


随着大规模网页文本语料库的出现以及深度学习技术在自然语言处理等领域的发展,网页分类任务在过去几年取得了很大的进步.本文梳理了近十年网页分类相关的系列工作,对其应用数据集和模型算法进行分析.数据集方面,当前网页分类算法的数据集使用比例如图1所示,公开数据项目ODP提供的DMOZ⁃50[8]、卡内基梅隆大学提供的WebKB[9]以及Kushmerick[10]提供的AD数据集得到了广泛应用,但72.89%的研究者偏向使用个人收集的数据进行实验,而这些数据往往采集方式模糊且不开源,难以形成统一的测评基准.另外,随着网页分类研究的不断深入,算法性能不断提高,如图2所示,Deng et al[11]和Kipf and Welling[12]提出的算法在DMOZ⁃50,WebKB及AD数据集上达到了95%以上的准确率.
图1
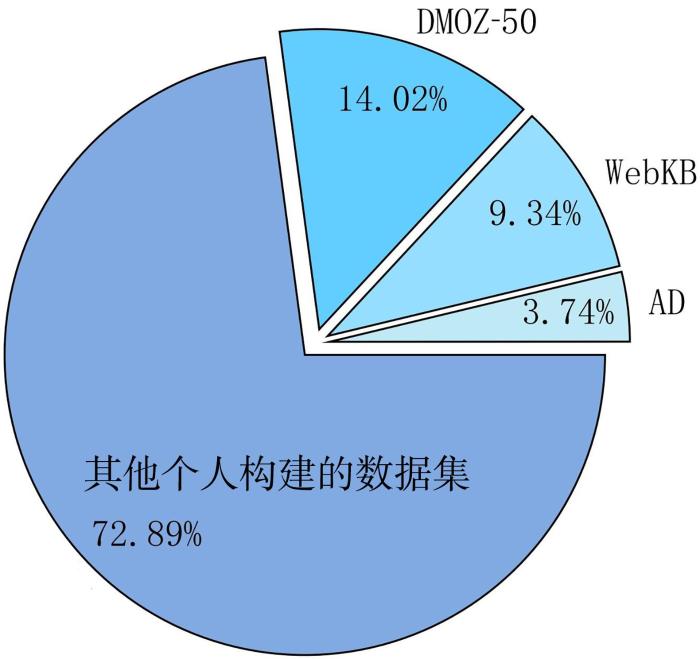
图2

图2
网页分类算法在不同数据集上的表现
Fig.2
Performance of webpage classification algorithms on different webpage datasets
在信息科学技术与自然科学互促发展的趋势下,由我国科学家主导的国际大科学计划“深时数字地球”项目[13]正在借助网页挖掘技术构建一个全球共享的地学数据网站检索平台,其中,数据网站的分类是平台构建的核心技术.针对此问题,本文联合领域专家选取一批数据集网站的正负样例进行实验,如图2所示,各类算法性能均有20%左右的明显下降.这可能是因为WebKB[9]等公开数据集的结构关系简单,所以基于文本信息进行表征即可达到较高的网页分类性能.然而,开放域中存在大量结构复杂、布局多样的网页.通过对比网页结构标签节点个数,本文对WebKB与测试数据进行了网页结构复杂度的对比分析.如图3所示,测试数据网页的平均结构标签节点个数为573,约为WebKB的5倍,即前者具有更高的结构复杂度.因此,融合更多视角的网页信息(例如DOM结构树)有利于更好地刻画开放域网页特征,提升分类任务性能,然而,现有公开数据集均未提供DOM结构树等网页特征,一个涵盖多视角信息的网页分类数据集亟待提出.
图3
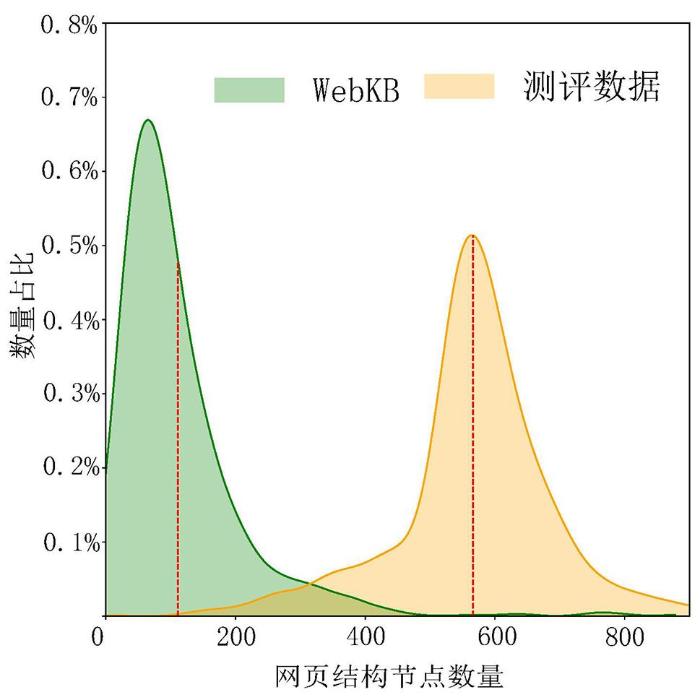
图3
WebKB与测评数据网页结构标签节点的分布
Fig.3
HTML tag distribution of WebKB and evaluation data
基于以上分析,本文提出一个用于网页分类的多视角网页数据集Web⁃Minds(Webpage with Multi⁃View Information Dataset),收集了来自600余个门户网站的21828条相关网页.构建流程包括数据收集、数据处理及数据标注三个步骤,提供如图4所示的纯文本、DOM结构树、关键词等多视角网页表征信息.作为网页分类数据集,Web⁃Minds数据标签内容包括网页类型信息,即数据网页与非数据网页以及网页主题信息,有地质学、地球物理学、地理学和地质资源四个主题.和现有数据集相比,Web⁃Minds更注重网页多样性以及网页和文本不同的结构多样性.此外,作为一个公开网页数据集,Web⁃Minds的每个样本都经过先验知识标注及专家验证,确保数据真实可靠.为了评估各网页分类算法在Web⁃Minds上的表现,本文针对Web⁃Minds提供的两类标签设计了网页类型分类与网页主题分类两种任务.同时,为了证明使用多视角信息能提升网页分类算法的性能,分别采用单视角信息与多视角信息进行对比实验,后者准确率比前者提升5.61%.最后,针对开放域中域名分布偏移与类别不均衡问题进行了广泛研究与深入分析,为研究人员后续的模型设计与性能调优提供数据参考.
图4
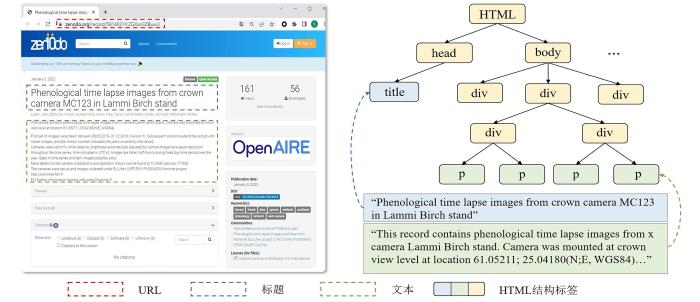
图4
Web⁃Minds数据集提供的网页URL链接、纯文本、DOM结构树、网页标题、网页关键词信息
Fig.4
Web page URL links,plain text,DOM structure tree,web page titles,web page keyword information from Web⁃Minds dataset
本文的主要贡献如下.
(1)提出一个多视角网页分类数据集Web⁃Minds,其网页数据来源多样,包含来自600多个门户网站的20000多条网页数据,标注信息真实可靠,提供专家标注的网页类型和网页主题信息.
(2)Web⁃Minds提供网页语义文本信息与结构信息,包括网页纯文本信息、网页标题、DOM结构树、网页关键词等一系列多视角网页属性信息,全方位刻画网页特征.
(3)Web⁃Minds支持多种网页数据挖掘任务,为研究人员提供数据支撑.本文在网页类型与主题分类上通过先进的分类算法进行性能评估,证明多视角特征对于网页分类性能有显著增益.
1 相关工作
1.1 网页数据集
网页数据集是网页分类的基础,广泛应用于网页数据挖掘.DMOZ是全球学术志愿者建立并维护的公共开放目录项目,DMOZ⁃ 50[8]是来自DMOZ网站的50个子数据集,包含3~10个类别,如艺术、运动、科学、购物等.DMOZ⁃ 50的内容以纯文本为主,其网页数据主要为门户网站首页内容信息.WebKB[9]来源于卡内基梅隆大学语言学习实验室主导的世界知识库项目,其网页数据来自四所高校计算机科学系,根据内容分为学生、教师、员工、系、课程、项目和其他,其中常用版本为课程网页与非课程网页.MGC数据集[14]收集开放互联网上的1539个英文网页,这些网页被标记为博客(Blog)、个人主页(Personal)、诗歌(Poetry)等.AD数据集[10]包含3279个网页,分458个广告网页与2821个非广告网页,目前的公开版本为预处理后得到特征向量表示,包含网页URL链接、超链接跳转信息和图片链接三种特征.以上公开数据集均以网页文本或URL链接为主,常用于文本分类、文本理解等相关任务.
1.2 网页分类算法
2 Web⁃Minds数据集
2.1 数据集构建
Web⁃Minds的构建流程如图5所示,分三个步骤:数据收集,即利用领域专家提供的关键词在开放域进行搜集,并去除失效网页、垃圾网页等,得到初步的相关网页;数据处理,即将原始网页经过处理获取所需各类网页属性信息;数据标注,即专家进行数据标签标注.
图5

2.1.1 数据收集
由于开放域网页信息具有多样性和隐蔽性,业外人士想要大量获取精准的、可靠的特定专业网页较困难.因此,Web⁃Minds在构建初期咨询了地球科学学科的国内外专家,经过去重、名词去复数等词级别操作,整理获得了一个精确可靠的学科关键词库,包含五千多个相关关键词,如泥石流(Mudslide)、碳同位素(Carbon isotope)、地层学(Stratigraphy)等,同时涵盖了地球科学下的地质学、地球物理学、地理学等子学科.Web⁃Minds以该关键词库为依据,在开放域海量的网页中进行搜索整合,收集了大量相关网页,记为
2.1.2 数据处理
在数据收集阶段获取的有效网页数据
2.1.2.1 源数据解析
早期网页分类工作通常仅使用网页链接
2.1.2.2 元数据清洗
经过源数据解析后的数据集有良好的结构规范性,然而,将网页纯文本信息、网页标题信息与网页关键词信息作为文本类信息会存在冗余、符号错乱、排版等问题,对后续使用带来负面影响.因此,本文根据地球科学专家与信息科学专家联合提出的数据格式要求,对数据集
2.1.3 数据标注
经过数据收集与数据处理后,网页信息数据集
2.1.3.1 网页类型标注
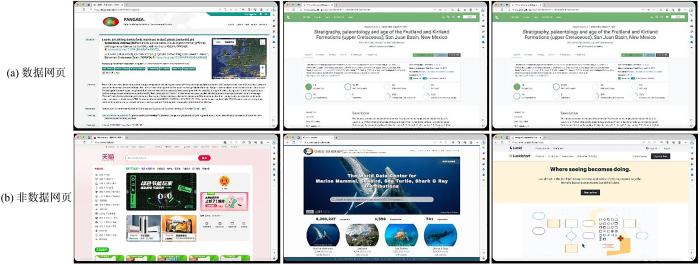
研究人员采集数据往往需要花费较多的人力物力资源,例如,花岗岩数据需要专业人员前往花岗岩分布地区采集数日,冰川数据则可能需要采集数年甚至更久,因此,建立一个全球可共享的科学数据集网站有重要意义.Web⁃Minds对每个网页进行类型标注,标注内容为
图6
2.1.3.2 网页主题标注
地球科学是个庞大的学科,存在众多分支学科.Web⁃Minds在数据收集阶段依据学科关键词库,因此每个网页都存在对应的子学科属性,可实现基于子学科的多分类任务.Web⁃Minds对每个网页进行主题标注,标注内容为地质学、地球物理学、地理学和地质资源学,但由于每个门户网站均涵盖不同的主题页面,因此,和网页类型标注相比,主题标注无法利用门户网站关系来简化标注流程.为了获取准确可靠的标注信息,选择大语言模型与学科专家共同标注的策略,借助学科专家标注的少量数据对GPT⁃3.5⁃turbo进行上下文学习,对大批量数据进行标注,再由专家纠正错误标注,实现“大模型赋能+专家在回路”式数据标注.另外,由于子学科之间存在交叉的必然性,专家进一步对所有模糊网页进行最终评判,保证数据标签的唯一性、可靠性.
在数据标注阶段,网页类型标签
2.2 数据集统计信息
Web⁃Minds作为开放域网页数据分布下的多视角网页数据集,由涵盖多类网页属性的网页信息集合
图7

表1展示了Web⁃Minds提供的网页类型与主题两种标注信息.网页类型指数据网页与非数据网页,二者占比分别为54.27%和45.73%.网页主题涵盖地质学、地球物理学、地理学和地质资源学,占比依次为58.7%,24.1%,9.6%和7.6%.可以发现,不同主题的网页分布呈现不均衡的趋势,服从开放域网页的分布规律.
表1 Web⁃Minds数据集的标签分布
Table 1
| 标签 | 类别 | 占比 |
|---|---|---|
| 网页类型 | 数据网页 | 54.3% |
| 非数据网页 | 45.7% | |
| 网页主题 | 地质学 | 58.7% |
| 地球物理学 | 24.1% | |
| 地理学 | 9.6% | |
| 地质资源学 | 7.6% |
Web⁃Minds针对每个网页提供了丰富的属性信息,如表2所示,包含网页URL链接、网页标题、网页关键词、网页纯文本信息以及网页结构信息.和其他网页数据集相比,Web⁃Minds更注重多视角信息,能帮助研究者还原网页本身.同时,多视角信息也可以支撑更多网页.
表2 Web⁃Minds与现有数据集的对比
Table 2
数据挖掘下游任务助力研究人员设计算法与性能评估,Web⁃Minds数据集的详细信息与数据文件可通过
2.3 数据集特征对比
3 实验结果与分析
为了评估诸多网页分类算法在Web⁃Minds上的表现,针对Web⁃Minds提供的两类标签,设计网页类型分类与网页主题分类两种任务,并对类别不均衡与域名分布偏移问题展开讨论.实验旨在验证数据集的可用性与多视角特征的增益,同时为后续网页分类研究提供基准指标参考.
3.1 实验设置
3.1.1 数据集划分
在网页类型与主题分类实验中,Web⁃Minds数据集中的样本被随机切分为训练集、验证集与测试集,比例为6∶1∶3.在域名分布偏移研究中,根据网页域名信息分为训练集、验证集与测试集,比例同前.原则上训练集与后两者中的样本来源于不同域名,以模拟开放域应用场景分布.
3.1.2 实验环境
网页分类算法均基于Pytorch深度学习框架实现,采用Adam优化器对网络进行参数更新,实验设备为NVIDIA GeForce GTX 3090 GPU.
3.1.3 评估指标
采用准确率(Accuracy,Acc)、精确率(Precision,Pre)、召回率(Recall,R)和F1分数(F1⁃score,F1)对算法进行评估.对于主题分类,考虑到其类别不均衡性,采用Micro⁃Recall(Micro⁃R)与Micro⁃F1进行评估.
3.2 基准算法
选用机器学习方法、文本分类算法与网页分类算法对Web⁃Minds进行多维评估,具体算法如下.
(1)机器学习方法
LR (Logistic Regression):逻辑回归模型.
SVM (Support Vector Machine):支持向量机模型.
(2)文本分类算法
BERT[23]:是基于Transformer架构的预训练语言模型,利用掩码语言模型生成深层双向语言表征,在自然语言处理多个任务中取得了最优性能.
RoBERTa[24]:是BERT的调优版本,有更大的模型参数量、更大的批容量和更多的训练数据.
XLNet[25]:是一种自回归语言模型,利用双流自注意力机制对上下文信息进行建模.
(3)网页分类算法
RiSER[15]:使用Word2Vec与LSTM对垃圾邮件中的文本与对应的XPath进行编码,对二者隐向量拼接后用于垃圾邮件分类.
DC⁃F[16]:是谷歌学者提出的利用网页URL链接与短文本描述信息进行数据集网页分类的算法.
SMGCN[12]:针对网页多视角特征构建多个关系图,使用图卷积网络提取多视角信息,并通过注意力机制加权多图贡献.
Fusion:使用BERT与LSTM[26]对网页中的文本信息与DOM结构信息分别进行编码和特征融合后训练分类器.
3.3 实验结果分析
3.3.1 网页类型分类
表3 多种基准算法在本文Web⁃Minds上的网页类型分类性能
Table 3
| 方法 | Acc | Pre | R | F1⁃score |
|---|---|---|---|---|
| LR | 65.26% | 70.44% | 70.52% | 0.7048 |
| SVM | 68.31% | 72.42% | 75.04% | 0.7371 |
| BERT | 76.65% | 82.18% | 86.53% | 0.8430 |
| RoBERTa | 76.56% | 81.89% | 86.12% | 0.8395 |
| XLNet | 75.08% | 82.03% | 85.89% | 0.8392 |
| RiSER | 70.33% | 76.54% | 79.21% | 0.7785 |
| DC⁃F | 70.29% | 79.34% | 83.27% | 0.8126 |
| SMGCN | 78.04% | 83.11% | 87.76% | 0.8537 |
| Fusion | 82.14% | 84.89% | 90.75% | 0.8772 |
网页类型分类中,综合利用多视角特征的方法明显优于只使用单视角特征的方法,证明了网页DOM结构特征的重要性.网页文本仅能表达网页内容的部分语义信息,无法精确刻画网页的布局特征,这在一定程度上限制了分类准确性.
3.3.2 网页主题分类
针对网页主题分类任务来测试多种基准算法的性能,实验结果如表4所示.与网页类型分类结果相似,Fusion由于综合利用了网页文本与DOM结构特征,取得了74.36% 的准确率,优于其他基准模型.由于缺少网页结构信息,BERT,RoBERTa与XLNet等预训练模型和Fusion相比,性能下降了5%~6%.
表4 多种基准算法在本文Web⁃Minds上的网页主题分类性能
Table 4
| 方法 | Acc | Micro⁃R | Micro⁃F1 |
|---|---|---|---|
| LR | 48.37% | 58.25% | 0.5633 |
| SVM | 51.35% | 60.42% | 0.6267 |
| BERT | 68.75% | 76.35% | 0.8430 |
| RoBERTa | 69.59% | 77.21% | 0.7690 |
| XLNet | 68.03% | 75.88% | 0.7478 |
| RiSER | 62.87% | 69.47% | 0.7064 |
| DC⁃F | 65.74% | 73.27% | 0.7265 |
| SMGCN | 70.12% | 77.76% | 0.7709 |
| Fusion | 74.36% | 81.79% | 0.8021 |
Web⁃Minds中四个主题类别样本的数量不平衡,所以其分类准确率参差不齐.针对这一问题,采用三种常用的类别不均衡策略来优化类别分布与模型参数更新过程.样本生成与下采样分别对应增加少样本类别中网页数量与减少多样本类别中网页数量,损失重加权采用Lin et al[27]的Focal loss,通过修改损失函数对不同类别样本赋予不同的权重来优化模型参数.实验结果如图8所示,分析发现:(1)Focal loss损失重加权的结果最优,尤其是在Fusion模型上,原因是在训练期间改变了四个类别的权重,并强化了对难区分样本的学习;(2)通过生成相似的样本和调整样本比例来提高性能,但由于样本信息有限,改进不够显著;(3)尽管下采样平衡了不同类别的样本数量,但其随机丢失了部分关键信息,降低了分类性能.
图8
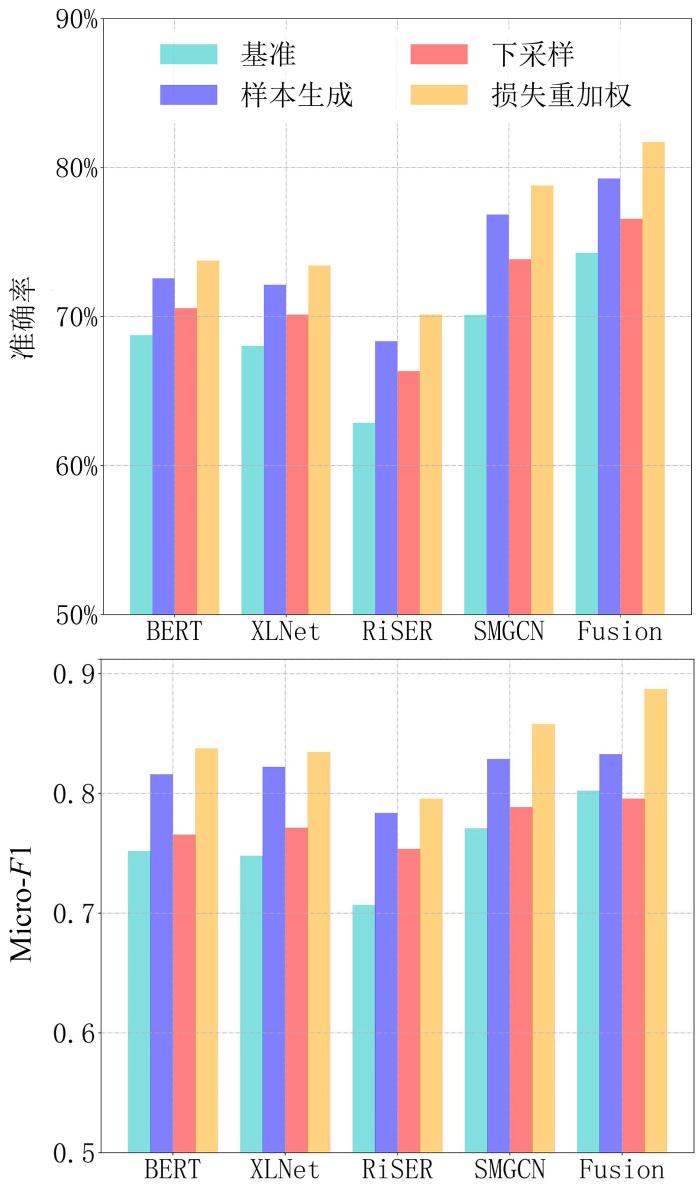
图8
网页主题分类中类别不均衡的实验结果
Fig.8
Performance of different topics with category imbalance
网页主题分类任务中,Web⁃Minds在提供网页文本、DOM结构和语义等信息的同时,其样本类别分布不均的特性真实反映了模型处理类别不平衡数据的能力.表5展示了进行网页主题分类时多视角分类Fusion模型在四种分布不均衡类别上的性能.分析发现:(1)由于地质学与地球物理学样本占比较高,分别为58.7%和24.1%,在不同样本不均衡策略下,分类准确率较高,地理学与地质资源学两类样本较少,模型在这两类上性能有所下降;(2)和下采样与样本生成策略相比,损失重加权将样本分布与预测概率纳入优化过程,对于样本偏少的类别准确率的提升更显著.这种评估可以更全面准确地体现模型对少数类别的分类效果,而不是仅仅关注整体准确率.
表5 Fusion模型对分布不均衡的网页主题进行分类的准确率比较
Table 5
| 类别 | 下采样 | 样本生成 | 损失重加权 |
|---|---|---|---|
| 平均 | 75.56% | 79.26% | 82.90% |
| 地质学 | 78.36% | 82.24% | 84.17% |
| 地球物理学 | 77.35% | 81.92% | 83.67% |
| 地理学 | 68.71% | 74.35% | 78.17% |
| 地质资源学 | 68.95% | 74.21% | 77.70% |
3.3.3 域名分布偏移分析
域名分布偏移是指将网页分类技术应用于开放互联网过程时,待分类网页与模型观测数据来源不一致的现象,是归纳学习研究的基础问题.Web⁃Minds根据域名信息来划分训练数据与测试数据,原则上保证两者数据来源不同,即具备分布偏移性.
针对网页类型与网页主题分类任务,选取BERT,XLNet,RiSER,SMGCN和Fusion算法模型,实验结果如图9所示.分析发现,测试样本与训练样本来源于不同网站,其内容形式有较大差异,特征分布存在明显偏移,所以各算法在Web⁃Minds分布偏移数据集上的性能均有不同程度的下降.进一步对比,Fusion与SMGCN的下降幅度较小,因为这两种模型均利用文本与DOM结构信息进行网页表征,充分学习相似网页间的语义特征与布局特征关联,提升了模型在分布偏移场景下的分类性能.
图9
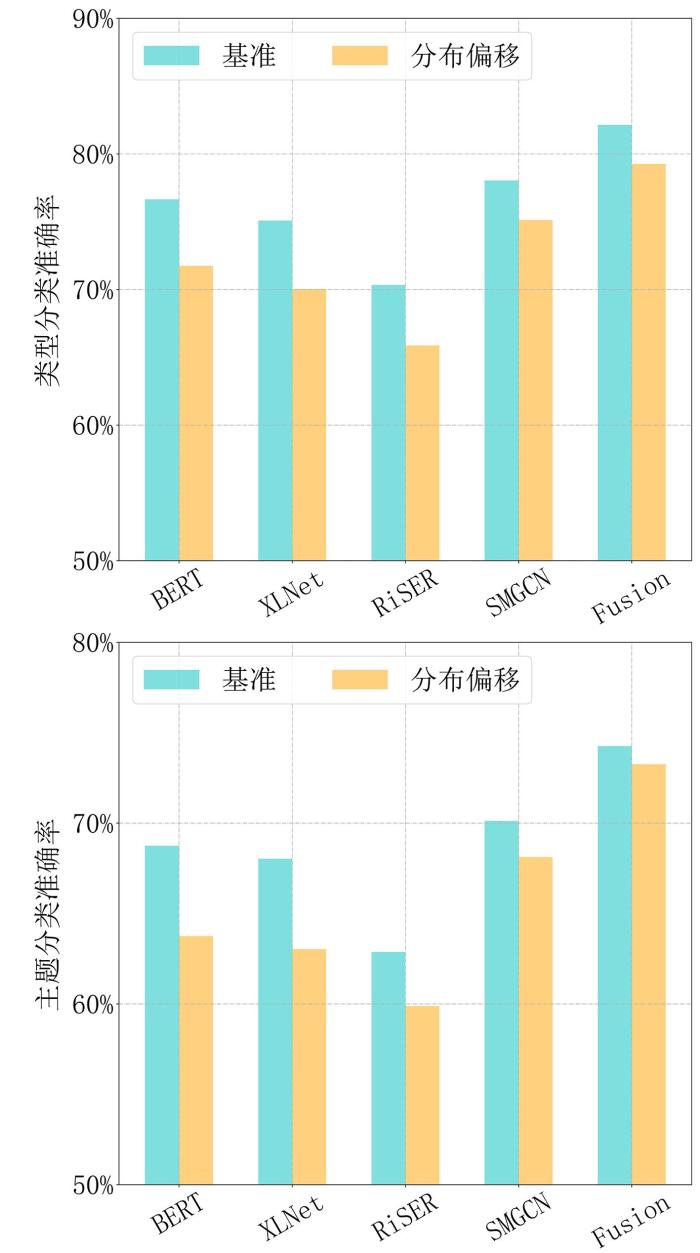
图9
不同算法对存在域名分布偏移的网页进行分类的准确率比较
Fig.9
Accuracy of webpage classification with domain distribution shift by different algorithms
本文提供的具备域名分布偏移性的Web⁃Minds数据集,旨在为归纳学习研究与网页分类算法的实际应用提供重要数据来源.
4 结论
本文提出了一个面向多视角网页分类的公开数据集Web⁃Minds,旨在为网页分类研究提供高质量数据来源.Web⁃Minds包含600余个门户网站的21828条网页,同时提供多视角的网页语义文本与DOM树结构信息,全方位刻画网页特征.在网页类型分类与主题分类上分别使用多种基准分类算法进行评估,证明多视角特征可以显著提升分类任务的性能,为模型设计和性能调优提供数据参考.后续将持续更新Web⁃Minds,提供更大规模、更多网页内容属性信息的数据集.
参考文献
大数据系统和分析技术综述
Survey on big data system and analytic technology
面向搜索的微博短文本语义建模方法
Microblog short text semantic modeling method for search
Dataset search:A survey
Learning intents behind interactions with knowledge Graph for recommendation
∥
Contrastive learning for sequential recommendation
∥
DataExpo:A one⁃stop dataset service for open science research
∥
Auctus:A dataset search engine for data discovery and augmentation
Classifier and feature set ensembles for web page classification
A unified dimensionality reduction framework for semi⁃paired and semi⁃supervised multi⁃view data
Learning to remove internet advertisements
∥
Web page classification based on heterogeneous features and a combination of multiple classifiers
Semi⁃supervised classification with graph convolutional networks
∥
The deep⁃time digital earth program:Data⁃driven discovery in geosciences
Using genres to improve search engines
∥
RiSER:Learning better representations for richly structured emails
∥
Dataset or not? A study on the veracity of semantic markup for dataset pages
∥
Neural news recommendation with attentive multi⁃view learning
∥
Co⁃GCN for multi⁃view semi⁃supervised learning
∥
Semi⁃supervised multi⁃view correlation feature learning with application to webpage classification
∥
Semi⁃supervised multi⁃view individual and sharable feature learning for webpage classification
∥
Semi⁃supervised multi⁃view deep discriminant representation learning
org:Evolution of structured data on the web
BERT:Pre⁃training of deep bidirectional transformers for language understanding
∥
RoBERTa:A robustly optimized BERT pretraining approach
XLNet:Generalized autoregressive pretraining for language understanding
∥
Long short⁃term memory
Focal loss for dense object detection
∥

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}