


深度神经网络可以将原始输入映射到特征空间,自动达到数据降维和特征学习的目的而不需要人为操作,有利于更好地聚类[10],所以基于深度神经网络的聚类,即深度聚类随之产生.神经网络提取的显著特征使聚类算法能够更好地进行聚类,而聚类结果又能作为监督信号对神经网络进行监督训练,二者相辅相成,使深度聚类在复杂数据集上有很好的聚类效果.
目前,深度聚类可以概括为两个框架:一是先训练神经网络,然后利用神经网络进行特征提取,如自动编码器、卷积神经网络、生成对抗网络、深度信念网络等,再使用传统的聚类算法进行聚类,如k⁃means、谱聚类、层次聚类等;二是将神经网络训练、特征提取和聚类同时进行,通过一个损失函数将它们联系起来得到聚类结果.经典的无监督DEC (Deep Embedded Clustering)聚类算法[11]利用自动编码器提取网络特征,提出目标辅助函数,再利用KL散度对聚类损失函数进行优化.DEC算法后又出现多个变体,如针对微调时只有聚类损失函数导致特征空间扭曲而加入重构损失函数的IDEC (Improved Deep Embedded Clustering)算法[12];为了更好地处理图像数据集而将全连接自动编码器变为卷积自动编码器的CAE(Convolutional Autoencders)+k⁃means算法[13];将聚类和特征提取任务统一的DEPICT(Deep Embedded Regularized Clustering)算法[14],目标函数在KL散度的基础上加入正则化项,使聚类在最佳的子空间中进行;将降维和k⁃means聚类联合的DCN(Deep Clustering Network)算法[15],通过加入适当的约束使降维后的子空间更适合k⁃means算法,为神经网络与聚类的融合提供函数优化设计的思想.这两类框架都提高了聚类的性能,但两类框架的特征提取都集中在中间层一层,忽略了其他层特征包含的重要信息.神经网络有强大的特征提取能力,且在特征提取阶段,各层特征对聚类结果都比较重要:如浅层特征可以提取数据的颜色、角度等,而深层的特征提取,由于不断的卷积操作使感受野的范围不断扩大,会提取一些说不清道不明的特征,即所谓的抽象特征.
针对以上问题,本文利用神经网络提取多层次特征的集成聚类 算法(Deep Ensemble Clustering Based on Multi⁃Level Features,DCMLF),通过提取不同层神经网络的特征得到更全面的特征信息,提升聚类效果.本研究使用三个卷积神经网络,分别利用一层卷积、二层卷积、三层卷积,它们除了卷积层数不同,其余的神经网络参数完全相同,保证对同一个输入对象提取的是其三个层次的特征.通过对三个层次特征的集成聚类与单一的三层卷积结果相比较,发现聚类效果得到提升,证明其浅层特征对聚类结果亦有重要影响.
1 相关原理
1.1 自动编码器
自动编码器[11]由编码器和解码器两部分组成.深度聚类中,编码器可以将高维的输入转换到低维的特征空间进行聚类,解码器与编码器对称,将特征空间还原为输入,通过最小化均方差函数保证特征空间的特征向量是有用的信息.
其中,
最初的自动编码器是堆叠的全连接层,为了更好地处理图像数据集将全连接层变为卷积层.
1.2 集成聚类
集成聚类将对同一个数据集合的多个划分结果利用一致性函数统一为一个聚类结果[16],所以集成聚类主要包括两个重要部分:一是得到聚类成员,二是选择一致性函数.得到聚类成员的方法分三类:(1)每次聚类都使用相同的聚类算法,目前多采用k⁃means,为了获得不同的聚类结果要求每次初始化的参数都不同;(2)每次聚类采用不同的聚类方法得到不同的聚类结果,再通过一致性函数得到最终结果;(3)将数据的特征空间通过添加约束映射到多个子空间进行聚类.一致性函数目前主要有投票法、基于超图的划分以及证据积累.投票法共享单次聚类结果对数据集划分的信息,根据每次的聚类结果对数据集的划分进行投票,然后设定一定的阈值,达到阈值就将其划分到这个簇中.基于超图划分的一致性函数将每次聚类结果都用超图表示,超边表示簇,超边的顶点表示属于该簇的数据点,将超图进行最小分割并用基于图论的聚类算法得到最终的聚类结果.证据积累是将每次聚类的结果看作一次独立的证据,然后计算其中两个数据点被划分到同一个簇的次数来得到共协矩阵,最终使用基于最小生成树的层次聚类来得到聚类结果.
本研究对数据集在一层卷积、二层卷积以及三层卷积的不同特征空间的特征信息采用相同的k⁃means聚类算法,通过集成聚类得到最终结果.
2 基于神经网络多层次特征提取的集成聚类算法
本文算法的结构主要由一层卷积自动编码器、二层卷积自动编码器、三层卷积自动编码器提取的特征以及集成聚类结果组成.为了保证提取同一个输入对象的三个不同层次特征,卷积自动编码器的神经网络参数完全相同,区别只在卷积层数的差异,如图1所示.
图1
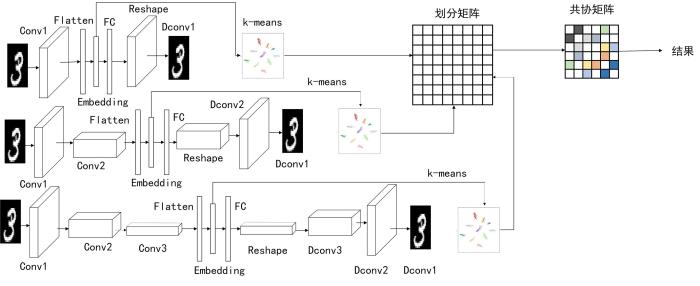
图1
基于卷积自动编码器集成聚类算法的结构
Fig.1
The structure diagram of ensemble clustering algorithm based on convolutional autoencoders
可以看到,本文算法利用三个卷积自动编码器进行特征提取,而一层、二层与三层卷积自动编码器在相应层数对应的神经网络参数完全相同,这样可以保证本网络结构尽可能提取输入图像的三个不同层次的特征.三个子网络编码器部分的设置具体分别为:
2.1 多层次特征提取
使用自动编码器的结构来保证中间层提取的特征信息尽可能有用,使用三个卷积参数相同而只有卷积层数不同的网络结构提取多层次特征.
使用卷积自动编码器,省略逐层预训练,将图像直接输入卷积层,经过卷积之后得到输入特征;然后利用Flatten层将特征空间拉平变成向量,紧接着连接一个只有10个神经单元的Dense层.这样不仅降低了输入数据集的维度,有利于后续聚类的进行,而且避免解码器复制输入导致无法提取有用特征.特征提取之后利用全连接层、Reshape层、反卷积层重构输入,利用均方差函数训练神经网络.为了区别于基本的全连接自动编码器,加入“*”代表卷积操作,
2.2 证据积累算法
证据积累算法[17]是集成聚类中常用的一致性函数,通过共协矩阵将不同的数据划分集成为统一的划分.首先通过k⁃means随机初始化聚类中心获得不同的聚类结果,得到划分矩阵P,数据对
基于多层次特征提取的集成聚类算法如下.
输入:数据集
输出:将数据集划分成
初始化:设定循环次数r,设定n×n共协矩阵,设定
n×r划分矩阵,并初始化为零
for i=0;
对feature1使用k⁃means算法聚类,存储聚类结果至
对feature2使用k⁃means算法聚类,存储聚类结果至
对feature3使用k⁃means算法聚类,存储聚类结果至
最终得到划分矩阵
3 实 验
为了评估本文算法的性能,选用三个图像数据集进行实验,对同一张图像可视化不同卷积次数之后的特征图,展现特征图之间的差异性,进而说明多层次特征的必要性.为了验证多层次特征对实验结果的重要性,对不同层次特征进行组合实验,选用准确率和标准互信息作为评估标准.选择k⁃means,SAE(Stacked Autoencoders)+k⁃means,CAE+k⁃means,DEC,IDEC,EAC(Evidence Accumulation)[18]算法作为对比算法.
3.1 数据集描述
MNIST⁃test数据集包含一万张图像,像素大小为28×28;USPS数据集包含9298张灰度的手写数字照片,像素大小为16×16;DIGITS数据集包含1797张图像,像素大小为8×8.数据集的统计信息如表1所示.
表1 数据集的信息
Table 1
| 数据集 | 数据点 | 维度 | 类别 |
|---|---|---|---|
| MNIST⁃test | 10000 | 784 | 10 |
| USPS | 9298 | 256 | 10 |
| DIGITS | 1797 | 64 | 10 |
3.2 实验设置
图2
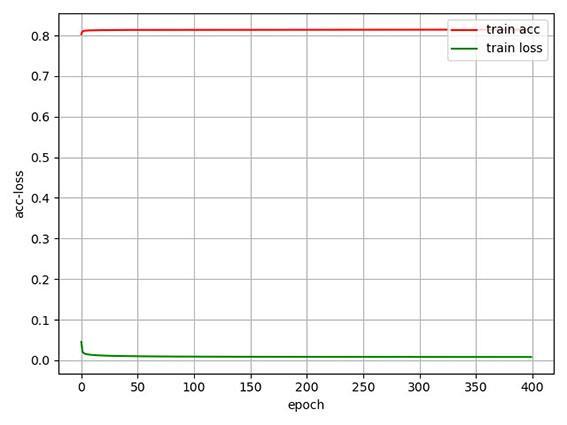
图3
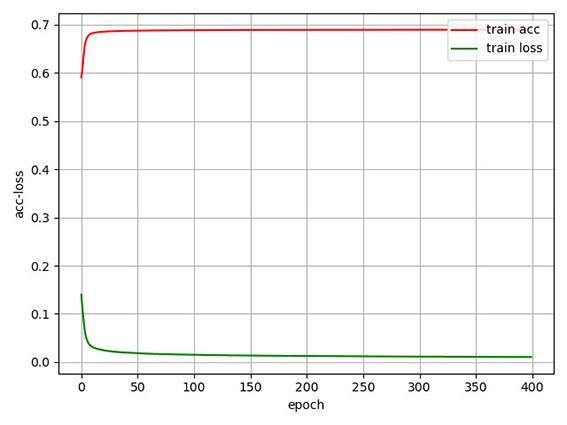
可以看到,USPS和MNIST⁃test数据集在epoch次数为200时损失函数和准确率基本达到稳定.由于DIGITS数据集维度较小,样本数量较少,三层网络只需训练很少的次数就能达到稳定,训练次数对其影响较小,所以选择与USPS及MNIST⁃test相同的epoch次数.在将聚类结果进行集成的过程中,将k⁃means在各层特征聚类的循环总次数r设定为六次,每个特征进行两次k⁃means.
3.3 评估标准
3.3.1 准确度
准确度(Accuracy,ACC)[19]是算法聚类分配的正确率,如
其中,
3.3.2 标准化互信息
互信息指两个随机变量之间的关联程度,标准化互信息(Normalized Mutual Information,NMI)[20]是将互信息归一化为0到1,如
其中,
3.4 实验内容
3.4.1 不同卷积层次网络的特征图
卷积层一般用于处理图像数据集,所以在卷积层中数据都以三维的形式存在,可以看作是将多个二维图像进行堆叠,如果是彩色图像就有三个特征图.通过可视化不同卷积层之后的特征图展现不同卷积次数之后特征图的差异性,由于它们的特征向量、抽象特征不同,通过将多个特征向量融合可以使特征更加全面化.
图4

图4
输入原始图像(a)及使用一层(b)、二层(c)、三层(d)卷积得到的特征融合图
Fig.4
The original image (a) and the feature fusion maps obtained by one layer (b), two layers (c) and three layers (d)
3.4.2 不同层次特征实验比较
为了验证不同层次特征对实验结果的重要性,以DIGITS数据集为例进行多个不同特征空间的组合实验,Feature1,Feature2,Feature3分别表示一层卷积、二层卷积以及三层卷积之后的特征,
表2 不同层次特征实验结果
Table 2
| Feature | DIGITS | ||
|---|---|---|---|
| ACC | NMI | ARI | |
| Feature3 | 79.96 | 74.63 | 67.93 |
| Feature3,Feature1 | 80.09 | 74.91 | 68.11 |
| Feature3,Feature2 | 80.02 | 74.84 | 68.07 |
| Feature3,Feature2,Feature1 | 80.65 | 75.11 | 68.54 |
可以看出,只用三层卷积之后的Feature3得到的聚类准确率最低,而用三个层次特征进行聚类的ACC,NMI以及ARI三个聚类指标均为最高,且用两个层次特征进行聚类的聚类指标都比单个特征的聚类指标高.证明不同层次特征对聚类结果都有一定程度的影响,多层次特征使特征更全面,更有益于聚类性能的提升.
3.4.3 实验结果比较
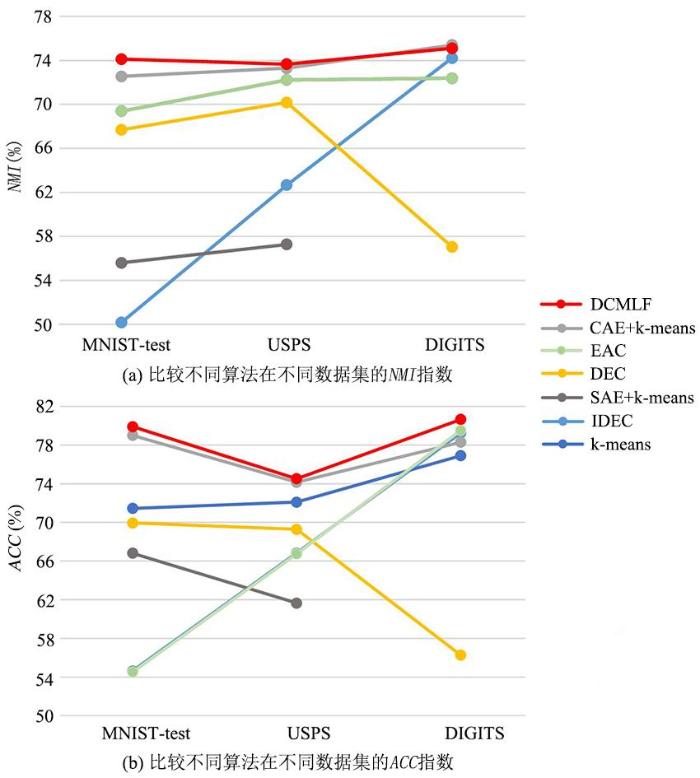
表3和表4(表中黑体字表示最优的实验结果)证明本文算法的聚类结果与基本的k⁃means算法以及其他五种算法相比都有提高,DEC,SAE+k⁃means以及IDEC使用了相同的初始化权重.与CAE+k⁃means相比,证明多层特征提取有利于聚类性能的提升;与DEC和IDEC相比,本文算法没有进行网络预训练及过多的超参数设置,但通过多层特征提取以及集成聚类也能提高聚类结果.为了更充分地论证提取多层特征的重要意义,还与集成聚类算法EAC进行对比.本文多层次提取特征的思想也可用于其他网络结构以达到更好的聚类效果.为了将实验结果的评价指标进行更直观的表达,各项算法的评价指标对比如图5所示.可以看出,本文算法位于图中的最顶端,表明聚类效果优于其他算法.
表3 各类算法的聚类准确率比较
Table 3
| Methods | MNIST⁃test | USPS | DIGITS |
|---|---|---|---|
| DCMLF | 79.90 | 74.51 | 80.65 |
| k⁃means | 54.63 | 66.82 | 79.24 |
| SAE+k⁃means | 66.81 | 61.65 | - |
| CAE+k⁃means | 79.00 | 74.15 | 78.29 |
| DEC | 69.94 | 69.28 | 56.26 |
| IDEC | 71.45 | 72.10 | 76.90 |
| EAC | 54.51 | 66.73 | 79.52 |
表4 各类算法的标准化互信息比较
Table 4
| Methods | MNIST⁃test | USPS | DIGITS |
|---|---|---|---|
| k⁃means | 50.18 | 62.66 | 74.22 |
| SAE+k⁃means | 55.59 | 57.27 | - |
| CAE+k⁃means | 72.55 | 73.30 | 75.40 |
| DEC | 67.69 | 70.18 | 57.05 |
| IDEC | 69.40 | 72.23 | 72.38 |
| EAC | 50.25 | 62.60 | 74.06 |
| DCMLF | 74.12 | 73.66 | 75.11 |
图5
4 结 论
本文提出一种基于神经网络多层次特征提取的集成聚类算法DCMLF,既利用了神经网络能够提取多层次特征的能力,又利用了集成聚类能够提高聚类结果鲁棒性的优势.DCMLF算法利用三个卷积自动编码器提取三层特征,使特征信息更全面;利用证据积累算法将不同层次特征的聚类结果进行集成,可减缓神经网络参数初始化的不确定性导致结果的不稳定性.实验结果表明,DCMLF算法在不同大小、不同维度的图像数据集中都有较高的准确率,和基于单层次特征的提取方法相比,准确率有所提高,说明层次特征的多样性在聚类性能提升中发挥着重要的作用.本文提取多层次特征的方法也适用于其他网络结构,为提取多层次特征提供了一种思路.今后将加强对神经网络训练的研究,使网络提取的特征信息更有效,进而提高聚类效果的性能.
参考文献
聚类方法综述
Review of clustering method
Research of semi⁃supervised spectral clustering algorithm based on pairwise constraints
Deep clustering:Discriminative embeddings for segmentation and separation
∥IEEE International Conference on Acoustics,Speech and Signal Processing.
求解大规模谱聚类的近似加权核k⁃means算法
Approximate weighted kernel k⁃means for large⁃scale spectral clustering
拉普拉斯加权聚类算法
Weighted laplacian clustering algorithm
Deep clustering for unsupervised learning of visual features
∥
Clustering with deep learning:Taxonomy and new methods
Alternative objective functions for deep clustering
∥2018 IEEE International Conference on Acoustics,Speech and Signal Processing.
基于类内和类间距离的主成分分析算法
Method of principal component analysis based on intra⁃class distance and inter⁃class distance
A survey of clustering with deep learning:from the perspective of network architecture
Unsupervised deep embedding for clustering analysis
∥
Improved deep embedded clustering with local structure preservation
∥
Deep clustering with convolutional autoencoders
∥Liu D,Xie S,Li Y,et al.
Deep clustering via joint convolutional autoencoder embedding and relative entropy minimization
∥
Towards k⁃means⁃friendly spaces:Simultaneous deep learning and clustering
聚类集成方法研究
Research on cluster aggregation approaches
Data clustering using evidence accumulation
∥
Combining multiple clusterings using evidence accumulation
Deep clustering by gaussian mixture variational autoencoders with graph embedding
∥
Semi⁃supervised learning with deep embedded clustering for image classification and segmentation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}