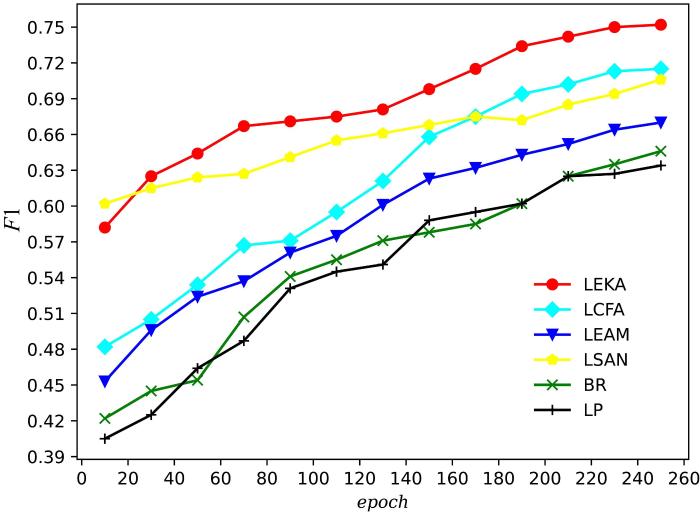
多标签文本分类是自然语言处理领域的重要任务之一.文本的标签语义信息与文本的文档内容有紧密的联系,而传统的多标签文本分类方法存在忽略标签的语义信息以及标签的语义信息不足等问题.针对以上问题,提出一种融合标签嵌入和知识感知的多标签文本分类方法LEKA (Label Embedding and Knowledge⁃Aware).该方法依赖于文档文本以及相应的多个标签,通过标签嵌入来获取与标签相关的注意力.考虑标签的语义信息,建立标签与文档内容的联系,将标签应用到文本分类中.另外,为了增强标签的语义信息,通过知识图谱嵌入引入外部感知知识,对标签文本进行语义扩展.在AAPD和RCV1⁃V2公开数据集上与其他分类模型进行了对比,实验结果表明,与LCFA (Label Combination and Fusion of Attentions)模型相比,LEKA的F1分别提高了3.5%和2.1%.
关键词:多标签文本分类
;
标签嵌入
;
知识图谱
;
注意力机制
Abstract
Multi⁃label text classification is one of the most important tasks in natural language processing. The label semantic information of the text is closely related to the document content of the text. However,traditional multi⁃label text classification methods have some problems,such as ignore the semantic information of the labels itself and insufficient semantic information of the labels. In response to the above problems,we propose a multi⁃label text classification method LEKA (Label Embedding and Knowledge⁃Aware). LEKA relies on the document text and multiple labels,obtains attention related to labels through label embedding,considers the semantic information of labels,the relationship between the labels and the content of the established document,and applies labels to text classification. In addition,to enhance the semantic information of the labels,the embedding of knowledge graph is used to introduced external aware knowledge,expanding the semantic information of label text. Compared with other classification models on AAPD and RCV1⁃V2 open data sets,excessive experimental results show that compared with the LCFA (Label Combination and Fusion of Attentions) model,the proposed method improves the F1 value by 3.5% and 2.1% respectively.
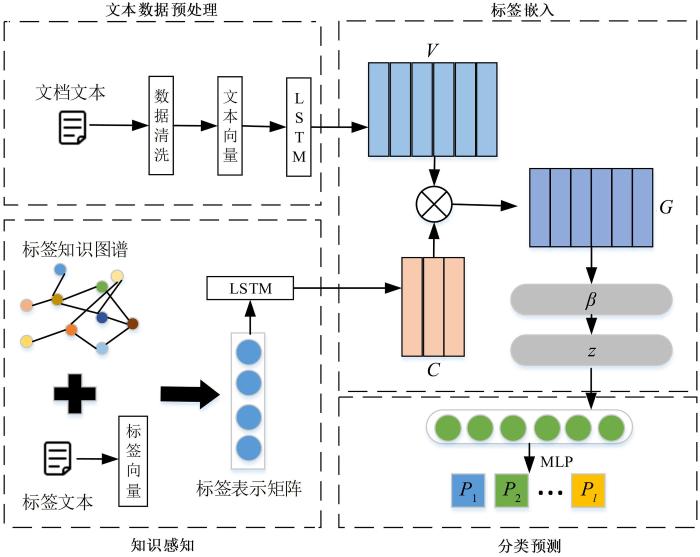
多标签文本分类(Multi⁃Class Text Classifica⁃tion,MCTC)是为文本文档分配一个或多个标签的文本分类任务,专注于文本的高级语义表示和标签相关性建模,有广泛的应用,如信息检索[3]、情感分析[4]、主题识别[5]、推荐系统[6]等.目前在多标签文本分类领域,主要有三个研究内容:(1)从文档中充分捕获有效的语义信息;(2)探究标签与文档之间的相关性,从文档中获取标签的文档表示;(3)探究标签之间的联系,因为在多标签文本分类中,大多数标签之间都有层次性.大多数研究者都是在完成第一个内容的前提下,重点对后两个内容进行探索[7].尽管多标签文本分类的研究有一定进展,但依然有诸多问题,如把标签当成没有语义信息的标记,忽略标签本身的语义信息,标签的语义信息仅仅在最后的分类预测阶段起监督的作用;同时,大多数标签是几个字符长度的短文本,标签文本存在数据稀疏问题.
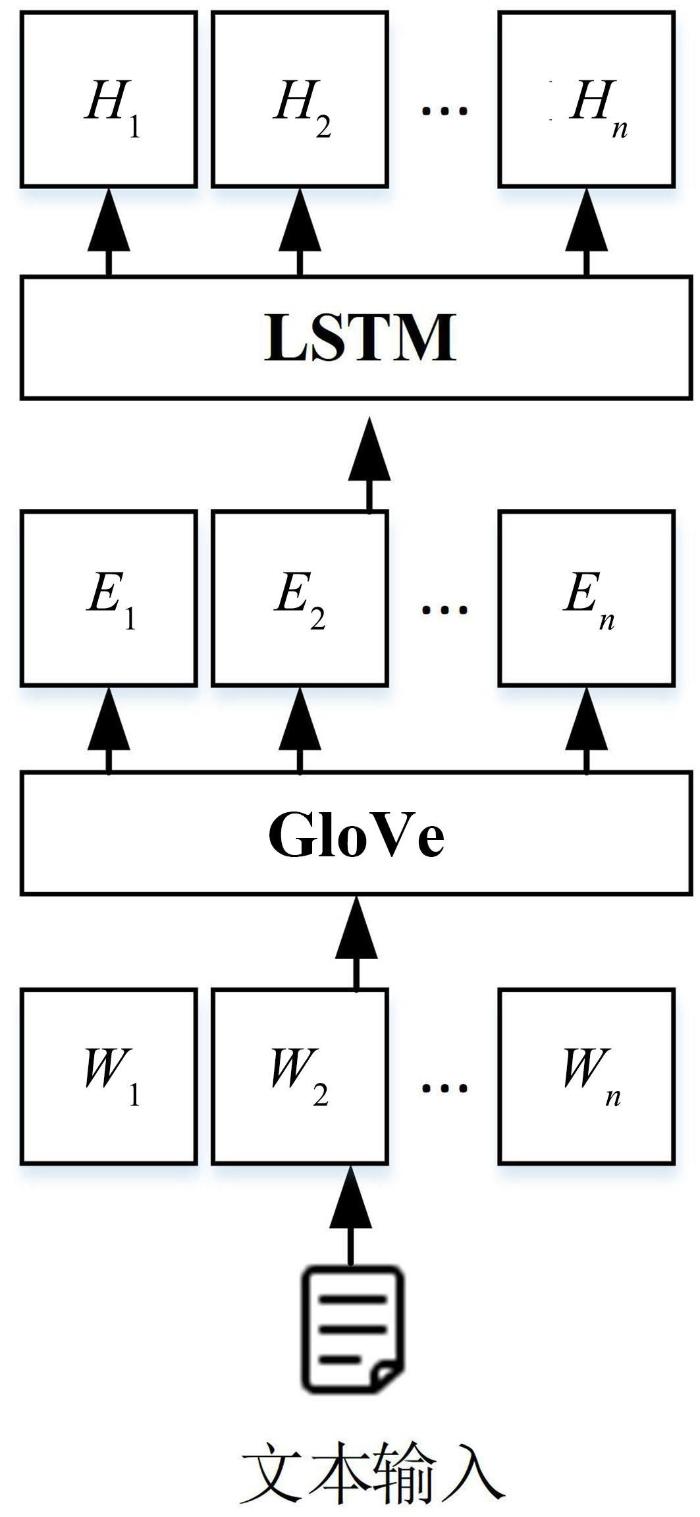
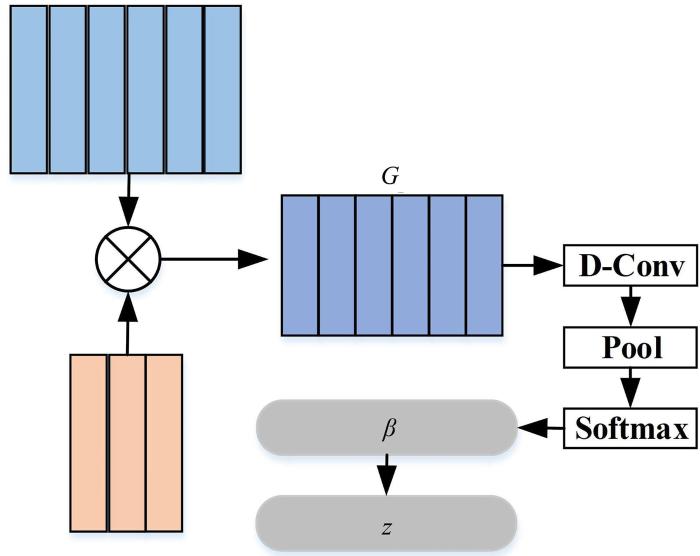
针对上述问题,本文提出一种融合标签嵌入和知识感知(Label Embedding and Knowledge⁃Aware,LEKA)的多标签文本分类方法,在利用标签嵌入的同时,将文本单词和类别标签在同维度语义空间进行学习嵌入,再通过知识图谱[8]嵌入对标签文本进行语义扩展,实现对标签的知识感知.最后,通过标签嵌入注意力使标签和文档文本进行语义交互,得到基于标签的文本表示,将标签应用到文本分类过程中.本文的主要贡献:
另一种是算法自适应,其基本思想是通过改进传统的单标签分类算法来解决多标签分类问题.单标签学习算法的改进已为多标签学习方法提供了理论和值得借鉴的实践经验.Ranking Support Vector Machine (Rank⁃SVM)[12]是建立在统计学习理论基础上的机器学习算法,直接对RNN (Recurrent Neural Network)的输出层进行改进,将经典的支持向量机推广到多标签学习中.Multi⁃Label Decision Tree (ML⁃DT)[13]采用决策树技术来处理多标签数据,利用熵的信息增益准则递归地构建决策树.Multi⁃Label k⁃Nearest Neighbor (ML⁃kNN)[14]直接对KNN的输出层进行改进,使用K近邻算法得到邻近的类别标记,再通过最大化后验概率得到位置示例的标记集合.
1.2 基于神经网络的深度学习算法
随着深度学习的飞速发展,多标签文本分类方法也由以机器学习为主的传统学习模型逐渐发展到基于神经网络的深度学习模型.2014年Kalchbrenner et al[15]提出动态卷积神经网络DCNN,首次将CNN应用到文本分类,取得了较好的结果,但无法发现标签之间的依赖性.CNN⁃RNN[16]利用RNN[17]来处理标签之间的依赖关系问题.Yang et al[18]提出序列生成模型(Sequence Generation Model,SGM),以Seq2Seq为基础,使用RNN作为编码器对指定文档文本进行编码,并使用新的RNN层作为解码器输出每个可能的标签序列.邬鑫珂等[19]提出基于标签组合和注意力的网络模型,通过对标签之间的互斥关系的建模来学习标签之间的依赖性.Wang et al[20]提出LEAM (Label⁃Embedding Attentive Model)网络模型,在相同维度语义空间下将文档文本和标签都转化为向量形式,基于这些向量表示来完成文本分类任务.肖琳等[1]提出LSAN (Label Semantic Attention Multi⁃label Classification)网络模型,通过标签语义注意力得到所有标签的文档表示,不仅考虑了标签的依赖性,而且得到了文档全部词的权重.
1.3 知识图谱嵌入
2012年谷歌正式提出知识图谱的概念,起初应用在搜索引擎,而今已发展得越来越成熟,其中规模较大的有YAGO[21],Freebase[22],Probase[23]等.知识图谱一般表示为,其中是实体集合,是关系集合;由实体⁃关系⁃实体组成的三元组,其中是头实体,是尾实体,是有向关系.知识图谱嵌入(Knowledge Graph Embedding,KGE)也称知识表示学习,其目标是将知识图谱中的每个实体表示为低维表示向量,而关系表示为在向量空间的运算.近年来,由于其简洁的模型和卓越的性能,知识图谱嵌入受到了学者的广泛关注.2013年Mikolov et al[24]提出一种基于表示学习的TransE模型,它是最经典的翻译模型,将实体和关系都表示为同一空间的向量形式.TransE有效地将语义信息作为学习知识表示的唯一特征,利用向量空间计算语义关系,极大地缓解了知识图谱中数据稀疏和传统表示学习方法计算效率低的问题,但在解决不同关系时效果不佳.2014年Wang et al[25]提出TransH模型,是对TransE模型的改进,将头、尾实体的嵌入向量映射到关系的超平面中,并允许实体在涉及不同关系时有不同的表示,解决了TransE模型存在的不足.2017年Lin et al[26]提出TransR模型,先将各个关系建模为一个投影矩阵,使实体嵌入映射到对应的关系空间.随后,各种改进的知识图谱嵌入模型被相继提出,如TransD,TransM,TransG[27]等.
Convolutional neural networks for sentence classification
∥Proceedings of 2014 Conference on Empirical Methods in Natural Language Processing. Doha,Qatar:Association for Computational Linguistics,2014:1746-1751.
Document modeling with gated recurrent neural network for sentiment classification
∥Proceedings of 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon,Portugal:Association for Computational Linguistics,2015:1422-1432.
SGM:Sequence generation model for multi⁃label classification
∥Proceedings of the 27th International Conference on Computational Linguistics. Santa Fe,NM,USA:Association for Computational Linguistics,2018:3915-3926.
Yago3:A knowledge base from multilingual wikipedias
∥The 7th Biennial Conference on Innovative Data Systems Research. Asilomar,CA,USA:www.cidrdb.org,https:∥www.cidrdb.org/cidr2015/Papers/CIDR15_ Paper1.pdf,2015.
Multilabel classification with meta?level features
1
2010
... 多标签文本分类(Multi⁃Class Text Classifica⁃tion,MCTC)是为文本文档分配一个或多个标签的文本分类任务,专注于文本的高级语义表示和标签相关性建模,有广泛的应用,如信息检索[3]、情感分析[4]、主题识别[5]、推荐系统[6]等.目前在多标签文本分类领域,主要有三个研究内容:(1)从文档中充分捕获有效的语义信息;(2)探究标签与文档之间的相关性,从文档中获取标签的文档表示;(3)探究标签之间的联系,因为在多标签文本分类中,大多数标签之间都有层次性.大多数研究者都是在完成第一个内容的前提下,重点对后两个内容进行探索[7].尽管多标签文本分类的研究有一定进展,但依然有诸多问题,如把标签当成没有语义信息的标记,忽略标签本身的语义信息,标签的语义信息仅仅在最后的分类预测阶段起监督的作用;同时,大多数标签是几个字符长度的短文本,标签文本存在数据稀疏问题. ...
Cross?domain sentiment classification with bidirectional contextualized trans?former language models
1
2019
... 多标签文本分类(Multi⁃Class Text Classifica⁃tion,MCTC)是为文本文档分配一个或多个标签的文本分类任务,专注于文本的高级语义表示和标签相关性建模,有广泛的应用,如信息检索[3]、情感分析[4]、主题识别[5]、推荐系统[6]等.目前在多标签文本分类领域,主要有三个研究内容:(1)从文档中充分捕获有效的语义信息;(2)探究标签与文档之间的相关性,从文档中获取标签的文档表示;(3)探究标签之间的联系,因为在多标签文本分类中,大多数标签之间都有层次性.大多数研究者都是在完成第一个内容的前提下,重点对后两个内容进行探索[7].尽管多标签文本分类的研究有一定进展,但依然有诸多问题,如把标签当成没有语义信息的标记,忽略标签本身的语义信息,标签的语义信息仅仅在最后的分类预测阶段起监督的作用;同时,大多数标签是几个字符长度的短文本,标签文本存在数据稀疏问题. ...
Document modeling with gated recurrent neural network for sentiment classification
1
2015
... 多标签文本分类(Multi⁃Class Text Classifica⁃tion,MCTC)是为文本文档分配一个或多个标签的文本分类任务,专注于文本的高级语义表示和标签相关性建模,有广泛的应用,如信息检索[3]、情感分析[4]、主题识别[5]、推荐系统[6]等.目前在多标签文本分类领域,主要有三个研究内容:(1)从文档中充分捕获有效的语义信息;(2)探究标签与文档之间的相关性,从文档中获取标签的文档表示;(3)探究标签之间的联系,因为在多标签文本分类中,大多数标签之间都有层次性.大多数研究者都是在完成第一个内容的前提下,重点对后两个内容进行探索[7].尽管多标签文本分类的研究有一定进展,但依然有诸多问题,如把标签当成没有语义信息的标记,忽略标签本身的语义信息,标签的语义信息仅仅在最后的分类预测阶段起监督的作用;同时,大多数标签是几个字符长度的短文本,标签文本存在数据稀疏问题. ...
Multi?label classification methods for green computing and application for mobile medical recommendations
1
2016
... 多标签文本分类(Multi⁃Class Text Classifica⁃tion,MCTC)是为文本文档分配一个或多个标签的文本分类任务,专注于文本的高级语义表示和标签相关性建模,有广泛的应用,如信息检索[3]、情感分析[4]、主题识别[5]、推荐系统[6]等.目前在多标签文本分类领域,主要有三个研究内容:(1)从文档中充分捕获有效的语义信息;(2)探究标签与文档之间的相关性,从文档中获取标签的文档表示;(3)探究标签之间的联系,因为在多标签文本分类中,大多数标签之间都有层次性.大多数研究者都是在完成第一个内容的前提下,重点对后两个内容进行探索[7].尽管多标签文本分类的研究有一定进展,但依然有诸多问题,如把标签当成没有语义信息的标记,忽略标签本身的语义信息,标签的语义信息仅仅在最后的分类预测阶段起监督的作用;同时,大多数标签是几个字符长度的短文本,标签文本存在数据稀疏问题. ...
基于标签嵌入注意力机制的多任务文本分类模型
1
2022
... 多标签文本分类(Multi⁃Class Text Classifica⁃tion,MCTC)是为文本文档分配一个或多个标签的文本分类任务,专注于文本的高级语义表示和标签相关性建模,有广泛的应用,如信息检索[3]、情感分析[4]、主题识别[5]、推荐系统[6]等.目前在多标签文本分类领域,主要有三个研究内容:(1)从文档中充分捕获有效的语义信息;(2)探究标签与文档之间的相关性,从文档中获取标签的文档表示;(3)探究标签之间的联系,因为在多标签文本分类中,大多数标签之间都有层次性.大多数研究者都是在完成第一个内容的前提下,重点对后两个内容进行探索[7].尽管多标签文本分类的研究有一定进展,但依然有诸多问题,如把标签当成没有语义信息的标记,忽略标签本身的语义信息,标签的语义信息仅仅在最后的分类预测阶段起监督的作用;同时,大多数标签是几个字符长度的短文本,标签文本存在数据稀疏问题. ...
A multi-task text classification model based on label embedding of attention mechanism
1
2022
... 多标签文本分类(Multi⁃Class Text Classifica⁃tion,MCTC)是为文本文档分配一个或多个标签的文本分类任务,专注于文本的高级语义表示和标签相关性建模,有广泛的应用,如信息检索[3]、情感分析[4]、主题识别[5]、推荐系统[6]等.目前在多标签文本分类领域,主要有三个研究内容:(1)从文档中充分捕获有效的语义信息;(2)探究标签与文档之间的相关性,从文档中获取标签的文档表示;(3)探究标签之间的联系,因为在多标签文本分类中,大多数标签之间都有层次性.大多数研究者都是在完成第一个内容的前提下,重点对后两个内容进行探索[7].尽管多标签文本分类的研究有一定进展,但依然有诸多问题,如把标签当成没有语义信息的标记,忽略标签本身的语义信息,标签的语义信息仅仅在最后的分类预测阶段起监督的作用;同时,大多数标签是几个字符长度的短文本,标签文本存在数据稀疏问题. ...
知识图谱数据管理研究综述
1
2019
... 针对上述问题,本文提出一种融合标签嵌入和知识感知(Label Embedding and Knowledge⁃Aware,LEKA)的多标签文本分类方法,在利用标签嵌入的同时,将文本单词和类别标签在同维度语义空间进行学习嵌入,再通过知识图谱[8]嵌入对标签文本进行语义扩展,实现对标签的知识感知.最后,通过标签嵌入注意力使标签和文档文本进行语义交互,得到基于标签的文本表示,将标签应用到文本分类过程中.本文的主要贡献: ...
Research on knowledge graph data management:A survey
1
2019
... 针对上述问题,本文提出一种融合标签嵌入和知识感知(Label Embedding and Knowledge⁃Aware,LEKA)的多标签文本分类方法,在利用标签嵌入的同时,将文本单词和类别标签在同维度语义空间进行学习嵌入,再通过知识图谱[8]嵌入对标签文本进行语义扩展,实现对标签的知识感知.最后,通过标签嵌入注意力使标签和文档文本进行语义交互,得到基于标签的文本表示,将标签应用到文本分类过程中.本文的主要贡献: ...
Joint embedding of words and labels for text classification
2
2018
... 随着深度学习的飞速发展,多标签文本分类方法也由以机器学习为主的传统学习模型逐渐发展到基于神经网络的深度学习模型.2014年Kalchbrenner et al[15]提出动态卷积神经网络DCNN,首次将CNN应用到文本分类,取得了较好的结果,但无法发现标签之间的依赖性.CNN⁃RNN[16]利用RNN[17]来处理标签之间的依赖关系问题.Yang et al[18]提出序列生成模型(Sequence Generation Model,SGM),以Seq2Seq为基础,使用RNN作为编码器对指定文档文本进行编码,并使用新的RNN层作为解码器输出每个可能的标签序列.邬鑫珂等[19]提出基于标签组合和注意力的网络模型,通过对标签之间的互斥关系的建模来学习标签之间的依赖性.Wang et al[20]提出LEAM (Label⁃Embedding Attentive Model)网络模型,在相同维度语义空间下将文档文本和标签都转化为向量形式,基于这些向量表示来完成文本分类任务.肖琳等[1]提出LSAN (Label Semantic Attention Multi⁃label Classification)网络模型,通过标签语义注意力得到所有标签的文档表示,不仅考虑了标签的依赖性,而且得到了文档全部词的权重. ...
... LEAM[20]:将文本和标签置于同一空间进行联合嵌入,获得更具识别性的文本表征. ...
Yago3:A knowledge base from multilingual wikipedias
1
2015
... 2012年谷歌正式提出知识图谱的概念,起初应用在搜索引擎,而今已发展得越来越成熟,其中规模较大的有YAGO[21],Freebase[22],Probase[23]等.知识图谱一般表示为,其中是实体集合,是关系集合;由实体⁃关系⁃实体组成的三元组,其中是头实体,是尾实体,是有向关系.知识图谱嵌入(Knowledge Graph Embedding,KGE)也称知识表示学习,其目标是将知识图谱中的每个实体表示为低维表示向量,而关系表示为在向量空间的运算.近年来,由于其简洁的模型和卓越的性能,知识图谱嵌入受到了学者的广泛关注.2013年Mikolov et al[24]提出一种基于表示学习的TransE模型,它是最经典的翻译模型,将实体和关系都表示为同一空间的向量形式.TransE有效地将语义信息作为学习知识表示的唯一特征,利用向量空间计算语义关系,极大地缓解了知识图谱中数据稀疏和传统表示学习方法计算效率低的问题,但在解决不同关系时效果不佳.2014年Wang et al[25]提出TransH模型,是对TransE模型的改进,将头、尾实体的嵌入向量映射到关系的超平面中,并允许实体在涉及不同关系时有不同的表示,解决了TransE模型存在的不足.2017年Lin et al[26]提出TransR模型,先将各个关系建模为一个投影矩阵,使实体嵌入映射到对应的关系空间.随后,各种改进的知识图谱嵌入模型被相继提出,如TransD,TransM,TransG[27]等. ...
Freebase:A collaboratively created graph database for structuring human knowledge
1
2008
... 2012年谷歌正式提出知识图谱的概念,起初应用在搜索引擎,而今已发展得越来越成熟,其中规模较大的有YAGO[21],Freebase[22],Probase[23]等.知识图谱一般表示为,其中是实体集合,是关系集合;由实体⁃关系⁃实体组成的三元组,其中是头实体,是尾实体,是有向关系.知识图谱嵌入(Knowledge Graph Embedding,KGE)也称知识表示学习,其目标是将知识图谱中的每个实体表示为低维表示向量,而关系表示为在向量空间的运算.近年来,由于其简洁的模型和卓越的性能,知识图谱嵌入受到了学者的广泛关注.2013年Mikolov et al[24]提出一种基于表示学习的TransE模型,它是最经典的翻译模型,将实体和关系都表示为同一空间的向量形式.TransE有效地将语义信息作为学习知识表示的唯一特征,利用向量空间计算语义关系,极大地缓解了知识图谱中数据稀疏和传统表示学习方法计算效率低的问题,但在解决不同关系时效果不佳.2014年Wang et al[25]提出TransH模型,是对TransE模型的改进,将头、尾实体的嵌入向量映射到关系的超平面中,并允许实体在涉及不同关系时有不同的表示,解决了TransE模型存在的不足.2017年Lin et al[26]提出TransR模型,先将各个关系建模为一个投影矩阵,使实体嵌入映射到对应的关系空间.随后,各种改进的知识图谱嵌入模型被相继提出,如TransD,TransM,TransG[27]等. ...
Probase:A probabilistic taxonomy for text understanding
1
2012
... 2012年谷歌正式提出知识图谱的概念,起初应用在搜索引擎,而今已发展得越来越成熟,其中规模较大的有YAGO[21],Freebase[22],Probase[23]等.知识图谱一般表示为,其中是实体集合,是关系集合;由实体⁃关系⁃实体组成的三元组,其中是头实体,是尾实体,是有向关系.知识图谱嵌入(Knowledge Graph Embedding,KGE)也称知识表示学习,其目标是将知识图谱中的每个实体表示为低维表示向量,而关系表示为在向量空间的运算.近年来,由于其简洁的模型和卓越的性能,知识图谱嵌入受到了学者的广泛关注.2013年Mikolov et al[24]提出一种基于表示学习的TransE模型,它是最经典的翻译模型,将实体和关系都表示为同一空间的向量形式.TransE有效地将语义信息作为学习知识表示的唯一特征,利用向量空间计算语义关系,极大地缓解了知识图谱中数据稀疏和传统表示学习方法计算效率低的问题,但在解决不同关系时效果不佳.2014年Wang et al[25]提出TransH模型,是对TransE模型的改进,将头、尾实体的嵌入向量映射到关系的超平面中,并允许实体在涉及不同关系时有不同的表示,解决了TransE模型存在的不足.2017年Lin et al[26]提出TransR模型,先将各个关系建模为一个投影矩阵,使实体嵌入映射到对应的关系空间.随后,各种改进的知识图谱嵌入模型被相继提出,如TransD,TransM,TransG[27]等. ...
Distributed representations of words and phrases and their compositionality
1
2013
... 2012年谷歌正式提出知识图谱的概念,起初应用在搜索引擎,而今已发展得越来越成熟,其中规模较大的有YAGO[21],Freebase[22],Probase[23]等.知识图谱一般表示为,其中是实体集合,是关系集合;由实体⁃关系⁃实体组成的三元组,其中是头实体,是尾实体,是有向关系.知识图谱嵌入(Knowledge Graph Embedding,KGE)也称知识表示学习,其目标是将知识图谱中的每个实体表示为低维表示向量,而关系表示为在向量空间的运算.近年来,由于其简洁的模型和卓越的性能,知识图谱嵌入受到了学者的广泛关注.2013年Mikolov et al[24]提出一种基于表示学习的TransE模型,它是最经典的翻译模型,将实体和关系都表示为同一空间的向量形式.TransE有效地将语义信息作为学习知识表示的唯一特征,利用向量空间计算语义关系,极大地缓解了知识图谱中数据稀疏和传统表示学习方法计算效率低的问题,但在解决不同关系时效果不佳.2014年Wang et al[25]提出TransH模型,是对TransE模型的改进,将头、尾实体的嵌入向量映射到关系的超平面中,并允许实体在涉及不同关系时有不同的表示,解决了TransE模型存在的不足.2017年Lin et al[26]提出TransR模型,先将各个关系建模为一个投影矩阵,使实体嵌入映射到对应的关系空间.随后,各种改进的知识图谱嵌入模型被相继提出,如TransD,TransM,TransG[27]等. ...
Knowledge graph embedding by translating on hyperplanes
1
2014
... 2012年谷歌正式提出知识图谱的概念,起初应用在搜索引擎,而今已发展得越来越成熟,其中规模较大的有YAGO[21],Freebase[22],Probase[23]等.知识图谱一般表示为,其中是实体集合,是关系集合;由实体⁃关系⁃实体组成的三元组,其中是头实体,是尾实体,是有向关系.知识图谱嵌入(Knowledge Graph Embedding,KGE)也称知识表示学习,其目标是将知识图谱中的每个实体表示为低维表示向量,而关系表示为在向量空间的运算.近年来,由于其简洁的模型和卓越的性能,知识图谱嵌入受到了学者的广泛关注.2013年Mikolov et al[24]提出一种基于表示学习的TransE模型,它是最经典的翻译模型,将实体和关系都表示为同一空间的向量形式.TransE有效地将语义信息作为学习知识表示的唯一特征,利用向量空间计算语义关系,极大地缓解了知识图谱中数据稀疏和传统表示学习方法计算效率低的问题,但在解决不同关系时效果不佳.2014年Wang et al[25]提出TransH模型,是对TransE模型的改进,将头、尾实体的嵌入向量映射到关系的超平面中,并允许实体在涉及不同关系时有不同的表示,解决了TransE模型存在的不足.2017年Lin et al[26]提出TransR模型,先将各个关系建模为一个投影矩阵,使实体嵌入映射到对应的关系空间.随后,各种改进的知识图谱嵌入模型被相继提出,如TransD,TransM,TransG[27]等. ...
Learning entity and relation embeddings for knowledge graph completion
2
2015
... 2012年谷歌正式提出知识图谱的概念,起初应用在搜索引擎,而今已发展得越来越成熟,其中规模较大的有YAGO[21],Freebase[22],Probase[23]等.知识图谱一般表示为,其中是实体集合,是关系集合;由实体⁃关系⁃实体组成的三元组,其中是头实体,是尾实体,是有向关系.知识图谱嵌入(Knowledge Graph Embedding,KGE)也称知识表示学习,其目标是将知识图谱中的每个实体表示为低维表示向量,而关系表示为在向量空间的运算.近年来,由于其简洁的模型和卓越的性能,知识图谱嵌入受到了学者的广泛关注.2013年Mikolov et al[24]提出一种基于表示学习的TransE模型,它是最经典的翻译模型,将实体和关系都表示为同一空间的向量形式.TransE有效地将语义信息作为学习知识表示的唯一特征,利用向量空间计算语义关系,极大地缓解了知识图谱中数据稀疏和传统表示学习方法计算效率低的问题,但在解决不同关系时效果不佳.2014年Wang et al[25]提出TransH模型,是对TransE模型的改进,将头、尾实体的嵌入向量映射到关系的超平面中,并允许实体在涉及不同关系时有不同的表示,解决了TransE模型存在的不足.2017年Lin et al[26]提出TransR模型,先将各个关系建模为一个投影矩阵,使实体嵌入映射到对应的关系空间.随后,各种改进的知识图谱嵌入模型被相继提出,如TransD,TransM,TransG[27]等. ...
TransG:A generative model for knowledge graph embedding
1
2016
... 2012年谷歌正式提出知识图谱的概念,起初应用在搜索引擎,而今已发展得越来越成熟,其中规模较大的有YAGO[21],Freebase[22],Probase[23]等.知识图谱一般表示为,其中是实体集合,是关系集合;由实体⁃关系⁃实体组成的三元组,其中是头实体,是尾实体,是有向关系.知识图谱嵌入(Knowledge Graph Embedding,KGE)也称知识表示学习,其目标是将知识图谱中的每个实体表示为低维表示向量,而关系表示为在向量空间的运算.近年来,由于其简洁的模型和卓越的性能,知识图谱嵌入受到了学者的广泛关注.2013年Mikolov et al[24]提出一种基于表示学习的TransE模型,它是最经典的翻译模型,将实体和关系都表示为同一空间的向量形式.TransE有效地将语义信息作为学习知识表示的唯一特征,利用向量空间计算语义关系,极大地缓解了知识图谱中数据稀疏和传统表示学习方法计算效率低的问题,但在解决不同关系时效果不佳.2014年Wang et al[25]提出TransH模型,是对TransE模型的改进,将头、尾实体的嵌入向量映射到关系的超平面中,并允许实体在涉及不同关系时有不同的表示,解决了TransE模型存在的不足.2017年Lin et al[26]提出TransR模型,先将各个关系建模为一个投影矩阵,使实体嵌入映射到对应的关系空间.随后,各种改进的知识图谱嵌入模型被相继提出,如TransD,TransM,TransG[27]等. ...
Rcv1:A new benchmark collection for text categorization research
1
2004
... RCV1⁃V2 (Reuters Corpus Volume Ⅰ):由Wang et al[28]提供的公开英文数据集(2004年),来源于路透社收集的新闻报道,共有80多万条新闻报道,所有新闻故事都对应一个或多个主题,共涉及103个主题. ...



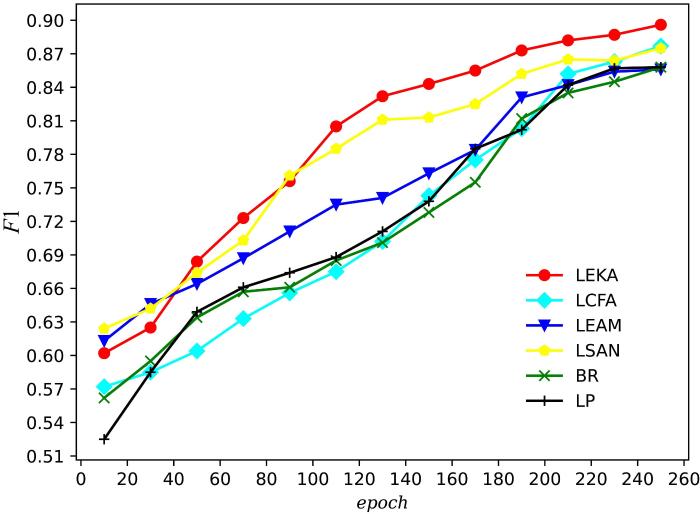
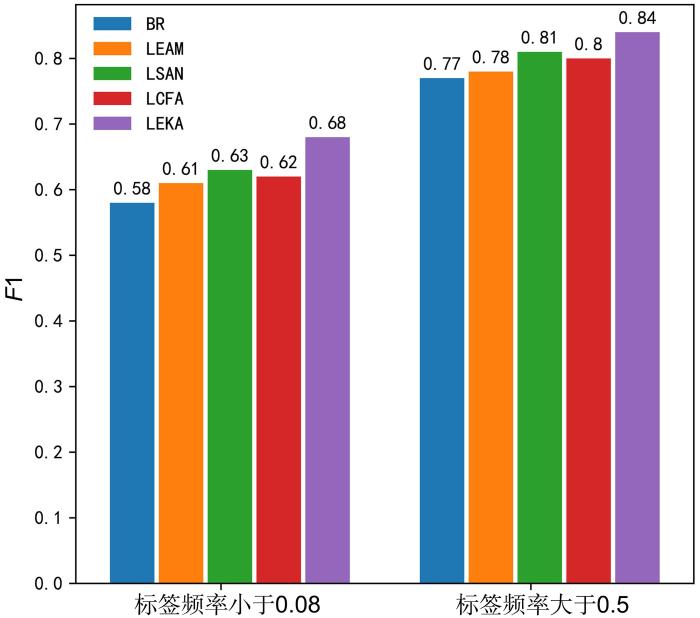

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}