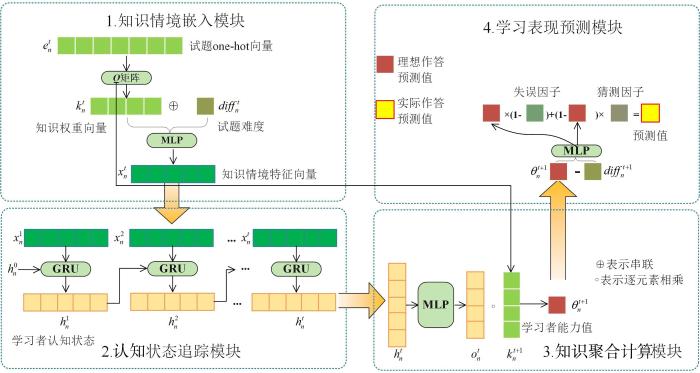
Knowledge tracing aims to track learners' cognitive states dynamically and predict their future performance based on their historical response data. However,existing knowledge tracking models usually only utilize the knowledge concepts representing the test without considering the critical knowledge contextual features contained in the test itself,which limits the effect of the model. Moreover,compared to cognitive diagnosis methods that incorporate educational priors,the interpretability of knowledge⁃tracing models is inadequate. This paper proposes a knowledge context⁃aware deep knowledge tracing model to address these issues. The model includes a knowledge context representation module to capture deep⁃level knowledge weights,question difficulty,and other contextual features. In the knowledge aggregation module,the model embeds the knowledge weights into the computation of learners' abilities toward specific questions. Lastly,in the learning prediction model,the factors of guess and error are introduced,and the predictive performance in real⁃world scenarios is optimized through a cognitive diagnosis model to further improve the model's predictive performance. Compared to existing methods,the model proposed in this paper achieves better prediction results at the question level and demonstrates advantages in model interpretability.
Pu Jie, Zhang Suojuan, Chen Weiwei. Knowledge context⁃aware deep knowledge tracing model. Journal of nanjing University[J], 2024, 60(1): 76-86 doi:10.13232/j.cnki.jnju.2024.01.008
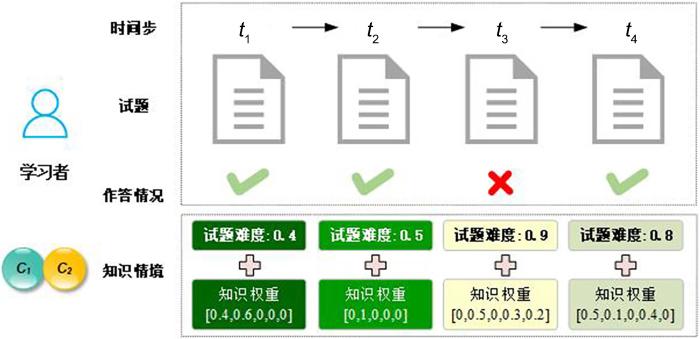
随着互联网和移动通信技术的普及,在线教育正以前所未有的规模发展[1].学习者在使用在线教育系统(如Massive Open Online Course,MOOC)时产生了大量学习者与学习系统之间的交互数据,而知识追踪(Knowledge Tracing,KT)就是从这些交互数据中挖掘学习者动态的认知状态、学习偏好等信息的一类认知诊断技术[2].
现有的知识追踪方法主要捕捉基于学科体系的知识关联,这类知识关联可以看作是相对静态和稳定的.其中,知识先决关系的研究受到了特别关注[6,11],如关系感知知识追踪(Relation⁃Aware Self⁃Attention Model for Knowledge Tracing,RKT)[12]通过自注意力感知试题的上下文信息来获得试题之间的相关关系;注意力知识追踪(Attentive Knowledge Tracing,AKT)[13]则利用多头注意力,用不同的时间尺度对应不同的衰减率来感知过去试题和当前试题的交互关系.
概率图模型用图形和概率分布表示变量之间的关系[15],贝叶斯知识追踪(Bayesian Knowledge Tracing,BKT)是一种具有代表性的基于概率图的知识追踪模型[2].BKT将学习者的认知状态建模为一个动态变化的过程,基于先验概率(通常根据领域专家的经验或大量数据得出)和学习者的历史答题记录,通过隐马尔可夫模型(Hidden Markov Model,HMM)来推测学习者的知识水平和理解程度.在BKT模型的基础上,许多研究者提出了相应的变体模型.例如,Käser et al[16]对知识点之间的关系和多个包含多个知识点的试题进行建模,Khajah et al[17]在BKT模型中引入猜测概率和失误概率,Yudelson et al[18]将学习者特定参数和技能特定参数作为BKT模型的参数.
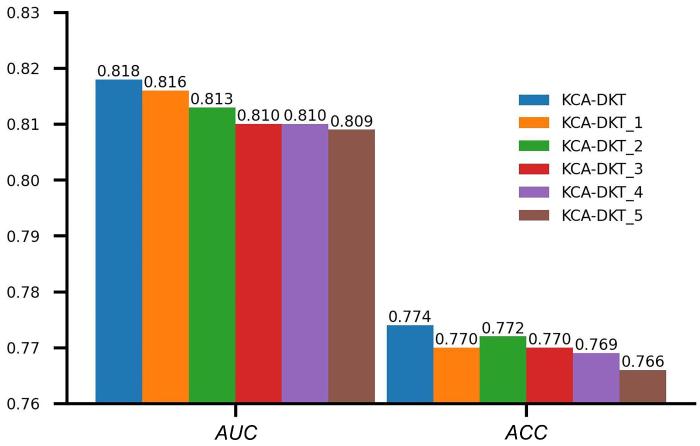
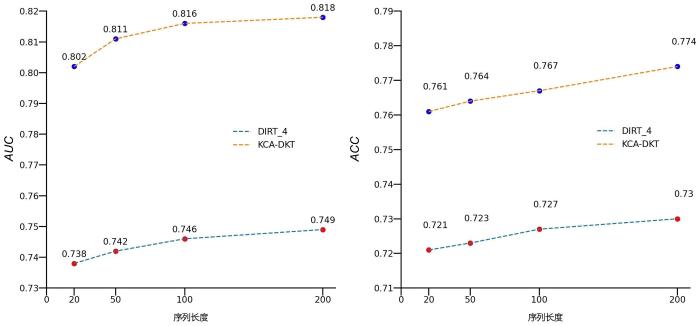
首先在两个公开数据集上进行了实验,选择曲线下方面积(Area under Curve,AUC)和准确性(Accuracy,ACC)作为评价指标.实验结果如表2所示,表中黑体字表示性能最优.由表可见,KCA⁃DKT的性能优于基准模型,预测精度更好.和同为试题层级的融入教育先验的DIRT_4对比,在ASSIST2009数据集上,KCA⁃DKT的AUC提升5.93%,ACC提升4.40%,在Algebra2006数据集上则分别提升了7.97%和2.49%,提升效果比较明显.
Table 2
表2
表2各模型在学习者学习表现预测上的性能对比
Table 2 Performance of each model on learner learning performance prediction
Improving knowledge tracing via pre⁃training question embeddings
∥Proceedings of the 29th International Joint Conference on Artificial Intelligence. Virtual Event:International Joint Conferences on Artificial Intelligence Organization,2020:1577-1583.
RKT:Relation⁃aware self⁃attention for knowledge tracing
∥Proceedings of the 29th ACM International Conference on Information & Knowledge Management. Virtual Event:Association for Computing Machinery,2020:1205-1214.
∥Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Virtual Event:Association for Computing Machinery,2020:2330-2339.
KollerD, FriedmanN. Probabilistic graphical models:Principles and techniques:Adaptive computation and machine learning. Cambridge,MA,USA:The MIT Press,2009:697-716.
Performance factors analysis:A new alternative to knowledge tracing
∥Proceedings of 2009 Conference on Artificial Intelligence in Education:Building Learning Systems that Care:From Knowledge Representation to Affective Modelling. Brighton,UK:IOS Press,2009:531-538.
Dynamic key⁃value memory networks for knowledge tracing
∥Proceedings of the 26th International Conference on World Wide Web. Perth,Australia:International World Wide Web Conferences Steering Committee,2017:765-774.
College students' use and acceptance of emergency online learning due to COVID?19
1
2020
... 随着互联网和移动通信技术的普及,在线教育正以前所未有的规模发展[1].学习者在使用在线教育系统(如Massive Open Online Course,MOOC)时产生了大量学习者与学习系统之间的交互数据,而知识追踪(Knowledge Tracing,KT)就是从这些交互数据中挖掘学习者动态的认知状态、学习偏好等信息的一类认知诊断技术[2]. ...
Knowledge tracing:Modeling the acquisition of procedural knowledge
3
1994
... 随着互联网和移动通信技术的普及,在线教育正以前所未有的规模发展[1].学习者在使用在线教育系统(如Massive Open Online Course,MOOC)时产生了大量学习者与学习系统之间的交互数据,而知识追踪(Knowledge Tracing,KT)就是从这些交互数据中挖掘学习者动态的认知状态、学习偏好等信息的一类认知诊断技术[2]. ...
... 概率图模型用图形和概率分布表示变量之间的关系[15],贝叶斯知识追踪(Bayesian Knowledge Tracing,BKT)是一种具有代表性的基于概率图的知识追踪模型[2].BKT将学习者的认知状态建模为一个动态变化的过程,基于先验概率(通常根据领域专家的经验或大量数据得出)和学习者的历史答题记录,通过隐马尔可夫模型(Hidden Markov Model,HMM)来推测学习者的知识水平和理解程度.在BKT模型的基础上,许多研究者提出了相应的变体模型.例如,Käser et al[16]对知识点之间的关系和多个包含多个知识点的试题进行建模,Khajah et al[17]在BKT模型中引入猜测概率和失误概率,Yudelson et al[18]将学习者特定参数和技能特定参数作为BKT模型的参数. ...
... 现有的知识追踪方法主要捕捉基于学科体系的知识关联,这类知识关联可以看作是相对静态和稳定的.其中,知识先决关系的研究受到了特别关注[6,11],如关系感知知识追踪(Relation⁃Aware Self⁃Attention Model for Knowledge Tracing,RKT)[12]通过自注意力感知试题的上下文信息来获得试题之间的相关关系;注意力知识追踪(Attentive Knowledge Tracing,AKT)[13]则利用多头注意力,用不同的时间尺度对应不同的衰减率来感知过去试题和当前试题的交互关系. ...
Improving knowledge tracing via pre?training question embeddings
... 现有的知识追踪方法主要捕捉基于学科体系的知识关联,这类知识关联可以看作是相对静态和稳定的.其中,知识先决关系的研究受到了特别关注[6,11],如关系感知知识追踪(Relation⁃Aware Self⁃Attention Model for Knowledge Tracing,RKT)[12]通过自注意力感知试题的上下文信息来获得试题之间的相关关系;注意力知识追踪(Attentive Knowledge Tracing,AKT)[13]则利用多头注意力,用不同的时间尺度对应不同的衰减率来感知过去试题和当前试题的交互关系. ...
RKT:Relation?aware self?attention for knowledge tracing
1
2020
... 现有的知识追踪方法主要捕捉基于学科体系的知识关联,这类知识关联可以看作是相对静态和稳定的.其中,知识先决关系的研究受到了特别关注[6,11],如关系感知知识追踪(Relation⁃Aware Self⁃Attention Model for Knowledge Tracing,RKT)[12]通过自注意力感知试题的上下文信息来获得试题之间的相关关系;注意力知识追踪(Attentive Knowledge Tracing,AKT)[13]则利用多头注意力,用不同的时间尺度对应不同的衰减率来感知过去试题和当前试题的交互关系. ...
Context?aware attentive knowledge tracing
3
2020
... 现有的知识追踪方法主要捕捉基于学科体系的知识关联,这类知识关联可以看作是相对静态和稳定的.其中,知识先决关系的研究受到了特别关注[6,11],如关系感知知识追踪(Relation⁃Aware Self⁃Attention Model for Knowledge Tracing,RKT)[12]通过自注意力感知试题的上下文信息来获得试题之间的相关关系;注意力知识追踪(Attentive Knowledge Tracing,AKT)[13]则利用多头注意力,用不同的时间尺度对应不同的衰减率来感知过去试题和当前试题的交互关系. ...
... 概率图模型用图形和概率分布表示变量之间的关系[15],贝叶斯知识追踪(Bayesian Knowledge Tracing,BKT)是一种具有代表性的基于概率图的知识追踪模型[2].BKT将学习者的认知状态建模为一个动态变化的过程,基于先验概率(通常根据领域专家的经验或大量数据得出)和学习者的历史答题记录,通过隐马尔可夫模型(Hidden Markov Model,HMM)来推测学习者的知识水平和理解程度.在BKT模型的基础上,许多研究者提出了相应的变体模型.例如,Käser et al[16]对知识点之间的关系和多个包含多个知识点的试题进行建模,Khajah et al[17]在BKT模型中引入猜测概率和失误概率,Yudelson et al[18]将学习者特定参数和技能特定参数作为BKT模型的参数. ...
Dynamic Bayesian networks for student modeling
1
2017
... 概率图模型用图形和概率分布表示变量之间的关系[15],贝叶斯知识追踪(Bayesian Knowledge Tracing,BKT)是一种具有代表性的基于概率图的知识追踪模型[2].BKT将学习者的认知状态建模为一个动态变化的过程,基于先验概率(通常根据领域专家的经验或大量数据得出)和学习者的历史答题记录,通过隐马尔可夫模型(Hidden Markov Model,HMM)来推测学习者的知识水平和理解程度.在BKT模型的基础上,许多研究者提出了相应的变体模型.例如,Käser et al[16]对知识点之间的关系和多个包含多个知识点的试题进行建模,Khajah et al[17]在BKT模型中引入猜测概率和失误概率,Yudelson et al[18]将学习者特定参数和技能特定参数作为BKT模型的参数. ...
Integrating latent?factor and knowledge?tracing models to predict individual differences in learning
1
2014
... 概率图模型用图形和概率分布表示变量之间的关系[15],贝叶斯知识追踪(Bayesian Knowledge Tracing,BKT)是一种具有代表性的基于概率图的知识追踪模型[2].BKT将学习者的认知状态建模为一个动态变化的过程,基于先验概率(通常根据领域专家的经验或大量数据得出)和学习者的历史答题记录,通过隐马尔可夫模型(Hidden Markov Model,HMM)来推测学习者的知识水平和理解程度.在BKT模型的基础上,许多研究者提出了相应的变体模型.例如,Käser et al[16]对知识点之间的关系和多个包含多个知识点的试题进行建模,Khajah et al[17]在BKT模型中引入猜测概率和失误概率,Yudelson et al[18]将学习者特定参数和技能特定参数作为BKT模型的参数. ...
Individualized Bayesian knowledge tracing models
1
2013
... 概率图模型用图形和概率分布表示变量之间的关系[15],贝叶斯知识追踪(Bayesian Knowledge Tracing,BKT)是一种具有代表性的基于概率图的知识追踪模型[2].BKT将学习者的认知状态建模为一个动态变化的过程,基于先验概率(通常根据领域专家的经验或大量数据得出)和学习者的历史答题记录,通过隐马尔可夫模型(Hidden Markov Model,HMM)来推测学习者的知识水平和理解程度.在BKT模型的基础上,许多研究者提出了相应的变体模型.例如,Käser et al[16]对知识点之间的关系和多个包含多个知识点的试题进行建模,Khajah et al[17]在BKT模型中引入猜测概率和失误概率,Yudelson et al[18]将学习者特定参数和技能特定参数作为BKT模型的参数. ...
Performance factors analysis:A new alternative to knowledge tracing




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}