近年来,伴随着人工智能的发展及法院裁判文书的公开化,“智慧司法”、案例推荐成为热点问题.针对案例推荐中存在的推荐准确性差、传统知识图谱向量化表示精度不高等问题,提出基于知识图谱的案件推荐(Knowledge Graph based Case Recommendation,KGCR)模型.该模型以知识图谱为辅助信息,利用文本分类和信息抽取技术构建面向刑事案例的知识图谱,针对当事人的陈词供述,利用知识表示学习求解相似的案件,进一步实现法条推荐.针对TransH算法的负采样问题进行改进,提出FU⁃TransH算法模型.以公开的刑事判决书为数据集进行实验,实验结果表明,与相关的具有代表性的算法相比,该算法的推荐准确率更高.
关键词:知识图谱
;
信息抽取
;
表示学习
;
法条推荐
;
类案推荐
Abstract
In recent years,with the development of artificial intelligence and the openness of court judgment documents,intelligent justice and case recommendation have become hot issues. Aiming at the problems of poor recommendation accuracy,low accuracy of vectorized representation of traditional knowledge graphs in case recommendation. This paper proposes Knowledge Graph based Case Recommendation (KGCR) model,which uses knowledge map as auxiliary information to solve similar cases. It uses text classification and information extraction technology to build a knowledge map for criminal cases,and uses knowledge representation learning to solve similar cases according to the confession of the parties. Aiming at the negative sampling problem of TransH algorithm,the Fu⁃TransH algorithm is proposed. The experimental results show that,compared with the representative algorithms,the proposed algorithm can improve the recommendation accuracy and recall rate.
Keywords:knowledge graph
;
information extraction
;
representation learning
;
legal recommendation
;
case recommendation
Huang Zhigang, Xie Xinqiang, Ge Dong, Dou Lili, Cai Chenqiu, Dou Lili, Wang Tianyi. Case recommendation based on knowledge graph of judicial cases. Journal of nanjing University[J], 2021, 57(6): 1053-1063 doi:10.13232/j.cnki.jnju.2021.06.014
对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法.
知识图谱表示学习的目的是在不丢失知识图谱固有结构的条件下将知识图谱中的实体和关系嵌入向量空间,使用数值化向量对实体和关系进行表示,并对语义信息进行保留.表示学习获得广泛关注源于Mikolov et al[9]对词向量空间平移不变现象的研究.Mikolov et al提出并实现了Word2Vec词表示学习模型和工具包,使表示学习进入实际应用领域[10].知识表示学习的主要方法有距离模型[11]、多层神经网络[12]、张量神经网络模型[13]、矩阵分解模型[14]和翻译模型[15].由于翻译模型在性能上提升巨大,不仅大大降低参数数量,还提升了准确率,因此翻译模型成为目前知识表示学习的代表模型.
Hu et al[16]构建个人兴趣点敏感知识图谱,使用翻译模型算法进行实体向量化,通过相似度计算实体间相似度进行推荐.Zhang et al[17]提出CKE (Collaborative Knowledge Base Embedding)推荐系统框架,对知识图谱的结构、文本及图像进行综合考虑,使用翻译模型算法对知识图谱中的结构信息进行处理得到实体的向量特征,然后融合文本信息和图像信息得到用户推荐列表.Wang et al[18]将新闻内容中的每个单词与知识图中的相关实体相关联,通过翻译模型中的TransD算法获得知识的嵌入向量,将向量信息引入项目信息并形成推荐.
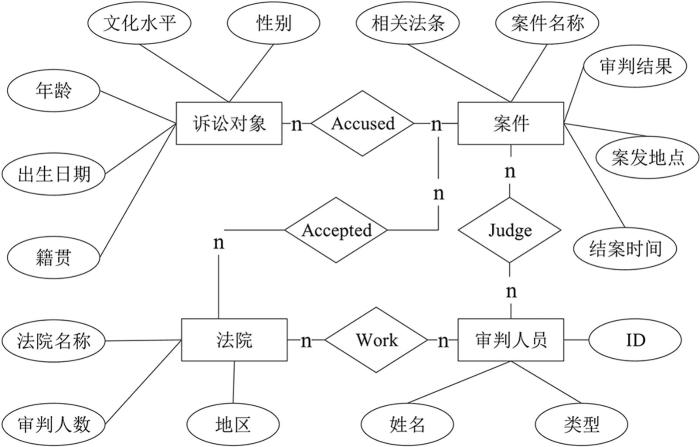
2 司法案例知识图谱构建
2.1 命名实体识别介绍
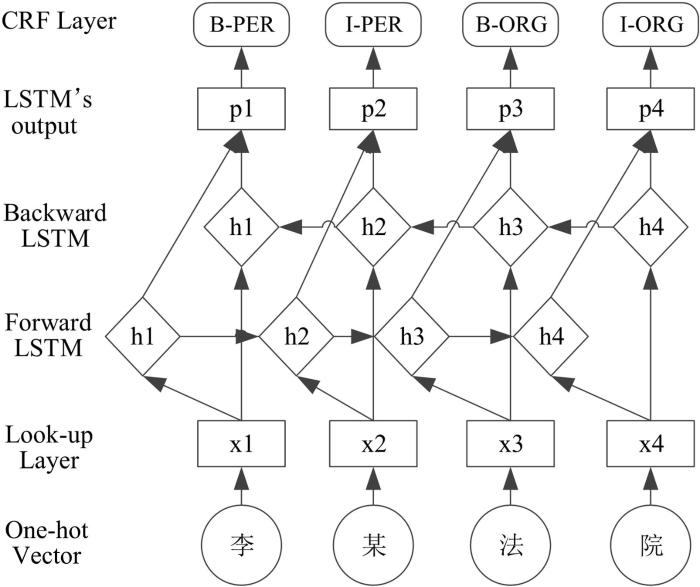
命名实体识别(Named Entity Recognition,NER)是自然语言处理的一个基础任务,目的是识别语料中人名、地名、组织机构名等命名实体.信息抽取就是从非结构化的文本中抽取结构化的数据和特定的关系.例如:“小李在1996年从清华大学毕业”,其中“小李”“1996年”“清华大学”都是命名实体,而这些实体包含了极为重要的信息:人物、时间、组织,其他词将这些实体串起来,才能表达这句话的完整语义.在一些专业领域,如化学、医药领域,经常出现如四氧化三铁、阿尔兹海默症等专业词汇,只通过简单的分词很难将这些重要的关键词汇识别出来,在这样的场景下NER就能发挥威力.传统的命名实体识别任务使用基于统计的机器学习方法将任务转化为序列标注或者分类问题.例如:冯静等[19]基于隐马尔可夫模型对桥梁检测文本进行命名体识别;王昌厚[20]提出条件随机场模型解决中文命名体识别问题;为了在特定领域提高命名实体识别效果,程名等[21]融合注意力机制和BiLSTM⁃CRF (Bi⁃Long Short⁃Term Memory⁃Conditional Radom Field)使模型有效学习上下文结构特征:注意力机制能输出不断变化的语义向量,可有效解决长序列语义稀释问题,BiLSTM⁃CRF模型将从文本中进行实体和属性抽取等问题转化为序列标注任务进行解决.
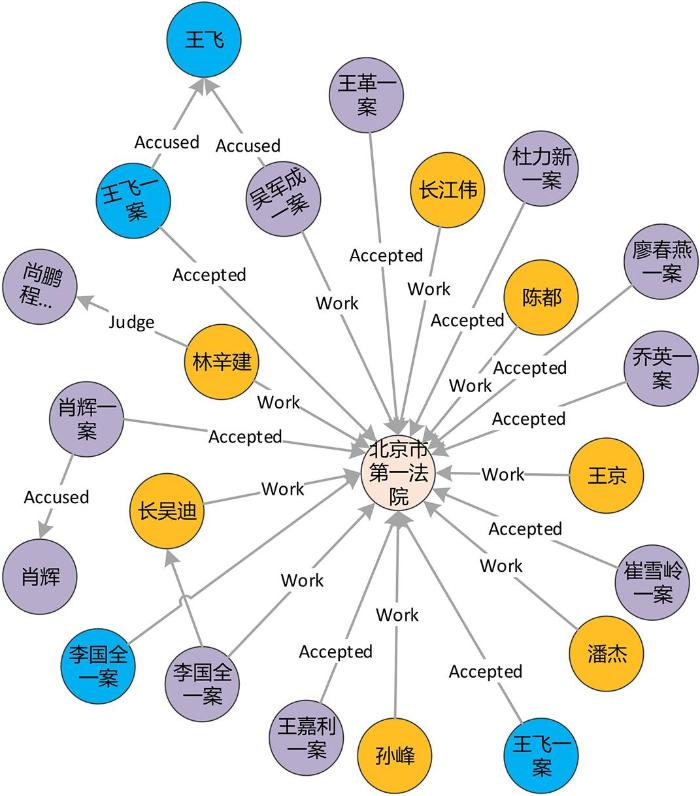
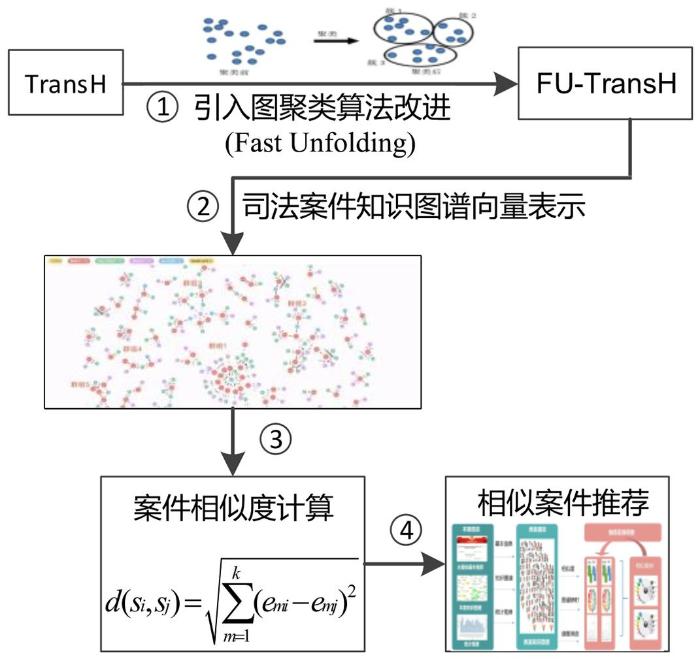
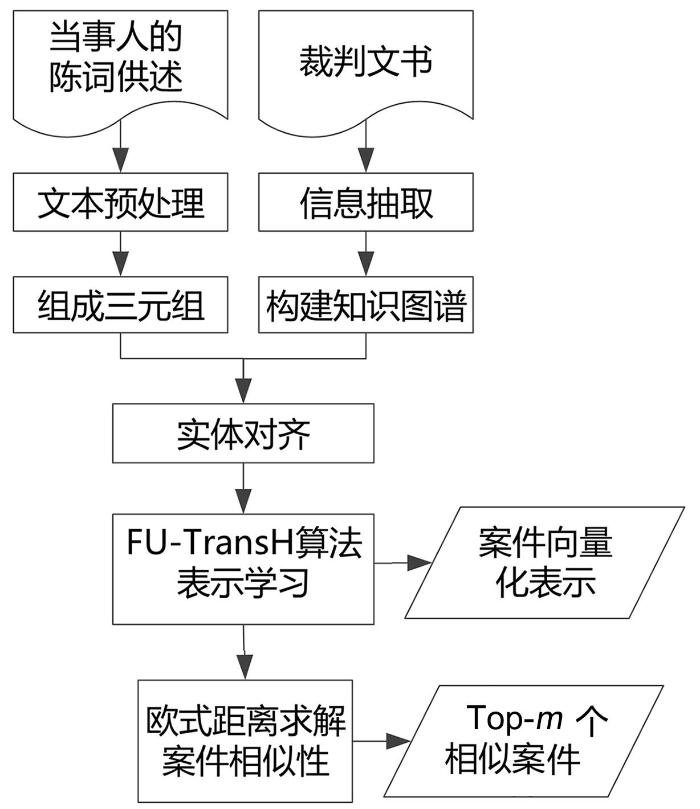
本节提出基于知识图谱的案件推荐模型(Knowledge Graph based Case Recommendation,KGCR),其整体框架如图5所示:(1)首先对传统的TransH算法进行改进,提出基于图聚类向量优化的案件知识图谱表征学习方法(FU⁃TransH),旨在提高实体向量化的准确性;(2)在构建的司法案例知识图谱基础上,利用改进的向量表征方法(FU⁃TransH)对司法案件知识图谱中所有的实体和关系进行向量化表征(Embedding)学习;
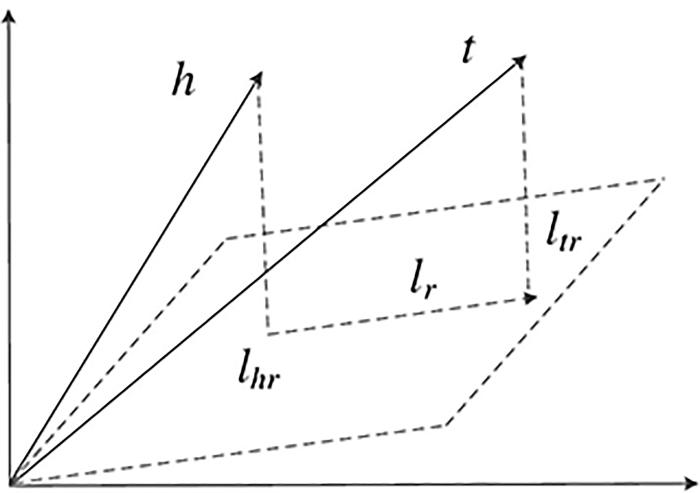
翻译模型的目的是使用向量对实体和关系进行向量化表示,将知识图谱中的实体和关系表示在向量空间中,并能对知识图谱的固有结构以及语义信息进行保留.Bordes et al[22]提出的TransE算法是翻译模型的代表算法.TransE算法对实体间一对一的关系有较好的结果,但对一对多、多对一和多对多的关系处理效果较差,主要是因为TransE在同一个平面上对实体和关系进行向量表示,因此在非一对一关系的情况下无法准确区分相似实体,造成不同实体的区分度不足,进而造成无法区分复杂关系的问题[23].为了能够处理实体间复杂的关系,方阳等[24]提出TransH算法,通过建立面向关系的超平面模型来改善上述问题.
Fast Unfolding是通过模块度进行社区划分判断的自底向上的图聚类算法[25].模块度可以衡量与评价社区划分的优劣,通常将模块度最大的社区划分作为最优社区划分.模块度(Modula⁃rity)指网络中连接社区结构内部顶点的边所占的比例减去在同样的社团结构下任意连接这两个节点的比例的期望值.模块度是度量社区划分优劣的重要标准,划分后的网络模块度值越大,说明社区划分的效果越好.Fast Unfolding算法便是基于模块度对社区划分的算法,它是一种迭代算法,主要目标是不断划分社区使划分后的整个网络的模块度不断增大.
链路预测的主要任务是,对于一个完整的三元组,给定预测t或给定预测r,从而验证模型预测实体的能力.选择三类不同的模型进行对比实验:第一类是基于TransE的距离模型,以TransE,TransH为代表;第二类是以SME (Structure Mapping Engine)为代表的语义匹配模型;第三类是基于矩阵分解的RESCAL(Research And Special Collections Available Locally)模型.
YeJ J. Research on intelligent statutes recommendation technology based on collaborative filtering and text relevance. Master Dissertation. Nanjing:Nanjing University,2019.
BlondelV D,GuillaumeJ L,LambiotteR,et al. Fast unfolding of communities in large networks. Journal of Statistical Mechanics:Theory and Experiment,2008,2008(10):P10008.
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
Legal question answering using ranking SVM and syntactic/semantic similarity
1
2014
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
基于刑事案例的知识图谱构建技术
1
2019
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
基于刑事案例的知识图谱构建技术
1
2019
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
1
2019
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
基于知识图谱的盗窃案件法律文书智能推理研究
1
2019
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
基于知识图谱的盗窃案件法律文书智能推理研究
1
2019
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
面向法律裁判文书的法条推荐方法
2
2019
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
... 对智能司法国内外都有相关的研究.国外,Winkels et al[1]发明了一种基于荷兰案例法的法律推荐系统,Kim et al[2]建立了一个结合法律信息检索和文本蕴含的法律问答系统.国内,陈彦光等[3]在公开的30余万份涉毒类案件中抽取实体建成了关于涉毒案件的知识图谱;马灿[4]提出“智慧司法”的知识图谱构建,并实现了关于案件的查询系统;乔钢柱等[5]实现了基于知识图谱的盗窃案件推理;张虎等[6]提出基于多模型融合的法条推荐方法,提高了法条推荐的准确率;叶菁菁[7]提出结合文本相似性和协同过滤技术的法条推荐,协同过滤缩小了备选法条的范围,解决了法条数目过多导致模型训练困难的问题;殷玥[8]利用神经网络提出基于注意力机制的循环卷积神经网络的法条推荐算法. ...
... 知识图谱表示学习的目的是在不丢失知识图谱固有结构的条件下将知识图谱中的实体和关系嵌入向量空间,使用数值化向量对实体和关系进行表示,并对语义信息进行保留.表示学习获得广泛关注源于Mikolov et al[9]对词向量空间平移不变现象的研究.Mikolov et al提出并实现了Word2Vec词表示学习模型和工具包,使表示学习进入实际应用领域[10].知识表示学习的主要方法有距离模型[11]、多层神经网络[12]、张量神经网络模型[13]、矩阵分解模型[14]和翻译模型[15].由于翻译模型在性能上提升巨大,不仅大大降低参数数量,还提升了准确率,因此翻译模型成为目前知识表示学习的代表模型. ...
知识表示学习研究进展
1
2016
... 知识图谱表示学习的目的是在不丢失知识图谱固有结构的条件下将知识图谱中的实体和关系嵌入向量空间,使用数值化向量对实体和关系进行表示,并对语义信息进行保留.表示学习获得广泛关注源于Mikolov et al[9]对词向量空间平移不变现象的研究.Mikolov et al提出并实现了Word2Vec词表示学习模型和工具包,使表示学习进入实际应用领域[10].知识表示学习的主要方法有距离模型[11]、多层神经网络[12]、张量神经网络模型[13]、矩阵分解模型[14]和翻译模型[15].由于翻译模型在性能上提升巨大,不仅大大降低参数数量,还提升了准确率,因此翻译模型成为目前知识表示学习的代表模型. ...
知识表示学习研究进展
1
2016
... 知识图谱表示学习的目的是在不丢失知识图谱固有结构的条件下将知识图谱中的实体和关系嵌入向量空间,使用数值化向量对实体和关系进行表示,并对语义信息进行保留.表示学习获得广泛关注源于Mikolov et al[9]对词向量空间平移不变现象的研究.Mikolov et al提出并实现了Word2Vec词表示学习模型和工具包,使表示学习进入实际应用领域[10].知识表示学习的主要方法有距离模型[11]、多层神经网络[12]、张量神经网络模型[13]、矩阵分解模型[14]和翻译模型[15].由于翻译模型在性能上提升巨大,不仅大大降低参数数量,还提升了准确率,因此翻译模型成为目前知识表示学习的代表模型. ...
Learning structured embeddings of knowledge bases
1
2011
... 知识图谱表示学习的目的是在不丢失知识图谱固有结构的条件下将知识图谱中的实体和关系嵌入向量空间,使用数值化向量对实体和关系进行表示,并对语义信息进行保留.表示学习获得广泛关注源于Mikolov et al[9]对词向量空间平移不变现象的研究.Mikolov et al提出并实现了Word2Vec词表示学习模型和工具包,使表示学习进入实际应用领域[10].知识表示学习的主要方法有距离模型[11]、多层神经网络[12]、张量神经网络模型[13]、矩阵分解模型[14]和翻译模型[15].由于翻译模型在性能上提升巨大,不仅大大降低参数数量,还提升了准确率,因此翻译模型成为目前知识表示学习的代表模型. ...
Reasoning with neural tensor networks for knowledge base completion
1
2013
... 知识图谱表示学习的目的是在不丢失知识图谱固有结构的条件下将知识图谱中的实体和关系嵌入向量空间,使用数值化向量对实体和关系进行表示,并对语义信息进行保留.表示学习获得广泛关注源于Mikolov et al[9]对词向量空间平移不变现象的研究.Mikolov et al提出并实现了Word2Vec词表示学习模型和工具包,使表示学习进入实际应用领域[10].知识表示学习的主要方法有距离模型[11]、多层神经网络[12]、张量神经网络模型[13]、矩阵分解模型[14]和翻译模型[15].由于翻译模型在性能上提升巨大,不仅大大降低参数数量,还提升了准确率,因此翻译模型成为目前知识表示学习的代表模型. ...
A semantic matching energy function for learning with multi?relational data
1
2014
... 知识图谱表示学习的目的是在不丢失知识图谱固有结构的条件下将知识图谱中的实体和关系嵌入向量空间,使用数值化向量对实体和关系进行表示,并对语义信息进行保留.表示学习获得广泛关注源于Mikolov et al[9]对词向量空间平移不变现象的研究.Mikolov et al提出并实现了Word2Vec词表示学习模型和工具包,使表示学习进入实际应用领域[10].知识表示学习的主要方法有距离模型[11]、多层神经网络[12]、张量神经网络模型[13]、矩阵分解模型[14]和翻译模型[15].由于翻译模型在性能上提升巨大,不仅大大降低参数数量,还提升了准确率,因此翻译模型成为目前知识表示学习的代表模型. ...
A three?way model for collective learning on multi?relational data
1
2011
... 知识图谱表示学习的目的是在不丢失知识图谱固有结构的条件下将知识图谱中的实体和关系嵌入向量空间,使用数值化向量对实体和关系进行表示,并对语义信息进行保留.表示学习获得广泛关注源于Mikolov et al[9]对词向量空间平移不变现象的研究.Mikolov et al提出并实现了Word2Vec词表示学习模型和工具包,使表示学习进入实际应用领域[10].知识表示学习的主要方法有距离模型[11]、多层神经网络[12]、张量神经网络模型[13]、矩阵分解模型[14]和翻译模型[15].由于翻译模型在性能上提升巨大,不仅大大降低参数数量,还提升了准确率,因此翻译模型成为目前知识表示学习的代表模型. ...
Knowledge graph embedding by translating on hyperplanes
1
2014
... 知识图谱表示学习的目的是在不丢失知识图谱固有结构的条件下将知识图谱中的实体和关系嵌入向量空间,使用数值化向量对实体和关系进行表示,并对语义信息进行保留.表示学习获得广泛关注源于Mikolov et al[9]对词向量空间平移不变现象的研究.Mikolov et al提出并实现了Word2Vec词表示学习模型和工具包,使表示学习进入实际应用领域[10].知识表示学习的主要方法有距离模型[11]、多层神经网络[12]、张量神经网络模型[13]、矩阵分解模型[14]和翻译模型[15].由于翻译模型在性能上提升巨大,不仅大大降低参数数量,还提升了准确率,因此翻译模型成为目前知识表示学习的代表模型. ...
A POI?sensitive knowledge graph based service recommendation method
1
2019
... Hu et al[16]构建个人兴趣点敏感知识图谱,使用翻译模型算法进行实体向量化,通过相似度计算实体间相似度进行推荐.Zhang et al[17]提出CKE (Collaborative Knowledge Base Embedding)推荐系统框架,对知识图谱的结构、文本及图像进行综合考虑,使用翻译模型算法对知识图谱中的结构信息进行处理得到实体的向量特征,然后融合文本信息和图像信息得到用户推荐列表.Wang et al[18]将新闻内容中的每个单词与知识图中的相关实体相关联,通过翻译模型中的TransD算法获得知识的嵌入向量,将向量信息引入项目信息并形成推荐. ...
Collaborative knowledge base embedding for recommender systems
1
2016
... Hu et al[16]构建个人兴趣点敏感知识图谱,使用翻译模型算法进行实体向量化,通过相似度计算实体间相似度进行推荐.Zhang et al[17]提出CKE (Collaborative Knowledge Base Embedding)推荐系统框架,对知识图谱的结构、文本及图像进行综合考虑,使用翻译模型算法对知识图谱中的结构信息进行处理得到实体的向量特征,然后融合文本信息和图像信息得到用户推荐列表.Wang et al[18]将新闻内容中的每个单词与知识图中的相关实体相关联,通过翻译模型中的TransD算法获得知识的嵌入向量,将向量信息引入项目信息并形成推荐. ...
DKN:Deep knowledge?aware network for news recom?mendation
1
2018
... Hu et al[16]构建个人兴趣点敏感知识图谱,使用翻译模型算法进行实体向量化,通过相似度计算实体间相似度进行推荐.Zhang et al[17]提出CKE (Collaborative Knowledge Base Embedding)推荐系统框架,对知识图谱的结构、文本及图像进行综合考虑,使用翻译模型算法对知识图谱中的结构信息进行处理得到实体的向量特征,然后融合文本信息和图像信息得到用户推荐列表.Wang et al[18]将新闻内容中的每个单词与知识图中的相关实体相关联,通过翻译模型中的TransD算法获得知识的嵌入向量,将向量信息引入项目信息并形成推荐. ...
基于隐马尔可夫模型的桥梁检测文本命名实体识别
1
2020
... 命名实体识别(Named Entity Recognition,NER)是自然语言处理的一个基础任务,目的是识别语料中人名、地名、组织机构名等命名实体.信息抽取就是从非结构化的文本中抽取结构化的数据和特定的关系.例如:“小李在1996年从清华大学毕业”,其中“小李”“1996年”“清华大学”都是命名实体,而这些实体包含了极为重要的信息:人物、时间、组织,其他词将这些实体串起来,才能表达这句话的完整语义.在一些专业领域,如化学、医药领域,经常出现如四氧化三铁、阿尔兹海默症等专业词汇,只通过简单的分词很难将这些重要的关键词汇识别出来,在这样的场景下NER就能发挥威力.传统的命名实体识别任务使用基于统计的机器学习方法将任务转化为序列标注或者分类问题.例如:冯静等[19]基于隐马尔可夫模型对桥梁检测文本进行命名体识别;王昌厚[20]提出条件随机场模型解决中文命名体识别问题;为了在特定领域提高命名实体识别效果,程名等[21]融合注意力机制和BiLSTM⁃CRF (Bi⁃Long Short⁃Term Memory⁃Conditional Radom Field)使模型有效学习上下文结构特征:注意力机制能输出不断变化的语义向量,可有效解决长序列语义稀释问题,BiLSTM⁃CRF模型将从文本中进行实体和属性抽取等问题转化为序列标注任务进行解决. ...
基于隐马尔可夫模型的桥梁检测文本命名实体识别
1
2020
... 命名实体识别(Named Entity Recognition,NER)是自然语言处理的一个基础任务,目的是识别语料中人名、地名、组织机构名等命名实体.信息抽取就是从非结构化的文本中抽取结构化的数据和特定的关系.例如:“小李在1996年从清华大学毕业”,其中“小李”“1996年”“清华大学”都是命名实体,而这些实体包含了极为重要的信息:人物、时间、组织,其他词将这些实体串起来,才能表达这句话的完整语义.在一些专业领域,如化学、医药领域,经常出现如四氧化三铁、阿尔兹海默症等专业词汇,只通过简单的分词很难将这些重要的关键词汇识别出来,在这样的场景下NER就能发挥威力.传统的命名实体识别任务使用基于统计的机器学习方法将任务转化为序列标注或者分类问题.例如:冯静等[19]基于隐马尔可夫模型对桥梁检测文本进行命名体识别;王昌厚[20]提出条件随机场模型解决中文命名体识别问题;为了在特定领域提高命名实体识别效果,程名等[21]融合注意力机制和BiLSTM⁃CRF (Bi⁃Long Short⁃Term Memory⁃Conditional Radom Field)使模型有效学习上下文结构特征:注意力机制能输出不断变化的语义向量,可有效解决长序列语义稀释问题,BiLSTM⁃CRF模型将从文本中进行实体和属性抽取等问题转化为序列标注任务进行解决. ...
基于条件随机场的中文命名体识别
1
2012
... 命名实体识别(Named Entity Recognition,NER)是自然语言处理的一个基础任务,目的是识别语料中人名、地名、组织机构名等命名实体.信息抽取就是从非结构化的文本中抽取结构化的数据和特定的关系.例如:“小李在1996年从清华大学毕业”,其中“小李”“1996年”“清华大学”都是命名实体,而这些实体包含了极为重要的信息:人物、时间、组织,其他词将这些实体串起来,才能表达这句话的完整语义.在一些专业领域,如化学、医药领域,经常出现如四氧化三铁、阿尔兹海默症等专业词汇,只通过简单的分词很难将这些重要的关键词汇识别出来,在这样的场景下NER就能发挥威力.传统的命名实体识别任务使用基于统计的机器学习方法将任务转化为序列标注或者分类问题.例如:冯静等[19]基于隐马尔可夫模型对桥梁检测文本进行命名体识别;王昌厚[20]提出条件随机场模型解决中文命名体识别问题;为了在特定领域提高命名实体识别效果,程名等[21]融合注意力机制和BiLSTM⁃CRF (Bi⁃Long Short⁃Term Memory⁃Conditional Radom Field)使模型有效学习上下文结构特征:注意力机制能输出不断变化的语义向量,可有效解决长序列语义稀释问题,BiLSTM⁃CRF模型将从文本中进行实体和属性抽取等问题转化为序列标注任务进行解决. ...
融合注意力机制和Bi?LSTM+CRF的渔业标准命名实体识别
1
2020
... 命名实体识别(Named Entity Recognition,NER)是自然语言处理的一个基础任务,目的是识别语料中人名、地名、组织机构名等命名实体.信息抽取就是从非结构化的文本中抽取结构化的数据和特定的关系.例如:“小李在1996年从清华大学毕业”,其中“小李”“1996年”“清华大学”都是命名实体,而这些实体包含了极为重要的信息:人物、时间、组织,其他词将这些实体串起来,才能表达这句话的完整语义.在一些专业领域,如化学、医药领域,经常出现如四氧化三铁、阿尔兹海默症等专业词汇,只通过简单的分词很难将这些重要的关键词汇识别出来,在这样的场景下NER就能发挥威力.传统的命名实体识别任务使用基于统计的机器学习方法将任务转化为序列标注或者分类问题.例如:冯静等[19]基于隐马尔可夫模型对桥梁检测文本进行命名体识别;王昌厚[20]提出条件随机场模型解决中文命名体识别问题;为了在特定领域提高命名实体识别效果,程名等[21]融合注意力机制和BiLSTM⁃CRF (Bi⁃Long Short⁃Term Memory⁃Conditional Radom Field)使模型有效学习上下文结构特征:注意力机制能输出不断变化的语义向量,可有效解决长序列语义稀释问题,BiLSTM⁃CRF模型将从文本中进行实体和属性抽取等问题转化为序列标注任务进行解决. ...
融合注意力机制和Bi?LSTM+CRF的渔业标准命名实体识别
1
2020
... 命名实体识别(Named Entity Recognition,NER)是自然语言处理的一个基础任务,目的是识别语料中人名、地名、组织机构名等命名实体.信息抽取就是从非结构化的文本中抽取结构化的数据和特定的关系.例如:“小李在1996年从清华大学毕业”,其中“小李”“1996年”“清华大学”都是命名实体,而这些实体包含了极为重要的信息:人物、时间、组织,其他词将这些实体串起来,才能表达这句话的完整语义.在一些专业领域,如化学、医药领域,经常出现如四氧化三铁、阿尔兹海默症等专业词汇,只通过简单的分词很难将这些重要的关键词汇识别出来,在这样的场景下NER就能发挥威力.传统的命名实体识别任务使用基于统计的机器学习方法将任务转化为序列标注或者分类问题.例如:冯静等[19]基于隐马尔可夫模型对桥梁检测文本进行命名体识别;王昌厚[20]提出条件随机场模型解决中文命名体识别问题;为了在特定领域提高命名实体识别效果,程名等[21]融合注意力机制和BiLSTM⁃CRF (Bi⁃Long Short⁃Term Memory⁃Conditional Radom Field)使模型有效学习上下文结构特征:注意力机制能输出不断变化的语义向量,可有效解决长序列语义稀释问题,BiLSTM⁃CRF模型将从文本中进行实体和属性抽取等问题转化为序列标注任务进行解决. ...
融合注意力机制和Bi?LSTM+CRF的渔业标准命名实体识别
1
2020
... 命名实体识别(Named Entity Recognition,NER)是自然语言处理的一个基础任务,目的是识别语料中人名、地名、组织机构名等命名实体.信息抽取就是从非结构化的文本中抽取结构化的数据和特定的关系.例如:“小李在1996年从清华大学毕业”,其中“小李”“1996年”“清华大学”都是命名实体,而这些实体包含了极为重要的信息:人物、时间、组织,其他词将这些实体串起来,才能表达这句话的完整语义.在一些专业领域,如化学、医药领域,经常出现如四氧化三铁、阿尔兹海默症等专业词汇,只通过简单的分词很难将这些重要的关键词汇识别出来,在这样的场景下NER就能发挥威力.传统的命名实体识别任务使用基于统计的机器学习方法将任务转化为序列标注或者分类问题.例如:冯静等[19]基于隐马尔可夫模型对桥梁检测文本进行命名体识别;王昌厚[20]提出条件随机场模型解决中文命名体识别问题;为了在特定领域提高命名实体识别效果,程名等[21]融合注意力机制和BiLSTM⁃CRF (Bi⁃Long Short⁃Term Memory⁃Conditional Radom Field)使模型有效学习上下文结构特征:注意力机制能输出不断变化的语义向量,可有效解决长序列语义稀释问题,BiLSTM⁃CRF模型将从文本中进行实体和属性抽取等问题转化为序列标注任务进行解决. ...
Translating embeddings for modeling multi?relational data
1
2013
... 翻译模型的目的是使用向量对实体和关系进行向量化表示,将知识图谱中的实体和关系表示在向量空间中,并能对知识图谱的固有结构以及语义信息进行保留.Bordes et al[22]提出的TransE算法是翻译模型的代表算法.TransE算法对实体间一对一的关系有较好的结果,但对一对多、多对一和多对多的关系处理效果较差,主要是因为TransE在同一个平面上对实体和关系进行向量表示,因此在非一对一关系的情况下无法准确区分相似实体,造成不同实体的区分度不足,进而造成无法区分复杂关系的问题[23].为了能够处理实体间复杂的关系,方阳等[24]提出TransH算法,通过建立面向关系的超平面模型来改善上述问题. ...
STransH:一种改进的基于翻译模型的知识表示模型
1
2019
... 翻译模型的目的是使用向量对实体和关系进行向量化表示,将知识图谱中的实体和关系表示在向量空间中,并能对知识图谱的固有结构以及语义信息进行保留.Bordes et al[22]提出的TransE算法是翻译模型的代表算法.TransE算法对实体间一对一的关系有较好的结果,但对一对多、多对一和多对多的关系处理效果较差,主要是因为TransE在同一个平面上对实体和关系进行向量表示,因此在非一对一关系的情况下无法准确区分相似实体,造成不同实体的区分度不足,进而造成无法区分复杂关系的问题[23].为了能够处理实体间复杂的关系,方阳等[24]提出TransH算法,通过建立面向关系的超平面模型来改善上述问题. ...
STransH:一种改进的基于翻译模型的知识表示模型
1
2019
... 翻译模型的目的是使用向量对实体和关系进行向量化表示,将知识图谱中的实体和关系表示在向量空间中,并能对知识图谱的固有结构以及语义信息进行保留.Bordes et al[22]提出的TransE算法是翻译模型的代表算法.TransE算法对实体间一对一的关系有较好的结果,但对一对多、多对一和多对多的关系处理效果较差,主要是因为TransE在同一个平面上对实体和关系进行向量表示,因此在非一对一关系的情况下无法准确区分相似实体,造成不同实体的区分度不足,进而造成无法区分复杂关系的问题[23].为了能够处理实体间复杂的关系,方阳等[24]提出TransH算法,通过建立面向关系的超平面模型来改善上述问题. ...
一种改进的基于翻译的知识图谱表示方法
1
2018
... 翻译模型的目的是使用向量对实体和关系进行向量化表示,将知识图谱中的实体和关系表示在向量空间中,并能对知识图谱的固有结构以及语义信息进行保留.Bordes et al[22]提出的TransE算法是翻译模型的代表算法.TransE算法对实体间一对一的关系有较好的结果,但对一对多、多对一和多对多的关系处理效果较差,主要是因为TransE在同一个平面上对实体和关系进行向量表示,因此在非一对一关系的情况下无法准确区分相似实体,造成不同实体的区分度不足,进而造成无法区分复杂关系的问题[23].为了能够处理实体间复杂的关系,方阳等[24]提出TransH算法,通过建立面向关系的超平面模型来改善上述问题. ...
一种改进的基于翻译的知识图谱表示方法
1
2018
... 翻译模型的目的是使用向量对实体和关系进行向量化表示,将知识图谱中的实体和关系表示在向量空间中,并能对知识图谱的固有结构以及语义信息进行保留.Bordes et al[22]提出的TransE算法是翻译模型的代表算法.TransE算法对实体间一对一的关系有较好的结果,但对一对多、多对一和多对多的关系处理效果较差,主要是因为TransE在同一个平面上对实体和关系进行向量表示,因此在非一对一关系的情况下无法准确区分相似实体,造成不同实体的区分度不足,进而造成无法区分复杂关系的问题[23].为了能够处理实体间复杂的关系,方阳等[24]提出TransH算法,通过建立面向关系的超平面模型来改善上述问题. ...
2
2008
... Fast Unfolding是通过模块度进行社区划分判断的自底向上的图聚类算法[25].模块度可以衡量与评价社区划分的优劣,通常将模块度最大的社区划分作为最优社区划分.模块度(Modula⁃rity)指网络中连接社区结构内部顶点的边所占的比例减去在同样的社团结构下任意连接这两个节点的比例的期望值.模块度是度量社区划分优劣的重要标准,划分后的网络模块度值越大,说明社区划分的效果越好.Fast Unfolding算法便是基于模块度对社区划分的算法,它是一种迭代算法,主要目标是不断划分社区使划分后的整个网络的模块度不断增大. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}