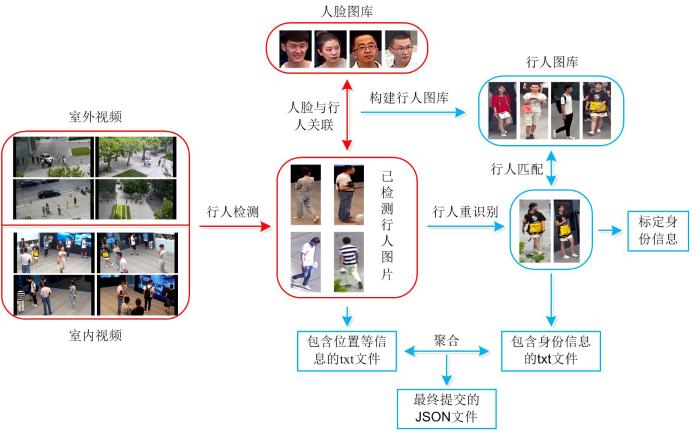
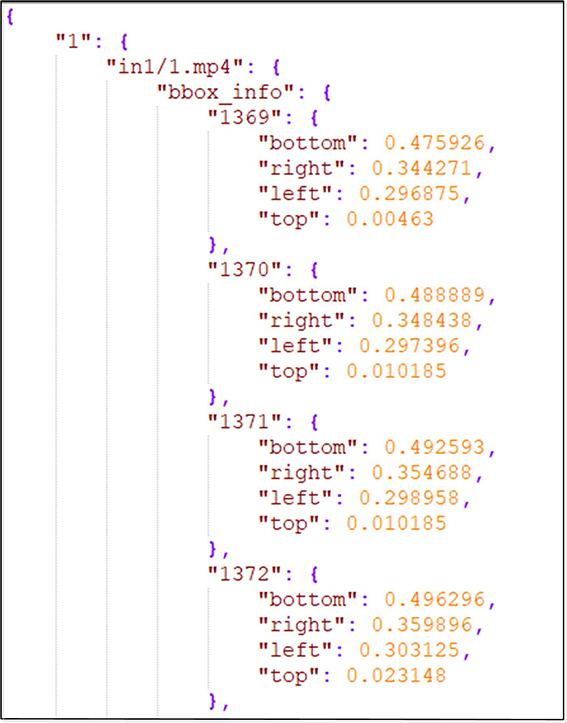
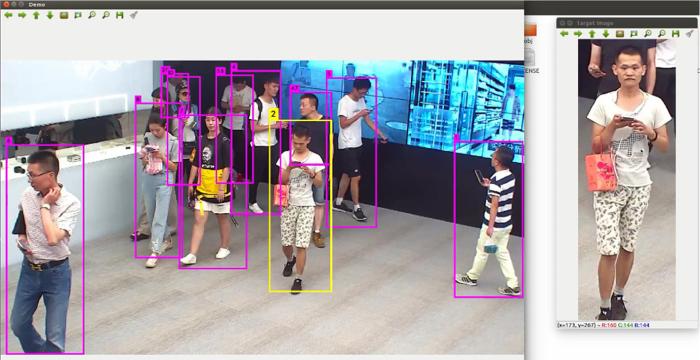
Combining the person detection algorithm and the person re⁃identification algorithm,a multi⁃target cross camera tracking algorithm is proposed. The algorithm consists of three modules:person detection,person re⁃identification and person data association. Firstly,the improved person detection algorithm based on YOLOv3 is used to detect the person appearing in the video and to save the video number,frame number and person body position information. Secondly,the improved person re⁃identification algorithm based on generative adversarial network and reranking is used to assign a label to the detected person images. Finally,the person information obtained in the first two steps is integrated to generate a JavaScript Object Notation (JSON) file containing all information of the person in the video. The algorithm can complete the multi⁃target cross camera tracking task quickly and efficiently,and has certain practical value,which won a single award in the Global (Nanjing) Artificial Intelligence Application competition.
Keywords:multi⁃target cross camera tracking
;
person re⁃identification
;
person detection
;
reranking
;
generative adversarial network
Dai Chenchao, Wang Hongyuan, Cao Liang, Yin Yuchang, Zhang Ji. Research and implementation of a multi⁃target cross camera tracking technology. Journal of nanjing University[J], 2021, 57(2): 227-236 doi:10.13232/j.cnki.jnju.2021.02.007
随着经济的发展和人们对安全需求的日益加强,越来越多的监控摄像机被安装在医院、火车站、机场和学校等大型公共场所.传统的监控摄像机仅有录制视频、存储视频、播放视频的功能,若要对异常状况进行实时监控和报警往往需要监控人员不间断地注视屏幕,这极其耗时耗力.最重要的是,各地部署的摄像机每天会产生海量的监控视频,仅仅依靠人工难以处理.为提高监控效率、减轻人工劳动负荷,可以借助计算机视觉、深度学习和模式识别等相关技术[1-4]实现对视频中无关信息的自动过滤、特定目标的自动识别和异常状况的及时报警等功能,因此多目标跨摄像头跟踪技术应运而生并迅速成为一大研究热点,同时涌现出一批有价值的多目标跨摄像头跟踪算法.例如,Chen et al[5]提出一种基于图模型的联合优化方法.该方法使用全局图模型来匹配局部轨迹片段,在图模型中每个节点代表一个轨迹片段,每条边代表轨迹片段的连接,通过寻找从源节点到目标节点的最小代价流,得到每个跟踪对象的完整运动轨迹.Zhang et al[6]使用卷积神经网络为每个追踪对象提取鲁棒的深度特征,并引入一个特征重排序机制匹配各个追踪对象的轨迹片段.Lee et al[7]提出一种增量相机链接模型,利用追踪对象的线索信息来自适应匹配轨迹片段,并且在线更新追踪对象的线索信息,以消除视角变化的影响.Xu et al[8]使用贝叶斯公式在非重叠摄像机网络中进行路径重建,以便在不同摄像机视图之间创建轨迹片段,同时提出一种时空解析结构,即利用追踪目标的语义属性对匹配候选对象进行剪枝.本文在前人研究的基础上,提出一种新的多目标跨摄像头跟踪算法.
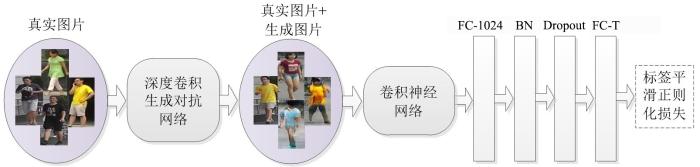
为了缓解全连接层相关性较高的问题,在原有的网络框架基础上进行修改,去掉原来网络中最后的1000维分类层,新增一个1024维的全连接层(记为FC⁃1024),并借鉴Sun et al[20]的训练思想,即在网络训练过程中始终保持该全连接层中权重向量的正交性,通过这种方式来降低全连接层中权重向量的相关性.
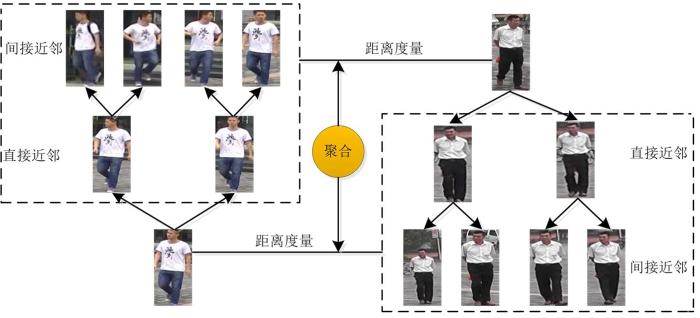
实验在2018全球(南京)人工智能应用大赛多目标跨摄像头跟踪赛题公布的测试视频上进行,测评指标为F1⁃score.该算法的优劣性很大程度上依赖行人检测和行人重识别算法的性能,因此在目前公开的数据集和自制的MTCCT2018数据集上测试本文采用的改进后的行人检测和行人重识别算法,并用累积匹配特征曲线以及平均查准率(mean Average Precision,mAP)作为测评指标.所有实验均在Ubuntu16.04环境下进行,详细配置:显卡NVIDIA TITAN XP,Cuda8.0,Cudnn5.1,Caffe,Opencv3.2.0,Python2.7.12,Nvidia驱动384和MatlabR2015b.
... 随着经济的发展和人们对安全需求的日益加强,越来越多的监控摄像机被安装在医院、火车站、机场和学校等大型公共场所.传统的监控摄像机仅有录制视频、存储视频、播放视频的功能,若要对异常状况进行实时监控和报警往往需要监控人员不间断地注视屏幕,这极其耗时耗力.最重要的是,各地部署的摄像机每天会产生海量的监控视频,仅仅依靠人工难以处理.为提高监控效率、减轻人工劳动负荷,可以借助计算机视觉、深度学习和模式识别等相关技术[1-4]实现对视频中无关信息的自动过滤、特定目标的自动识别和异常状况的及时报警等功能,因此多目标跨摄像头跟踪技术应运而生并迅速成为一大研究热点,同时涌现出一批有价值的多目标跨摄像头跟踪算法.例如,Chen et al[5]提出一种基于图模型的联合优化方法.该方法使用全局图模型来匹配局部轨迹片段,在图模型中每个节点代表一个轨迹片段,每条边代表轨迹片段的连接,通过寻找从源节点到目标节点的最小代价流,得到每个跟踪对象的完整运动轨迹.Zhang et al[6]使用卷积神经网络为每个追踪对象提取鲁棒的深度特征,并引入一个特征重排序机制匹配各个追踪对象的轨迹片段.Lee et al[7]提出一种增量相机链接模型,利用追踪对象的线索信息来自适应匹配轨迹片段,并且在线更新追踪对象的线索信息,以消除视角变化的影响.Xu et al[8]使用贝叶斯公式在非重叠摄像机网络中进行路径重建,以便在不同摄像机视图之间创建轨迹片段,同时提出一种时空解析结构,即利用追踪目标的语义属性对匹配候选对象进行剪枝.本文在前人研究的基础上,提出一种新的多目标跨摄像头跟踪算法. ...
1
2016
... 随着经济的发展和人们对安全需求的日益加强,越来越多的监控摄像机被安装在医院、火车站、机场和学校等大型公共场所.传统的监控摄像机仅有录制视频、存储视频、播放视频的功能,若要对异常状况进行实时监控和报警往往需要监控人员不间断地注视屏幕,这极其耗时耗力.最重要的是,各地部署的摄像机每天会产生海量的监控视频,仅仅依靠人工难以处理.为提高监控效率、减轻人工劳动负荷,可以借助计算机视觉、深度学习和模式识别等相关技术[1-4]实现对视频中无关信息的自动过滤、特定目标的自动识别和异常状况的及时报警等功能,因此多目标跨摄像头跟踪技术应运而生并迅速成为一大研究热点,同时涌现出一批有价值的多目标跨摄像头跟踪算法.例如,Chen et al[5]提出一种基于图模型的联合优化方法.该方法使用全局图模型来匹配局部轨迹片段,在图模型中每个节点代表一个轨迹片段,每条边代表轨迹片段的连接,通过寻找从源节点到目标节点的最小代价流,得到每个跟踪对象的完整运动轨迹.Zhang et al[6]使用卷积神经网络为每个追踪对象提取鲁棒的深度特征,并引入一个特征重排序机制匹配各个追踪对象的轨迹片段.Lee et al[7]提出一种增量相机链接模型,利用追踪对象的线索信息来自适应匹配轨迹片段,并且在线更新追踪对象的线索信息,以消除视角变化的影响.Xu et al[8]使用贝叶斯公式在非重叠摄像机网络中进行路径重建,以便在不同摄像机视图之间创建轨迹片段,同时提出一种时空解析结构,即利用追踪目标的语义属性对匹配候选对象进行剪枝.本文在前人研究的基础上,提出一种新的多目标跨摄像头跟踪算法. ...
arXiv:1610
0
2016
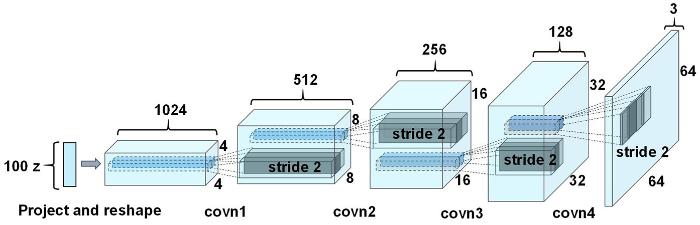
Unlabeled samples generated by gan improve the person re?identification baseline in vitro
1
2017
... 虽然DCGAN生成的行人图片与原始训练集中的真实图片有某种共性,但无法判断生成图片到底属于哪个类别,无法直接用于全监督的行人重识别训练.为了将生成图片加入训练过程,引用了Zheng et al[3]的训练策略,为生成图片分配一个统一的标签.生成图片的标签分布可定义为: ...
Camera style adaptation for person re?identification
1
2018
... 随着经济的发展和人们对安全需求的日益加强,越来越多的监控摄像机被安装在医院、火车站、机场和学校等大型公共场所.传统的监控摄像机仅有录制视频、存储视频、播放视频的功能,若要对异常状况进行实时监控和报警往往需要监控人员不间断地注视屏幕,这极其耗时耗力.最重要的是,各地部署的摄像机每天会产生海量的监控视频,仅仅依靠人工难以处理.为提高监控效率、减轻人工劳动负荷,可以借助计算机视觉、深度学习和模式识别等相关技术[1-4]实现对视频中无关信息的自动过滤、特定目标的自动识别和异常状况的及时报警等功能,因此多目标跨摄像头跟踪技术应运而生并迅速成为一大研究热点,同时涌现出一批有价值的多目标跨摄像头跟踪算法.例如,Chen et al[5]提出一种基于图模型的联合优化方法.该方法使用全局图模型来匹配局部轨迹片段,在图模型中每个节点代表一个轨迹片段,每条边代表轨迹片段的连接,通过寻找从源节点到目标节点的最小代价流,得到每个跟踪对象的完整运动轨迹.Zhang et al[6]使用卷积神经网络为每个追踪对象提取鲁棒的深度特征,并引入一个特征重排序机制匹配各个追踪对象的轨迹片段.Lee et al[7]提出一种增量相机链接模型,利用追踪对象的线索信息来自适应匹配轨迹片段,并且在线更新追踪对象的线索信息,以消除视角变化的影响.Xu et al[8]使用贝叶斯公式在非重叠摄像机网络中进行路径重建,以便在不同摄像机视图之间创建轨迹片段,同时提出一种时空解析结构,即利用追踪目标的语义属性对匹配候选对象进行剪枝.本文在前人研究的基础上,提出一种新的多目标跨摄像头跟踪算法. ...
An equalized global graph model?based approach for multicamera object tracking
1
2017
... 随着经济的发展和人们对安全需求的日益加强,越来越多的监控摄像机被安装在医院、火车站、机场和学校等大型公共场所.传统的监控摄像机仅有录制视频、存储视频、播放视频的功能,若要对异常状况进行实时监控和报警往往需要监控人员不间断地注视屏幕,这极其耗时耗力.最重要的是,各地部署的摄像机每天会产生海量的监控视频,仅仅依靠人工难以处理.为提高监控效率、减轻人工劳动负荷,可以借助计算机视觉、深度学习和模式识别等相关技术[1-4]实现对视频中无关信息的自动过滤、特定目标的自动识别和异常状况的及时报警等功能,因此多目标跨摄像头跟踪技术应运而生并迅速成为一大研究热点,同时涌现出一批有价值的多目标跨摄像头跟踪算法.例如,Chen et al[5]提出一种基于图模型的联合优化方法.该方法使用全局图模型来匹配局部轨迹片段,在图模型中每个节点代表一个轨迹片段,每条边代表轨迹片段的连接,通过寻找从源节点到目标节点的最小代价流,得到每个跟踪对象的完整运动轨迹.Zhang et al[6]使用卷积神经网络为每个追踪对象提取鲁棒的深度特征,并引入一个特征重排序机制匹配各个追踪对象的轨迹片段.Lee et al[7]提出一种增量相机链接模型,利用追踪对象的线索信息来自适应匹配轨迹片段,并且在线更新追踪对象的线索信息,以消除视角变化的影响.Xu et al[8]使用贝叶斯公式在非重叠摄像机网络中进行路径重建,以便在不同摄像机视图之间创建轨迹片段,同时提出一种时空解析结构,即利用追踪目标的语义属性对匹配候选对象进行剪枝.本文在前人研究的基础上,提出一种新的多目标跨摄像头跟踪算法. ...
arXiv:1712
1
2017
... 随着经济的发展和人们对安全需求的日益加强,越来越多的监控摄像机被安装在医院、火车站、机场和学校等大型公共场所.传统的监控摄像机仅有录制视频、存储视频、播放视频的功能,若要对异常状况进行实时监控和报警往往需要监控人员不间断地注视屏幕,这极其耗时耗力.最重要的是,各地部署的摄像机每天会产生海量的监控视频,仅仅依靠人工难以处理.为提高监控效率、减轻人工劳动负荷,可以借助计算机视觉、深度学习和模式识别等相关技术[1-4]实现对视频中无关信息的自动过滤、特定目标的自动识别和异常状况的及时报警等功能,因此多目标跨摄像头跟踪技术应运而生并迅速成为一大研究热点,同时涌现出一批有价值的多目标跨摄像头跟踪算法.例如,Chen et al[5]提出一种基于图模型的联合优化方法.该方法使用全局图模型来匹配局部轨迹片段,在图模型中每个节点代表一个轨迹片段,每条边代表轨迹片段的连接,通过寻找从源节点到目标节点的最小代价流,得到每个跟踪对象的完整运动轨迹.Zhang et al[6]使用卷积神经网络为每个追踪对象提取鲁棒的深度特征,并引入一个特征重排序机制匹配各个追踪对象的轨迹片段.Lee et al[7]提出一种增量相机链接模型,利用追踪对象的线索信息来自适应匹配轨迹片段,并且在线更新追踪对象的线索信息,以消除视角变化的影响.Xu et al[8]使用贝叶斯公式在非重叠摄像机网络中进行路径重建,以便在不同摄像机视图之间创建轨迹片段,同时提出一种时空解析结构,即利用追踪目标的语义属性对匹配候选对象进行剪枝.本文在前人研究的基础上,提出一种新的多目标跨摄像头跟踪算法. ...
Online?learning?based human tracking across non?overlapping cameras
1
2018
... 随着经济的发展和人们对安全需求的日益加强,越来越多的监控摄像机被安装在医院、火车站、机场和学校等大型公共场所.传统的监控摄像机仅有录制视频、存储视频、播放视频的功能,若要对异常状况进行实时监控和报警往往需要监控人员不间断地注视屏幕,这极其耗时耗力.最重要的是,各地部署的摄像机每天会产生海量的监控视频,仅仅依靠人工难以处理.为提高监控效率、减轻人工劳动负荷,可以借助计算机视觉、深度学习和模式识别等相关技术[1-4]实现对视频中无关信息的自动过滤、特定目标的自动识别和异常状况的及时报警等功能,因此多目标跨摄像头跟踪技术应运而生并迅速成为一大研究热点,同时涌现出一批有价值的多目标跨摄像头跟踪算法.例如,Chen et al[5]提出一种基于图模型的联合优化方法.该方法使用全局图模型来匹配局部轨迹片段,在图模型中每个节点代表一个轨迹片段,每条边代表轨迹片段的连接,通过寻找从源节点到目标节点的最小代价流,得到每个跟踪对象的完整运动轨迹.Zhang et al[6]使用卷积神经网络为每个追踪对象提取鲁棒的深度特征,并引入一个特征重排序机制匹配各个追踪对象的轨迹片段.Lee et al[7]提出一种增量相机链接模型,利用追踪对象的线索信息来自适应匹配轨迹片段,并且在线更新追踪对象的线索信息,以消除视角变化的影响.Xu et al[8]使用贝叶斯公式在非重叠摄像机网络中进行路径重建,以便在不同摄像机视图之间创建轨迹片段,同时提出一种时空解析结构,即利用追踪目标的语义属性对匹配候选对象进行剪枝.本文在前人研究的基础上,提出一种新的多目标跨摄像头跟踪算法. ...
Cross?view people tracking by scene?centered spatio?temporal parsing
1
2017
... 随着经济的发展和人们对安全需求的日益加强,越来越多的监控摄像机被安装在医院、火车站、机场和学校等大型公共场所.传统的监控摄像机仅有录制视频、存储视频、播放视频的功能,若要对异常状况进行实时监控和报警往往需要监控人员不间断地注视屏幕,这极其耗时耗力.最重要的是,各地部署的摄像机每天会产生海量的监控视频,仅仅依靠人工难以处理.为提高监控效率、减轻人工劳动负荷,可以借助计算机视觉、深度学习和模式识别等相关技术[1-4]实现对视频中无关信息的自动过滤、特定目标的自动识别和异常状况的及时报警等功能,因此多目标跨摄像头跟踪技术应运而生并迅速成为一大研究热点,同时涌现出一批有价值的多目标跨摄像头跟踪算法.例如,Chen et al[5]提出一种基于图模型的联合优化方法.该方法使用全局图模型来匹配局部轨迹片段,在图模型中每个节点代表一个轨迹片段,每条边代表轨迹片段的连接,通过寻找从源节点到目标节点的最小代价流,得到每个跟踪对象的完整运动轨迹.Zhang et al[6]使用卷积神经网络为每个追踪对象提取鲁棒的深度特征,并引入一个特征重排序机制匹配各个追踪对象的轨迹片段.Lee et al[7]提出一种增量相机链接模型,利用追踪对象的线索信息来自适应匹配轨迹片段,并且在线更新追踪对象的线索信息,以消除视角变化的影响.Xu et al[8]使用贝叶斯公式在非重叠摄像机网络中进行路径重建,以便在不同摄像机视图之间创建轨迹片段,同时提出一种时空解析结构,即利用追踪目标的语义属性对匹配候选对象进行剪枝.本文在前人研究的基础上,提出一种新的多目标跨摄像头跟踪算法. ...
... 为了缓解全连接层相关性较高的问题,在原有的网络框架基础上进行修改,去掉原来网络中最后的1000维分类层,新增一个1024维的全连接层(记为FC⁃1024),并借鉴Sun et al[20]的训练思想,即在网络训练过程中始终保持该全连接层中权重向量的正交性,通过这种方式来降低全连接层中权重向量的相关性. ...
Rethinking the inception architecture for computer vision







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}