多标记学习旨在构建一个分类模型,将相应的示例映射到多个类标记上.多标记学习被广泛应用于现实生活中的许多领域,如图像分类[1 ] 、文本分类[2 ] 、基因功能分类[3 ] 和音乐情感识别[4 ] .如一张图片的标记可能有“飞机”“山丘”“蓝天”等不同语义信息(见图1 );一篇新闻报道中有不同的关键字,如“C罗”“转会”“尤文图斯”;疾病的诊断[5 ] 中,每个病人可能同时有“心脏病”“高血压”“慢性胃炎”等多种疾病.
在多标记学习[5 ] 中,数据特征空间的高维性易导致维数灾难,造成分类性能的降低,因此降低多标记数据的特征维数有显著的意义.目前,多标记特征降维技术主要分特征映射和特征选择两类.多标记特征映射是将原高维特征向量映射到低维特征空间中的过程,主要有线性判别分析(Linear Discriminant Analysis,LDA)[6 ] 、依赖度最大化的多标记维数约简(Multi⁃label Dimensionality reduction via Dependence Maximization,MDDM)[7 ] 和多标记语义搜索(Multi⁃label informed latent semantic indexing,MLSI)[8 ] 等特征映射方法.虽然多标记特征映射降低了特征的维度,但使特征失去了原有的物理意义,导致映射后的特征与标记之间的因果关系难以解释.而多标记特征选择[9 ] 利用某种度量指标对原始特征进行排序或选择最优的特征子集.多标记特征选择一般分过滤、包装、嵌入三种方法,其中过滤式多标记特征选择方法因与分类器无关、因果解释清楚而受到广泛的关注.目前,许多基于不同度量指标的过滤式多标记特征选择算法被提出,如依赖性分析[10 ] 、线性判别分析[6 ] 及互信息[11 ,12 ] .
然而,上述方法只能处理静态的多标记特征选择.大量实际应用场景中多标记数据的特征通常无法一次性全部获得,而要根据实际需求或时间顺序逐步提取相应特征.如在无人车的自动驾驶过程中,无人车根据实际需求自动切换传感器及传输时间顺序提取目标样本特征,然后进行实时特征处理.为了使到达的特征被及时处理,许多在线流多标记特征选择算法被提出.程玉胜等[13 ] 提出动态滑动窗口加权互信息流特征选择,Lin et al提出[14 ] 基于模糊互信息的多标记流特征选择算法,Liu et al[15 ] 提出基于邻域依赖度在线分析的多标记流特征选择算法(Online Multi⁃label Streaming Feature Selection Based on Neighborhood Rough Set,OM⁃NRS).这些多标记流特征选择算法虽能有效地在流环境下选择一组较强差异能力的特征,但也存在高计算代价、选择的特征数量多等缺点.
为了处理流环境下的多标记特征选择问题,本文基于邻域交互增益信息提出一种多标记流特征选择算法(Streaming Multi⁃label Feature Selection,SMFS).首先利用平均间隔粒化不同标记下样本,并定义了多标记学习下的邻域交互增益信息;其次,对新到特征进行在线相关分析与在线冗余分析,基于邻域交互增益信息构建在线多标记特征选择的优化目标函数;最后,大量实验验证了所提算法的有效性.
本文的主要贡献:(1)根据不同的标记,计算样本的平均间隔,以此进行邻域粒化.(2)在流特征的环境下,考虑特征与标记的相关性以及特征间的条件冗余性,提出度量特征的有效性指标.(3)定义了邻域交互增益信息和特征有效性指标,并设计特征选择方法,对已选特征子集进行约简.实验结果证明,本文的算法能够选出一个高质量特征子集,有效地提高分类器的预测性能.
1 多标记学习下的邻域熵与邻域互信息
本节主要介绍多标记学习环境下的邻域熵与邻域互信息.
设U ∀ x i , x j , x k ∈ U Δ Δ
(1)Δ ( x i , x j ) ≥ 0 x i = x j Δ ( x i , x j ) = 0
(3)Δ ( x i , x k ) ≤ Δ ( x i , x j ) + Δ ( x j , x k )
则称Δ U U , Δ p ⁃范数距离函数定义为:
Δ p ( x i , x j ) = ∑ l = 1 N ( x l i , x l j ) P 1 P (1)
当P =1时,Δ P =2时,Δ
U = x 1 , x 2 , … , x n F = f 1 , f 2 , … , f t
是描述样本特征集,L = l 1 , l 2 , … , l m x l i
m l i ( x ) = Δ l i x , N M l i ( x ) - Δ l i x , N T l i ( x ) , ∀ l i ∈ L (2)
其中,N M l i ( x ) x l i N T l i ( x ) x l i
U = x 1 , x 2 , … , x n F = f 1 , f 2 , … ,
f t L = l 1 , l 2 , … , l m x L
m n e u ( x ) = 1 m ∑ i = 1 t m l i ( x ) (3)
定义3[16 ] 给定多标记决策系统U , F , L U L ∀ x ∈ U ∀ l ∈ L x L m n e u ( x ) ≥ 0 x
δ n e u ( x ) = y Δ ( x , y ) ≤ m n e u ( x ) , y ∈ U (4)
定义4[16 ] 给定多标记决策系统U , F , L U = x 1 , x 2 , … , x n f ⊆ F L . 样本x i f δ f n e u ( x i )
N H δ n e u ( f ) = - 1 n ∑ i = 1 n l g δ f n e u ( x i ) n (5)
定义5[16 ] 假设有两个多标记学习下的特征子集r , f ⊆ F x i r ⋃ f δ r ⋃ f n e u ( x i )
N H δ n e u ( f ) = - 1 n ∑ i = 1 n l g δ r ⋃ f n e u ( x i ) n (6)
定义6[16 ] 假设有两个多标记学习下的特征子集r , f ⊆ F
N H δ n e u ( r f ) = - 1 n ∑ i = 1 n l g δ r ⋃ f n e u ( x i ) δ f n e u ( x i ) (7)
定义7[16 ] 假设有两个多标记学习下的特征子集r , f ⊆ F
N M I δ n e u ( r ; f ) = - 1 n ∑ i = 1 n l g δ r n e u ( x i ) ⋅ δ f n e u ( x i ) n δ r ⋃ f n e u ( x i ) (8)
定义8[16 ] 假设有一个多标记学习下的特征子集r ⊆ F L = l 1 , l 2 , ⋯ , l m r L
N M I δ n e u ( r ; L ) = ∑ i = 1 m N M I δ n e u ( r ; l i ) (9)
定义9 假设一个多标记学习下的特征子集f ⊆ F r L = l 1 , l 2 , ⋯ , l m
综合Kwak and Choi[17 ] 所述,在多标记学习中平均间隔下,多标记邻域交互增益信息可近似为:
N M I δ n e u ( L ; r ; f ) = ∑ f s ∈ f N M I δ n e u ( L ; f s ) N H δ n e u ( f s ) N M I δ n e u ( r ; f s ) (10)
邻域交互增益信息能够反映两个不同特征在标记空间L 下所提供的信息量.当它的值为正数时,说明两个特征放在一起能够提供信息,但无法独立提供信息;当它的值为负数时,说明两个特征提供了相同的信息;当它为0时,说明两个特征相互独立.
2 基于邻域交互增益信息的多标记流特征选择算法
为了从流环境下的多标记学习任务中进行特征选择,定义了多标记流特征选择的优化目标函数.
定义10 给定一个流特征多标记决策系统U , F t , L F t = f 1 , f 2 , ⋯ , f t f t t S t - 1 t
S t = a r g m a x N M I δ n e u ( X ; L ) X X ⊆ S t - 1 ⋃ f t (11)
为求解式(11),可分两步进行在线特征分析:第一步,计算新到特征与多标记空间的相关性,若相关,则表示新到特征可以添加到已选特征;第二步,通过定义特征的有效性进行新特征与已选特征间的冗余性分析,得到更紧凑的特征子集.
2.1 在线相关性分析
给定一个流特征多标记决策系统U , F t , L F t = f 1 , f 2 , ⋯ , f t f t t S t - 1 t f t L γ f t = N M I δ n e u ( f t ; L ) . 为了尽可能暂时保留特征的多样性,设置相关性的阈值为0.如果γ f t > 0 f t S t f t . 这样既排除了不相关的特征,又保证了特征多样性,为下一阶段的冗余性分析提供了更多特征组合的可能性.
2.2 在线冗余性分析
为了获得一个更加紧凑的特征子集,候选特征经过相关性分析后,还需计算与已选特征的冗余性.
定义11 给定一个流特征多标记决策系统U , F t , L F t = f 1 , f 2 , ⋯ , f t f t t S t - 1 t f t L S t = S t - 1 ⋃ f t . 可定义特征g ∈ S t = S t - 1 ⋃ f t
λ g , S t = N M I δ n e u ( g ; L ) - 1 S t N M I δ n e u L ; g ; S t \ g , ∀ g ∈ S t (12)
λ g , S t = N M I δ n e u ( g ; L ) - 1 S t ∑ f s ∈ S t \ g N M I δ n e u ( L ; f s ) N H δ n e u ( f s ) N M I δ n e u ( g ; f s ) (13)
在线冗余性分析阶段,对t S t λ g , S t λ ¯ m i n λ g , S t λ ¯ - m i n λ g , S t λ ¯ > β β S t λ g , S t
2.3 基于邻域交互增益信息的多标记流特征选择算法
根据式(11),可设计基于邻域交互增益信息的多标记流特征选择算法(详见算法1).
算法1 基于邻域交互增益信息的多标记流特征选择算法(Streaming Multi⁃label Feature Selection based on neighborhood interaction gain,SMFS)
(4) if γ f t > 0 S t = S t - 1 ⋃ f t
(6) if S t g ∈ S t λ g , S t
(8) 寻找最小的λ g , S t λ λ ¯ .
(10) 将g S t λ g , S t
算法第一步计算平均间隔,时间复杂度为O U ⋅ L + U ⋅ U . 第二步计算特征和多标记空间的相关性,时间复杂度为O U ⋅ U ⋅ L . 第三步对特征的冗余性分析,时间复杂度为O S t l g S t . 因此SMFS算法的时间复杂度为
O U ⋅ L + U ⋅ U + U ⋅ U ⋅ L + S t l g S t
3 实验设计与结果比较
3.1 实验数据
表1 展现了实验数据集的描述情况.下文给出的实验结果的表格中,用括号中的字母代表数据集.
3.2 评价指标
假设d X = R m × d M L = - 1 , + 1 } M . 给定多标记训练集D = ( x i , Y i ) 1 ≤ i ≤ n Z = ( x i , Y i ) 1 ≤ i ≤ m x i ∈ X d x i = ( x i 1 , x i 2 , ⋯ , x i d ) Y i ∈ L f : x → y Y i ' ∈ L . 而r a n k f ( ⋅ , ⋅ ) f
在多标记学习中,为了衡量特征选择效果的优劣,选取Average Precision(AP ),Ranking Loss(RL ),Hamming Loss(HL )和MicroF1(Mi⁃F 1)作为评价算法性能的指标.
A P = 1 m ∑ i = 1 m 1 Y i ∑ y ∈ Y i y ' ∈ Y i : r a n k f ( x i , y ' ) ≤ r a n k f ( x i , y ) r a n k f ( x i , y ) (14)
AP 统计了在样本的类标记的排序序列中,排在相关标记之前的标记依然是相关标记的情况.该指标越大则系统性能越好.
R L = 1 m 1 Y i Y i ¯ ( y ' , y ' ' ) f ( x i , y ' ) ≤ f ( x i , y ' ' ) , ( y ' , y ' ' ) ∈ Y i × Y i ¯ (15)
其中,Y i ¯ Y i
H L = 1 m ∑ i = 1 m Y i ' ⊕ Y i M (16)
其中,⊕ HL 评估误分类的情况的比例,取值越小则算法性能系统性能越好.
M i - F 1 = 2 × ∑ i = 1 m Y i ' ⋂ Y i 1 ∑ i = 1 m Y i 1 + ∑ i = 1 m Y i ' 1 (17)
Mi⁃F 1将统计结果相加,再求得分类性能.该指标越大分类效果越好.
3.3 实验设置
为了有效地评估所提算法,选择五个不同的算法进行对比:MLNB (Feature selection for multi⁃label naive Bayes classification)[18 ] ,MDDM(Multi⁃Label Dimensionality Reduction via Dependence Maximization),根据算法投影方式分为MDDMspc和MDDMproj,PMU (Feature Selection for Multi⁃label Classification Using Multivariate Mutual Information)[19 ] 和RF⁃ML(ReliefF for Multi⁃Label Feature Selection)[20 ] .SMFS算法中β k 个(SMFS算法得到的特征子集个数)特征作为特征子集.最后用ML⁃KNN (Multi⁃Label k ⁃Nearest Neighbor)算法作为多标记分类器.
表2 至表5 展现了四种多标记评价指标下,不同算法的实验结果.表中的“↑”表示表中该指标的取值越高越好,“↓”则表示该指标的取值越小越好.表中最后一行是每个算法在所有数据集中得到的平均值,黑体字表示该算法在当前数据集上的效果最优.
(1)总体来看,SMFS在四个数据集上的各个指标的平均性能都排在第一.
(2)AP 和Mi⁃F 1,SMFS在一半以上的数据集上性能最优,在其他的数据集上也达到次优.
(3)SMFS对于Arts,Business和Emotions数据集上的分类性能的所有指标都是最优的,而在其他数据集上的分类性能与最优值相差不大.
(4)除了SMFS算法,其余五个算法均是处理静态环境下的多标记特征选择算法,然而SMFS在无法事先获取整个特征空间的条件下,仍然有着优异的分类性能.
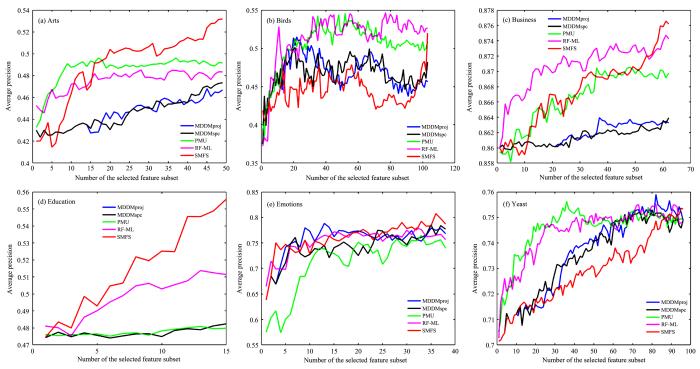
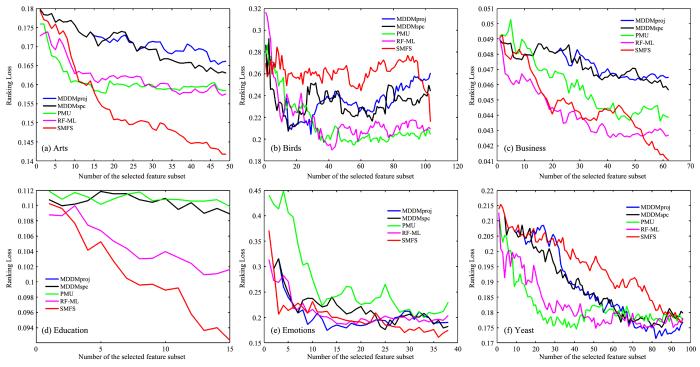
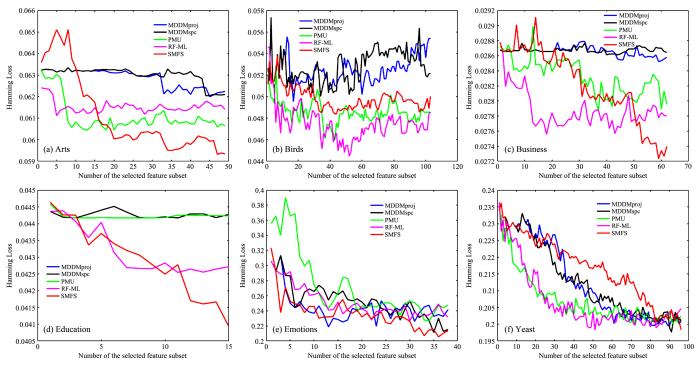
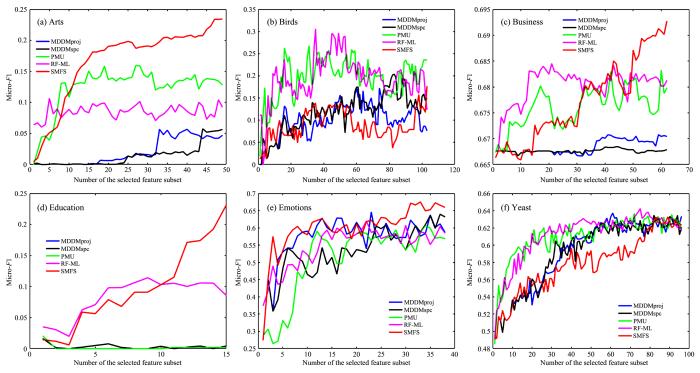
为了更好地观察算法性能与所选特征数目的关系,图2 至图5 展示了SMFS和四个对比算法(MDDMspc,MDDMproj,PMU,RF⁃ML)在不同数据集上的分类性能变化.图中,X 轴代表所选特征的数量,Y 轴代表所选特征对应的评价指标的结果.根据图2 至图5 可以得出:
图1
图1
多标记图片示例
Fig.1
A picture with multi⁃label
图2
图2
SMFS和四个对比算法的AP (↑)在六个数据集上的变化
Fig.2
AP (↑) of SMFS and other four algorithms on six datasts
图3
图3
SMFS和四个对比算法的RL (↓)在六个数据集上的变化
Fig.3
RL (↓) of SMFS and other four algorithms on six datasts
图4
图4
SMFS和四个对比算法的HL (↓)在六个数据集上的变化
Fig.4
HL (↓) of SMFS and other four algorithms on six datasts
图5
图5
SMFS和四个对比算法的Mi-F 1 (↑)在六个数据集上的变化
Fig.5
Mi-F 1 (↑) of SMFS and other four algorithms on six datasts
(1)随着所选特征的增加,评价指标并不是单调增加或者单调减少,说明有的特征对分类性能的提高有负面影响.
(2)在Birds和Yeast数据集上,随着SMFS筛选的特征数目增加,性能提升得较慢,而在其余
(3)总体来看,SMFS的分类性能优于其他四个算法(注:在Education数据集上,由于SMFS选择的特征个数为15,而MDDMporj和MDDMspc特征排序结果的前15位相同,因此关于Education的图中蓝色折线被黄色折线所覆盖).
由于SMFS是处理流特征环境下的算法,因此无法获得整个特征空间时分类性能会受到未知影响.若先流入模型的特征有效性较高,会导致后续的特征越来越难以保留.故在不同的数据集上,算法分类性能的提升速度会有差异.
为了更直观地对比SMFS和五个对比算法之间分类性能的差异,采用Friedman[21 ] 测试和Bonferroni⁃Dunn[22 ] 测试.
首先进行Friedman测试:给定k 个算法和N 个数据集进行比较,r i j j 个算法在第i 个数据集上的序值,测试结果见表6 .第i 个数据集的平均序值为:
R i = 1 N ∑ i = 1 N r i j
假设所有算法的性能都相同的情况下,通常使用变量F F
F F = ( N - 1 ) χ F 2 N ( k - 1 ) - χ F 2 χ F 2 = 12 N k ( k + 1 ) ∑ i = 1 k R i 2 - k ( k + 1 ) 2 4 (18)
从表6 可以看出FF 大于显著性水平α =0.1时的临界值,因此拒绝“所有算法的性能相同”这个假设.
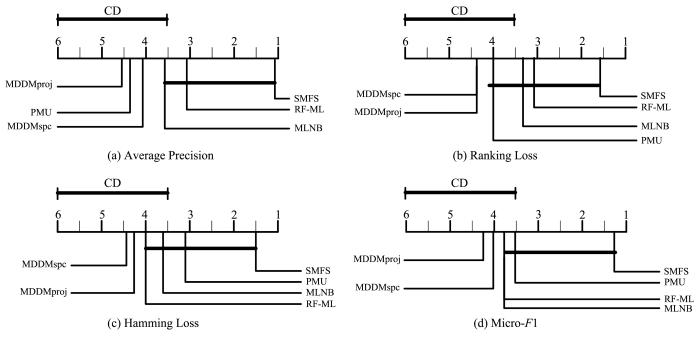
进一步,通过Bonferroni⁃Dunn测试来准确比较不同算法的性能差异(图6 ).该测试计算出平均值序差别的临界值域CD:
C D α = q α k ( k + 1 ) 6 N (19)
图6
图6
通过Bonferroni⁃Dunn测试比较SMFS与其他算法的性能差异
Fig. 6
Performance of SMFS and other algorithms tested by Bonferroni⁃Dunn
在显著性水平α =0.1下,有q α = 2.326 C D = 2.5124 ( k =6,N =6).
图6 根据算法的平均值序进行绘制,排名高的算法在右边.在不同的评估指标下,任意一个在SMFS算法CD值域内的算法,都没有显著性差异.而在CD值域外的算法与SMFS在分类性能上有显著区别.根据图6 可以得到:
(1)SMFS的RL,HL 和Mi⁃F 1指标明显优于MDDMspc和MDDMproj.
(2)SMFS的AP 指标与PMU,MDDMspc和MDDMproj有显著性差异.
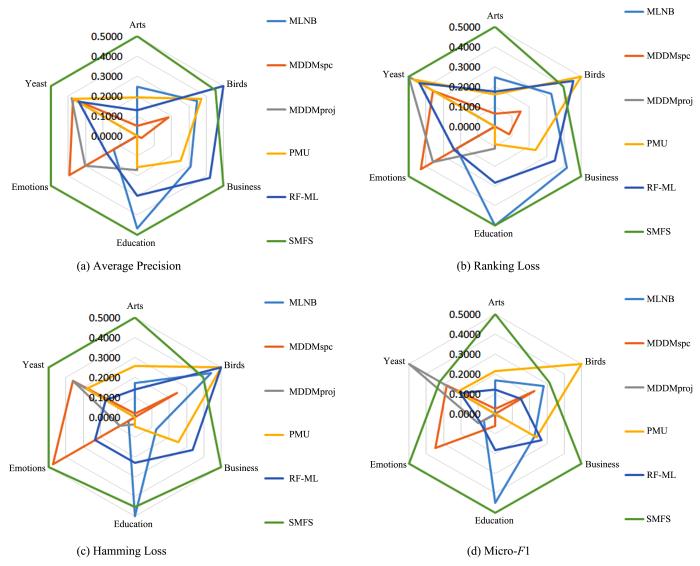
图7
图7
蜘蛛网图展示的SMFS算法在六个多标记数据集下不同指标的稳定性
Fig.7
Spider web diagram of the stability index values of SMFS obtained on six multi⁃label datasets
with different evaluation metrics
的稳定性.其中,绿色代表提出的SMFS算法.根据图7 可以观察到:
(1)在AP ,RL 和HL 指标下,SMFS的形状接近正六边形,说明SMFS得到的解更加优异.
(2)在Mi⁃F 1指标下,Yeast和Birds数据集上的结果较差.但在其他数据集上效果最佳.
(3)在各个指标下,SMFS在至少四个数据集上拥有最优的性能.
(4)在所有指标下,SMFS的覆盖面积远大于其他算法,说明SMFS能够获得更稳定的解.
根据上述实验的结果,说明SMFS算法的稳定性远高于其他算法.
3.4 与OM⁃NRS比较
为了更好地评估SMFS算法在流特征环境下的分类性能,将它与近期提出的多标记流特征选择算法OM⁃NRS进行比较.实验结果如表7 所示,表中最后一行是六个数据集在各自算法下的平均值,黑体表示性能较优的结果.
(1)SMFS在过半的数据集上表现优于OM⁃NRS.同时,在其他数据集上的性能相差不大.
(2)从六个数据集的平均性能来看,SMFS在三个指标下都优于OM⁃NRS.对比这两个流特征择算法,OM⁃NRS采取贪心的思想进行特征选择,意味着它无法摈弃已选择的特征,也就容易受制于前面选择的特征.而SMFS在冗余性分析阶段结合已选特征子集,对所有已选特征重新评估.故SMFS更易找到最优的特征子集,提高分类性能.
4 总 结
在邻域互信息的基础上,对多标记样本进行邻域粒化,提出了邻域交互增益信息.并根据显示应用需要,考虑动态流特征的场景,提出了基于邻域交互增益信息的多标记流特征选择算法.通过四种不同的多标记评价指标,在六个多标记数据集下进行实验.结果表明,提出的SMFS算法优于其他五个多标记特征选择算法.
参考文献
View Option
[1]
Boutell M R Luo J B Shen X P et al Learning multi⁃label scene classification
Pattern Recognition ,2004 ,37 (9 ):1757 -1771 .
[本文引用: 1]
[2]
Lewis D D Yang Y M Rose T G et al RCV1:a new benchmark collection for text categorization research
The Journal of Machine Learning Research ,2004 ,5 (2 ):361 -397 .
[本文引用: 1]
[3]
Elisseeff A Weston J A kernel method for multi⁃labelled classification
∥Proceedings of the 14th International Conference on Neural Information Processing Systems:Natural and Synthetic . Cambridge,MA,USA :MIT Press ,2001 .
[本文引用: 1]
[4]
Trohidis K Tsoumakas G Kalliris G et al Multi⁃label classification of music by emotion
EURASIP Journal on Audio ,Speech ,and Music Processing ,2011 ,2011 (1 ):4 .
[本文引用: 1]
[5]
段洁 ,胡清华 ,张灵均 等 基于邻域粗糙集的多标记分类特征选择算法
计算机研究与发展 ,2015 ,52 (1 ):56 -65 .
[本文引用: 2]
Duan J Hu Q H Zhang L J et al Feature selection for multi⁃label classification based on neighborhood rough set
Journal of Computer Research and Development ,2015 ,52 (1 ):56 -65 .
[本文引用: 2]
[6]
Hotelling H Relations between two sets of variates
Biometrika ,1936 ,28 (3-4 ):321 -377 .
[本文引用: 2]
[7]
Zhang Y Zhou Z H Multilabel dimensionality reduction via dependence maximization
ACM Transactions on Knowledge Discovery from Data ,2010 ,4 (3 ):14 .
[本文引用: 1]
[8]
Yu K Yu S P Tresp V Multi⁃label informed latent semantic indexing
∥Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval .Salvador,Brazil :ACM ,2005 :258 -265 .
[本文引用: 1]
[9]
许行 ,张凯 ,王文剑 一种小样本数据的特征选择方法
计算机研究与发展 ,2018 ,55 (10 ):2321 -2330 .
[本文引用: 1]
Xu X,Zhang K,Wang W J. A feature selection method for small samples
Journal of Computer Research and Development ,2018 ,55 (10 ):2321 -2330 .
[本文引用: 1]
[10]
Zhang L J Hu Q H Duan J et al Multi⁃label feature selection with fuzzy rough sets
∥International Conference on Rough Sets and Knowledge Technology . Springer Berlin Heidelberg ,2014 :121 -128 .
[本文引用: 1]
[11]
Lin Y J Hu Q H Liu J H et al Multi⁃label feature selection based on neighborhood mutual information
Applied Soft Computing ,2016 ,38 :244 -256 .
[本文引用: 1]
[12]
Hu L Gao W F Zhao K et al Feature selection considering two types of feature relevancy and feature interdependency
Expert Systems with Applications ,2018 ,93 :423 -434 .
[本文引用: 1]
[13]
程玉胜 ,李雨 ,王一宾 等 动态滑动窗口加权互信息流特征选择
南京大学学报(自然科学) ,2018 ,54 (5 ):974 -985 .
[本文引用: 1]
Cheng Y S Li Y Wang Y B et al Streaming feature selection with weighted fuzzy mutual information based on dynamic sliding window
Journal of Nanjing University (Natural Science) ,2018 ,54 (5 ):974 -985 .
[本文引用: 1]
[14]
Lin Y J Hu Q H Liu J H et al Streaming feature selection for multilabel learning based on fuzzy mutual information
IEEE Transactions on Fuzzy Systems ,2017 ,25 (6 ):1491 -1507 .
[本文引用: 1]
[15]
Liu J H Lin Y J Li Y W et al Online multi⁃label streaming feature selection based on neighborhood rough set
Pattern Recognition ,2018 ,84 :273 -287 .
[本文引用: 1]
[16]
Lin Y J Hu Q H Liu J H et al Multi⁃label fea⁃ture selection based on max⁃dependency and min⁃redundancy
Neurocomputing ,2015 ,168 :92 -103 .
[本文引用: 8]
[17]
Kwak N Choi C H Input feature selection for classification problems
IEEE Transactions on Neural Networks ,2002 ,13 (1 ):143 -159 .
[本文引用: 1]
[18]
Zhang M L Peña J M Robles V Feature selection for multi⁃label naive Bayes classification
Information Sciences ,2009 ,179 (19 ):3218 -3229 .
[本文引用: 1]
[19]
Lee J Kim D W Feature selection for multi⁃label classification using multivariate mutual information
Pattern Recognition Letters ,2013 ,34 (3 ):349 -357 .
[本文引用: 1]
[20]
Spolaôr N Cherman E A Monard M C et al ReliefF for multi⁃label feature selection
∥2013 Brazilian Conference on Intelligent Systems (BRACIS) . Fortaleza,Brazil :IEEE ,2013 :6 -11 .
[本文引用: 1]
[21]
Friedman M A comparison of alternative tests of significance for the problem of m rankings
The Annals of Mathematical Statistics ,1940 ,11 (1 ):86 -92 .
[本文引用: 1]
[22]
Dunn O J Multiple comparisons among means
Journal of the American Statistical Association ,1961 ,56 (293 ):52 -64 .
[本文引用: 1]
Learning multi?label scene classification
1
2004
... 多标记学习旨在构建一个分类模型,将相应的示例映射到多个类标记上.多标记学习被广泛应用于现实生活中的许多领域,如图像分类[1 ] 、文本分类[2 ] 、基因功能分类[3 ] 和音乐情感识别[4 ] .如一张图片的标记可能有“飞机”“山丘”“蓝天”等不同语义信息(见图1 );一篇新闻报道中有不同的关键字,如“C罗”“转会”“尤文图斯”;疾病的诊断[5 ] 中,每个病人可能同时有“心脏病”“高血压”“慢性胃炎”等多种疾病. ...
RCV1:a new benchmark collection for text categorization research
1
2004
... 多标记学习旨在构建一个分类模型,将相应的示例映射到多个类标记上.多标记学习被广泛应用于现实生活中的许多领域,如图像分类[1 ] 、文本分类[2 ] 、基因功能分类[3 ] 和音乐情感识别[4 ] .如一张图片的标记可能有“飞机”“山丘”“蓝天”等不同语义信息(见图1 );一篇新闻报道中有不同的关键字,如“C罗”“转会”“尤文图斯”;疾病的诊断[5 ] 中,每个病人可能同时有“心脏病”“高血压”“慢性胃炎”等多种疾病. ...
A kernel method for multi?labelled classification
1
2001
... 多标记学习旨在构建一个分类模型,将相应的示例映射到多个类标记上.多标记学习被广泛应用于现实生活中的许多领域,如图像分类[1 ] 、文本分类[2 ] 、基因功能分类[3 ] 和音乐情感识别[4 ] .如一张图片的标记可能有“飞机”“山丘”“蓝天”等不同语义信息(见图1 );一篇新闻报道中有不同的关键字,如“C罗”“转会”“尤文图斯”;疾病的诊断[5 ] 中,每个病人可能同时有“心脏病”“高血压”“慢性胃炎”等多种疾病. ...
Multi?label classification of music by emotion
1
2011
... 多标记学习旨在构建一个分类模型,将相应的示例映射到多个类标记上.多标记学习被广泛应用于现实生活中的许多领域,如图像分类[1 ] 、文本分类[2 ] 、基因功能分类[3 ] 和音乐情感识别[4 ] .如一张图片的标记可能有“飞机”“山丘”“蓝天”等不同语义信息(见图1 );一篇新闻报道中有不同的关键字,如“C罗”“转会”“尤文图斯”;疾病的诊断[5 ] 中,每个病人可能同时有“心脏病”“高血压”“慢性胃炎”等多种疾病. ...
基于邻域粗糙集的多标记分类特征选择算法
2
2015
... 多标记学习旨在构建一个分类模型,将相应的示例映射到多个类标记上.多标记学习被广泛应用于现实生活中的许多领域,如图像分类[1 ] 、文本分类[2 ] 、基因功能分类[3 ] 和音乐情感识别[4 ] .如一张图片的标记可能有“飞机”“山丘”“蓝天”等不同语义信息(见图1 );一篇新闻报道中有不同的关键字,如“C罗”“转会”“尤文图斯”;疾病的诊断[5 ] 中,每个病人可能同时有“心脏病”“高血压”“慢性胃炎”等多种疾病. ...
... 在多标记学习[5 ] 中,数据特征空间的高维性易导致维数灾难,造成分类性能的降低,因此降低多标记数据的特征维数有显著的意义.目前,多标记特征降维技术主要分特征映射和特征选择两类.多标记特征映射是将原高维特征向量映射到低维特征空间中的过程,主要有线性判别分析(Linear Discriminant Analysis,LDA)[6 ] 、依赖度最大化的多标记维数约简(Multi⁃label Dimensionality reduction via Dependence Maximization,MDDM)[7 ] 和多标记语义搜索(Multi⁃label informed latent semantic indexing,MLSI)[8 ] 等特征映射方法.虽然多标记特征映射降低了特征的维度,但使特征失去了原有的物理意义,导致映射后的特征与标记之间的因果关系难以解释.而多标记特征选择[9 ] 利用某种度量指标对原始特征进行排序或选择最优的特征子集.多标记特征选择一般分过滤、包装、嵌入三种方法,其中过滤式多标记特征选择方法因与分类器无关、因果解释清楚而受到广泛的关注.目前,许多基于不同度量指标的过滤式多标记特征选择算法被提出,如依赖性分析[10 ] 、线性判别分析[6 ] 及互信息[11 ,12 ] . ...
基于邻域粗糙集的多标记分类特征选择算法
2
2015
... 多标记学习旨在构建一个分类模型,将相应的示例映射到多个类标记上.多标记学习被广泛应用于现实生活中的许多领域,如图像分类[1 ] 、文本分类[2 ] 、基因功能分类[3 ] 和音乐情感识别[4 ] .如一张图片的标记可能有“飞机”“山丘”“蓝天”等不同语义信息(见图1 );一篇新闻报道中有不同的关键字,如“C罗”“转会”“尤文图斯”;疾病的诊断[5 ] 中,每个病人可能同时有“心脏病”“高血压”“慢性胃炎”等多种疾病. ...
... 在多标记学习[5 ] 中,数据特征空间的高维性易导致维数灾难,造成分类性能的降低,因此降低多标记数据的特征维数有显著的意义.目前,多标记特征降维技术主要分特征映射和特征选择两类.多标记特征映射是将原高维特征向量映射到低维特征空间中的过程,主要有线性判别分析(Linear Discriminant Analysis,LDA)[6 ] 、依赖度最大化的多标记维数约简(Multi⁃label Dimensionality reduction via Dependence Maximization,MDDM)[7 ] 和多标记语义搜索(Multi⁃label informed latent semantic indexing,MLSI)[8 ] 等特征映射方法.虽然多标记特征映射降低了特征的维度,但使特征失去了原有的物理意义,导致映射后的特征与标记之间的因果关系难以解释.而多标记特征选择[9 ] 利用某种度量指标对原始特征进行排序或选择最优的特征子集.多标记特征选择一般分过滤、包装、嵌入三种方法,其中过滤式多标记特征选择方法因与分类器无关、因果解释清楚而受到广泛的关注.目前,许多基于不同度量指标的过滤式多标记特征选择算法被提出,如依赖性分析[10 ] 、线性判别分析[6 ] 及互信息[11 ,12 ] . ...
Relations between two sets of variates
2
1936
... 在多标记学习[5 ] 中,数据特征空间的高维性易导致维数灾难,造成分类性能的降低,因此降低多标记数据的特征维数有显著的意义.目前,多标记特征降维技术主要分特征映射和特征选择两类.多标记特征映射是将原高维特征向量映射到低维特征空间中的过程,主要有线性判别分析(Linear Discriminant Analysis,LDA)[6 ] 、依赖度最大化的多标记维数约简(Multi⁃label Dimensionality reduction via Dependence Maximization,MDDM)[7 ] 和多标记语义搜索(Multi⁃label informed latent semantic indexing,MLSI)[8 ] 等特征映射方法.虽然多标记特征映射降低了特征的维度,但使特征失去了原有的物理意义,导致映射后的特征与标记之间的因果关系难以解释.而多标记特征选择[9 ] 利用某种度量指标对原始特征进行排序或选择最优的特征子集.多标记特征选择一般分过滤、包装、嵌入三种方法,其中过滤式多标记特征选择方法因与分类器无关、因果解释清楚而受到广泛的关注.目前,许多基于不同度量指标的过滤式多标记特征选择算法被提出,如依赖性分析[10 ] 、线性判别分析[6 ] 及互信息[11 ,12 ] . ...
... [6 ]及互信息[11 ,12 ] . ...
Multilabel dimensionality reduction via dependence maximization
1
2010
... 在多标记学习[5 ] 中,数据特征空间的高维性易导致维数灾难,造成分类性能的降低,因此降低多标记数据的特征维数有显著的意义.目前,多标记特征降维技术主要分特征映射和特征选择两类.多标记特征映射是将原高维特征向量映射到低维特征空间中的过程,主要有线性判别分析(Linear Discriminant Analysis,LDA)[6 ] 、依赖度最大化的多标记维数约简(Multi⁃label Dimensionality reduction via Dependence Maximization,MDDM)[7 ] 和多标记语义搜索(Multi⁃label informed latent semantic indexing,MLSI)[8 ] 等特征映射方法.虽然多标记特征映射降低了特征的维度,但使特征失去了原有的物理意义,导致映射后的特征与标记之间的因果关系难以解释.而多标记特征选择[9 ] 利用某种度量指标对原始特征进行排序或选择最优的特征子集.多标记特征选择一般分过滤、包装、嵌入三种方法,其中过滤式多标记特征选择方法因与分类器无关、因果解释清楚而受到广泛的关注.目前,许多基于不同度量指标的过滤式多标记特征选择算法被提出,如依赖性分析[10 ] 、线性判别分析[6 ] 及互信息[11 ,12 ] . ...
Multi?label informed latent semantic indexing
1
2005
... 在多标记学习[5 ] 中,数据特征空间的高维性易导致维数灾难,造成分类性能的降低,因此降低多标记数据的特征维数有显著的意义.目前,多标记特征降维技术主要分特征映射和特征选择两类.多标记特征映射是将原高维特征向量映射到低维特征空间中的过程,主要有线性判别分析(Linear Discriminant Analysis,LDA)[6 ] 、依赖度最大化的多标记维数约简(Multi⁃label Dimensionality reduction via Dependence Maximization,MDDM)[7 ] 和多标记语义搜索(Multi⁃label informed latent semantic indexing,MLSI)[8 ] 等特征映射方法.虽然多标记特征映射降低了特征的维度,但使特征失去了原有的物理意义,导致映射后的特征与标记之间的因果关系难以解释.而多标记特征选择[9 ] 利用某种度量指标对原始特征进行排序或选择最优的特征子集.多标记特征选择一般分过滤、包装、嵌入三种方法,其中过滤式多标记特征选择方法因与分类器无关、因果解释清楚而受到广泛的关注.目前,许多基于不同度量指标的过滤式多标记特征选择算法被提出,如依赖性分析[10 ] 、线性判别分析[6 ] 及互信息[11 ,12 ] . ...
一种小样本数据的特征选择方法
1
2018
... 在多标记学习[5 ] 中,数据特征空间的高维性易导致维数灾难,造成分类性能的降低,因此降低多标记数据的特征维数有显著的意义.目前,多标记特征降维技术主要分特征映射和特征选择两类.多标记特征映射是将原高维特征向量映射到低维特征空间中的过程,主要有线性判别分析(Linear Discriminant Analysis,LDA)[6 ] 、依赖度最大化的多标记维数约简(Multi⁃label Dimensionality reduction via Dependence Maximization,MDDM)[7 ] 和多标记语义搜索(Multi⁃label informed latent semantic indexing,MLSI)[8 ] 等特征映射方法.虽然多标记特征映射降低了特征的维度,但使特征失去了原有的物理意义,导致映射后的特征与标记之间的因果关系难以解释.而多标记特征选择[9 ] 利用某种度量指标对原始特征进行排序或选择最优的特征子集.多标记特征选择一般分过滤、包装、嵌入三种方法,其中过滤式多标记特征选择方法因与分类器无关、因果解释清楚而受到广泛的关注.目前,许多基于不同度量指标的过滤式多标记特征选择算法被提出,如依赖性分析[10 ] 、线性判别分析[6 ] 及互信息[11 ,12 ] . ...
一种小样本数据的特征选择方法
1
2018
... 在多标记学习[5 ] 中,数据特征空间的高维性易导致维数灾难,造成分类性能的降低,因此降低多标记数据的特征维数有显著的意义.目前,多标记特征降维技术主要分特征映射和特征选择两类.多标记特征映射是将原高维特征向量映射到低维特征空间中的过程,主要有线性判别分析(Linear Discriminant Analysis,LDA)[6 ] 、依赖度最大化的多标记维数约简(Multi⁃label Dimensionality reduction via Dependence Maximization,MDDM)[7 ] 和多标记语义搜索(Multi⁃label informed latent semantic indexing,MLSI)[8 ] 等特征映射方法.虽然多标记特征映射降低了特征的维度,但使特征失去了原有的物理意义,导致映射后的特征与标记之间的因果关系难以解释.而多标记特征选择[9 ] 利用某种度量指标对原始特征进行排序或选择最优的特征子集.多标记特征选择一般分过滤、包装、嵌入三种方法,其中过滤式多标记特征选择方法因与分类器无关、因果解释清楚而受到广泛的关注.目前,许多基于不同度量指标的过滤式多标记特征选择算法被提出,如依赖性分析[10 ] 、线性判别分析[6 ] 及互信息[11 ,12 ] . ...
Multi?label feature selection with fuzzy rough sets
1
2014
... 在多标记学习[5 ] 中,数据特征空间的高维性易导致维数灾难,造成分类性能的降低,因此降低多标记数据的特征维数有显著的意义.目前,多标记特征降维技术主要分特征映射和特征选择两类.多标记特征映射是将原高维特征向量映射到低维特征空间中的过程,主要有线性判别分析(Linear Discriminant Analysis,LDA)[6 ] 、依赖度最大化的多标记维数约简(Multi⁃label Dimensionality reduction via Dependence Maximization,MDDM)[7 ] 和多标记语义搜索(Multi⁃label informed latent semantic indexing,MLSI)[8 ] 等特征映射方法.虽然多标记特征映射降低了特征的维度,但使特征失去了原有的物理意义,导致映射后的特征与标记之间的因果关系难以解释.而多标记特征选择[9 ] 利用某种度量指标对原始特征进行排序或选择最优的特征子集.多标记特征选择一般分过滤、包装、嵌入三种方法,其中过滤式多标记特征选择方法因与分类器无关、因果解释清楚而受到广泛的关注.目前,许多基于不同度量指标的过滤式多标记特征选择算法被提出,如依赖性分析[10 ] 、线性判别分析[6 ] 及互信息[11 ,12 ] . ...
Multi?label feature selection based on neighborhood mutual information
1
2016
... 在多标记学习[5 ] 中,数据特征空间的高维性易导致维数灾难,造成分类性能的降低,因此降低多标记数据的特征维数有显著的意义.目前,多标记特征降维技术主要分特征映射和特征选择两类.多标记特征映射是将原高维特征向量映射到低维特征空间中的过程,主要有线性判别分析(Linear Discriminant Analysis,LDA)[6 ] 、依赖度最大化的多标记维数约简(Multi⁃label Dimensionality reduction via Dependence Maximization,MDDM)[7 ] 和多标记语义搜索(Multi⁃label informed latent semantic indexing,MLSI)[8 ] 等特征映射方法.虽然多标记特征映射降低了特征的维度,但使特征失去了原有的物理意义,导致映射后的特征与标记之间的因果关系难以解释.而多标记特征选择[9 ] 利用某种度量指标对原始特征进行排序或选择最优的特征子集.多标记特征选择一般分过滤、包装、嵌入三种方法,其中过滤式多标记特征选择方法因与分类器无关、因果解释清楚而受到广泛的关注.目前,许多基于不同度量指标的过滤式多标记特征选择算法被提出,如依赖性分析[10 ] 、线性判别分析[6 ] 及互信息[11 ,12 ] . ...
Feature selection considering two types of feature relevancy and feature interdependency
1
2018
... 在多标记学习[5 ] 中,数据特征空间的高维性易导致维数灾难,造成分类性能的降低,因此降低多标记数据的特征维数有显著的意义.目前,多标记特征降维技术主要分特征映射和特征选择两类.多标记特征映射是将原高维特征向量映射到低维特征空间中的过程,主要有线性判别分析(Linear Discriminant Analysis,LDA)[6 ] 、依赖度最大化的多标记维数约简(Multi⁃label Dimensionality reduction via Dependence Maximization,MDDM)[7 ] 和多标记语义搜索(Multi⁃label informed latent semantic indexing,MLSI)[8 ] 等特征映射方法.虽然多标记特征映射降低了特征的维度,但使特征失去了原有的物理意义,导致映射后的特征与标记之间的因果关系难以解释.而多标记特征选择[9 ] 利用某种度量指标对原始特征进行排序或选择最优的特征子集.多标记特征选择一般分过滤、包装、嵌入三种方法,其中过滤式多标记特征选择方法因与分类器无关、因果解释清楚而受到广泛的关注.目前,许多基于不同度量指标的过滤式多标记特征选择算法被提出,如依赖性分析[10 ] 、线性判别分析[6 ] 及互信息[11 ,12 ] . ...
动态滑动窗口加权互信息流特征选择
1
2018
... 然而,上述方法只能处理静态的多标记特征选择.大量实际应用场景中多标记数据的特征通常无法一次性全部获得,而要根据实际需求或时间顺序逐步提取相应特征.如在无人车的自动驾驶过程中,无人车根据实际需求自动切换传感器及传输时间顺序提取目标样本特征,然后进行实时特征处理.为了使到达的特征被及时处理,许多在线流多标记特征选择算法被提出.程玉胜等[13 ] 提出动态滑动窗口加权互信息流特征选择,Lin et al提出[14 ] 基于模糊互信息的多标记流特征选择算法,Liu et al[15 ] 提出基于邻域依赖度在线分析的多标记流特征选择算法(Online Multi⁃label Streaming Feature Selection Based on Neighborhood Rough Set,OM⁃NRS).这些多标记流特征选择算法虽能有效地在流环境下选择一组较强差异能力的特征,但也存在高计算代价、选择的特征数量多等缺点. ...
动态滑动窗口加权互信息流特征选择
1
2018
... 然而,上述方法只能处理静态的多标记特征选择.大量实际应用场景中多标记数据的特征通常无法一次性全部获得,而要根据实际需求或时间顺序逐步提取相应特征.如在无人车的自动驾驶过程中,无人车根据实际需求自动切换传感器及传输时间顺序提取目标样本特征,然后进行实时特征处理.为了使到达的特征被及时处理,许多在线流多标记特征选择算法被提出.程玉胜等[13 ] 提出动态滑动窗口加权互信息流特征选择,Lin et al提出[14 ] 基于模糊互信息的多标记流特征选择算法,Liu et al[15 ] 提出基于邻域依赖度在线分析的多标记流特征选择算法(Online Multi⁃label Streaming Feature Selection Based on Neighborhood Rough Set,OM⁃NRS).这些多标记流特征选择算法虽能有效地在流环境下选择一组较强差异能力的特征,但也存在高计算代价、选择的特征数量多等缺点. ...
Streaming feature selection for multilabel learning based on fuzzy mutual information
1
2017
... 然而,上述方法只能处理静态的多标记特征选择.大量实际应用场景中多标记数据的特征通常无法一次性全部获得,而要根据实际需求或时间顺序逐步提取相应特征.如在无人车的自动驾驶过程中,无人车根据实际需求自动切换传感器及传输时间顺序提取目标样本特征,然后进行实时特征处理.为了使到达的特征被及时处理,许多在线流多标记特征选择算法被提出.程玉胜等[13 ] 提出动态滑动窗口加权互信息流特征选择,Lin et al提出[14 ] 基于模糊互信息的多标记流特征选择算法,Liu et al[15 ] 提出基于邻域依赖度在线分析的多标记流特征选择算法(Online Multi⁃label Streaming Feature Selection Based on Neighborhood Rough Set,OM⁃NRS).这些多标记流特征选择算法虽能有效地在流环境下选择一组较强差异能力的特征,但也存在高计算代价、选择的特征数量多等缺点. ...
Online multi?label streaming feature selection based on neighborhood rough set
1
2018
... 然而,上述方法只能处理静态的多标记特征选择.大量实际应用场景中多标记数据的特征通常无法一次性全部获得,而要根据实际需求或时间顺序逐步提取相应特征.如在无人车的自动驾驶过程中,无人车根据实际需求自动切换传感器及传输时间顺序提取目标样本特征,然后进行实时特征处理.为了使到达的特征被及时处理,许多在线流多标记特征选择算法被提出.程玉胜等[13 ] 提出动态滑动窗口加权互信息流特征选择,Lin et al提出[14 ] 基于模糊互信息的多标记流特征选择算法,Liu et al[15 ] 提出基于邻域依赖度在线分析的多标记流特征选择算法(Online Multi⁃label Streaming Feature Selection Based on Neighborhood Rough Set,OM⁃NRS).这些多标记流特征选择算法虽能有效地在流环境下选择一组较强差异能力的特征,但也存在高计算代价、选择的特征数量多等缺点. ...
Multi?label fea?ture selection based on max?dependency and min?redundancy
8
2015
... 定义1[16 ] 给定多标记决策系统U , F , L ,
... 定义2[16 ] 给定多标记决策系统U , F , L
... 定义3[16 ] 给定多标记决策系统U , F , L U L ∀ x ∈ U ∀ l ∈ L x L m n e u ( x ) ≥ 0 x
... 定义4[16 ] 给定多标记决策系统U , F , L U = x 1 , x 2 , … , x n f ⊆ F L . 样本x i f δ f n e u ( x i )
... 定义5[16 ] 假设有两个多标记学习下的特征子集r , f ⊆ F x i r ⋃ f δ r ⋃ f n e u ( x i )
... 定义6[16 ] 假设有两个多标记学习下的特征子集r , f ⊆ F
... 定义7[16 ] 假设有两个多标记学习下的特征子集r , f ⊆ F
... 定义8[16 ] 假设有一个多标记学习下的特征子集r ⊆ F L = l 1 , l 2 , ⋯ , l m r L
Input feature selection for classification problems
1
2002
... 综合Kwak and Choi[17 ] 所述,在多标记学习中平均间隔下,多标记邻域交互增益信息可近似为: ...
Feature selection for multi?label naive Bayes classification
1
2009
... 为了有效地评估所提算法,选择五个不同的算法进行对比:MLNB (Feature selection for multi⁃label naive Bayes classification)[18 ] ,MDDM(Multi⁃Label Dimensionality Reduction via Dependence Maximization),根据算法投影方式分为MDDMspc和MDDMproj,PMU (Feature Selection for Multi⁃label Classification Using Multivariate Mutual Information)[19 ] 和RF⁃ML(ReliefF for Multi⁃Label Feature Selection)[20 ] .SMFS算法中β k 个(SMFS算法得到的特征子集个数)特征作为特征子集.最后用ML⁃KNN (Multi⁃Label k ⁃Nearest Neighbor)算法作为多标记分类器. ...
Feature selection for multi?label classification using multivariate mutual information
1
2013
... 为了有效地评估所提算法,选择五个不同的算法进行对比:MLNB (Feature selection for multi⁃label naive Bayes classification)[18 ] ,MDDM(Multi⁃Label Dimensionality Reduction via Dependence Maximization),根据算法投影方式分为MDDMspc和MDDMproj,PMU (Feature Selection for Multi⁃label Classification Using Multivariate Mutual Information)[19 ] 和RF⁃ML(ReliefF for Multi⁃Label Feature Selection)[20 ] .SMFS算法中β k 个(SMFS算法得到的特征子集个数)特征作为特征子集.最后用ML⁃KNN (Multi⁃Label k ⁃Nearest Neighbor)算法作为多标记分类器. ...
ReliefF for multi?label feature selection
1
2013
... 为了有效地评估所提算法,选择五个不同的算法进行对比:MLNB (Feature selection for multi⁃label naive Bayes classification)[18 ] ,MDDM(Multi⁃Label Dimensionality Reduction via Dependence Maximization),根据算法投影方式分为MDDMspc和MDDMproj,PMU (Feature Selection for Multi⁃label Classification Using Multivariate Mutual Information)[19 ] 和RF⁃ML(ReliefF for Multi⁃Label Feature Selection)[20 ] .SMFS算法中β k 个(SMFS算法得到的特征子集个数)特征作为特征子集.最后用ML⁃KNN (Multi⁃Label k ⁃Nearest Neighbor)算法作为多标记分类器. ...
A comparison of alternative tests of significance for the problem of m rankings
1
1940
... 为了更直观地对比SMFS和五个对比算法之间分类性能的差异,采用Friedman[21 ] 测试和Bonferroni⁃Dunn[22 ] 测试. ...
Multiple comparisons among means
1
1961
... 为了更直观地对比SMFS和五个对比算法之间分类性能的差异,采用Friedman[21 ] 测试和Bonferroni⁃Dunn[22 ] 测试. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}