


受人类认知学习过程[8]的启发,本文提出一个新的认知学习框架,通过选取少量有效样本对深层主动识别模型进行逐步微调,旨在学习新的实例并在实际应用中随时适应被识别对象的变化.
1 少样本识别问题与应用现状
1.1 少样本识别与主动学习
为了获取有标签训练样本,有很多方式通过指定查询策略提高学习效率,最常用的查询方法是不确定性抽样[11].这个框架中,主动学习模型查询它最不确定的样本,但这种策略只考虑最可能标签的信息,并将剩余标签的分布信息进行强制转换.为了纠正这一点,边际抽样[12]方法采用多类不确定性抽样的策略,然而对于非常大标签集的问题,这种方法仍然忽略了其余类的大部分输出分布.Lines and Bagnall[13]提出一种更通用的不确定度抽样策略,将熵作为不确定度度量,并基于互信息理论,提出基于分歧的贝叶斯主动学习方法(Bayesian Active Learning by Disagreement,BALD).此外,Dayoub et al[14]提出一种基于事件的贝叶斯神经网络主动学习方法.但以上这些查询策略没有像人类那样进行认知学习,也就不能充分利用过往经验来提高学习的效果.
1.2 深度学习和感知学习
然而,在深度学习情境中,需要大量的标记样本来训练模型以提高其识别能力,但这不符合人类的学习情况,因为人类通常选择最有效的材料来主动学习.
本文设计了一种新的深度主动识别框架,通过选择有效的样本对深度模型进行逐步微调,来适应水下对抗应用领域中对象的复杂变化模式.
2 基于在线感知学习的深度主动学习网络构建
为了模仿人类的学习机制,深度模型使用一小部分选定的标记数据进行在线微调(图1).由于小样本集的训练会带来过拟合,而丢弃(Dropout)的方法可以防止过拟合.此外,深度模型应能识别确定和不确定样本,不确定值可通过随机前向传播算法(Stochastic Forward Passes Method)计算.
图1
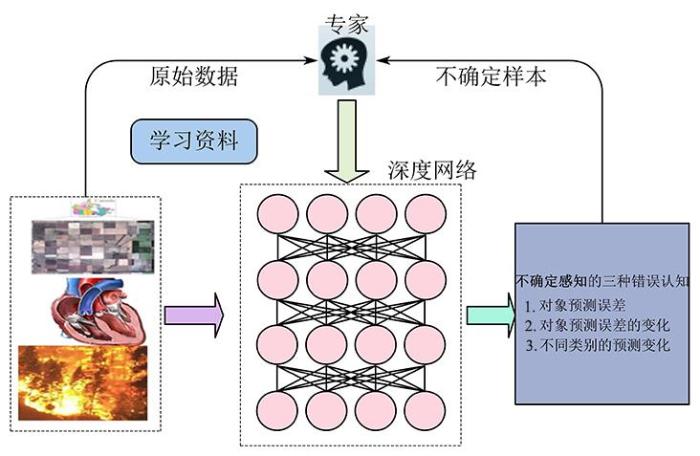
图1
基于主动学习的感知学习框架
Fig.1
The cognitive learning framework based on active learning
此外还有两个问题:首先,在专家的帮助下,模型可以选择最有效的样本作为微调数据;第二,深度模型通过在线逐步微调的方式提高了识别精度,避免了对先前学习知识的遗忘.
为了选择最有效的学习样本,结合深度模型的认知信息和专家的指导,提出有效的样本选择方法.这里,认知信息集(Cognitive Information Sets,CISs)被定义为一种认知特征,它在专家的指导下融合了三种认知错误(图1).由于特征是由模型的认知错误产生的,最大的CISs反映了数据上最大的认知信息.选取最大值(即最难理解的样本)作为有效样本,对模型进行微调.
为了逐步提高深度模型的在线性能,将整个学习过程分为工作阶段和更新阶段.在工作阶段,深度模型给出对置信输入的识别结果,并将不确定实例放入不确定池中寻求专家的指导.在更新阶段,选取最不确定的样本作为微调数据,对模型进行在线提升.为了防止以前的学习知识被遗忘,从以前的训练数据池中随机选取几个样本,同时刷新深层模型.这种在线训练方法能有效地使深度模型逐渐适应新的模式变化,与人类学习的实际过程相似,能够自适应对象的变化,是一种终身递增的学习方式.
综上所述,本文的创新点包括:(1)设计一种新的认知特征:认知信息集(CISs),用于选择有效样本,提高深度模型的性能;(2)提出一种新的主动识别框架,它是一种具有深度模型的在线认知学习框架;(3)将认知知识引入深度学习,可以有效地减少深度模型的认知错误.
2.1 主动识别框架
我们的目标是通过一些有效的训练样本,如人类的在线认知学习,逐步提高深度模型的性能,为了实现这个目标开发了深度主动识别框架,如图2所示.首先利用少量的标记数据训练初始深度模型:在工作阶段(黑色框架),当对象熟悉时模型能产生自信的表现;否则模型会寻求专家的帮助,对不确定样本进行分析,专家根据专业知识和对模型误差的分析进行指导.在更新阶段(绿色框架)通过评估认知错误和专家指示选择目标敏感样本(Target Sensitive Sample,TSS)来计算CISs.此外,在训练数据池中加入TSS并选取刷新样本以防止遗忘先前的知识,最后利用TSSs和刷新样本对模型进行改进.
图2
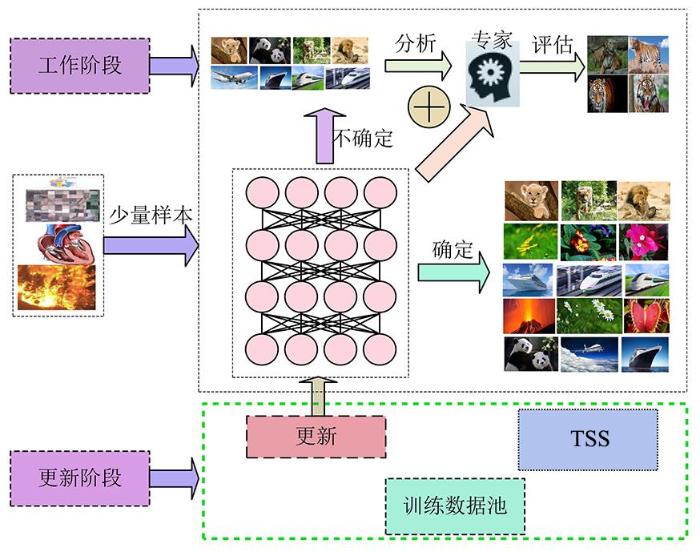
由于真实应用中目标的特征会随着时间的推移而变化,因此模型的确信度是一个重要的性质.在工作阶段,模型能给出基于确信输入的最终识别结果;否则,对于不确定的情况,模型会寻求专家的帮助,专家给出相关的指导并帮助模型产生相应的结果.在模型的更新周期(即工作间隔或指定时间)内,在专家的指导下,对不确定样本的认知误差进行评估并转化为CISs,选择最有效的样本作为微调数据,然后将所选样本添加到训练数据池中.为了避免知识被遗忘,同时从训练数据池中随机选取刷新样本.最后,对深层模型进行微调和刷新.
2.2 深度模型的确信度
2.2.1 深度变化率特性(VarRatio)
对于一个深度感知模型计算其输出的变化率信息.在输入样本x的每次随机前向传播过程结束后取样,并收集对于同一输入x的多次随机前向过程中所预测的标签y,记作集合T,其中
其中,
2.2.2 深度交叉熵特性(Entropy)
不同于变化率特性,深度模型的预测交叉熵在信息论中已经有自己的基础[23],如下所示:
把所有y可能的c个类加起来.给定一个测试点x,当预测所有类具有相等的均匀概率时预测熵达到其最大值;当一个类具有概率1且所有其他概率为0时,预测熵达到其最小值(即预测是确定的).
2.2.3 深度BALD特性
其中,
变化率提供了一个度量,即输出分布在类周围的“扩散”程度,熵可以捕获预测分布中包含的平均信息量.作为比较,深度BALD方法提供了模型的输入对象x与其输出
2.3 认知信息集合(CISs)
过往经验很大程度上决定人类能否准确地识别目标.与人类的学习特性类似,深度学习模型也随着训练样本的增加提升识别效果,然而在深度学习领域需要大量标记数据来训练深度模型,这与人类的学习不一致.
如图1所示,当一个学习者遇到一个新的对象时,他会感到困惑并给出一个不确定的预测.不确定性包括三个因素:对象预测的误差、对象预测的误差变化和不同类别之间的预测变化.
假设存在专家予以帮助,在学习者不确定性最高的地方提供指导,并给出一些有效的学习实例.预测⁃询问⁃选择(有效样本)的学习过程是人类的一种认知过程,是学习者与教师之间的一个闭环、相互作用的过程.这是一个从粗到细、从复杂到简单的循环比较和权衡过程[25].
受人类学习过程的启发,结合模型预测和专家指导,本文采用认知信息集合(CISs)用于样本选择以积极提高模型的识别精度.由于贝叶斯推理是分析深度学习的完美工具,使用统计方法对CISs进行以下的描述.为了像人类一样训练模型,所有这些不确定性因素都应该以一种混合的方式来考虑.
对于具有三个或更多类别标签的情况,与第一个因素预测误差(PE)相关的更一般的不确定变量可以描述为
上述标准考虑了可能标签上预测误差变化的不确定性.为了获得信息量,采用熵方法计算相关信息量.评估
其中,T是随机向前传递的重复次数,C是类标签的数目,
综合考虑上述三个不确定因素,得出认知信息包
其中,T是通过模型的随机正演的运行时间,α是作为特征约束参数的专家关于识别结果的指示,操作“
目前,在主动学习文献中广泛使用的不确定性查询方法,如果以日志损失最小为目标函数是可行的.然而,如果我们的目标是减少模型的预测误差,那么集成合并三个认知集合(
2.4 目标敏感样本
基于2.3关于认知信息包
图3
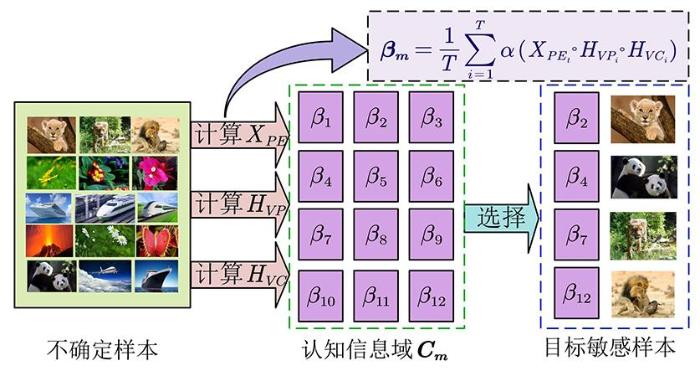
本文中最有效的数据也是对目标敏感的样本,因为从目前深度模型的ω来看,它们对识别信息贡献最大.这里考虑不确定性样本池的大小和应用条件,选择前m个最主要的
2.5 在线微调
在主动学习场景中用新的训练标签来改进模型时要使用整个训练数据重新训练[17],所以需要更多的调优迭代和更多的训练时间来收敛.特别是在深度学习场景中,长时间产生的大量训练样本被用来训练深度模型.
为了节省学习时间并应用于实际应用,本文提出了一种在线微调方法,通过认知学习的方式,在终身学习中逐步学习新的信息.在模型更新过程中,首先通过评估模型的认知信息和专家指令,选择目标敏感样本(TSSs,即有效样本)作为微调数据,如图4所示.由于在利用新样本对深度模型进行逐步在线微调的同时,记忆原始信息的模型权值会逐渐被遗忘,为了防止知识被遗忘,模仿人类的记忆机制从以前的训练数据库中选取样本,在学习新信息的同时对相关知识进行刷新.也就是说,当通过一个新的批量样本对deep模型进行微调时,随机选取一小部分在前一时间用来训练模型的样本来刷新模型.本文从训练数据池中选取了10%的样本作为前面的例子以帮助deep模型巩固先验信息记忆,然后将TSSs样本加入训练数据集.
图4
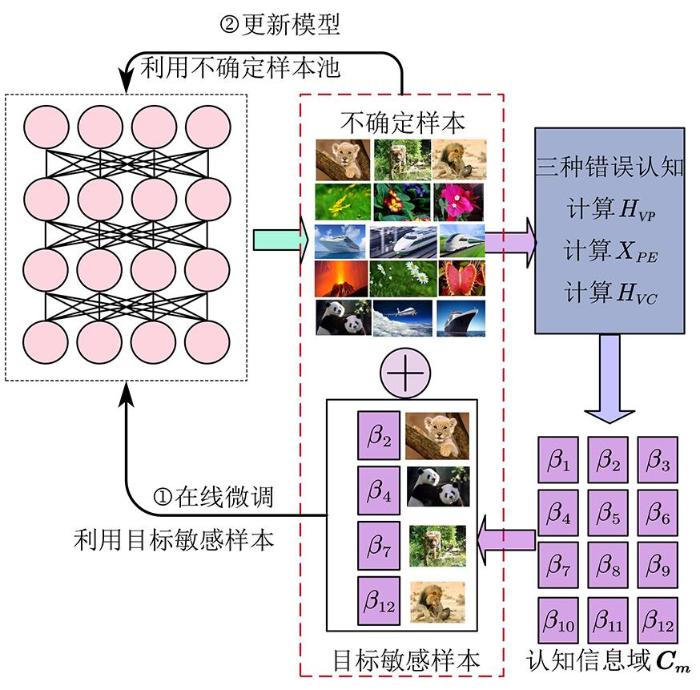
3 实验与结果
3.1 数据集和实验设置
首先选择手写数字数据集MNIST作为测试数据集.不同的人有不同的书写习惯,同一个汉字由不同的人书写其表现形式五花八门,正如同真实世界的数据是复杂的和非均匀分布的,与我们的识别对象具备一定的可类比空间.此外,为了验证复杂对象背景变化的影响,选取CIFAR⁃10和CIFAR⁃100两个数据集来演示输入图像的复杂性对模型性能的影响.后两个数据集分别有10类和100类不同形状和背景的彩色图像,所以这三个数据集的复杂度由MNIST到CIFAR⁃10再到CIFAR⁃100是增加的.以上三个数据集都是非均匀分布的,在机器学习领域中经常使用.
从MNIST训练数据集选取60000个模式训练集,包含来自大约250个作者的示例.再分为初始训练批(10000张图像)、验证批(10000张图像)和池数据批(40000张图像),用于创建不确定性池,生成目标敏感样本来训练深度模型.
选取CIFAR⁃10数据集中的50000个训练图像和10000个测试图像.将CIFAR⁃10数据库分为若干批进行实验,测试批包含从每个类中随机选择的1000个图像,训练批包含随机顺序的剩余图像,分为5000个图像的验证批、5000个图像的初始训练批和40000个图像的池数据批来创建训练数据.其中,训练批次中每节课正好包含5000张图片.
将CIFAR⁃100数据集分为10000幅图像的测试批、5000幅图像的初始训练批、5000幅图像的验证批和40000幅图像的池数据批.
对所有实验都使用以下最佳设置.在上述三个数据集上用九层dropout CNN[21]实现.选取10幅图像、200幅图像和200幅图像作为初始训练数据,分别对MNIST,CIFAR⁃10和CIFAR⁃100进行初始模型训练.同样,在更新阶段,通过有效样本选择方法从不确定度池中选择10,100,200幅图像对模型进行在线微调,提高模型的性能.同时,从以前的训练数据池中随机抽取10%的样本,刷新模型对以前知识的记忆.
3.2 结果与分析
为了评价本文方法的性能,将提出的CISs方法与其他三种方法进行比较,分别是变异比(VarRatio)、预测熵(Entropy)两种参数和BALD[20].和CISs一样,这三种方法也在主动学习过程中选择新增样本,但因为三种方法基于的原理不同,所以训练中的测试精度不同.故本文采用测试精度作为算法的比对因素,四种方法均在相同的 条件下选取样本对模型进行在线微调.
在MNIST,CIFAR⁃10和CIFAR⁃100三个数据集上进行实验,在识别对象复杂度增加的情况下对模型进行测试.下面讨论所选有效样本的结果和相应分析、模型精度、验证损失、识别结果和耗时比较.本文采用在线微调的方法,对人类学习新知识的深层模型进行改进.相比之下,传统的主动学习在获取新的标记样本时,使用的是整个训练数据来调整模型[27].
选择四个样本被四种方法用作微调数据,如图5所示.左边的块来自MNIST数据集,中间的块来自CIFAR⁃10数据集,右边的块来自CIFAR⁃100数据集.每个块中(a)到(d)列表示不同算法选择的样本:VarRatio,Entropy,BALD和CISs.由图可见,不同的方法从不确定度池中选取不同的有效样本对模型进行微调,CISs方法更倾向使用更无形的图像作为有效图像,其次是CIFAR⁃10数据集,最不明显的是CIFAR⁃100数据集.
图5

敏感样本数量:因为敏感样本的选择是模型根据新样本的不确定性和专家的指导信息综合决定的,不同训练样本和不同训练过程产生的敏感样本数不一样且变化较大,没有固定的规律,因此本文没有针对敏感样本的具体个数m进行分析.
模型测试精度:图6展示了四种选择样本的方法在训练过程中微调次数对模型的测试精度的影响.由图可见,测试精度随着微调次数的增多逐渐变大并趋于稳定,在MNIST数据集上,CISs方法在20次调谐迭代后就能达到稳定的高识别精度,而其他三种方法则需要60次以上的调谐迭代才能达到稳定.并且,在所有的实验数据集上,CISs从开始到最后一次优化迭代,测试精度都优于其他三种方法,但随着目标复杂度的增加,识别结果的波动性也增大,需要更多次的调整迭代才能达到稳定的结果.不过,当识别对象的复杂度从MNIST提高到CIFAR⁃10再到CIFAR⁃100时,即使波动增大,CISs的稳定性也优于其他算法.实验结果还表明,另外,熵方法和BALD方法性质相似,因为后者利用互信息来获得与前者相同的不确定信息,而变异比率法在早期学习阶段有时表现良好.
图6
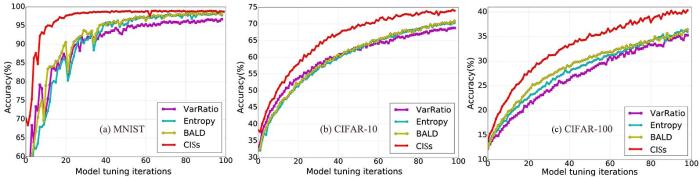
图6
不同微调次数下四种模型的测试精度对比
Fig.6
Model accuracy of four algorithms with different model tuning iterations
模型识别结果:表1、表2和表3分别显示了MNIST,CIFAR⁃10和CIFAR⁃100数据集上四种模型的识别结果.为了方便比较,每七次迭代选择从第9次到第100次的14次调优,实验结果见相关表,表中黑体字表示该方法在所有的微调迭代中最优.由表1可见,在MNIST数据集上,CISs模型经过几次优化迭代后识别效果显著,第65次优化后识别率已超过99%.而表2和表3的结果表明,CIFAR⁃10和CIFAR⁃100中的复杂例子需要学习迭代更多次才能得到好一点的识别结果,这也准确地反映了算法与人类的学习本质的相似性,即更困难的知识需要更多的时间和努力去学习.这在CIFAR⁃100数据集上尤甚,优化迭代的次数较少时的识别率不理想.
表1 MNIST手写数据集的识别结果
Table 1
| 方法 | T9 | T16 | T23 | T30 | T44 | T51 | T58 | T65 | T72 | T79 | T86 | T93 | T100 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 变异比 | 83.75% | 87.68% | 90.87% | 93.13% | 93.03% | 94.96% | 94.97% | 95.15% | 95.80% | 95.54% | 94.96% | 96.13% | 96.59% |
| 预测熵 | 83.53% | 85.04% | 90.30% | 91.05% | 95.09% | 94.67% | 96.23% | 97.11% | 96.93% | 97.94% | 96.85% | 98.03% | 98.01% |
| BALD | 86.73% | 89.06% | 93.75% | 92.77% | 95.85% | 95.20% | 96.76% | 97.39% | 97.48% | 98.04% | 98.32% | 98.20% | 98.15% |
| CISs | 93.25% | 94.93% | 95.87% | 95.13% | 96.03% | 96.96% | 97.97% | 99.15% | 99.80% | 99.54% | 99.96% | 99.13% | 99.25% |
表2 CIFAR⁃10的识别结果
Table 2
| 方法 | T9 | T16 | T23 | T30 | T44 | T51 | T58 | T65 | T72 | T79 | T86 | T93 | T100 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 变异比 | 51.92% | 55.38% | 57.68% | 59.54% | 60.98% | 62.32% | 63.75% | 64.29% | 64.29% | 65.99% | 66.71% | 67.48% | 68.12% |
| 预测熵 | 49.96% | 53.55% | 56.05% | 58.38% | 60.14% | 62.18% | 63.45% | 65.07% | 66.27% | 67.12% | 68.26% | 69.14% | 69.53% |
| BALD | 49.67% | 53.47% | 56.96% | 58.92% | 60.41% | 61.95% | 63.72% | 64.56% | 66.09% | 67.17% | 67.36% | 69.15% | 69.90% |
| CISs | 56.19% | 60.69% | 63.36% | 66.08% | 67.38% | 69.18% | 69.75% | 71.18% | 71.97% | 72.23% | 72.46% | 73.45% | 73.75% |
表3 CIFAR⁃100的识别结果
Table 3
| 方法 | T9 | T16 | T23 | T30 | T44 | T51 | T58 | T65 | T72 | T79 | T86 | T93 | T100 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 变异比 | 19.03% | 23.14% | 23.29% | 24.44% | 27.60% | 27.97% | 29.89% | 30.97% | 32.98% | 32.86% | 33.84% | 34.19% | 35.15% |
| 预测熵 | 21.13% | 23.24% | 26.13% | 27.52% | 30.04% | 30.80% | 32.34% | 33.10% | 33.05% | 34.53% | 35.46% | 35.62% | 36.58% |
| BALD | 23.26% | 25.96% | 27.77% | 29.29% | 31.26% | 31.50% | 33.01% | 33.84% | 34.83% | 35.69% | 36.16% | 35.79% | 37.81% |
| CISs | 28.81% | 31.06% | 32.23% | 33.22% | 35.01% | 36.26% | 37.04% | 37.72% | 39.16% | 39.24% | 40.18% | 38.65% | 40.18% |
训练方法比较:比较在线微调(建议)和整体训练数据方法(先验)的实验结果,分别采用全训练数据(All Data,AD)和在线微调数据(Online Fine⁃tune Data,OD),在MNIST,CIFAR⁃10和CIFAR⁃100数据集上运用上述四种方法各训练100次迭代.为了便于区分,将这些方法标注为:CIS⁃AD、CIS⁃OD、BALD⁃AD、BALD⁃OD、预测熵⁃AD、预测熵⁃OD、变异比⁃AD、变异比⁃OD.如表4所示,和AD方法相比,在得到几乎相同的实验结果的前提下,某些OD方法的耗时还不到AD方法的一半,说明OD方法可以节省大量的训练时间,因此可以在实际中应用.而且这种在已有知识的基础上利用新的实例进行学习的机制,也更符合人类学习的特点.
表4 MNIST,CIFAR⁃10,CIFAR⁃100在不同训练集上的时间耗费比较
Table 4
| 方法 | MNIST | CIFAR⁃10 | CIFAR⁃100 | |||
|---|---|---|---|---|---|---|
| 100轮耗时(s) | 每轮平均耗时(s) | 100轮耗时(s) | 每轮平均耗时(s) | 100轮耗时(s) | 每轮平均耗时(s) | |
| 变异比⁃AD | 33699.99 | 336.99 | 520540.78 | 5205.40 | 833933.65 | 8339.33 |
| 变异比⁃OD | 18809.54 | 188.09 | 21807.34 | 218.07 | 34354.54 | 343.54 |
| 预测熵⁃AD | 30081.62 | 300.81 | 487761.18 | 4877.61 | 813504.12 | 8135.04 |
| 预测熵⁃OD | 17943.67 | 179.43 | 21043.45 | 210.43 | 34065.86 | 340.65 |
| BALD⁃AD | 29989.71 | 299.89 | 484232.12 | 4842.32 | 803423.55 | 8034.23 |
| BALD⁃OD | 17353.88 | 173.53 | 20942.65 | 209.42 | 33901.54 | 339.01 |
| CIS⁃AD | 49023.34 | 490.23 | 689832.73 | 6898.32 | 1232323.51 | 12323.23 |
| CIS⁃OD | 21302.62 | 213.02 | 30231.51 | 302.31 | 39515.21 | 395.15 |
综合以上实验结果可以看出,本文提出的方法在三个数据集上的性能都优于其他三种方法,但如果实验对象更复杂或模式变化很大,则模型需要更多的学习时间来适应复杂的条件.
4 结 论
本文提出的方法可以为认知终身深度学习的研究提供一条思路,接下来将重点分析人类对相关数学描述方法的认知,并研究深度学习应用中的认知评价标准.虽然本文的方法对少量数据样本情况下的标记和学习有很大的帮助,但这种帮助仅限于相对静态的、输入和输出相对固定的问题.当观测数据长度不定时输出模板也会产生相应的长度变化,如何将Seq2seq模型等解决可变长度时序观测的模型与现有模型融合,是未来需要考虑的问题.
参考文献
潜艇使用声抗器材防御鱼雷方案优化模型及模型求解策略
Optimal model and model solving strategy of submarine torpedo defence using acoustic countermeasure equipment
Deep bayesian active learning with image data
∥
Benchmarking framework for command and control mission planning under uncertain environment
Neuroscience,psychology,and society:Translating research to improve learning
Speeding up similarity search under dynamic time warping by pruning unpromising alignments
10 challenging problems in data mining research
Active one⁃shot learning by a deep Q⁃network strategy
The great time series classification bake off:A review and experimental evaluation of recent algorithmic advances
Stability in mean for multi⁃dimensional uncertain differential equation
What uncertainties do we need in bayesian deep learning for computer vision?
∥
Active hidden markov models for information extraction
∥
A survey on transfer learning
Time series classification with ensembles of elastic distance measures
Episode⁃based active learning with bayesian neural networks
∥
Model metric co⁃learning for time series classification
∥
An analysis of machine learning intelligence
Critical events based resource layer structure dynamic adaptive optimization method
Deep learning algorithms for human activity recognition using mobile and wearable sensor networks:State of the art and research challenges
Bayesian active learning for classification and preference learning
DECADE:A deep metric learning model for multivariate time series
∥
Time series classification by sequence learning in all⁃subsequence space
∥
Learning strategies:A synthesis and conceptual model
Multiobjective learning in the model space for time series classification
Model⁃based time series classification
∥
A run length transformation for discriminating between auto regressive time series
Deep k⁃nearest neighbors:Towards confident,interpretable and robust deep learning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}