Time series anomaly detection aims to detect anomalies from normal values giving observed time series. However,existing methods are difficult to model sophisticated time series since they are either non⁃stochastic or require explicit data posterior distribution. Also,those methods are in lack of mechanisms to handle missing values and to leverage prior knowledge (such as occasionally available labels). To address the above issues,this paper introduces SALAD (Stochastic Adversarial Learned Anomaly Detection),a novel unsupervised anomaly detection model based on generative adversarial networks for time series. In the original space,the generative adversarial network and the auto⁃encoder network are combined,and the discriminant loss and absolute loss are fully utilized to accomplish data reconstruction. In the hidden space,in order to learn a more compact stochastic representation of the distribution of the hidden variables in the auto⁃encoder to the original data,and the generative adversarial network is also introduced to constrain the convergence of the hidden variables so that they are closer to the prior distribution. The introduced data⁃imputation method introduced in the training process is a more reasonable mechanism for handling missing values. The proposed contrast reconstruction loss enables SALAD to make full use of the small amount of labeled anomalous data. Through extensive experimental results on the dataset of this paper,it is shown that the F1 scores of the model in this paper are significantly improved over the existing baseline methods in both the cases of completely unsupervised and using partial anomaly labels.
Shao Shikuan, Zhang Hongjun, Xiao Qinfeng, Wang Jing, Liu Xiaohui, Lin Youfang. Time series anomaly detection based on unsupervised adversarial learning. Journal of nanjing University[J], 2021, 57(6): 1042-1052 doi:10.13232/j.cnki.jnju.2021.06.013
Kieu et al[3]和Zhang et al[4]提出基于自编码器的异常检测模型,在正常数据上训练时使用重构误差作为损失函数;在测试阶段,重构误差作为异常分数超过设定的阈值,则判定为异常数据.虽然它们是无监督的方法,但是自编码器的结构过于简单,缺少对自编码器隐变量的正则化,导致这些方法难以对复杂的时间序列中复杂的数据分布和大量的非高斯噪声进行建模.变分自编码器(Variational Auto⁃Encoders,VAEs)在自编码器的基础上,对隐变量增加了约束,并加入隐变量的随机采样过程,使基于变分自编码器的异常检测模型对复杂的数据分布和噪声更加鲁棒.An and Cho[5]首先将变分自编码器用作异常检测,Xu et al[1]将变分自编码器应用到时间序列异常检测.虽然这些基于变分自编码器的模型提升了对复杂数据分布和噪声的建模能力,然而,变分自编码器容易生成模糊的样本.
1.2 基于生成对抗神经网络的异常检测
与变分自编码器相比,使用对抗训练的生成对抗神经网络生成的样本细节更加清晰.Zenati et al[6]提出基于生成对抗神经网络的图像异常检测模型.Li et al[7]提出基于生成对抗神经网络的时间序列异常检测模型,但在检测异常阶段需要经过多次迭代才能得到相应的输入样本对应的隐空间变量,造成额外的计算开销和时间消耗.Zhou et al[8]结合自编码器和生成对抗神经网络提出针对时间序列的异常检测模型,但这个模型不仅要求数据有周期时间序列,还要在每个周期的固定位置采样.这些限制导致模型的实用性不强,没有充分发挥生成对抗神经网络对复杂数据分布的建模能力.
传统的对抗自编码器(Adversarial Auto⁃Encoders,AAEs)会在隐空间中通过对抗训练过程施加一个先验分布[11]并且输出样本会使用一个重构损失来进行训练,而本研究将判别损失和重构损失结合起来进行训练.在训练过程中,传统对抗自编码器AAEs中由解码器产生的重构损失导致重构的样本过于平滑,对下游任务会产生非常不利的影响.和Pidhorskyi et al[12]类似,本文通过原始空间判别器在解码器的输出上引入一个对抗正则化项来减少平滑并增加重构之后的细节信息,不同的是,本文使用解码器重构之后的样本作为原始空间判别器的输入,而不是将这一隐变量的先验分布产生的重构样本输入原始空间判别器.
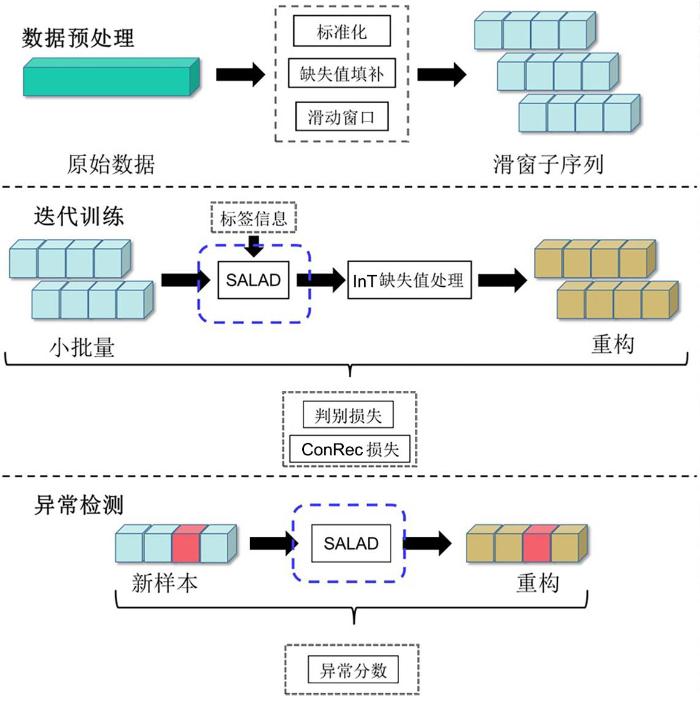
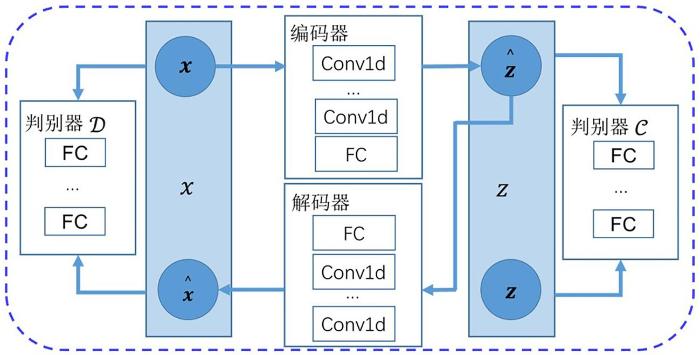
数据预处理之后,将预处理完的时序数据输入训练模块来学习序列的正常模式,SALAD模型包含四个部分:编码器、解码器、原始空间判别器、隐空间判别器.首先提出一种全新的缺失值处理方法InT (Imputation in Training),在每一轮的网络迭代训练过程中,使用当前的网络对缺失值进行预测,使用预测值对缺失进行相应的填补,填补完成后继续进行网络训练.编码器将输入的序列编码成隐变量输入解码器,解码器将输入的隐变量重新解码回原始空间.为了使自编码重构过程能够利用可使用的标签信息{14】,引入一个全新的损失函数——对比重构损失(ConRec),能够根据标签的比率灵活调整重构参数.同时,为了确保编码器与解码器的重构能够更加稳健,引入原始空间判别器来判别重构样本和原始样本,期望解码器尽可能地解码原始空间中的数据.此外,引入隐空间判别器来判别先验数据分布和编码器编码出的隐变量,确保编码出的隐变量能够尽可能地服从预定义的先验分布,使模型在建模复杂时序时表现出更好的性能.由此,缺失值填补和网络训练交替进行,使缺失值的填补更加可信.
传统的重构损失无法利用少量的标签信息,而本文提出对比重构损失函数,在函数中增加对于异常标签样本的特定损失部分.对于训练过程中的正常样本,和传统重构损失的思想类似,也是尽可能地减小原始样本和重构样本之间的差异.而对于异常样本,则异常点与正常点之间的差异很大,异常点应该在重构之后尽可能地远离原始的异常点.受Hadsell et al[15]的启发,将损失函数分成两项来分别处理正常样本和异常样本,对比重构(ConRec)的损失函数定义如下:
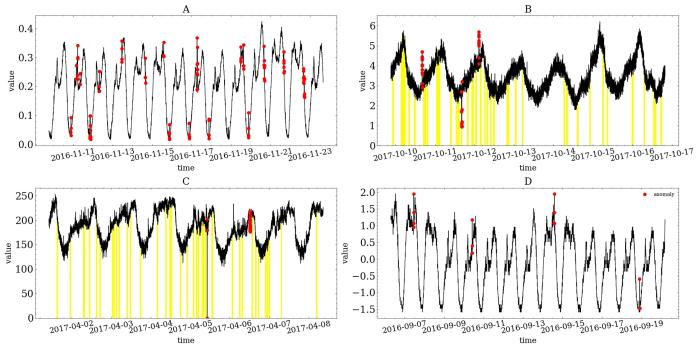
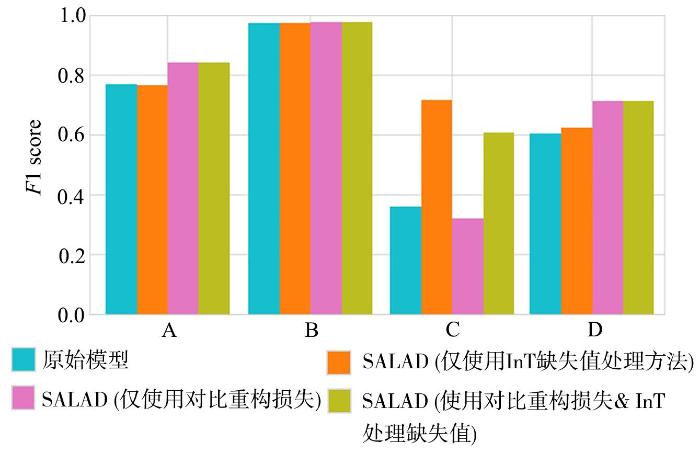
Donut[1]是一种基于VAE的时序异常检测方法,它使用专门设计的方法,包括M⁃ELBO、缺失数据注入和MCMC (Markov Chain Monte Carlo)缺失值填充方法,可以处理包含缺失值和异常值的时序数据集.对于低缺失率和低异常率的情况(数据集C),SALAD的实验效果和Donut比较接近,因为这两种方法都有处理缺失值和异常值的具体方法.但是,当数据集中的缺失值和异常值比较多(数据集B)并应用了无监督的实验设置时,SALAD的实验效果就大大超过Donut,说明SALAD在面对完全无监督的情况下,建模复杂时序的能力比Donut效果更好.此外,当有少量标签可用时,SALAD在数据集A和D上获得了比Donut更显著的提升.在数据集E上的实验结果证明SALAD在无监督实验设置下,建模一般时序数据的能力超过了Donut.
... Kieu et al[3]和Zhang et al[4]提出基于自编码器的异常检测模型,在正常数据上训练时使用重构误差作为损失函数;在测试阶段,重构误差作为异常分数超过设定的阈值,则判定为异常数据.虽然它们是无监督的方法,但是自编码器的结构过于简单,缺少对自编码器隐变量的正则化,导致这些方法难以对复杂的时间序列中复杂的数据分布和大量的非高斯噪声进行建模.变分自编码器(Variational Auto⁃Encoders,VAEs)在自编码器的基础上,对隐变量增加了约束,并加入隐变量的随机采样过程,使基于变分自编码器的异常检测模型对复杂的数据分布和噪声更加鲁棒.An and Cho[5]首先将变分自编码器用作异常检测,Xu et al[1]将变分自编码器应用到时间序列异常检测.虽然这些基于变分自编码器的模型提升了对复杂数据分布和噪声的建模能力,然而,变分自编码器容易生成模糊的样本. ...
... Donut[1]:基于变分自编码器的单变量时序异常检测方法. ...
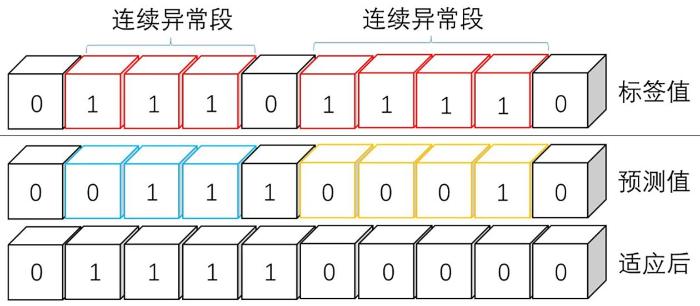
... 本文使用的评价指标是基于F1 score定义的.实际应用中,传统的F1 score基于点对点的方式逐点评估,但对于运维人员这种评估方式不准确.经常遇到的一种情况是成段连续的异常点,在这种情况下点对点的F1 score的评估方式很低效.另一种评估方式是在这段连续的异常点上,如果在一定的延迟下检测出任何一个异常点,则整段序列都判断为异常.这种改进的F1 score评估方式由Xu et al[1]提出并被广泛应用,本文也使用这种评价设置方式. ...
Outlier detection for time series with recurrent autoencoder ensembles
1
2019
... Kieu et al[3]和Zhang et al[4]提出基于自编码器的异常检测模型,在正常数据上训练时使用重构误差作为损失函数;在测试阶段,重构误差作为异常分数超过设定的阈值,则判定为异常数据.虽然它们是无监督的方法,但是自编码器的结构过于简单,缺少对自编码器隐变量的正则化,导致这些方法难以对复杂的时间序列中复杂的数据分布和大量的非高斯噪声进行建模.变分自编码器(Variational Auto⁃Encoders,VAEs)在自编码器的基础上,对隐变量增加了约束,并加入隐变量的随机采样过程,使基于变分自编码器的异常检测模型对复杂的数据分布和噪声更加鲁棒.An and Cho[5]首先将变分自编码器用作异常检测,Xu et al[1]将变分自编码器应用到时间序列异常检测.虽然这些基于变分自编码器的模型提升了对复杂数据分布和噪声的建模能力,然而,变分自编码器容易生成模糊的样本. ...
A deep neural network for unsupervised anomaly detection and diagnosis in multivariate time series data
1
2019
... Kieu et al[3]和Zhang et al[4]提出基于自编码器的异常检测模型,在正常数据上训练时使用重构误差作为损失函数;在测试阶段,重构误差作为异常分数超过设定的阈值,则判定为异常数据.虽然它们是无监督的方法,但是自编码器的结构过于简单,缺少对自编码器隐变量的正则化,导致这些方法难以对复杂的时间序列中复杂的数据分布和大量的非高斯噪声进行建模.变分自编码器(Variational Auto⁃Encoders,VAEs)在自编码器的基础上,对隐变量增加了约束,并加入隐变量的随机采样过程,使基于变分自编码器的异常检测模型对复杂的数据分布和噪声更加鲁棒.An and Cho[5]首先将变分自编码器用作异常检测,Xu et al[1]将变分自编码器应用到时间序列异常检测.虽然这些基于变分自编码器的模型提升了对复杂数据分布和噪声的建模能力,然而,变分自编码器容易生成模糊的样本. ...
Variational autoencoder based anomaly detection using reconstruction probability
1
2015
... Kieu et al[3]和Zhang et al[4]提出基于自编码器的异常检测模型,在正常数据上训练时使用重构误差作为损失函数;在测试阶段,重构误差作为异常分数超过设定的阈值,则判定为异常数据.虽然它们是无监督的方法,但是自编码器的结构过于简单,缺少对自编码器隐变量的正则化,导致这些方法难以对复杂的时间序列中复杂的数据分布和大量的非高斯噪声进行建模.变分自编码器(Variational Auto⁃Encoders,VAEs)在自编码器的基础上,对隐变量增加了约束,并加入隐变量的随机采样过程,使基于变分自编码器的异常检测模型对复杂的数据分布和噪声更加鲁棒.An and Cho[5]首先将变分自编码器用作异常检测,Xu et al[1]将变分自编码器应用到时间序列异常检测.虽然这些基于变分自编码器的模型提升了对复杂数据分布和噪声的建模能力,然而,变分自编码器容易生成模糊的样本. ...
Adversarially learned anomaly detection
1
2018
... 与变分自编码器相比,使用对抗训练的生成对抗神经网络生成的样本细节更加清晰.Zenati et al[6]提出基于生成对抗神经网络的图像异常检测模型.Li et al[7]提出基于生成对抗神经网络的时间序列异常检测模型,但在检测异常阶段需要经过多次迭代才能得到相应的输入样本对应的隐空间变量,造成额外的计算开销和时间消耗.Zhou et al[8]结合自编码器和生成对抗神经网络提出针对时间序列的异常检测模型,但这个模型不仅要求数据有周期时间序列,还要在每个周期的固定位置采样.这些限制导致模型的实用性不强,没有充分发挥生成对抗神经网络对复杂数据分布的建模能力. ...
MAD?GAN:Multivariate anomaly detection for time series data with generative adversarial networks
3
2019
... 与变分自编码器相比,使用对抗训练的生成对抗神经网络生成的样本细节更加清晰.Zenati et al[6]提出基于生成对抗神经网络的图像异常检测模型.Li et al[7]提出基于生成对抗神经网络的时间序列异常检测模型,但在检测异常阶段需要经过多次迭代才能得到相应的输入样本对应的隐空间变量,造成额外的计算开销和时间消耗.Zhou et al[8]结合自编码器和生成对抗神经网络提出针对时间序列的异常检测模型,但这个模型不仅要求数据有周期时间序列,还要在每个周期的固定位置采样.这些限制导致模型的实用性不强,没有充分发挥生成对抗神经网络对复杂数据分布的建模能力. ...
BeatGAN:Anomalous rhythm detection using adversarially generated time series
3
2019
... 与变分自编码器相比,使用对抗训练的生成对抗神经网络生成的样本细节更加清晰.Zenati et al[6]提出基于生成对抗神经网络的图像异常检测模型.Li et al[7]提出基于生成对抗神经网络的时间序列异常检测模型,但在检测异常阶段需要经过多次迭代才能得到相应的输入样本对应的隐空间变量,造成额外的计算开销和时间消耗.Zhou et al[8]结合自编码器和生成对抗神经网络提出针对时间序列的异常检测模型,但这个模型不仅要求数据有周期时间序列,还要在每个周期的固定位置采样.这些限制导致模型的实用性不强,没有充分发挥生成对抗神经网络对复杂数据分布的建模能力. ...
Dimensionality reduction by learning an invariant mapping
2
2006
... 传统的重构损失无法利用少量的标签信息,而本文提出对比重构损失函数,在函数中增加对于异常标签样本的特定损失部分.对于训练过程中的正常样本,和传统重构损失的思想类似,也是尽可能地减小原始样本和重构样本之间的差异.而对于异常样本,则异常点与正常点之间的差异很大,异常点应该在重构之后尽可能地远离原始的异常点.受Hadsell et al[15]的启发,将损失函数分成两项来分别处理正常样本和异常样本,对比重构(ConRec)的损失函数定义如下: ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}