概念漂移会导致数据流分类模型的分类能力随时间发展而下降,这就要求分类模型有自适应的能力.现有的大多数自适应概念漂移的数据流分类模型往往假设数据输入分类模型得到预测标签之后就可以得到其真实标签,但这种假设在某些情况下是不合理的,因为数据标记往往成本高、耗时长.因此,针对数据流少量标签的问题,在考虑主动学习可能出现采样偏差的情况下,结合不确定性主动学习策略以及边界点和离群点检测方法(Boundary and Outlier Detection,BOD),提出一种新的主动学习方法ALBOD(Active Learning Based on Boundary and Outlier Detection).比较实验的结果表明,在概念漂移发生的情况下,与100%标记算法OzaBagAdwin(OBA)和HoeffdingAdaptiveTree(HAT)相比,ALBOD主动学习方法只需要平均20%左右的标签就可以使分类器保持同等分类精度,说明新方法ALBOD有良好的主动学习能力.
关键词:数据流
;
概念漂移
;
主动学习
;
自适应分类
Abstract
Concept drift will cause the ability of data stream classification model to decrease with time,which requires the classification model with the ability of self⁃adaptation. However,most of the existing data stream classification models adapting to concept drift ignore the limited label of data stream. They usually assume that the coming data input to classification model can get the real label after the predicted label obtained. But,this assumption is unreasonable in some cases,as labeling data tends to be costly and time⁃consuming. In this paper,a new active learning method,ALBOD (Active Learning based on Boundary and Outlier Detection),is proposed to solve the problem of the scarcity of data stream labels. Our method considers the problem of sampling bias which may occur in the process of active learning by combining the uncertainty active learning method with the BOD (Boundary and Outlier Detection) method. The first criterion is the most common active learning criterion,which selects instances that are the most uncertain in terms of class membership. The latter curbs the sampling bias by using the fact that boundary samples and outliers can reflect the feature space. Compared to the 100% label algorithm OzaBagAdwin (OBA) and HoeffdingAdaptiveTree (HAT),the proposed algorithm ALBOD can make the classification model maintain the same accuracy learning an average of about 20% labels under concept drift. The experiments show that though ALBOD is a sample combination of the above two criterions,it has a good active learning ability.
Zhang Yinfang, Yu Hong, Wang Guoyin, Xie Yongfang. An active learning method for data stream adaptive classification. Journal of nanjing University[J], 2020, 56(1): 67-73 doi:10.13232/j.cnki.jnju.2020.01.008
概念漂移是现实数据流应用中普遍存在的问题,1986年由Schlimmer and Granger[1]首次提出.现在预测分析和机器学习中的概念漂移大多指目标变量的统计特性随时间以不可预见的方式变化的现象.目前已有大量关于概念漂移的研究[2].概念漂移会导致数据流分类模型的能力随时间的变化而下降,所以数据流的分类模型要保持其分类能力就必须能适应数据流中的概念漂移.
针对数据流少量标签问题,需要标记哪些数据有两种策略:随机标记[6]与主动学习.基于不确定性[7]是常用的主动学习策略.不确定性的衡量通常可以采用信息熵、置信度以及边界法等方法[8,9].这类主动学习方法选择的样本通常位于决策的边界,意味着采样偏向分类器的决策边界,但概念漂移可能在任何时间发生在特征空间的任何位置,导致数据流主动学习可能出现采样偏差(sampling bias)[10],即主动学习的样本所代表的分布与数据本身的分布发生偏离.目前已有少量考虑采样偏差的主动学习方法.Zliobaite et al[11]提出带有随机性的不确定性策略和分裂策略.Mohamad et al[10]提出基于不确定性和密度的双准则主动选择策略BAL(Bi⁃Criteria Active Learning),还提出基于能够减少未来期望误差(reduce the future expected error)选择样本的主动学习策略SAL(Stream Active Learning)[12].
模式选择是针对一个有个模式的数据集,选择包含个模式的数据子集在一定准则下充分表示原始的数据集,即期望使用子数据集设计的分类器保持使用原始数据集所设计的分类器的泛化性能,而数据量却远远小于原始数据集[13].在数据集过大或数据量不断增大时,其优点是显而易见的.据所知,模式选择所选择的数据通常位于密集分布数据的边缘或者偏离已有的观测数据[13,14],前者通常称边界点,而后者通常称离群点.边界点与离群点的检测有很多重要的应用,如网络入侵的识别[15]、森林火灾的风险预测[16]、机器故障的检测与诊断[17]等.Li et al[14]认为边界点和离群点代表了数据中最有效、有用、富含价值的模式.对边界点与离群点的检测方法,Chandola et al[18]和Agrawal and Agrawal[19]作了全面的概述.Li et al[14]基于数据表示的相关性质提出了一种有效的边界点和离群点的检测方法BOD(Boundary and Outlier Detection algorithm).
本文针对数据流少量标签问题,在考虑主动学习可能出现采样偏差的情况下,结合不确定性主动学习策略及边界点和离群点检测方法BOD,提出一种新的主动学习方法ALBOD(Active Learning based on Boundary and Outlier Detection).实验表明,在概念漂移的情况下,分类模型即使只使用ALBOD主动学习的少量标签进行更新,也可以表现良好的自适应能力.
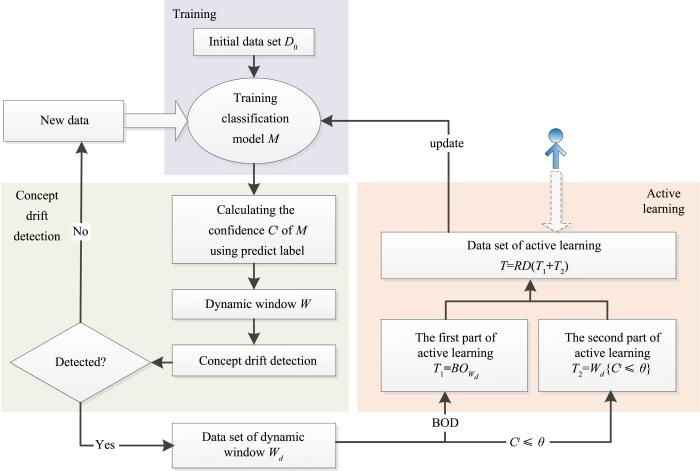
建立基于主动学习的数据流自适应分类模型的主要目的是在分类模型的整个自适应过程中只使用少量的主动学习标签.整个模型的框架如图1所示:自适应分类模型由多个不同k值的kNN分类模型组成,自适应模块分为概念漂移检测和主动学习两部分.概念漂移检测使用Haque et al[7]的方法,检测所使用的分类器置信度计算方法见1.2节.
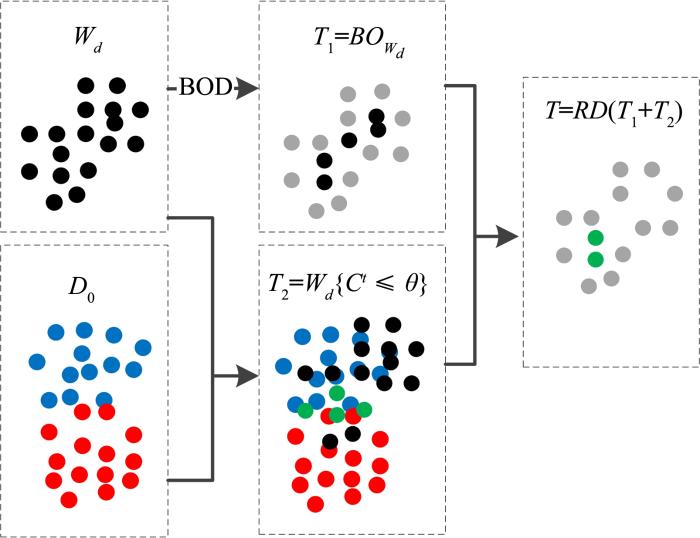
(3)接下来,将每个样本的反向不可达量排序.Li et al[14]认为样本的值越大则样本越偏离密集区域.选择值最大的m个样本作为离群点,除去这m个样本的剩余样本,则设置阈值选择其中的边界点.由于窗口是动态变化的,每个窗口的样本数量存在差异,导致每个窗口的值分布存在差异,所以如果固定选择边界点的参数则可能导致某些窗口不能很好选择出边界点,因此使用除去m个样本后剩余样本的反向不达量的最大值乘以百分比来确定的值.百分比根据不同的数据集以及选择样本的多少人为设定.阈值随窗口中样本数动态的调整如式(7)所示:
最终,一致性子集由m个离群点和阈值选择出的边界点组成.
1.4 主动学习
模型中的概念漂移检测使用Haque et al[7]的方法,其中所使用的分类器置信度在1.2节已经介绍.在检测到概念漂移之后,记录样本置信度的窗口停止增长.接下来,对对应的样本采用1.3节所介绍的方法求一致性子集,作为需要请求标签的第一个样本集,如图2中灰色的点所示.
... 概念漂移是现实数据流应用中普遍存在的问题,1986年由Schlimmer and Granger[1]首次提出.现在预测分析和机器学习中的概念漂移大多指目标变量的统计特性随时间以不可预见的方式变化的现象.目前已有大量关于概念漂移的研究[2].概念漂移会导致数据流分类模型的能力随时间的变化而下降,所以数据流的分类模型要保持其分类能力就必须能适应数据流中的概念漂移. ...
基于可扩展活动关系的过程概念漂移检测
1
2018
... 概念漂移是现实数据流应用中普遍存在的问题,1986年由Schlimmer and Granger[1]首次提出.现在预测分析和机器学习中的概念漂移大多指目标变量的统计特性随时间以不可预见的方式变化的现象.目前已有大量关于概念漂移的研究[2].概念漂移会导致数据流分类模型的能力随时间的变化而下降,所以数据流的分类模型要保持其分类能力就必须能适应数据流中的概念漂移. ...
基于可扩展活动关系的过程概念漂移检测
1
2018
... 概念漂移是现实数据流应用中普遍存在的问题,1986年由Schlimmer and Granger[1]首次提出.现在预测分析和机器学习中的概念漂移大多指目标变量的统计特性随时间以不可预见的方式变化的现象.目前已有大量关于概念漂移的研究[2].概念漂移会导致数据流分类模型的能力随时间的变化而下降,所以数据流的分类模型要保持其分类能力就必须能适应数据流中的概念漂移. ...
Semi?supervised ensemble learning of data streams in the presence of concept drift
1
2012
... 针对数据流少量标签问题,需要标记哪些数据有两种策略:随机标记[6]与主动学习.基于不确定性[7]是常用的主动学习策略.不确定性的衡量通常可以采用信息熵、置信度以及边界法等方法[8,9].这类主动学习方法选择的样本通常位于决策的边界,意味着采样偏向分类器的决策边界,但概念漂移可能在任何时间发生在特征空间的任何位置,导致数据流主动学习可能出现采样偏差(sampling bias)[10],即主动学习的样本所代表的分布与数据本身的分布发生偏离.目前已有少量考虑采样偏差的主动学习方法.Zliobaite et al[11]提出带有随机性的不确定性策略和分裂策略.Mohamad et al[10]提出基于不确定性和密度的双准则主动选择策略BAL(Bi⁃Criteria Active Learning),还提出基于能够减少未来期望误差(reduce the future expected error)选择样本的主动学习策略SAL(Stream Active Learning)[12]. ...
Sand:semi?supervised adaptive novel class detection and classification over data stream
3
2016
... 针对数据流少量标签问题,需要标记哪些数据有两种策略:随机标记[6]与主动学习.基于不确定性[7]是常用的主动学习策略.不确定性的衡量通常可以采用信息熵、置信度以及边界法等方法[8,9].这类主动学习方法选择的样本通常位于决策的边界,意味着采样偏向分类器的决策边界,但概念漂移可能在任何时间发生在特征空间的任何位置,导致数据流主动学习可能出现采样偏差(sampling bias)[10],即主动学习的样本所代表的分布与数据本身的分布发生偏离.目前已有少量考虑采样偏差的主动学习方法.Zliobaite et al[11]提出带有随机性的不确定性策略和分裂策略.Mohamad et al[10]提出基于不确定性和密度的双准则主动选择策略BAL(Bi⁃Criteria Active Learning),还提出基于能够减少未来期望误差(reduce the future expected error)选择样本的主动学习策略SAL(Stream Active Learning)[12]. ...
... 建立基于主动学习的数据流自适应分类模型的主要目的是在分类模型的整个自适应过程中只使用少量的主动学习标签.整个模型的框架如图1所示:自适应分类模型由多个不同k值的kNN分类模型组成,自适应模块分为概念漂移检测和主动学习两部分.概念漂移检测使用Haque et al[7]的方法,检测所使用的分类器置信度计算方法见1.2节. ...
... 模型中的概念漂移检测使用Haque et al[7]的方法,其中所使用的分类器置信度在1.2节已经介绍.在检测到概念漂移之后,记录样本置信度的窗口停止增长.接下来,对对应的样本采用1.3节所介绍的方法求一致性子集,作为需要请求标签的第一个样本集,如图2中灰色的点所示. ...
Active learning literature survey
1
2009
... 针对数据流少量标签问题,需要标记哪些数据有两种策略:随机标记[6]与主动学习.基于不确定性[7]是常用的主动学习策略.不确定性的衡量通常可以采用信息熵、置信度以及边界法等方法[8,9].这类主动学习方法选择的样本通常位于决策的边界,意味着采样偏向分类器的决策边界,但概念漂移可能在任何时间发生在特征空间的任何位置,导致数据流主动学习可能出现采样偏差(sampling bias)[10],即主动学习的样本所代表的分布与数据本身的分布发生偏离.目前已有少量考虑采样偏差的主动学习方法.Zliobaite et al[11]提出带有随机性的不确定性策略和分裂策略.Mohamad et al[10]提出基于不确定性和密度的双准则主动选择策略BAL(Bi⁃Criteria Active Learning),还提出基于能够减少未来期望误差(reduce the future expected error)选择样本的主动学习策略SAL(Stream Active Learning)[12]. ...
A survey on instance selection for active learning
1
2013
... 针对数据流少量标签问题,需要标记哪些数据有两种策略:随机标记[6]与主动学习.基于不确定性[7]是常用的主动学习策略.不确定性的衡量通常可以采用信息熵、置信度以及边界法等方法[8,9].这类主动学习方法选择的样本通常位于决策的边界,意味着采样偏向分类器的决策边界,但概念漂移可能在任何时间发生在特征空间的任何位置,导致数据流主动学习可能出现采样偏差(sampling bias)[10],即主动学习的样本所代表的分布与数据本身的分布发生偏离.目前已有少量考虑采样偏差的主动学习方法.Zliobaite et al[11]提出带有随机性的不确定性策略和分裂策略.Mohamad et al[10]提出基于不确定性和密度的双准则主动选择策略BAL(Bi⁃Criteria Active Learning),还提出基于能够减少未来期望误差(reduce the future expected error)选择样本的主动学习策略SAL(Stream Active Learning)[12]. ...
A bi?criteria active learning algorithm for dynamic data streams
2
2018
... 针对数据流少量标签问题,需要标记哪些数据有两种策略:随机标记[6]与主动学习.基于不确定性[7]是常用的主动学习策略.不确定性的衡量通常可以采用信息熵、置信度以及边界法等方法[8,9].这类主动学习方法选择的样本通常位于决策的边界,意味着采样偏向分类器的决策边界,但概念漂移可能在任何时间发生在特征空间的任何位置,导致数据流主动学习可能出现采样偏差(sampling bias)[10],即主动学习的样本所代表的分布与数据本身的分布发生偏离.目前已有少量考虑采样偏差的主动学习方法.Zliobaite et al[11]提出带有随机性的不确定性策略和分裂策略.Mohamad et al[10]提出基于不确定性和密度的双准则主动选择策略BAL(Bi⁃Criteria Active Learning),还提出基于能够减少未来期望误差(reduce the future expected error)选择样本的主动学习策略SAL(Stream Active Learning)[12]. ...
... [10]提出基于不确定性和密度的双准则主动选择策略BAL(Bi⁃Criteria Active Learning),还提出基于能够减少未来期望误差(reduce the future expected error)选择样本的主动学习策略SAL(Stream Active Learning)[12]. ...
Active learning with drifting streaming data
1
2013
... 针对数据流少量标签问题,需要标记哪些数据有两种策略:随机标记[6]与主动学习.基于不确定性[7]是常用的主动学习策略.不确定性的衡量通常可以采用信息熵、置信度以及边界法等方法[8,9].这类主动学习方法选择的样本通常位于决策的边界,意味着采样偏向分类器的决策边界,但概念漂移可能在任何时间发生在特征空间的任何位置,导致数据流主动学习可能出现采样偏差(sampling bias)[10],即主动学习的样本所代表的分布与数据本身的分布发生偏离.目前已有少量考虑采样偏差的主动学习方法.Zliobaite et al[11]提出带有随机性的不确定性策略和分裂策略.Mohamad et al[10]提出基于不确定性和密度的双准则主动选择策略BAL(Bi⁃Criteria Active Learning),还提出基于能够减少未来期望误差(reduce the future expected error)选择样本的主动学习策略SAL(Stream Active Learning)[12]. ...
Active learning for classifying data streams with unknown number of classes
1
2018
... 针对数据流少量标签问题,需要标记哪些数据有两种策略:随机标记[6]与主动学习.基于不确定性[7]是常用的主动学习策略.不确定性的衡量通常可以采用信息熵、置信度以及边界法等方法[8,9].这类主动学习方法选择的样本通常位于决策的边界,意味着采样偏向分类器的决策边界,但概念漂移可能在任何时间发生在特征空间的任何位置,导致数据流主动学习可能出现采样偏差(sampling bias)[10],即主动学习的样本所代表的分布与数据本身的分布发生偏离.目前已有少量考虑采样偏差的主动学习方法.Zliobaite et al[11]提出带有随机性的不确定性策略和分裂策略.Mohamad et al[10]提出基于不确定性和密度的双准则主动选择策略BAL(Bi⁃Criteria Active Learning),还提出基于能够减少未来期望误差(reduce the future expected error)选择样本的主动学习策略SAL(Stream Active Learning)[12]. ...
Selecting critical patterns based on local geometrical and statistical information
2
2011
... 模式选择是针对一个有个模式的数据集,选择包含个模式的数据子集在一定准则下充分表示原始的数据集,即期望使用子数据集设计的分类器保持使用原始数据集所设计的分类器的泛化性能,而数据量却远远小于原始数据集[13].在数据集过大或数据量不断增大时,其优点是显而易见的.据所知,模式选择所选择的数据通常位于密集分布数据的边缘或者偏离已有的观测数据[13,14],前者通常称边界点,而后者通常称离群点.边界点与离群点的检测有很多重要的应用,如网络入侵的识别[15]、森林火灾的风险预测[16]、机器故障的检测与诊断[17]等.Li et al[14]认为边界点和离群点代表了数据中最有效、有用、富含价值的模式.对边界点与离群点的检测方法,Chandola et al[18]和Agrawal and Agrawal[19]作了全面的概述.Li et al[14]基于数据表示的相关性质提出了一种有效的边界点和离群点的检测方法BOD(Boundary and Outlier Detection algorithm). ...
... [13,14],前者通常称边界点,而后者通常称离群点.边界点与离群点的检测有很多重要的应用,如网络入侵的识别[15]、森林火灾的风险预测[16]、机器故障的检测与诊断[17]等.Li et al[14]认为边界点和离群点代表了数据中最有效、有用、富含价值的模式.对边界点与离群点的检测方法,Chandola et al[18]和Agrawal and Agrawal[19]作了全面的概述.Li et al[14]基于数据表示的相关性质提出了一种有效的边界点和离群点的检测方法BOD(Boundary and Outlier Detection algorithm). ...
An efficient representation?based method for boundary point and outlier detection
7
2016
... 模式选择是针对一个有个模式的数据集,选择包含个模式的数据子集在一定准则下充分表示原始的数据集,即期望使用子数据集设计的分类器保持使用原始数据集所设计的分类器的泛化性能,而数据量却远远小于原始数据集[13].在数据集过大或数据量不断增大时,其优点是显而易见的.据所知,模式选择所选择的数据通常位于密集分布数据的边缘或者偏离已有的观测数据[13,14],前者通常称边界点,而后者通常称离群点.边界点与离群点的检测有很多重要的应用,如网络入侵的识别[15]、森林火灾的风险预测[16]、机器故障的检测与诊断[17]等.Li et al[14]认为边界点和离群点代表了数据中最有效、有用、富含价值的模式.对边界点与离群点的检测方法,Chandola et al[18]和Agrawal and Agrawal[19]作了全面的概述.Li et al[14]基于数据表示的相关性质提出了一种有效的边界点和离群点的检测方法BOD(Boundary and Outlier Detection algorithm). ...
... [14]认为边界点和离群点代表了数据中最有效、有用、富含价值的模式.对边界点与离群点的检测方法,Chandola et al[18]和Agrawal and Agrawal[19]作了全面的概述.Li et al[14]基于数据表示的相关性质提出了一种有效的边界点和离群点的检测方法BOD(Boundary and Outlier Detection algorithm). ...
... [14]基于数据表示的相关性质提出了一种有效的边界点和离群点的检测方法BOD(Boundary and Outlier Detection algorithm). ...
... 是一个仿射空间,则称为的数据表示[14,21].计算数据表示有多种方法,Roweis and Saul[21]提出的数据表示计算方法如式(5)所示: ...
... 所对应的近邻点的表示分量有如下性质[14]: ...
... Li et al[14]基于数据表示的相关性质提出了模式选择方法BOD.通过BOD算法选择出的数据称为数据集的一致性子集.求动态窗口所对应的样本集的一致性子集的步骤如下: ...
... (3)接下来,将每个样本的反向不可达量排序.Li et al[14]认为样本的值越大则样本越偏离密集区域.选择值最大的m个样本作为离群点,除去这m个样本的剩余样本,则设置阈值选择其中的边界点.由于窗口是动态变化的,每个窗口的样本数量存在差异,导致每个窗口的值分布存在差异,所以如果固定选择边界点的参数则可能导致某些窗口不能很好选择出边界点,因此使用除去m个样本后剩余样本的反向不达量的最大值乘以百分比来确定的值.百分比根据不同的数据集以及选择样本的多少人为设定.阈值随窗口中样本数动态的调整如式(7)所示: ...
A survey of network anomaly detection techniques
1
2016
... 模式选择是针对一个有个模式的数据集,选择包含个模式的数据子集在一定准则下充分表示原始的数据集,即期望使用子数据集设计的分类器保持使用原始数据集所设计的分类器的泛化性能,而数据量却远远小于原始数据集[13].在数据集过大或数据量不断增大时,其优点是显而易见的.据所知,模式选择所选择的数据通常位于密集分布数据的边缘或者偏离已有的观测数据[13,14],前者通常称边界点,而后者通常称离群点.边界点与离群点的检测有很多重要的应用,如网络入侵的识别[15]、森林火灾的风险预测[16]、机器故障的检测与诊断[17]等.Li et al[14]认为边界点和离群点代表了数据中最有效、有用、富含价值的模式.对边界点与离群点的检测方法,Chandola et al[18]和Agrawal and Agrawal[19]作了全面的概述.Li et al[14]基于数据表示的相关性质提出了一种有效的边界点和离群点的检测方法BOD(Boundary and Outlier Detection algorithm). ...
A survey on anomaly detection in evolving data:with application to forest fire risk prediction
1
2018
... 模式选择是针对一个有个模式的数据集,选择包含个模式的数据子集在一定准则下充分表示原始的数据集,即期望使用子数据集设计的分类器保持使用原始数据集所设计的分类器的泛化性能,而数据量却远远小于原始数据集[13].在数据集过大或数据量不断增大时,其优点是显而易见的.据所知,模式选择所选择的数据通常位于密集分布数据的边缘或者偏离已有的观测数据[13,14],前者通常称边界点,而后者通常称离群点.边界点与离群点的检测有很多重要的应用,如网络入侵的识别[15]、森林火灾的风险预测[16]、机器故障的检测与诊断[17]等.Li et al[14]认为边界点和离群点代表了数据中最有效、有用、富含价值的模式.对边界点与离群点的检测方法,Chandola et al[18]和Agrawal and Agrawal[19]作了全面的概述.Li et al[14]基于数据表示的相关性质提出了一种有效的边界点和离群点的检测方法BOD(Boundary and Outlier Detection algorithm). ...
A survey of fault diagnosis and fault?tolerant techniques?Part I:fault diagnosis with model?based and signal?based approaches
1
2015
... 模式选择是针对一个有个模式的数据集,选择包含个模式的数据子集在一定准则下充分表示原始的数据集,即期望使用子数据集设计的分类器保持使用原始数据集所设计的分类器的泛化性能,而数据量却远远小于原始数据集[13].在数据集过大或数据量不断增大时,其优点是显而易见的.据所知,模式选择所选择的数据通常位于密集分布数据的边缘或者偏离已有的观测数据[13,14],前者通常称边界点,而后者通常称离群点.边界点与离群点的检测有很多重要的应用,如网络入侵的识别[15]、森林火灾的风险预测[16]、机器故障的检测与诊断[17]等.Li et al[14]认为边界点和离群点代表了数据中最有效、有用、富含价值的模式.对边界点与离群点的检测方法,Chandola et al[18]和Agrawal and Agrawal[19]作了全面的概述.Li et al[14]基于数据表示的相关性质提出了一种有效的边界点和离群点的检测方法BOD(Boundary and Outlier Detection algorithm). ...
Anomaly detection:a survey
1
2009
... 模式选择是针对一个有个模式的数据集,选择包含个模式的数据子集在一定准则下充分表示原始的数据集,即期望使用子数据集设计的分类器保持使用原始数据集所设计的分类器的泛化性能,而数据量却远远小于原始数据集[13].在数据集过大或数据量不断增大时,其优点是显而易见的.据所知,模式选择所选择的数据通常位于密集分布数据的边缘或者偏离已有的观测数据[13,14],前者通常称边界点,而后者通常称离群点.边界点与离群点的检测有很多重要的应用,如网络入侵的识别[15]、森林火灾的风险预测[16]、机器故障的检测与诊断[17]等.Li et al[14]认为边界点和离群点代表了数据中最有效、有用、富含价值的模式.对边界点与离群点的检测方法,Chandola et al[18]和Agrawal and Agrawal[19]作了全面的概述.Li et al[14]基于数据表示的相关性质提出了一种有效的边界点和离群点的检测方法BOD(Boundary and Outlier Detection algorithm). ...
Survey on anomaly detection using data mining techniques
1
2015
... 模式选择是针对一个有个模式的数据集,选择包含个模式的数据子集在一定准则下充分表示原始的数据集,即期望使用子数据集设计的分类器保持使用原始数据集所设计的分类器的泛化性能,而数据量却远远小于原始数据集[13].在数据集过大或数据量不断增大时,其优点是显而易见的.据所知,模式选择所选择的数据通常位于密集分布数据的边缘或者偏离已有的观测数据[13,14],前者通常称边界点,而后者通常称离群点.边界点与离群点的检测有很多重要的应用,如网络入侵的识别[15]、森林火灾的风险预测[16]、机器故障的检测与诊断[17]等.Li et al[14]认为边界点和离群点代表了数据中最有效、有用、富含价值的模式.对边界点与离群点的检测方法,Chandola et al[18]和Agrawal and Agrawal[19]作了全面的概述.Li et al[14]基于数据表示的相关性质提出了一种有效的边界点和离群点的检测方法BOD(Boundary and Outlier Detection algorithm). ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}