

为了得到更合理、更符合用户需求的约简,一些以用户偏好为出发点,结合属性的外部信息,考虑属性代价的算法相继被提出[12-15],还有一些研究结合用户兴趣以及属性的语义信息,通过属性序的方式对用户偏好进行描述.Wang and Wang[16]首次提出属性序的概念并设计了一种基于Skowron分辨矩阵的属性约简方法,解决了Pawlak约简算法完备性和给定属性序下约简的唯一性问题.Zhao and Wang[17]利用属性序关系代表用户偏好,设计了一种包括属性顺序在前的属性约简方法以满足用户需求,同时提出三种属性序关系:全序、组序以及平衡序.Yao et al[18-19]提出一种考虑用户对属性偏好的机器学习泛化模型,该模型结合了内部信息和外部信息,可以构建用户优选的属性集.Han and Wang[20]给出了相邻的属性对基本定理,通过第二属性证明了属性对的决策定理.官礼和等[21]提出一种属性序下分层递阶的决策规则挖掘算法,能够获取较高识别率的决策规则.韩素青和阴桂梅[22]将约简问题转化为集合覆盖的问题,提出一种面向用户需求的属性约简算法.胡峰和王国胤[23]结合分治法的思想,提出一种快速属性约简算法,能够在海量数据中快速得到约简.
现有基于属性序的属性约简算法都需要给出所有属性的全序关系.然而在现实生活中,治疗某一种病有不同的治疗方式,如外科治疗、化学治疗、放射治疗和中医治疗等等,不同治疗方式还包含更具体的不同药物方法,所以不同用户对不同方式的偏好形成了属性组序的关系,而不必考虑每个属性的偏好关系.目前对于属性组序关系下的约简方法研究较少,Zhao and Wang[17]提出一个简单的方法,利用字母序对组序中的属性排序使其变为全序关系.该方法简单但合理性不足,没有考虑现实生活中用户的偏好问题以及获取属性所需的代价或费用等问题.为此,本文优先考虑属性组序的关系,其次在每个分组中综合考虑属性重要度和代价的影响,给出了属性组序下基于代价敏感的约简方法,并通过实例和仿真实验进行了分析和验证.
1 基础理论
粗糙集理论是属性约简的核心知识,本节主要回顾粗糙集理论和属性序的基本概念.
(1)
(2)
其中,条件(1)表明属性子集
输入:决策表
输出:约简
①令
②
③
④重复以上步骤,直到
⑤返回约简
其中,
2 属性组序下基于代价敏感的约简方法
在一些实际问题中,用户可能无法给出所有属性的全序,但可以对属性进行分组;组内的属性间没有序关系,但属性组间有偏序关系,称为属性组序.属性组序的描述方式较好地满足了人们对属性的偏好,以属性组序形式存在的偏好关系也非常常见,又或者部分属性间本身没有可比性.然而,现有的研究还没有针对属性组序的属性约简方法,本节针对属性组序的情形,考虑现实中的代价问题,设计了一种基于代价敏感的约简算法.
该属性组序描述了用户对属性的偏好.组间
在信息系统中,对于一个特定的问题,并不是所有的条件属性都是必要的,或者说存在冗余属性.考虑属性客观代价可以作为用户偏好的一个指标,本文结合属性组序的特点,定义了一种度量约简子集所处平均位置的指标,以此来描述该子集是否处于属性组序中更为靠前的位置,称为子集平均位置(
例如有
属性组序描述的是用户的偏好,其作为描述属性的外部信息,可以直观地发现各组间的优劣关系.为了获得偏好程度更高的约简子集,本文采取一种按组删除再添加、最后对约简子集进行验证的方法,其主要分为三步:第一,结合其分组的特点,依次从偏好程度低的分组开始删除,尽可能保留偏好程度更高,分组更为靠前的属性;第二,当每次删除分组正域发生改变时,从当前分组中选择属性,直到正域与原始条件属性集的正域相同;第三,对约简子集中每个属性进行判断是否为必要属性.其流程图如图1所示.
图1

第二步中,如何从局部组中选择合适的属性作为约简结果至关重要.如果按照属性组序依次删除分组是遵循属性语义上的偏好,则在局部分组中选择通过统计和客观评价信息,也就是属性重要度的方式来优先选择属性.首先选择组中核属性,其次利用加权的方式,选择重要程度最大的属性加入约简子集中.属性重要度作为信息表的统计信息,代价作为现实生活中存在的客观评判标准,都可以对各分组中的属性进行客观的评价.Zhang and Shen[25]综合考虑用户需求,设计了一种属性重要度和代价加权的约简算法(Attribute Reduction algorithm with Weight,ARWW),其代价重要度由单个属性代价占据总代价的比例决定,而对于分组来讲,同组内属性代价的重要度也会随着候选属性子集增加或减少而动态变化.下面介绍属性重要度的相关定义.
其中,
属性
属性外部重要度表明属性
其中,
代价重要度描述的是考虑获取属性所需代价的客观因素对属性产生的影响.对用户而言,代价越大其重要程度越低,因为人们通常会倾向代价更低的约简子集.
结合以上属性重要度的定义,定义加权重要度为:
当
输入:决策表
输出:约简后属性集
(1)令
(2)依照组序
①对于任意属性
②当
③对于任意属性
(3)对于任意属性
(4)返回约简集
算法复杂度分析:设
下面通过一个实例来说明算法的执行过程.
如表1所示是一个决策表,该决策表包含五个条件属性
(1)初始化
(2)从
(3)从
同理,当
属性组序是属性完全有序和完全无序的中间状态.当属性集完全无序时,即分组数为1,此时本文提出的算法退化为ARWW算法,[25],该算法利用属性重要度和代价加权的方式在全局寻找属性,得到不同权重时的约简子集.当属性集处于完全有序时,即分组数等于属性个数,此时算法仅根据用户偏好顺序依次删除属性,得到偏好程度较高约简集合,因为每个分组中仅存在一个属性,其局部选择属性的方法将失效.在实验分析中也验证了属性集随着分组数的增加,其参数
3 实验分析
为了验证本文提出算法的有效性,本文选取了五组UCI数据集进行实验,分别用
表2 Lymphography的分组方式
Table 2
| 属性组序 | |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 |
通常情况下,属性的重要性与获取属性所需的成本呈正相关,因此本文采用属性重要度算法对属性进行代价的设置.例如在Lymphography数据集中,根据属性重要度算法得的到约简为
表3至表7是ARCSGO算法在属性重要度和代价加权(
表3 Lymphography数据集在10种不同分组方式下的约简结果
Table 3
| 1 | 170 | 2.44 | 180 | 2.5 | ||
| 2 | 220 | 2.77 | 220 | 2.77 | ||
| 3 | 180 | 2.5 | 180 | 2.5 | ||
| 4 | 220 | 2.28 | 270 | 2.14 | ||
| 5 | 220 | 2.37 | 270 | 2.42 | ||
| 6 | 240 | 2.25 | 260 | 2.42 | ||
| 7 | 230 | 2.33 | 230 | 2.33 | ||
| 8 | 230 | 2.2 | 250 | 2.37 | ||
| 9 | 190 | 2.27 | 190 | 2.5 | ||
| 10 | 170 | 2.22 | 180 | 2.25 | ||
表4 Lung⁃Cancer数据集在10种不同分组方式下的约简结果
Table 4
| 1 | 80 | 3 | 100 | 3 | ||
| 2 | 100 | 3 | 190 | 3 | ||
| 3 | 70 | 3 | 70 | 3 | ||
| 4 | 60 | 3 | 70 | 3 | ||
| 5 | 60 | 3 | 90 | 3 | ||
| 6 | 50 | 3 | 80 | 3 | ||
| 7 | 90 | 3 | 130 | 3 | ||
| 8 | 70 | 3 | 90 | 3 | ||
| 9 | 90 | 3 | 150 | 3 | ||
| 10 | 70 | 3 | 120 | 3 | ||
表5 Dermatology数据集在10种不同分组方式下的约简结果
Table 5
| 1 | 150 | 2.9 | 210 | 2.9 | ||
| 2 | 110 | 2.11 | 150 | 2.7 | ||
| 3 | 170 | 2.9 | 220 | 2.9 | ||
| 4 | 150 | 2.87 | 210 | 2.87 | ||
| 5 | 130 | 2.8 | 200 | 2.85 | ||
| 6 | 130 | 3 | 130 | 3 | ||
| 7 | 120 | 2.62 | 130 | 2.5 | ||
| 8 | 120 | 2.5 | 200 | 2.71 | ||
| 9 | 140 | 2.57 | 160 | 2.71 | ||
| 10 | 120 | 2.7 | 140 | 2.75 | ||
表6 BCW数据集在10种不同分组方式下的约简结果
Table 6
| 1 | 110 | 2.25 | 110 | 2.6 | ||
| 2 | 110 | 2.5 | 120 | 2.5 | ||
| 3 | 110 | 2 | 120 | 2.4 | ||
| 4 | 110 | 2.2 | 110 | 2.2 | ||
| 5 | 110 | 2.2 | 130 | 2 | ||
| 6 | 110 | 2.2 | 110 | 2.25 | ||
| 7 | 110 | 2.2 | 110 | 2.25 | ||
| 8 | 90 | 2.5 | 90 | 2.5 | ||
| 9 | 90 | 2.25 | 110 | 2.25 | ||
| 10 | 90 | 2 | 120 | 2.25 | ||
表7 Connect⁃4数据集在10种不同分组方式下的约简结果
Table 7
| 1 | 670 | 1.76 | 760 | 2.07 | ||
| 2 | 720 | 1.94 | 850 | 1.92 | ||
| 3 | 700 | 2 | 700 | 2 | ||
| 4 | 720 | 2.05 | 940 | 2.07 | ||
| 5 | 720 | 2.17 | 850 | 2.28 | ||
| 6 | 870 | 2.05 | 960 | 2.07 | ||
| 7 | 700 | 2.07 | 810 | 2.14 | ||
| 8 | 720 | 2.05 | 810 | 2.21 | ||
| 9 | 700 | 2.2 | 810 | 2.21 | ||
| 10 | 720 | 1.94 | 840 | 2.12 | ||
图2至图6分别表示在五个数据集中10种不同分组方式下,
图2

图3
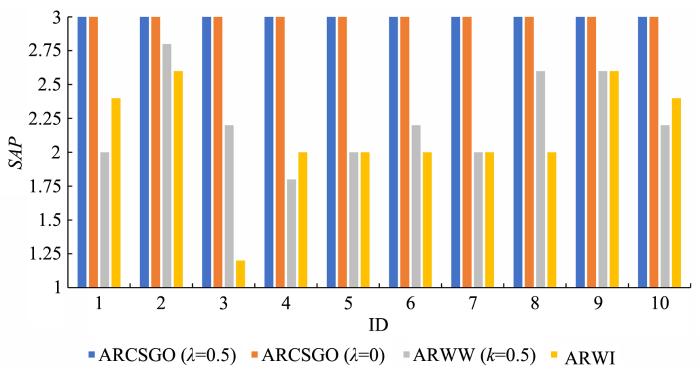
图4
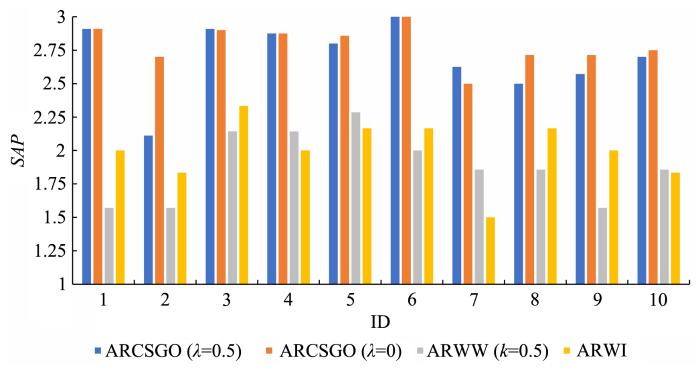
图5
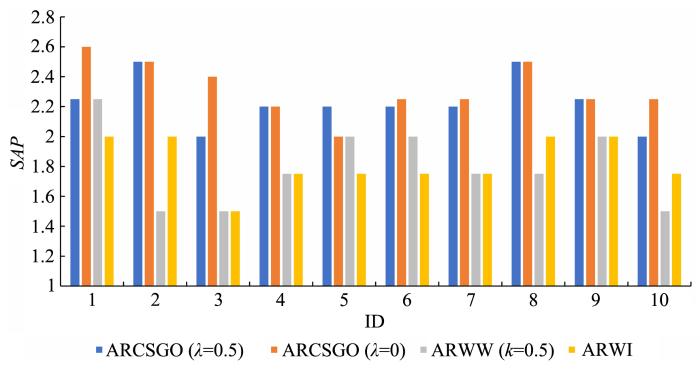
图6
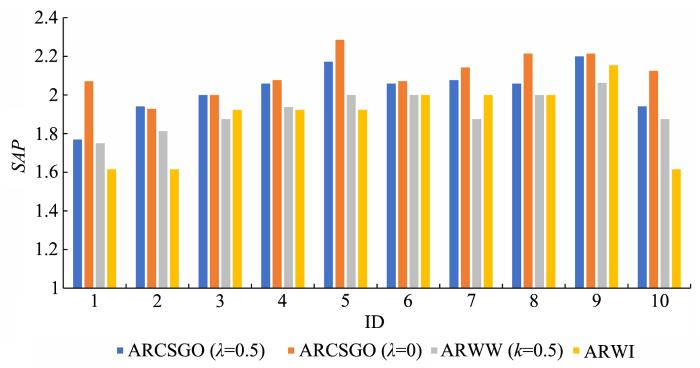
图7
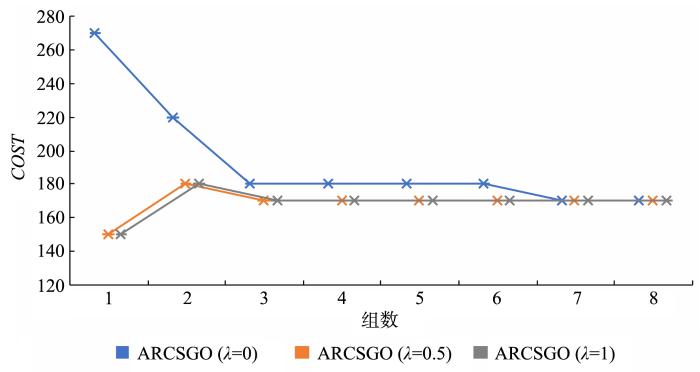
图7
Lymphography数据集在不同组数下的代价
Fig.7
Cost under different groups of Lymphography dataset
图8
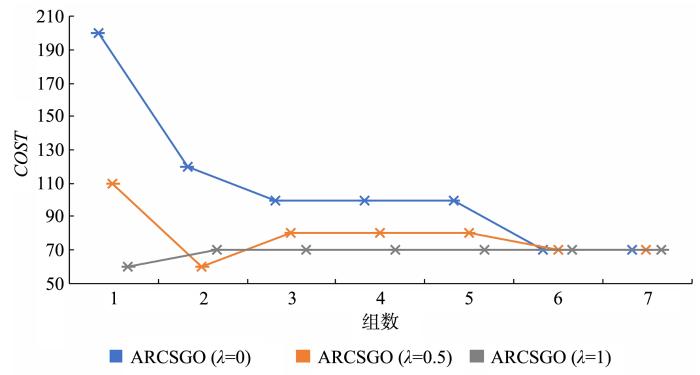
图8
Lung⁃Cancer数据集在不同组数下的代价
Fig.8
Cost under different groups of Lung⁃Cancer dataset
图9
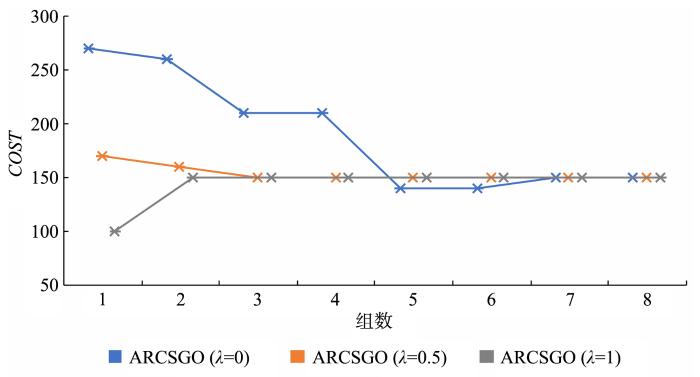
图9
Dermatology数据集在不同组数下的代价
Fig.9
Cost under different groups of Dermatology dataset
图10
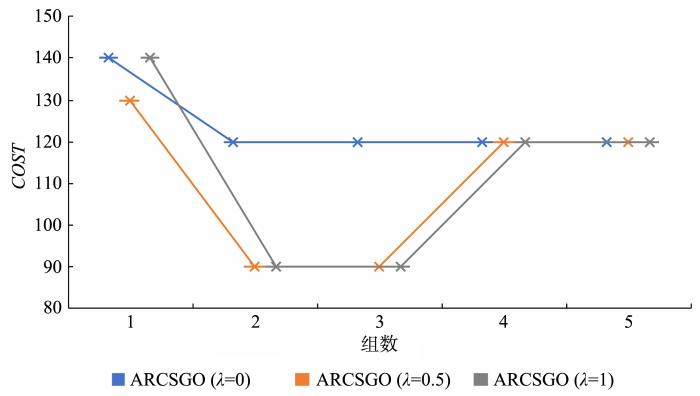
图11
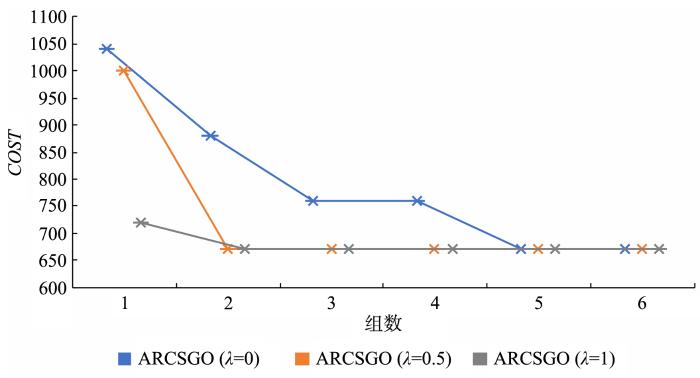
图11
Connect⁃4数据集在不同组数下的代价
Fig.11
Cost under different groups of Connect⁃4 dataset
4 结 论
考虑用户偏好及现实生活中的代价敏感问题,本文提出一种属性组序下基于代价敏感的约简算法.该算法结合分组的思想,可对整组属性进行删除,然后再对组内属性进行添加.通过局部加权的方式添加属性和利用属性重要度选择属性相比,能够获取代价更低的约简集合.本文定义平均子集位置来描述子集在该分组中所处位置的高低,代表用户对子集的偏好程度,所设计的算法能获取较高的
参考文献
Rough sets
粗糙集理论与应用研究综述
A survey on rough set theory and applications
决策粗糙集理论研究现状与展望
Current research and future perspectives on decision:theoretic rough sets
变精度粗糙集的属性核和最小属性约简算法
The core of attributes and minimal attributes reduction in variable precision rough set
Generalization of rough sets using modal logics
Decision⁃theoretic rough set models
∥
基于粗糙集的属性约简方法研究综述
Overview of attribute reduction based on rough set
Positive approximation:an accelerator for attribute reduction in rough set theory
A new algorithm for computing reducts based on the binary discernibility matrix
Maximum decision entropy⁃based attribute reduction in decision⁃theoretic rough set model
Attribute reduction via local conditional entropy
Test⁃cost⁃sensitive attribute reduction
Cost⁃sensitive approximate attribute reduction with three⁃way decisions
Cost⁃sensitive three⁃way class⁃specific attribute reduction
Minimum cost attribute reduction in decision⁃theoretic rough set models
Reduction algorithms based on discernibility matrix:the ordered attributes method
A reduction algorithm meeting users' requirements
A model of machine learning based on user preference of attributes
∥
A model of user⁃oriented reduct construction for machine learning
Reduct and attribute order
一种基于属性序的决策规则挖掘算法
A decision rules mining algorithm based on attribute order
一种面向用户需求的属性约简算法
An user⁃oriented attribute reduct construction algorithm
属性序下的快速约简算法
Quick reduction algorithm based on attribute order
Research on attribute reduction algorithm with weights
Advances in rough set theory and its applicatinons

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}