


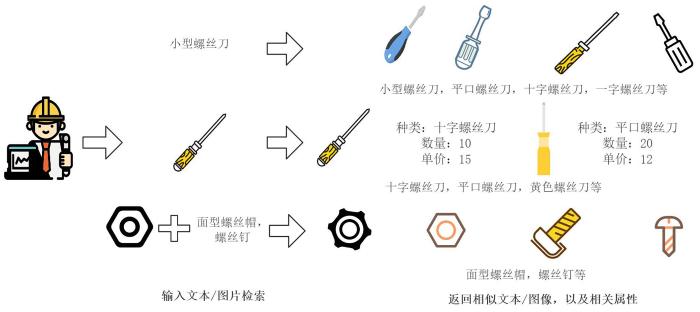
制造业在设计、生产、销售和服务环节中产生了文本、图像、音视频等海量多源异构数据.在制造环节中,一件产品从概念设计到生产制造再到销售服务可能会面临诸多查询问题,如图1所示.在设计一个产品时,设计师还经常拍摄或者手绘一个图片,希望能在数据库中找到相关或者类似的产品组件;在产品投产前,工程师还会想知道“现有备件库中是否能找到型号为SSOP的电子元器件”;进一步,产品工程师还希望通过模糊的文字、图像混合输入得到结构化生产工艺详情.为了实现上述查询需求,制造业迫切需要对其流程中产生的海量多源异构数据进行高效存储与检索,构建适当数据的存储结构,设计高效的索引模式,实现有效的跨模态检索.
图1
近年来,将文本、图像等多源异构数据映射到统一的高维空间进行高效检索是一个非常活跃的研究领域[1-3].得益于图像识别以及文本理解等深度神经网络技术的快速进步[4-5],Zhou et al[6]尝试使用对抗学习实现数据的跨模态检索,但是计算复杂度过高,影响检索速率;Jin et al[7]通过优化特征的排列结构提高检索速率,但没有考虑语义的稀疏性,产生了文本和视觉误导.跨模态检索对于企业特别是制造业管理和整合自身的多模态数据极其高效,当前百度、搜狗等公司已经在图文互检领域展开了研究,例如百度识图、搜狗识图以及用于类似商品搜索的淘宝、拍立淘等.但是,百度识图等只能提供简单场景的识图搜图服务,拍立淘仅仅提供关于商品的识图搜图服务,因此,为制造企业建立支持跨模态检索的海量跨模态存储与检索系统仍然是一个非常具有挑战性的工作.
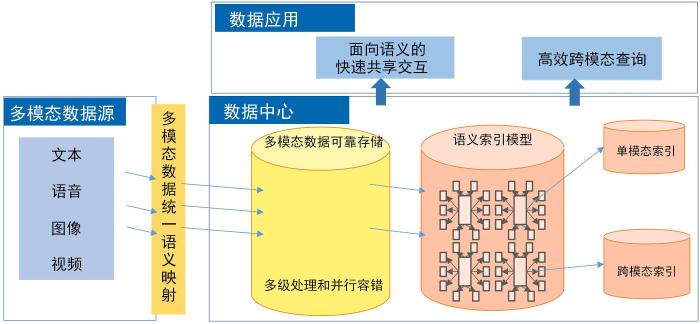
针对上述需求,本文设计并实现了一个面向多源异构数据的跨模态存储与检索系统(Multi⁃Source Heterogeneous Data Storage and Retrieval System,MDSRS).该系统首先将制造企业生产运营过程中产生的多源异构数据投影到统一高维语义空间进行表示产生语义向量,并按不同的查询需求将数据存储到不同的模式中;其次,MDSRS设计了三级结构+分层联通朴素构图算法的高效检索方法,将多模态数据按照语义向量进行索引,以满足制造业用户的语义查询需求.
本文设计的系统创新之处:
(1)设计并实现了多源异构数据的跨模态存储结构和事件存储结构;
(2)实现了正向索引+倒排索引+聚类的跨模态索引结构;
(3)提出了三级结构+分层联通朴素构图算法的高效检索算法;
(4)在flickr30k数据集上验证了MDSRS的效率和正确性.
1 相关工作
本节介绍常见的文本搜索算法、以图搜图算法、基于深度学习的跨模态检索算法及其在多模态数据统一表示上的应用.
1.1 文本检索算法
文本检索的基本任务是对于任意一个用户查询,在给定的文档集合中找到一个与用户查询相关的文档子集[8].将目标文本转化为向量是检索步骤中较常见的任务,相关方法有向量空间模型(Vector Space Model,VSM).VSM能将词汇的权重特征融合到模型中,这一做法虽然会降低计算难度,但却疏远了词与词之间的关联性.信息检索的本质就是语义的检索,如果仅仅用某些关键字来表示文档内容,通过简单的词汇模式匹配进行检索,忽视上下文语境的影响作用,就会影响信息检索的结果以及查准率和查全率,尤其对关系紧密的数据,效果一般.word2vec/doc2vec分布表示[9]用神经网络深度学习等技术分析处理海量文本,将文本表示为低维稠密向量形式,缺点在于对长文本的处理效果一般.LSA/LDA(Latent Semantic Analysis/Latent Dirichlet Allocation)主题模型[10]假设存在一个K维的主题空间,将文档表示成K个主题上的一个数值表示,但会囿于数据条件的限制.
1.2 以图搜图算法
目前最常用的以图搜图算法有两种.
基于图像内容特征描述[11]:这是一种语义层次的匹配,需要人工对图像的内容(如物体、背景、构成、颜色特征等)进行描述并分类,给出描述词,检索时主要在这些描述词中搜索检索词.这种查询方式比较准确,一般可以获得较好的查准率,但需要人工参与,劳动强度大,因而限制了可处理的图像数量,并且需要一定的规范和标准,效果取决于人工描述的精确度.
基于图像形式特征的抽取[12]:由图像分析软件自动抽取图像的颜色、形状、纹理等特征,建立特征索引库,用户只需描述查找图像的大致特征就可以找出与之具有相近特征的图像.这是一种基于图像特征层次的机械匹配,特别适用于检索目标明确、各查询要求之间区别大(例如对常见事物的检索)的任务,且检索结果能很好地满足用户要求.但这种方法主要应用于涉及多种类别的公共图数据库,无法很好地做到针对某一领域(图与图之间具备高相似性度)的识别与检索.
1.3 图像文本跨模态匹配算法
因为目标检索信息与返回信息可以用多种类型(图片、文本、音视频等)来表示,所以把检索不同模态信息的任务称作“跨模态检索”[13].图像文本跨模态匹配方法很多,最常见的有两种.一种是基于全局的图像文本跨模态匹配方法,提取图像与文本的全局特征并进行全局图像与全局文本匹配,达到提升模型性能的目的.具体地,为了解决全局图像和全局文本特征无法充分表达其全局语义信息的问题,Faghri et al[14]在三元组损失函数中引进难分样本,能够学习比较好的映射矩阵并更好地度量图像与文本的相关性.Zheng et al[15]提出可微调的视觉和文本表示,利用微调之后的全局图像特征与全局文本特征进行匹配学习,提升图像文本跨模态检索的效果.Huang et al[16]提出一种语义增强的图像与文本匹配模型,通过学习语义概念来增强图像的表示,然后按照正确的语义顺序组织它们.虽然这类方法考虑了全局特征信息,能较好地实现全局信息的对齐,但它们都缺乏局部图像特征与局部文本特征之间的匹配,没有挖掘到局部特征信息,最终影响图像文本跨模态检索的效果.
基于局部的图像文本跨模态匹配方法是近几年较为流行的方法,通常是提取图像与文本的局部特征并进行局部图像与局部文本匹配,达到提升模型性能的目的.具体地,为解决图像与文本的局部特征无法得到充分优化的问题,Lee et al[17]提出一种堆叠交叉注意力方法用于捕捉图像区域和文本单词之间的潜在对齐.还可以从减少计算图像相似度、复杂度的角度来进行图像文本跨模态匹配,Wu et al[18]提出学习嵌入图像和文本,将这两种异构数据独立投影到联合空间.前者考虑了局部特征信息,后者考虑了计算复杂度,但它们均忽略了多源异构数据本身的复杂性和多模态性,仅仅使用单一方法无法做到适应任何图文数据,最终影响图像文本跨模态检索的效果.
以上这些检索算法很少考虑多源异构数据本身的多模态特性,仅仅简单地考虑其泛用性,当具体落实到某一特定领域时,效果欠佳.同时,针对某一方向的算法可能无法兼顾其他方面,例如图搜图算法可能在图文检索中表现效果并不出色.本文提出的系统存储了百万级别的多模态数据,整合了各类检索算法使其适应大多数的场景,从而提高整体的查准率、查全率与检索速率.
2 系统设计与实现
2.1 概述
图2
2.2 面向业务流程的语义存储模式
为了实现前文提到的检索需求,MDSRS设计了两种存储模式,分别为多模态存储模式和事件存储模式.多模态存储模式的构建是为了满足产品设计时,设计师需要在数据库中进行全局搜索的需求;事件存储模式主要是为了管理制造业生产流程中的生产工艺方案.
MDSRS的存储属性如表1所示,数据存储之前需进行归一化处理.目前,研究人员经常使用的方法是最小⁃最大归一化、z分数归一化、atan函数转换和log函数转换.本文采用最小⁃最大归一化,可以对原始数据进行线性更改而不更改变其整体分布,归一化结果落在
表1 数据库定义及其相关属性
Table 1
| 数据库类型 | 定义 | 属性 |
|---|---|---|
多模态 存储模式 | 存储图文等跨模态信息 | id,向量,名称,文本描述,图像url |
事件 存储模式 | 存储一组有时序因果关系的跨模态数据 | id,向量,图文url,标题,对象,事件 |
2.3 跨模态检索架构
MDSRS的检索架构如图3所示.首先,在接收到来自用户的查询时,前端模块将查询请求转发给某一个集成器.然后,集成器模块将查询发送给所有中继器模块,每个中继器模块要求其对应的搜索器模块并行执行搜索.同时,每个中继器都有多个相同的实例,实例指负责中继器阶段检索的程序,某实例若意外终止则启动其他相同的实例,确保中继器阶段检索任务的顺利进行,实现负载平衡和容错能力.每个搜索器模块负责从整个数据库的一个数据分区中搜索相似的数据,搜索器将前M个最相似的数据返回给请求的中继器模块;中继器模块将来自其对应的搜索器模块的结果合并,然后将其发送回集成器模块;集成器模块对结果进行排序并将其返回给前端模块,展示给用户.
图3
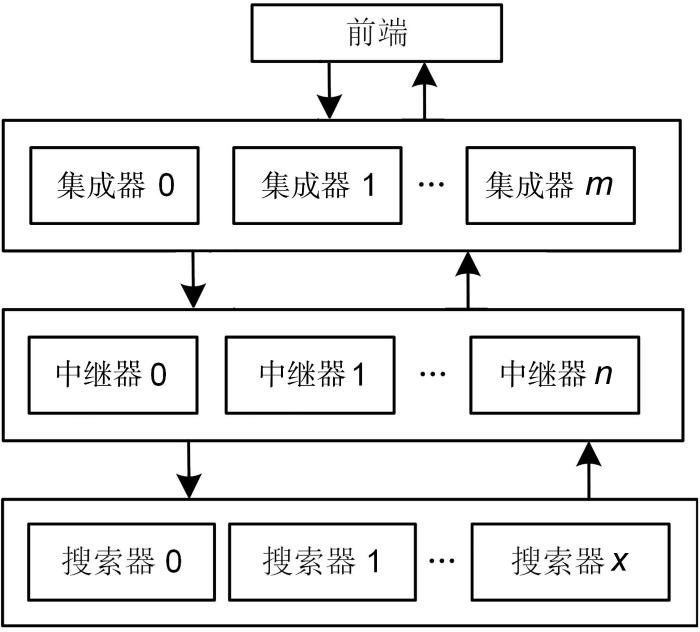
每个数据分区都有一个搜索器模块,负责搜索相应的数据分区,具体搜索相应数据分区的索引.每个搜索器模块识别与查询图像/文本最相似的数据子集,扫描数据子集的倒排表,并计算与倒排表中每个图像/文本的相似度,返回前M个最相似的图像/文本,可通过遍历倒排表并计算其到倒排列表中每个图像/文本的欧几里得距离来识别最相似的项.最后,对结果进行排名.
通过上述的三级架构模式,当数据量不断增大至百万级别甚至千万级别时,MDSRS可以通过在每一级架构中添加相应的集成器、中继器、搜索器等,使单阶段中每个检索任务的检索规模维持在一个稳定的数量级来维持系统整体的负载均衡,确保系统的可扩展性.
2.4 跨模态数据索引
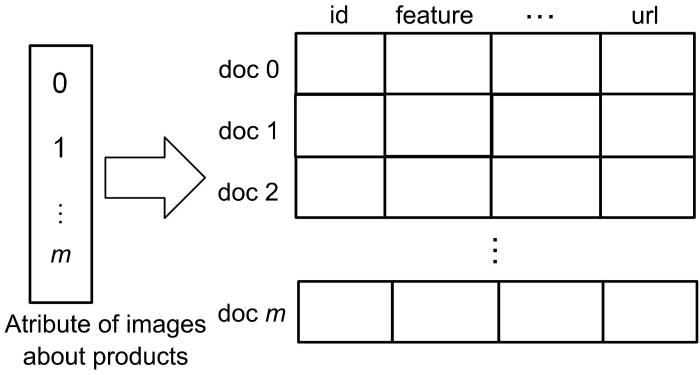
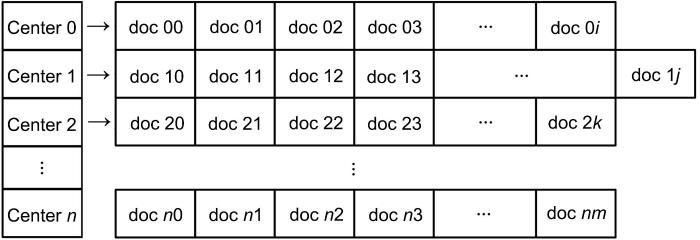
MDSRS的索引采取正向索引与倒排索引结合的方式.假设每个图像/文本都按顺序编号,其属性存储在一个正向索引中.如图4所示,正向索引是一个自定义数组,数组中的每个元素都包含相应的图像/文本属性信息、id、特征向量feature等数值属性存储在数组的固定长度字段中.
图4
如图5所示,倒排索引由N个倒排表组成,每个倒排表代表具有相似维特征的一类图像,给定训练数据集的k⁃means算法用于生成分类.在索引过程中,使用最近邻算法根据相似度计算图像所属的类别,并将图像id附加到相应的倒排表.
图5
2.5 基于聚类的高维向量相似性度量算法
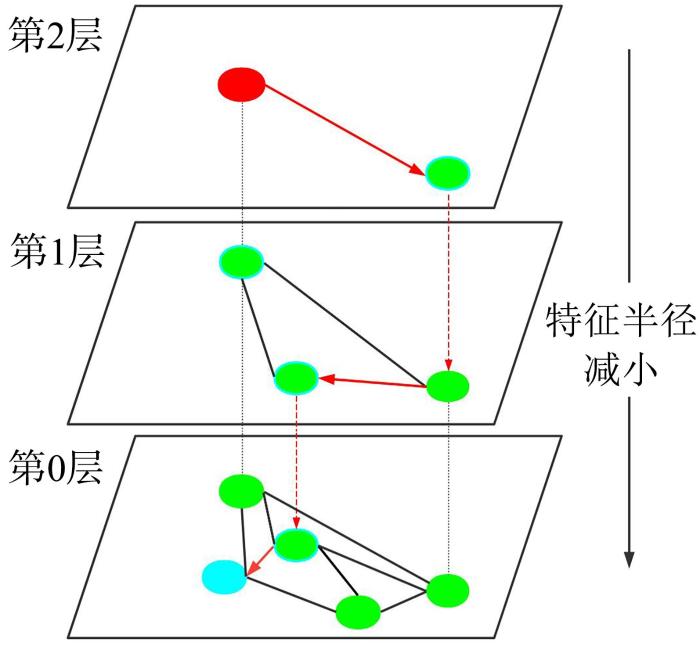
为了加快MDSRS在检索时的效率,本文提出一种基于聚类的HNSW算法来度量高维语义向量之间的相似性.HNSW算法的主要思路是把高维空间中的所有向量构建成一张相互联通的图,基于这张图搜索某个顶点的K个最近邻.具体地,HNSW算法向图中逐个插入点,每当插入一个全新点时,通过朴素想法中的朴素查找法(通过计算相邻的点和待插入点的距离来判断下一个进入点是哪个点)查找与这个全新点最近的n个点(n由用户设置),连接全新点到n个点的连线.HNSW的原理如图6所示,图中每一层都采用NSW算法,之后通过跳表连接各层从而找到目标向量.图中第0层包含数据集中的所有点,同时,为了构建每层的联通图需要设置一个常数n,计算这个点可以深入到第几层.
图6
其中,
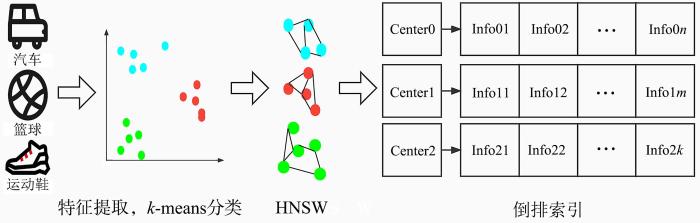
综上所述,通过HNSW算法,将各个高维向量的点连成图,并借助跳表的思想一层层检索相似点,但是由于高维向量过多,导致生成的连通图过于复杂,层数过高,计算各高维向量之间的距离复杂度过高,会大大影响检索效率.因此,本文提出一种全新的解决策略:基于聚类的高维向量相似性度量算法,算法流程如图7所示.该算法首先对图文等多模态数据进行相应的特征提取(vgg16,word2vec),特征向量通过k⁃means算法进行数据分类,形成多个簇中心;然后,在每个分类中各自进行HNSW算法,建立特征向量连通图;最后,根据不同分类中心及相关数据属性建立各自的倒排索引表.
图7
3 实验验证
3.1 实验数据
为了验证MDSRS的性能,在公开图文数据集flickr30k上进行实验.该数据集包含图像文件夹与标注文件夹两部分.图像文件夹包含31783张图片;标注文件夹包含一个token文件,读取文件得到标注信息,标注信息分image与caption两部分,image表示图像名称,caption表示该图像对应的文本描述,每张图片对应五句文本描述,总计158915条文本描述(下载地址https:∥www.kaggle.com/hsankesara/flickr⁃image⁃dataset).此外,为了验证事件模式,本研究爬取互联网图文事件栏目中约1000组图文事件(每组信息包含图片、事件内容、事件标题、事件人物、事件地点等数据).分别在跨模态存储模式以及事件模式上测试了多模态存储与检索系统,图像检索结果如图8所示,系统演示结果如图9所示,新闻具体内容如图10所示,图中查询结果根据相似度从高到低依次排名.
图8
图9
图10

3.2 在标准数据集的实验结果
对上述四种数据库整体性能进行测试.对flickr30k数据集进行填充,因为一份数据集中含有三万多张图片,将其复制32份得到约一百万张图片;同时,对图片名称在原有基础上进行前缀编号,标注每张图片所属的数据集.文本描述部分,因为一张图片对应五句文本描述,所以随机抽取每张图片对应的一条文本描述并标注其所属图片与所属数据集,得到约一百万条文本描述,以此测试系统的速度与准确率.同时,还系统对比了基于MatConvNet框架的卷积神经网络(Convolutional Neural Networks,CNN).一方面,MatConvNet是用matlab实现的CNN,该框架的设计注重简洁性和灵活性,将CNN的构建模块公开为易使用的matlab函数,提供用于计算带有滤波器组的线性卷积、特征池化等例程.通过这种方式,MatConv⁃Net可以快速建立新的CNN结构,大多数CNN通过组合简单的线性和非线性滤波操作(例如卷积和整形)来获得,但它们的实现非常重要,为了获得非常有效的实现,CNN需要从大量数据中学习,经常是数百万的图像.作为大多数CNN库,MatConvNet通过使用各种优化来实现这一点.它支持GPU上的高效计算,以此加快数据训练和验证环节,加速下游图像检索任务.另一方面,采用vgg⁃f作为预先加载的模型.imagenet⁃vgg⁃f是一个21层的卷积神经网络,在ImageNet数据集上训练其参数.它的网络结构包括五层卷积层和三层全连接层,输出的类别可达1000种.二者结合可以保证在实现图像分类的基础上进行快速高效的检索与验证,因此本文选用基于MatConv⁃Net框架的CNN作为对比方法.
对比结果如表2所示.可以看出,单次检索速度可达毫秒级,查准率与查全率稳定在90%以上.无论是速率还是准确率,本文提出的MDSRS均表现更优.
表2 本文提出的MDSRS和MatConvNet的性能对比
Table 2
| 测试对象 | 查准率 | 查全率 | 速率(s) |
|---|---|---|---|
| MDSRS | 92.32% | 90.75% | 0.025 |
| MatConvNet | 90.16% | 86.78% | 0.53 |
采用单个flickr30k数据集对图文互检进行对比实验,实验结果如表3所示.其中,Recall@k表示正确答案占前k个返回结果的比例;Median Rank表示在结果排序中,第一个真实样本出现的位置的中位数,也是使
表3 MDSRS与MatConvNet单个flickr30k数据集上的性能对比
Table 3
| 测试数目 | 测试对象 | Recall@1 | Recall@3 | Recall@5 | AVE | MR |
|---|---|---|---|---|---|---|
| 100 | MDSRS | 90.06% | 90.59% | 90.91% | 90.52% | 0 |
| 100 | MatConvNet | 80.02% | 80.23% | 80.78% | 80.13% | 0 |
| 500 | MDSRS | 89.01% | 90.22% | 90.42% | 89.88% | 0 |
| 500 | MatConvNet | 80.21% | 80.31% | 80.72% | 80.41% | 0 |
| 1000 | MDSRS | 90.34% | 90.59% | 91.19% | 90.71% | 0 |
| 1000 | MatConvNet | 80.24% | 80.41% | 80.42% | 80.36% | 0 |
为了验证系统对数据库之外的新数据能否得到好的检索效果,分别从名词类图片与行为类图片各设定八种类别,测试用例类型如表4所示,然后根据每种类别从网上选取相应类别的若干张图片存储至系统,最后进行以图搜图对比测试.实验结果如表5所示.由表可见,针对新的类型数据,二者的Recall@3稳定在90%左右.随着测试新数据的数目与种类的增多,二者的性能有略微的降低.同时,对flickr30k数据集中每张图片从对应的五句文本描述中随机抽取两句文本,再改变测试句/原句的比例进行测试.首先统计每句文本的单词数量,然后在不改变原句顺序的情况下,按照比例(以50%为例)随机抽取原句一半的单词组成新的文本进行测试.后续再通过不断增加比例来验证MDSRS对于局部文本数据是否依然具有很高的召回率.
表5 MDSRS与MatConvNet在新数据上的性能对比
Table 5
| 测试对象 | Recall@1 | Recall@2 | Recall@3 |
|---|---|---|---|
| MDSRS | 87.47% | 89.18% | 89.98% |
| MatConvNet | 88.90% | 89.12% | 89.18% |
表6 MDSRS对于局部文本数据的Recall@ k
Table 6
| 测试句/原句 | Recall@1 | Recall@2 | Recall@3 |
|---|---|---|---|
| 50% | 49.51% | 57.33% | 60.32% |
| 60% | 65.50% | 70.12% | 73.24% |
| 70% | 79.26% | 80.05% | 80.12% |
| 80% | 86.23% | 87.43% | 88.31% |
| 90% | 90.03% | 90.12% | 90.13% |
表7 MatConvNet对于局部文本数据的Recall@ k
Table 7
| 测试句/原句 | Recall@1 | Recall@2 | Recall@3 |
|---|---|---|---|
| 50% | 27.32% | 30.69% | 31.45% |
| 60% | 40.12% | 41.42% | 43.48% |
| 70% | 54.12% | 59.32% | 57.47% |
| 80% | 65.32% | 67.25% | 68.15% |
| 90% | 79.21% | 80.12% | 80.21% |
4 结论
高效整合与管理多模态数据是当前制造业面临的一大挑战,市面上识图搜图以及图文互搜的软件很多,但是大都存在局限性.例如,注重泛用性的百度识图与搜狗识图返回的结果良莠不齐;拍信受制于数据库的限制,针对行为类图片返回的结果很差;淘宝的拍立淘是典型的定制化识图软件,仅仅适用于对常用商品类的查询.对此,本文设计并实现了一个多模态数据的存储与检索系统MDSRS.该系统将制造企业生产运营过程中产生的多模态数据投影到统一高维语义空间进行表示产生语义向量,并按不同的查询需求,将多模态数据存储到不同的模式中.MDSRS实现了三级结构+分层联通朴素构图算法的高效检索方法,将多模态数据按照语义向量进行索引,以满足制造业用户的语义查询需求.在flickr30k数据集上对系统进行测试,还对比了基于MatConv⁃Net框架的CNN以及检验系统对新数据的查询效果.实验结果表明,无论是准确率、召回率还是检索速率,MDSRS都体现出性能优势.未来将持续优化系统,设计新的功能,使其支持更丰富更多样化的数据类型(比如音频),同时优化存储与检索,实现并行查询等多种查询操作.
参考文献
Visual search engine for product images
∥
Very deep convolutional networks for large⁃scale image recognition
Scalable multimedia retrieval by deep learning hashing with relative similarity learning
∥
A study on different image retrieval techniques in image processing
Port container number recognition system based on improved YOLO and CRNN algorithm
∥
Cross⁃modal search for social networks via adversarial learning
Deep semantic⁃preserving ordinal hashing for cross⁃modal similarity search
面向文本检索的语义计算
Semantic computation for text retrieval
Word2Vec and Doc2Vec in unsupervised sentiment analysis of clinical discharge summaries
Comparison between LSA⁃LDA⁃lexical chains
∥
Relevance feedback:A power tool for interactive content⁃based image retrieval
Distinctive image features from scale⁃invariant keypoints
面向跨模态检索的音频数据库内容匹配方法研究
Research on content matching method of audio database for cross⁃modal retrieval
VSE++:Improving visual⁃semantic embeddings with hard negatives
Dual⁃path convolutional image⁃text embeddings with instance loss
Learning semantic concepts and order for image and sentence matching
∥
Stacked cross attention for image⁃text matching
∥
Learning fragment self-attention embeddings for image⁃text matching
∥
Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}