在石油工业中,测井是整个石油生产开采中的重要环节,测井数据的完整性对地下煤层气(如干层、气层等)的判断具有重要意义.传统的储层预测往往需要耗费大量时间,并且对研究人员的专业能力要求较高.新的人工智能方法可以有效提高储层预测的效率和准确性,然而在实际生产过程中,由于测井环境的复杂以及人为因素导致采集的数据含有大量缺失值,而大量缺失数据的存在会大大降低后续储层预测的准确性.
因此,在储层预测前,通常会对缺失数据进行处理.流行的方法是缺失值插补[1 ] ,包括经典的回归[2 ] 和相关分析等方法,人工神经网络[3 ] 和遗传规划[4 ] 也有助于设计复杂的方案.另一种方法是主动特征获取(Active Feature Acquisition,AFA)[5 ] ,这是属性值严重缺失时最可靠的方法[6 ] .在这种情况下,缺失的值可以根据请求以一定的代价获得,例如运行附加的诊断过程.这些算法在一定程度上改善了数据的可用性和可学习性.然而,对于储层预测这种属性缺失同时标签稀缺的场景,如何对属性值的价值和标签价值进行统一评估,获取关键的属性值和标签仍是需要考虑的关键问题.
因此,本文提出一个新的代价敏感主动学习问题,并设计一种动态评估和增量学习算法(Active Learning Algorithm with Unified Evaluation and Dynamic Selection,ALES)来解决此问题.首先,考虑到不同的输入、输出和各种代价设置,定义一个五元组的不完备代价敏感信息系统数据模型.输入包括不完备数据集、属性代价和教师代价,输出包括查询的关键属性值和标签以及预测的样本,优化目标是总代价最小.
其次,提出一种统一评估和动态选择关键属性值和标签的方法.使用softmax回归来获得每个样本预测为每个类别的概率;然后计算预期的误分类代价和属性填补代价,通过排列组合和贪婪策略获得最优的属性值填补方案;最后,选择代价最小的一个关键样本来执行相应的预测或查询,并增量更新训练模型.
第三,开发一种新的动态评估和增量学习算法(ALES).图1 是ALES算法的框架图,通过单个样本x i
图1
图1
ALES算法框图
Fig.1
The algorithm framework of ALES
算法在三个真实的测井数据集上进行测试实验.将ALES算法与流行的分类器和最新的代价敏感学习算法进行比较,然后使用Friedman检验和Nemenyi假设检验来验证ALES与对比算法之间的显著性差异.结果表明,就平均代价而言,ALES优于这些对比算法.
1 问题描述
本节介绍三种典型的主动学习问题,包括固定查询个数的主动学习、代价敏感主动学习和不完备数据的代价敏感主动学习.
许多复杂的学习任务,标记样本非常困难,既耗时又昂贵.主动学习能制定策略动态选择关键样本,与专家交互,有效降低所需训练样本数量[7 ] .根据Settles[8 ] 的说法“主动学习试图查询专家获取未标记样本标签来克服标记瓶颈”,主动学习的根本问题是确定如何选择最关键的样本.有两个主要标准,即信息性[9 ] 和代表性[10 -11 ] .
1.1 固定查询个数的主动学习
在某些应用场景中,专家提供固定数量的标签,例如,考虑这样一种情况,某任务总预算为10000元,专家每标注一个标签花费10元,因此总标签的数量为1000个.
S = ( U , C , D ) (1)
其中,U C D
问题1考虑固定查询个数的主动学习.输入是决策系统S = ( U , C , D ) n l U I U I I . 与监督学习不同,训练子集U I U I I
输入:决策系统S = ( U , C , D ) D n l
1.2 代价敏感主动学习
对于代价敏感主动学习,教师代价和误分类代价应纳入决策系统.
定义2 考虑教师代价和误分类代价敏感的决策系统(TMC⁃DS)是五元组:
S = ( U , C , D , M , t ) (2)
考虑代价时,问题1演变为代价敏感主动学习问题(问题2).输入为TMC⁃DS:S = ( U , C , D , M , t ) D U I U I I . 这里t × U I ∑ i = 1 U - U I M ( l i , y i ) t × U I + ∑ i = 1 U - U I M ( l i , y i )
输入:TMC⁃DS:S = ( U , C , D , M , t )
优化目标:m i n t × U I + ∑ i = 1 | U - U I M ( l i , y i ) .
1.3 不完备数据的代价敏感主动学习
定义3 不完备的代价敏感信息系统(ICS⁃DS)是六元组:
S = ( X , y , W , M , t , a ) (3)
其中,X = x 1 , x 2 , ⋯ , x n ∈ R n × m y W X
如果x i j ω i j = 0 a 表1 是一个不完备的代价敏感信息系统,其中X = x 1 , x 2 , ⋯ , x 15 . 这里的条件属性是数值,缺失值用*表示.
问题3考虑不完备代价敏感决策系统(ICS⁃DS).缺失的属性值和标签都能以代价获取.输出为查询的属性值集合A r X r X t . 优化目标是总代价最小.总代价包括三部分:属性代价、标签代价和误分类代价.
输入:ICS⁃IS:S = ( X , y , W , M , t , a ) .
输出:查询的属性值集合A r X r X t .
2 改进的算法
本文提出统一评估和动态选择的代价敏感主动学习算法,实现属性值和标签的动态查询.首先,根据训练集构建模型并采用softmax回归训练参数θ f a ( x s ) f l ( x s ) x s U I x s x s U I θ
2.1 统一评估和动态选择的代价敏感主动学习
2.1.1 优化方法
数据集用X = x 1 , x 2 , ⋯ , x n x = x i 1 , x i 2 , ⋯ , x i m T m θ x s f *
s * = a r g m i n n l < s < n f * ( x s ) (4)
其中,f * ( x s ) = m i n f a ( x s ) , f l ( x s ) .
2.1.2 模型构建及参数更新
该部分是算法的第一阶段,主要包括选择具有代表性的样本以构成初始训练集、构建模型和参数更新.
2.1.2.1 构建初始训练集
定义一个新的指标,即样本权重γ . 首先,使用CFDP[12 ] 算法中的方法来计算局部密度ρ . 样本x i ρ i
ρ ( x i ) = ∑ x j χ d i s t ( x i , x j ) - d c (5)
其中,当x < 0 χ ( x ) = 1 χ ( x ) = 0 d c d i s t ( x i , x j )
其次,计算最小距离δ . 通过计算样本x i δ
δ ( x i ) = m a x x j d i s t ( x i , x j ) ρ ( x i ) m i n j : ρ ( x i ) > ρ ( x j ) d i s t ( x i , x j ) o t h e r w i s e (6)
γ ( x i ) = ρ ( x i ) ⋅ δ ( x i ) (7)
选择具有最高γ ( x i ) n l U I .
2.1.2.2 构建模型
建立概率预测模型,通过softmax回归获得P y j x i ; θ . 给定任何样本x i y j
P y j x i ; θ = e θ j T x i ∑ l = 1 k e θ l T x i (8)
2.1.2.3 参数更新
首先确定损失函数J ( θ ) J ( θ )
J ( θ ) = - 1 n l ∑ i = 1 n l ∑ j = 1 k 1 y i = j l g e θ j T x i ∑ l = 1 k e θ l T x i (9)
其中,i ∈ 1,2 , ⋯ , n l j ∈ 1,2 , ⋯ , k i i j ∙ θ . 使用迭代优化算法(例如梯度下降法[13 ] 或拟牛顿法[14 ] )来求解J ( θ ) . 经过一些推导后,获得代表损失函数偏导数的梯度:
∇ θ j J ( θ ) = - 1 n l ∑ i = 1 n l x i y i = j - P y i = j x i ; θ (10)
θ j : = θ j - α ∇ θ j J ( θ ) (11)
其中,α U I J ( θ ) θ .
2.1.3 统一评估和动态选择属性值及标签
统一评估和动态选择属性值及标签的关键在于各种代价的计算.考虑五个代价函数,即误分类代价f m ( x ) f f ( x ) f a ( x ) f l ( x ) f ( x ) . 下文详细介绍五种代价的计算方法.
2.1.3.1 期望误分类代价函数f m ( x )
期望误分类代价在样本决策中起着至关重要的作用.利用分类概率,可以获得期望误分类代价函数f m ( x ) . 计算该函数主要包括以下三个步骤.首先,使用参数θ h θ ( x ) . 对于每个输入的样本x j P y j x ; θ . 假设函数为:
h θ ( x ) = p ( y ) = 1 x ; θ p ( y ) = 2 x ; θ ⋮ p ( y ) = k x ; θ = 1 ∑ j = 1 k e θ j T x e θ 1 T x e θ 2 T x ⋮ e θ k T x (12)
其中,θ 1 , θ 2 , ⋯ , θ k ∈ R m + 1 1 ∑ j = 1 k e θ j T x
P ( x ) = m a x 1 ≤ j ≤ k P y j x ; θ (13)
f m ( x i ) = 1 - m a x 1 ≤ j ≤ k P y j x i ⋅ M i j (14)
2.1.3.2 属性填补代价函数f f ( x )
对于样本x f f ( x ) . 根据预期的误分类代价、属性查询代价a m '
f f ( x f ) = 1 - m a x 1 ≤ j ≤ k P y j x f ⋅ M i j + m ' a (15)
2.1.3.3 属性代价函数f a ( x )
利用排列组合和贪婪策略,设计属性代价函数f a ( x )
x ¯ = x ¯ 1 k 1 + x ¯ 2 k 2 + ⋯ + x ¯ n k n k 1 + k 2 + ⋯ + k n (16)
其次,通过排列组合策略,获得多种属性值的填补方案.缺失属性的填补方案数量为:
c = ∑ i = 0 m ' C m ' i (17)
第三,通过贪婪策略,搜索所有填补方案中代价最小的一个.属性代价f a ( x )
f a ( x ) = m i n 1 ≤ f ≤ c 1 - P ( x f ) M + m ' a (18)
2.1.3.4 标签代价函数f l ( x )
f l ( x i ) = t (19)
2.1.3.5 样本代价f ( x )
对于任何样本x f a ( x ) f l ( x ) . 因此,将两者中的最小值作为样本代价,即:
f * ( x ) = m i n f a ( x ) , f l ( x ) (20)
2.2 算法描述
本节首先描述ALES算法的伪代码,其次介绍平均代价计算公式,最后分析算法时间复杂度.
2.2.1 ALES算法伪代码
算法1描述了ALES算法,该算法迭代地选择属性值以预测标签或直接查询标签.
算法1 不完备信息系统代价敏感主动学习算法(ALES)
1.U I = ∅ U I I = U [ l i ] n × 1 ← - 1
5. [ θ ] k × ( m + 1 ) ← s o f t m a x T r a i n ( U I ) θ k
7. { s f , f a } ← c o m p u t e A t t r i b u t e C o s t ( X )
14. x s ← a r g m i n 1 ≤ i ≤ U I I | ( f ) x s
16. if (x j
第1行对应初始化阶段.专家标记的样本集为U I = ∅ U I I = U . 将所有样本的标签初始化为-1.第2行选择k U I . 第3行更新数据U I I .
第4至14行统一评估和动态选择属性值及标签.第5行通过softmax回归获得模型参数θ . 第7至13行计算样本代价f ( x ) . 第7行计算属性代价f a ( x ) f a ( x ) f l ( x ) . 两者中最小的是样本代价f ( x ) . 第14行选择U I I x s .
第15至19行将所选样本x s s f x s x s s f U I I = = ∅
2.2.2 平均代价计算
ALES算法的优化目标是最小化平均代价,如式(21)所示:
m i n 1 n × a × A r + t × X r + ∑ i = 1 | X t | M ( l i , y i ) (21)
代价的计算包含三部分,分别为属性查询代价、标签查询代价以及误分类代价.
2.2.3 复杂度分析
表2 分析了ALES算法的时间复杂度.令m n
O ( m n 2 ) + O ( n 2 ) + O ( m ' c n ) = O ( m n 2 ) (22)
3 实验结果与分析
3.1 数据集
实验采用三个真实的测井数据集,包括某油气田公司滇黔川地区天然气井数据、美国Hugoton油气田的井下数据和Panoma油气田井下数据,具体信息如表3 所示.数据的属性包括伽马射线、电阻率、光电效应、中子密度空隙率等属性指标,最终的储层预测目标为干层或气层等决策信息.实验采用完全随机缺失(Missing Completely at Random,MCAR)的方法,并且设置缺失率为10%~50%.实验中相应的代价设置:属性查询代价a = 0.2 t = 1 M ( l i , y i ) = 2 .
3.2 实验设计
将ALES算法与朴素贝叶斯(NB),k最近邻(kNN),J48,CALF[15 ] ,GESI[16 ] 和BPCA[17 ] 等算法进行对比,获得每种算法的平均代价.其中NB,kNN和J48三种监督型代价敏感分类算法使用Weka[18 ] 的内置代码进行测试.CALF,GESI和BPCA是缺失值填补的算法.CALF提出一种基于协同过滤加权预测的主动学习填补算法.GESI提出一种新颖的非参数单插补广义回归神经网络集成算法.BPCA提出一种基于双聚类的贝叶斯主成分分析方法.在双聚类中,识别出与缺失样本最相关的基因和实验条件,并在这些双聚类上运行BPCA来估算缺失值.实验中三个真实测井数据通过MCAR的方法,将属性值随机缺失,分别产生缺失率为10%~50%的五个数据集.
3.3 实验结果及分析
表4 对比了缺失率为50%时ALES算法和其他六种算法的平均代价,表中的黑体字表示每个数据集的最佳结果.可以看出,ALES算法优于现有的六种分类算法.各个算法的平均代价结果,通过KEEL[19 ] 软件内置的检验方法进行结果分析,得到平均排名和性能分析.
平均排名是通过弗里德曼(Friedman)方法获得的.当有两个以上相关算法时,Friedman检验[20 ] 是最著名的非参数检验.通过显著性分析,ALES算法的平均排名为1.00,在真实测井数据集的测试中排名第一.ALES优于现有的监督分类器算法和缺失值填补算法.
根据弗里德曼(Friedman)统计,可以拒绝“所有算法都具有相同性能”的假设.统计结果表明,这些算法的性能明显不同.使用事后Nemenyi检验在α = 0.05 表5 是最后的测试结果,可见ALES算法明显优于其他六种算法.根据Friedman检验计算出的p 值排名结果,首先缺失值填补算法普遍要比传统的监督算法的平均代价要小,而在缺失值填补算法中,ALES算法比其他的填补算法平均代价小,填补效果更好,分类精度较高.
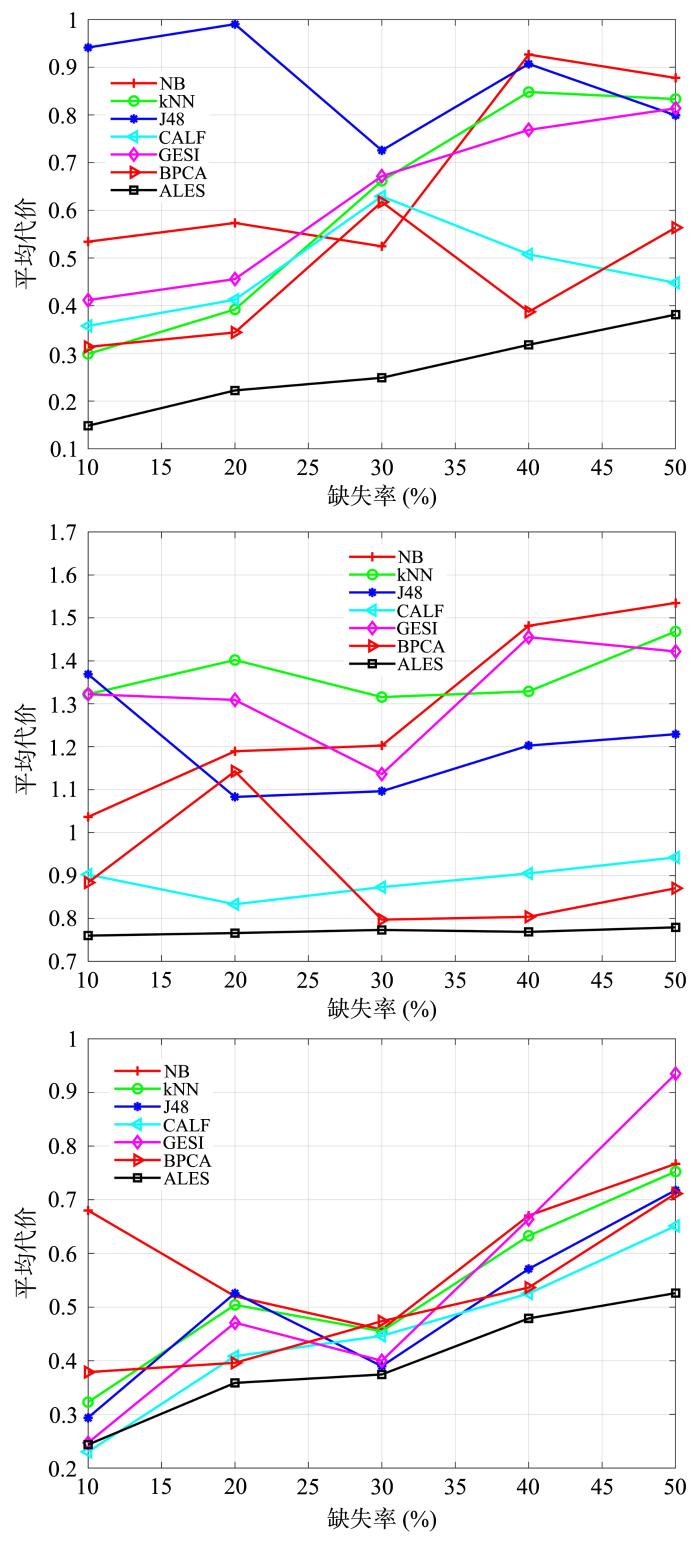
图2 显示了ALES和六种算法在10%,20%,30%,40%和50%缺失率下的平均代价对比.对于三个真实测井数据集,ALES算法的平均代价曲线明显低于其他算法,这表明ALES算法在各个缺失率下都有不错表现.
图2
图2
不同缺失率时ALES和六种算法的平均代价对比(从上至下分别对应:Well 01;Well 02;Well 03)
Fig.2
The average cost of ALES and six algorithms on different missing ratio (Well 01,Well 02 and Well 03 from up to dowm)
4 结 论
在属性缺失的情况下实现储层的准确预测是一个困难而且有意义的问题,本文从数据模型、代价敏感的优化方法和算法设计三个层面研究了该问题.数据模型考虑了不完备的数据、属性查询代价和标签查询代价;优化方法定义了代价函数,来获得属性值和标签的统一评估;算法设计给出了各种输入、输出和优化目标.实验结果表明,ALES算法可以以较低的代价填补缺失值,也可以更好地识别含气层.同时,显著性分析的结果证明ALES算法优于其他监督算法和填补算法.
参考文献
View Option
[1]
Zahin S A Ahmed C F Alam T An effective method for classification with missing values
Applied Intelligence ,2018 ,48 (10 ):3209 -3230 .
[本文引用: 1]
[2]
Zhang J Clayton M K Townsend P A Missing data and regression models for spatial images
IEEE Transactions on Geoscience and Remote Sensing ,2015 ,53 (3 ):1574 -1582 .
[本文引用: 1]
[3]
Silva⁃Ramírez E L Pino⁃Mejías R López⁃Coello M et al Missing value imputation on missing completely at random data using multilayer perceptrons
Neural Networks ,2011 ,24 (1 ):121 -129 .
[本文引用: 1]
[4]
Azadeh A Asadzadeh S M Jafari⁃Marandi R et al Optimum estimation of missing values in randomized complete block design by genetic algorithm
Knowledge⁃Based Systems ,2013 ,37 :37 -47 .
[本文引用: 1]
[5]
Melville P Saar⁃Tsechansky M Provost F et al Active feature⁃value acquisition for classifier induction
∥The 4th IEEE International Conference on Data Mining . Brighton,United Kingdom :IEEE ,2004 :483 -486 .
[本文引用: 1]
[6]
Kwon O Sim J M Effects of data set features on the performances of classification algorithms
Expert Systems with Applications ,2013 ,40 (5 ):1847 -1857 .
[本文引用: 1]
[7]
Min F Liu F L Wen L Y et al Tri⁃partition cost⁃sensitive active learning through kNN
Soft Computing ,2019 ,23 (5 ):1557 -1572 .
[本文引用: 1]
[8]
Settles B Active learning . San Rafael :Morgan & Claypool Publishers ,2012 :1 -114 .
[本文引用: 1]
[9]
Tong S Koller D Support vector machine active learning with applications to text classification
The Journal of Machine Learning Research ,2002 ,2 (1 ):45 -66 .
[本文引用: 1]
[10]
Wang M Min F Zhang Z H et al Active learning through density clustering
Expert Systems with Applications ,2017 ,85 :305 -317 .
[本文引用: 1]
[11]
Wang M Fu K Min F et al Active learning through label error statistical methods
Knowledge⁃Based Systems ,2020 ,189 :105140 .
[本文引用: 1]
[12]
Rodriguez A Laio A Machine learning
clustering by fast search and find of density peaks. Science ,2014 ,344 (6191 ):1492 -1496 .
[本文引用: 1]
[13]
Allcock J Zhang S Y Quantum machine learning
National Science Review ,2019 ,6 (1 ):26 -28 .
[本文引用: 1]
[14]
Dennis J E Moré J J Quasi⁃newton methods,motivation and theory
SIAM Review ,1977 ,19 (1 ):46 -89 .
[本文引用: 1]
[15]
黄帷 ,闵帆 ,任杰 基于协同过滤加权预测的主动学习缺失值填补算法
南京大学学报(自然科学) ,2018 ,54 (4 ):758 -765 .
[本文引用: 1]
Huang W Min F Ren J Missing value imputation with active learning based on collaborative filtering weighted prediction
Journal of Nanjing University (Natural Science) ,2018 ,54 (4 ):758 -765 .
[本文引用: 1]
[16]
Gheyas I A Smith L S A neural network⁃based framework for the reconstruction of incomplete data sets
Neurocomputing ,2010 ,73 (16-18 ):3039 -3065 .
[本文引用: 1]
[17]
Meng F C Cai C Yan H A bicluster⁃based bayesian principal component analysis method for microarray missing value estimation
IEEE Journal of Biomedical and Health Informatics ,2014 ,18 (3 ):863 -871 .
[本文引用: 1]
[18]
Holmes G Donkin A Witten I H WEKA:A machine learning workbench
∥Proceedings of ANZIIS'94:Australian New Zealnd Intelligent Information Systems Conference . Brisbane,Australia :IEEE ,1994 :357 -361 .
[本文引用: 1]
[19]
Triguero I González S Moyano J M et al KEEL 3
.0 :an open source software for multi⁃stage analysis in data mining
International Journal of Computational Intelligence Systems ,2017 ,10 (1 ):1238 -1249 .
[本文引用: 1]
[20]
Reyes O Altalhi A H Ventura S Statistical comparisons of active learning strategies over multiple datasets
Knowledge⁃Based Systems ,2018 ,145 :274 -288 .
[本文引用: 1]
An effective method for classification with missing values
1
2018
... 因此,在储层预测前,通常会对缺失数据进行处理.流行的方法是缺失值插补[1 ] ,包括经典的回归[2 ] 和相关分析等方法,人工神经网络[3 ] 和遗传规划[4 ] 也有助于设计复杂的方案.另一种方法是主动特征获取(Active Feature Acquisition,AFA)[5 ] ,这是属性值严重缺失时最可靠的方法[6 ] .在这种情况下,缺失的值可以根据请求以一定的代价获得,例如运行附加的诊断过程.这些算法在一定程度上改善了数据的可用性和可学习性.然而,对于储层预测这种属性缺失同时标签稀缺的场景,如何对属性值的价值和标签价值进行统一评估,获取关键的属性值和标签仍是需要考虑的关键问题. ...
Missing data and regression models for spatial images
1
2015
... 因此,在储层预测前,通常会对缺失数据进行处理.流行的方法是缺失值插补[1 ] ,包括经典的回归[2 ] 和相关分析等方法,人工神经网络[3 ] 和遗传规划[4 ] 也有助于设计复杂的方案.另一种方法是主动特征获取(Active Feature Acquisition,AFA)[5 ] ,这是属性值严重缺失时最可靠的方法[6 ] .在这种情况下,缺失的值可以根据请求以一定的代价获得,例如运行附加的诊断过程.这些算法在一定程度上改善了数据的可用性和可学习性.然而,对于储层预测这种属性缺失同时标签稀缺的场景,如何对属性值的价值和标签价值进行统一评估,获取关键的属性值和标签仍是需要考虑的关键问题. ...
Missing value imputation on missing completely at random data using multilayer perceptrons
1
2011
... 因此,在储层预测前,通常会对缺失数据进行处理.流行的方法是缺失值插补[1 ] ,包括经典的回归[2 ] 和相关分析等方法,人工神经网络[3 ] 和遗传规划[4 ] 也有助于设计复杂的方案.另一种方法是主动特征获取(Active Feature Acquisition,AFA)[5 ] ,这是属性值严重缺失时最可靠的方法[6 ] .在这种情况下,缺失的值可以根据请求以一定的代价获得,例如运行附加的诊断过程.这些算法在一定程度上改善了数据的可用性和可学习性.然而,对于储层预测这种属性缺失同时标签稀缺的场景,如何对属性值的价值和标签价值进行统一评估,获取关键的属性值和标签仍是需要考虑的关键问题. ...
Optimum estimation of missing values in randomized complete block design by genetic algorithm
1
2013
... 因此,在储层预测前,通常会对缺失数据进行处理.流行的方法是缺失值插补[1 ] ,包括经典的回归[2 ] 和相关分析等方法,人工神经网络[3 ] 和遗传规划[4 ] 也有助于设计复杂的方案.另一种方法是主动特征获取(Active Feature Acquisition,AFA)[5 ] ,这是属性值严重缺失时最可靠的方法[6 ] .在这种情况下,缺失的值可以根据请求以一定的代价获得,例如运行附加的诊断过程.这些算法在一定程度上改善了数据的可用性和可学习性.然而,对于储层预测这种属性缺失同时标签稀缺的场景,如何对属性值的价值和标签价值进行统一评估,获取关键的属性值和标签仍是需要考虑的关键问题. ...
Active feature?value acquisition for classifier induction
1
2004
... 因此,在储层预测前,通常会对缺失数据进行处理.流行的方法是缺失值插补[1 ] ,包括经典的回归[2 ] 和相关分析等方法,人工神经网络[3 ] 和遗传规划[4 ] 也有助于设计复杂的方案.另一种方法是主动特征获取(Active Feature Acquisition,AFA)[5 ] ,这是属性值严重缺失时最可靠的方法[6 ] .在这种情况下,缺失的值可以根据请求以一定的代价获得,例如运行附加的诊断过程.这些算法在一定程度上改善了数据的可用性和可学习性.然而,对于储层预测这种属性缺失同时标签稀缺的场景,如何对属性值的价值和标签价值进行统一评估,获取关键的属性值和标签仍是需要考虑的关键问题. ...
Effects of data set features on the performances of classification algorithms
1
2013
... 因此,在储层预测前,通常会对缺失数据进行处理.流行的方法是缺失值插补[1 ] ,包括经典的回归[2 ] 和相关分析等方法,人工神经网络[3 ] 和遗传规划[4 ] 也有助于设计复杂的方案.另一种方法是主动特征获取(Active Feature Acquisition,AFA)[5 ] ,这是属性值严重缺失时最可靠的方法[6 ] .在这种情况下,缺失的值可以根据请求以一定的代价获得,例如运行附加的诊断过程.这些算法在一定程度上改善了数据的可用性和可学习性.然而,对于储层预测这种属性缺失同时标签稀缺的场景,如何对属性值的价值和标签价值进行统一评估,获取关键的属性值和标签仍是需要考虑的关键问题. ...
Tri?partition cost?sensitive active learning through kNN
1
2019
... 许多复杂的学习任务,标记样本非常困难,既耗时又昂贵.主动学习能制定策略动态选择关键样本,与专家交互,有效降低所需训练样本数量[7 ] .根据Settles[8 ] 的说法“主动学习试图查询专家获取未标记样本标签来克服标记瓶颈”,主动学习的根本问题是确定如何选择最关键的样本.有两个主要标准,即信息性[9 ] 和代表性[10 -11 ] . ...
1
2012
... 许多复杂的学习任务,标记样本非常困难,既耗时又昂贵.主动学习能制定策略动态选择关键样本,与专家交互,有效降低所需训练样本数量[7 ] .根据Settles[8 ] 的说法“主动学习试图查询专家获取未标记样本标签来克服标记瓶颈”,主动学习的根本问题是确定如何选择最关键的样本.有两个主要标准,即信息性[9 ] 和代表性[10 -11 ] . ...
Support vector machine active learning with applications to text classification
1
2002
... 许多复杂的学习任务,标记样本非常困难,既耗时又昂贵.主动学习能制定策略动态选择关键样本,与专家交互,有效降低所需训练样本数量[7 ] .根据Settles[8 ] 的说法“主动学习试图查询专家获取未标记样本标签来克服标记瓶颈”,主动学习的根本问题是确定如何选择最关键的样本.有两个主要标准,即信息性[9 ] 和代表性[10 -11 ] . ...
Active learning through density clustering
1
2017
... 许多复杂的学习任务,标记样本非常困难,既耗时又昂贵.主动学习能制定策略动态选择关键样本,与专家交互,有效降低所需训练样本数量[7 ] .根据Settles[8 ] 的说法“主动学习试图查询专家获取未标记样本标签来克服标记瓶颈”,主动学习的根本问题是确定如何选择最关键的样本.有两个主要标准,即信息性[9 ] 和代表性[10 -11 ] . ...
Active learning through label error statistical methods
1
2020
... 许多复杂的学习任务,标记样本非常困难,既耗时又昂贵.主动学习能制定策略动态选择关键样本,与专家交互,有效降低所需训练样本数量[7 ] .根据Settles[8 ] 的说法“主动学习试图查询专家获取未标记样本标签来克服标记瓶颈”,主动学习的根本问题是确定如何选择最关键的样本.有两个主要标准,即信息性[9 ] 和代表性[10 -11 ] . ...
Machine learning
1
2014
... 定义一个新的指标,即样本权重γ . 首先,使用CFDP[12 ] 算法中的方法来计算局部密度ρ . 样本x i ρ i
Quantum machine learning
1
2019
... 其中,i ∈ 1,2 , ⋯ , n l j ∈ 1,2 , ⋯ , k i i j ∙ θ . 使用迭代优化算法(例如梯度下降法[13 ] 或拟牛顿法[14 ] )来求解J ( θ ) . 经过一些推导后,获得代表损失函数偏导数的梯度: ...
Quasi?newton methods,motivation and theory
1
1977
... 其中,i ∈ 1,2 , ⋯ , n l j ∈ 1,2 , ⋯ , k i i j ∙ θ . 使用迭代优化算法(例如梯度下降法[13 ] 或拟牛顿法[14 ] )来求解J ( θ ) . 经过一些推导后,获得代表损失函数偏导数的梯度: ...
基于协同过滤加权预测的主动学习缺失值填补算法
1
2018
... 将ALES算法与朴素贝叶斯(NB),k最近邻(kNN),J48,CALF[15 ] ,GESI[16 ] 和BPCA[17 ] 等算法进行对比,获得每种算法的平均代价.其中NB,kNN和J48三种监督型代价敏感分类算法使用Weka[18 ] 的内置代码进行测试.CALF,GESI和BPCA是缺失值填补的算法.CALF提出一种基于协同过滤加权预测的主动学习填补算法.GESI提出一种新颖的非参数单插补广义回归神经网络集成算法.BPCA提出一种基于双聚类的贝叶斯主成分分析方法.在双聚类中,识别出与缺失样本最相关的基因和实验条件,并在这些双聚类上运行BPCA来估算缺失值.实验中三个真实测井数据通过MCAR的方法,将属性值随机缺失,分别产生缺失率为10%~50%的五个数据集. ...
基于协同过滤加权预测的主动学习缺失值填补算法
1
2018
... 将ALES算法与朴素贝叶斯(NB),k最近邻(kNN),J48,CALF[15 ] ,GESI[16 ] 和BPCA[17 ] 等算法进行对比,获得每种算法的平均代价.其中NB,kNN和J48三种监督型代价敏感分类算法使用Weka[18 ] 的内置代码进行测试.CALF,GESI和BPCA是缺失值填补的算法.CALF提出一种基于协同过滤加权预测的主动学习填补算法.GESI提出一种新颖的非参数单插补广义回归神经网络集成算法.BPCA提出一种基于双聚类的贝叶斯主成分分析方法.在双聚类中,识别出与缺失样本最相关的基因和实验条件,并在这些双聚类上运行BPCA来估算缺失值.实验中三个真实测井数据通过MCAR的方法,将属性值随机缺失,分别产生缺失率为10%~50%的五个数据集. ...
A neural network?based framework for the reconstruction of incomplete data sets
1
2010
... 将ALES算法与朴素贝叶斯(NB),k最近邻(kNN),J48,CALF[15 ] ,GESI[16 ] 和BPCA[17 ] 等算法进行对比,获得每种算法的平均代价.其中NB,kNN和J48三种监督型代价敏感分类算法使用Weka[18 ] 的内置代码进行测试.CALF,GESI和BPCA是缺失值填补的算法.CALF提出一种基于协同过滤加权预测的主动学习填补算法.GESI提出一种新颖的非参数单插补广义回归神经网络集成算法.BPCA提出一种基于双聚类的贝叶斯主成分分析方法.在双聚类中,识别出与缺失样本最相关的基因和实验条件,并在这些双聚类上运行BPCA来估算缺失值.实验中三个真实测井数据通过MCAR的方法,将属性值随机缺失,分别产生缺失率为10%~50%的五个数据集. ...
A bicluster?based bayesian principal component analysis method for microarray missing value estimation
1
2014
... 将ALES算法与朴素贝叶斯(NB),k最近邻(kNN),J48,CALF[15 ] ,GESI[16 ] 和BPCA[17 ] 等算法进行对比,获得每种算法的平均代价.其中NB,kNN和J48三种监督型代价敏感分类算法使用Weka[18 ] 的内置代码进行测试.CALF,GESI和BPCA是缺失值填补的算法.CALF提出一种基于协同过滤加权预测的主动学习填补算法.GESI提出一种新颖的非参数单插补广义回归神经网络集成算法.BPCA提出一种基于双聚类的贝叶斯主成分分析方法.在双聚类中,识别出与缺失样本最相关的基因和实验条件,并在这些双聚类上运行BPCA来估算缺失值.实验中三个真实测井数据通过MCAR的方法,将属性值随机缺失,分别产生缺失率为10%~50%的五个数据集. ...
WEKA:A machine learning workbench
1
1994
... 将ALES算法与朴素贝叶斯(NB),k最近邻(kNN),J48,CALF[15 ] ,GESI[16 ] 和BPCA[17 ] 等算法进行对比,获得每种算法的平均代价.其中NB,kNN和J48三种监督型代价敏感分类算法使用Weka[18 ] 的内置代码进行测试.CALF,GESI和BPCA是缺失值填补的算法.CALF提出一种基于协同过滤加权预测的主动学习填补算法.GESI提出一种新颖的非参数单插补广义回归神经网络集成算法.BPCA提出一种基于双聚类的贝叶斯主成分分析方法.在双聚类中,识别出与缺失样本最相关的基因和实验条件,并在这些双聚类上运行BPCA来估算缺失值.实验中三个真实测井数据通过MCAR的方法,将属性值随机缺失,分别产生缺失率为10%~50%的五个数据集. ...
an open source software for multi?stage analysis in data mining
1
2017
... 表4 对比了缺失率为50%时ALES算法和其他六种算法的平均代价,表中的黑体字表示每个数据集的最佳结果.可以看出,ALES算法优于现有的六种分类算法.各个算法的平均代价结果,通过KEEL[19 ] 软件内置的检验方法进行结果分析,得到平均排名和性能分析. ...
Statistical comparisons of active learning strategies over multiple datasets
1
2018
... 平均排名是通过弗里德曼(Friedman)方法获得的.当有两个以上相关算法时,Friedman检验[20 ] 是最著名的非参数检验.通过显著性分析,ALES算法的平均排名为1.00,在真实测井数据集的测试中排名第一.ALES优于现有的监督分类器算法和缺失值填补算法. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}