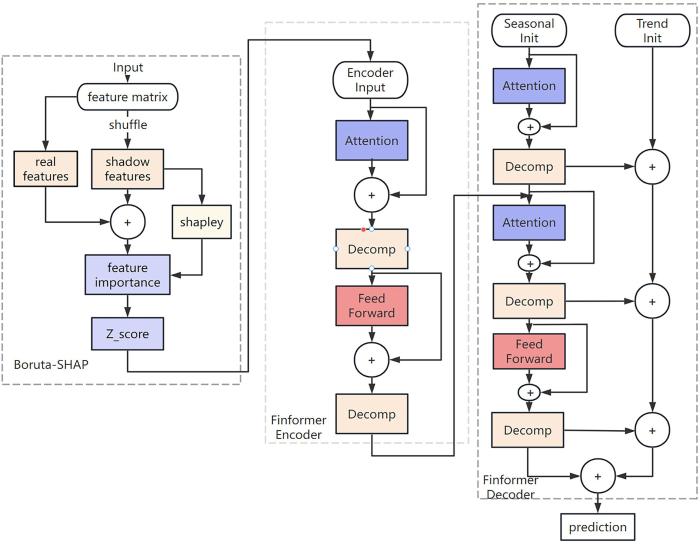
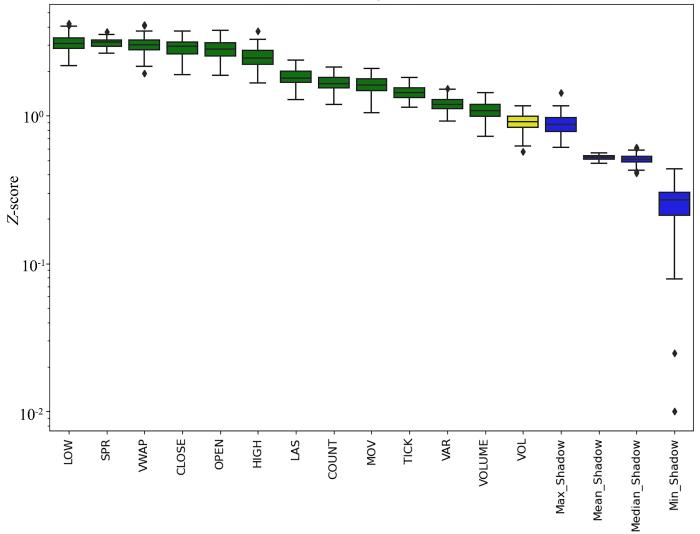
The long⁃term series prediction in the financial domain faces challenges due to complex markets and numerous financial products. Traditional methods in time series forecasting perform well in handling linear distributed data,but their effectiveness is limited when dealing with redundant feature parameters and nonlinear data of long sequence financial products. To address this issue,this study proposes a method in long⁃term series prediction called BSFinformer (Boruta⁃SHAP+Finformer). This method leverages the time correlation of financial data and integrates techniques such as Boruta⁃SHAP and Finformer to accomplish feature selection and prediction tasks.Firstly,the Boruta⁃SHAP module is introduced,which utilizes such analytical methods as XgBoost and SHAP for feature selection. It identifies important features related to tasks of financial time series prediction from the given feature set and explains the impact of these features on the prediction. Secondly,the Finformer module is developed by improving the Transformer structure and incorporating self⁃attention mechanisms. It decomposes long sequence financial data into trend,cycle,and residual components,and combines sparse self⁃attention mechanisms. The BSFinformer model is evaluated on multiple real financial datasets through experiments.The experimental results demonstrate that the BSFinformer model exhibits excellent performance in price prediction of financial products. Compared to other forecasting methods,the BSFinformer model accurately captures long⁃term trends and periodicity to achieve high⁃quality predictions. Specifically,compared to the traditional Transformer model,the BSFinformer model reduces Mean⁃Square Error by 52%,16% and reduces 19%,and Mean Absolute Error by 34%,25% and 11% on the three datasets,respectively. It provides an effective solution for long⁃term series prediction of financial data.
Keywords:feature selection
;
Boruta SHAP
;
long time series
;
Finformer
;
financial data prediction
Zhu Xiaotong, Lin Peiguang, Sun Mei, Wang Qian, Li Jinyu, Wang Jieru. Feature selection and prediction of financial data based on BSFinformer model. Journal of nanjing University[J], 2024, 60(3): 442-450 doi:10.13232/j.cnki.jnju.2024.03.008
在金融时间序列预测领域,已经有多项重要的研究工作涉及了特征选择和长期预测的问题.特征选择是一项关键步骤,旨在选择具有预测能力的特征并消除冗余特征,而统计学方法和机器学习方法被广泛应用于特征选择.2003年Kim[8]在支持向量机中进行时间序列特征选择,提出一种基于相关系数的特征选择策略来提高预测准确性和模型解释性.2010年Crone and Kourentzes[9]探讨基于神经网络的时间序列预测的特征选择方法,提出一种结合过滤和包装两种方法的特征选择策略来提高预测性能,降低计算复杂度.2021年Leung and Zhao[10]使用经验模态分解(Empirical Mode Decomposition,EMD)来生成特征并结合机器学习进行金融时间序列分析和预测的方法,提出一种结合Hilbert⁃Huang变换(HHT)和机器学习方法的框架来提高金融时间序列的预测精度和稳定性.2023年张展云等[11]基于多标签学习领域中的流标签,提出一种新的特征选择方法来提高特征选择的有效性和高效性.
随着特征选择的精度和稳定性不断提高,时间序列预测的准确度也不断进步.2018年Tran et al[12]使用深度学习和注意力机制进行金融时间序列预测,基于循环神经网络(Recurrent Netural Network,RNN)和自注意力机制,通过自动关注序列中重要的时间步来提高预测性能,能更准确地预测金融时间序列.2020年Sezer et al[13]回顾2005-2019年深度学习在金融时间序列预测中的应用,总结了各种深度学习模型在金融数据预测中的效果和局限性,提出了未来研究的方向和挑战.长期预测是金融时间序列预测中的挑战之一,2021年后,随着Transformer的流行,Informer,Autoformer,Fedformer,Yformer等模型陆续被提出,它们可以捕捉长期记忆效应和非线性特征,结合自注意力机制和全局上下文编码器,可捕捉序列中的长期依赖关系,对长序列时间序列预测表现出强大的性能[14-16].2023年方宇等[17]提出三支残差修正的时间序列预测,利用时间序列分解算法STL(Seasonal Decomposition of Time Series by Loess)来修正时间序列的预测结果.
Transformers:State⁃of⁃the⁃art natural language processing
∥Proceedings of 2020 Conference on Empirical Methods in Natural Language Processing:System Demonstrations. Online:Association for Computational Linguistics:2020:38-45.
Financial time series forecasting using support vector machines
1
2003
... 在金融时间序列预测领域,已经有多项重要的研究工作涉及了特征选择和长期预测的问题.特征选择是一项关键步骤,旨在选择具有预测能力的特征并消除冗余特征,而统计学方法和机器学习方法被广泛应用于特征选择.2003年Kim[8]在支持向量机中进行时间序列特征选择,提出一种基于相关系数的特征选择策略来提高预测准确性和模型解释性.2010年Crone and Kourentzes[9]探讨基于神经网络的时间序列预测的特征选择方法,提出一种结合过滤和包装两种方法的特征选择策略来提高预测性能,降低计算复杂度.2021年Leung and Zhao[10]使用经验模态分解(Empirical Mode Decomposition,EMD)来生成特征并结合机器学习进行金融时间序列分析和预测的方法,提出一种结合Hilbert⁃Huang变换(HHT)和机器学习方法的框架来提高金融时间序列的预测精度和稳定性.2023年张展云等[11]基于多标签学习领域中的流标签,提出一种新的特征选择方法来提高特征选择的有效性和高效性. ...
Feature selection for time series prediction:A combined filter and wrapper approach for neural networks
1
2010
... 在金融时间序列预测领域,已经有多项重要的研究工作涉及了特征选择和长期预测的问题.特征选择是一项关键步骤,旨在选择具有预测能力的特征并消除冗余特征,而统计学方法和机器学习方法被广泛应用于特征选择.2003年Kim[8]在支持向量机中进行时间序列特征选择,提出一种基于相关系数的特征选择策略来提高预测准确性和模型解释性.2010年Crone and Kourentzes[9]探讨基于神经网络的时间序列预测的特征选择方法,提出一种结合过滤和包装两种方法的特征选择策略来提高预测性能,降低计算复杂度.2021年Leung and Zhao[10]使用经验模态分解(Empirical Mode Decomposition,EMD)来生成特征并结合机器学习进行金融时间序列分析和预测的方法,提出一种结合Hilbert⁃Huang变换(HHT)和机器学习方法的框架来提高金融时间序列的预测精度和稳定性.2023年张展云等[11]基于多标签学习领域中的流标签,提出一种新的特征选择方法来提高特征选择的有效性和高效性. ...
Financial time series analysis and forecasting with Hilbert–Huang transform feature generation and machine learning
1
2021
... 在金融时间序列预测领域,已经有多项重要的研究工作涉及了特征选择和长期预测的问题.特征选择是一项关键步骤,旨在选择具有预测能力的特征并消除冗余特征,而统计学方法和机器学习方法被广泛应用于特征选择.2003年Kim[8]在支持向量机中进行时间序列特征选择,提出一种基于相关系数的特征选择策略来提高预测准确性和模型解释性.2010年Crone and Kourentzes[9]探讨基于神经网络的时间序列预测的特征选择方法,提出一种结合过滤和包装两种方法的特征选择策略来提高预测性能,降低计算复杂度.2021年Leung and Zhao[10]使用经验模态分解(Empirical Mode Decomposition,EMD)来生成特征并结合机器学习进行金融时间序列分析和预测的方法,提出一种结合Hilbert⁃Huang变换(HHT)和机器学习方法的框架来提高金融时间序列的预测精度和稳定性.2023年张展云等[11]基于多标签学习领域中的流标签,提出一种新的特征选择方法来提高特征选择的有效性和高效性. ...
基于组标签的多标签流特征选择算法
1
2023
... 在金融时间序列预测领域,已经有多项重要的研究工作涉及了特征选择和长期预测的问题.特征选择是一项关键步骤,旨在选择具有预测能力的特征并消除冗余特征,而统计学方法和机器学习方法被广泛应用于特征选择.2003年Kim[8]在支持向量机中进行时间序列特征选择,提出一种基于相关系数的特征选择策略来提高预测准确性和模型解释性.2010年Crone and Kourentzes[9]探讨基于神经网络的时间序列预测的特征选择方法,提出一种结合过滤和包装两种方法的特征选择策略来提高预测性能,降低计算复杂度.2021年Leung and Zhao[10]使用经验模态分解(Empirical Mode Decomposition,EMD)来生成特征并结合机器学习进行金融时间序列分析和预测的方法,提出一种结合Hilbert⁃Huang变换(HHT)和机器学习方法的框架来提高金融时间序列的预测精度和稳定性.2023年张展云等[11]基于多标签学习领域中的流标签,提出一种新的特征选择方法来提高特征选择的有效性和高效性. ...
Multi?label streaming feature selection based on group labels
1
2023
... 在金融时间序列预测领域,已经有多项重要的研究工作涉及了特征选择和长期预测的问题.特征选择是一项关键步骤,旨在选择具有预测能力的特征并消除冗余特征,而统计学方法和机器学习方法被广泛应用于特征选择.2003年Kim[8]在支持向量机中进行时间序列特征选择,提出一种基于相关系数的特征选择策略来提高预测准确性和模型解释性.2010年Crone and Kourentzes[9]探讨基于神经网络的时间序列预测的特征选择方法,提出一种结合过滤和包装两种方法的特征选择策略来提高预测性能,降低计算复杂度.2021年Leung and Zhao[10]使用经验模态分解(Empirical Mode Decomposition,EMD)来生成特征并结合机器学习进行金融时间序列分析和预测的方法,提出一种结合Hilbert⁃Huang变换(HHT)和机器学习方法的框架来提高金融时间序列的预测精度和稳定性.2023年张展云等[11]基于多标签学习领域中的流标签,提出一种新的特征选择方法来提高特征选择的有效性和高效性. ...
Temporal attention?augmented bilinear network for financial time?series data analysis
1
2019
... 随着特征选择的精度和稳定性不断提高,时间序列预测的准确度也不断进步.2018年Tran et al[12]使用深度学习和注意力机制进行金融时间序列预测,基于循环神经网络(Recurrent Netural Network,RNN)和自注意力机制,通过自动关注序列中重要的时间步来提高预测性能,能更准确地预测金融时间序列.2020年Sezer et al[13]回顾2005-2019年深度学习在金融时间序列预测中的应用,总结了各种深度学习模型在金融数据预测中的效果和局限性,提出了未来研究的方向和挑战.长期预测是金融时间序列预测中的挑战之一,2021年后,随着Transformer的流行,Informer,Autoformer,Fedformer,Yformer等模型陆续被提出,它们可以捕捉长期记忆效应和非线性特征,结合自注意力机制和全局上下文编码器,可捕捉序列中的长期依赖关系,对长序列时间序列预测表现出强大的性能[14-16].2023年方宇等[17]提出三支残差修正的时间序列预测,利用时间序列分解算法STL(Seasonal Decomposition of Time Series by Loess)来修正时间序列的预测结果. ...
Financial time series forecasting with deep learning:A systematic literature review:2005-2019
1
2020
... 随着特征选择的精度和稳定性不断提高,时间序列预测的准确度也不断进步.2018年Tran et al[12]使用深度学习和注意力机制进行金融时间序列预测,基于循环神经网络(Recurrent Netural Network,RNN)和自注意力机制,通过自动关注序列中重要的时间步来提高预测性能,能更准确地预测金融时间序列.2020年Sezer et al[13]回顾2005-2019年深度学习在金融时间序列预测中的应用,总结了各种深度学习模型在金融数据预测中的效果和局限性,提出了未来研究的方向和挑战.长期预测是金融时间序列预测中的挑战之一,2021年后,随着Transformer的流行,Informer,Autoformer,Fedformer,Yformer等模型陆续被提出,它们可以捕捉长期记忆效应和非线性特征,结合自注意力机制和全局上下文编码器,可捕捉序列中的长期依赖关系,对长序列时间序列预测表现出强大的性能[14-16].2023年方宇等[17]提出三支残差修正的时间序列预测,利用时间序列分解算法STL(Seasonal Decomposition of Time Series by Loess)来修正时间序列的预测结果. ...
Informer:Beyond efficient transformer for long sequence time?series forecasting
1
2021
... 随着特征选择的精度和稳定性不断提高,时间序列预测的准确度也不断进步.2018年Tran et al[12]使用深度学习和注意力机制进行金融时间序列预测,基于循环神经网络(Recurrent Netural Network,RNN)和自注意力机制,通过自动关注序列中重要的时间步来提高预测性能,能更准确地预测金融时间序列.2020年Sezer et al[13]回顾2005-2019年深度学习在金融时间序列预测中的应用,总结了各种深度学习模型在金融数据预测中的效果和局限性,提出了未来研究的方向和挑战.长期预测是金融时间序列预测中的挑战之一,2021年后,随着Transformer的流行,Informer,Autoformer,Fedformer,Yformer等模型陆续被提出,它们可以捕捉长期记忆效应和非线性特征,结合自注意力机制和全局上下文编码器,可捕捉序列中的长期依赖关系,对长序列时间序列预测表现出强大的性能[14-16].2023年方宇等[17]提出三支残差修正的时间序列预测,利用时间序列分解算法STL(Seasonal Decomposition of Time Series by Loess)来修正时间序列的预测结果. ...
FEDformer:Frequency enhanced decomposed transformer for long?term series forecasting
0
2022
U?Net inspired transformer architecture for far horizon time series forecastingBaltimore,USA
1
2022
... 随着特征选择的精度和稳定性不断提高,时间序列预测的准确度也不断进步.2018年Tran et al[12]使用深度学习和注意力机制进行金融时间序列预测,基于循环神经网络(Recurrent Netural Network,RNN)和自注意力机制,通过自动关注序列中重要的时间步来提高预测性能,能更准确地预测金融时间序列.2020年Sezer et al[13]回顾2005-2019年深度学习在金融时间序列预测中的应用,总结了各种深度学习模型在金融数据预测中的效果和局限性,提出了未来研究的方向和挑战.长期预测是金融时间序列预测中的挑战之一,2021年后,随着Transformer的流行,Informer,Autoformer,Fedformer,Yformer等模型陆续被提出,它们可以捕捉长期记忆效应和非线性特征,结合自注意力机制和全局上下文编码器,可捕捉序列中的长期依赖关系,对长序列时间序列预测表现出强大的性能[14-16].2023年方宇等[17]提出三支残差修正的时间序列预测,利用时间序列分解算法STL(Seasonal Decomposition of Time Series by Loess)来修正时间序列的预测结果. ...
三支残差修正的时间序列预测
1
2023
... 随着特征选择的精度和稳定性不断提高,时间序列预测的准确度也不断进步.2018年Tran et al[12]使用深度学习和注意力机制进行金融时间序列预测,基于循环神经网络(Recurrent Netural Network,RNN)和自注意力机制,通过自动关注序列中重要的时间步来提高预测性能,能更准确地预测金融时间序列.2020年Sezer et al[13]回顾2005-2019年深度学习在金融时间序列预测中的应用,总结了各种深度学习模型在金融数据预测中的效果和局限性,提出了未来研究的方向和挑战.长期预测是金融时间序列预测中的挑战之一,2021年后,随着Transformer的流行,Informer,Autoformer,Fedformer,Yformer等模型陆续被提出,它们可以捕捉长期记忆效应和非线性特征,结合自注意力机制和全局上下文编码器,可捕捉序列中的长期依赖关系,对长序列时间序列预测表现出强大的性能[14-16].2023年方宇等[17]提出三支残差修正的时间序列预测,利用时间序列分解算法STL(Seasonal Decomposition of Time Series by Loess)来修正时间序列的预测结果. ...
Time series prediction with three?way residual error amendment
1
2023
... 随着特征选择的精度和稳定性不断提高,时间序列预测的准确度也不断进步.2018年Tran et al[12]使用深度学习和注意力机制进行金融时间序列预测,基于循环神经网络(Recurrent Netural Network,RNN)和自注意力机制,通过自动关注序列中重要的时间步来提高预测性能,能更准确地预测金融时间序列.2020年Sezer et al[13]回顾2005-2019年深度学习在金融时间序列预测中的应用,总结了各种深度学习模型在金融数据预测中的效果和局限性,提出了未来研究的方向和挑战.长期预测是金融时间序列预测中的挑战之一,2021年后,随着Transformer的流行,Informer,Autoformer,Fedformer,Yformer等模型陆续被提出,它们可以捕捉长期记忆效应和非线性特征,结合自注意力机制和全局上下文编码器,可捕捉序列中的长期依赖关系,对长序列时间序列预测表现出强大的性能[14-16].2023年方宇等[17]提出三支残差修正的时间序列预测,利用时间序列分解算法STL(Seasonal Decomposition of Time Series by Loess)来修正时间序列的预测结果. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}