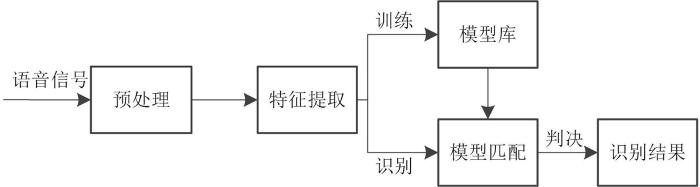
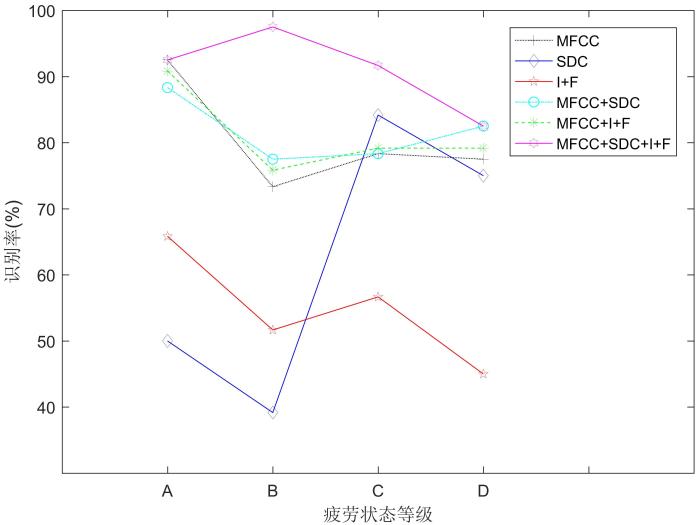
Fatigue detection through speech has the advantages of simple operation,non⁃invasive and real⁃time. In order to improve the performance of speech fatigue detection,this paper combines prosodic features with dynamic cepstral features,uses Gaussian mixture model as the classifier to perform voice fatigue detection. The detection performance of Mel frequency cepstral coefficient,shifted delta cepstral feature and prosodic feature is investigated respectively. The experimental results show that the detection performance of Mel frequency cepstral coefficient is better than that of shifted delta cepstral feature and prosodic feature in single feature. For fusion feature,the detection performance is better than that of single feature. If the three features are fused,the detection accuracy can reach 91%.
Keywords:fatigue
;
mel frequency cepstral coefficient
;
shifted delta cepstral
;
prosody
;
gaussian mixture model
;
fusion
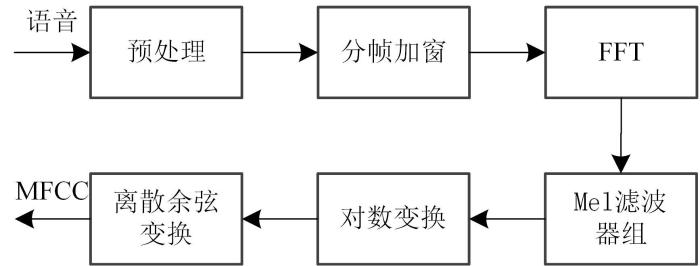
在疲劳度检测中,语音信号的特征选取尤为重要.常用的语音特征有描述声道特性的倒谱特征,包括梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC).MFCC能够反映语音信号的静态特性,它是由梅尔频率与赫兹频率之间的非线性关系计算得到的频谱特征,陈枢茜[3]通过提取MFCC特征,利用支持向量机和集成方法AdaBoost构造分类器,进行语音疲劳度检测.除了声道特征,语音中还包括韵律特征,如基音频率、能量、共振峰等随时间的变化规律.赵强[4]通过提取韵律特征,用TensorFlow框架搭建神经网络,对语音疲劳度分类.
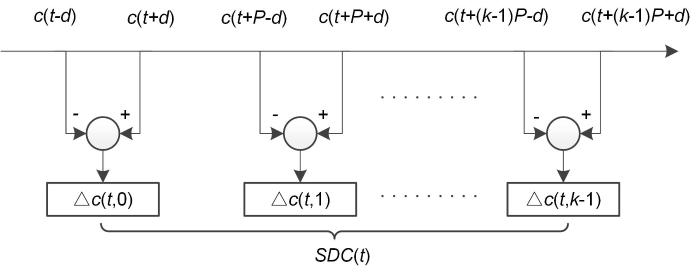
为了改善语音疲劳度检测的效果,本文考察了MFCC、滑动差分倒谱(Shifted Delta Cepstral,SDC)特征以及韵律特征的检测性能.SDC特征是差分倒谱系数的扩展,考虑了前后多帧差分倒谱的影响,已被用于语种识别[5],通过提取SDC特征可对六个语种进行识别[6],Kshirod and Utpal[7]使用MFCC⁃SDC进行说话人识别,Murali Krishna et al[8]使用MFCC⁃SDC来识别说话人不同的情绪状态,识别结果均比单特征好.但是SDC特征尚未用于语音疲劳度检测研究.据此,本文首先对语音信号预处理,然后分别提取了MFCC、SDC以及韵律特征,送入分类器中训练识别,并依据各特征参数特性进一步考察了三类特征相互融合后的检测性能.
WangM R. Research of speaker recognition system based on mixed feature parameters and GMM⁃UBM.Master Dissertation. Guilin:Guilin University of Electronic Technology,2016.
Research on fatigue detection based on voice analysis
1
2017
... 在疲劳度检测中,语音信号的特征选取尤为重要.常用的语音特征有描述声道特性的倒谱特征,包括梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC).MFCC能够反映语音信号的静态特性,它是由梅尔频率与赫兹频率之间的非线性关系计算得到的频谱特征,陈枢茜[3]通过提取MFCC特征,利用支持向量机和集成方法AdaBoost构造分类器,进行语音疲劳度检测.除了声道特征,语音中还包括韵律特征,如基音频率、能量、共振峰等随时间的变化规律.赵强[4]通过提取韵律特征,用TensorFlow框架搭建神经网络,对语音疲劳度分类. ...
Research on fatigue detection based on voice analysis
1
2017
... 在疲劳度检测中,语音信号的特征选取尤为重要.常用的语音特征有描述声道特性的倒谱特征,包括梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC).MFCC能够反映语音信号的静态特性,它是由梅尔频率与赫兹频率之间的非线性关系计算得到的频谱特征,陈枢茜[3]通过提取MFCC特征,利用支持向量机和集成方法AdaBoost构造分类器,进行语音疲劳度检测.除了声道特征,语音中还包括韵律特征,如基音频率、能量、共振峰等随时间的变化规律.赵强[4]通过提取韵律特征,用TensorFlow框架搭建神经网络,对语音疲劳度分类. ...
基于神经网络的语音疲劳度检测
1
2019
... 在疲劳度检测中,语音信号的特征选取尤为重要.常用的语音特征有描述声道特性的倒谱特征,包括梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC).MFCC能够反映语音信号的静态特性,它是由梅尔频率与赫兹频率之间的非线性关系计算得到的频谱特征,陈枢茜[3]通过提取MFCC特征,利用支持向量机和集成方法AdaBoost构造分类器,进行语音疲劳度检测.除了声道特征,语音中还包括韵律特征,如基音频率、能量、共振峰等随时间的变化规律.赵强[4]通过提取韵律特征,用TensorFlow框架搭建神经网络,对语音疲劳度分类. ...
基于神经网络的语音疲劳度检测
1
2019
... 在疲劳度检测中,语音信号的特征选取尤为重要.常用的语音特征有描述声道特性的倒谱特征,包括梅尔频率倒谱系数(Mel Frequency Cepstral Coefficient,MFCC).MFCC能够反映语音信号的静态特性,它是由梅尔频率与赫兹频率之间的非线性关系计算得到的频谱特征,陈枢茜[3]通过提取MFCC特征,利用支持向量机和集成方法AdaBoost构造分类器,进行语音疲劳度检测.除了声道特征,语音中还包括韵律特征,如基音频率、能量、共振峰等随时间的变化规律.赵强[4]通过提取韵律特征,用TensorFlow框架搭建神经网络,对语音疲劳度分类. ...
A unified deep neural network for speaker and language recognition
1
2015
... 为了改善语音疲劳度检测的效果,本文考察了MFCC、滑动差分倒谱(Shifted Delta Cepstral,SDC)特征以及韵律特征的检测性能.SDC特征是差分倒谱系数的扩展,考虑了前后多帧差分倒谱的影响,已被用于语种识别[5],通过提取SDC特征可对六个语种进行识别[6],Kshirod and Utpal[7]使用MFCC⁃SDC进行说话人识别,Murali Krishna et al[8]使用MFCC⁃SDC来识别说话人不同的情绪状态,识别结果均比单特征好.但是SDC特征尚未用于语音疲劳度检测研究.据此,本文首先对语音信号预处理,然后分别提取了MFCC、SDC以及韵律特征,送入分类器中训练识别,并依据各特征参数特性进一步考察了三类特征相互融合后的检测性能. ...
基于声学特征的自动语言辨识研究
1
2007
... 为了改善语音疲劳度检测的效果,本文考察了MFCC、滑动差分倒谱(Shifted Delta Cepstral,SDC)特征以及韵律特征的检测性能.SDC特征是差分倒谱系数的扩展,考虑了前后多帧差分倒谱的影响,已被用于语种识别[5],通过提取SDC特征可对六个语种进行识别[6],Kshirod and Utpal[7]使用MFCC⁃SDC进行说话人识别,Murali Krishna et al[8]使用MFCC⁃SDC来识别说话人不同的情绪状态,识别结果均比单特征好.但是SDC特征尚未用于语音疲劳度检测研究.据此,本文首先对语音信号预处理,然后分别提取了MFCC、SDC以及韵律特征,送入分类器中训练识别,并依据各特征参数特性进一步考察了三类特征相互融合后的检测性能. ...
基于声学特征的自动语言辨识研究
1
2007
... 为了改善语音疲劳度检测的效果,本文考察了MFCC、滑动差分倒谱(Shifted Delta Cepstral,SDC)特征以及韵律特征的检测性能.SDC特征是差分倒谱系数的扩展,考虑了前后多帧差分倒谱的影响,已被用于语种识别[5],通过提取SDC特征可对六个语种进行识别[6],Kshirod and Utpal[7]使用MFCC⁃SDC进行说话人识别,Murali Krishna et al[8]使用MFCC⁃SDC来识别说话人不同的情绪状态,识别结果均比单特征好.但是SDC特征尚未用于语音疲劳度检测研究.据此,本文首先对语音信号预处理,然后分别提取了MFCC、SDC以及韵律特征,送入分类器中训练识别,并依据各特征参数特性进一步考察了三类特征相互融合后的检测性能. ...
GMM based language identification using MFCC and SDC features
1
2013
... 为了改善语音疲劳度检测的效果,本文考察了MFCC、滑动差分倒谱(Shifted Delta Cepstral,SDC)特征以及韵律特征的检测性能.SDC特征是差分倒谱系数的扩展,考虑了前后多帧差分倒谱的影响,已被用于语种识别[5],通过提取SDC特征可对六个语种进行识别[6],Kshirod and Utpal[7]使用MFCC⁃SDC进行说话人识别,Murali Krishna et al[8]使用MFCC⁃SDC来识别说话人不同的情绪状态,识别结果均比单特征好.但是SDC特征尚未用于语音疲劳度检测研究.据此,本文首先对语音信号预处理,然后分别提取了MFCC、SDC以及韵律特征,送入分类器中训练识别,并依据各特征参数特性进一步考察了三类特征相互融合后的检测性能. ...
Inferring the human emotional state of mind using assymetric distrubution
1
2013
... 为了改善语音疲劳度检测的效果,本文考察了MFCC、滑动差分倒谱(Shifted Delta Cepstral,SDC)特征以及韵律特征的检测性能.SDC特征是差分倒谱系数的扩展,考虑了前后多帧差分倒谱的影响,已被用于语种识别[5],通过提取SDC特征可对六个语种进行识别[6],Kshirod and Utpal[7]使用MFCC⁃SDC进行说话人识别,Murali Krishna et al[8]使用MFCC⁃SDC来识别说话人不同的情绪状态,识别结果均比单特征好.但是SDC特征尚未用于语音疲劳度检测研究.据此,本文首先对语音信号预处理,然后分别提取了MFCC、SDC以及韵律特征,送入分类器中训练识别,并依据各特征参数特性进一步考察了三类特征相互融合后的检测性能. ...
Automatic genre classification of Indian Tamil and western music using fractional MFCC




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}