半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类.
从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始.
本文沿袭kPC的几何解释,根据“样本距离其簇对应的拟合平面最近”的思想来实现“样本归簇”和“平面更新”,基于kPC和已有工作L1kPC设计半监督聚类算法,提出基于L2范数的semi⁃kPC和基于L1范数的semi⁃L1kPC.所需求解的拟合平面,可通过求解一般特征方程和线性规划完成.算法均在每簇仅有一个已标样本的极端情形下进行设计.
1 kPC和L1kPC聚类算法简介
1.1 kPC聚类
k ⁃means的点原型聚类中心,其优化目标是要寻找k 个超平面,记为H = h 1 , h 2 , ⋯ , h k
h i = x w i T x + γ i = 0 , x ∈ R d i = 1,2 , ⋯ , k (1)
其中,w i γ i h i
m i n ∑ i = 1 k ∑ j = 1 n i w i T x j ( i ) + γ i 2 s . t . w i 2 = 1 , i = 1 ~ k (2)
其中,w i T x j ( i ) + γ i 2 w i 2 i 簇的第j 个样本x j ( i ) h i n i i 簇样本数.进一步化简可知,超平面h i
1.2 L1kPC聚类
采用L1范数的L1kPC算法需要解决两个问题:(1)点到平面距离的L1解析度量;(2)L1范数约束下,可行域是非凸的.由文献[21 ]可知,点v w T x + γ = 0
s = w T v + γ w ∞ (3)
其中,⋅ ∞ ⋅ 1 w ∞ = 1 i 某簇样本
A i = x 1 ( i ) T ⋮ x n i ( i ) T
∑ j = 1 n i w i T x j ( i ) + γ i A i w i + e γ i 1 . 在w i ∞ = 1 A i w i + e γ i 1 e w i 1 = 1 w ∞ = 1 w i | w i | [9 ,22 ] ,如式(4)所示:
m i n ( w , γ ) A w + e γ 1 , s . t . | | w | | 1 = 1 (4)
该问题(式(4))是一个非凸优化问题,可将此非凸问题转化为有限个子集上凸问题来求解,这样可使问题转化为求解一个线性规划.
该算法启动同kPC,通过“样本归簇”和“平面更新”两个步骤实现聚类.实验验证了该聚类较之kPC具有鲁棒性.
2 半监督kPC和L1kPC平面聚类算法
对呈平面型分布的数据,采用kPC类聚类方法非常有效,但此类算法通过随机初始化平面启动算法,实验中发现,这种随机启动会直接影响到聚类效果.受k ⁃means类型半监督聚类的启发,若是利用少量监督信息来启动算法,则聚类效果应该会有明显改善.
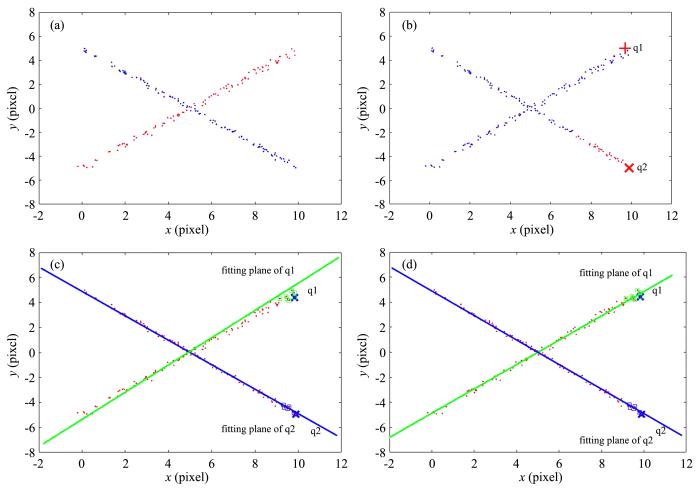
图1 是一个典型的XOR问题的两类数据,图1 a显示两类数据,抽样于两条相互交叉的直线(施加了部分噪声).图1 b中加入了两个标记样本,分别记为“x ”(q1)和“x ”(q2),在此监督信息作用下,半监督型k ⁃means仍然有较多样本被错误聚类.图1 c和图1 d表示本文提出的两个半监督聚类方法:semi⁃kPC和semi⁃L1kPC.直观上,二者产生的两个拟合平面能够真实地反映样本的原来分布,绝大多数样本均获得了正确的聚类.由于无法从一个已标样本生成拟合平面,图1 c和图1 d中标记为“□”的样本是根据q1和q2查询点k 近邻寻找到的样本用以辅助求解拟合平面的.
图1
图1
数据集的原始分布(a)和k ⁃means (b),semi⁃kPC (c),semi⁃L1kPC (d)三种方法在XOR上的聚类效果
Fig.1
Illustration for results of three methods on XOR dataset:(a) original distriburion,
(b) k ⁃means,(c) semi⁃kPC,(d) semi⁃L1kPC
2.1 半监督平面聚类算法
两个半监督聚类算法,其主要步骤仍遵循kPC的两步迭代:“样本归簇”和“平面更新”.由于Semi⁃kPC采用人们熟悉的L2范数,为避免重复和限于篇幅,本节仅描述采用L1范数的Semi⁃L1kPC算法.符号说明如下:给定k 簇n 个样本,包含两部分数据:有标样本集x L a b e l e d ( 少量)和无标样本集x U n l a b e l e d ( 大量),记每簇的有标样本集为S j j = 1,2 , ⋯ , k . 如前文所述,每簇中至少含一个有标样本,故S j ≠ ∅ ,
S j ⋂ S i = ∅ i ≠ j ⋃ S j = X L a b e l e d i , j = 1,2 , ⋯ ,
k . 迭代过程中产生的临时簇记为A i , i = 1 , ⋯ , k k 个平面标记同前文.算法描述如下.
输入:样本集x L a b e l e d x U n l a b e l e d k .
Step1 初始化,用有标样本初始化S i A i ← S i i = 1,2 , ⋯ , k . 设置最大迭代次数MaxIter,迭代计数器iter← 0.
Step2 检查每个A i
Step3 从x U n l a b e l e d A i A i
Step4 平面更新.按式(4)的解更新超平面.∥※
Step5 样本归簇.根据公式(3)计算L1范数的点到平面距离,实现样本归簇.
A i ← A i ⋃ S i i = 1,2 , ⋯ , k ←
条件1:若iter>MaxIter,停机,否则转Step4;
条件2:若A i
(1)算法的Step4和Step5加注了标记“※”以示Semi⁃kPC与之有所不同,其平面更新可按下文的式(6)进行(见下文定理1).而semi⁃L1kPC则按下文的式(10)计算(见下文定理4).
(2)Step2中的检查能否产生拟合平面,可通过检查簇中线性无关的样本数是否超过样本维数来判断.因为在d 维线性空间中,唯一确定一个平面至少需要d 个样本.当然亦可通过点原型的半监督方法来启动平面聚类.
(3)两个聚类算法kPC和L1kPC得到的解都是非凸问题,无法保证全局最优解.k 个拟合平面均在k 个簇上计算,在各自的凸集上的优化是凸优化,存在最优解.为防止算法不收敛或收敛速度过慢,在停机条件中设置了最大迭代次数.由实验的经验可知设置次数为50时,大多数问题均有较好聚类效果.
(4)监督信息利用问题.算法的Step1和Step5都运用了监督信息.Step1中是为了避免原聚类算法的随机初始化问题,而Step5中是为了防止样本归簇过程中因拟合平面尚未稳定而可能产生的有标样本归簇错误,为强调有标样本的作用,在迭代过程中加以强化.
2.2 模型描述与相关证明
为方便阅读,给出几个定理并简证,为上述算法提供理论支撑.
定理1 可通过解决式(5)获得semi⁃kPC的更新平面:
m i n ( w i , γ i ) A i w i + e γ i 2 2 , s . t . w i 2 2 = 1 (5)
拟合平面的w i ψ w i = λ w i γ i = - e T A i w i / n i ψ [17 ] .
简证 由于L2范数可导,构造拉格朗日函数,并令其对w i γ i
ψ w i = λ w i , γ i = - e T A i w i n i (6)
其中,ψ = A T I - e e T n i A e T A i n i
下面介绍在L1范数下,semi⁃L1kPC算法需要的理论保证.符号说明同前.
定理2 L1范数下,可通过求解式(7)来解决semi⁃L1kPC中的平面更新:
m i n ( w i , γ i ) A i w i + e γ i 1 , s . t . w i ∞ = 1 (7)
证明 由文献[22 ]可知,在w i ∞ = 1 w i T x j ( i ) + γ i
A i w i + e γ i 1 = x j ( i ) T w i + γ i
m i n ( w i , γ i ) A i w i + e γ i 1 , s . t . w i 1 = 1 (8)
证明 比较式(7)和式(8),两者只在范数约束上存在不同.
先证(8)→(7).设w i * w i * = w i 1 * , w i 2 * , ⋯ , w i d * T ∑ j w i j * = 1 l 个分量的绝对值最大.若w i l * > 0 w i * ← w i * / w i l * w i l * < 0 w i * ← w i * / ( - w i l * ) w i * w i * ∞ = 1 . 对式(7)的目标函数同样进行放缩,可知式(7)仍能保持原有几何解释,且解不变.考虑在式(7)的目标中除以正数(| w i l * | ) 是为了保证问题在迭代过程中始终保持优化最小化目标.
证明(8)←(7),与证明(8)→(7)类似,只需对式(7)的最优解进行归一化处理即可.
从证明过程知,令超平面法向量长度为1,一方面是为了保持几何解释,同时也起到了避免问题的解退化为平凡解(零解).
m i n α A - e m P α 1 , s . t . α ≥ 0 , e T α = 1 (9)
其中,P = ( p 1 , p 2 , ⋯ , p d ) w i 1 = 1 d 个线性无关的向量(分量对应顶点坐标)组成.
限于篇幅,仅说明基本思路:因w i 1 = 1
w i = P α (10)
3 实验与分析
本文的实验环境为CPU 2.6 GHz,Intel(R) Core(TM) i5⁃3230 M,内存4.0 GB,Windows 7旗舰版,Matlab R2015b.在人工数据集和UCI标准数据集上进行实验.其中,人工数据集主要用于可视化、验证semi⁃kPC和semi⁃L1kPC算法在XOR问题上的平面特性以及比较两种范数的半监督聚类方法的鲁棒性;UCI数据集用来测试半监督平面聚类算法的推广能力.实验采用十折交叉验证.训练集中除少量样本作为有标样本,对训练模型提供监督信息外,其余样本均作无标记处理.采用聚类准确率[16 ,17 ,23 ] 来评价聚类算法的性能.假定G 是聚类算法预测出的样本标签集合,Q 是样本真实标签集合.对于样本集合中的任意一对数据点,用四个变量f 11 , f 10 , f 01 , f 00 ACC )的定义如下:
A C C = f 11 + f 00 f 11 + f 01 + f 10 + f 00 (11)
其中,f 11 = | G ⋂ Q | G 也在集合Q 中,剩下三个变量.同理,f 00 = G ¯ ⋂ Q ¯ f 10 = G ⋂ Q ¯ f 01 = G ¯ ⋂ Q . 符号| ⋅ | G ¯ Q ¯ G Q
3.1 人工数据集
3.1.1 两类XOR问题实验
图1 所示的两类人工数据集是从两条相互交叉的直线中各抽样100个点,在所有样本点的第二个分量上注入高斯噪声(噪声服从高斯分布,大小为N (0,0.1))构成.从每类仅有的一个有标样本出发,此时仍无法产生拟合平面.本文按k 近邻方法寻找与之相似样本并加入到对应的临时簇集,当簇中样本数超过2时,计算拟合平面,不断重复算法1的“平面更新”和“样本归簇”,直到满足停机条件.图1 b的半监督k ⁃means方法共有70个样本发生聚类错误,准确率为65%,而semi⁃kPC和semi⁃L1kPC共有三个和一个样本未能获得正确归簇,准确率分别为98.5%和99.5%.实验表明,与点原型的k ⁃means相比,在XOR问题上,平面型的半监督聚类方法更适用于平面型或线型分布的数据.
3.1.2 混有野值的人工数据集实验
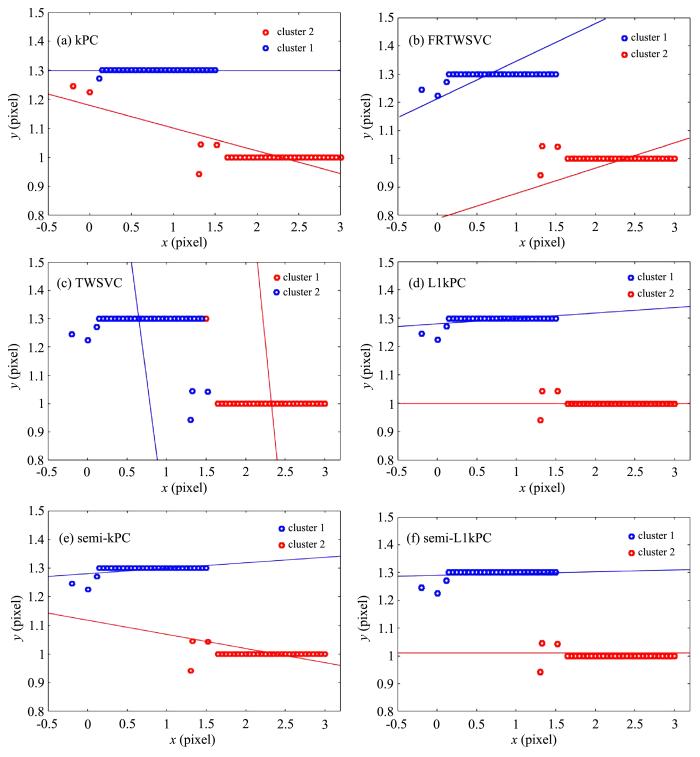
大量文献说明,采用L1范数的学习机比采用L2范数能更有效地抑制野值(outlier)和噪声的影响.已在实验上得到了验证,采用L1范数的L1kPC聚类方法,比采用L2范数的kPC抗野值能力更好.人工数据集分布如图2 所示,两类样本的第一分量(横轴)分别从区间[0,1.5]和[1.5,3]抽样,第二分量(纵轴)分别设为1和1.3,按第一分量的次序,在两类的前六个样本中加上10%的高斯噪声.图2 所示的q1和q2同样表示两个有标记样本,按算法1生成两类拟合平面如图2 所示的线段.图2 a至图2 f分别展示了六种聚类算法的聚类结果及拟合平面的结果.其中,图2 e中的两条拟合直线,一条虽几乎与横轴平行,但发生了偏移;而另一条则明显偏离样本原始分布.而在图2 f中两类拟合平面几乎都与横轴平行,两类样本也都达到了正确归簇,即semi⁃L1kPC的两个拟合平面能够较好地反映样本分布.需要注意的是,图2 e至图2 f中的有标样本选择了野值点,若选择正常样本作为有标样本,则两种方法获得的拟合平面均能较好地反映样本的线性分布特性,拟合效果上两者的差异不明显.为节约篇幅,结果未在文中列出.
图2
图2
六种算法的鲁棒性测试
Fig.2
Robustness test of six algorithms
图2 所示的人工数据集上,semi⁃L1kPC算法和semi⁃kPC相比,其拟合效果更为符合人类直觉,这也正验证了L1范数比L2范数更鲁棒.
3.2 UCI数据集
为了进一步检验平面型的半监督聚类算法的泛化能力,在UCI数据集上进行实验.本文选取Ecoli,Glass和Haberman等九个数据集,数据基本信息如表1 所示.
从每类仅有一个有标样本出发(监督信息),按算法1,在不满足生成拟合平面的条件时采用k 近邻方法寻找相似样本,当临时簇中样本数大于维数时按“平面更新”和“样本归簇”完成后续聚类.按10折交叉验证,聚类准确率取10次的平均结果,汇报结果于表2 ,表中黑体字为聚类准确率最高,下画线为聚类准确率的平均值较高.
从表2 可见,和点原型的k ⁃means聚类方法相比,平面型聚类方法在八个数据集上获得了最高的聚类准确率.为检验引入的少量监督信息是否有利于提升聚类性能,表2 中还分别对两个半监督方法和四个无监督方法的聚类结果进行了平均,结果显示:引入监督信息后,七个数据集上的聚类准确率均有提升,其中在Ecoil上有大幅度提升.具体到各方法,在六个数据集上,semi⁃kPC优于kPC;在七个数据集上,semi⁃L1kPC优于L1kPC,半监督的方法(semi⁃kPC和semi⁃L1kPC)也优于无监督(kPC,TWSVC,FRTWSVC和L1kPC).不同范数的聚类方法性能比较上,在八个数据集上FRTWSVC性能优于TWSVC,在七个数据集上L1kPC性能优于kPC,在六个数据集上semi⁃L1kPC优于semi⁃kPC.
综合以上信息:(1)平面型聚类方法整体优于k ⁃means,说明平面型聚类方法对未知分布的数据同样有效;数据集Haberman上该数据(三维)的可视化结果呈椭球形分布,更适合k ⁃means的点原型聚类方法.表2 的实验结果也反映出在该数据集上,平面型聚类方法弱于k ⁃means.(2)引入监督信息的半监督方法,其聚类性能整体上要优于无监督方法,说明少量监督信息的利用对通过随机取值启动算法的无监督聚类,聚类性能有明显提升.同时亦发现,监督信息的利用并非全部有效,若利用的监督信息自身有误或者不能反映类别信息,效果反而不如随机方法.此外,采用随机的方法在机器学习得到广泛应用,一种可行的解释是,随机方法更有利于跳出局部极小解问题.(3)采用L1范数的聚类方法较L2范数更鲁棒,实验结果也反映出在大多数据集上,L1范数的聚类性能更好.然而在面对真实场景时,数据在采集或传输过程中不可避免会受到污染,只是污染程度未知,这也是鲁棒学习普遍关心的问题.
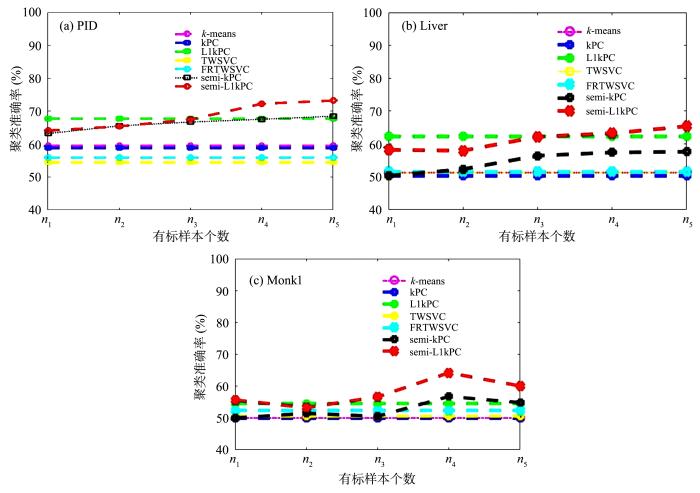
为进一步探究监督信息的多少对聚类性能的影响,下面的实验通过逐步加大监督信息的比例完成.限于篇幅,只在三个数据集上做了实验,实验结果分别如图3 a至图3 c所示,横轴表示有标样本个数,用以描述监督信息的多少,纵轴表示聚类准确率.监督信息的多少根据有标样本的个数来决定:在样本维数d ≤ 8 时,有标样本个数分别取2,4 , 8,16,20 d > 8 时,取2,8 , 16,20,32 图3 中的横轴刻度n 1 , n 2 , n 3 ,
n 4 , n 5
图3
图3
有标样本的个数对聚类准确率的影响
Fig.3
Accuracies on three datasets with labeled samples of different number
图3 展示了七种算法在PID,Liver和Monk1数据集上的实验结果.整体上看,半监督学习的聚类结果随着有标样本的增加要优于无监督学习方法.此外,图3 也反映出无监督学习在某些情况下已有可能优于半监督学习,其原因可能是样本的标签信息是错误的或者是有标样本选取的跨度不够大等原因造成的.
4 结 论
现有的半监督学习方法大多以点原型为基础设计,这类算法不能处理平面型数据分布.本文借鉴k 平面聚类算法的思想,提出semi⁃kPC和semi⁃L1kPC.这两种聚类方法在处理平面分布型数据和XOR问题上大大提高了聚类准确率.针对semi⁃kPC算法不鲁棒的特点,本文进一步提出基于L1范数的semi⁃L1kPC.该方法在数据集中含有噪声或异常值时,聚类准确率比semi⁃kPC有明显的提升.但是在实验中也发现基于平面的半监督聚类算法依赖于查询点位置,当查询点的位置处于数据点的交叉处,则上述方法失效.今后的工作可以研究避免此类问题的优化算法.
参考文献
View Option
[1]
业巧林 ,许等平 ,张冬 . 基于深度学习特征和支持向量机的遥感图像分类
林业工程学报 ,2019 ,4 (02 ):119 -125 .
[本文引用: 1]
Ye Q L,Xu D P,Zhang D. Remote sensing image classification based on deep learning features and support vector machine
Journal of Forestry Engineering ,2019 ,4 (02 ):119 -125 .
[本文引用: 1]
[2]
许博鸣 ,刘晓峰 ,业巧林 等 . 面向移动平台的深度学习复杂场景目标识别应用
陕西师范大学学报(自然科学版) ,2019 ,47 (05 ):10 -15 .
[本文引用: 1]
Xu B M , Liu X F , Ye Q L ,et al . A deep learning based object detection application for mobile platform in complex scenes
Journal of Shaanxi Normal University (Nature Science Edition) ,2019 ,47 (5 ):10 -15 .
[本文引用: 1]
[3]
刘建伟 ,刘媛 ,罗雄麟 . 半监督学习方法
计算机学报 ,2015 ,38 (8 ):1592 -1617 .
[本文引用: 2]
Liu J W,Liu Y,Luo X L. Semi⁃supervised learning methods
Chinese Journal of Computers ,2015 ,38 (8 ):1592 -1617 .
[本文引用: 2]
[4]
Li Y F , Kwok J T , Zhou Z H . Semi⁃supervised learning using label mean
∥Proceedings of the 26th Annual International Conference on Machine Learning .Montreal,Canada :ACM Press ,2009 :633 -640 .
[本文引用: 1]
[5]
张云斌 ,张春梅 ,周千琪 等 . 基于L1范数和k近邻叠加图的半监督分类算法
模式识别与人工智能 ,2016 ,29 (9 ):850 -855 .
[本文引用: 1]
Zhang Y B , Zhang C M , Zhou Q Q ,et al . Semi⁃supervised classification algorithm based on L1⁃norm and KNN superposition graph
Pattern Recognition and Artificial Intelligence ,2016 ,29 (9 ):850 -855 .
[本文引用: 1]
[6]
马蕾 ,汪西莉 . 基于支持向量机协同训练的半监督回归
计算机工程与应用 ,2011 ,47 (3 ):177 -180 .
[本文引用: 1]
Ma L,Wang X L. (Semi⁃supervised regression based on support vector machine co⁃training
Computer Engineering and Application ,2011 ,47 (3 ):177 -180 .
[本文引用: 1]
[7]
吕峰 ,柴变芳 ,李文斌 等 . 一种主动半监督K⁃means聚类算法的改进策略
南京师范大学学报(工程技术版) ,2018 ,18 (2 ):56 -62 .
[本文引用: 2]
Lü F , Chai B F , Li W B ,et al . An Improved strategy of active semi⁃supervision k⁃means clustering algorithm
Journal of Nanjing Normal University (Engineering and Technology Edition) ,2018 ,18 (2 ):56 -62 .
[本文引用: 2]
[8]
方玲 ,陈松灿 . 结合特征偏好的半监督聚类学习
计算机科学与探索 ,2015 ,9 (1 ):105 -111 .
[本文引用: 1]
Fang L,Chen S C. Semi⁃supervised clustering learning combined with feature preferences
Journal of Frontiers of Computer Science & Technology ,2015 ,9 (1 ):105 -111 .
[本文引用: 1]
[9]
张春涛 ,郭皎 ,徐家良 . 基于稀疏表示的半监督降维方法
计算机工程与应用 ,2011 ,47 (20 ):181 -183 ,187 .
[本文引用: 2]
Zhang C T,Guo J,Xu J L. Semi⁃supervised dimensionality reduction based on sparsity representation
Computer Engineering and Applications ,2011 ,47 (20 ):181 -183 ,187 .
[本文引用: 2]
[10]
Basu S , Banerjee A , Mooney R J . Semi⁃supervised clustering by seeding
∥Machine Learning,Proceedings of the Nineteenth International Conference. Sydney ,Australia :University of New South Wales ,2002 .
[本文引用: 1]
[11]
高滢 ,刘大有 ,齐红 等 . 一种半监督K均值多关系数据聚类算法
软件学报 ,2008 ,19 (11 ):2814 -2821 .
[本文引用: 1]
Gao Y , Liu D Y , Qi H ,et al . Semi⁃supervised k⁃means clustering algorithm for multi⁃type relational data
Journal of Software ,2008 ,19 (11 ):2814 -2821 .
[本文引用: 1]
[12]
Bradley P S , Mangasarian O L . K⁃plane clustering
Journal of Global Optimization ,2000 ,16 (1 ):23 -32 .
[本文引用: 1]
[13]
Fung G M , Mangasarian O L . Multicategory proximal support vector machine classifiers
Machine Learning ,2005 ,59 (1-2 ):77 -97 .
[本文引用: 2]
[14]
Mangasarian O L , Wild E W . Multisurface proximal support vector machine classification via generalized eigenvalues
IEEE Transactions on Pattern Analysis and Machine Intelligence ,2006 ,28 (1 ):69 -74 .
[本文引用: 2]
[15]
Jayadeva , Khemchandani R , Chandra S . Twin support vector machines for pattern classification
IEEE Transactions on Pattern Analysis and Machine Intelligence ,2007 ,29 (5 ):905 -910 .
[本文引用: 1]
[16]
Wang Z , Shao Y H , Bai L ,et al . Twin support vector machine for clustering
IEEE Transactions on Neural Networks and Learning Systems ,2015 ,26 (10 ):2583 -2588 .
[本文引用: 2]
[17]
Ye Q L , Zhao H H , Li Z C ,et al . L1⁃norm distance minimization⁃based fast robust twin support vector k ⁃plane clustering
IEEE Transactions on Neural Networks and Learning Systems ,2018 ,29 (9 ):4494 -4503 .
[本文引用: 3]
[18]
徐庆伶 ,汪西莉 . 一种基于支持向量机的半监督分类方法
计算机技术与发展 ,2010 ,20 (10 ):115 -117 ,121 .
[本文引用: 2]
Xu Q L,Wang X L. A Novel semi⁃supervised classification method based on SVM
Computer Technology and Development ,2010 ,20 (10 ):115 -117 ,121 .
[本文引用: 2]
[19]
杨绪兵 ,潘志松 ,陈松灿 . 半监督型广义特征值最接近支持向量机
模式识别与人工智能 ,2009 ,22 (3 ):349 -353 .
[本文引用: 1]
Yang X B,Pan Z S,Chen S C. Semi⁃supervised proximal support vector machine via generalized eigenvalues
Pattern Recognition and Artificial Intelligence ,2009 ,22 (3 ):349 -353 .
[本文引用: 1]
[20]
Rastogi R , Pal A . Fuzzy semi⁃supervised weighted linear loss twin support vector clustering
Knowledge⁃Based Systems ,2019 ,165 :132 -148 .
[本文引用: 2]
[21]
寇振宇 ,杨绪兵 ,张福全 等 . L1范数最大间隔分类器设计
南京师范大学学报(自然科学版) ,2018 ,41 (4 ):59 -64 .
[本文引用: 1]
Kou Z Y , Yang X B , Zhang F Q ,et al . Design of L1 norm Maximum margin classifier
Journal of Nanjing Normal University (Natural science Edition) ,2018 ,41 (4 ):59 -64 .
[本文引用: 1]
[22]
Yang H X , Yang X B , Zhang F Q ,et al . Infinite norm large margin classifier
International Journal of Machine Learning and Cybernetics ,2019 ,doi:10.1007/s13042⁃018⁃0881⁃y .
[本文引用: 2]
[23]
Halkidi M , Batistakis Y , Vazirgiannis M . On clustering validation techniques
Journal of Intelligent Information Systems ,2001 ,17 (2-3 ):107 -145 .
[本文引用: 1]
基于深度学习特征和支持向量机的遥感图像分类
1
2019
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
基于深度学习特征和支持向量机的遥感图像分类
1
2019
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
面向移动平台的深度学习复杂场景目标识别应用
1
2019
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
面向移动平台的深度学习复杂场景目标识别应用
1
2019
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
半监督学习方法
2
2015
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
半监督学习方法
2
2015
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
Semi?supervised learning using label mean
1
2009
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
基于L1范数和k近邻叠加图的半监督分类算法
1
2016
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
基于L1范数和k近邻叠加图的半监督分类算法
1
2016
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
基于支持向量机协同训练的半监督回归
1
2011
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
基于支持向量机协同训练的半监督回归
1
2011
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
一种主动半监督K?means聚类算法的改进策略
2
2018
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
一种主动半监督K?means聚类算法的改进策略
2
2018
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
结合特征偏好的半监督聚类学习
1
2015
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
结合特征偏好的半监督聚类学习
1
2015
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
基于稀疏表示的半监督降维方法
2
2011
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
... ∑ j = 1 n i w i T x j ( i ) + γ i A i w i + e γ i 1 . 在w i ∞ = 1 A i w i + e γ i 1 e w i 1 = 1 w ∞ = 1 w i | w i | [9 ,22 ] ,如式(4)所示: ...
基于稀疏表示的半监督降维方法
2
2011
... 半监督学习是机器学习、数据挖掘等领域的重要研究方向,已广泛应用于自然语言处理、计算机视觉和手写数字识别等领域[1 ,2 ] .科技发展使数据采集和数据存储更简便,人们可以很容易地获得无类别标记的海量数据.但由于类别的标签难以获取(实验时间过长甚至是毁灭性的)或是代价昂贵(使用高精尖仪器设备等),如何充分利用少量的标记样本和大量无标记样本完成学习任务成为半监督学习所要解决的问题.自20世纪70年代的自训练方法(Self⁃Training)问世以来,经过近50年的发展,按学习任务可将半监督学习[3 ,4 ] 分为半监督分类[5 ] 、半监督回归[6 ] 、半监督聚类[7 ,8 ] 和半监督降维[9 ] .本文仅关注半监督聚类. ...
... ∑ j = 1 n i w i T x j ( i ) + γ i A i w i + e γ i 1 . 在w i ∞ = 1 A i w i + e γ i 1 e w i 1 = 1 w ∞ = 1 w i | w i | [9 ,22 ] ,如式(4)所示: ...
Semi?supervised clustering by seeding
1
2002
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
一种半监督K均值多关系数据聚类算法
1
2008
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
一种半监督K均值多关系数据聚类算法
1
2008
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
K?plane clustering
1
2000
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
Multicategory proximal support vector machine classifiers
2
2005
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
... [13 ]和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
Multisurface proximal support vector machine classification via generalized eigenvalues
2
2006
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
... [14 ],导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
Twin support vector machines for pattern classification
1
2007
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
Twin support vector machine for clustering
2
2015
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
... 本文的实验环境为CPU 2.6 GHz,Intel(R) Core(TM) i5⁃3230 M,内存4.0 GB,Windows 7旗舰版,Matlab R2015b.在人工数据集和UCI标准数据集上进行实验.其中,人工数据集主要用于可视化、验证semi⁃kPC和semi⁃L1kPC算法在XOR问题上的平面特性以及比较两种范数的半监督聚类方法的鲁棒性;UCI数据集用来测试半监督平面聚类算法的推广能力.实验采用十折交叉验证.训练集中除少量样本作为有标样本,对训练模型提供监督信息外,其余样本均作无标记处理.采用聚类准确率[16 ,17 ,23 ] 来评价聚类算法的性能.假定G 是聚类算法预测出的样本标签集合,Q 是样本真实标签集合.对于样本集合中的任意一对数据点,用四个变量f 11 , f 10 , f 01 , f 00 ACC )的定义如下: ...
L1?norm distance minimization?based fast robust twin support vector k ?plane clustering
3
2018
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
... 拟合平面的w i ψ w i = λ w i γ i = - e T A i w i / n i ψ [17 ] . ...
... 本文的实验环境为CPU 2.6 GHz,Intel(R) Core(TM) i5⁃3230 M,内存4.0 GB,Windows 7旗舰版,Matlab R2015b.在人工数据集和UCI标准数据集上进行实验.其中,人工数据集主要用于可视化、验证semi⁃kPC和semi⁃L1kPC算法在XOR问题上的平面特性以及比较两种范数的半监督聚类方法的鲁棒性;UCI数据集用来测试半监督平面聚类算法的推广能力.实验采用十折交叉验证.训练集中除少量样本作为有标样本,对训练模型提供监督信息外,其余样本均作无标记处理.采用聚类准确率[16 ,17 ,23 ] 来评价聚类算法的性能.假定G 是聚类算法预测出的样本标签集合,Q 是样本真实标签集合.对于样本集合中的任意一对数据点,用四个变量f 11 , f 10 , f 01 , f 00 ACC )的定义如下: ...
一种基于支持向量机的半监督分类方法
2
2010
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
... [18 ],semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
一种基于支持向量机的半监督分类方法
2
2010
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
... [18 ],semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
半监督型广义特征值最接近支持向量机
1
2009
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
半监督型广义特征值最接近支持向量机
1
2009
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
Fuzzy semi?supervised weighted linear loss twin support vector clustering
2
2019
... 从监督信息利用上看现有的半监督聚类方法可分为三类[3 ] :(1)基于约束的;(2)基于距离度量的;(3)对约束和距离度量进行融合的.第一类主要采用must⁃link和cannot⁃link成对约束关系作为监督信息,用于指导聚类.第二类根据少量已标样本信息,通过相似性度量,如k 近邻等,寻找一批与之相似的样本,并以已标样本的标号标记之.当标记出的样本个数达到某条件后,再完成后续聚类.第三类是在使用带约束的监督信息的同时进行度量学习的半监督聚类学习方法.如经典k ⁃means,2002年Basu et al[10 ] 设计了半监督的约束k ⁃means (Constrained k ⁃means)和种子k ⁃means (Seeds k ⁃means)算法,先使用标记样本组成种子集合,在种子集合中构造出k 个簇中心用以替换k ⁃means的随机代表点,再按k ⁃means继续迭代.以k ⁃means为原型,吕峰等[7 ] 提出同时利用特征和样本两个层面的信息来设计半监督聚类方法.高滢等[11 ] 改进了k ⁃means聚类算法的初始聚类中心以及相似性度量方法,提出一种半监督k ⁃means多关系数据聚类算法.由于上述方法都是基于点原型的聚类算法进行设计,对于样本呈球形或椭球形分布较为有效,而当样本呈线性(包括XOR(Exclusive OR)问题)或平面型分布时,上述算法难以胜任.借鉴点原型思想,Bradley and Mangasarian[12 ] 用平面原型替换k ⁃means的点原型,提出kPC(k⁃Plane Clustering)聚类算法,即对k 簇聚类问题,先随机选择k 个平面,根据样本到各个平面的距离实现“样本归簇”,再根据归簇的样本“更新平面”,交替使用“样本归簇”和“平面更新”直到所有簇中的样本归属不再变化,迭代中的拟合平面可通过计算特征方程获得.这种采用平面拟合样本的思想,结合SVM(Support Vector Machine),Fung and Mangasarian[13 ] 和Mangasarian and Wild[14 ] 发表了二分类方法PSVM(Proximal Support Vector Machine)[13 ] 和GEPSVM(PSVM via Generalized Eigenvalue)[14 ] ,导出的问题可分别通过线性方程组和广义特征方程求解.Jayadeva et al[15 ] 用平面拟合样本的模型设计取代SVM的间隔,发表了TWSVM(Twin SVM)二分类算法,两个拟合平面可通过求解两个较小规模的二次规划获得(占SVM求解规模的1/4).自此,平面型学习机受到了广泛关注,提出诸如聚类的TWSVC(Twin SV Clustering)[16 ] ,FRTWSVC(L1 norm TWSVC) [17 ] 和MMC(Maximal Margin clustering)[18 ] ,半监督分类的semi⁃SVM[18 ] ,semi⁃GEPSVM[19 ] ,半监督聚类的semi⁃supervised WLL⁃TWSVC,fuzzy semi⁃supervised WLL⁃TWSVC[20 ] 等.据所知,除Rastogi and Pal[20 ] 报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
... [20 ]报道将半监督方法应用在平面聚类外,未见文献采用平面拟合思想设计半监督聚类算法.fuzzy semi⁃supervised WLL⁃TWSVC本身就是基于L2范数的TWSVC为原型构造目标函数,虽然TWSVC也借鉴平面拟合样本设计模型,但为了引入簇间信息取消了kPC的点到平面距离思想,这样做不仅使TWSVC失去了kPC原有的清晰的几何解释,另一方面,在聚类过程中产生的样本临时所属的簇信息是否一定有利于后续聚类仍值得商榷.基于TWSVC的后续工作均存在此类问题.因此本文的研究仍从保留kPC的几何解释开始. ...
L1范数最大间隔分类器设计
1
2018
... 采用L1范数的L1kPC算法需要解决两个问题:(1)点到平面距离的L1解析度量;(2)L1范数约束下,可行域是非凸的.由文献[21 ]可知,点v w T x + γ = 0
L1范数最大间隔分类器设计
1
2018
... 采用L1范数的L1kPC算法需要解决两个问题:(1)点到平面距离的L1解析度量;(2)L1范数约束下,可行域是非凸的.由文献[21 ]可知,点v w T x + γ = 0
Infinite norm large margin classifier
2
2019
... ∑ j = 1 n i w i T x j ( i ) + γ i A i w i + e γ i 1 . 在w i ∞ = 1 A i w i + e γ i 1 e w i 1 = 1 w ∞ = 1 w i | w i | [9 ,22 ] ,如式(4)所示: ...
... 证明 由文献[22 ]可知,在w i ∞ = 1 w i T x j ( i ) + γ i
On clustering validation techniques
1
2001
... 本文的实验环境为CPU 2.6 GHz,Intel(R) Core(TM) i5⁃3230 M,内存4.0 GB,Windows 7旗舰版,Matlab R2015b.在人工数据集和UCI标准数据集上进行实验.其中,人工数据集主要用于可视化、验证semi⁃kPC和semi⁃L1kPC算法在XOR问题上的平面特性以及比较两种范数的半监督聚类方法的鲁棒性;UCI数据集用来测试半监督平面聚类算法的推广能力.实验采用十折交叉验证.训练集中除少量样本作为有标样本,对训练模型提供监督信息外,其余样本均作无标记处理.采用聚类准确率[16 ,17 ,23 ] 来评价聚类算法的性能.假定G 是聚类算法预测出的样本标签集合,Q 是样本真实标签集合.对于样本集合中的任意一对数据点,用四个变量f 11 , f 10 , f 01 , f 00 ACC )的定义如下: ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}