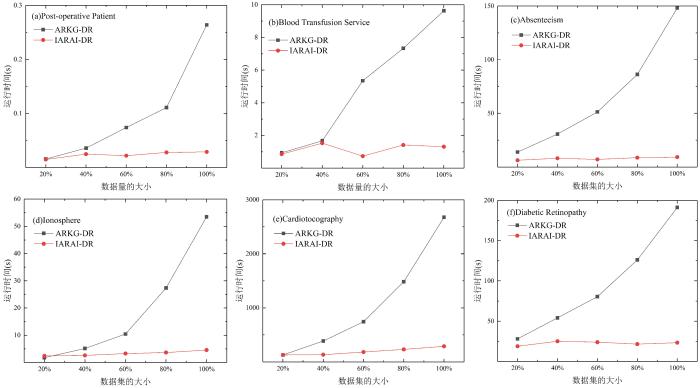
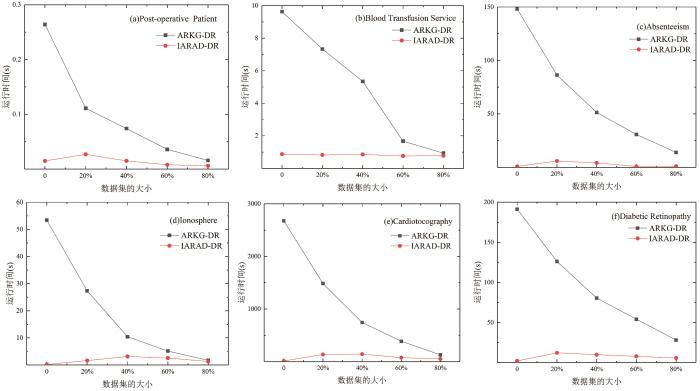
When attribute set in the ordered decision information system is constantly changing,existing static algorithms that have been studied based on dominance relationship cannot efficiently update its attribute reduction. To this end,this paper proposes two new incremental attribute reduction algorithms from the perspective of both attribute addition and attribute deletion,respectively,using the attribute importance of knowledge granularity representations as the heuristic information. Firstly,the relevant basic knowledge of the dominance rough set method are introduced,and the attribute reduction algorithm based on knowledge granularity in the classical rough set is extended to the dominance rough set method to obtain an attribute reduction algorithm that can handle ordered decision information systems; Then,the definition of the inferior attribute matrix is given,and the incremental update mechanism of attribute reduction during attribute addition and deletion is analyzed by the matrix calculation method of knowledge granularity. From there,two incremental attribute reduction algorithms are further designed; Finally,time complexity of the three algorithms is analyzed and compared,and six different UCI datasets are selected to test the algorithm performance. The test results show that the algorithm proposed in this paper is more efficient than the static attribute reduction algorithm.
Keywords:ordered decision information system
;
knowledge granularity
;
the dominance rough set approach
;
inferior attribute matrix
;
incremental attribute reduction
Zhang Yizong, Wang Lei, Xu Yang. Incremental attribute reduction algorithm for ordered decision information systems with the change of attribute set. Journal of nanjing University[J], 2023, 59(5): 813-822 doi:10.13232/j.cnki.jnju.2023.05.009
经典粗糙集理论以等价关系对论域进行划分形成的等价类为研究基础,但其不适合处理属性值具有偏序关系的数据.为此,Greco et al[7-8]基于优势关系对经典粗糙集方法进行推广,提出优势粗糙集方法(Dominance Rough Set Approach,DRSA),而DRSA近似集的运算对象是决策类的上(下)向联合集,由此给出了上(下)向联合集的上、下近似集的定义.此后,众多学者对优势粗糙集方法进行了一系列的研究和推广.李艳等[9]深入研究了不协调目标信息系统的属性约简,在优势关系上给出了浓缩布尔矩阵的概念来计算属性约简.Li et al[10]针对区间值序信息系统提出一种基于优势关系的特征选择(属性约简)方法.Du and Hu[11]针对一致不完备序信息系统的属性约简问题,基于可分辨矩阵和可分辨函数,提出一种计算所有属性约简的方法.Yang et al[12]将优势关系拓展到区间值决策系统上,提出基于α⁃优势的粗糙集模型,并给出了上、下近似的计算方法.Zhang and Yang[13]将α⁃优势推广至集值信息系统,结合合取和析取给出了两种新的优势关系,并基于此提出集值决策表的特征选择(属性约简)方法.以上研究均是对优势粗糙集模型的扩展和推广,可解决不同类型数据集的属性约简问题.
然而,实际生活中数据的属性集会发生动态变化,相应的属性约简结果也随之变化,使用非增量属性约简算法对属性集动态变化的数据进行属性约简是不可行的,因为这会重复计算未变动前的部分属性,增加计算成本,在大数据集上甚至无法满足其属性约简的效率要求.因而,众多学者针对属性集动态变化的序决策信息系统展开了一系列研究,如Luo et al[14]将知识粒度引入序集值决策信息系统,对系统中属性增加和删除的情况,基于矩阵提出一种增量更新近似集的方法.Wang et al[15]针对有序信息系统多维变化的动态更新近似集的问题,基于矩阵提出一种可以在对象和属性同时增加的情况下有效更新的增量方法.Huang et al[16]将近似集的布尔矩阵表示方法引入动态模糊信息系统,考虑属性和对象增加的情况,通过更新布尔矩阵达到动态更新近似集的目的.Sang et al[17]将条件熵引入序决策信息系统,在系统中添加或删除多个对象时,基于矩阵提出两种增量属性约简算法,还针对动态变化的有序模糊信息系统的特征选择(属性约简)问题,提出一种新的模糊优势邻域粗糙集模型,并基于条件熵提出一种启发式增量特征选择(属性约简)算法[18].上述研究推动了序决策信息系统近似集的动态更新在众多领域的发展,但是,针对属性集动态变化的序决策信息系统,基于矩阵计算其属性约简的增量算法并不常见.
A new rough set approach to multicriteria and multiattribute classification
1
1998
... 经典粗糙集理论以等价关系对论域进行划分形成的等价类为研究基础,但其不适合处理属性值具有偏序关系的数据.为此,Greco et al[7-8]基于优势关系对经典粗糙集方法进行推广,提出优势粗糙集方法(Dominance Rough Set Approach,DRSA),而DRSA近似集的运算对象是决策类的上(下)向联合集,由此给出了上(下)向联合集的上、下近似集的定义.此后,众多学者对优势粗糙集方法进行了一系列的研究和推广.李艳等[9]深入研究了不协调目标信息系统的属性约简,在优势关系上给出了浓缩布尔矩阵的概念来计算属性约简.Li et al[10]针对区间值序信息系统提出一种基于优势关系的特征选择(属性约简)方法.Du and Hu[11]针对一致不完备序信息系统的属性约简问题,基于可分辨矩阵和可分辨函数,提出一种计算所有属性约简的方法.Yang et al[12]将优势关系拓展到区间值决策系统上,提出基于α⁃优势的粗糙集模型,并给出了上、下近似的计算方法.Zhang and Yang[13]将α⁃优势推广至集值信息系统,结合合取和析取给出了两种新的优势关系,并基于此提出集值决策表的特征选择(属性约简)方法.以上研究均是对优势粗糙集模型的扩展和推广,可解决不同类型数据集的属性约简问题. ...
Rough approximation of a preference relation by dominance relations
1
1999
... 经典粗糙集理论以等价关系对论域进行划分形成的等价类为研究基础,但其不适合处理属性值具有偏序关系的数据.为此,Greco et al[7-8]基于优势关系对经典粗糙集方法进行推广,提出优势粗糙集方法(Dominance Rough Set Approach,DRSA),而DRSA近似集的运算对象是决策类的上(下)向联合集,由此给出了上(下)向联合集的上、下近似集的定义.此后,众多学者对优势粗糙集方法进行了一系列的研究和推广.李艳等[9]深入研究了不协调目标信息系统的属性约简,在优势关系上给出了浓缩布尔矩阵的概念来计算属性约简.Li et al[10]针对区间值序信息系统提出一种基于优势关系的特征选择(属性约简)方法.Du and Hu[11]针对一致不完备序信息系统的属性约简问题,基于可分辨矩阵和可分辨函数,提出一种计算所有属性约简的方法.Yang et al[12]将优势关系拓展到区间值决策系统上,提出基于α⁃优势的粗糙集模型,并给出了上、下近似的计算方法.Zhang and Yang[13]将α⁃优势推广至集值信息系统,结合合取和析取给出了两种新的优势关系,并基于此提出集值决策表的特征选择(属性约简)方法.以上研究均是对优势粗糙集模型的扩展和推广,可解决不同类型数据集的属性约简问题. ...
优势关系下基于浓缩布尔矩阵的属性约简方法
1
2018
... 经典粗糙集理论以等价关系对论域进行划分形成的等价类为研究基础,但其不适合处理属性值具有偏序关系的数据.为此,Greco et al[7-8]基于优势关系对经典粗糙集方法进行推广,提出优势粗糙集方法(Dominance Rough Set Approach,DRSA),而DRSA近似集的运算对象是决策类的上(下)向联合集,由此给出了上(下)向联合集的上、下近似集的定义.此后,众多学者对优势粗糙集方法进行了一系列的研究和推广.李艳等[9]深入研究了不协调目标信息系统的属性约简,在优势关系上给出了浓缩布尔矩阵的概念来计算属性约简.Li et al[10]针对区间值序信息系统提出一种基于优势关系的特征选择(属性约简)方法.Du and Hu[11]针对一致不完备序信息系统的属性约简问题,基于可分辨矩阵和可分辨函数,提出一种计算所有属性约简的方法.Yang et al[12]将优势关系拓展到区间值决策系统上,提出基于α⁃优势的粗糙集模型,并给出了上、下近似的计算方法.Zhang and Yang[13]将α⁃优势推广至集值信息系统,结合合取和析取给出了两种新的优势关系,并基于此提出集值决策表的特征选择(属性约简)方法.以上研究均是对优势粗糙集模型的扩展和推广,可解决不同类型数据集的属性约简问题. ...
Attribute reduction based on concentration Boolean matrix under dominance relations
1
2018
... 经典粗糙集理论以等价关系对论域进行划分形成的等价类为研究基础,但其不适合处理属性值具有偏序关系的数据.为此,Greco et al[7-8]基于优势关系对经典粗糙集方法进行推广,提出优势粗糙集方法(Dominance Rough Set Approach,DRSA),而DRSA近似集的运算对象是决策类的上(下)向联合集,由此给出了上(下)向联合集的上、下近似集的定义.此后,众多学者对优势粗糙集方法进行了一系列的研究和推广.李艳等[9]深入研究了不协调目标信息系统的属性约简,在优势关系上给出了浓缩布尔矩阵的概念来计算属性约简.Li et al[10]针对区间值序信息系统提出一种基于优势关系的特征选择(属性约简)方法.Du and Hu[11]针对一致不完备序信息系统的属性约简问题,基于可分辨矩阵和可分辨函数,提出一种计算所有属性约简的方法.Yang et al[12]将优势关系拓展到区间值决策系统上,提出基于α⁃优势的粗糙集模型,并给出了上、下近似的计算方法.Zhang and Yang[13]将α⁃优势推广至集值信息系统,结合合取和析取给出了两种新的优势关系,并基于此提出集值决策表的特征选择(属性约简)方法.以上研究均是对优势粗糙集模型的扩展和推广,可解决不同类型数据集的属性约简问题. ...
Interval dominance?based feature selection for interval?valued ordered data
1
2022
... 经典粗糙集理论以等价关系对论域进行划分形成的等价类为研究基础,但其不适合处理属性值具有偏序关系的数据.为此,Greco et al[7-8]基于优势关系对经典粗糙集方法进行推广,提出优势粗糙集方法(Dominance Rough Set Approach,DRSA),而DRSA近似集的运算对象是决策类的上(下)向联合集,由此给出了上(下)向联合集的上、下近似集的定义.此后,众多学者对优势粗糙集方法进行了一系列的研究和推广.李艳等[9]深入研究了不协调目标信息系统的属性约简,在优势关系上给出了浓缩布尔矩阵的概念来计算属性约简.Li et al[10]针对区间值序信息系统提出一种基于优势关系的特征选择(属性约简)方法.Du and Hu[11]针对一致不完备序信息系统的属性约简问题,基于可分辨矩阵和可分辨函数,提出一种计算所有属性约简的方法.Yang et al[12]将优势关系拓展到区间值决策系统上,提出基于α⁃优势的粗糙集模型,并给出了上、下近似的计算方法.Zhang and Yang[13]将α⁃优势推广至集值信息系统,结合合取和析取给出了两种新的优势关系,并基于此提出集值决策表的特征选择(属性约简)方法.以上研究均是对优势粗糙集模型的扩展和推广,可解决不同类型数据集的属性约简问题. ...
Dominance?based rough set approach to incomplete ordered information systems
1
2016
... 经典粗糙集理论以等价关系对论域进行划分形成的等价类为研究基础,但其不适合处理属性值具有偏序关系的数据.为此,Greco et al[7-8]基于优势关系对经典粗糙集方法进行推广,提出优势粗糙集方法(Dominance Rough Set Approach,DRSA),而DRSA近似集的运算对象是决策类的上(下)向联合集,由此给出了上(下)向联合集的上、下近似集的定义.此后,众多学者对优势粗糙集方法进行了一系列的研究和推广.李艳等[9]深入研究了不协调目标信息系统的属性约简,在优势关系上给出了浓缩布尔矩阵的概念来计算属性约简.Li et al[10]针对区间值序信息系统提出一种基于优势关系的特征选择(属性约简)方法.Du and Hu[11]针对一致不完备序信息系统的属性约简问题,基于可分辨矩阵和可分辨函数,提出一种计算所有属性约简的方法.Yang et al[12]将优势关系拓展到区间值决策系统上,提出基于α⁃优势的粗糙集模型,并给出了上、下近似的计算方法.Zhang and Yang[13]将α⁃优势推广至集值信息系统,结合合取和析取给出了两种新的优势关系,并基于此提出集值决策表的特征选择(属性约简)方法.以上研究均是对优势粗糙集模型的扩展和推广,可解决不同类型数据集的属性约简问题. ...
α?dominance relation and rough sets in interval?valued information systems
1
2015
... 经典粗糙集理论以等价关系对论域进行划分形成的等价类为研究基础,但其不适合处理属性值具有偏序关系的数据.为此,Greco et al[7-8]基于优势关系对经典粗糙集方法进行推广,提出优势粗糙集方法(Dominance Rough Set Approach,DRSA),而DRSA近似集的运算对象是决策类的上(下)向联合集,由此给出了上(下)向联合集的上、下近似集的定义.此后,众多学者对优势粗糙集方法进行了一系列的研究和推广.李艳等[9]深入研究了不协调目标信息系统的属性约简,在优势关系上给出了浓缩布尔矩阵的概念来计算属性约简.Li et al[10]针对区间值序信息系统提出一种基于优势关系的特征选择(属性约简)方法.Du and Hu[11]针对一致不完备序信息系统的属性约简问题,基于可分辨矩阵和可分辨函数,提出一种计算所有属性约简的方法.Yang et al[12]将优势关系拓展到区间值决策系统上,提出基于α⁃优势的粗糙集模型,并给出了上、下近似的计算方法.Zhang and Yang[13]将α⁃优势推广至集值信息系统,结合合取和析取给出了两种新的优势关系,并基于此提出集值决策表的特征选择(属性约简)方法.以上研究均是对优势粗糙集模型的扩展和推广,可解决不同类型数据集的属性约简问题. ...
Feature selection and approximate reasoning of large?scale set?valued decision tables based on α?dominance?based quanti?tative rough sets
1
2017
... 经典粗糙集理论以等价关系对论域进行划分形成的等价类为研究基础,但其不适合处理属性值具有偏序关系的数据.为此,Greco et al[7-8]基于优势关系对经典粗糙集方法进行推广,提出优势粗糙集方法(Dominance Rough Set Approach,DRSA),而DRSA近似集的运算对象是决策类的上(下)向联合集,由此给出了上(下)向联合集的上、下近似集的定义.此后,众多学者对优势粗糙集方法进行了一系列的研究和推广.李艳等[9]深入研究了不协调目标信息系统的属性约简,在优势关系上给出了浓缩布尔矩阵的概念来计算属性约简.Li et al[10]针对区间值序信息系统提出一种基于优势关系的特征选择(属性约简)方法.Du and Hu[11]针对一致不完备序信息系统的属性约简问题,基于可分辨矩阵和可分辨函数,提出一种计算所有属性约简的方法.Yang et al[12]将优势关系拓展到区间值决策系统上,提出基于α⁃优势的粗糙集模型,并给出了上、下近似的计算方法.Zhang and Yang[13]将α⁃优势推广至集值信息系统,结合合取和析取给出了两种新的优势关系,并基于此提出集值决策表的特征选择(属性约简)方法.以上研究均是对优势粗糙集模型的扩展和推广,可解决不同类型数据集的属性约简问题. ...
Fast algorithms for computing rough approximations in set?valued decision systems while updating criteria values
1
2015
... 然而,实际生活中数据的属性集会发生动态变化,相应的属性约简结果也随之变化,使用非增量属性约简算法对属性集动态变化的数据进行属性约简是不可行的,因为这会重复计算未变动前的部分属性,增加计算成本,在大数据集上甚至无法满足其属性约简的效率要求.因而,众多学者针对属性集动态变化的序决策信息系统展开了一系列研究,如Luo et al[14]将知识粒度引入序集值决策信息系统,对系统中属性增加和删除的情况,基于矩阵提出一种增量更新近似集的方法.Wang et al[15]针对有序信息系统多维变化的动态更新近似集的问题,基于矩阵提出一种可以在对象和属性同时增加的情况下有效更新的增量方法.Huang et al[16]将近似集的布尔矩阵表示方法引入动态模糊信息系统,考虑属性和对象增加的情况,通过更新布尔矩阵达到动态更新近似集的目的.Sang et al[17]将条件熵引入序决策信息系统,在系统中添加或删除多个对象时,基于矩阵提出两种增量属性约简算法,还针对动态变化的有序模糊信息系统的特征选择(属性约简)问题,提出一种新的模糊优势邻域粗糙集模型,并基于条件熵提出一种启发式增量特征选择(属性约简)算法[18].上述研究推动了序决策信息系统近似集的动态更新在众多领域的发展,但是,针对属性集动态变化的序决策信息系统,基于矩阵计算其属性约简的增量算法并不常见. ...
Efficient updating rough approximations with multi?dimensional variation of ordered data
1
2016
... 然而,实际生活中数据的属性集会发生动态变化,相应的属性约简结果也随之变化,使用非增量属性约简算法对属性集动态变化的数据进行属性约简是不可行的,因为这会重复计算未变动前的部分属性,增加计算成本,在大数据集上甚至无法满足其属性约简的效率要求.因而,众多学者针对属性集动态变化的序决策信息系统展开了一系列研究,如Luo et al[14]将知识粒度引入序集值决策信息系统,对系统中属性增加和删除的情况,基于矩阵提出一种增量更新近似集的方法.Wang et al[15]针对有序信息系统多维变化的动态更新近似集的问题,基于矩阵提出一种可以在对象和属性同时增加的情况下有效更新的增量方法.Huang et al[16]将近似集的布尔矩阵表示方法引入动态模糊信息系统,考虑属性和对象增加的情况,通过更新布尔矩阵达到动态更新近似集的目的.Sang et al[17]将条件熵引入序决策信息系统,在系统中添加或删除多个对象时,基于矩阵提出两种增量属性约简算法,还针对动态变化的有序模糊信息系统的特征选择(属性约简)问题,提出一种新的模糊优势邻域粗糙集模型,并基于条件熵提出一种启发式增量特征选择(属性约简)算法[18].上述研究推动了序决策信息系统近似集的动态更新在众多领域的发展,但是,针对属性集动态变化的序决策信息系统,基于矩阵计算其属性约简的增量算法并不常见. ...
Matrix?based dynamic updating rough fuzzy approximations for data mining
1
2017
... 然而,实际生活中数据的属性集会发生动态变化,相应的属性约简结果也随之变化,使用非增量属性约简算法对属性集动态变化的数据进行属性约简是不可行的,因为这会重复计算未变动前的部分属性,增加计算成本,在大数据集上甚至无法满足其属性约简的效率要求.因而,众多学者针对属性集动态变化的序决策信息系统展开了一系列研究,如Luo et al[14]将知识粒度引入序集值决策信息系统,对系统中属性增加和删除的情况,基于矩阵提出一种增量更新近似集的方法.Wang et al[15]针对有序信息系统多维变化的动态更新近似集的问题,基于矩阵提出一种可以在对象和属性同时增加的情况下有效更新的增量方法.Huang et al[16]将近似集的布尔矩阵表示方法引入动态模糊信息系统,考虑属性和对象增加的情况,通过更新布尔矩阵达到动态更新近似集的目的.Sang et al[17]将条件熵引入序决策信息系统,在系统中添加或删除多个对象时,基于矩阵提出两种增量属性约简算法,还针对动态变化的有序模糊信息系统的特征选择(属性约简)问题,提出一种新的模糊优势邻域粗糙集模型,并基于条件熵提出一种启发式增量特征选择(属性约简)算法[18].上述研究推动了序决策信息系统近似集的动态更新在众多领域的发展,但是,针对属性集动态变化的序决策信息系统,基于矩阵计算其属性约简的增量算法并不常见. ...
Incremental attribute reduction approaches for ordered data with time?evolving objects
1
2021
... 然而,实际生活中数据的属性集会发生动态变化,相应的属性约简结果也随之变化,使用非增量属性约简算法对属性集动态变化的数据进行属性约简是不可行的,因为这会重复计算未变动前的部分属性,增加计算成本,在大数据集上甚至无法满足其属性约简的效率要求.因而,众多学者针对属性集动态变化的序决策信息系统展开了一系列研究,如Luo et al[14]将知识粒度引入序集值决策信息系统,对系统中属性增加和删除的情况,基于矩阵提出一种增量更新近似集的方法.Wang et al[15]针对有序信息系统多维变化的动态更新近似集的问题,基于矩阵提出一种可以在对象和属性同时增加的情况下有效更新的增量方法.Huang et al[16]将近似集的布尔矩阵表示方法引入动态模糊信息系统,考虑属性和对象增加的情况,通过更新布尔矩阵达到动态更新近似集的目的.Sang et al[17]将条件熵引入序决策信息系统,在系统中添加或删除多个对象时,基于矩阵提出两种增量属性约简算法,还针对动态变化的有序模糊信息系统的特征选择(属性约简)问题,提出一种新的模糊优势邻域粗糙集模型,并基于条件熵提出一种启发式增量特征选择(属性约简)算法[18].上述研究推动了序决策信息系统近似集的动态更新在众多领域的发展,但是,针对属性集动态变化的序决策信息系统,基于矩阵计算其属性约简的增量算法并不常见. ...
Incremental feature selection using a conditional entropy based on fuzzy dominance neighborhood rough sets
1
2022
... 然而,实际生活中数据的属性集会发生动态变化,相应的属性约简结果也随之变化,使用非增量属性约简算法对属性集动态变化的数据进行属性约简是不可行的,因为这会重复计算未变动前的部分属性,增加计算成本,在大数据集上甚至无法满足其属性约简的效率要求.因而,众多学者针对属性集动态变化的序决策信息系统展开了一系列研究,如Luo et al[14]将知识粒度引入序集值决策信息系统,对系统中属性增加和删除的情况,基于矩阵提出一种增量更新近似集的方法.Wang et al[15]针对有序信息系统多维变化的动态更新近似集的问题,基于矩阵提出一种可以在对象和属性同时增加的情况下有效更新的增量方法.Huang et al[16]将近似集的布尔矩阵表示方法引入动态模糊信息系统,考虑属性和对象增加的情况,通过更新布尔矩阵达到动态更新近似集的目的.Sang et al[17]将条件熵引入序决策信息系统,在系统中添加或删除多个对象时,基于矩阵提出两种增量属性约简算法,还针对动态变化的有序模糊信息系统的特征选择(属性约简)问题,提出一种新的模糊优势邻域粗糙集模型,并基于条件熵提出一种启发式增量特征选择(属性约简)算法[18].上述研究推动了序决策信息系统近似集的动态更新在众多领域的发展,但是,针对属性集动态变化的序决策信息系统,基于矩阵计算其属性约简的增量算法并不常见. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}