大数据时代无时无刻地进行着海量的数据和信息交换,如何从海量的高维数据中挖掘提取有价值的信息是近年讨论的热点问题.数据聚类分析是数据挖掘的有效工具之一,是数据挖掘领域研究的重点和热点[1 -3 ] .聚类分析是一种通过算法自动分析数据对象之间的相似性或者相异性、自动地将数据集中未标记的数据分到不同的簇之中的方法.每个簇中的数据在某个标准下具有一定的相似性,而簇间的数据在这一标准下的相似性则很低[4 ] .这种方法的用途是对原始的数据集合进行处理,得到一种聚类处理结果,再通过对聚类结果的分析,提取人们需要的有价值的信息.目前,聚类分析已被广泛应用到各个领域:在商业领域,聚类分析可以被用来发现不同的客户群,研究不同客户的消费行为,寻找潜在市场来制定不同的销售方案[5 -6 ] ;在生物医学领域,聚类分析能够对基因进行分类,从而研究不同的种群结构,分析与各种疾病之间的潜在联系[7 ] ;在电子商务类行业,聚类分析能从网站建设的数据中挖掘分析出各个客户的相似习惯,达到优化服务的目的.
近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性.
迁移学习是一种在已有的环境中认知和学习到的信息被应用到新的任务和环境下的能力.迁移学习作为一种能利用其他相似领域上学到的知识来辅助当前任务的一种方法,被广泛运用于各个邻域中[21 ] .根据源任务和目标任务之间的差异,可将迁移学习大致分为归纳式迁移学习、直推式迁移学习和无监督学习[22 ] .在聚类分析算法的过程中,需要大量已知数据支持,而实际情况下,很多时候会出现已知数据样本不足、数据残缺或者信息不准确的情况[23 ] .因此本文引入熵的概念,根据信息熵来确定权重,并将迁移学习与子空间聚类算法结合,利用迁移学习改进优化软子空间聚类算法的聚类性能.
1 基础理论
1.1 子空间聚类算法
1.1.1 软子空间聚类算法
在传统的软子空间聚类算法中,所有的簇类共享相同的子空间和权重向量,例如WK⁃Means(Weights K⁃Means)算法和WFCM(Weighting Fuzzy C⁃Means)算法.
WFCM算法的全称为样本加权模糊C均值算法,它是对FCM((Fuzzy C⁃means))算法的改进[24 ] .FCM算法基于传统欧式距离,每个数据样本对聚类的贡献几乎相同,然而实际上在高维领域,每个数据样本都会对聚类产生不同的程度的影响.用传统的FCM算法无法体现噪声点或者偏远数据样本集体对聚类的影响,所以WFCM引入一种点密度函数来作为样本点的加权系数计算方法,对于每个样本点,点密度函数计算方式为:
z i = ∑ j = 1 , j ≠ i n 1 d i j (1)
d i j = x i - x j , 1 ≤ i ≤ n , 1 ≤ j ≤ n (2)
其中,d i j z W i i X i
W i = z i ∑ j = 1 n z j , 1 ≤ i ≤ n (3)
将W i
J ( u , v , w ) = ∑ i = 1 c ∑ j = 1 n w j u i j m d i j 2 (4)
v i = ∑ j = 1 n w j u i j m x j ∑ j = 1 n w j u i j m , 1 ≤ i ≤ c (5)
u i j = ∑ k = 1 c v i - x j v k - x j 2 m - 1 - 1 , 1 ≤ i ≤ c , 1 ≤ j ≤ n (6)
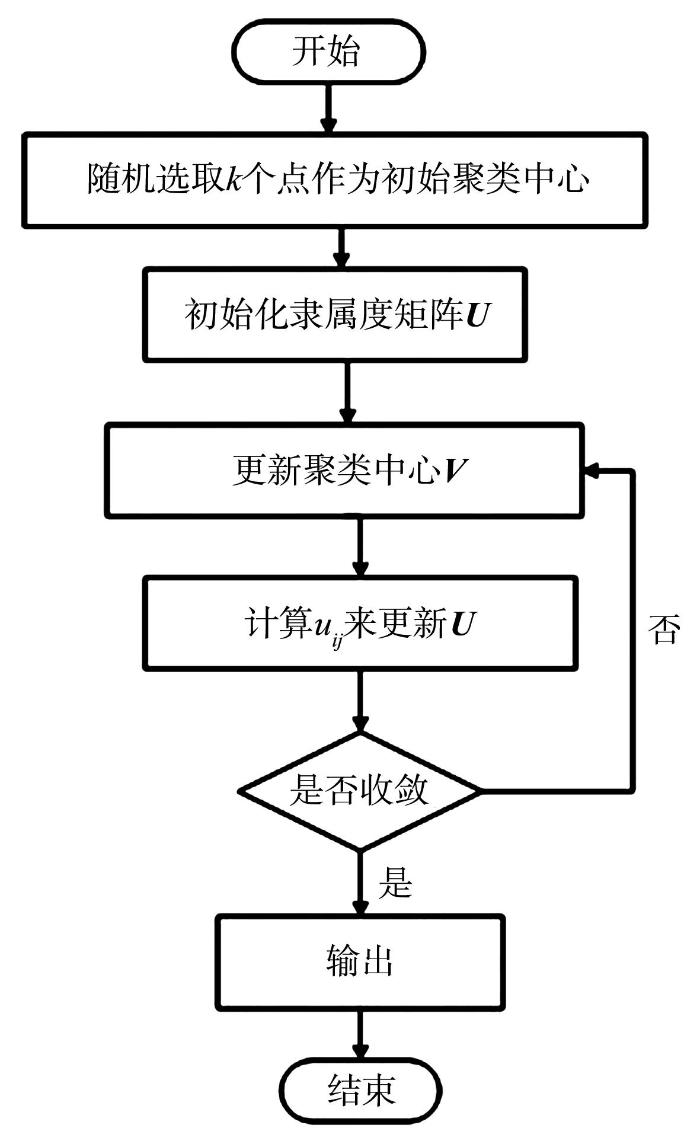
图1
图1
WFCM的算法流程图
Fig.1
Flow chart of WFCM algorithm
1.1.2 扩展软子空间聚类算法
扩展的软子空间聚类算法[25 ] 通过引入新的机制来进一步优化提升传统软子空间聚类或者独立软子空间聚类算法的聚类效果,典型的有ESSC算法,ESSC算法原名Enhanced Soft Subspace Clustering,意为增强的软子空间聚类算法.该算法通过引入类间分离度的思想,其聚类效果经过实验表明明显优于之前只考虑类内相似度的算法.ESSC算法的目标函数为:
J E S S C = ∑ i = 1 C ∑ j = 1 N u i j m ∑ k = 1 D w i j x j k - v j k 2 + φ ∑ i = 1 C ∑ k = 1 D w i k l n w i k - η ∑ i = 1 C ∑ j = 1 N u i j m ∑ k = 1 D w i k v i k - v 0 k 2 (7)
v 0 k = ∑ j = 1 N x j k N (8)
ESSC算法引入了一个参数η U、 V W 的更新如式(9)和式(10)所示:
u i j = d i j - 1 m - 1 ∑ i = 1 C d i j - 1 m - 1 (9)
v i k = ∑ j = 1 N u i j m x i k - η v 0 k ∑ j = 1 N u i j m 1 - η (10)
其中,d i j δ i k 式(11)和式(12)所示:
d i j = ∑ k = 1 D w i k x j k - v i k 2 - η ∑ k = 1 D w i k v j k - v 0 k 2 (11)
δ i k = ∑ j = 1 N u i j m x j k - v i k 2 - η ∑ j = 1 N u i j m v j k - v 0 k 2 (12)
1.2 迁移学习
迁移学习作为机器学习领域的一个新的研究方向,近年来受到越来越多的关注.传统的机器学习方法要求源领域数据和目标领域数据同分布,而迁移学习放松了这一限制,能够把已经获得的知识应用到不同但相似的领域中,解决了目标领域中可用训练样本不足的学习问题.
为了解决目标任务数据仅存在少量或无标注数据问题,通过迁移学习将某个领域或任务已具有的先验知识或模型应用到与其相关的任务或问题中,更为有效地利用有标注数据[26 ] .通常,迁移学习主要针对两个问题展开研究:(1)小数据问题:传统机器学习算法一般假设训练数据与测试数据服从相同的数据分布规律但实际应用中往往无法满足,为了保证训练效果,通常需要重新标注大量数据但有时会带来数据的浪费,而当训练数据过少时,还会出现严重过拟合问题;而迁移学习可从源域的小数据中抽取并迁移知识来完成新的学习任务.(2)个性化问题:当源领域过广又不够具体且研究需要专注于某一个特定目标领域时,可以通过迁移学习将源领域的预训练模型特征迁移到目标领域,从而实现个性化.
迁移学习中,域与任务是两个常见的基本概念.领域D (Domain)定义为由d χ p ( x )
D = χ , p ( x ) , x ∈ χ (13)
迁移学习的任务T 由对应某一领域的类别空间Y f ( x )
T = Y , f ( x ) , y ∈ Y (14)
目标领域D t D t D s
D s = x i , y i i = 1,2 , ⋯ , n s (15)
源领域一般包含大量有标注数据,且源领域可以为一个或多个.由于D t D s D ( s ) T ( s ) D ( T ) T ( T ) D ( s ) T ( s ) f ( x )
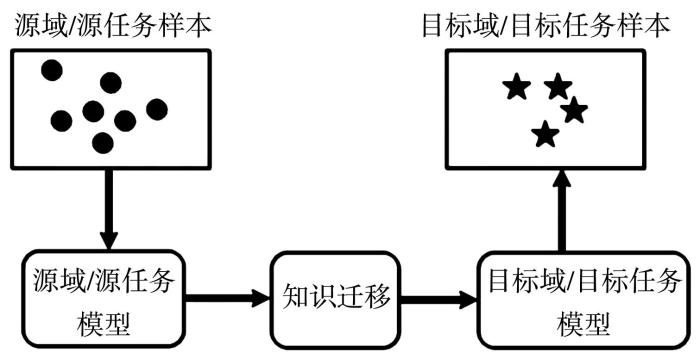
迁移学习的关键在于找到源域与目标域或源任务与目标任务之间的共性,包括样本实例、网络架构或特征表示等方面,从而获得可以对目标域样本进行分类或识别的新模型,达到有效完成目标任务的目标,如图2 所示.
图2
图2
知识迁移
Fig.2
Knowledge Transfer
迁移学习主要研究以下问题:(1)迁移什么和何时迁移,即源领域数据的哪些先验知识训练出新的模型应用到目标域中能够表现出优异的性能,也就是什么条件下可以迁移?(2)在无标注或少量标注数据的目标域中,如何在训练中与大量有标注的源数据结合,获得测试误差最小,即迁移学习算法的研究也就是如何迁移.目前的迁移学习技术涉及多种机器学习技术,如半监督学习、领域适配、鲁棒学习、样本选择偏置、多任务学习等.通过迁移学习的研究,不仅可以更加充分地利用现有已标签数据信息,而且可以利用模型的泛化能力和鲁棒性实现知识在新领域新应用模型中的迁移复用.
2 结合迁移学习的软子空间聚类算法
近年来,聚类分析在统计学、数据库领域和机器学习等领域得到广泛研究.传统聚类分析算法存在诸多限制,而子空间聚类算法能进一步提升聚类分析的性能和效果,其中软子空间聚类算法更是同时具有灵活性和适用性.目前大部分软子空间算法是基于传统k⁃Means/FCM框架进行聚类,而这类算法往往存在如下缺点:(1)无法为每个簇选择各自有用的特征维度,从而导致聚类精度大大降低;(2)算法在运算时需要已有的完整数据作为支撑,所以聚类效果往往不佳[27 ] .
基于以上问题,本文将熵加权软子空间聚类算法(Entropy Weighting k⁃Means Algorithm for Subspace Clustering,EWKM)和迁移学习进行融合,通过引入信息熵的概念和迁移学习的思想,提出一种基于迁移学习的软子空间聚类算法(Soft Subspace Clustering Algorithm Based on Transfer Learning,TSC).
2.1 熵加权的k⁃Means软子空间聚类算法
熵加权的软子空间聚类算法通过引入信息熵的概念,使数据维度的权重由信息熵来计算和确定[28 ] ,因此权重不会使每个簇拥有相同的特征子空间维度.熵加权的软子空间聚类算法和以往的其他子空间聚类算法相比,如模糊加权软子空间聚类算法等,在大数据集或高维度数据集上往往能获得更好的聚类效果.
2.1.1 算法原理
熵加权的k⁃Means软子空间聚类算法的目标函数为:
J E W K M W , Z , Λ = ∑ l = 1 k ∑ j = 1 n ∑ i = 1 m w l j λ l i z l i - x j i 2 + γ ∑ i = 1 m λ l i l g λ l i (16)
∑ l = 1 k w l j = 1,1 ≤ j ≤ n , 1 ≤ l ≤ k , w l j ∈ 0,1 ∑ l = 1 k λ l j = 1,1 ≤ l ≤ k , 1 ≤ j ≤ m , 0 ≤ λ l j ≤ 1 (17)
其中,W k × n Z k n m λ k × m γ 式(16)中矩阵Λ λ γ γ ∑ i = 1 m λ l i l g λ l i
2.1.2 EWKM算法流程输入:聚类中心数k γ . 随机选取k 1 / m .
2.2 TSC算法
虽然EWKM算法能很好地解决数据分散在稀疏的高维子空间的问题,但其和以往的软子空间聚类算法一样,优点是建立在数据样本充足并且没有大量残缺数据信息的条件下.而当样本数据量不足或者存在信息缺失时,软子空间聚类的性能将大幅下降.为此,从熵加权软子空间聚类算法的基础上,尝试引入迁移学习来改善数据样本不足或信息缺失的问题.这种基于迁移学习的熵加权软子空间聚类算法的关键是如何用以往的数据信息作为辅助数据来弥补数据样本不足或信息缺失的缺点,从而得到更好的聚类效果.
TSC算法通过从历史数据中获得的聚类中心z ̂
2.2.1 算法原理
J T S C W , Z , Z ̂ , Λ = J E W K M W , Z , Λ + J T r a n s f e r W , Z , Z ̂ (18)
J E W K M W , Z , Λ = ∑ l = 1 k ∑ j = 1 n ∑ i = 1 m w l j λ l i z l i - x j i 2 + γ ∑ i = 1 m λ l i l g λ l i (19)
J T r a n s f e r W , Z , Z ̂ = β 1 ∑ l = 1 k ∑ j = 1 n ∑ i = 1 m w l j λ l i z ̂ l i - x j i 2 + β 2 ∑ l = 1 k ∑ j = 1 n ∑ i = 1 m w l j λ l i z ̂ l i - z l i 2 ( 20 )
∑ l = 1 k w l j = 1,1 ≤ j ≤ n , 1 ≤ l ≤ k , w l j ∈ 0,1 ∑ l = 1 k λ l j = 1,1 ≤ l ≤ k , 1 ≤ i ≤ m , 0 ≤ λ l i ≤ 1 (21)
其中,n m k W k × n Λ k × m γ Z Z ̂ β 1 β 2
由式(18)可知,算法的目标函数中第一项是熵加权k⁃Means软子空间聚类算法,主要用来处理当前数据集;第二项为迁移学习项,主要作用是利用历史聚类中心来指导当前聚类任务.该算法的主要思想就是利用历史数据化指导目标数据聚类分析来强化熵加权软子空间聚类,弥补数据样本不足或信息残缺的问题.同样,使用拉格朗日乘子法可得到分配矩阵更新公式为:
w l j = 1 i f d l j ≤ d r j w l j = 0 o t h e r w i s e (22)
d l j = ∑ i = 1 m λ l i z l i - x j i 2 + β 1 ∑ i = 1 m λ l i z ̂ l i - x j i 2 + β 2 ∑ i = 1 m λ l i z ̂ l i - z l i 2 (23)
z l i = ∑ j = 1 n w l j x j i + β 2 ∑ j = 1 n w l j z ̂ l i ∑ j = 1 n w l j + β 2 ∑ j = 1 n w l j , 1 ≤ l ≤ k , 1 ≤ i ≤ m (24)
λ l t = e x p - D l t γ ∑ i = 1 M e x p - D l i γ (25)
D l t = ∑ j = 1 n w l j z l t - x j t 2 + β 1 ∑ j = 1 n w l j z ̂ l t - x j t 2 + β 2 ∑ j = 1 n w l j z ̂ l t - z l t 2 (26)
2.2.2 TSC算法流程输入:聚类中心数k γ β 1 β 2 . 随机选取k 1 / m .
3 实验与分析
用MATLAB R2019a进行仿真实验,选取UCI标准数据集中的Iriss、Wine、Vehicle和Australian这四个典型的数据集进行测试,并与以往的典型软子空间聚类分析算法EWKM,ESSC和FSC进行比较.本文设计的实验中,最大迭代次数iterations=100为算法终止条件,设置γ = 50 m = m i n N , D - 1 m i n N , D - 1 - 2 β 1 = 1 β 2 = 1 .
3.1 UCI数据集
为了测试算法的性能和有效性,本文选用三个UCI标准数据集,它们都是在聚类分析算法评测中广泛使用的典型的数据集.数据集的详细信息如表1 所示.
3.2 聚类评价指标
评测聚类分析算法的有效性需要有有效的评价指标,本文采用大多数研究文献中的评价标准,即兰德指数(RI )和标准化互信息(NMI )作为评价指标:
R I = f 00 + f 11 N N - 1 / 2 (27)
N M I = ∑ i = 1 K ∑ j = 1 C n i j l o g 2 N × n i j n i × n j ∑ i = 1 K n i l o g 2 n i N ∑ i = 1 C n j l o g 2 n j N (28)
其中,N 表示整个数据集样本数,C 为簇的数目,K 是数据集实际簇数;f 00 f 11 n i i n j j n i j i ≠ j .
RI 和NMI 的评测值均在0,1 RI 或NMI 值为1则表示聚类结果完全匹配,准确度为100%;RI 或NMI 的值为0则表示聚类结果和实际情况完全不匹配.
3.3 实验结果分析
为了验证本文提出的基于迁移学习的软子空间算法的性能,将各个数据集中前70%的数据作为历史数据信息X h i s t o r y X c u r r e n t . 又将X c u r r e n t X c u r r e n t - a l l X c u r r e n t - l o s t X h i s t o r y 表2 和表3 所示.
然后加入TSC算法,将四种算法在X c u r r e n t - a l l X c u r r e n t - l o s t 表4 和表5 所示.
由表4 和表5 的评测结果可知,在多项不同类别的数据集上,TSC算法所得到的聚类结果要优于其他对比算法,即能够取得相对良好的处理结果;而在对数据进行聚类时,即使面临数据样本或者数据信息缺失,TSC算法也能取得最佳的聚类效果.这是由于该算法引入了迁移学习的思想,从以往的数据中获取历史中心来指导修正当前数据不足时的聚类分析任务;而其他算法由于数据样本太少,信息不足,导致性能下降.设置好的正参数对算法性能有很大提升.
4 结 论
针对传统的软子空间聚类算法在样本数据残缺时聚类准确度不高的问题,提出一种基于迁移学习的软子空间聚类算法,通过引入迁移学习与信息熵,用熵权法确定权重处理高维数据,并将历史数据用于指导和修正当前的聚类分析,有效地提升了算法在数据样本残缺情况下的聚类效果,拓展了软子空间聚类算法的应用范围.通过实验表明,在相同的高维数据集下,与三种典型的聚类算法相比较,本文算法在两种评价指标下均取得了更高的聚类准确度,得到了更好的聚类性能.
参考文献
View Option
[1]
Chan E Y Ching W K Ng M K et al An optimization algorithm for clustering using weighted dissimilarity measures
Pattern Recognition ,2004 ,37 (5 ):943 -952 .
[本文引用: 1]
[2]
Gan G J Wu J H Yang Z J A fuzzy subspace algorithm for clustering high dimensional data
∥International Conference on Advanced Data Mining and Applications . Springer Berlin Heidelberg ,2006 :271 -278 .
[3]
Jing L P Ng M K Huang J Z An entropy weighting k⁃means algorithm for subspace clustering of high⁃dimensional sparse data
IEEE Transactions on Knowledge and Data Engineering ,2007 ,19 (8 ):1026 -1041 .
[本文引用: 1]
[4]
Domeniconi C Gunopulos D Ma S et al Locally adaptive metrics for clustering high dimensional data
Data Mining and Knowledge Discovery ,2007 ,14 (1 ):63 -97 .
[本文引用: 1]
[5]
Deng Z H Choi K S Chung F L et al Enhanced soft subspace clustering integrating within⁃cluster and between⁃cluster information
Pattern Recognition ,2010 ,43 (3 ):767 -781 .
[本文引用: 1]
[6]
Lu Y P Wang S R Li S Z et al Particle swarm optimizer for variable weighting in clustering high⁃dimensional data
Machine Learning ,2011 ,82 (1 ):43 -70 .
[本文引用: 1]
[7]
Wang X B Lei Z Shi H L et al Co⁃referenced subspace clustering
∥2018 IEEE International Conference on Multimedia and Expo (ICME) . San Diego,CA,USA :IEEE ,2018 :1 -6 .
[本文引用: 1]
[8]
Elhamifar E Vidal R Sparse subspace clustering:algorithm,theoryand applications
IEEE Transac⁃tions on Pattern Analysis & Machine Intelligence , 2012 , 35 (11 ):2765 -2781 .
[本文引用: 1]
[9]
Dai W Xue G R Yang Q et al Transferring naive Bayes classifiers for text classification
∥Proceedings of the 22nd AAAI Conference on Artificial Intelligence . Vancouver,Canada :AAAI Press ,2007 :540 -545 .
[10]
Wei F M Zhang J P Chu Y et al FSFP:transfer learning from long texts to the short
Applied Mathematics & Information Sciences ,2014 ,8 (4 ):2033 -2040 .
[本文引用: 1]
[11]
Dai W Y Yang Q Xue G R et al Boosting for transfer learning
∥Proceedings of the 24th international conference on Machine learning . Helsinki Finland :ACM ,2007 :193 -200 .
[本文引用: 1]
[12]
Agrawal R Gehrke J Gunopulos D et al Automatic subspace clustering of high dimensional data for data mining applications
∥ACM SIGMOD Record . Seattle,WA,USA :ACM ,1998 :94 -105 .
[本文引用: 1]
[13]
钱鹏江 ,孙寿伟 ,蒋亦棒 等 知识迁移极大熵聚类算法
控制与决策 ,2015 ,30 (6 ):1001 -1006 .
[本文引用: 1]
Qian P J Sun S W Jiang Y B et al Knowledge Transfer based maximum entropy clustering
Control and Decision ,2015 ,30 (6 ):1001 -1006 .
[本文引用: 1]
[14]
Yu J Shi H B Huang H K et al Counterexamples to convergence theorem of maximum⁃entropy clustering algorithm . Science in China Series F :Information Sciences ,2003 ,46 (5 ):321 -326 .
[15]
王熙照 ,安素芳 基于极大模糊熵原理的模糊产生式规则中的权重获取方法研究
计算机研究与发展 ,2006 ,43 (4 ):673 -678 .
Wang X Z An S F Research on learning weights of fuzzy production rules based on maximum fuzzy entropy
Journal of Computer Research and Development ,2006 ,43 (4 ):673 -678 .
[16]
邓赵红 ,王士同 ,吴锡生 等 鲁棒的极大熵聚类算法RMEC及其例外点标识
中国工程科学 ,2004 ,6 (9 ):38 -45 .
[本文引用: 1]
Deng Z H Wang S T Wu X S et al Robust maximum entropy clustering algorithm RMEC and its outlier labeling
Engineering Science ,2004 ,6 (9 ):38 -45 .
[本文引用: 1]
[17]
Jiang W H Chung F L Transfer spectral clustering
∥Proceedings of the 2012 European conference on Machine Learning and Knowledge Discovery in Databases . Springer Berlin Heidelberg ,2012 :790 -803 .
[本文引用: 1]
[18]
Jain A K Murty M N Flynn P J Data Clustering:a review
ACM Computing Surveys (CSUR) ,1999 ,31 (3 ):265 -320 .
[本文引用: 1]
[19]
Guo G D Chen S Chen L F Soft subspace clustering with an improved feature weight self⁃adjustment mechanism
International Journal of Machine Learning & Cybernetics ,2012 ,3 (1 ):39 -49 .
[本文引用: 1]
[20]
Xu Y M Wang C D Lai J H Weighted multi⁃view clustering with feature selection
Pattern Recognition ,2016 ,53 :25 -35 .
[本文引用: 1]
[21]
Zhao X R Evans N Dugelay J L A subspace co⁃training framework for multi⁃view clustering
Pattern Recognition Letters ,2014 ,41 :73 -82 .
[本文引用: 1]
[22]
Ji J C Bai T Zhou C G et al An improved k⁃prototypes clustering algorithm for mixed numeric and categorical data
Neurocomputing ,2013 ,120 :590 -596 .
[本文引用: 1]
[23]
黄王非 ,黎飞 ,青山 基于子空间维度加权的密度聚类算法
计算机工程 2010 ,36 (9 ):65 -67 . (Huang W F,Li F,Qing S
Density clustering algorithm based on subspace dimensional weighting. Computer Engineering ,2010 ,36 (9 ):65 -67 .)
[本文引用: 1]
[24]
Donoho D L High⁃dimensional data analysis:The curses and blessings of dimensionality
American Mathematical Society Math Challenges Lecture ,2000 ,1 :32 .
[本文引用: 1]
[25]
许亚骏 子空间聚类算法研究及应用 . 硕士学位论文. 无锡 :江南大学 ,2016 .
[本文引用: 1]
Xu Y J Research on subspace clustering algorithms and its applications . Master Dissertation. Wuxi :Jiangnan University ,2016 .
[本文引用: 1]
[26]
Weiss K Khoshgoftaar T M Wang D D A survey of transfer learning
Journal of Big Data ,2016 ,3 :9 .
[本文引用: 1]
[27]
Günnemann S Boden B Seidl T DB⁃CSC: a density⁃based approach for subspace clustering in graphs with feature vectors
∥Joint European Conference on Machine Learning and Knowledge Discovery in Databases . Springer Berlin Heidelberg ,2011 :565 -580 .
[本文引用: 1]
[28]
Wan S J Wong S K M Prusinkiewicz P An algorithm for multidimensional data clustering
ACM Transactions on Mathematical Software ,14 (2 ):153 -162 .
[本文引用: 1]
An optimization algorithm for clustering using weighted dissimilarity measures
1
2004
... 大数据时代无时无刻地进行着海量的数据和信息交换,如何从海量的高维数据中挖掘提取有价值的信息是近年讨论的热点问题.数据聚类分析是数据挖掘的有效工具之一,是数据挖掘领域研究的重点和热点[1 -3 ] .聚类分析是一种通过算法自动分析数据对象之间的相似性或者相异性、自动地将数据集中未标记的数据分到不同的簇之中的方法.每个簇中的数据在某个标准下具有一定的相似性,而簇间的数据在这一标准下的相似性则很低[4 ] .这种方法的用途是对原始的数据集合进行处理,得到一种聚类处理结果,再通过对聚类结果的分析,提取人们需要的有价值的信息.目前,聚类分析已被广泛应用到各个领域:在商业领域,聚类分析可以被用来发现不同的客户群,研究不同客户的消费行为,寻找潜在市场来制定不同的销售方案[5 -6 ] ;在生物医学领域,聚类分析能够对基因进行分类,从而研究不同的种群结构,分析与各种疾病之间的潜在联系[7 ] ;在电子商务类行业,聚类分析能从网站建设的数据中挖掘分析出各个客户的相似习惯,达到优化服务的目的. ...
A fuzzy subspace algorithm for clustering high dimensional data
0
2006
An entropy weighting k?means algorithm for subspace clustering of high?dimensional sparse data
1
2007
... 大数据时代无时无刻地进行着海量的数据和信息交换,如何从海量的高维数据中挖掘提取有价值的信息是近年讨论的热点问题.数据聚类分析是数据挖掘的有效工具之一,是数据挖掘领域研究的重点和热点[1 -3 ] .聚类分析是一种通过算法自动分析数据对象之间的相似性或者相异性、自动地将数据集中未标记的数据分到不同的簇之中的方法.每个簇中的数据在某个标准下具有一定的相似性,而簇间的数据在这一标准下的相似性则很低[4 ] .这种方法的用途是对原始的数据集合进行处理,得到一种聚类处理结果,再通过对聚类结果的分析,提取人们需要的有价值的信息.目前,聚类分析已被广泛应用到各个领域:在商业领域,聚类分析可以被用来发现不同的客户群,研究不同客户的消费行为,寻找潜在市场来制定不同的销售方案[5 -6 ] ;在生物医学领域,聚类分析能够对基因进行分类,从而研究不同的种群结构,分析与各种疾病之间的潜在联系[7 ] ;在电子商务类行业,聚类分析能从网站建设的数据中挖掘分析出各个客户的相似习惯,达到优化服务的目的. ...
Locally adaptive metrics for clustering high dimensional data
1
2007
... 大数据时代无时无刻地进行着海量的数据和信息交换,如何从海量的高维数据中挖掘提取有价值的信息是近年讨论的热点问题.数据聚类分析是数据挖掘的有效工具之一,是数据挖掘领域研究的重点和热点[1 -3 ] .聚类分析是一种通过算法自动分析数据对象之间的相似性或者相异性、自动地将数据集中未标记的数据分到不同的簇之中的方法.每个簇中的数据在某个标准下具有一定的相似性,而簇间的数据在这一标准下的相似性则很低[4 ] .这种方法的用途是对原始的数据集合进行处理,得到一种聚类处理结果,再通过对聚类结果的分析,提取人们需要的有价值的信息.目前,聚类分析已被广泛应用到各个领域:在商业领域,聚类分析可以被用来发现不同的客户群,研究不同客户的消费行为,寻找潜在市场来制定不同的销售方案[5 -6 ] ;在生物医学领域,聚类分析能够对基因进行分类,从而研究不同的种群结构,分析与各种疾病之间的潜在联系[7 ] ;在电子商务类行业,聚类分析能从网站建设的数据中挖掘分析出各个客户的相似习惯,达到优化服务的目的. ...
Enhanced soft subspace clustering integrating within?cluster and between?cluster information
1
2010
... 大数据时代无时无刻地进行着海量的数据和信息交换,如何从海量的高维数据中挖掘提取有价值的信息是近年讨论的热点问题.数据聚类分析是数据挖掘的有效工具之一,是数据挖掘领域研究的重点和热点[1 -3 ] .聚类分析是一种通过算法自动分析数据对象之间的相似性或者相异性、自动地将数据集中未标记的数据分到不同的簇之中的方法.每个簇中的数据在某个标准下具有一定的相似性,而簇间的数据在这一标准下的相似性则很低[4 ] .这种方法的用途是对原始的数据集合进行处理,得到一种聚类处理结果,再通过对聚类结果的分析,提取人们需要的有价值的信息.目前,聚类分析已被广泛应用到各个领域:在商业领域,聚类分析可以被用来发现不同的客户群,研究不同客户的消费行为,寻找潜在市场来制定不同的销售方案[5 -6 ] ;在生物医学领域,聚类分析能够对基因进行分类,从而研究不同的种群结构,分析与各种疾病之间的潜在联系[7 ] ;在电子商务类行业,聚类分析能从网站建设的数据中挖掘分析出各个客户的相似习惯,达到优化服务的目的. ...
Particle swarm optimizer for variable weighting in clustering high?dimensional data
1
2011
... 大数据时代无时无刻地进行着海量的数据和信息交换,如何从海量的高维数据中挖掘提取有价值的信息是近年讨论的热点问题.数据聚类分析是数据挖掘的有效工具之一,是数据挖掘领域研究的重点和热点[1 -3 ] .聚类分析是一种通过算法自动分析数据对象之间的相似性或者相异性、自动地将数据集中未标记的数据分到不同的簇之中的方法.每个簇中的数据在某个标准下具有一定的相似性,而簇间的数据在这一标准下的相似性则很低[4 ] .这种方法的用途是对原始的数据集合进行处理,得到一种聚类处理结果,再通过对聚类结果的分析,提取人们需要的有价值的信息.目前,聚类分析已被广泛应用到各个领域:在商业领域,聚类分析可以被用来发现不同的客户群,研究不同客户的消费行为,寻找潜在市场来制定不同的销售方案[5 -6 ] ;在生物医学领域,聚类分析能够对基因进行分类,从而研究不同的种群结构,分析与各种疾病之间的潜在联系[7 ] ;在电子商务类行业,聚类分析能从网站建设的数据中挖掘分析出各个客户的相似习惯,达到优化服务的目的. ...
Co?referenced subspace clustering
1
2018
... 大数据时代无时无刻地进行着海量的数据和信息交换,如何从海量的高维数据中挖掘提取有价值的信息是近年讨论的热点问题.数据聚类分析是数据挖掘的有效工具之一,是数据挖掘领域研究的重点和热点[1 -3 ] .聚类分析是一种通过算法自动分析数据对象之间的相似性或者相异性、自动地将数据集中未标记的数据分到不同的簇之中的方法.每个簇中的数据在某个标准下具有一定的相似性,而簇间的数据在这一标准下的相似性则很低[4 ] .这种方法的用途是对原始的数据集合进行处理,得到一种聚类处理结果,再通过对聚类结果的分析,提取人们需要的有价值的信息.目前,聚类分析已被广泛应用到各个领域:在商业领域,聚类分析可以被用来发现不同的客户群,研究不同客户的消费行为,寻找潜在市场来制定不同的销售方案[5 -6 ] ;在生物医学领域,聚类分析能够对基因进行分类,从而研究不同的种群结构,分析与各种疾病之间的潜在联系[7 ] ;在电子商务类行业,聚类分析能从网站建设的数据中挖掘分析出各个客户的相似习惯,达到优化服务的目的. ...
Sparse subspace clustering:algorithm,theoryand applications
1
2012
... 近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性. ...
Transferring naive Bayes classifiers for text classification
0
2007
FSFP:transfer learning from long texts to the short
1
2014
... 近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性. ...
Boosting for transfer learning
1
2007
... 近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性. ...
Automatic subspace clustering of high dimensional data for data mining applications
1
1998
... 近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性. ...
知识迁移极大熵聚类算法
1
2015
... 近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性. ...
知识迁移极大熵聚类算法
1
2015
... 近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性. ...
基于极大模糊熵原理的模糊产生式规则中的权重获取方法研究
0
2006
基于极大模糊熵原理的模糊产生式规则中的权重获取方法研究
0
2006
鲁棒的极大熵聚类算法RMEC及其例外点标识
1
2004
... 近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性. ...
鲁棒的极大熵聚类算法RMEC及其例外点标识
1
2004
... 近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性. ...
Transfer spectral clustering
1
2012
... 近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性. ...
Data Clustering:a review
1
1999
... 近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性. ...
Soft subspace clustering with an improved feature weight self?adjustment mechanism
1
2012
... 近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性. ...
Weighted multi?view clustering with feature selection
1
2016
... 近年来,在各个应用领域的实际数据都呈现维度剧增的趋势,数据呈现高维化发展的态势并因此爆发了“维度灾难”[8 -10 ] .高维数据比低维有更多的难以处理的特性,比如在高维数据中,判断数据样本之间的相似性非常困难,因为数据样本之间的距离几乎一致,这是数据在高维空间的分布越来越稀疏导致的;其次,高维数据有大量的子属性,这些子属性中存在一些与特定簇无关或者冗余的属性,导致进行聚类时不同的子空间可能发现不同的簇的问题[11 ] ;并且,随着维数的不断增加,每个维度的取值将会呈现指数级别的增长,很难完全枚举所有的子空间.因此在高维数据领域,传统的聚类方法的表现并不理想.Agrawal et al[12 ] 在SIGMOD会议上提出子空间聚类的概念.子空间聚类是对传统聚类的扩展,能从高维数据集中发现隐藏在不同低维子空间中的簇类.子空间聚类将原始数据集划分成不同的簇并同时搜索各个簇的子空间,对各个簇中关联的各个属性赋予不同的权重,从而研究属性与簇的关联程度.子空间聚类算法又分硬子空间(Hard subspace)和软子空间(Soft subspace)[13 -16 ] .硬子空间是采用自底向上或者自顶向下的搜索策略,按照一定的标准在源数据集的所有特征集中选取精确的特征子集组成子空间并进行聚类.对高维数据的聚类算法就是从硬子空间开始研究的,并且已经取得了很大成果,所以硬子空间聚类已经相对成熟,如CLIQUE算法[17 ] 、PROCLUS算法[18 ] 等.软子空间聚类则是在硬子空间聚类之后慢慢发展起来的,因为其在面对高维数据时有更好的适应性,因而引起国内外学者的广泛关注[19 -20 ] .软子空间算法为簇类各个特征赋予不同的权值,从而获知簇类与全特征空间中哪些特征具有相关性,并且反应各个特征与簇的相关程度与差异,为每个簇寻找一个模糊子空间.与硬子空间相比,面对高维数据时软子空间有更好的适应性与灵活性. ...
A subspace co?training framework for multi?view clustering
1
2014
... 迁移学习是一种在已有的环境中认知和学习到的信息被应用到新的任务和环境下的能力.迁移学习作为一种能利用其他相似领域上学到的知识来辅助当前任务的一种方法,被广泛运用于各个邻域中[21 ] .根据源任务和目标任务之间的差异,可将迁移学习大致分为归纳式迁移学习、直推式迁移学习和无监督学习[22 ] .在聚类分析算法的过程中,需要大量已知数据支持,而实际情况下,很多时候会出现已知数据样本不足、数据残缺或者信息不准确的情况[23 ] .因此本文引入熵的概念,根据信息熵来确定权重,并将迁移学习与子空间聚类算法结合,利用迁移学习改进优化软子空间聚类算法的聚类性能. ...
An improved k?prototypes clustering algorithm for mixed numeric and categorical data
1
2013
... 迁移学习是一种在已有的环境中认知和学习到的信息被应用到新的任务和环境下的能力.迁移学习作为一种能利用其他相似领域上学到的知识来辅助当前任务的一种方法,被广泛运用于各个邻域中[21 ] .根据源任务和目标任务之间的差异,可将迁移学习大致分为归纳式迁移学习、直推式迁移学习和无监督学习[22 ] .在聚类分析算法的过程中,需要大量已知数据支持,而实际情况下,很多时候会出现已知数据样本不足、数据残缺或者信息不准确的情况[23 ] .因此本文引入熵的概念,根据信息熵来确定权重,并将迁移学习与子空间聚类算法结合,利用迁移学习改进优化软子空间聚类算法的聚类性能. ...
)
1
2010
... 迁移学习是一种在已有的环境中认知和学习到的信息被应用到新的任务和环境下的能力.迁移学习作为一种能利用其他相似领域上学到的知识来辅助当前任务的一种方法,被广泛运用于各个邻域中[21 ] .根据源任务和目标任务之间的差异,可将迁移学习大致分为归纳式迁移学习、直推式迁移学习和无监督学习[22 ] .在聚类分析算法的过程中,需要大量已知数据支持,而实际情况下,很多时候会出现已知数据样本不足、数据残缺或者信息不准确的情况[23 ] .因此本文引入熵的概念,根据信息熵来确定权重,并将迁移学习与子空间聚类算法结合,利用迁移学习改进优化软子空间聚类算法的聚类性能. ...
High?dimensional data analysis:The curses and blessings of dimensionality
1
2000
... WFCM算法的全称为样本加权模糊C均值算法,它是对FCM((Fuzzy C⁃means))算法的改进[24 ] .FCM算法基于传统欧式距离,每个数据样本对聚类的贡献几乎相同,然而实际上在高维领域,每个数据样本都会对聚类产生不同的程度的影响.用传统的FCM算法无法体现噪声点或者偏远数据样本集体对聚类的影响,所以WFCM引入一种点密度函数来作为样本点的加权系数计算方法,对于每个样本点,点密度函数计算方式为: ...
1
2016
... 扩展的软子空间聚类算法[25 ] 通过引入新的机制来进一步优化提升传统软子空间聚类或者独立软子空间聚类算法的聚类效果,典型的有ESSC算法,ESSC算法原名Enhanced Soft Subspace Clustering,意为增强的软子空间聚类算法.该算法通过引入类间分离度的思想,其聚类效果经过实验表明明显优于之前只考虑类内相似度的算法.ESSC算法的目标函数为: ...
1
2016
... 扩展的软子空间聚类算法[25 ] 通过引入新的机制来进一步优化提升传统软子空间聚类或者独立软子空间聚类算法的聚类效果,典型的有ESSC算法,ESSC算法原名Enhanced Soft Subspace Clustering,意为增强的软子空间聚类算法.该算法通过引入类间分离度的思想,其聚类效果经过实验表明明显优于之前只考虑类内相似度的算法.ESSC算法的目标函数为: ...
A survey of transfer learning
1
2016
... 为了解决目标任务数据仅存在少量或无标注数据问题,通过迁移学习将某个领域或任务已具有的先验知识或模型应用到与其相关的任务或问题中,更为有效地利用有标注数据[26 ] .通常,迁移学习主要针对两个问题展开研究:(1)小数据问题:传统机器学习算法一般假设训练数据与测试数据服从相同的数据分布规律但实际应用中往往无法满足,为了保证训练效果,通常需要重新标注大量数据但有时会带来数据的浪费,而当训练数据过少时,还会出现严重过拟合问题;而迁移学习可从源域的小数据中抽取并迁移知识来完成新的学习任务.(2)个性化问题:当源领域过广又不够具体且研究需要专注于某一个特定目标领域时,可以通过迁移学习将源领域的预训练模型特征迁移到目标领域,从而实现个性化. ...
DB?CSC: a density?based approach for subspace clustering in graphs with feature vectors
1
2011
... 近年来,聚类分析在统计学、数据库领域和机器学习等领域得到广泛研究.传统聚类分析算法存在诸多限制,而子空间聚类算法能进一步提升聚类分析的性能和效果,其中软子空间聚类算法更是同时具有灵活性和适用性.目前大部分软子空间算法是基于传统k⁃Means/FCM框架进行聚类,而这类算法往往存在如下缺点:(1)无法为每个簇选择各自有用的特征维度,从而导致聚类精度大大降低;(2)算法在运算时需要已有的完整数据作为支撑,所以聚类效果往往不佳[27 ] . ...
An algorithm for multidimensional data clustering
1
... 熵加权的软子空间聚类算法通过引入信息熵的概念,使数据维度的权重由信息熵来计算和确定[28 ] ,因此权重不会使每个簇拥有相同的特征子空间维度.熵加权的软子空间聚类算法和以往的其他子空间聚类算法相比,如模糊加权软子空间聚类算法等,在大数据集或高维度数据集上往往能获得更好的聚类效果. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}