A comparative study on network alignment techniques
1
2020
... 图(网络)是一种常用的数据结构,可用来建模不同实体之间的关系,图数据分析中,研究人员运用各种技术(如网络表示学习和深度学习)和手段(如社区发现、节点分类和链接预测)来挖掘图中隐藏的信息.其中,网络对齐(Network Alignment)是一项重要的数据挖掘技术,能发现不同网络中实体之间的等价关系和相似性[1],在社交网络分析、生物信息学和知识图谱构建等领域得到了广泛应用.例如,在社交网络分析中,可基于用户对齐结果进行跨平台的信息传递[2];在生物信息学中,对齐不同物种间的蛋白质分子网络可以实现蛋白质功能注释[3];在知识图谱的构建过程中,利用实体对齐可以完成知识补全[4]. ...
Cross?network social user embedding with hybrid differential privacy guarantees
1
2022
... 图(网络)是一种常用的数据结构,可用来建模不同实体之间的关系,图数据分析中,研究人员运用各种技术(如网络表示学习和深度学习)和手段(如社区发现、节点分类和链接预测)来挖掘图中隐藏的信息.其中,网络对齐(Network Alignment)是一项重要的数据挖掘技术,能发现不同网络中实体之间的等价关系和相似性[1],在社交网络分析、生物信息学和知识图谱构建等领域得到了广泛应用.例如,在社交网络分析中,可基于用户对齐结果进行跨平台的信息传递[2];在生物信息学中,对齐不同物种间的蛋白质分子网络可以实现蛋白质功能注释[3];在知识图谱的构建过程中,利用实体对齐可以完成知识补全[4]. ...
Data?driven biological network alignment that uses topological,sequence,and functional information
1
2021
... 图(网络)是一种常用的数据结构,可用来建模不同实体之间的关系,图数据分析中,研究人员运用各种技术(如网络表示学习和深度学习)和手段(如社区发现、节点分类和链接预测)来挖掘图中隐藏的信息.其中,网络对齐(Network Alignment)是一项重要的数据挖掘技术,能发现不同网络中实体之间的等价关系和相似性[1],在社交网络分析、生物信息学和知识图谱构建等领域得到了广泛应用.例如,在社交网络分析中,可基于用户对齐结果进行跨平台的信息传递[2];在生物信息学中,对齐不同物种间的蛋白质分子网络可以实现蛋白质功能注释[3];在知识图谱的构建过程中,利用实体对齐可以完成知识补全[4]. ...
Joint completion and alignment of multilingual knowledge graphs
1
... 图(网络)是一种常用的数据结构,可用来建模不同实体之间的关系,图数据分析中,研究人员运用各种技术(如网络表示学习和深度学习)和手段(如社区发现、节点分类和链接预测)来挖掘图中隐藏的信息.其中,网络对齐(Network Alignment)是一项重要的数据挖掘技术,能发现不同网络中实体之间的等价关系和相似性[1],在社交网络分析、生物信息学和知识图谱构建等领域得到了广泛应用.例如,在社交网络分析中,可基于用户对齐结果进行跨平台的信息传递[2];在生物信息学中,对齐不同物种间的蛋白质分子网络可以实现蛋白质功能注释[3];在知识图谱的构建过程中,利用实体对齐可以完成知识补全[4]. ...
Attributed network alignment:Problem definitions and fast solutions
1
2019
... 网络对齐任务中,可利用网络的拓扑结构或节点属性信息来识别不同网络中的相似节点[5],但由于网络结构的复杂性,传统的网络对齐方法无法满足当下网络对齐任务的需求.近年来,研究人员提出许多基于嵌入的网络对齐方法,包括基于网络嵌入的方法[6-8]和基于图神经网络的方法[9-14],已有研究表明,基于嵌入方法的性能普遍优于传统方法.网络嵌入(Network Embedding)是一种降维技术,可以将网络节点特征映射到低维向量空间,能更好地表示节点之间的关系[15].图神经网络(Graph Neural Networks,GNN)是一种深度学习模型,能捕捉节点和边之间的复杂交互关系以及全局拓扑信息.这些技术被广泛应用于各种任务,如节点分类、链接预测和图分类[16]. ...
Predict anchor links across social networks via an embedding approach
2
2016
... 网络对齐任务中,可利用网络的拓扑结构或节点属性信息来识别不同网络中的相似节点[5],但由于网络结构的复杂性,传统的网络对齐方法无法满足当下网络对齐任务的需求.近年来,研究人员提出许多基于嵌入的网络对齐方法,包括基于网络嵌入的方法[6-8]和基于图神经网络的方法[9-14],已有研究表明,基于嵌入方法的性能普遍优于传统方法.网络嵌入(Network Embedding)是一种降维技术,可以将网络节点特征映射到低维向量空间,能更好地表示节点之间的关系[15].图神经网络(Graph Neural Networks,GNN)是一种深度学习模型,能捕捉节点和边之间的复杂交互关系以及全局拓扑信息.这些技术被广泛应用于各种任务,如节点分类、链接预测和图分类[16]. ...
... 基于网络嵌入的方法使用DeepWalk[17]或LINE[18]等网络嵌入技术来学习不同网络中的节点表示.Man et al[6]提出PALE (Predicting Anchor Links via Embedding)算法,利用观测到的锚链为监督信息,结合LINE来捕捉不同网络之间的结构规律和相似性,并使用学习的嵌入向量来预测锚链.其中,锚链被视为网络中的关键节点,它们的位置和连接关系被用来指导嵌入向量的学习,通过这种方式PALE算法能更好地捕捉网络的结构和特征,提高预测的准确性和可靠性.Heimann et al[7]提出REGAL(Representation Based Graph Alignment)算法,通过扩展低秩矩阵近似的Nyström方法[26]和设置标准节点来加速表示学习,并通过Kd⁃tree方法[27]实现贪婪对齐.Nguyen et al[8]提出NAWAL (Network Alignment with Self⁃supervised Anchor Links)算法.首先,分别学习源网络和目标网络的节点向量表示;然后,使用生成对抗网络(Generative Adversarial Networks,GAN)[28]在无监督样本的情况下学习一个映射函数W,将两个网络的嵌入空间协调到一个公共空间中,在这个过程中,通过生成的伪锚链,利用Procrustes的封闭解[29]进一步优化嵌入;最后,采用贪婪启发式的方法进行对齐.Zhu et al[30]提出CAPER(Coarsen,Align,Project,Refine)算法,首先将输入网络粗化为不同粒度的网络,接着在最粗的网络上使用现有对齐算法(如REGAL)获得最粗的对齐矩阵,最后,将对齐结果进行逐层映射,最终得到最细层次的对齐矩阵.此外,CAPER在映射过程中,通过在不同粒度的对齐矩阵上使用CONE_Align[31]来改善对齐结果.CONE_Align提供了一种基于近邻一致性(Neighborhood Consistency)的优化方法来提高现有网络对齐算法的鲁棒性.具体地,如果已对齐的节点对具有相似的特征,则它们的邻居节点中很可能也存在相互对齐的节点. ...
REGAL:Representation learning?based graph alignment
2
2018
... 基于网络嵌入的方法使用DeepWalk[17]或LINE[18]等网络嵌入技术来学习不同网络中的节点表示.Man et al[6]提出PALE (Predicting Anchor Links via Embedding)算法,利用观测到的锚链为监督信息,结合LINE来捕捉不同网络之间的结构规律和相似性,并使用学习的嵌入向量来预测锚链.其中,锚链被视为网络中的关键节点,它们的位置和连接关系被用来指导嵌入向量的学习,通过这种方式PALE算法能更好地捕捉网络的结构和特征,提高预测的准确性和可靠性.Heimann et al[7]提出REGAL(Representation Based Graph Alignment)算法,通过扩展低秩矩阵近似的Nyström方法[26]和设置标准节点来加速表示学习,并通过Kd⁃tree方法[27]实现贪婪对齐.Nguyen et al[8]提出NAWAL (Network Alignment with Self⁃supervised Anchor Links)算法.首先,分别学习源网络和目标网络的节点向量表示;然后,使用生成对抗网络(Generative Adversarial Networks,GAN)[28]在无监督样本的情况下学习一个映射函数W,将两个网络的嵌入空间协调到一个公共空间中,在这个过程中,通过生成的伪锚链,利用Procrustes的封闭解[29]进一步优化嵌入;最后,采用贪婪启发式的方法进行对齐.Zhu et al[30]提出CAPER(Coarsen,Align,Project,Refine)算法,首先将输入网络粗化为不同粒度的网络,接着在最粗的网络上使用现有对齐算法(如REGAL)获得最粗的对齐矩阵,最后,将对齐结果进行逐层映射,最终得到最细层次的对齐矩阵.此外,CAPER在映射过程中,通过在不同粒度的对齐矩阵上使用CONE_Align[31]来改善对齐结果.CONE_Align提供了一种基于近邻一致性(Neighborhood Consistency)的优化方法来提高现有网络对齐算法的鲁棒性.具体地,如果已对齐的节点对具有相似的特征,则它们的邻居节点中很可能也存在相互对齐的节点. ...
... REGAL[7]首先将源网络和目标网络组合起来,然后利用隐式矩阵分解方法(xNetMF)进行联合嵌入,得到节点表示向量,最后使用贪婪匹配的方法对齐不同网络间的节点. ...
Structural representation learning for network alignment with self?supervised anchor links
3
2021
... 网络对齐任务中,可利用网络的拓扑结构或节点属性信息来识别不同网络中的相似节点[5],但由于网络结构的复杂性,传统的网络对齐方法无法满足当下网络对齐任务的需求.近年来,研究人员提出许多基于嵌入的网络对齐方法,包括基于网络嵌入的方法[6-8]和基于图神经网络的方法[9-14],已有研究表明,基于嵌入方法的性能普遍优于传统方法.网络嵌入(Network Embedding)是一种降维技术,可以将网络节点特征映射到低维向量空间,能更好地表示节点之间的关系[15].图神经网络(Graph Neural Networks,GNN)是一种深度学习模型,能捕捉节点和边之间的复杂交互关系以及全局拓扑信息.这些技术被广泛应用于各种任务,如节点分类、链接预测和图分类[16]. ...
... 基于网络嵌入的方法使用DeepWalk[17]或LINE[18]等网络嵌入技术来学习不同网络中的节点表示.Man et al[6]提出PALE (Predicting Anchor Links via Embedding)算法,利用观测到的锚链为监督信息,结合LINE来捕捉不同网络之间的结构规律和相似性,并使用学习的嵌入向量来预测锚链.其中,锚链被视为网络中的关键节点,它们的位置和连接关系被用来指导嵌入向量的学习,通过这种方式PALE算法能更好地捕捉网络的结构和特征,提高预测的准确性和可靠性.Heimann et al[7]提出REGAL(Representation Based Graph Alignment)算法,通过扩展低秩矩阵近似的Nyström方法[26]和设置标准节点来加速表示学习,并通过Kd⁃tree方法[27]实现贪婪对齐.Nguyen et al[8]提出NAWAL (Network Alignment with Self⁃supervised Anchor Links)算法.首先,分别学习源网络和目标网络的节点向量表示;然后,使用生成对抗网络(Generative Adversarial Networks,GAN)[28]在无监督样本的情况下学习一个映射函数W,将两个网络的嵌入空间协调到一个公共空间中,在这个过程中,通过生成的伪锚链,利用Procrustes的封闭解[29]进一步优化嵌入;最后,采用贪婪启发式的方法进行对齐.Zhu et al[30]提出CAPER(Coarsen,Align,Project,Refine)算法,首先将输入网络粗化为不同粒度的网络,接着在最粗的网络上使用现有对齐算法(如REGAL)获得最粗的对齐矩阵,最后,将对齐结果进行逐层映射,最终得到最细层次的对齐矩阵.此外,CAPER在映射过程中,通过在不同粒度的对齐矩阵上使用CONE_Align[31]来改善对齐结果.CONE_Align提供了一种基于近邻一致性(Neighborhood Consistency)的优化方法来提高现有网络对齐算法的鲁棒性.具体地,如果已对齐的节点对具有相似的特征,则它们的邻居节点中很可能也存在相互对齐的节点. ...
... NAWAL[8]首先利用Node2Vec[39]算法学习节点的特征表示,然后使用自监督锚链接来实时更新节点的嵌入向量,并通过最大化锚链接之间的相似性来实现对齐. ...
Adaptive network alignment with unsupervised and multi?order convolutional networks
6
2020
... 网络对齐任务中,可利用网络的拓扑结构或节点属性信息来识别不同网络中的相似节点[5],但由于网络结构的复杂性,传统的网络对齐方法无法满足当下网络对齐任务的需求.近年来,研究人员提出许多基于嵌入的网络对齐方法,包括基于网络嵌入的方法[6-8]和基于图神经网络的方法[9-14],已有研究表明,基于嵌入方法的性能普遍优于传统方法.网络嵌入(Network Embedding)是一种降维技术,可以将网络节点特征映射到低维向量空间,能更好地表示节点之间的关系[15].图神经网络(Graph Neural Networks,GNN)是一种深度学习模型,能捕捉节点和边之间的复杂交互关系以及全局拓扑信息.这些技术被广泛应用于各种任务,如节点分类、链接预测和图分类[16]. ...
... 基于图神经网络的方法是利用图神经网络模型,例如图卷积网络(Graph Convolutional Network,GCN)[32]和图同构网络(Graph Isomorphic Network,GIN)[33]来学习不同网络中节点的表示,并通过学习到的特征向量推断不同网络中节点之间的相似性.Trung et al[9]提出GAlign算法,利用GCN学习节点的多阶嵌入.为了提高模型性能,GAlign设计了一种数据增强方法,主要通过对网络节点的边进行随机添加或删除操作来增加模型的鲁棒性和泛化能力,为网络对齐提供高质量的节点嵌入表示.Qin et al[10]提出G⁃CREWE (Graph CompRE⁃ssion with Embedding)算法,首先,利用GCN提取节点特征,获得原始网络的对齐结果;然后使用提出的MERGE (Minimum DEgRee NeiGhbors ComprEssion)方法对网络进行压缩,并在粗图上进行对齐;最后,将来自两种粒度网络的对齐结果合并,以实现高质量的对齐性能.Gao et al[11]提出WAlign算法,利用LGCN (Lightweight GCN)模型来捕获网络的局部和全局结构信息,获得高质量的节点特征向量,然后通过Wasserstein距离[34]鉴别器生成伪锚节点对,并在统一的优化框架下,利用对抗训练的方法迭代更新嵌入和鉴别器参数来提高对齐准确率.Park et al[12]提出Grade⁃Align算法,首先使用GIN生成嵌入向量并构建嵌入相似度矩阵,然后通过迭代的方式,融合嵌入相似度矩阵和不断更新的Tversky相似度矩阵来生成伪锚节点集合,逐步提高算法的对齐准确性.Tversky相似度[35]是一种基于集合的相似度计算方法,用于评估两个集合之间的相似程度.构造Tversky相似度矩阵的方法如下:首先,构建两个新图;接着,依据伪锚节点集合,将来自另一方的节点和相应的边加入到各自的图中;最后,计算不同图中两个节点邻域集合之间的Tversky系数,构造Tversky相似度矩阵.Lu et al[13]提出Bi_GANA (Bi⁃layer Graph Attention Neural Network for Network Alignment)算法,利用双层图注意力神经网络对多维用户特征和社交网络的局部和全局拓扑信息进行建模,通过不规则图和多维用户特征信息实现社交网络用户对齐问题.Huynh et al[14]提出NAME (Network Alignment with Multiple Embedding)算法,集成多种嵌入技术以创建更丰富、更准确的节点表示,并通过端到端的学习来实现高效对齐. ...
... 为了确保源网络和目标网络中的节点特征表示在相同的向量空间中,采用了权重共享机制,即使用相同的参数来更新每个节点的特征向量.此外,还采用多阶嵌入的方法[9],可以更好地利用网络的局部和全局拓扑信息来增强模型的语义表示能力. ...
... GAlign[9]使用GCN学习两个网络中每个节点的多阶嵌入,然后根据不同卷积层输出的节点表示向量的相似性计算多个对齐矩阵,最终通过融合多个对齐矩阵实现节点对齐. ...
... 为了评估算法的性能,使用两个度量指标来衡量网络对齐结果的优劣,分别是MAP (Mean Average Precision)[9]和[9,11].具体地: ...
... [9,11].具体地: ...
G?CREWE:Graph compression with embedding for network alignment
1
2020
... 基于图神经网络的方法是利用图神经网络模型,例如图卷积网络(Graph Convolutional Network,GCN)[32]和图同构网络(Graph Isomorphic Network,GIN)[33]来学习不同网络中节点的表示,并通过学习到的特征向量推断不同网络中节点之间的相似性.Trung et al[9]提出GAlign算法,利用GCN学习节点的多阶嵌入.为了提高模型性能,GAlign设计了一种数据增强方法,主要通过对网络节点的边进行随机添加或删除操作来增加模型的鲁棒性和泛化能力,为网络对齐提供高质量的节点嵌入表示.Qin et al[10]提出G⁃CREWE (Graph CompRE⁃ssion with Embedding)算法,首先,利用GCN提取节点特征,获得原始网络的对齐结果;然后使用提出的MERGE (Minimum DEgRee NeiGhbors ComprEssion)方法对网络进行压缩,并在粗图上进行对齐;最后,将来自两种粒度网络的对齐结果合并,以实现高质量的对齐性能.Gao et al[11]提出WAlign算法,利用LGCN (Lightweight GCN)模型来捕获网络的局部和全局结构信息,获得高质量的节点特征向量,然后通过Wasserstein距离[34]鉴别器生成伪锚节点对,并在统一的优化框架下,利用对抗训练的方法迭代更新嵌入和鉴别器参数来提高对齐准确率.Park et al[12]提出Grade⁃Align算法,首先使用GIN生成嵌入向量并构建嵌入相似度矩阵,然后通过迭代的方式,融合嵌入相似度矩阵和不断更新的Tversky相似度矩阵来生成伪锚节点集合,逐步提高算法的对齐准确性.Tversky相似度[35]是一种基于集合的相似度计算方法,用于评估两个集合之间的相似程度.构造Tversky相似度矩阵的方法如下:首先,构建两个新图;接着,依据伪锚节点集合,将来自另一方的节点和相应的边加入到各自的图中;最后,计算不同图中两个节点邻域集合之间的Tversky系数,构造Tversky相似度矩阵.Lu et al[13]提出Bi_GANA (Bi⁃layer Graph Attention Neural Network for Network Alignment)算法,利用双层图注意力神经网络对多维用户特征和社交网络的局部和全局拓扑信息进行建模,通过不规则图和多维用户特征信息实现社交网络用户对齐问题.Huynh et al[14]提出NAME (Network Alignment with Multiple Embedding)算法,集成多种嵌入技术以创建更丰富、更准确的节点表示,并通过端到端的学习来实现高效对齐. ...
Unsupervised graph alignment with wasserstein distance discriminator
3
2021
... 基于图神经网络的方法是利用图神经网络模型,例如图卷积网络(Graph Convolutional Network,GCN)[32]和图同构网络(Graph Isomorphic Network,GIN)[33]来学习不同网络中节点的表示,并通过学习到的特征向量推断不同网络中节点之间的相似性.Trung et al[9]提出GAlign算法,利用GCN学习节点的多阶嵌入.为了提高模型性能,GAlign设计了一种数据增强方法,主要通过对网络节点的边进行随机添加或删除操作来增加模型的鲁棒性和泛化能力,为网络对齐提供高质量的节点嵌入表示.Qin et al[10]提出G⁃CREWE (Graph CompRE⁃ssion with Embedding)算法,首先,利用GCN提取节点特征,获得原始网络的对齐结果;然后使用提出的MERGE (Minimum DEgRee NeiGhbors ComprEssion)方法对网络进行压缩,并在粗图上进行对齐;最后,将来自两种粒度网络的对齐结果合并,以实现高质量的对齐性能.Gao et al[11]提出WAlign算法,利用LGCN (Lightweight GCN)模型来捕获网络的局部和全局结构信息,获得高质量的节点特征向量,然后通过Wasserstein距离[34]鉴别器生成伪锚节点对,并在统一的优化框架下,利用对抗训练的方法迭代更新嵌入和鉴别器参数来提高对齐准确率.Park et al[12]提出Grade⁃Align算法,首先使用GIN生成嵌入向量并构建嵌入相似度矩阵,然后通过迭代的方式,融合嵌入相似度矩阵和不断更新的Tversky相似度矩阵来生成伪锚节点集合,逐步提高算法的对齐准确性.Tversky相似度[35]是一种基于集合的相似度计算方法,用于评估两个集合之间的相似程度.构造Tversky相似度矩阵的方法如下:首先,构建两个新图;接着,依据伪锚节点集合,将来自另一方的节点和相应的边加入到各自的图中;最后,计算不同图中两个节点邻域集合之间的Tversky系数,构造Tversky相似度矩阵.Lu et al[13]提出Bi_GANA (Bi⁃layer Graph Attention Neural Network for Network Alignment)算法,利用双层图注意力神经网络对多维用户特征和社交网络的局部和全局拓扑信息进行建模,通过不规则图和多维用户特征信息实现社交网络用户对齐问题.Huynh et al[14]提出NAME (Network Alignment with Multiple Embedding)算法,集成多种嵌入技术以创建更丰富、更准确的节点表示,并通过端到端的学习来实现高效对齐. ...
... WAlign[11]首先通过LGCN模型来学习节点的嵌入向量,然后利用一种新颖的Wasserstein距离鉴别器来识别用于更新节点嵌入的候选节点对,最后通过自监督的对抗学习得到适合对齐任务的嵌入. ...
... 为了评估算法的性能,使用两个度量指标来衡量网络对齐结果的优劣,分别是MAP (Mean Average Precision)[9]和[9,11].具体地: ...
2
2022
... 基于图神经网络的方法是利用图神经网络模型,例如图卷积网络(Graph Convolutional Network,GCN)[32]和图同构网络(Graph Isomorphic Network,GIN)[33]来学习不同网络中节点的表示,并通过学习到的特征向量推断不同网络中节点之间的相似性.Trung et al[9]提出GAlign算法,利用GCN学习节点的多阶嵌入.为了提高模型性能,GAlign设计了一种数据增强方法,主要通过对网络节点的边进行随机添加或删除操作来增加模型的鲁棒性和泛化能力,为网络对齐提供高质量的节点嵌入表示.Qin et al[10]提出G⁃CREWE (Graph CompRE⁃ssion with Embedding)算法,首先,利用GCN提取节点特征,获得原始网络的对齐结果;然后使用提出的MERGE (Minimum DEgRee NeiGhbors ComprEssion)方法对网络进行压缩,并在粗图上进行对齐;最后,将来自两种粒度网络的对齐结果合并,以实现高质量的对齐性能.Gao et al[11]提出WAlign算法,利用LGCN (Lightweight GCN)模型来捕获网络的局部和全局结构信息,获得高质量的节点特征向量,然后通过Wasserstein距离[34]鉴别器生成伪锚节点对,并在统一的优化框架下,利用对抗训练的方法迭代更新嵌入和鉴别器参数来提高对齐准确率.Park et al[12]提出Grade⁃Align算法,首先使用GIN生成嵌入向量并构建嵌入相似度矩阵,然后通过迭代的方式,融合嵌入相似度矩阵和不断更新的Tversky相似度矩阵来生成伪锚节点集合,逐步提高算法的对齐准确性.Tversky相似度[35]是一种基于集合的相似度计算方法,用于评估两个集合之间的相似程度.构造Tversky相似度矩阵的方法如下:首先,构建两个新图;接着,依据伪锚节点集合,将来自另一方的节点和相应的边加入到各自的图中;最后,计算不同图中两个节点邻域集合之间的Tversky系数,构造Tversky相似度矩阵.Lu et al[13]提出Bi_GANA (Bi⁃layer Graph Attention Neural Network for Network Alignment)算法,利用双层图注意力神经网络对多维用户特征和社交网络的局部和全局拓扑信息进行建模,通过不规则图和多维用户特征信息实现社交网络用户对齐问题.Huynh et al[14]提出NAME (Network Alignment with Multiple Embedding)算法,集成多种嵌入技术以创建更丰富、更准确的节点表示,并通过端到端的学习来实现高效对齐. ...
... Grad⁃Align[12]使用GIN学习节点的特征向量,然后融合嵌入向量相似性和节点结构的Tversky相似性.逐步发现强一致性的节点对,以便更好地捕获跨网络的节点的一致性. ...
Social network alignment:A bi?layer graph attention neural networks based method
1
2022
... 基于图神经网络的方法是利用图神经网络模型,例如图卷积网络(Graph Convolutional Network,GCN)[32]和图同构网络(Graph Isomorphic Network,GIN)[33]来学习不同网络中节点的表示,并通过学习到的特征向量推断不同网络中节点之间的相似性.Trung et al[9]提出GAlign算法,利用GCN学习节点的多阶嵌入.为了提高模型性能,GAlign设计了一种数据增强方法,主要通过对网络节点的边进行随机添加或删除操作来增加模型的鲁棒性和泛化能力,为网络对齐提供高质量的节点嵌入表示.Qin et al[10]提出G⁃CREWE (Graph CompRE⁃ssion with Embedding)算法,首先,利用GCN提取节点特征,获得原始网络的对齐结果;然后使用提出的MERGE (Minimum DEgRee NeiGhbors ComprEssion)方法对网络进行压缩,并在粗图上进行对齐;最后,将来自两种粒度网络的对齐结果合并,以实现高质量的对齐性能.Gao et al[11]提出WAlign算法,利用LGCN (Lightweight GCN)模型来捕获网络的局部和全局结构信息,获得高质量的节点特征向量,然后通过Wasserstein距离[34]鉴别器生成伪锚节点对,并在统一的优化框架下,利用对抗训练的方法迭代更新嵌入和鉴别器参数来提高对齐准确率.Park et al[12]提出Grade⁃Align算法,首先使用GIN生成嵌入向量并构建嵌入相似度矩阵,然后通过迭代的方式,融合嵌入相似度矩阵和不断更新的Tversky相似度矩阵来生成伪锚节点集合,逐步提高算法的对齐准确性.Tversky相似度[35]是一种基于集合的相似度计算方法,用于评估两个集合之间的相似程度.构造Tversky相似度矩阵的方法如下:首先,构建两个新图;接着,依据伪锚节点集合,将来自另一方的节点和相应的边加入到各自的图中;最后,计算不同图中两个节点邻域集合之间的Tversky系数,构造Tversky相似度矩阵.Lu et al[13]提出Bi_GANA (Bi⁃layer Graph Attention Neural Network for Network Alignment)算法,利用双层图注意力神经网络对多维用户特征和社交网络的局部和全局拓扑信息进行建模,通过不规则图和多维用户特征信息实现社交网络用户对齐问题.Huynh et al[14]提出NAME (Network Alignment with Multiple Embedding)算法,集成多种嵌入技术以创建更丰富、更准确的节点表示,并通过端到端的学习来实现高效对齐. ...
Network alignment with holistic embeddings
2
2023
... 网络对齐任务中,可利用网络的拓扑结构或节点属性信息来识别不同网络中的相似节点[5],但由于网络结构的复杂性,传统的网络对齐方法无法满足当下网络对齐任务的需求.近年来,研究人员提出许多基于嵌入的网络对齐方法,包括基于网络嵌入的方法[6-8]和基于图神经网络的方法[9-14],已有研究表明,基于嵌入方法的性能普遍优于传统方法.网络嵌入(Network Embedding)是一种降维技术,可以将网络节点特征映射到低维向量空间,能更好地表示节点之间的关系[15].图神经网络(Graph Neural Networks,GNN)是一种深度学习模型,能捕捉节点和边之间的复杂交互关系以及全局拓扑信息.这些技术被广泛应用于各种任务,如节点分类、链接预测和图分类[16]. ...
... 基于图神经网络的方法是利用图神经网络模型,例如图卷积网络(Graph Convolutional Network,GCN)[32]和图同构网络(Graph Isomorphic Network,GIN)[33]来学习不同网络中节点的表示,并通过学习到的特征向量推断不同网络中节点之间的相似性.Trung et al[9]提出GAlign算法,利用GCN学习节点的多阶嵌入.为了提高模型性能,GAlign设计了一种数据增强方法,主要通过对网络节点的边进行随机添加或删除操作来增加模型的鲁棒性和泛化能力,为网络对齐提供高质量的节点嵌入表示.Qin et al[10]提出G⁃CREWE (Graph CompRE⁃ssion with Embedding)算法,首先,利用GCN提取节点特征,获得原始网络的对齐结果;然后使用提出的MERGE (Minimum DEgRee NeiGhbors ComprEssion)方法对网络进行压缩,并在粗图上进行对齐;最后,将来自两种粒度网络的对齐结果合并,以实现高质量的对齐性能.Gao et al[11]提出WAlign算法,利用LGCN (Lightweight GCN)模型来捕获网络的局部和全局结构信息,获得高质量的节点特征向量,然后通过Wasserstein距离[34]鉴别器生成伪锚节点对,并在统一的优化框架下,利用对抗训练的方法迭代更新嵌入和鉴别器参数来提高对齐准确率.Park et al[12]提出Grade⁃Align算法,首先使用GIN生成嵌入向量并构建嵌入相似度矩阵,然后通过迭代的方式,融合嵌入相似度矩阵和不断更新的Tversky相似度矩阵来生成伪锚节点集合,逐步提高算法的对齐准确性.Tversky相似度[35]是一种基于集合的相似度计算方法,用于评估两个集合之间的相似程度.构造Tversky相似度矩阵的方法如下:首先,构建两个新图;接着,依据伪锚节点集合,将来自另一方的节点和相应的边加入到各自的图中;最后,计算不同图中两个节点邻域集合之间的Tversky系数,构造Tversky相似度矩阵.Lu et al[13]提出Bi_GANA (Bi⁃layer Graph Attention Neural Network for Network Alignment)算法,利用双层图注意力神经网络对多维用户特征和社交网络的局部和全局拓扑信息进行建模,通过不规则图和多维用户特征信息实现社交网络用户对齐问题.Huynh et al[14]提出NAME (Network Alignment with Multiple Embedding)算法,集成多种嵌入技术以创建更丰富、更准确的节点表示,并通过端到端的学习来实现高效对齐. ...
Network representation learning:From preprocessing,feature extraction to node embedding
1
2023
... 网络对齐任务中,可利用网络的拓扑结构或节点属性信息来识别不同网络中的相似节点[5],但由于网络结构的复杂性,传统的网络对齐方法无法满足当下网络对齐任务的需求.近年来,研究人员提出许多基于嵌入的网络对齐方法,包括基于网络嵌入的方法[6-8]和基于图神经网络的方法[9-14],已有研究表明,基于嵌入方法的性能普遍优于传统方法.网络嵌入(Network Embedding)是一种降维技术,可以将网络节点特征映射到低维向量空间,能更好地表示节点之间的关系[15].图神经网络(Graph Neural Networks,GNN)是一种深度学习模型,能捕捉节点和边之间的复杂交互关系以及全局拓扑信息.这些技术被广泛应用于各种任务,如节点分类、链接预测和图分类[16]. ...
Self?supervised learning of graph neural networks:A unified review
1
2023
... 网络对齐任务中,可利用网络的拓扑结构或节点属性信息来识别不同网络中的相似节点[5],但由于网络结构的复杂性,传统的网络对齐方法无法满足当下网络对齐任务的需求.近年来,研究人员提出许多基于嵌入的网络对齐方法,包括基于网络嵌入的方法[6-8]和基于图神经网络的方法[9-14],已有研究表明,基于嵌入方法的性能普遍优于传统方法.网络嵌入(Network Embedding)是一种降维技术,可以将网络节点特征映射到低维向量空间,能更好地表示节点之间的关系[15].图神经网络(Graph Neural Networks,GNN)是一种深度学习模型,能捕捉节点和边之间的复杂交互关系以及全局拓扑信息.这些技术被广泛应用于各种任务,如节点分类、链接预测和图分类[16]. ...
DeepWalk:Online learning of social representations
2
2014
... 基于网络嵌入的方法通常使用DeepWalk[17],LINE[18]等算法来学习源网络和目标网络的节点嵌入向量,然而,由于嵌入空间是独立构造的,无法直接利用这些向量表示来计算对齐矩阵.为了解决这个问题,常用的方法是对嵌入矩阵进行线性变换或使用神经网络学习两个嵌入空间的映射关系,但将不同的嵌入空间映射到同一向量空间通常需要大量监督样本,计算成本高,应用过程中存在困难.这些困难主要源于两方面:一是监督样本的获取困难;二是不同网络之间存在结构和语义差异,早期的网络嵌入技术难以捕获节点深层的语义特征.结构差异指两个网络的节点数量不同,语义差异指等效节点的邻域结构不同. ...
... 基于网络嵌入的方法使用DeepWalk[17]或LINE[18]等网络嵌入技术来学习不同网络中的节点表示.Man et al[6]提出PALE (Predicting Anchor Links via Embedding)算法,利用观测到的锚链为监督信息,结合LINE来捕捉不同网络之间的结构规律和相似性,并使用学习的嵌入向量来预测锚链.其中,锚链被视为网络中的关键节点,它们的位置和连接关系被用来指导嵌入向量的学习,通过这种方式PALE算法能更好地捕捉网络的结构和特征,提高预测的准确性和可靠性.Heimann et al[7]提出REGAL(Representation Based Graph Alignment)算法,通过扩展低秩矩阵近似的Nyström方法[26]和设置标准节点来加速表示学习,并通过Kd⁃tree方法[27]实现贪婪对齐.Nguyen et al[8]提出NAWAL (Network Alignment with Self⁃supervised Anchor Links)算法.首先,分别学习源网络和目标网络的节点向量表示;然后,使用生成对抗网络(Generative Adversarial Networks,GAN)[28]在无监督样本的情况下学习一个映射函数W,将两个网络的嵌入空间协调到一个公共空间中,在这个过程中,通过生成的伪锚链,利用Procrustes的封闭解[29]进一步优化嵌入;最后,采用贪婪启发式的方法进行对齐.Zhu et al[30]提出CAPER(Coarsen,Align,Project,Refine)算法,首先将输入网络粗化为不同粒度的网络,接着在最粗的网络上使用现有对齐算法(如REGAL)获得最粗的对齐矩阵,最后,将对齐结果进行逐层映射,最终得到最细层次的对齐矩阵.此外,CAPER在映射过程中,通过在不同粒度的对齐矩阵上使用CONE_Align[31]来改善对齐结果.CONE_Align提供了一种基于近邻一致性(Neighborhood Consistency)的优化方法来提高现有网络对齐算法的鲁棒性.具体地,如果已对齐的节点对具有相似的特征,则它们的邻居节点中很可能也存在相互对齐的节点. ...
LINE:Large?scale information network embedding
2
2015
... 基于网络嵌入的方法通常使用DeepWalk[17],LINE[18]等算法来学习源网络和目标网络的节点嵌入向量,然而,由于嵌入空间是独立构造的,无法直接利用这些向量表示来计算对齐矩阵.为了解决这个问题,常用的方法是对嵌入矩阵进行线性变换或使用神经网络学习两个嵌入空间的映射关系,但将不同的嵌入空间映射到同一向量空间通常需要大量监督样本,计算成本高,应用过程中存在困难.这些困难主要源于两方面:一是监督样本的获取困难;二是不同网络之间存在结构和语义差异,早期的网络嵌入技术难以捕获节点深层的语义特征.结构差异指两个网络的节点数量不同,语义差异指等效节点的邻域结构不同. ...
... 基于网络嵌入的方法使用DeepWalk[17]或LINE[18]等网络嵌入技术来学习不同网络中的节点表示.Man et al[6]提出PALE (Predicting Anchor Links via Embedding)算法,利用观测到的锚链为监督信息,结合LINE来捕捉不同网络之间的结构规律和相似性,并使用学习的嵌入向量来预测锚链.其中,锚链被视为网络中的关键节点,它们的位置和连接关系被用来指导嵌入向量的学习,通过这种方式PALE算法能更好地捕捉网络的结构和特征,提高预测的准确性和可靠性.Heimann et al[7]提出REGAL(Representation Based Graph Alignment)算法,通过扩展低秩矩阵近似的Nyström方法[26]和设置标准节点来加速表示学习,并通过Kd⁃tree方法[27]实现贪婪对齐.Nguyen et al[8]提出NAWAL (Network Alignment with Self⁃supervised Anchor Links)算法.首先,分别学习源网络和目标网络的节点向量表示;然后,使用生成对抗网络(Generative Adversarial Networks,GAN)[28]在无监督样本的情况下学习一个映射函数W,将两个网络的嵌入空间协调到一个公共空间中,在这个过程中,通过生成的伪锚链,利用Procrustes的封闭解[29]进一步优化嵌入;最后,采用贪婪启发式的方法进行对齐.Zhu et al[30]提出CAPER(Coarsen,Align,Project,Refine)算法,首先将输入网络粗化为不同粒度的网络,接着在最粗的网络上使用现有对齐算法(如REGAL)获得最粗的对齐矩阵,最后,将对齐结果进行逐层映射,最终得到最细层次的对齐矩阵.此外,CAPER在映射过程中,通过在不同粒度的对齐矩阵上使用CONE_Align[31]来改善对齐结果.CONE_Align提供了一种基于近邻一致性(Neighborhood Consistency)的优化方法来提高现有网络对齐算法的鲁棒性.具体地,如果已对齐的节点对具有相似的特征,则它们的邻居节点中很可能也存在相互对齐的节点. ...
Multilevel graph partitioning:An evolutionary approach
1
2005
... 基于匹配的方法是一种有效的图粗化方法,其主要思想是使用匹配规则来寻找相互匹配的节点,并通过互匹配的节点来构造超级节点.这一操作可以重复进行,直到没有节点能匹配或达到所需的粗化水平.通常可以根据图的固有特征制定相应的匹配规则,例如节点的度或节点共邻的数量.代表算法有重边匹配(Heavy Edge Matching,HEM)算法[19]、结构等价匹配(Structural Equivalence Matching,SEM)算法[20]和归一化重边匹配(Normalized Heavy Edge Matching,NHEM)算法[21].其中,HEM算法采用贪心原则,依据边的权重来匹配合并相邻节点;SEM算法将具有相同结构的节点视为等价节点进行匹配;NHEM算法在HEM的基础上进行改进,通过对每个节点的边权重进行归一化处理使所有边权值的和为1,避免权重过大或过小而导致的匹配偏差. ...
Understanding coarsening for embedding large?scale graphs
1
2020
... 基于匹配的方法是一种有效的图粗化方法,其主要思想是使用匹配规则来寻找相互匹配的节点,并通过互匹配的节点来构造超级节点.这一操作可以重复进行,直到没有节点能匹配或达到所需的粗化水平.通常可以根据图的固有特征制定相应的匹配规则,例如节点的度或节点共邻的数量.代表算法有重边匹配(Heavy Edge Matching,HEM)算法[19]、结构等价匹配(Structural Equivalence Matching,SEM)算法[20]和归一化重边匹配(Normalized Heavy Edge Matching,NHEM)算法[21].其中,HEM算法采用贪心原则,依据边的权重来匹配合并相邻节点;SEM算法将具有相同结构的节点视为等价节点进行匹配;NHEM算法在HEM的基础上进行改进,通过对每个节点的边权重进行归一化处理使所有边权值的和为1,避免权重过大或过小而导致的匹配偏差. ...
Structural equivalence in subgraph matching
1
2023
... 基于匹配的方法是一种有效的图粗化方法,其主要思想是使用匹配规则来寻找相互匹配的节点,并通过互匹配的节点来构造超级节点.这一操作可以重复进行,直到没有节点能匹配或达到所需的粗化水平.通常可以根据图的固有特征制定相应的匹配规则,例如节点的度或节点共邻的数量.代表算法有重边匹配(Heavy Edge Matching,HEM)算法[19]、结构等价匹配(Structural Equivalence Matching,SEM)算法[20]和归一化重边匹配(Normalized Heavy Edge Matching,NHEM)算法[21].其中,HEM算法采用贪心原则,依据边的权重来匹配合并相邻节点;SEM算法将具有相同结构的节点视为等价节点进行匹配;NHEM算法在HEM的基础上进行改进,通过对每个节点的边权重进行归一化处理使所有边权值的和为1,避免权重过大或过小而导致的匹配偏差. ...
Unsupervised multi?view K?means clustering algorithm
1
2023
... 基于聚类的方法采用图聚类或社团检测算法,按照特定标准(如距离或模块度)将节点划分为不同的簇,使同一簇内节点的相似性尽可能大,同时,不同簇的节点差异性也尽可能大,然后递归地合并这些簇,直至达到所需的粗化水平.代表的图聚类算法有K⁃means[22]和高斯混合模型(Gaussian Mixture Model,GMM)[23]等.K⁃means是一种迭代求解的聚类分析算法,GMM是一种基于概率模型的聚类方法,代表的社团检测算法有鲁汶(Louvain)算法[24]等. ...
Graph representation learning based on deep generative gaussian mixture models
1
2023
... 基于聚类的方法采用图聚类或社团检测算法,按照特定标准(如距离或模块度)将节点划分为不同的簇,使同一簇内节点的相似性尽可能大,同时,不同簇的节点差异性也尽可能大,然后递归地合并这些簇,直至达到所需的粗化水平.代表的图聚类算法有K⁃means[22]和高斯混合模型(Gaussian Mixture Model,GMM)[23]等.K⁃means是一种迭代求解的聚类分析算法,GMM是一种基于概率模型的聚类方法,代表的社团检测算法有鲁汶(Louvain)算法[24]等. ...
Scalable distributed Louvain algorithm for community detection in large graphs
1
2022
... 基于聚类的方法采用图聚类或社团检测算法,按照特定标准(如距离或模块度)将节点划分为不同的簇,使同一簇内节点的相似性尽可能大,同时,不同簇的节点差异性也尽可能大,然后递归地合并这些簇,直至达到所需的粗化水平.代表的图聚类算法有K⁃means[22]和高斯混合模型(Gaussian Mixture Model,GMM)[23]等.K⁃means是一种迭代求解的聚类分析算法,GMM是一种基于概率模型的聚类方法,代表的社团检测算法有鲁汶(Louvain)算法[24]等. ...
Graph reduction with spectral and cut guarantees
2
2019
... 基于谱的图粗化方法的目的是保留原始图和粗图之间的谱特性.图中的谱通常指拉普拉斯(Laplacian)矩阵,用于在谱域上描述图结构和节点之间的关系.Loukas[25]提出一种基于受限谱逼近的多层次图粗化算法,可以在保持原始图结构特征不变的情况下将其缩减为更小规模的图.受限谱逼近是一种谱逼近方法,其主要思想是选择一个低维子空间,使得在该子空间中,原始图和粗图之间的谱距离最小化. ...
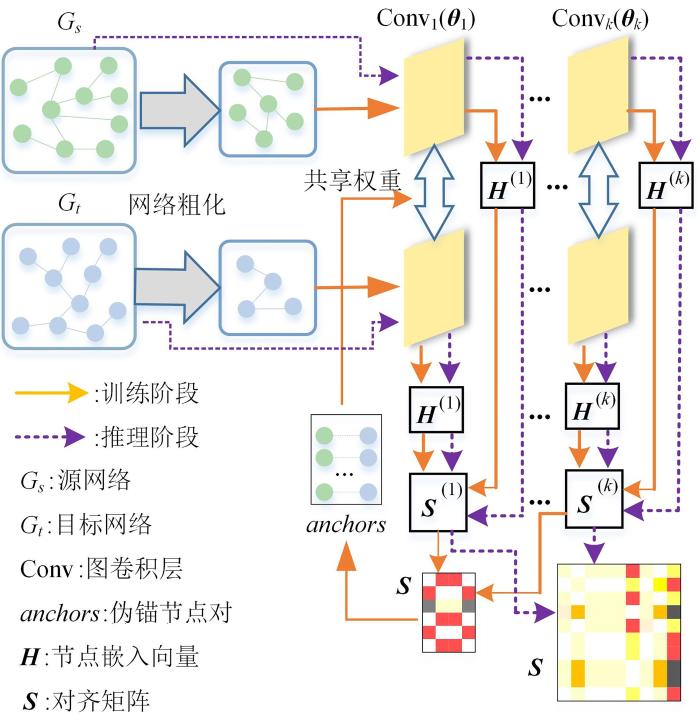
... 由于结构噪声对图拉普拉斯矩阵的谱影响较小[36],因此本文采用基于谱的粗化方法来简化网络结构.具体地,采用Loukas[25]的基于邻域的局部变化的图粗化方法,利用受限谱逼近方法来缩减图的大小,在不显著改变图的基本属性的情况下,具有很强的谱和割保证.因此,该方法可以有效地简化网络结构,同时保留原始图的关键谱(结构)特性.另外,该方法还提供参数来控制输出粗图的规模,,其中,是原始图的节点数,是粗图的节点数.算法的输出为粗图的邻接矩阵和分配矩阵,分配矩阵决定哪些邻居可以聚在一起形成超节点.根据分配矩阵可获得粗图的属性矩阵,计算如下: ...
On the Nystr?m method for approximating a gram matrix for improved kernel?based learning
1
2005
... 基于网络嵌入的方法使用DeepWalk[17]或LINE[18]等网络嵌入技术来学习不同网络中的节点表示.Man et al[6]提出PALE (Predicting Anchor Links via Embedding)算法,利用观测到的锚链为监督信息,结合LINE来捕捉不同网络之间的结构规律和相似性,并使用学习的嵌入向量来预测锚链.其中,锚链被视为网络中的关键节点,它们的位置和连接关系被用来指导嵌入向量的学习,通过这种方式PALE算法能更好地捕捉网络的结构和特征,提高预测的准确性和可靠性.Heimann et al[7]提出REGAL(Representation Based Graph Alignment)算法,通过扩展低秩矩阵近似的Nyström方法[26]和设置标准节点来加速表示学习,并通过Kd⁃tree方法[27]实现贪婪对齐.Nguyen et al[8]提出NAWAL (Network Alignment with Self⁃supervised Anchor Links)算法.首先,分别学习源网络和目标网络的节点向量表示;然后,使用生成对抗网络(Generative Adversarial Networks,GAN)[28]在无监督样本的情况下学习一个映射函数W,将两个网络的嵌入空间协调到一个公共空间中,在这个过程中,通过生成的伪锚链,利用Procrustes的封闭解[29]进一步优化嵌入;最后,采用贪婪启发式的方法进行对齐.Zhu et al[30]提出CAPER(Coarsen,Align,Project,Refine)算法,首先将输入网络粗化为不同粒度的网络,接着在最粗的网络上使用现有对齐算法(如REGAL)获得最粗的对齐矩阵,最后,将对齐结果进行逐层映射,最终得到最细层次的对齐矩阵.此外,CAPER在映射过程中,通过在不同粒度的对齐矩阵上使用CONE_Align[31]来改善对齐结果.CONE_Align提供了一种基于近邻一致性(Neighborhood Consistency)的优化方法来提高现有网络对齐算法的鲁棒性.具体地,如果已对齐的节点对具有相似的特征,则它们的邻居节点中很可能也存在相互对齐的节点. ...
A dynamic linkage clustering using KD?tree
1
2013
... 基于网络嵌入的方法使用DeepWalk[17]或LINE[18]等网络嵌入技术来学习不同网络中的节点表示.Man et al[6]提出PALE (Predicting Anchor Links via Embedding)算法,利用观测到的锚链为监督信息,结合LINE来捕捉不同网络之间的结构规律和相似性,并使用学习的嵌入向量来预测锚链.其中,锚链被视为网络中的关键节点,它们的位置和连接关系被用来指导嵌入向量的学习,通过这种方式PALE算法能更好地捕捉网络的结构和特征,提高预测的准确性和可靠性.Heimann et al[7]提出REGAL(Representation Based Graph Alignment)算法,通过扩展低秩矩阵近似的Nyström方法[26]和设置标准节点来加速表示学习,并通过Kd⁃tree方法[27]实现贪婪对齐.Nguyen et al[8]提出NAWAL (Network Alignment with Self⁃supervised Anchor Links)算法.首先,分别学习源网络和目标网络的节点向量表示;然后,使用生成对抗网络(Generative Adversarial Networks,GAN)[28]在无监督样本的情况下学习一个映射函数W,将两个网络的嵌入空间协调到一个公共空间中,在这个过程中,通过生成的伪锚链,利用Procrustes的封闭解[29]进一步优化嵌入;最后,采用贪婪启发式的方法进行对齐.Zhu et al[30]提出CAPER(Coarsen,Align,Project,Refine)算法,首先将输入网络粗化为不同粒度的网络,接着在最粗的网络上使用现有对齐算法(如REGAL)获得最粗的对齐矩阵,最后,将对齐结果进行逐层映射,最终得到最细层次的对齐矩阵.此外,CAPER在映射过程中,通过在不同粒度的对齐矩阵上使用CONE_Align[31]来改善对齐结果.CONE_Align提供了一种基于近邻一致性(Neighborhood Consistency)的优化方法来提高现有网络对齐算法的鲁棒性.具体地,如果已对齐的节点对具有相似的特征,则它们的邻居节点中很可能也存在相互对齐的节点. ...
Generative adversarial networks
1
2020
... 基于网络嵌入的方法使用DeepWalk[17]或LINE[18]等网络嵌入技术来学习不同网络中的节点表示.Man et al[6]提出PALE (Predicting Anchor Links via Embedding)算法,利用观测到的锚链为监督信息,结合LINE来捕捉不同网络之间的结构规律和相似性,并使用学习的嵌入向量来预测锚链.其中,锚链被视为网络中的关键节点,它们的位置和连接关系被用来指导嵌入向量的学习,通过这种方式PALE算法能更好地捕捉网络的结构和特征,提高预测的准确性和可靠性.Heimann et al[7]提出REGAL(Representation Based Graph Alignment)算法,通过扩展低秩矩阵近似的Nyström方法[26]和设置标准节点来加速表示学习,并通过Kd⁃tree方法[27]实现贪婪对齐.Nguyen et al[8]提出NAWAL (Network Alignment with Self⁃supervised Anchor Links)算法.首先,分别学习源网络和目标网络的节点向量表示;然后,使用生成对抗网络(Generative Adversarial Networks,GAN)[28]在无监督样本的情况下学习一个映射函数W,将两个网络的嵌入空间协调到一个公共空间中,在这个过程中,通过生成的伪锚链,利用Procrustes的封闭解[29]进一步优化嵌入;最后,采用贪婪启发式的方法进行对齐.Zhu et al[30]提出CAPER(Coarsen,Align,Project,Refine)算法,首先将输入网络粗化为不同粒度的网络,接着在最粗的网络上使用现有对齐算法(如REGAL)获得最粗的对齐矩阵,最后,将对齐结果进行逐层映射,最终得到最细层次的对齐矩阵.此外,CAPER在映射过程中,通过在不同粒度的对齐矩阵上使用CONE_Align[31]来改善对齐结果.CONE_Align提供了一种基于近邻一致性(Neighborhood Consistency)的优化方法来提高现有网络对齐算法的鲁棒性.具体地,如果已对齐的节点对具有相似的特征,则它们的邻居节点中很可能也存在相互对齐的节点. ...
A generalized solution of the orthogonal procrustes problem
1
1966
... 基于网络嵌入的方法使用DeepWalk[17]或LINE[18]等网络嵌入技术来学习不同网络中的节点表示.Man et al[6]提出PALE (Predicting Anchor Links via Embedding)算法,利用观测到的锚链为监督信息,结合LINE来捕捉不同网络之间的结构规律和相似性,并使用学习的嵌入向量来预测锚链.其中,锚链被视为网络中的关键节点,它们的位置和连接关系被用来指导嵌入向量的学习,通过这种方式PALE算法能更好地捕捉网络的结构和特征,提高预测的准确性和可靠性.Heimann et al[7]提出REGAL(Representation Based Graph Alignment)算法,通过扩展低秩矩阵近似的Nyström方法[26]和设置标准节点来加速表示学习,并通过Kd⁃tree方法[27]实现贪婪对齐.Nguyen et al[8]提出NAWAL (Network Alignment with Self⁃supervised Anchor Links)算法.首先,分别学习源网络和目标网络的节点向量表示;然后,使用生成对抗网络(Generative Adversarial Networks,GAN)[28]在无监督样本的情况下学习一个映射函数W,将两个网络的嵌入空间协调到一个公共空间中,在这个过程中,通过生成的伪锚链,利用Procrustes的封闭解[29]进一步优化嵌入;最后,采用贪婪启发式的方法进行对齐.Zhu et al[30]提出CAPER(Coarsen,Align,Project,Refine)算法,首先将输入网络粗化为不同粒度的网络,接着在最粗的网络上使用现有对齐算法(如REGAL)获得最粗的对齐矩阵,最后,将对齐结果进行逐层映射,最终得到最细层次的对齐矩阵.此外,CAPER在映射过程中,通过在不同粒度的对齐矩阵上使用CONE_Align[31]来改善对齐结果.CONE_Align提供了一种基于近邻一致性(Neighborhood Consistency)的优化方法来提高现有网络对齐算法的鲁棒性.具体地,如果已对齐的节点对具有相似的特征,则它们的邻居节点中很可能也存在相互对齐的节点. ...
CAPER:Coarsen,align,project,refine:A general multilevel framework for network alignment
1
2022
... 基于网络嵌入的方法使用DeepWalk[17]或LINE[18]等网络嵌入技术来学习不同网络中的节点表示.Man et al[6]提出PALE (Predicting Anchor Links via Embedding)算法,利用观测到的锚链为监督信息,结合LINE来捕捉不同网络之间的结构规律和相似性,并使用学习的嵌入向量来预测锚链.其中,锚链被视为网络中的关键节点,它们的位置和连接关系被用来指导嵌入向量的学习,通过这种方式PALE算法能更好地捕捉网络的结构和特征,提高预测的准确性和可靠性.Heimann et al[7]提出REGAL(Representation Based Graph Alignment)算法,通过扩展低秩矩阵近似的Nyström方法[26]和设置标准节点来加速表示学习,并通过Kd⁃tree方法[27]实现贪婪对齐.Nguyen et al[8]提出NAWAL (Network Alignment with Self⁃supervised Anchor Links)算法.首先,分别学习源网络和目标网络的节点向量表示;然后,使用生成对抗网络(Generative Adversarial Networks,GAN)[28]在无监督样本的情况下学习一个映射函数W,将两个网络的嵌入空间协调到一个公共空间中,在这个过程中,通过生成的伪锚链,利用Procrustes的封闭解[29]进一步优化嵌入;最后,采用贪婪启发式的方法进行对齐.Zhu et al[30]提出CAPER(Coarsen,Align,Project,Refine)算法,首先将输入网络粗化为不同粒度的网络,接着在最粗的网络上使用现有对齐算法(如REGAL)获得最粗的对齐矩阵,最后,将对齐结果进行逐层映射,最终得到最细层次的对齐矩阵.此外,CAPER在映射过程中,通过在不同粒度的对齐矩阵上使用CONE_Align[31]来改善对齐结果.CONE_Align提供了一种基于近邻一致性(Neighborhood Consistency)的优化方法来提高现有网络对齐算法的鲁棒性.具体地,如果已对齐的节点对具有相似的特征,则它们的邻居节点中很可能也存在相互对齐的节点. ...
CONE?Align:Consistent network alignment with proximity?preserving node embedding
1
... 基于网络嵌入的方法使用DeepWalk[17]或LINE[18]等网络嵌入技术来学习不同网络中的节点表示.Man et al[6]提出PALE (Predicting Anchor Links via Embedding)算法,利用观测到的锚链为监督信息,结合LINE来捕捉不同网络之间的结构规律和相似性,并使用学习的嵌入向量来预测锚链.其中,锚链被视为网络中的关键节点,它们的位置和连接关系被用来指导嵌入向量的学习,通过这种方式PALE算法能更好地捕捉网络的结构和特征,提高预测的准确性和可靠性.Heimann et al[7]提出REGAL(Representation Based Graph Alignment)算法,通过扩展低秩矩阵近似的Nyström方法[26]和设置标准节点来加速表示学习,并通过Kd⁃tree方法[27]实现贪婪对齐.Nguyen et al[8]提出NAWAL (Network Alignment with Self⁃supervised Anchor Links)算法.首先,分别学习源网络和目标网络的节点向量表示;然后,使用生成对抗网络(Generative Adversarial Networks,GAN)[28]在无监督样本的情况下学习一个映射函数W,将两个网络的嵌入空间协调到一个公共空间中,在这个过程中,通过生成的伪锚链,利用Procrustes的封闭解[29]进一步优化嵌入;最后,采用贪婪启发式的方法进行对齐.Zhu et al[30]提出CAPER(Coarsen,Align,Project,Refine)算法,首先将输入网络粗化为不同粒度的网络,接着在最粗的网络上使用现有对齐算法(如REGAL)获得最粗的对齐矩阵,最后,将对齐结果进行逐层映射,最终得到最细层次的对齐矩阵.此外,CAPER在映射过程中,通过在不同粒度的对齐矩阵上使用CONE_Align[31]来改善对齐结果.CONE_Align提供了一种基于近邻一致性(Neighborhood Consistency)的优化方法来提高现有网络对齐算法的鲁棒性.具体地,如果已对齐的节点对具有相似的特征,则它们的邻居节点中很可能也存在相互对齐的节点. ...
Semi?supervised classification with graph convolutional networks
2
2016
... 基于图神经网络的方法是利用图神经网络模型,例如图卷积网络(Graph Convolutional Network,GCN)[32]和图同构网络(Graph Isomorphic Network,GIN)[33]来学习不同网络中节点的表示,并通过学习到的特征向量推断不同网络中节点之间的相似性.Trung et al[9]提出GAlign算法,利用GCN学习节点的多阶嵌入.为了提高模型性能,GAlign设计了一种数据增强方法,主要通过对网络节点的边进行随机添加或删除操作来增加模型的鲁棒性和泛化能力,为网络对齐提供高质量的节点嵌入表示.Qin et al[10]提出G⁃CREWE (Graph CompRE⁃ssion with Embedding)算法,首先,利用GCN提取节点特征,获得原始网络的对齐结果;然后使用提出的MERGE (Minimum DEgRee NeiGhbors ComprEssion)方法对网络进行压缩,并在粗图上进行对齐;最后,将来自两种粒度网络的对齐结果合并,以实现高质量的对齐性能.Gao et al[11]提出WAlign算法,利用LGCN (Lightweight GCN)模型来捕获网络的局部和全局结构信息,获得高质量的节点特征向量,然后通过Wasserstein距离[34]鉴别器生成伪锚节点对,并在统一的优化框架下,利用对抗训练的方法迭代更新嵌入和鉴别器参数来提高对齐准确率.Park et al[12]提出Grade⁃Align算法,首先使用GIN生成嵌入向量并构建嵌入相似度矩阵,然后通过迭代的方式,融合嵌入相似度矩阵和不断更新的Tversky相似度矩阵来生成伪锚节点集合,逐步提高算法的对齐准确性.Tversky相似度[35]是一种基于集合的相似度计算方法,用于评估两个集合之间的相似程度.构造Tversky相似度矩阵的方法如下:首先,构建两个新图;接着,依据伪锚节点集合,将来自另一方的节点和相应的边加入到各自的图中;最后,计算不同图中两个节点邻域集合之间的Tversky系数,构造Tversky相似度矩阵.Lu et al[13]提出Bi_GANA (Bi⁃layer Graph Attention Neural Network for Network Alignment)算法,利用双层图注意力神经网络对多维用户特征和社交网络的局部和全局拓扑信息进行建模,通过不规则图和多维用户特征信息实现社交网络用户对齐问题.Huynh et al[14]提出NAME (Network Alignment with Multiple Embedding)算法,集成多种嵌入技术以创建更丰富、更准确的节点表示,并通过端到端的学习来实现高效对齐. ...
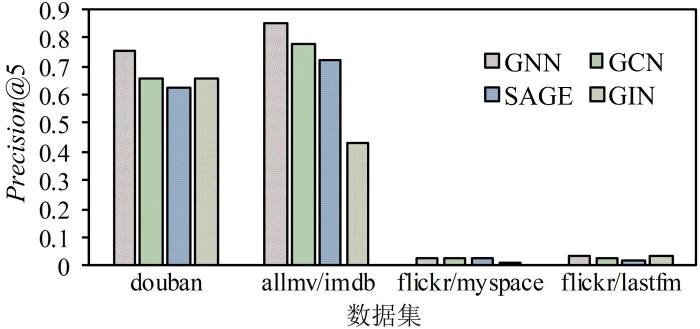
... 探究不同的GNN模型和网络粗化策略对FAROS性能的影响.首先使用三种常见的卷积图神经网络模型,分别是GCN[32],GraphSAGE[40]和GIN[33]来替换本文中的GNN模型.实验结果如图5所示. ...
How powerful are graph neural networks?
2
2018
... 基于图神经网络的方法是利用图神经网络模型,例如图卷积网络(Graph Convolutional Network,GCN)[32]和图同构网络(Graph Isomorphic Network,GIN)[33]来学习不同网络中节点的表示,并通过学习到的特征向量推断不同网络中节点之间的相似性.Trung et al[9]提出GAlign算法,利用GCN学习节点的多阶嵌入.为了提高模型性能,GAlign设计了一种数据增强方法,主要通过对网络节点的边进行随机添加或删除操作来增加模型的鲁棒性和泛化能力,为网络对齐提供高质量的节点嵌入表示.Qin et al[10]提出G⁃CREWE (Graph CompRE⁃ssion with Embedding)算法,首先,利用GCN提取节点特征,获得原始网络的对齐结果;然后使用提出的MERGE (Minimum DEgRee NeiGhbors ComprEssion)方法对网络进行压缩,并在粗图上进行对齐;最后,将来自两种粒度网络的对齐结果合并,以实现高质量的对齐性能.Gao et al[11]提出WAlign算法,利用LGCN (Lightweight GCN)模型来捕获网络的局部和全局结构信息,获得高质量的节点特征向量,然后通过Wasserstein距离[34]鉴别器生成伪锚节点对,并在统一的优化框架下,利用对抗训练的方法迭代更新嵌入和鉴别器参数来提高对齐准确率.Park et al[12]提出Grade⁃Align算法,首先使用GIN生成嵌入向量并构建嵌入相似度矩阵,然后通过迭代的方式,融合嵌入相似度矩阵和不断更新的Tversky相似度矩阵来生成伪锚节点集合,逐步提高算法的对齐准确性.Tversky相似度[35]是一种基于集合的相似度计算方法,用于评估两个集合之间的相似程度.构造Tversky相似度矩阵的方法如下:首先,构建两个新图;接着,依据伪锚节点集合,将来自另一方的节点和相应的边加入到各自的图中;最后,计算不同图中两个节点邻域集合之间的Tversky系数,构造Tversky相似度矩阵.Lu et al[13]提出Bi_GANA (Bi⁃layer Graph Attention Neural Network for Network Alignment)算法,利用双层图注意力神经网络对多维用户特征和社交网络的局部和全局拓扑信息进行建模,通过不规则图和多维用户特征信息实现社交网络用户对齐问题.Huynh et al[14]提出NAME (Network Alignment with Multiple Embedding)算法,集成多种嵌入技术以创建更丰富、更准确的节点表示,并通过端到端的学习来实现高效对齐. ...
... 探究不同的GNN模型和网络粗化策略对FAROS性能的影响.首先使用三种常见的卷积图神经网络模型,分别是GCN[32],GraphSAGE[40]和GIN[33]来替换本文中的GNN模型.实验结果如图5所示. ...
Wasserstein distance based multi?scale adversarial domain adaptation method for remaining useful life prediction
1
2023
... 基于图神经网络的方法是利用图神经网络模型,例如图卷积网络(Graph Convolutional Network,GCN)[32]和图同构网络(Graph Isomorphic Network,GIN)[33]来学习不同网络中节点的表示,并通过学习到的特征向量推断不同网络中节点之间的相似性.Trung et al[9]提出GAlign算法,利用GCN学习节点的多阶嵌入.为了提高模型性能,GAlign设计了一种数据增强方法,主要通过对网络节点的边进行随机添加或删除操作来增加模型的鲁棒性和泛化能力,为网络对齐提供高质量的节点嵌入表示.Qin et al[10]提出G⁃CREWE (Graph CompRE⁃ssion with Embedding)算法,首先,利用GCN提取节点特征,获得原始网络的对齐结果;然后使用提出的MERGE (Minimum DEgRee NeiGhbors ComprEssion)方法对网络进行压缩,并在粗图上进行对齐;最后,将来自两种粒度网络的对齐结果合并,以实现高质量的对齐性能.Gao et al[11]提出WAlign算法,利用LGCN (Lightweight GCN)模型来捕获网络的局部和全局结构信息,获得高质量的节点特征向量,然后通过Wasserstein距离[34]鉴别器生成伪锚节点对,并在统一的优化框架下,利用对抗训练的方法迭代更新嵌入和鉴别器参数来提高对齐准确率.Park et al[12]提出Grade⁃Align算法,首先使用GIN生成嵌入向量并构建嵌入相似度矩阵,然后通过迭代的方式,融合嵌入相似度矩阵和不断更新的Tversky相似度矩阵来生成伪锚节点集合,逐步提高算法的对齐准确性.Tversky相似度[35]是一种基于集合的相似度计算方法,用于评估两个集合之间的相似程度.构造Tversky相似度矩阵的方法如下:首先,构建两个新图;接着,依据伪锚节点集合,将来自另一方的节点和相应的边加入到各自的图中;最后,计算不同图中两个节点邻域集合之间的Tversky系数,构造Tversky相似度矩阵.Lu et al[13]提出Bi_GANA (Bi⁃layer Graph Attention Neural Network for Network Alignment)算法,利用双层图注意力神经网络对多维用户特征和社交网络的局部和全局拓扑信息进行建模,通过不规则图和多维用户特征信息实现社交网络用户对齐问题.Huynh et al[14]提出NAME (Network Alignment with Multiple Embedding)算法,集成多种嵌入技术以创建更丰富、更准确的节点表示,并通过端到端的学习来实现高效对齐. ...
Design of chemical space networks on the basis of Tversky similarity
1
2016
... 基于图神经网络的方法是利用图神经网络模型,例如图卷积网络(Graph Convolutional Network,GCN)[32]和图同构网络(Graph Isomorphic Network,GIN)[33]来学习不同网络中节点的表示,并通过学习到的特征向量推断不同网络中节点之间的相似性.Trung et al[9]提出GAlign算法,利用GCN学习节点的多阶嵌入.为了提高模型性能,GAlign设计了一种数据增强方法,主要通过对网络节点的边进行随机添加或删除操作来增加模型的鲁棒性和泛化能力,为网络对齐提供高质量的节点嵌入表示.Qin et al[10]提出G⁃CREWE (Graph CompRE⁃ssion with Embedding)算法,首先,利用GCN提取节点特征,获得原始网络的对齐结果;然后使用提出的MERGE (Minimum DEgRee NeiGhbors ComprEssion)方法对网络进行压缩,并在粗图上进行对齐;最后,将来自两种粒度网络的对齐结果合并,以实现高质量的对齐性能.Gao et al[11]提出WAlign算法,利用LGCN (Lightweight GCN)模型来捕获网络的局部和全局结构信息,获得高质量的节点特征向量,然后通过Wasserstein距离[34]鉴别器生成伪锚节点对,并在统一的优化框架下,利用对抗训练的方法迭代更新嵌入和鉴别器参数来提高对齐准确率.Park et al[12]提出Grade⁃Align算法,首先使用GIN生成嵌入向量并构建嵌入相似度矩阵,然后通过迭代的方式,融合嵌入相似度矩阵和不断更新的Tversky相似度矩阵来生成伪锚节点集合,逐步提高算法的对齐准确性.Tversky相似度[35]是一种基于集合的相似度计算方法,用于评估两个集合之间的相似程度.构造Tversky相似度矩阵的方法如下:首先,构建两个新图;接着,依据伪锚节点集合,将来自另一方的节点和相应的边加入到各自的图中;最后,计算不同图中两个节点邻域集合之间的Tversky系数,构造Tversky相似度矩阵.Lu et al[13]提出Bi_GANA (Bi⁃layer Graph Attention Neural Network for Network Alignment)算法,利用双层图注意力神经网络对多维用户特征和社交网络的局部和全局拓扑信息进行建模,通过不规则图和多维用户特征信息实现社交网络用户对齐问题.Huynh et al[14]提出NAME (Network Alignment with Multiple Embedding)算法,集成多种嵌入技术以创建更丰富、更准确的节点表示,并通过端到端的学习来实现高效对齐. ...
Hierarchical and unsupervised graph representation learning with Loukas's coarsening
1
2020
... 由于结构噪声对图拉普拉斯矩阵的谱影响较小[36],因此本文采用基于谱的粗化方法来简化网络结构.具体地,采用Loukas[25]的基于邻域的局部变化的图粗化方法,利用受限谱逼近方法来缩减图的大小,在不显著改变图的基本属性的情况下,具有很强的谱和割保证.因此,该方法可以有效地简化网络结构,同时保留原始图的关键谱(结构)特性.另外,该方法还提供参数来控制输出粗图的规模,,其中,是原始图的节点数,是粗图的节点数.算法的输出为粗图的邻接矩阵和分配矩阵,分配矩阵决定哪些邻居可以聚在一起形成超节点.根据分配矩阵可获得粗图的属性矩阵,计算如下: ...
Weisfeiler and leman go neural:Higher?order graph neural networks
1
2019
... 网络对齐中,通过GNN学习节点的特征向量来构建对齐矩阵.一个标准的GNN模型[37]由个图卷积层组成,每个图卷积层通过消息传递策略来捕获网络的结构和属性信息[38].从初始的特征开始,第层的节点特征由第层的相邻节点的特征聚合而成.具体地,设源网络或目标网络中的节点在第层的特征向量为,那么,第层的图卷积可表示为: ...
A comprehensive survey on graph neural networks
1
2021
... 网络对齐中,通过GNN学习节点的特征向量来构建对齐矩阵.一个标准的GNN模型[37]由个图卷积层组成,每个图卷积层通过消息传递策略来捕获网络的结构和属性信息[38].从初始的特征开始,第层的节点特征由第层的相邻节点的特征聚合而成.具体地,设源网络或目标网络中的节点在第层的特征向量为,那么,第层的图卷积可表示为: ...
FINAL:Fast attributed network alignment
2
2016
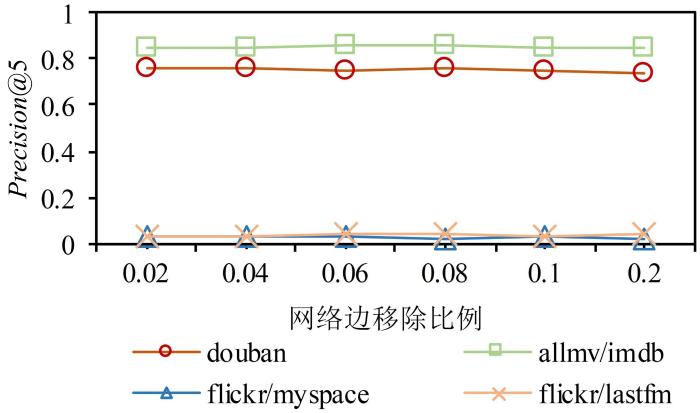
... douban数据集来自豆瓣网,包括douban online/offline[39],其中节点代表用户.douban online中,边代表用户之间是否互为好友,douban offline中,边代表用户是否参加了同一场线下活动.allmv/imdb数据集来自Rotten Tomatoes网站和Imdb网站,其中节点代表电影,边代表两部电影至少有一位共同演员.flickr,myspace和lastfm数据集均来自社交网络平台,其中节点表示用户,边代表用户之间的交互关系. ...
... NAWAL[8]首先利用Node2Vec[39]算法学习节点的特征表示,然后使用自监督锚链接来实时更新节点的嵌入向量,并通过最大化锚链接之间的相似性来实现对齐. ...
node2vec:Scalable feature learning for networks
1
2016
... 探究不同的GNN模型和网络粗化策略对FAROS性能的影响.首先使用三种常见的卷积图神经网络模型,分别是GCN[32],GraphSAGE[40]和GIN[33]来替换本文中的GNN模型.实验结果如图5所示. ...
Relaxation?based coarsening and multiscale graph organization
1
2011
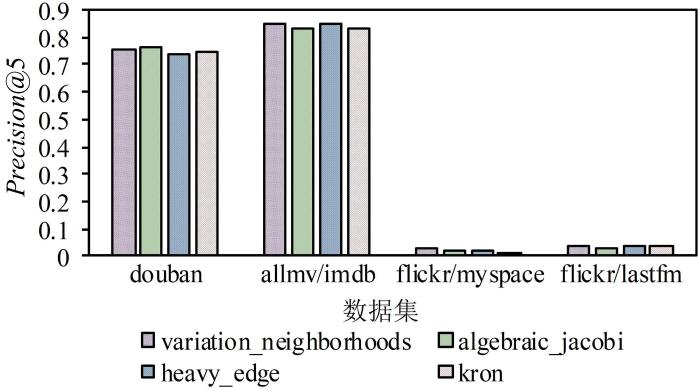
... 采用三种其他粗化方法替代本文使用的粗化方法(variation_neighborhoods),分别是基于代数多重网格的粗化算法(algebraic_jacobi)[41],基于重边匹配的粗化算法(heavy_edge)[42]和基于Kron简化的粗化算法(kron)[43].实验结果如图6所示. ...
Weighted graph cuts without eigenvectors a multilevel approach
1
2007
... 采用三种其他粗化方法替代本文使用的粗化方法(variation_neighborhoods),分别是基于代数多重网格的粗化算法(algebraic_jacobi)[41],基于重边匹配的粗化算法(heavy_edge)[42]和基于Kron简化的粗化算法(kron)[43].实验结果如图6所示. ...
A multiscale pyramid transform for graph signals
1
2016
... 采用三种其他粗化方法替代本文使用的粗化方法(variation_neighborhoods),分别是基于代数多重网格的粗化算法(algebraic_jacobi)[41],基于重边匹配的粗化算法(heavy_edge)[42]和基于Kron简化的粗化算法(kron)[43].实验结果如图6所示. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}