


为了解决以上问题,本文设计并提出一种新颖的基于改进局部密度的可扩展层次聚类算法DBSC (Density⁃based Scalable Hierarchical Clustering),其利用每个数据项的最近邻来构造最近邻图,在最近邻图上结合互惠最近邻[7]和局部密度寻找每个最近邻分量最适合的代表点,避免人工结点占用额外内存.为了降低孤立最近邻分量对该步骤的干扰,算法通过二阶最近邻定位并重连至适合的最近邻分量.最后,将每个最近邻图上的结点指派至其代表结点,由代表结点参与后续迭代过程.通过以上步骤,DBSC算法可以构造一棵理想的聚类树,使其兼具良好的扩展性和可理解性,因此可以被用于大规模数据的处理和分析.
本文的创新点如下.
(1)提出一种重连机制,以避免孤立最近邻对代表点选择造成的干扰.该机制利用孤立最近邻结点的二阶最近邻来选择适合的最近邻分量,并将其连接,该操作能保证代表点选择策略对于每个最近邻分量都是有效的.
(2)提出基于改进局部密度的代表点选择策略,能区分最近邻分量上的互惠最近邻结点,这样既可以避免额外的内存占用,又可以提高聚类效果.
(3)通过在真实数据和人工数据上的大量实验研究来验证DBSC算法的性能,证明DBSC的聚类准确度优于其他的基准算法,且在大规模数据上有较好的表现.经过统计学检验,DBSC算法的聚类效果在5%的统计显著水平上优于其他基准算法,证明DBSC是一种十分有效的算法.经过效率和扩展性验证的结果表明,DBSC算法在时间和空间上的需求相对较低,可以在大规模数据上应用.
1 相关工作
为了提高层次聚类算法的可扩展性,利用最近邻关系[10]代替成对距离进行聚类受到广泛关注.SCC算法[11]利用最近邻关系改进了层次聚类,加速了簇合并的过程.在此基础上,Monath et al[12]设计了一种新的数据结构SB⁃Tree,结合流式数据结点插入时间重新调整聚类树以获得更佳的聚类效果.Ros and Guillaume[13]进一步考虑从互惠最近邻开始聚合其他距离较近的结点构造聚类树,直至所有结点均被分配.RSC算法[7]借助最近邻构造子簇树,并将互惠最近邻的中点视为代表点.算法迭代过程中,不断聚合代表点来构造聚类树.Huang et al[14]提出一种基于一致性选择方法的集成层次聚类算法.该算法首先利用多种基本的层次聚类算法来创建主要的聚类,然后利用一种稳健性度量对聚类和分区水平的结果进行评估.此外,面对大规模多模态多目标优化问题,提出一种基于混合层次聚类的多模式进化算法HHC⁃MMEA[15].它通过混合分层聚类将解空间中的解聚类成多个组,结合了局部和全局引导向量,加速收敛并生成更多有前途的解.这些算法虽然在加速聚类过程上取得成效,但在平衡聚类效果和资源消耗的问题上还需要进一步优化.
大多数聚类算法在面对不同形状和密度的簇时无法取得令人满意的效果,此时,引出基于密度的聚类DBSCAN算法[16],通过密度可达的概念定义核心对象.当选择合适的半径参数
在面向大规模聚类的应用上,基于密度的算法往往受限于全局密度估计计算带来的高额时间和空间开销,为此,研究者们提出了多种优化方案,例如基于采样策略减少距离计算[22]、基于K近邻假设改进分配策略[23-24]等.然而不论采用何种方式,时间和空间开销的平衡仍待解决.最近邻关系在聚类算法中的应用[25],尤其是大规模数据处理上备受关注,因为其时间开销小,且最近邻关系所构建的数据结构本就具备高密度区域的特征,而互惠最近邻又可以看作该区域上的局部密度最大的区域.采用基于改进局部密度策略来选择互惠最近邻中更加适合的代表点,不会产生中间变量,因此显著降低了空间上的消耗.综上,该策略可有效应对大规模数据的处理.
2 基础概念
2.1 最近邻
在欧式空间上,对于给定的数据集
则称
2.2 互惠最近邻
设存在向量
2.3 最近邻分量
给定一个无向图
3 算法描述
DBSC是一种自底向上的层次聚类算法,主要过程包含三个部分:(1)最近邻图的构建
DBSC的执行流程如算法1所示:
输入:数据
输出:数据标签
1.
2.for
3.
4. 通过
5. 通过
6. if
7.
8.return
首先,将数据保存在数据对象集合
图1是DBSC算法的一个例子,其中初始结点的分布如图1a所示.图1b展示了DBSC算法的工作流程.首先,
图1
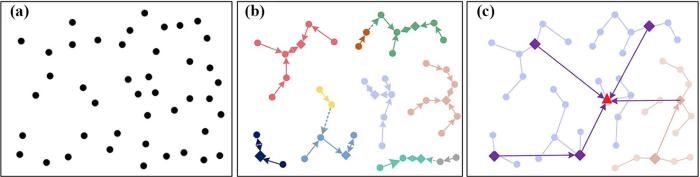
3.1 构建最近邻分量
构造最近邻分量是DBSC的基础步骤,其主要目的是:(1)通过最近邻关系划分数据集;(2)定位每个最近邻分量上的互惠最近邻.使用Ball⁃Tree算法[10]可以快速获得结点间的最近邻关系,紧接着连接每个最近邻对,如果发现某对结点重复连接,说明该对结点为互惠最近邻,最后从互惠最近邻点开始执行广度优先搜索,就可以得到多个最近邻分量.此外,如果存在孤立最近邻分量,则通过
该过程的伪代码如算法2所示.
输入:数据集合
输出:最近邻分量集合
1.
2.
3.for each
4. if
5. else 将
6.for each
7.
8.
9.return
图2
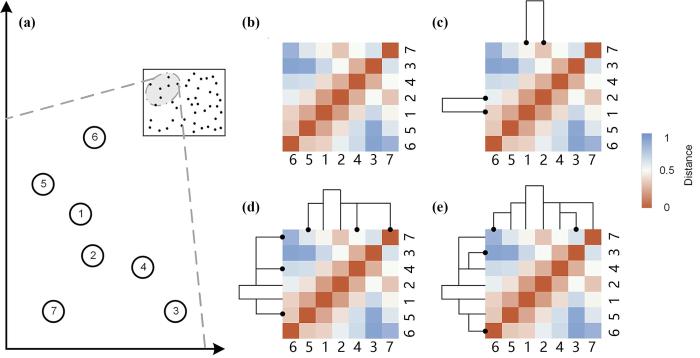
3.2 重连孤立最近邻分量
由于iNNC的两个节点的密度相等,所以无法有效识别唯一的代表点.为了保证对于每个NNC都存在唯一一个代表点,本文提出一种优化策略.该策略将借助iNNC的二阶最近邻结点定位距离它最近的NNC.然后将iNNC和结点数量较小的NNC相连接.通过该操作,一方面解决最近邻选择策略无法作用于iNNC的问题,另一方面通过增加结点数量以加强局部密度对于选择代表点的作用.
该过程的伪代码如算法3所示.
iNNCsRep算法
输入:最近邻分量集合
输出:最近邻分量集合
1.从
2.For each
3. 寻找
4.
5. If
6. Else 连接
7.return
图3
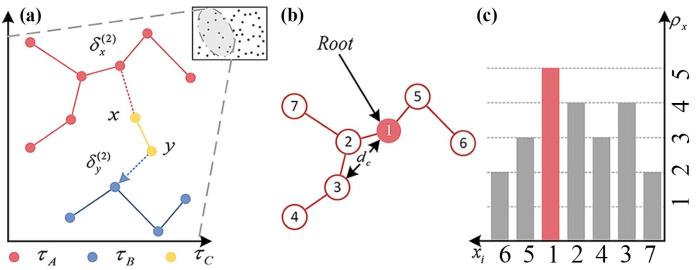
3.3 寻找代表结点
DBSC的最后一步就是在每个RNN中选择一个结点,该结点将作为最近邻分量的根结点.在后续迭代过程中,代表结点代替最近邻分量中的其余结点参与聚类树的构造.因此,每轮迭代后,需要计算的数据量将大幅减少.本文采用基于密度的代表点选举策略,给定截断阈值
其中,
给定一个最近邻组件
其中,
该过程的伪代码如算法4所示.
RootsDet算法
输入:最近邻分量集合
输出:根节点集合
1.
2.For each
3.
4.
5.
6.
7. If
8. else
9.
10.return
RootsDet遍历每个最近邻分量
3.4 复杂度分析
DBSC算法主要包括三个步骤:(1)最近邻图的构建
由上可知,DBSC的时间复杂度为
4 实验
4.1 实验数据集
表1 实验中采用的来源于真实世界的数据集
Table 1
| 编号 | 名称 | 样本数 | 属性 | 类别 |
|---|---|---|---|---|
| 1 | mfeat⁃fourier | 2000 | 76 | 10 |
| 2 | mfeat⁃karhune | 2000 | 64 | 10 |
| 3 | mfeat⁃zernike | 2000 | 47 | 10 |
| 4 | segment | 2310 | 18 | 7 |
| 5 | optdigits | 5620 | 62 | 10 |
| 6 | letter | 20000 | 16 | 26 |
| 7 | avila | 20867 | 10 | 12 |
| 8 | ALOI | 108K | 128 | 1000 |
| 9 | ILSVRC(Ⅰ) | 500K | 100 | 400 |
| 10 | ILSVRC(Ⅱ) | 500K | 100 | 400 |
| 11 | CovType | 500K | 54 | 7 |
| 12 | har | 2259K | 7 | 15 |
实验使用的人工数据集是利用在机器学习领域广泛使用的python工具包sklearn生成不同数量的数据集.这些数据集具有十个维度,大小为
4.2 评价指标
兰德指数[29](Rand Index,RI)考虑所有样本对,计算在预测聚类和真实聚类中分配在相同或不同聚类中的对来计算两个聚类之间的相似性度量.取值为
其中,
调整兰德指数[30](Adjusted Rand Index,ARI)通过计算在真实标签和聚类结果中被分配在相同或不同类簇的样本对的个数来进行聚类有效性的评价.其取值为
归一化互信息[31](Normalized Mutual Information,NMI)可以衡量两个数据分布的吻合程度,表示两个事件集合之间的相关性.其取值为
其中,
4.3 对比算法
对于小规模数据集的参数
RSC[7]是一种高效的凝聚式层次聚类算法,借助最近邻链和人造结点构造聚类树.
HK⁃means[8]是一种自顶向下的层次聚类算法,使用K⁃means算法划分并构造聚类树.
SCC[11]是一种基于一阶最近邻图和传统连接方法的可扩展的凝聚式层次聚类算法.
Munec[13]是一种凝聚式的层次聚类算法,同时考虑了距离和最近邻对于簇的影响.
DPC[17]是基于密度峰值的聚类算法,使用决策图选择密度中心进行聚类.
HAC[32]是传统的凝聚式层次聚类算法,本文算法使用average⁃link方式进行聚类.
Affinity[33]是基于Boruvka最小生成树和链接函数的层次聚类.
GRINCH[34]是一种用于大规模、非贪婪的分层聚类的聚类算法.
streaKHC[35]是一种流式聚类算法,基于随机划分判断簇间相似性进行点对合并操作.
4.4 实验环境配置
硬件设备CPU为i9⁃12900,内存为64 G,操作系统为Windows 11.编程语言采用Python 3.8.
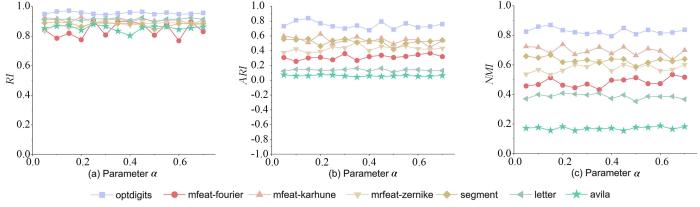
4.5 参数敏感性
如图4所示,使用RI,ARI和NMI指标测量的DBSC算法精度在avila,letter,optdigits数据集上波动较小,但是在其他数据集上波动明显,证明DBSC对于参数
图4
4.6 聚类准确性
表2展示了所有算法在七个普通UCI数据集上的表现,表中黑体字表示性能最优,下划线表示性能次优.其中,DBSC(opt=
表2 本文算法和对比算法在UCI数据集上的聚类结果
Table 2
| 数据集 | 算法 | RI | ARI | NMI | 数据集 | 算法 | RI | ARI | NMI |
|---|---|---|---|---|---|---|---|---|---|
| mfeat⁃fourier | DBSC(opt=0.65) | 0.8810 | 0.3680 | 0.5345 | mfeat⁃karhune | DBSC(opt=0.2) | 0.9305 | 0.6261 | 0.7384 |
| DBSC(0.7) | 0.8308 | DBSC(0.7) | |||||||
| HAC | 0.1818 | 0.0040 | 0.0816 | HAC | 0.5016 | 0.1030 | 0.3423 | ||
| Affinity | 0.7980 | 0.2159 | 0.4523 | Affinity | 0.8965 | 0.5086 | 0.6778 | ||
| DPC | 0.5036 | 0.0796 | 0.1897 | DPC | 0.7228 | 0.1766 | 0.3798 | ||
| GRINCH | 0.1988 | 0.0002 | 0.0159 | GRINCH | 0.2091 | <0.0001 | 0.0233 | ||
| HK⁃means | 0.8562 | 0.3169 | 0.4557 | HK⁃means | 0.8959 | 0.3964 | 0.5316 | ||
| Munec | 0.8168 | 0.2581 | 0.4821 | Munec | 0.8729 | 0.3294 | 0.6209 | ||
| RSC | 0.8367 | 0.3195 | 0.5046 | RSC | 0.8830 | 0.5172 | 0.7110 | ||
| SCC | 0.1028 | <0.0001 | 0.0028 | SCC | 0.4869 | 0.0261 | 0.1333 | ||
| streaKHC | 0.3035 | 0.4220 | streaKHC | 0.8737 | 0.3539 | 0.4710 | |||
| mfeat⁃zernike | DBSC(opt=0.35) | 0.9084 | 0.5174 | 0.6270 | segment | DBSC(opt=0.3) | 0.8910 | 0.5584 | |
| DBSC(0.7) | 0.8729 | 0.4322 | DBSC(0.7) | 0.6246 | |||||
| HAC | 0.5733 | 0.1368 | 0.4016 | HAC | 0.5983 | 0.2394 | 0.5757 | ||
| Affinity | 0.8036 | 0.2592 | 0.4650 | Affinity | 0.8752 | 0.5090 | 0.6481 | ||
| DPC | 0.4934 | 0.0296 | 0.0617 | DPC | 0.3970 | 0.0122 | 0.0320 | ||
| GRINCH | 0.3800 | 0.0601 | 0.1636 | GRINCH | 0.5897 | 0.2385 | 0.3908 | ||
| HK⁃means | 0.8565 | 0.3195 | 0.4323 | HK⁃means | 0.8412 | 0.4165 | 0.5391 | ||
| Munec | 0.8293 | 0.2354 | 0.5365 | Munec | 0.8428 | 0.2052 | 0.5154 | ||
| RSC | 0.5903 | RSC | 0.7311 | 0.3043 | 0.5329 | ||||
| SCC | 0.6082 | 0.0701 | 0.1829 | SCC | 0.6148 | 0.2139 | 0.3669 | ||
| streaKHC | 0.8609 | 0.3158 | 0.4358 | streaKHC | 0.8592 | 0.4625 | 0.5699 | ||
| optdigits | DBSC(opt=0.15) | 0.9722 | 0.8401 | 0.8694 | letter | DBSC(opt=0.4) | 0.9261 | 0.4027 | |
| DBSC(0.7) | 0.9576 | 0.7603 | 0.8373 | DBSC(0.7) | 0.9140 | 0.1303 | |||
| HAC | 0.8956 | 0.5517 | 0.7341 | HAC | 0.7841 | 0.0608 | 0.3342 | ||
| Affinity | Affinity | 0.9047 | 0.1283 | 0.3830 | |||||
| DPC | 0.6551 | 0.1146 | 0.2730 | DPC | 0.0663 | 0.0001 | 0.0066 | ||
| GRINCH | 0.2754 | 0.0160 | 0.1001 | GRINCH | 0.2311 | 0.0017 | 0.0514 | ||
| HK⁃means | 0.9119 | 0.5374 | 0.6347 | HK⁃means | 0.8323 | 0.0713 | 0.2440 | ||
| Munec | 0.7739 | 0.1791 | 0.5729 | Munec | 0.5131 | 0.0092 | 0.2367 | ||
| RSC | 0.8623 | 0.4832 | 0.7013 | RSC | 0.1498 | 0.3927 | |||
| SCC | 0.7108 | 0.1906 | 0.3654 | SCC | 0.3948 | 0.0059 | 0.0511 | ||
| streaKHC | 0.8946 | 0.4515 | 0.5507 | streaKHC | 0.9125 | 0.0836 | 0.2396 | ||
| avila | DBSC(opt=0.15) | 0.7249 | 0.0929 | 0.1842 | Mean | DBSC(opt) | 0.8906 | 0.4483 | 0.5708 |
| DBSC(0.7) | 0.7134 | DBSC(0.7) | |||||||
| HAC | 0.2820 | <0.0001 | 0.0328 | HAC | 0.5452 | 0.1557 | 0.3575 | ||
| Affinity | 0.7113 | 0.0528 | 0.1617 | Affinity | 0.8505 | 0.3535 | 0.5188 | ||
| DPC | 0.5009 | 0.0151 | 0.0814 | DPC | 0.4770 | 0.0611 | 0.1463 | ||
| GRINCH | 0.2967 | 0.0069 | 0.0420 | GRINCH | 0.3115 | 0.0461 | 0.1124 | ||
| HK⁃means | 0.2598 | <0.0001 | 0.0199 | HK⁃means | 0.7791 | 0.2932 | 0.4082 | ||
| Munec | 0.5761 | 0.0480 | 0.1615 | Munec | 0.7464 | 0.1806 | 0.4466 | ||
| RSC | 0.5271 | 0.0224 | 0.0714 | RSC | 0.8063 | 0.3233 | 0.5006 | ||
| SCC | 0.2484 | <0.0001 | 0.0284 | SCC | 0.4524 | 0.0716 | 0.1615 | ||
| streaKHC | 0.0245 | 0.0886 | streaKHC | 0.8550 | 0.2850 | 0.3968 |
表3展示了所有算法在大型数据集上的表现,表中黑体字表示性能最优,“-”表示由于内存需求过大无法在实验环境中运行的算法.DBSC(0.5)表示参数
表3 本文算法和对比算法在五个大规模数据集上的聚类结果
Table 3
| 数据集 | 算法 | RI | ARI | NMI | 数据集 | 算法 | RI | ARI | NMI |
|---|---|---|---|---|---|---|---|---|---|
| ALOI | DBSC(0.5) | 0.9990 | 0.4543 | 0.7834 | CovType | DBSC(0.5) | 0.6113 | 0.0346 | 0.1592 |
| HK⁃means | 0.9921 | 0.0864 | 0.6701 | HK⁃means | 0.5997 | 0.0941 | 0.1595 | ||
| RSC | 0.9962 | 0.2565 | 0.8004 | RSC | 0.5645 | 0.0083 | 0.0461 | ||
| SCC | 0.9900 | <0.0001 | 0.6915 | SCC | 0.4316 | 0.0504 | <0.0001 | ||
| streaKHC | 0.0901 | <0.0001 | 0.0600 | streaKHC | - | - | - | ||
| ILSVRC(I) | DBSC(0.5) | 0.9851 | 0.0420 | 0.3031 | ILSVRC(Ⅱ) | DBSC(0.5) | 0.9918 | 0.0483 | 0.3309 |
| HK⁃means | 0.5181 | 0.0002 | 0.0439 | HK⁃means | 0.5700 | 0.0002 | 0.0385 | ||
| RSC | 0.6343 | 0.0011 | 0.2042 | RSC | 0.9867 | 0.0291 | 0.3050 | ||
| SCC | 0.1585 | <0.0001 | 0.0143 | SCC | 0.2696 | <0.0001 | 0.0125 | ||
| streaKHC | - | - | - | streaKHC | - | - | - | ||
| har | DBSC(0.5) | 0.7049 | 0.2718 | 0.4406 | Mean | DBSC(0.5) | 0.8584 | 0.1702 | 0.4035 |
| HK⁃means | 0.6409 | 0.1749 | 0.2679 | HK⁃means | 0.6642 | 0.0711 | 0.2360 | ||
| RSC | 0.5795 | 0.2476 | 0.3851 | RSC | 0.7523 | 0.1085 | 0.3482 | ||
| SCC | - | - | - | SCC | - | - | - | ||
| streaKHC | - | - | - | streaKHC | - | - | - |
4.7 统计学检验评估
为了验证DBSC算法的上述优势具有统计学意义,进行配对
表4 在所有数据集上的成对检验结果
Table 4
| 评价指标 | HAC | Affinity | DPC | GRINCH | HK⁃means | Munec | RSC | SCC | streaKHC | |
|---|---|---|---|---|---|---|---|---|---|---|
| RI | t⁃value | 5.0204 | 3.0212 | 6.8472 | 11.0110 | 2.7193 | 3.8603 | 3.1274 | 7.6177 | 2.5354 |
| p⁃value | 0.0004 | 0.0116 | <0.0001 | <0.0001 | 0.0200 | 0.0027 | 0.0096 | <0.0001 | 0.0277 | |
| ARI | t⁃value | 4.5508 | 3.2136 | 4.3996 | 4.1685 | 3.7369 | 3.9972 | 3.0334 | 4.5698 | 4.1749 |
| p⁃value | 0.0008 | 0.0083 | 0.0011 | 0.0016 | 0.0033 | 0.0021 | 0.0114 | 0.0008 | 0.0016 | |
| NMI | t⁃value | 5.6271 | 2.9437 | 7.3709 | 6.7397 | 6.9410 | 3.9242 | 4.0527 | 7.6785 | 6.7032 |
| p⁃value | 0.0002 | 0.0134 | <0.0001 | <0.0001 | <0.0001 | 0.0024 | 0.0019 | <0.0001 | <0.0001 | |
4.8 效率和可扩展性
为了更好地证明DBSC算法在执行效率上的优势,在增量人工数据集上对所有算法进行响应时间的多项式拟合,结果如表5所示.由表可见,DBSC的拟合结果为1.62,仅次于SCC(1.40)和HK⁃means(1.39).
表5 所有算法响应时间的多项式拟合结果
Table 5
| 算法名称 | DBSC | HAC | Affinity | DPC | GRINCH |
|---|---|---|---|---|---|
| 拟合结果 | 1.62 | 2.38 | 2.17 | 2.23 | 3.24 |
| 算法名称 | HK⁃means | Munec | RSC | SCC | streaKHC |
| 拟合结果 | 1.39 | 3.02 | 1.70 | 1.40 | 2.08 |
图5展示了DBSC及其他九个基准算法的响应时间和内存占用情况,其结果在双对数坐标下展示.实验表明,与大多数基准算法相比,DBSC算法的时间和内存消耗较少,对比算法中只有HK⁃means的内存消耗较低.
图5
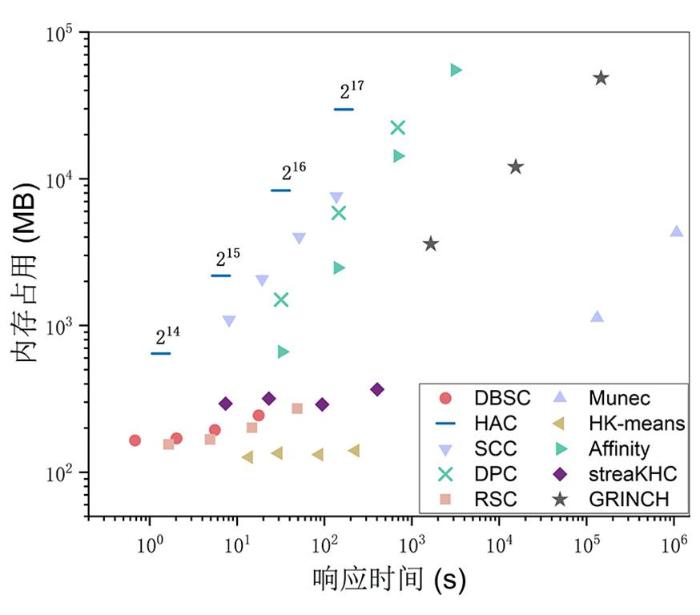
综上所述,DBSC的准确性优于所有基准算法,效率和可扩展性仅次于HK⁃means.
5 结论
对于层次聚类算法难以平衡时间和空间的开销问题,本文提出基于改进局部密度的可扩展层次聚类算法.通过最近邻关系构造最近邻图,从局部密度峰值的角度出发,为每个最近邻分量确定最佳代表点以构造子簇树.最终,算法迭代地构造一棵聚类树,并有效地降低了时间和空间的开销.经过大量实验证明,本文提出的算法在聚类精度上优于其他基准算法.此外,本文与其他算法相比,具有更低的时间和空间开销.
综上所述,本文提出的DBSC算法在较低的时间消耗和空间消耗下,能够高效地对数据进行聚类,同时提供可靠的聚类结果,是一种有效且高效的算法,并能够在现实应用中发挥作用.未来将致力于解决参数
参考文献
加权最近邻分配的局部间隙密度聚类
Weighted nearest neighbor distribution of local gap density clustering
基于相关熵和流形正则化的图像聚类
Image clustering based on correntropy and manifold regularization
基于机器学习的自发性早产生物标记物发现
Discovery of spontaneous preterm birth biomarkers based on machine learning
Minimum spanning tree hierarchical clustering algorithm:A new Pythagorean fuzzy similarity measure for the analysis of functional brain networks
Salting our freshwater lakes
Boosting cluster tree with reciprocal nearest neighbors scoring
Hierarchical clustering supported by reciprocal nearest neighbors
A hierarchical algorithm for extreme clustering
∥
The k⁃means algorithm:A comprehensive survey and performance evaluation
Multidimensional binary search trees used for associative searching
Scalable hierarchical agglomerative clustering
∥
Online level⁃wise hierarchical clustering
∥
Munec:A mutual neighbor⁃based clustering algorithm
An ensemble hierarchical clustering algorithm based on merits at cluster and partition levels
Large⁃scale multimodal multiobjective evolutionary optimization based on hybrid hierarchical clustering
A density⁃based algorithm for discovering clusters in large spatial databases with noise
∥
Clustering by fast search and find of density peaks
Clustering by fast search and find of density peaks via heat diffusion
DPCG:An efficient density peaks clustering algorithm based on grid
VDPC:Variational density peak clustering algorithm
An improved density peaks clustering algorithm based on natural neighbor with a merging strategy
A sampling⁃based density peaks clustering algorithm for large⁃scale data
SFKNN⁃DPC:Standard deviation weighted distance based density peak clustering algorithm
Fast density peaks clustering algorithm based on improved mutual K⁃nearest⁃neighbor and sub⁃cluster merging
Scalable clustering by aggregating representatives in hierarchical groups
Fast exact k nearest neighbors search using an orthogonal search tree
The Amsterdam library of object images
ImageNet large scale visual recognition challenge
Objective criteria for the evaluation of clustering methods
Discrete nonnegative spectral clustering
Efficient agglomerative hierarchical clustering
Affinity clustering:Hierarchical clustering at scale
∥
Scalable hierarchical clustering with tree grafting
∥
Streaming hierarchical clustering based on point⁃set kernel
∥

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}