With the continuous development of the Internet and recommendation system,the object of recommendation service expands from a single user to group members. How to obtain and integrate the preferences of group members and improve the effect of group recommendation has become a hot issue in the field of recommendation research. This paper makes full use of the user⁃provided multi⁃attribute rating matrix,and a group recommendation algorithm combining implicit trust and attribute preference is proposed. Firstly,the direct implicit trust between users is calculated based on the number of items shared by users and the similarity of multi⁃attribute ratings. In order to reduce the sparsity of data,the trust transfer mechanism is used to obtain indirect trust between users. Then,the user's attribute preference is mined by calculating the distance between each attribute rating and the overall rating. On this basis,the attention mechanism is used to learn the weight of users in the group,and user preferences are aggregated into group preferences. Then the deep learning framework is combined to predict candidate projects and generate the final recommendation list. Finally,experiments conducted on four datasets to verify the effectiveness and feasibility of the proposed algorithm verify its significantly superior to the compared algorithm in accuracy,nDCG and other evaluation indicators.
Bian Jichao, Pang Jifang, Song Peng. Group recommendation algorithm combining implicit trust and attribute preference. Journal of nanjing University[J], 2023, 59(5): 803-812 doi:10.13232/j.cnki.jnju.2023.05.008
为了更加全面、精准地捕获用户偏好,部分学者结合多属性评分矩阵对推荐算法进行了研究.Zhu et al[7]基于多属性评分信息,提出一种面向群组的高效提升算法(Efficient Promotion Algorithm in Recommendation,PromoRec).Biswas and Liu[8]基于多属性评分对用户进行画像,并使用线性回归算法学习用户对各个属性的偏好程度.Papamit⁃siou and Economides[9]提出一种基于多属性评分的协同过滤算法,能发现偏好相似的邻居并通过相似邻居完成推荐.朱文强等[10]基于多属性评分建立相似度计算公式,通过寻找相似用户来预测用户在每个属性上的评分,再根据预测评分对用户进行推荐.覃正和李岱峰[11]建立了一种面向群组的多属性推荐模型,通过模拟退火的方法学习各成员在各属性上的偏好权重,聚合组内所有成员的偏好.Nilashi et al[12]在使用决策树对多属性评分进行处理的基础上,提出一种多属性协同过滤推荐算法.Majumder et al[13]发展了一种基于多属性评分的矩阵分解方法来提高推荐的准确率.但上述算法仅仅分析了用户在各个属性上的偏好,本文充分挖掘用户在不同属性上的评分与总体评分之间的关系,对多属性评分进行更加全面的分析和利用,提高群组推荐效果.
1.2 融合信任关系的推荐算法研究现状
随着信任网络的出现和发展,信任关系逐渐被引入推荐系统.Da'u et al[14]提出一种根据信任网络的出入度来重构信任度的混合推荐算法.Guo et al[15]提出一种融合项目流行度和用户信任关系的矩阵分解推荐算法.Chen et al[16]结合信任关系和协同过滤建立了一种随机游走模型来提高推荐性能.Victor et al[17]将用户交互信息作为信任关系,提出一种社交推荐(Social Recommendation,SoRec)方法.由于隐私问题,获取用户之间的信任分数通常很困难,当用户之间的信任关系无法直接获知时,可以通过分析用户行为、社交网络等隐含信息来进行推断.近年来,越来越多的研究开始探索隐性信任的提取方法.刘辉等[18]利用用户之间的相似度来计算信任度,提出一种整合用户相似度、地理位置和信任关系的混合推荐算法.张槟淇等[19]根据用户的影响力来计算用户信任度,提出一种融合信任关系的群组推荐算法.上述算法虽然能得到用户之间的信任关系,但缺少对用户间信任程度的客观度量.本文基于多属性评分来挖掘用户之间的隐式信任关系,结合用户在共同评分项目上的数量和多属性评分的相似度两个方面来获得用户之间的信任程度,能更好地刻画用户信任关系,获得更精准的群组偏好.
1.3 基于深度学习的推荐算法研究现状
基于深度学习的推荐算法大多是将用户和项目嵌入神经网络,从用户、群组和项目之间的交互数据中学习用户偏好.Choudhary et al[20]通过群组和用户组成的双层注意网络来学习群组成员权重.Cao et al[21]利用注意力机制,动态地调整用户在不同群组中的影响力,较好地解释了群组偏好的集结过程.Wang et al[22]利用神经注意网络,以动态方式来学习成员之间的相对影响,利用组内的成员偏好来表示群组偏好.He et al[24]利用自注意力机制来挖掘用户与项目间的潜在信息,进而学习得到群组的潜在偏好.Jia et al[25]提出一种由成员级偏好网络和组级偏好网络构成的双通道超图卷积网络.深度学习技术与群组推荐算法的结合有效地促进了群组偏好融合研究,但现有研究大多根据评分来获取用户与项目之间的交互,没有充分考虑用户之间的关系,导致获取的群组偏好不够全面,影响推荐效果.本文在利用神经网络学习用户⁃项目交互的基础上,引入用户之间的信任关系,能获得更全面的群组偏好.
Matrix factorization and regression⁃based approach for multi⁃criteria recommender system
∥Proceedings of the International Conference on Information & Commu⁃nication Technology for Intelligent Systems. Ahmedabad,India:Springer Cham,2017:103-110.
∥Proceedings of the 26th International Conference on World Wide Web. Perth,Australia:International World Wide Web Conferences Steering Committee,2017:173-182.
∥Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY,USA:Association for Computing Machinery,2014:163-172.
... 为了更加全面、精准地捕获用户偏好,部分学者结合多属性评分矩阵对推荐算法进行了研究.Zhu et al[7]基于多属性评分信息,提出一种面向群组的高效提升算法(Efficient Promotion Algorithm in Recommendation,PromoRec).Biswas and Liu[8]基于多属性评分对用户进行画像,并使用线性回归算法学习用户对各个属性的偏好程度.Papamit⁃siou and Economides[9]提出一种基于多属性评分的协同过滤算法,能发现偏好相似的邻居并通过相似邻居完成推荐.朱文强等[10]基于多属性评分建立相似度计算公式,通过寻找相似用户来预测用户在每个属性上的评分,再根据预测评分对用户进行推荐.覃正和李岱峰[11]建立了一种面向群组的多属性推荐模型,通过模拟退火的方法学习各成员在各属性上的偏好权重,聚合组内所有成员的偏好.Nilashi et al[12]在使用决策树对多属性评分进行处理的基础上,提出一种多属性协同过滤推荐算法.Majumder et al[13]发展了一种基于多属性评分的矩阵分解方法来提高推荐的准确率.但上述算法仅仅分析了用户在各个属性上的偏好,本文充分挖掘用户在不同属性上的评分与总体评分之间的关系,对多属性评分进行更加全面的分析和利用,提高群组推荐效果. ...
A hybrid recommender system for recommending smartphones to prospective customers
1
2022
... 为了更加全面、精准地捕获用户偏好,部分学者结合多属性评分矩阵对推荐算法进行了研究.Zhu et al[7]基于多属性评分信息,提出一种面向群组的高效提升算法(Efficient Promotion Algorithm in Recommendation,PromoRec).Biswas and Liu[8]基于多属性评分对用户进行画像,并使用线性回归算法学习用户对各个属性的偏好程度.Papamit⁃siou and Economides[9]提出一种基于多属性评分的协同过滤算法,能发现偏好相似的邻居并通过相似邻居完成推荐.朱文强等[10]基于多属性评分建立相似度计算公式,通过寻找相似用户来预测用户在每个属性上的评分,再根据预测评分对用户进行推荐.覃正和李岱峰[11]建立了一种面向群组的多属性推荐模型,通过模拟退火的方法学习各成员在各属性上的偏好权重,聚合组内所有成员的偏好.Nilashi et al[12]在使用决策树对多属性评分进行处理的基础上,提出一种多属性协同过滤推荐算法.Majumder et al[13]发展了一种基于多属性评分的矩阵分解方法来提高推荐的准确率.但上述算法仅仅分析了用户在各个属性上的偏好,本文充分挖掘用户在不同属性上的评分与总体评分之间的关系,对多属性评分进行更加全面的分析和利用,提高群组推荐效果. ...
Recommendation of educational resources to groups:A game?theoretic approach
1
2018
... 为了更加全面、精准地捕获用户偏好,部分学者结合多属性评分矩阵对推荐算法进行了研究.Zhu et al[7]基于多属性评分信息,提出一种面向群组的高效提升算法(Efficient Promotion Algorithm in Recommendation,PromoRec).Biswas and Liu[8]基于多属性评分对用户进行画像,并使用线性回归算法学习用户对各个属性的偏好程度.Papamit⁃siou and Economides[9]提出一种基于多属性评分的协同过滤算法,能发现偏好相似的邻居并通过相似邻居完成推荐.朱文强等[10]基于多属性评分建立相似度计算公式,通过寻找相似用户来预测用户在每个属性上的评分,再根据预测评分对用户进行推荐.覃正和李岱峰[11]建立了一种面向群组的多属性推荐模型,通过模拟退火的方法学习各成员在各属性上的偏好权重,聚合组内所有成员的偏好.Nilashi et al[12]在使用决策树对多属性评分进行处理的基础上,提出一种多属性协同过滤推荐算法.Majumder et al[13]发展了一种基于多属性评分的矩阵分解方法来提高推荐的准确率.但上述算法仅仅分析了用户在各个属性上的偏好,本文充分挖掘用户在不同属性上的评分与总体评分之间的关系,对多属性评分进行更加全面的分析和利用,提高群组推荐效果. ...
融合社交信任的多属性元路径好友推荐方法
1
2020
... 为了更加全面、精准地捕获用户偏好,部分学者结合多属性评分矩阵对推荐算法进行了研究.Zhu et al[7]基于多属性评分信息,提出一种面向群组的高效提升算法(Efficient Promotion Algorithm in Recommendation,PromoRec).Biswas and Liu[8]基于多属性评分对用户进行画像,并使用线性回归算法学习用户对各个属性的偏好程度.Papamit⁃siou and Economides[9]提出一种基于多属性评分的协同过滤算法,能发现偏好相似的邻居并通过相似邻居完成推荐.朱文强等[10]基于多属性评分建立相似度计算公式,通过寻找相似用户来预测用户在每个属性上的评分,再根据预测评分对用户进行推荐.覃正和李岱峰[11]建立了一种面向群组的多属性推荐模型,通过模拟退火的方法学习各成员在各属性上的偏好权重,聚合组内所有成员的偏好.Nilashi et al[12]在使用决策树对多属性评分进行处理的基础上,提出一种多属性协同过滤推荐算法.Majumder et al[13]发展了一种基于多属性评分的矩阵分解方法来提高推荐的准确率.但上述算法仅仅分析了用户在各个属性上的偏好,本文充分挖掘用户在不同属性上的评分与总体评分之间的关系,对多属性评分进行更加全面的分析和利用,提高群组推荐效果. ...
Friend recommen?dation method based on multi?attribute meta?path with social trust
1
2020
... 为了更加全面、精准地捕获用户偏好,部分学者结合多属性评分矩阵对推荐算法进行了研究.Zhu et al[7]基于多属性评分信息,提出一种面向群组的高效提升算法(Efficient Promotion Algorithm in Recommendation,PromoRec).Biswas and Liu[8]基于多属性评分对用户进行画像,并使用线性回归算法学习用户对各个属性的偏好程度.Papamit⁃siou and Economides[9]提出一种基于多属性评分的协同过滤算法,能发现偏好相似的邻居并通过相似邻居完成推荐.朱文强等[10]基于多属性评分建立相似度计算公式,通过寻找相似用户来预测用户在每个属性上的评分,再根据预测评分对用户进行推荐.覃正和李岱峰[11]建立了一种面向群组的多属性推荐模型,通过模拟退火的方法学习各成员在各属性上的偏好权重,聚合组内所有成员的偏好.Nilashi et al[12]在使用决策树对多属性评分进行处理的基础上,提出一种多属性协同过滤推荐算法.Majumder et al[13]发展了一种基于多属性评分的矩阵分解方法来提高推荐的准确率.但上述算法仅仅分析了用户在各个属性上的偏好,本文充分挖掘用户在不同属性上的评分与总体评分之间的关系,对多属性评分进行更加全面的分析和利用,提高群组推荐效果. ...
一种基于资源多属性分类的群组推荐模型
1
2010
... 为了更加全面、精准地捕获用户偏好,部分学者结合多属性评分矩阵对推荐算法进行了研究.Zhu et al[7]基于多属性评分信息,提出一种面向群组的高效提升算法(Efficient Promotion Algorithm in Recommendation,PromoRec).Biswas and Liu[8]基于多属性评分对用户进行画像,并使用线性回归算法学习用户对各个属性的偏好程度.Papamit⁃siou and Economides[9]提出一种基于多属性评分的协同过滤算法,能发现偏好相似的邻居并通过相似邻居完成推荐.朱文强等[10]基于多属性评分建立相似度计算公式,通过寻找相似用户来预测用户在每个属性上的评分,再根据预测评分对用户进行推荐.覃正和李岱峰[11]建立了一种面向群组的多属性推荐模型,通过模拟退火的方法学习各成员在各属性上的偏好权重,聚合组内所有成员的偏好.Nilashi et al[12]在使用决策树对多属性评分进行处理的基础上,提出一种多属性协同过滤推荐算法.Majumder et al[13]发展了一种基于多属性评分的矩阵分解方法来提高推荐的准确率.但上述算法仅仅分析了用户在各个属性上的偏好,本文充分挖掘用户在不同属性上的评分与总体评分之间的关系,对多属性评分进行更加全面的分析和利用,提高群组推荐效果. ...
A Group recommendation model based on multi?attribute classification of resources
1
2010
... 为了更加全面、精准地捕获用户偏好,部分学者结合多属性评分矩阵对推荐算法进行了研究.Zhu et al[7]基于多属性评分信息,提出一种面向群组的高效提升算法(Efficient Promotion Algorithm in Recommendation,PromoRec).Biswas and Liu[8]基于多属性评分对用户进行画像,并使用线性回归算法学习用户对各个属性的偏好程度.Papamit⁃siou and Economides[9]提出一种基于多属性评分的协同过滤算法,能发现偏好相似的邻居并通过相似邻居完成推荐.朱文强等[10]基于多属性评分建立相似度计算公式,通过寻找相似用户来预测用户在每个属性上的评分,再根据预测评分对用户进行推荐.覃正和李岱峰[11]建立了一种面向群组的多属性推荐模型,通过模拟退火的方法学习各成员在各属性上的偏好权重,聚合组内所有成员的偏好.Nilashi et al[12]在使用决策树对多属性评分进行处理的基础上,提出一种多属性协同过滤推荐算法.Majumder et al[13]发展了一种基于多属性评分的矩阵分解方法来提高推荐的准确率.但上述算法仅仅分析了用户在各个属性上的偏好,本文充分挖掘用户在不同属性上的评分与总体评分之间的关系,对多属性评分进行更加全面的分析和利用,提高群组推荐效果. ...
A Multi?criteria collaborative filtering recommender system using clustering and regression techniques
1
2016
... 为了更加全面、精准地捕获用户偏好,部分学者结合多属性评分矩阵对推荐算法进行了研究.Zhu et al[7]基于多属性评分信息,提出一种面向群组的高效提升算法(Efficient Promotion Algorithm in Recommendation,PromoRec).Biswas and Liu[8]基于多属性评分对用户进行画像,并使用线性回归算法学习用户对各个属性的偏好程度.Papamit⁃siou and Economides[9]提出一种基于多属性评分的协同过滤算法,能发现偏好相似的邻居并通过相似邻居完成推荐.朱文强等[10]基于多属性评分建立相似度计算公式,通过寻找相似用户来预测用户在每个属性上的评分,再根据预测评分对用户进行推荐.覃正和李岱峰[11]建立了一种面向群组的多属性推荐模型,通过模拟退火的方法学习各成员在各属性上的偏好权重,聚合组内所有成员的偏好.Nilashi et al[12]在使用决策树对多属性评分进行处理的基础上,提出一种多属性协同过滤推荐算法.Majumder et al[13]发展了一种基于多属性评分的矩阵分解方法来提高推荐的准确率.但上述算法仅仅分析了用户在各个属性上的偏好,本文充分挖掘用户在不同属性上的评分与总体评分之间的关系,对多属性评分进行更加全面的分析和利用,提高群组推荐效果. ...
Matrix factorization and regression?based approach for multi?criteria recommender system
... 为了更加全面、精准地捕获用户偏好,部分学者结合多属性评分矩阵对推荐算法进行了研究.Zhu et al[7]基于多属性评分信息,提出一种面向群组的高效提升算法(Efficient Promotion Algorithm in Recommendation,PromoRec).Biswas and Liu[8]基于多属性评分对用户进行画像,并使用线性回归算法学习用户对各个属性的偏好程度.Papamit⁃siou and Economides[9]提出一种基于多属性评分的协同过滤算法,能发现偏好相似的邻居并通过相似邻居完成推荐.朱文强等[10]基于多属性评分建立相似度计算公式,通过寻找相似用户来预测用户在每个属性上的评分,再根据预测评分对用户进行推荐.覃正和李岱峰[11]建立了一种面向群组的多属性推荐模型,通过模拟退火的方法学习各成员在各属性上的偏好权重,聚合组内所有成员的偏好.Nilashi et al[12]在使用决策树对多属性评分进行处理的基础上,提出一种多属性协同过滤推荐算法.Majumder et al[13]发展了一种基于多属性评分的矩阵分解方法来提高推荐的准确率.但上述算法仅仅分析了用户在各个属性上的偏好,本文充分挖掘用户在不同属性上的评分与总体评分之间的关系,对多属性评分进行更加全面的分析和利用,提高群组推荐效果. ...
An adaptive deep learning method for item recommendation system
... 随着信任网络的出现和发展,信任关系逐渐被引入推荐系统.Da'u et al[14]提出一种根据信任网络的出入度来重构信任度的混合推荐算法.Guo et al[15]提出一种融合项目流行度和用户信任关系的矩阵分解推荐算法.Chen et al[16]结合信任关系和协同过滤建立了一种随机游走模型来提高推荐性能.Victor et al[17]将用户交互信息作为信任关系,提出一种社交推荐(Social Recommendation,SoRec)方法.由于隐私问题,获取用户之间的信任分数通常很困难,当用户之间的信任关系无法直接获知时,可以通过分析用户行为、社交网络等隐含信息来进行推断.近年来,越来越多的研究开始探索隐性信任的提取方法.刘辉等[18]利用用户之间的相似度来计算信任度,提出一种整合用户相似度、地理位置和信任关系的混合推荐算法.张槟淇等[19]根据用户的影响力来计算用户信任度,提出一种融合信任关系的群组推荐算法.上述算法虽然能得到用户之间的信任关系,但缺少对用户间信任程度的客观度量.本文基于多属性评分来挖掘用户之间的隐式信任关系,结合用户在共同评分项目上的数量和多属性评分的相似度两个方面来获得用户之间的信任程度,能更好地刻画用户信任关系,获得更精准的群组偏好. ...
TrustSVD:Collaborative filtering with both the explicit and implicit influence of user trust and of item ratings
3
2015
... 随着信任网络的出现和发展,信任关系逐渐被引入推荐系统.Da'u et al[14]提出一种根据信任网络的出入度来重构信任度的混合推荐算法.Guo et al[15]提出一种融合项目流行度和用户信任关系的矩阵分解推荐算法.Chen et al[16]结合信任关系和协同过滤建立了一种随机游走模型来提高推荐性能.Victor et al[17]将用户交互信息作为信任关系,提出一种社交推荐(Social Recommendation,SoRec)方法.由于隐私问题,获取用户之间的信任分数通常很困难,当用户之间的信任关系无法直接获知时,可以通过分析用户行为、社交网络等隐含信息来进行推断.近年来,越来越多的研究开始探索隐性信任的提取方法.刘辉等[18]利用用户之间的相似度来计算信任度,提出一种整合用户相似度、地理位置和信任关系的混合推荐算法.张槟淇等[19]根据用户的影响力来计算用户信任度,提出一种融合信任关系的群组推荐算法.上述算法虽然能得到用户之间的信任关系,但缺少对用户间信任程度的客观度量.本文基于多属性评分来挖掘用户之间的隐式信任关系,结合用户在共同评分项目上的数量和多属性评分的相似度两个方面来获得用户之间的信任程度,能更好地刻画用户信任关系,获得更精准的群组偏好. ...
A group recommendation system with consideration of interactions among group members
3
2008
... 随着信任网络的出现和发展,信任关系逐渐被引入推荐系统.Da'u et al[14]提出一种根据信任网络的出入度来重构信任度的混合推荐算法.Guo et al[15]提出一种融合项目流行度和用户信任关系的矩阵分解推荐算法.Chen et al[16]结合信任关系和协同过滤建立了一种随机游走模型来提高推荐性能.Victor et al[17]将用户交互信息作为信任关系,提出一种社交推荐(Social Recommendation,SoRec)方法.由于隐私问题,获取用户之间的信任分数通常很困难,当用户之间的信任关系无法直接获知时,可以通过分析用户行为、社交网络等隐含信息来进行推断.近年来,越来越多的研究开始探索隐性信任的提取方法.刘辉等[18]利用用户之间的相似度来计算信任度,提出一种整合用户相似度、地理位置和信任关系的混合推荐算法.张槟淇等[19]根据用户的影响力来计算用户信任度,提出一种融合信任关系的群组推荐算法.上述算法虽然能得到用户之间的信任关系,但缺少对用户间信任程度的客观度量.本文基于多属性评分来挖掘用户之间的隐式信任关系,结合用户在共同评分项目上的数量和多属性评分的相似度两个方面来获得用户之间的信任程度,能更好地刻画用户信任关系,获得更精准的群组偏好. ...
... 考虑到现实生活中一些用户的评分项目比较少,无法直接计算用户间的信任度,导致得到的直接隐式信任矩阵比较稀疏,为此,使用Victor et al[16]的基于T范数的信任传播方法来计算间接隐式信任度,对直接隐式信任矩阵进行补充,从而获得混合隐式信任矩阵. ...
Practical aggregation operators for gradual trust and distrust
3
2011
... 随着信任网络的出现和发展,信任关系逐渐被引入推荐系统.Da'u et al[14]提出一种根据信任网络的出入度来重构信任度的混合推荐算法.Guo et al[15]提出一种融合项目流行度和用户信任关系的矩阵分解推荐算法.Chen et al[16]结合信任关系和协同过滤建立了一种随机游走模型来提高推荐性能.Victor et al[17]将用户交互信息作为信任关系,提出一种社交推荐(Social Recommendation,SoRec)方法.由于隐私问题,获取用户之间的信任分数通常很困难,当用户之间的信任关系无法直接获知时,可以通过分析用户行为、社交网络等隐含信息来进行推断.近年来,越来越多的研究开始探索隐性信任的提取方法.刘辉等[18]利用用户之间的相似度来计算信任度,提出一种整合用户相似度、地理位置和信任关系的混合推荐算法.张槟淇等[19]根据用户的影响力来计算用户信任度,提出一种融合信任关系的群组推荐算法.上述算法虽然能得到用户之间的信任关系,但缺少对用户间信任程度的客观度量.本文基于多属性评分来挖掘用户之间的隐式信任关系,结合用户在共同评分项目上的数量和多属性评分的相似度两个方面来获得用户之间的信任程度,能更好地刻画用户信任关系,获得更精准的群组偏好. ...
... 采用Victor et al[17]的有序加权平均(OWA)算子来集结不同路径的信任度.由于OWA算子能够灵活反映不同的集结度,其在群体决策的信息集结过程中得到了广泛的应用. ...
... 的取值采用Victor et al[17]的基于语言量词Q的量词引导方法计算得到,即: ...
融合邻居选择策略和信任关系的兴趣点推荐
1
2020
... 随着信任网络的出现和发展,信任关系逐渐被引入推荐系统.Da'u et al[14]提出一种根据信任网络的出入度来重构信任度的混合推荐算法.Guo et al[15]提出一种融合项目流行度和用户信任关系的矩阵分解推荐算法.Chen et al[16]结合信任关系和协同过滤建立了一种随机游走模型来提高推荐性能.Victor et al[17]将用户交互信息作为信任关系,提出一种社交推荐(Social Recommendation,SoRec)方法.由于隐私问题,获取用户之间的信任分数通常很困难,当用户之间的信任关系无法直接获知时,可以通过分析用户行为、社交网络等隐含信息来进行推断.近年来,越来越多的研究开始探索隐性信任的提取方法.刘辉等[18]利用用户之间的相似度来计算信任度,提出一种整合用户相似度、地理位置和信任关系的混合推荐算法.张槟淇等[19]根据用户的影响力来计算用户信任度,提出一种融合信任关系的群组推荐算法.上述算法虽然能得到用户之间的信任关系,但缺少对用户间信任程度的客观度量.本文基于多属性评分来挖掘用户之间的隐式信任关系,结合用户在共同评分项目上的数量和多属性评分的相似度两个方面来获得用户之间的信任程度,能更好地刻画用户信任关系,获得更精准的群组偏好. ...
Point?of?interest recommendation based on neighbor selection strategy and trust relationship
1
2020
... 随着信任网络的出现和发展,信任关系逐渐被引入推荐系统.Da'u et al[14]提出一种根据信任网络的出入度来重构信任度的混合推荐算法.Guo et al[15]提出一种融合项目流行度和用户信任关系的矩阵分解推荐算法.Chen et al[16]结合信任关系和协同过滤建立了一种随机游走模型来提高推荐性能.Victor et al[17]将用户交互信息作为信任关系,提出一种社交推荐(Social Recommendation,SoRec)方法.由于隐私问题,获取用户之间的信任分数通常很困难,当用户之间的信任关系无法直接获知时,可以通过分析用户行为、社交网络等隐含信息来进行推断.近年来,越来越多的研究开始探索隐性信任的提取方法.刘辉等[18]利用用户之间的相似度来计算信任度,提出一种整合用户相似度、地理位置和信任关系的混合推荐算法.张槟淇等[19]根据用户的影响力来计算用户信任度,提出一种融合信任关系的群组推荐算法.上述算法虽然能得到用户之间的信任关系,但缺少对用户间信任程度的客观度量.本文基于多属性评分来挖掘用户之间的隐式信任关系,结合用户在共同评分项目上的数量和多属性评分的相似度两个方面来获得用户之间的信任程度,能更好地刻画用户信任关系,获得更精准的群组偏好. ...
... 随着信任网络的出现和发展,信任关系逐渐被引入推荐系统.Da'u et al[14]提出一种根据信任网络的出入度来重构信任度的混合推荐算法.Guo et al[15]提出一种融合项目流行度和用户信任关系的矩阵分解推荐算法.Chen et al[16]结合信任关系和协同过滤建立了一种随机游走模型来提高推荐性能.Victor et al[17]将用户交互信息作为信任关系,提出一种社交推荐(Social Recommendation,SoRec)方法.由于隐私问题,获取用户之间的信任分数通常很困难,当用户之间的信任关系无法直接获知时,可以通过分析用户行为、社交网络等隐含信息来进行推断.近年来,越来越多的研究开始探索隐性信任的提取方法.刘辉等[18]利用用户之间的相似度来计算信任度,提出一种整合用户相似度、地理位置和信任关系的混合推荐算法.张槟淇等[19]根据用户的影响力来计算用户信任度,提出一种融合信任关系的群组推荐算法.上述算法虽然能得到用户之间的信任关系,但缺少对用户间信任程度的客观度量.本文基于多属性评分来挖掘用户之间的隐式信任关系,结合用户在共同评分项目上的数量和多属性评分的相似度两个方面来获得用户之间的信任程度,能更好地刻画用户信任关系,获得更精准的群组偏好. ...
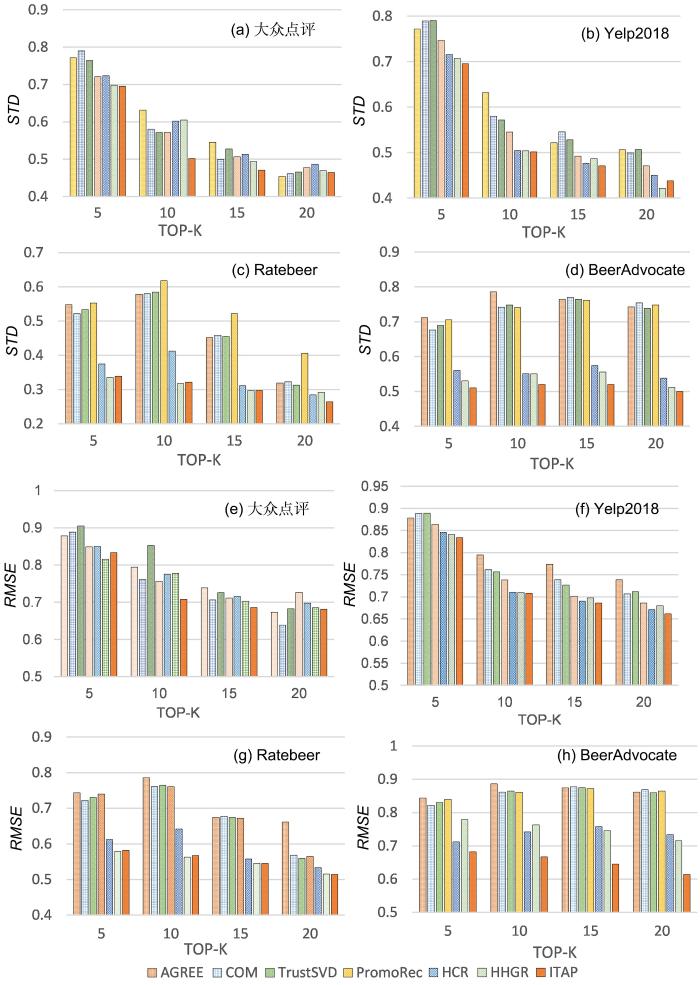
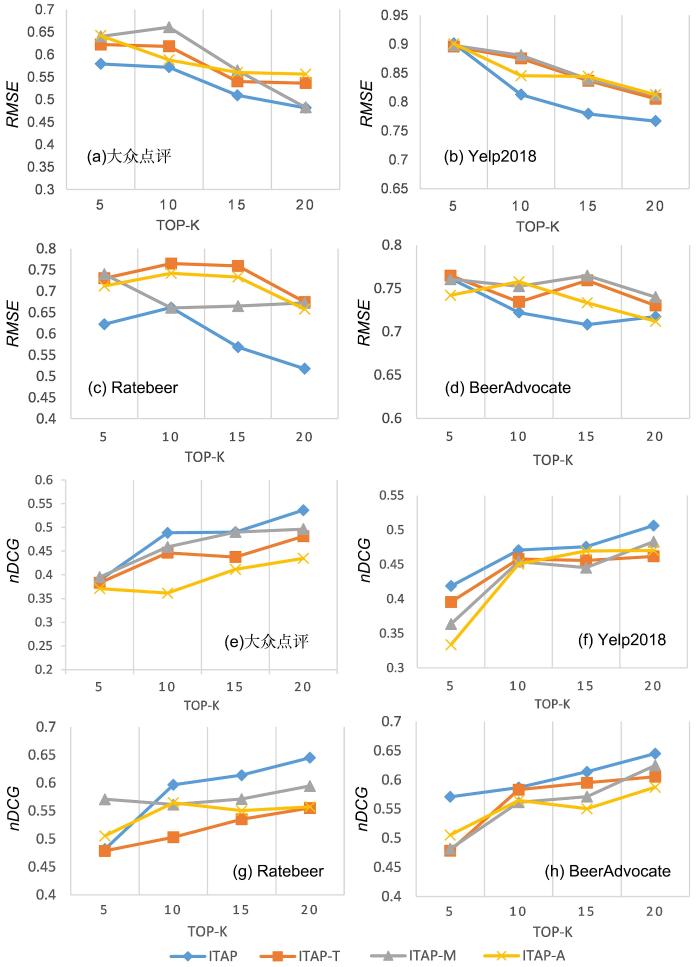
... 为了衡量ITAP算法和基线方法的性能,采用标准差(Standard Deviation,STD)[19]、归一化折损累计增益(Normalized Discounted Cumulative Gain,nDCG)[20]和均方根误差(Root Mean Square Error,RMSE)[21]三个评估指标对算法进行比较分析.具体定义如下. ...
Recommendation model combining implicit influence of trust with trust degree
... 随着信任网络的出现和发展,信任关系逐渐被引入推荐系统.Da'u et al[14]提出一种根据信任网络的出入度来重构信任度的混合推荐算法.Guo et al[15]提出一种融合项目流行度和用户信任关系的矩阵分解推荐算法.Chen et al[16]结合信任关系和协同过滤建立了一种随机游走模型来提高推荐性能.Victor et al[17]将用户交互信息作为信任关系,提出一种社交推荐(Social Recommendation,SoRec)方法.由于隐私问题,获取用户之间的信任分数通常很困难,当用户之间的信任关系无法直接获知时,可以通过分析用户行为、社交网络等隐含信息来进行推断.近年来,越来越多的研究开始探索隐性信任的提取方法.刘辉等[18]利用用户之间的相似度来计算信任度,提出一种整合用户相似度、地理位置和信任关系的混合推荐算法.张槟淇等[19]根据用户的影响力来计算用户信任度,提出一种融合信任关系的群组推荐算法.上述算法虽然能得到用户之间的信任关系,但缺少对用户间信任程度的客观度量.本文基于多属性评分来挖掘用户之间的隐式信任关系,结合用户在共同评分项目上的数量和多属性评分的相似度两个方面来获得用户之间的信任程度,能更好地刻画用户信任关系,获得更精准的群组偏好. ...
... 为了衡量ITAP算法和基线方法的性能,采用标准差(Standard Deviation,STD)[19]、归一化折损累计增益(Normalized Discounted Cumulative Gain,nDCG)[20]和均方根误差(Root Mean Square Error,RMSE)[21]三个评估指标对算法进行比较分析.具体定义如下. ...
Circle?based group recommendation in social networks
... 基于深度学习的推荐算法大多是将用户和项目嵌入神经网络,从用户、群组和项目之间的交互数据中学习用户偏好.Choudhary et al[20]通过群组和用户组成的双层注意网络来学习群组成员权重.Cao et al[21]利用注意力机制,动态地调整用户在不同群组中的影响力,较好地解释了群组偏好的集结过程.Wang et al[22]利用神经注意网络,以动态方式来学习成员之间的相对影响,利用组内的成员偏好来表示群组偏好.He et al[24]利用自注意力机制来挖掘用户与项目间的潜在信息,进而学习得到群组的潜在偏好.Jia et al[25]提出一种由成员级偏好网络和组级偏好网络构成的双通道超图卷积网络.深度学习技术与群组推荐算法的结合有效地促进了群组偏好融合研究,但现有研究大多根据评分来获取用户与项目之间的交互,没有充分考虑用户之间的关系,导致获取的群组偏好不够全面,影响推荐效果.本文在利用神经网络学习用户⁃项目交互的基础上,引入用户之间的信任关系,能获得更全面的群组偏好. ...
... 为了衡量ITAP算法和基线方法的性能,采用标准差(Standard Deviation,STD)[19]、归一化折损累计增益(Normalized Discounted Cumulative Gain,nDCG)[20]和均方根误差(Root Mean Square Error,RMSE)[21]三个评估指标对算法进行比较分析.具体定义如下. ...
... 基于深度学习的推荐算法大多是将用户和项目嵌入神经网络,从用户、群组和项目之间的交互数据中学习用户偏好.Choudhary et al[20]通过群组和用户组成的双层注意网络来学习群组成员权重.Cao et al[21]利用注意力机制,动态地调整用户在不同群组中的影响力,较好地解释了群组偏好的集结过程.Wang et al[22]利用神经注意网络,以动态方式来学习成员之间的相对影响,利用组内的成员偏好来表示群组偏好.He et al[24]利用自注意力机制来挖掘用户与项目间的潜在信息,进而学习得到群组的潜在偏好.Jia et al[25]提出一种由成员级偏好网络和组级偏好网络构成的双通道超图卷积网络.深度学习技术与群组推荐算法的结合有效地促进了群组偏好融合研究,但现有研究大多根据评分来获取用户与项目之间的交互,没有充分考虑用户之间的关系,导致获取的群组偏好不够全面,影响推荐效果.本文在利用神经网络学习用户⁃项目交互的基础上,引入用户之间的信任关系,能获得更全面的群组偏好. ...
... 为了衡量ITAP算法和基线方法的性能,采用标准差(Standard Deviation,STD)[19]、归一化折损累计增益(Normalized Discounted Cumulative Gain,nDCG)[20]和均方根误差(Root Mean Square Error,RMSE)[21]三个评估指标对算法进行比较分析.具体定义如下. ...
... 基于深度学习的推荐算法大多是将用户和项目嵌入神经网络,从用户、群组和项目之间的交互数据中学习用户偏好.Choudhary et al[20]通过群组和用户组成的双层注意网络来学习群组成员权重.Cao et al[21]利用注意力机制,动态地调整用户在不同群组中的影响力,较好地解释了群组偏好的集结过程.Wang et al[22]利用神经注意网络,以动态方式来学习成员之间的相对影响,利用组内的成员偏好来表示群组偏好.He et al[24]利用自注意力机制来挖掘用户与项目间的潜在信息,进而学习得到群组的潜在偏好.Jia et al[25]提出一种由成员级偏好网络和组级偏好网络构成的双通道超图卷积网络.深度学习技术与群组推荐算法的结合有效地促进了群组偏好融合研究,但现有研究大多根据评分来获取用户与项目之间的交互,没有充分考虑用户之间的关系,导致获取的群组偏好不够全面,影响推荐效果.本文在利用神经网络学习用户⁃项目交互的基础上,引入用户之间的信任关系,能获得更全面的群组偏好. ...
A group recommendation approach based on neural network collaborative filtering
... 基于深度学习的推荐算法大多是将用户和项目嵌入神经网络,从用户、群组和项目之间的交互数据中学习用户偏好.Choudhary et al[20]通过群组和用户组成的双层注意网络来学习群组成员权重.Cao et al[21]利用注意力机制,动态地调整用户在不同群组中的影响力,较好地解释了群组偏好的集结过程.Wang et al[22]利用神经注意网络,以动态方式来学习成员之间的相对影响,利用组内的成员偏好来表示群组偏好.He et al[24]利用自注意力机制来挖掘用户与项目间的潜在信息,进而学习得到群组的潜在偏好.Jia et al[25]提出一种由成员级偏好网络和组级偏好网络构成的双通道超图卷积网络.深度学习技术与群组推荐算法的结合有效地促进了群组偏好融合研究,但现有研究大多根据评分来获取用户与项目之间的交互,没有充分考虑用户之间的关系,导致获取的群组偏好不够全面,影响推荐效果.本文在利用神经网络学习用户⁃项目交互的基础上,引入用户之间的信任关系,能获得更全面的群组偏好. ...
Hypergraph convolutional network for group recommendation
... 基于深度学习的推荐算法大多是将用户和项目嵌入神经网络,从用户、群组和项目之间的交互数据中学习用户偏好.Choudhary et al[20]通过群组和用户组成的双层注意网络来学习群组成员权重.Cao et al[21]利用注意力机制,动态地调整用户在不同群组中的影响力,较好地解释了群组偏好的集结过程.Wang et al[22]利用神经注意网络,以动态方式来学习成员之间的相对影响,利用组内的成员偏好来表示群组偏好.He et al[24]利用自注意力机制来挖掘用户与项目间的潜在信息,进而学习得到群组的潜在偏好.Jia et al[25]提出一种由成员级偏好网络和组级偏好网络构成的双通道超图卷积网络.深度学习技术与群组推荐算法的结合有效地促进了群组偏好融合研究,但现有研究大多根据评分来获取用户与项目之间的交互,没有充分考虑用户之间的关系,导致获取的群组偏好不够全面,影响推荐效果.本文在利用神经网络学习用户⁃项目交互的基础上,引入用户之间的信任关系,能获得更全面的群组偏好. ...



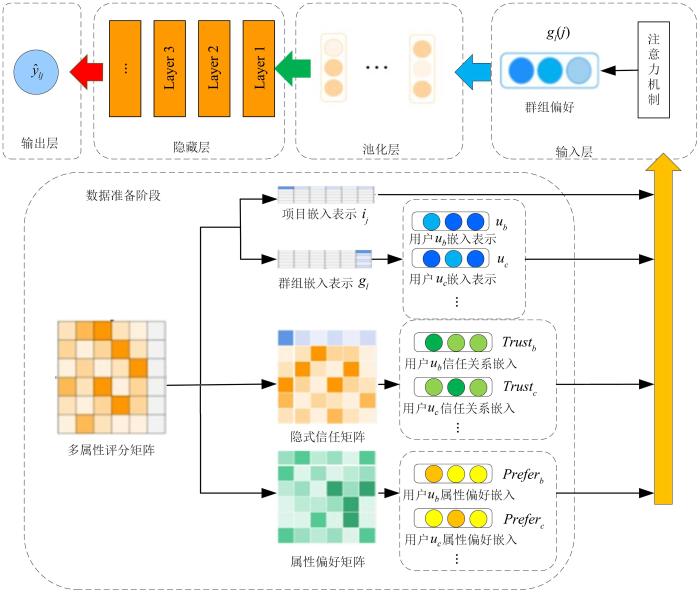
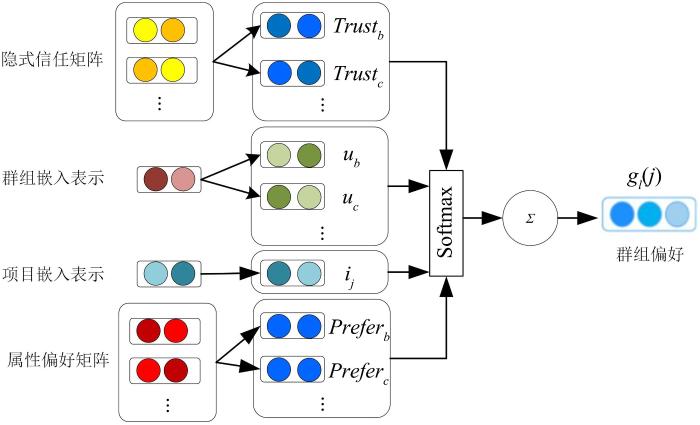
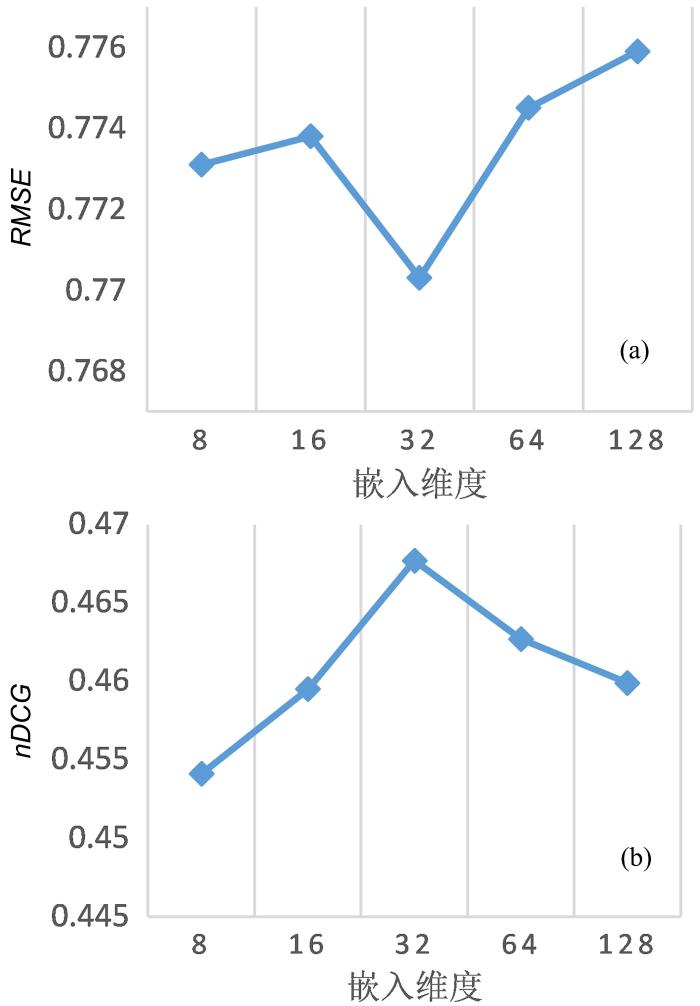
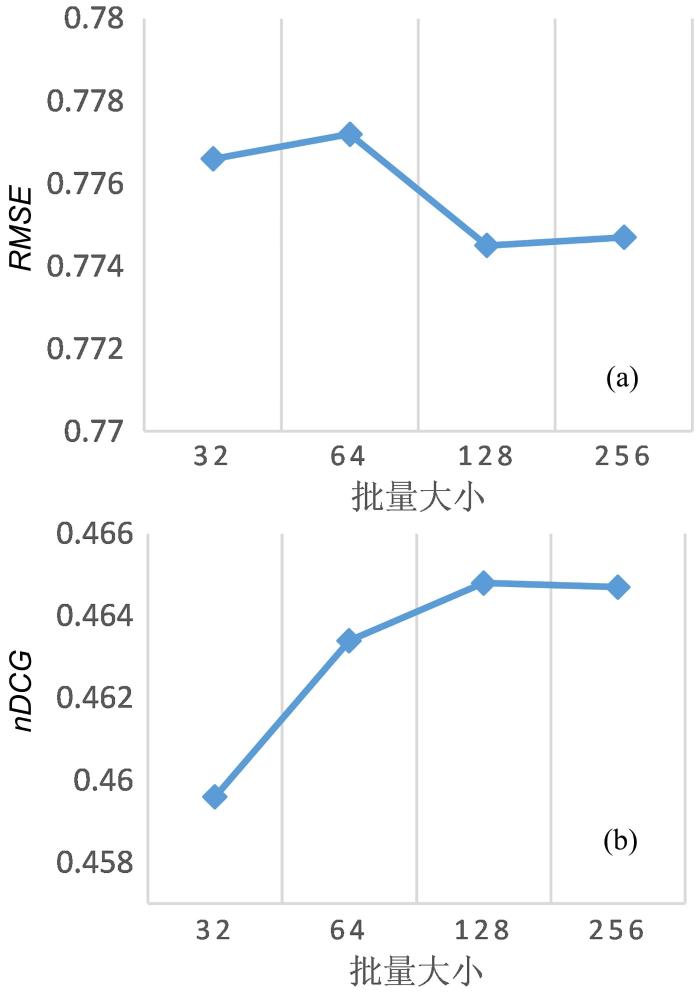


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}