
∥Findings of the Association for Computational Linguistics:EMNLP 2022. Abu Dhabi,United Arab Emirates:Association for Computational Linguistics,2022:1179-1188.
Improving Chinese spelling check by character pronunciation prediction:The effects of adaptivity and granularity
∥Proceedings of 2022 Conference on Empirical Methods in Natural Language Processing. Abu Dhabi,United Arab Emirates:Association for Computational Linguistics,2022:4275-4286.
An error⁃guided correction model for Chinese spelling error correction
∥Findings of the Association for Computational Linguistics:EMNLP 2022. Abu Dhabi,United Arab Emirates:Association for Computational Linguistics,2022:3800-3810.
uChecker:Masked pretrained language models as unsupervised Chinese spelling checkers
∥Proceedings of the 29th International Conference on Computational Linguistics. Gyeongju,Republic of Korea:Association for Computational Linguistics,2022:2812-2822.
Chinese spelling error detection and correction based on knowledge graph
∥Database Systems for Advanced Applications. DASFAA 2022 International Workshops:BDMS,BDQM,GDMA,IWBT,MAQTDS,and PMBD. Springer Berlin Heidelberg,2022:149-159.
A hybrid approach to automatic corpus generation for Chinese spelling check
∥Proceedings of 2018 Conference on Empirical Methods in Natural Language Processing. Brussels,Belgium:Association for Computational Linguistics,2018:2517-2527.
DCSpell:A detector?corrector framework for Chinese spelling error correction
1
2021
... 随着计算机计算能力的不断提升和大数据时代下数据的不断丰富,以深度学习为代表的各种模型算法层出不穷,和传统机器学习相比,这些模型大大提升了对特定任务的效果,并逐渐成为主流的机器学习算法.例如,Li et al[7]利用Transformer设计了检错网络和纠错网络,仅纠正被检错网络遮盖的字.Hong et al[8]利用预训练的BERT,采用特殊的数据遮罩模式对数据进行遮罩,并对模型进行微调,将模型输出的置信度与汉字的视觉与语音相似度相结合,拟合二者曲线来寻找最优解.Wang et al[9]提出一种基于指针网络的复制机制来减少搜索空间并提高生成正确字的概率,同时,还利用混淆集来确保生成的字只能在混淆集中,而不是在整个词表中.Cheng et al[10]利用图卷积网络来提取汉字的语义,并将图卷积网络的输出作为预训练模型输出结果的分类器. ...
FASPell:A fast,adaptable,simple,powerful Chinese spell checker based on DAE?decoder paradigm
1
2019
... 随着计算机计算能力的不断提升和大数据时代下数据的不断丰富,以深度学习为代表的各种模型算法层出不穷,和传统机器学习相比,这些模型大大提升了对特定任务的效果,并逐渐成为主流的机器学习算法.例如,Li et al[7]利用Transformer设计了检错网络和纠错网络,仅纠正被检错网络遮盖的字.Hong et al[8]利用预训练的BERT,采用特殊的数据遮罩模式对数据进行遮罩,并对模型进行微调,将模型输出的置信度与汉字的视觉与语音相似度相结合,拟合二者曲线来寻找最优解.Wang et al[9]提出一种基于指针网络的复制机制来减少搜索空间并提高生成正确字的概率,同时,还利用混淆集来确保生成的字只能在混淆集中,而不是在整个词表中.Cheng et al[10]利用图卷积网络来提取汉字的语义,并将图卷积网络的输出作为预训练模型输出结果的分类器. ...
Confusionset?guided pointer networks for Chinese spelling check
4
2019
... 随着计算机计算能力的不断提升和大数据时代下数据的不断丰富,以深度学习为代表的各种模型算法层出不穷,和传统机器学习相比,这些模型大大提升了对特定任务的效果,并逐渐成为主流的机器学习算法.例如,Li et al[7]利用Transformer设计了检错网络和纠错网络,仅纠正被检错网络遮盖的字.Hong et al[8]利用预训练的BERT,采用特殊的数据遮罩模式对数据进行遮罩,并对模型进行微调,将模型输出的置信度与汉字的视觉与语音相似度相结合,拟合二者曲线来寻找最优解.Wang et al[9]提出一种基于指针网络的复制机制来减少搜索空间并提高生成正确字的概率,同时,还利用混淆集来确保生成的字只能在混淆集中,而不是在整个词表中.Cheng et al[10]利用图卷积网络来提取汉字的语义,并将图卷积网络的输出作为预训练模型输出结果的分类器. ...
... Wang et al[9]提出基于指针网络的复制机制方法(PN),同时利用混淆集使生成的字只能在混淆集中而不是在整个词表中,从而减少搜索空间并提高生成正确字的概率. ...
... Test results of ECS and benchmark method on the SIGHAN datasetTable 5
模型
检错层面
纠错层面
Acc
P
R
F1⁃score
Acc
P
R
F1⁃score
ECS
77.6%
80.2%
68.8%
74.1%
76.3%
77.7%
66.7%
71.8%
LMC[34]
(-)
73.3%
37.0%
49.2%
(-)
72.1%
34.9%
46.8%
SL[33]
(-)
54.2%
68.3%
60.4%
(-)
(-)
(-)
55.1%
PN[9]
(-)
62.3%
82.3%
72.0%
(-)
76.8%
62.6%
69.0%
ChatGPT在SIGHAN15上的纠错效果 ...
SpellGCN:Incorporating phonological and visual similarities into language models for Chinese spelling check
1
2020
... 随着计算机计算能力的不断提升和大数据时代下数据的不断丰富,以深度学习为代表的各种模型算法层出不穷,和传统机器学习相比,这些模型大大提升了对特定任务的效果,并逐渐成为主流的机器学习算法.例如,Li et al[7]利用Transformer设计了检错网络和纠错网络,仅纠正被检错网络遮盖的字.Hong et al[8]利用预训练的BERT,采用特殊的数据遮罩模式对数据进行遮罩,并对模型进行微调,将模型输出的置信度与汉字的视觉与语音相似度相结合,拟合二者曲线来寻找最优解.Wang et al[9]提出一种基于指针网络的复制机制来减少搜索空间并提高生成正确字的概率,同时,还利用混淆集来确保生成的字只能在混淆集中,而不是在整个词表中.Cheng et al[10]利用图卷积网络来提取汉字的语义,并将图卷积网络的输出作为预训练模型输出结果的分类器. ...
Exploration and exploitation:Two ways to improve Chinese spelling correction models
1
2021
... Li et al[11]提出一种基于字符替换的方法,鼓励模型探索看不见的拼写错误,创建大型伪数据来训练模型.Zhang et al[12]发现了预训练模型检错能力的不足,并提出检错网络与纠错网络架构,利用Bi⁃GRU (Gate Recurrent Unit)作为检错网络,将soft⁃mask的检错结果输入BERT组成的纠错网络.Liu et al[13]利用GRU获得汉字的语音与视觉编码,加入词嵌入并利用预训练中文模型RoBERTa来进行预测,最后通过预测拼音和汉字并进行联合优化来进行纠错.Wang et al[14]将语音加入词嵌入并利用动态规划算法和语音相似性来解决以往预测中预测词语不连贯的问题.Liu et al[15]为了解决错别字给句子带来的噪声,在预训练时给每个训练样本构造一个噪声上下文,然后修正模型被迫产生相似的基于噪声和原始上下文的输出.为了解决过度纠正问题还提出了复制机制,如Zhang et al[16]将语音相似性融入预训练过程,用语音相似的单词替换原单词,并利用嵌入的拼音和预训练模型一起改正错误. ...
Spelling error correction with soft?masked BERT
1
2020
... Li et al[11]提出一种基于字符替换的方法,鼓励模型探索看不见的拼写错误,创建大型伪数据来训练模型.Zhang et al[12]发现了预训练模型检错能力的不足,并提出检错网络与纠错网络架构,利用Bi⁃GRU (Gate Recurrent Unit)作为检错网络,将soft⁃mask的检错结果输入BERT组成的纠错网络.Liu et al[13]利用GRU获得汉字的语音与视觉编码,加入词嵌入并利用预训练中文模型RoBERTa来进行预测,最后通过预测拼音和汉字并进行联合优化来进行纠错.Wang et al[14]将语音加入词嵌入并利用动态规划算法和语音相似性来解决以往预测中预测词语不连贯的问题.Liu et al[15]为了解决错别字给句子带来的噪声,在预训练时给每个训练样本构造一个噪声上下文,然后修正模型被迫产生相似的基于噪声和原始上下文的输出.为了解决过度纠正问题还提出了复制机制,如Zhang et al[16]将语音相似性融入预训练过程,用语音相似的单词替换原单词,并利用嵌入的拼音和预训练模型一起改正错误. ...
PLOME:Pre?training with misspelled knowledge for Chinese spelling correction
1
2021
... Li et al[11]提出一种基于字符替换的方法,鼓励模型探索看不见的拼写错误,创建大型伪数据来训练模型.Zhang et al[12]发现了预训练模型检错能力的不足,并提出检错网络与纠错网络架构,利用Bi⁃GRU (Gate Recurrent Unit)作为检错网络,将soft⁃mask的检错结果输入BERT组成的纠错网络.Liu et al[13]利用GRU获得汉字的语音与视觉编码,加入词嵌入并利用预训练中文模型RoBERTa来进行预测,最后通过预测拼音和汉字并进行联合优化来进行纠错.Wang et al[14]将语音加入词嵌入并利用动态规划算法和语音相似性来解决以往预测中预测词语不连贯的问题.Liu et al[15]为了解决错别字给句子带来的噪声,在预训练时给每个训练样本构造一个噪声上下文,然后修正模型被迫产生相似的基于噪声和原始上下文的输出.为了解决过度纠正问题还提出了复制机制,如Zhang et al[16]将语音相似性融入预训练过程,用语音相似的单词替换原单词,并利用嵌入的拼音和预训练模型一起改正错误. ...
Dynamic connected networks for Chinese spelling check
1
2021
... Li et al[11]提出一种基于字符替换的方法,鼓励模型探索看不见的拼写错误,创建大型伪数据来训练模型.Zhang et al[12]发现了预训练模型检错能力的不足,并提出检错网络与纠错网络架构,利用Bi⁃GRU (Gate Recurrent Unit)作为检错网络,将soft⁃mask的检错结果输入BERT组成的纠错网络.Liu et al[13]利用GRU获得汉字的语音与视觉编码,加入词嵌入并利用预训练中文模型RoBERTa来进行预测,最后通过预测拼音和汉字并进行联合优化来进行纠错.Wang et al[14]将语音加入词嵌入并利用动态规划算法和语音相似性来解决以往预测中预测词语不连贯的问题.Liu et al[15]为了解决错别字给句子带来的噪声,在预训练时给每个训练样本构造一个噪声上下文,然后修正模型被迫产生相似的基于噪声和原始上下文的输出.为了解决过度纠正问题还提出了复制机制,如Zhang et al[16]将语音相似性融入预训练过程,用语音相似的单词替换原单词,并利用嵌入的拼音和预训练模型一起改正错误. ...
CRASpell:A contextual typo robust approach to improve Chinese spelling correction
1
2022
... Li et al[11]提出一种基于字符替换的方法,鼓励模型探索看不见的拼写错误,创建大型伪数据来训练模型.Zhang et al[12]发现了预训练模型检错能力的不足,并提出检错网络与纠错网络架构,利用Bi⁃GRU (Gate Recurrent Unit)作为检错网络,将soft⁃mask的检错结果输入BERT组成的纠错网络.Liu et al[13]利用GRU获得汉字的语音与视觉编码,加入词嵌入并利用预训练中文模型RoBERTa来进行预测,最后通过预测拼音和汉字并进行联合优化来进行纠错.Wang et al[14]将语音加入词嵌入并利用动态规划算法和语音相似性来解决以往预测中预测词语不连贯的问题.Liu et al[15]为了解决错别字给句子带来的噪声,在预训练时给每个训练样本构造一个噪声上下文,然后修正模型被迫产生相似的基于噪声和原始上下文的输出.为了解决过度纠正问题还提出了复制机制,如Zhang et al[16]将语音相似性融入预训练过程,用语音相似的单词替换原单词,并利用嵌入的拼音和预训练模型一起改正错误. ...
Correcting Chinese spelling errors with phonetic pre?training
1
2021
... Li et al[11]提出一种基于字符替换的方法,鼓励模型探索看不见的拼写错误,创建大型伪数据来训练模型.Zhang et al[12]发现了预训练模型检错能力的不足,并提出检错网络与纠错网络架构,利用Bi⁃GRU (Gate Recurrent Unit)作为检错网络,将soft⁃mask的检错结果输入BERT组成的纠错网络.Liu et al[13]利用GRU获得汉字的语音与视觉编码,加入词嵌入并利用预训练中文模型RoBERTa来进行预测,最后通过预测拼音和汉字并进行联合优化来进行纠错.Wang et al[14]将语音加入词嵌入并利用动态规划算法和语音相似性来解决以往预测中预测词语不连贯的问题.Liu et al[15]为了解决错别字给句子带来的噪声,在预训练时给每个训练样本构造一个噪声上下文,然后修正模型被迫产生相似的基于噪声和原始上下文的输出.为了解决过度纠正问题还提出了复制机制,如Zhang et al[16]将语音相似性融入预训练过程,用语音相似的单词替换原单词,并利用嵌入的拼音和预训练模型一起改正错误. ...
Global attention decoder for Chinese spelling error correction
1
2021
... Guo et al[17]针对以往方法没有考虑句子中的错误词对句子表征及纠错任务的影响,训练了一个针对纠错任务的预训练语言模型BERT_CRS,提出全局注意力解码器(Global Attention Decoder,GAD)方法来学习输入句子中正确字符和错误字符候选集之间的关联关系,减轻局部错误的上下文影响.Bao et al[18]提出基于组块解码的方法,以单字、多字词、短语、成语为组块,利用全局优化修改单字和多字词错误,结合发音、字形、语义混淆集来处理多种不同的错误.Xu et al[19]使用文本、声音、视觉三个编码器来学习信息表示,采用BERT作为语义编码器的主干来捕获文本信息,使用分层编码器处理字符级和句子拼音字母,使用ResNet对图像进行分块编码,构建了多通道字符图像作为图形特征,得到字符图形标识.Huang et al[20]分别利用VGG19,TTS和BERT模型来获取汉字的视觉、语音和语义信息,并联合三者信息进行纠错.Ji et al[21]同样利用视觉和语音信息,分别采用部首偏旁信息,将整个拼音视为整体而非序列,并利用图网络进行信息融合. ...
Chunk?based Chinese spelling check with global optimization
1
... Guo et al[17]针对以往方法没有考虑句子中的错误词对句子表征及纠错任务的影响,训练了一个针对纠错任务的预训练语言模型BERT_CRS,提出全局注意力解码器(Global Attention Decoder,GAD)方法来学习输入句子中正确字符和错误字符候选集之间的关联关系,减轻局部错误的上下文影响.Bao et al[18]提出基于组块解码的方法,以单字、多字词、短语、成语为组块,利用全局优化修改单字和多字词错误,结合发音、字形、语义混淆集来处理多种不同的错误.Xu et al[19]使用文本、声音、视觉三个编码器来学习信息表示,采用BERT作为语义编码器的主干来捕获文本信息,使用分层编码器处理字符级和句子拼音字母,使用ResNet对图像进行分块编码,构建了多通道字符图像作为图形特征,得到字符图形标识.Huang et al[20]分别利用VGG19,TTS和BERT模型来获取汉字的视觉、语音和语义信息,并联合三者信息进行纠错.Ji et al[21]同样利用视觉和语音信息,分别采用部首偏旁信息,将整个拼音视为整体而非序列,并利用图网络进行信息融合. ...
Read,listen,and see:Leveraging multimodal information helps Chinese spell checking
1
2021
... Guo et al[17]针对以往方法没有考虑句子中的错误词对句子表征及纠错任务的影响,训练了一个针对纠错任务的预训练语言模型BERT_CRS,提出全局注意力解码器(Global Attention Decoder,GAD)方法来学习输入句子中正确字符和错误字符候选集之间的关联关系,减轻局部错误的上下文影响.Bao et al[18]提出基于组块解码的方法,以单字、多字词、短语、成语为组块,利用全局优化修改单字和多字词错误,结合发音、字形、语义混淆集来处理多种不同的错误.Xu et al[19]使用文本、声音、视觉三个编码器来学习信息表示,采用BERT作为语义编码器的主干来捕获文本信息,使用分层编码器处理字符级和句子拼音字母,使用ResNet对图像进行分块编码,构建了多通道字符图像作为图形特征,得到字符图形标识.Huang et al[20]分别利用VGG19,TTS和BERT模型来获取汉字的视觉、语音和语义信息,并联合三者信息进行纠错.Ji et al[21]同样利用视觉和语音信息,分别采用部首偏旁信息,将整个拼音视为整体而非序列,并利用图网络进行信息融合. ...
PHMOSpell:Phonological and morphological knowledge guided Chinese spelling check
1
2021
... Guo et al[17]针对以往方法没有考虑句子中的错误词对句子表征及纠错任务的影响,训练了一个针对纠错任务的预训练语言模型BERT_CRS,提出全局注意力解码器(Global Attention Decoder,GAD)方法来学习输入句子中正确字符和错误字符候选集之间的关联关系,减轻局部错误的上下文影响.Bao et al[18]提出基于组块解码的方法,以单字、多字词、短语、成语为组块,利用全局优化修改单字和多字词错误,结合发音、字形、语义混淆集来处理多种不同的错误.Xu et al[19]使用文本、声音、视觉三个编码器来学习信息表示,采用BERT作为语义编码器的主干来捕获文本信息,使用分层编码器处理字符级和句子拼音字母,使用ResNet对图像进行分块编码,构建了多通道字符图像作为图形特征,得到字符图形标识.Huang et al[20]分别利用VGG19,TTS和BERT模型来获取汉字的视觉、语音和语义信息,并联合三者信息进行纠错.Ji et al[21]同样利用视觉和语音信息,分别采用部首偏旁信息,将整个拼音视为整体而非序列,并利用图网络进行信息融合. ...
SpellBERT:A lightweight pretrained model for Chinese spelling check
1
2021
... Guo et al[17]针对以往方法没有考虑句子中的错误词对句子表征及纠错任务的影响,训练了一个针对纠错任务的预训练语言模型BERT_CRS,提出全局注意力解码器(Global Attention Decoder,GAD)方法来学习输入句子中正确字符和错误字符候选集之间的关联关系,减轻局部错误的上下文影响.Bao et al[18]提出基于组块解码的方法,以单字、多字词、短语、成语为组块,利用全局优化修改单字和多字词错误,结合发音、字形、语义混淆集来处理多种不同的错误.Xu et al[19]使用文本、声音、视觉三个编码器来学习信息表示,采用BERT作为语义编码器的主干来捕获文本信息,使用分层编码器处理字符级和句子拼音字母,使用ResNet对图像进行分块编码,构建了多通道字符图像作为图形特征,得到字符图形标识.Huang et al[20]分别利用VGG19,TTS和BERT模型来获取汉字的视觉、语音和语义信息,并联合三者信息进行纠错.Ji et al[21]同样利用视觉和语音信息,分别采用部首偏旁信息,将整个拼音视为整体而非序列,并利用图网络进行信息融合. ...
Improve Chinese spelling check by reevaluation
1
2022
... Wang and Shang[22]针对连续错误会改变语义导致无法有效提取语义的问题,提出基于混淆集生成多个候选句子来改正错误.Zhu et al[23]基于Transformer和BERT设计一个多任务的网络修正模型,保留错误字的信息,使预测更准确.Yang and Yu[24]通过复制机制来解决BERT过度纠正的问题,并将注意力机制用于提取汉字的语音与形状信息.Bao et al[25]利用Bi⁃GRU编码汉字语音信息,利用表意文字序列(Ideographic Description Characters,IDS)编码汉字结构信息,多通道融合进行纠错.Zhao et al[26]利用视觉转换器、GRU+CNN和BERT分别提取字形、拼音和语义特征,并对三种嵌入进行平均来生成最终的多模态表示,送入Transfomer进行纠正.Li et al[27]认为错误的拼写会导致错误的分词,提出在嵌入层加入分词信息并加以训练来提高分词正确率,提升模型效果.Li et al[28]引入汉语语音预测辅助任务来改进汉语语音识别,并首次系统讨论了该辅助任务的自适应性和粒度问题.Sun et al[29]提出一种错误检测方法,引导模型更多地关注编码过程中可能出现的错误标记,并引入一个新的损失函数来整合错误混淆集,使模型能区分容易被误用的词语.Li[30]提出一个名为uChecker的框架来进行无监督拼写错误检测和纠正,还提出一种混淆集引导掩蔽策略来精细训练掩蔽语言模型,以进一步提高无监督检测和校正的性能.Jiang et al[31]定义了医学领域中文拼写纠正(Medical CSC,MCSC)的任务,并提出MCSCSet,这是一个包含大约20万个样本的大规模专家注释数据集,还论证了开放领域和医学领域的拼写纠正之间存在的显著差距.Sun et al[32]提出一种新的基于知识图谱的纠错方法,从知识图谱中查询三元组,并将查询到的三元组作为领域知识注入句子,使模型具有推理能力和常识. ...
MDCSpell:A multi?task detector?corrector framework for Chinese spelling correction
1
2022
... Wang and Shang[22]针对连续错误会改变语义导致无法有效提取语义的问题,提出基于混淆集生成多个候选句子来改正错误.Zhu et al[23]基于Transformer和BERT设计一个多任务的网络修正模型,保留错误字的信息,使预测更准确.Yang and Yu[24]通过复制机制来解决BERT过度纠正的问题,并将注意力机制用于提取汉字的语音与形状信息.Bao et al[25]利用Bi⁃GRU编码汉字语音信息,利用表意文字序列(Ideographic Description Characters,IDS)编码汉字结构信息,多通道融合进行纠错.Zhao et al[26]利用视觉转换器、GRU+CNN和BERT分别提取字形、拼音和语义特征,并对三种嵌入进行平均来生成最终的多模态表示,送入Transfomer进行纠正.Li et al[27]认为错误的拼写会导致错误的分词,提出在嵌入层加入分词信息并加以训练来提高分词正确率,提升模型效果.Li et al[28]引入汉语语音预测辅助任务来改进汉语语音识别,并首次系统讨论了该辅助任务的自适应性和粒度问题.Sun et al[29]提出一种错误检测方法,引导模型更多地关注编码过程中可能出现的错误标记,并引入一个新的损失函数来整合错误混淆集,使模型能区分容易被误用的词语.Li[30]提出一个名为uChecker的框架来进行无监督拼写错误检测和纠正,还提出一种混淆集引导掩蔽策略来精细训练掩蔽语言模型,以进一步提高无监督检测和校正的性能.Jiang et al[31]定义了医学领域中文拼写纠正(Medical CSC,MCSC)的任务,并提出MCSCSet,这是一个包含大约20万个样本的大规模专家注释数据集,还论证了开放领域和医学领域的拼写纠正之间存在的显著差距.Sun et al[32]提出一种新的基于知识图谱的纠错方法,从知识图谱中查询三元组,并将查询到的三元组作为领域知识注入句子,使模型具有推理能力和常识. ...
CoSPA:An improved masked language model with copy mechanism for Chinese spelling correction
1
2022
... Wang and Shang[22]针对连续错误会改变语义导致无法有效提取语义的问题,提出基于混淆集生成多个候选句子来改正错误.Zhu et al[23]基于Transformer和BERT设计一个多任务的网络修正模型,保留错误字的信息,使预测更准确.Yang and Yu[24]通过复制机制来解决BERT过度纠正的问题,并将注意力机制用于提取汉字的语音与形状信息.Bao et al[25]利用Bi⁃GRU编码汉字语音信息,利用表意文字序列(Ideographic Description Characters,IDS)编码汉字结构信息,多通道融合进行纠错.Zhao et al[26]利用视觉转换器、GRU+CNN和BERT分别提取字形、拼音和语义特征,并对三种嵌入进行平均来生成最终的多模态表示,送入Transfomer进行纠正.Li et al[27]认为错误的拼写会导致错误的分词,提出在嵌入层加入分词信息并加以训练来提高分词正确率,提升模型效果.Li et al[28]引入汉语语音预测辅助任务来改进汉语语音识别,并首次系统讨论了该辅助任务的自适应性和粒度问题.Sun et al[29]提出一种错误检测方法,引导模型更多地关注编码过程中可能出现的错误标记,并引入一个新的损失函数来整合错误混淆集,使模型能区分容易被误用的词语.Li[30]提出一个名为uChecker的框架来进行无监督拼写错误检测和纠正,还提出一种混淆集引导掩蔽策略来精细训练掩蔽语言模型,以进一步提高无监督检测和校正的性能.Jiang et al[31]定义了医学领域中文拼写纠正(Medical CSC,MCSC)的任务,并提出MCSCSet,这是一个包含大约20万个样本的大规模专家注释数据集,还论证了开放领域和医学领域的拼写纠正之间存在的显著差距.Sun et al[32]提出一种新的基于知识图谱的纠错方法,从知识图谱中查询三元组,并将查询到的三元组作为领域知识注入句子,使模型具有推理能力和常识. ...
PGBERT:Phonology and glyph enhanced pre?training for Chinese spelling correction
1
2022
... Wang and Shang[22]针对连续错误会改变语义导致无法有效提取语义的问题,提出基于混淆集生成多个候选句子来改正错误.Zhu et al[23]基于Transformer和BERT设计一个多任务的网络修正模型,保留错误字的信息,使预测更准确.Yang and Yu[24]通过复制机制来解决BERT过度纠正的问题,并将注意力机制用于提取汉字的语音与形状信息.Bao et al[25]利用Bi⁃GRU编码汉字语音信息,利用表意文字序列(Ideographic Description Characters,IDS)编码汉字结构信息,多通道融合进行纠错.Zhao et al[26]利用视觉转换器、GRU+CNN和BERT分别提取字形、拼音和语义特征,并对三种嵌入进行平均来生成最终的多模态表示,送入Transfomer进行纠正.Li et al[27]认为错误的拼写会导致错误的分词,提出在嵌入层加入分词信息并加以训练来提高分词正确率,提升模型效果.Li et al[28]引入汉语语音预测辅助任务来改进汉语语音识别,并首次系统讨论了该辅助任务的自适应性和粒度问题.Sun et al[29]提出一种错误检测方法,引导模型更多地关注编码过程中可能出现的错误标记,并引入一个新的损失函数来整合错误混淆集,使模型能区分容易被误用的词语.Li[30]提出一个名为uChecker的框架来进行无监督拼写错误检测和纠正,还提出一种混淆集引导掩蔽策略来精细训练掩蔽语言模型,以进一步提高无监督检测和校正的性能.Jiang et al[31]定义了医学领域中文拼写纠正(Medical CSC,MCSC)的任务,并提出MCSCSet,这是一个包含大约20万个样本的大规模专家注释数据集,还论证了开放领域和医学领域的拼写纠正之间存在的显著差距.Sun et al[32]提出一种新的基于知识图谱的纠错方法,从知识图谱中查询三元组,并将查询到的三元组作为领域知识注入句子,使模型具有推理能力和常识. ...
A multimodal method for Chinese spelling correction
1
2022
... Wang and Shang[22]针对连续错误会改变语义导致无法有效提取语义的问题,提出基于混淆集生成多个候选句子来改正错误.Zhu et al[23]基于Transformer和BERT设计一个多任务的网络修正模型,保留错误字的信息,使预测更准确.Yang and Yu[24]通过复制机制来解决BERT过度纠正的问题,并将注意力机制用于提取汉字的语音与形状信息.Bao et al[25]利用Bi⁃GRU编码汉字语音信息,利用表意文字序列(Ideographic Description Characters,IDS)编码汉字结构信息,多通道融合进行纠错.Zhao et al[26]利用视觉转换器、GRU+CNN和BERT分别提取字形、拼音和语义特征,并对三种嵌入进行平均来生成最终的多模态表示,送入Transfomer进行纠正.Li et al[27]认为错误的拼写会导致错误的分词,提出在嵌入层加入分词信息并加以训练来提高分词正确率,提升模型效果.Li et al[28]引入汉语语音预测辅助任务来改进汉语语音识别,并首次系统讨论了该辅助任务的自适应性和粒度问题.Sun et al[29]提出一种错误检测方法,引导模型更多地关注编码过程中可能出现的错误标记,并引入一个新的损失函数来整合错误混淆集,使模型能区分容易被误用的词语.Li[30]提出一个名为uChecker的框架来进行无监督拼写错误检测和纠正,还提出一种混淆集引导掩蔽策略来精细训练掩蔽语言模型,以进一步提高无监督检测和校正的性能.Jiang et al[31]定义了医学领域中文拼写纠正(Medical CSC,MCSC)的任务,并提出MCSCSet,这是一个包含大约20万个样本的大规模专家注释数据集,还论证了开放领域和医学领域的拼写纠正之间存在的显著差距.Sun et al[32]提出一种新的基于知识图谱的纠错方法,从知识图谱中查询三元组,并将查询到的三元组作为领域知识注入句子,使模型具有推理能力和常识. ...
WSpeller:Robust word segmentation for enhancing Chinese spelling check
1
... Wang and Shang[22]针对连续错误会改变语义导致无法有效提取语义的问题,提出基于混淆集生成多个候选句子来改正错误.Zhu et al[23]基于Transformer和BERT设计一个多任务的网络修正模型,保留错误字的信息,使预测更准确.Yang and Yu[24]通过复制机制来解决BERT过度纠正的问题,并将注意力机制用于提取汉字的语音与形状信息.Bao et al[25]利用Bi⁃GRU编码汉字语音信息,利用表意文字序列(Ideographic Description Characters,IDS)编码汉字结构信息,多通道融合进行纠错.Zhao et al[26]利用视觉转换器、GRU+CNN和BERT分别提取字形、拼音和语义特征,并对三种嵌入进行平均来生成最终的多模态表示,送入Transfomer进行纠正.Li et al[27]认为错误的拼写会导致错误的分词,提出在嵌入层加入分词信息并加以训练来提高分词正确率,提升模型效果.Li et al[28]引入汉语语音预测辅助任务来改进汉语语音识别,并首次系统讨论了该辅助任务的自适应性和粒度问题.Sun et al[29]提出一种错误检测方法,引导模型更多地关注编码过程中可能出现的错误标记,并引入一个新的损失函数来整合错误混淆集,使模型能区分容易被误用的词语.Li[30]提出一个名为uChecker的框架来进行无监督拼写错误检测和纠正,还提出一种混淆集引导掩蔽策略来精细训练掩蔽语言模型,以进一步提高无监督检测和校正的性能.Jiang et al[31]定义了医学领域中文拼写纠正(Medical CSC,MCSC)的任务,并提出MCSCSet,这是一个包含大约20万个样本的大规模专家注释数据集,还论证了开放领域和医学领域的拼写纠正之间存在的显著差距.Sun et al[32]提出一种新的基于知识图谱的纠错方法,从知识图谱中查询三元组,并将查询到的三元组作为领域知识注入句子,使模型具有推理能力和常识. ...
Improving Chinese spelling check by character pronunciation prediction:The effects of adaptivity and granularity
1
2022
... Wang and Shang[22]针对连续错误会改变语义导致无法有效提取语义的问题,提出基于混淆集生成多个候选句子来改正错误.Zhu et al[23]基于Transformer和BERT设计一个多任务的网络修正模型,保留错误字的信息,使预测更准确.Yang and Yu[24]通过复制机制来解决BERT过度纠正的问题,并将注意力机制用于提取汉字的语音与形状信息.Bao et al[25]利用Bi⁃GRU编码汉字语音信息,利用表意文字序列(Ideographic Description Characters,IDS)编码汉字结构信息,多通道融合进行纠错.Zhao et al[26]利用视觉转换器、GRU+CNN和BERT分别提取字形、拼音和语义特征,并对三种嵌入进行平均来生成最终的多模态表示,送入Transfomer进行纠正.Li et al[27]认为错误的拼写会导致错误的分词,提出在嵌入层加入分词信息并加以训练来提高分词正确率,提升模型效果.Li et al[28]引入汉语语音预测辅助任务来改进汉语语音识别,并首次系统讨论了该辅助任务的自适应性和粒度问题.Sun et al[29]提出一种错误检测方法,引导模型更多地关注编码过程中可能出现的错误标记,并引入一个新的损失函数来整合错误混淆集,使模型能区分容易被误用的词语.Li[30]提出一个名为uChecker的框架来进行无监督拼写错误检测和纠正,还提出一种混淆集引导掩蔽策略来精细训练掩蔽语言模型,以进一步提高无监督检测和校正的性能.Jiang et al[31]定义了医学领域中文拼写纠正(Medical CSC,MCSC)的任务,并提出MCSCSet,这是一个包含大约20万个样本的大规模专家注释数据集,还论证了开放领域和医学领域的拼写纠正之间存在的显著差距.Sun et al[32]提出一种新的基于知识图谱的纠错方法,从知识图谱中查询三元组,并将查询到的三元组作为领域知识注入句子,使模型具有推理能力和常识. ...
An error?guided correction model for Chinese spelling error correction
1
... Wang and Shang[22]针对连续错误会改变语义导致无法有效提取语义的问题,提出基于混淆集生成多个候选句子来改正错误.Zhu et al[23]基于Transformer和BERT设计一个多任务的网络修正模型,保留错误字的信息,使预测更准确.Yang and Yu[24]通过复制机制来解决BERT过度纠正的问题,并将注意力机制用于提取汉字的语音与形状信息.Bao et al[25]利用Bi⁃GRU编码汉字语音信息,利用表意文字序列(Ideographic Description Characters,IDS)编码汉字结构信息,多通道融合进行纠错.Zhao et al[26]利用视觉转换器、GRU+CNN和BERT分别提取字形、拼音和语义特征,并对三种嵌入进行平均来生成最终的多模态表示,送入Transfomer进行纠正.Li et al[27]认为错误的拼写会导致错误的分词,提出在嵌入层加入分词信息并加以训练来提高分词正确率,提升模型效果.Li et al[28]引入汉语语音预测辅助任务来改进汉语语音识别,并首次系统讨论了该辅助任务的自适应性和粒度问题.Sun et al[29]提出一种错误检测方法,引导模型更多地关注编码过程中可能出现的错误标记,并引入一个新的损失函数来整合错误混淆集,使模型能区分容易被误用的词语.Li[30]提出一个名为uChecker的框架来进行无监督拼写错误检测和纠正,还提出一种混淆集引导掩蔽策略来精细训练掩蔽语言模型,以进一步提高无监督检测和校正的性能.Jiang et al[31]定义了医学领域中文拼写纠正(Medical CSC,MCSC)的任务,并提出MCSCSet,这是一个包含大约20万个样本的大规模专家注释数据集,还论证了开放领域和医学领域的拼写纠正之间存在的显著差距.Sun et al[32]提出一种新的基于知识图谱的纠错方法,从知识图谱中查询三元组,并将查询到的三元组作为领域知识注入句子,使模型具有推理能力和常识. ...
uChecker:Masked pretrained language models as unsupervised Chinese spelling checkers
1
2022
... Wang and Shang[22]针对连续错误会改变语义导致无法有效提取语义的问题,提出基于混淆集生成多个候选句子来改正错误.Zhu et al[23]基于Transformer和BERT设计一个多任务的网络修正模型,保留错误字的信息,使预测更准确.Yang and Yu[24]通过复制机制来解决BERT过度纠正的问题,并将注意力机制用于提取汉字的语音与形状信息.Bao et al[25]利用Bi⁃GRU编码汉字语音信息,利用表意文字序列(Ideographic Description Characters,IDS)编码汉字结构信息,多通道融合进行纠错.Zhao et al[26]利用视觉转换器、GRU+CNN和BERT分别提取字形、拼音和语义特征,并对三种嵌入进行平均来生成最终的多模态表示,送入Transfomer进行纠正.Li et al[27]认为错误的拼写会导致错误的分词,提出在嵌入层加入分词信息并加以训练来提高分词正确率,提升模型效果.Li et al[28]引入汉语语音预测辅助任务来改进汉语语音识别,并首次系统讨论了该辅助任务的自适应性和粒度问题.Sun et al[29]提出一种错误检测方法,引导模型更多地关注编码过程中可能出现的错误标记,并引入一个新的损失函数来整合错误混淆集,使模型能区分容易被误用的词语.Li[30]提出一个名为uChecker的框架来进行无监督拼写错误检测和纠正,还提出一种混淆集引导掩蔽策略来精细训练掩蔽语言模型,以进一步提高无监督检测和校正的性能.Jiang et al[31]定义了医学领域中文拼写纠正(Medical CSC,MCSC)的任务,并提出MCSCSet,这是一个包含大约20万个样本的大规模专家注释数据集,还论证了开放领域和医学领域的拼写纠正之间存在的显著差距.Sun et al[32]提出一种新的基于知识图谱的纠错方法,从知识图谱中查询三元组,并将查询到的三元组作为领域知识注入句子,使模型具有推理能力和常识. ...
MCSCSet:A specialist?annotated dataset for medical?domain Chinese spelling correction
1
2022
... Wang and Shang[22]针对连续错误会改变语义导致无法有效提取语义的问题,提出基于混淆集生成多个候选句子来改正错误.Zhu et al[23]基于Transformer和BERT设计一个多任务的网络修正模型,保留错误字的信息,使预测更准确.Yang and Yu[24]通过复制机制来解决BERT过度纠正的问题,并将注意力机制用于提取汉字的语音与形状信息.Bao et al[25]利用Bi⁃GRU编码汉字语音信息,利用表意文字序列(Ideographic Description Characters,IDS)编码汉字结构信息,多通道融合进行纠错.Zhao et al[26]利用视觉转换器、GRU+CNN和BERT分别提取字形、拼音和语义特征,并对三种嵌入进行平均来生成最终的多模态表示,送入Transfomer进行纠正.Li et al[27]认为错误的拼写会导致错误的分词,提出在嵌入层加入分词信息并加以训练来提高分词正确率,提升模型效果.Li et al[28]引入汉语语音预测辅助任务来改进汉语语音识别,并首次系统讨论了该辅助任务的自适应性和粒度问题.Sun et al[29]提出一种错误检测方法,引导模型更多地关注编码过程中可能出现的错误标记,并引入一个新的损失函数来整合错误混淆集,使模型能区分容易被误用的词语.Li[30]提出一个名为uChecker的框架来进行无监督拼写错误检测和纠正,还提出一种混淆集引导掩蔽策略来精细训练掩蔽语言模型,以进一步提高无监督检测和校正的性能.Jiang et al[31]定义了医学领域中文拼写纠正(Medical CSC,MCSC)的任务,并提出MCSCSet,这是一个包含大约20万个样本的大规模专家注释数据集,还论证了开放领域和医学领域的拼写纠正之间存在的显著差距.Sun et al[32]提出一种新的基于知识图谱的纠错方法,从知识图谱中查询三元组,并将查询到的三元组作为领域知识注入句子,使模型具有推理能力和常识. ...
Chinese spelling error detection and correction based on knowledge graph
1
2022
... Wang and Shang[22]针对连续错误会改变语义导致无法有效提取语义的问题,提出基于混淆集生成多个候选句子来改正错误.Zhu et al[23]基于Transformer和BERT设计一个多任务的网络修正模型,保留错误字的信息,使预测更准确.Yang and Yu[24]通过复制机制来解决BERT过度纠正的问题,并将注意力机制用于提取汉字的语音与形状信息.Bao et al[25]利用Bi⁃GRU编码汉字语音信息,利用表意文字序列(Ideographic Description Characters,IDS)编码汉字结构信息,多通道融合进行纠错.Zhao et al[26]利用视觉转换器、GRU+CNN和BERT分别提取字形、拼音和语义特征,并对三种嵌入进行平均来生成最终的多模态表示,送入Transfomer进行纠正.Li et al[27]认为错误的拼写会导致错误的分词,提出在嵌入层加入分词信息并加以训练来提高分词正确率,提升模型效果.Li et al[28]引入汉语语音预测辅助任务来改进汉语语音识别,并首次系统讨论了该辅助任务的自适应性和粒度问题.Sun et al[29]提出一种错误检测方法,引导模型更多地关注编码过程中可能出现的错误标记,并引入一个新的损失函数来整合错误混淆集,使模型能区分容易被误用的词语.Li[30]提出一个名为uChecker的框架来进行无监督拼写错误检测和纠正,还提出一种混淆集引导掩蔽策略来精细训练掩蔽语言模型,以进一步提高无监督检测和校正的性能.Jiang et al[31]定义了医学领域中文拼写纠正(Medical CSC,MCSC)的任务,并提出MCSCSet,这是一个包含大约20万个样本的大规模专家注释数据集,还论证了开放领域和医学领域的拼写纠正之间存在的显著差距.Sun et al[32]提出一种新的基于知识图谱的纠错方法,从知识图谱中查询三元组,并将查询到的三元组作为领域知识注入句子,使模型具有推理能力和常识. ...
A hybrid approach to automatic corpus generation for Chinese spelling check



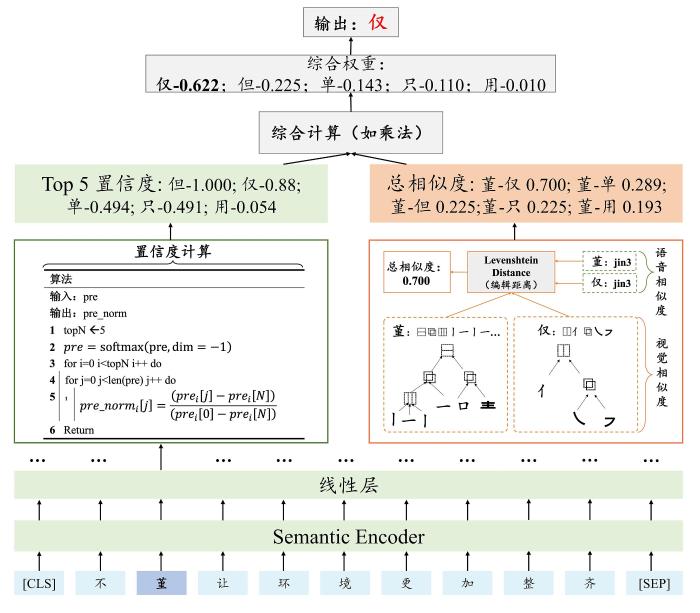
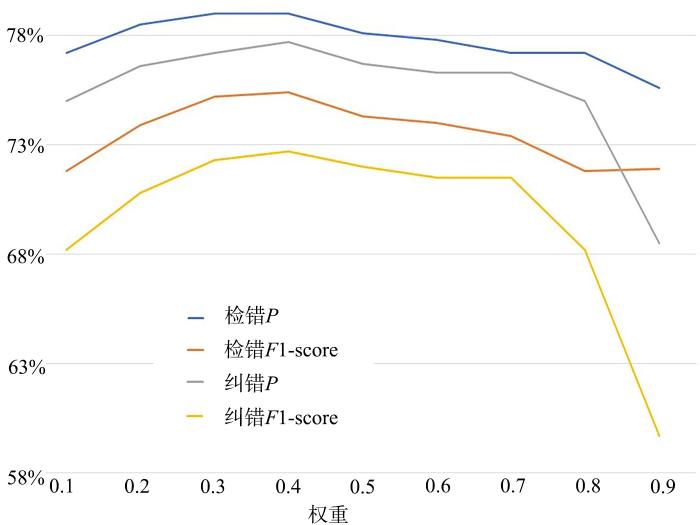
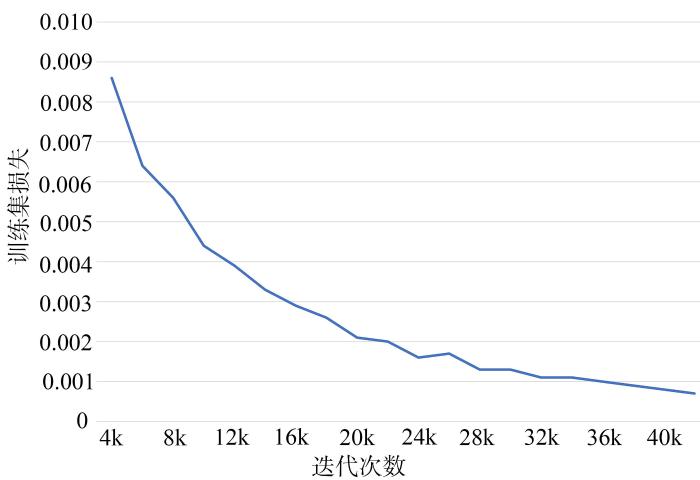

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}