Clustering ensemble has become a popular research topic in data mining and machine learning. Despite significant progress in recent years,there are still two challenging problems in current researches on clustering ensemble. Firstly,most ensemble algorithms tend to study similarity at the object level,lacking the ability to mine cluster⁃level information. Secondly,many current ensemble algorithms focus only on the direct co⁃occurrence of objects within clusters,ignoring the relationship between clusters. To address these two problems,this paper proposes a link based meta⁃clustering algorithm (L⁃MCLA) which constructs a cluster similarity matrix based on Jaccard similarity,then refines this similarity matrix using connecting triples,and finally obtains the final result through graph partitioning and membership assignment. Theoretical analysis and experimental testing show that the proposed algorithm not only produces good clustering results,but also is less affected by the scale of clustering ensemble.
Du Shuying, Ding Shifei, Shao Changlong. Link based meta⁃clustering algorithm. Journal of nanjing University[J], 2023, 59(6): 961-969 doi:10.13232/j.cnki.jnju.2023.06.006
基于共关联矩阵的算法根据数据点与数据点之间在相同簇中共现的频率得到一个共关联矩阵,以该矩阵作为相似度矩阵,采用层次聚类的算法得到最终结果.Fred and Jain[11]首次提出共关联矩阵的概念,并据此设计了证据集聚聚类(Evidence Accumulate Clustering,EAC)算法.Wang et al[12]对EAC算法进行扩展,考虑到簇的大小,提出概率集聚算法.Rathore et al[13]利用随机投影对高维数据进行降维,并利用共关联矩阵设计了一种针对于模糊聚类的聚类集成算法.Zhong et al[14]认为删除共关联矩阵值较小的项可以提高聚类效果,并猜想哪些项中可能包含大量噪声.
基于图分区的算法将聚类集成的信息构成一个图结构,再利用图分割算法将图分割成若干块,进而得到最终的聚类结果.Strehl and Ghosh[15]将聚类成员里的每个簇都作为一个超边缘,构造了三种超图结构,再用METIS算法对其进行图分割,得到最终的聚类结果.Fern and Brodley[16]将聚类成员构造成二部图,其中对象和簇都表示为图节点,只有当其中一个节点是对象,另一个节点是包含它的簇时,二部图的值才不为0,并用Ncut算法对其进行分割.Huang et al[17]提出一种针对大规模数据的基于采样的谱聚类算法,并设计了一个二部图对其进行聚类集成.
基于中值聚类的算法将聚类集成问题建模成一个最优化问题,其优化目标是寻找一个与所有聚类成员最相似的聚类结果,这个聚类结果被视为所有聚类成员的中值点.这个问题已经被证明是一个NP难问题,所以在全局聚类空间里寻找最优解在较大的数据集上是不可行的.为此,Cristofor and Simovici[18]利用遗传算法求聚类集成的近似解,其中聚类被视为染色体.Topchy et al[19]将中值聚类问题转化为极大似然问题,并用EM (Expectation Maximization)算法求解.Huang et al[20]将聚类集成问题转化为二元线性规划问题,通过因子图模型进行求解.
Fig.1
The relationship between points:(a)within the same cluster,(b)belonging to two clusters with common parts,(c)belonging to two unrelated clusters,while both clusters are related to the third cluster
2003年,Strehl and Ghosh[15]提出被称为“元聚类”(Meta⁃Clustering Algorithm,MCLA)的聚类集成算法,其中心思想是对簇进行分类,而不是对对象进行分类,最后,将对象分配到最有可能归属的簇群中.元聚类算法利用Jaccard系数计算簇间的相似度,假设有簇Ci 和Cj,它们之间的Jaccard系数的计算如下:
2011年,Iam⁃On et al[22]提出加权连接三元组(Weighted Connected⁃Triple,WCT)的概念来挖掘簇与簇之间隐藏的间接关系,其基本思想是:如果两个节点都与第三个节点有连接,则认为这两个节点之间也有一定的关系,第三个节点被称为这个三元组的中心.通过这种算法可以找到簇与簇之间的间接连接,进一步丰富原来的相似度矩阵包含的信息,进而得到更好的聚类结果.
Combining multiple clusterings using evidence accumulation
3
2005
... 基于共关联矩阵的算法根据数据点与数据点之间在相同簇中共现的频率得到一个共关联矩阵,以该矩阵作为相似度矩阵,采用层次聚类的算法得到最终结果.Fred and Jain[11]首次提出共关联矩阵的概念,并据此设计了证据集聚聚类(Evidence Accumulate Clustering,EAC)算法.Wang et al[12]对EAC算法进行扩展,考虑到簇的大小,提出概率集聚算法.Rathore et al[13]利用随机投影对高维数据进行降维,并利用共关联矩阵设计了一种针对于模糊聚类的聚类集成算法.Zhong et al[14]认为删除共关联矩阵值较小的项可以提高聚类效果,并猜想哪些项中可能包含大量噪声. ...
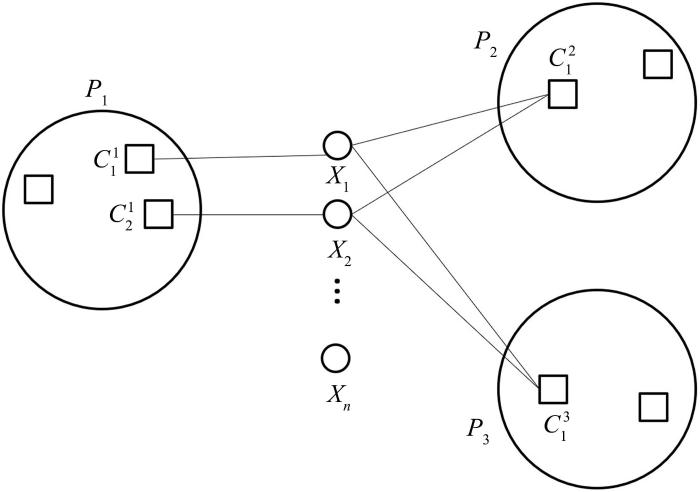
... 在聚类集成的过程中,对象间的直接共现是最容易捕捉的信息,Fred and Jain[11]提出共关联矩阵的概念,用两个对象在同一簇中共现的次数作为它们的相似度.但是现实情况远比此更复杂,图1列出了几种可能出现的情况. ...
Clustering aggregation by probability accumulation
1
2009
... 基于共关联矩阵的算法根据数据点与数据点之间在相同簇中共现的频率得到一个共关联矩阵,以该矩阵作为相似度矩阵,采用层次聚类的算法得到最终结果.Fred and Jain[11]首次提出共关联矩阵的概念,并据此设计了证据集聚聚类(Evidence Accumulate Clustering,EAC)算法.Wang et al[12]对EAC算法进行扩展,考虑到簇的大小,提出概率集聚算法.Rathore et al[13]利用随机投影对高维数据进行降维,并利用共关联矩阵设计了一种针对于模糊聚类的聚类集成算法.Zhong et al[14]认为删除共关联矩阵值较小的项可以提高聚类效果,并猜想哪些项中可能包含大量噪声. ...
Ensemble fuzzy clustering using cumulative aggregation on random projections
1
2018
... 基于共关联矩阵的算法根据数据点与数据点之间在相同簇中共现的频率得到一个共关联矩阵,以该矩阵作为相似度矩阵,采用层次聚类的算法得到最终结果.Fred and Jain[11]首次提出共关联矩阵的概念,并据此设计了证据集聚聚类(Evidence Accumulate Clustering,EAC)算法.Wang et al[12]对EAC算法进行扩展,考虑到簇的大小,提出概率集聚算法.Rathore et al[13]利用随机投影对高维数据进行降维,并利用共关联矩阵设计了一种针对于模糊聚类的聚类集成算法.Zhong et al[14]认为删除共关联矩阵值较小的项可以提高聚类效果,并猜想哪些项中可能包含大量噪声. ...
Ensemble clustering based on evidence extracted from the co?association matrix
1
2019
... 基于共关联矩阵的算法根据数据点与数据点之间在相同簇中共现的频率得到一个共关联矩阵,以该矩阵作为相似度矩阵,采用层次聚类的算法得到最终结果.Fred and Jain[11]首次提出共关联矩阵的概念,并据此设计了证据集聚聚类(Evidence Accumulate Clustering,EAC)算法.Wang et al[12]对EAC算法进行扩展,考虑到簇的大小,提出概率集聚算法.Rathore et al[13]利用随机投影对高维数据进行降维,并利用共关联矩阵设计了一种针对于模糊聚类的聚类集成算法.Zhong et al[14]认为删除共关联矩阵值较小的项可以提高聚类效果,并猜想哪些项中可能包含大量噪声. ...
Cluster ensembles:A knowledge reuse framework for combining multiple partitions
6
2003
... 基于图分区的算法将聚类集成的信息构成一个图结构,再利用图分割算法将图分割成若干块,进而得到最终的聚类结果.Strehl and Ghosh[15]将聚类成员里的每个簇都作为一个超边缘,构造了三种超图结构,再用METIS算法对其进行图分割,得到最终的聚类结果.Fern and Brodley[16]将聚类成员构造成二部图,其中对象和簇都表示为图节点,只有当其中一个节点是对象,另一个节点是包含它的簇时,二部图的值才不为0,并用Ncut算法对其进行分割.Huang et al[17]提出一种针对大规模数据的基于采样的谱聚类算法,并设计了一个二部图对其进行聚类集成. ...
... 2003年,Strehl and Ghosh[15]提出被称为“元聚类”(Meta⁃Clustering Algorithm,MCLA)的聚类集成算法,其中心思想是对簇进行分类,而不是对对象进行分类,最后,将对象分配到最有可能归属的簇群中.元聚类算法利用Jaccard系数计算簇间的相似度,假设有簇Ci 和Cj,它们之间的Jaccard系数的计算如下: ...
... Strehl and Ghosh[15]用一系列实验证明了元聚类算法的优越性和鲁棒性,使其成为一个经典的聚类集成算法. ...
Solving cluster ensemble problems by bipartite graph partitioning
2
2004
... 基于图分区的算法将聚类集成的信息构成一个图结构,再利用图分割算法将图分割成若干块,进而得到最终的聚类结果.Strehl and Ghosh[15]将聚类成员里的每个簇都作为一个超边缘,构造了三种超图结构,再用METIS算法对其进行图分割,得到最终的聚类结果.Fern and Brodley[16]将聚类成员构造成二部图,其中对象和簇都表示为图节点,只有当其中一个节点是对象,另一个节点是包含它的簇时,二部图的值才不为0,并用Ncut算法对其进行分割.Huang et al[17]提出一种针对大规模数据的基于采样的谱聚类算法,并设计了一个二部图对其进行聚类集成. ...
Ultra?scalable spectral clustering and ensemble clustering
1
2020
... 基于图分区的算法将聚类集成的信息构成一个图结构,再利用图分割算法将图分割成若干块,进而得到最终的聚类结果.Strehl and Ghosh[15]将聚类成员里的每个簇都作为一个超边缘,构造了三种超图结构,再用METIS算法对其进行图分割,得到最终的聚类结果.Fern and Brodley[16]将聚类成员构造成二部图,其中对象和簇都表示为图节点,只有当其中一个节点是对象,另一个节点是包含它的簇时,二部图的值才不为0,并用Ncut算法对其进行分割.Huang et al[17]提出一种针对大规模数据的基于采样的谱聚类算法,并设计了一个二部图对其进行聚类集成. ...
Finding median partitions using information?theoretical?based genetic algorithms
1
2002
... 基于中值聚类的算法将聚类集成问题建模成一个最优化问题,其优化目标是寻找一个与所有聚类成员最相似的聚类结果,这个聚类结果被视为所有聚类成员的中值点.这个问题已经被证明是一个NP难问题,所以在全局聚类空间里寻找最优解在较大的数据集上是不可行的.为此,Cristofor and Simovici[18]利用遗传算法求聚类集成的近似解,其中聚类被视为染色体.Topchy et al[19]将中值聚类问题转化为极大似然问题,并用EM (Expectation Maximization)算法求解.Huang et al[20]将聚类集成问题转化为二元线性规划问题,通过因子图模型进行求解. ...
Clustering ensembles:Models of consensus and weak partitions
1
2005
... 基于中值聚类的算法将聚类集成问题建模成一个最优化问题,其优化目标是寻找一个与所有聚类成员最相似的聚类结果,这个聚类结果被视为所有聚类成员的中值点.这个问题已经被证明是一个NP难问题,所以在全局聚类空间里寻找最优解在较大的数据集上是不可行的.为此,Cristofor and Simovici[18]利用遗传算法求聚类集成的近似解,其中聚类被视为染色体.Topchy et al[19]将中值聚类问题转化为极大似然问题,并用EM (Expectation Maximization)算法求解.Huang et al[20]将聚类集成问题转化为二元线性规划问题,通过因子图模型进行求解. ...
Ensemble clustering using factor graph
1
2016
... 基于中值聚类的算法将聚类集成问题建模成一个最优化问题,其优化目标是寻找一个与所有聚类成员最相似的聚类结果,这个聚类结果被视为所有聚类成员的中值点.这个问题已经被证明是一个NP难问题,所以在全局聚类空间里寻找最优解在较大的数据集上是不可行的.为此,Cristofor and Simovici[18]利用遗传算法求聚类集成的近似解,其中聚类被视为染色体.Topchy et al[19]将中值聚类问题转化为极大似然问题,并用EM (Expectation Maximization)算法求解.Huang et al[20]将聚类集成问题转化为二元线性规划问题,通过因子图模型进行求解. ...
A fast and high quality multilevel scheme for partitioning irregular graphs







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}